一、引言
在实际爬虫开发中,我们经常会遇到一种特殊的数据存储方式:网站将关键数据(如文章ID)直接埋点在HTML标签的data-*自定义属性中。这种设计虽然方便了前端JavaScript调用,却给爬虫开发带来了新的挑战------需要从属性而非文本内容中提取数据。
本文将深入分析一个针对 雅式橡塑网(adsalecprj.com) 的爬虫设计案例。该爬虫创新性地解决了 "HTML属性数据埋点提取" 和 "分页起始偏移控制" 两大核心难题,实现了对新闻数据的高效采集。
与之前案例的核心差异:
- 数据存储位置差异 :ID存储在
data-id属性中,而非URL或文本中 - 分页起始差异:page从2开始(之前案例多从1开始)
- ID类型差异:纯数字ID,无需正则提取
- 解析方式差异:直接提取属性值,无需复杂正则
二、系统架构与核心流程
2.1 整体架构设计
该爬虫采用 "属性提取 + 索引关联 + 偏移分页" 的架构,整体流程如下:
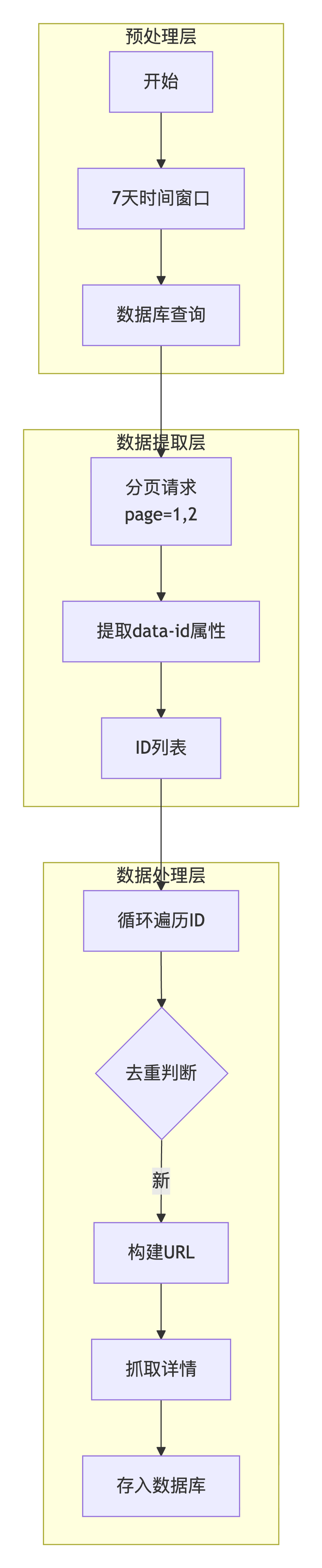
2.2 数据流向图

三、关键技术难点与解决方案
难点一:HTML属性数据埋点提取
问题描述:
该网站将新闻ID存储在HTML标签的data-id自定义属性中,而不是显示在文本内容或URL中。传统的文本提取方式完全失效,必须专门提取属性值。
解决方案:
使用CSS选择器提取特定元素的data-id属性:
javascript
// 新闻地址列表节点配置
{
"variable-name": ["news_urllist", "page"],
"variable-value": [
// 提取#new_ajax_hmtls元素的data-id属性
"${extract.selectors(resp.html, '#new_ajax_hmtls', 'attr', 'data-id')}",
"${page==null?2:page+1}" // 注意:page从2开始
]
}属性埋点原理图:
提取结果
提取过程
HTML结构
data-id='12345'
data-title='新闻标题'
data-date='2024-01-15'>
CSS选择器
#new_ajax_hmtls
attr参数
'data-id'
12345
HTML示例:
html
<!-- 实际页面结构 -->
<div id="new_ajax_hmtls"
data-id="12345"
data-title="塑料行业新趋势"
data-date="2024-01-15">
<!-- 其他内容 -->
</div>
<!-- 提取结果 -->
12345难点二:分页起始偏移控制
问题描述:
该网站的分页逻辑特殊,第一页的page参数为1,但后续页面的page从2开始递增。如果按照常规方式从1开始,会导致页码错位。
解决方案:
调整分页起始值和递增逻辑:
javascript
// 抓取新闻地址列表节点 - URL模板
{
"url": "https://www.adsalecprj.com/en/news/article_ajax_index?page=${page==null?1:page}&return_type=view"
}
// 定义变量节点 - 分页控制
{
"variable-name": ["news_urllist", "page"],
"variable-value": [
"${extract.selectors(resp.html, '#new_ajax_hmtls', 'attr', 'data-id')}",
"${page==null?2:page+1}" // 首次设置为2,后续递增
]
}
// 循环控制条件
"condition": "${page<=2}" // 只抓取2页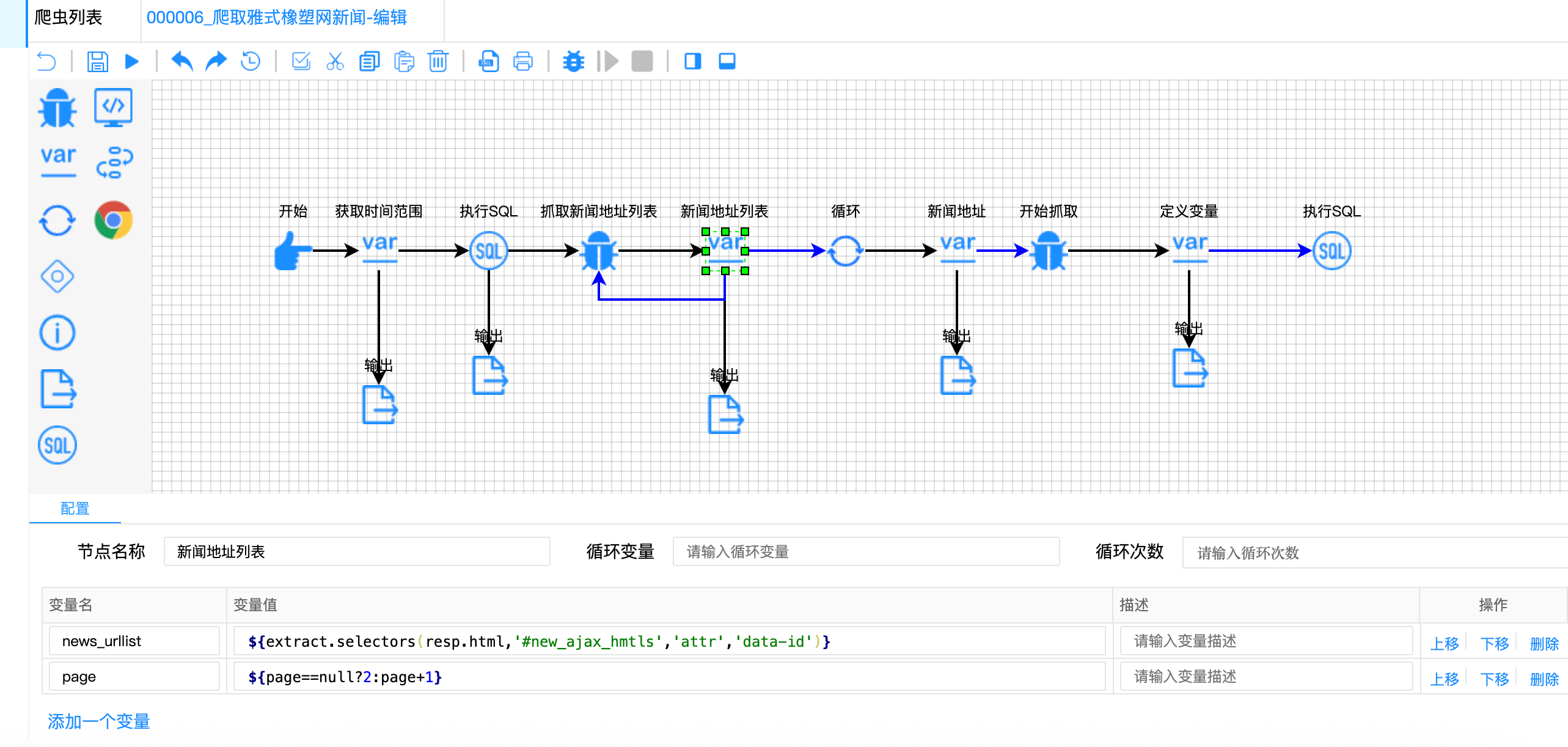
分页逻辑示意图:
循环控制
第二次请求
首次请求
是
否
page=null
URL中使用1
?page=1
提取ID列表
设置page=2
page=2
URL中使用2
?page=2
提取ID列表
设置page=3
page<=2?
结束
分页参数对照表:
| 请求次数 | page变量值 | URL中的page | 说明 |
|---|---|---|---|
| 第1次 | null | 1 | 首次请求,获取第一页 |
| 第2次 | 2 | 2 | 第二次请求,获取第二页 |
| 第3次 | 3 | 3 | 触发page<=2条件,停止 |
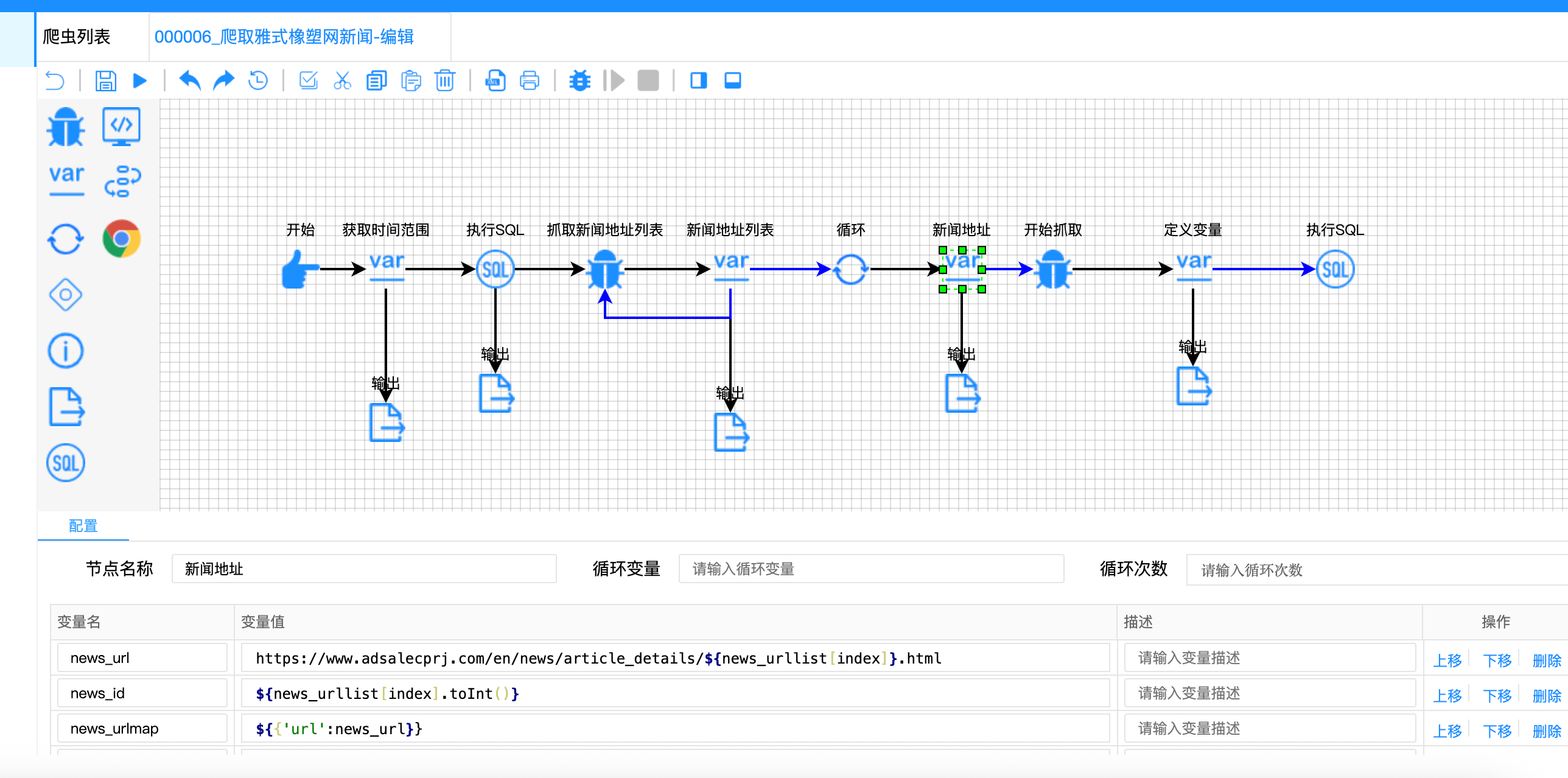
难点三:纯数字ID的直接使用
问题描述:
提取到的data-id已经是纯数字格式(如12345),可以直接使用,无需正则提取或类型转换。
解决方案:
直接使用提取的值,只需简单类型转换:
javascript
// 新闻地址节点配置
{
"variable-name": ["news_url", "news_id", "news_urlmap", "query_result"],
"variable-value": [
// 直接拼接ID到URL
"https://www.adsalecprj.com/en/news/article_details/${news_urllist[index]}.html",
// 直接转换为整数
"${news_urllist[index].toInt()}",
"${{'url': news_url}}",
"${!rs.contains(news_urlmap)}"
]
}
ID处理对比:
| 案例 | ID原始格式 | 处理方式 | 复杂度 |
|---|---|---|---|
| icis新闻 | /news/123/abc | 复杂正则 | ⭐⭐⭐ |
| polymerupdate博客 | 对象属性.Id | 直接使用 | ⭐ |
| bioplasticsnews | post-12345 | 正则提取 | ⭐⭐ |
| 雅式橡塑网 | 12345 | toInt() | ⭐ |
难点四:单元素多属性提取
问题描述:
#new_ajax_hmtls元素可能包含多个data-*属性,但只需要提取data-id。
解决方案:
精确指定要提取的属性名:
javascript
// 只提取data-id属性
"${extract.selectors(resp.html, '#new_ajax_hmtls', 'attr', 'data-id')}"
// 如果需要其他属性,可以分别提取
// data-title: "${extract.selectors(resp.html, '#new_ajax_hmtls', 'attr', 'data-title')}"
// data-date: "${extract.selectors(resp.html, '#new_ajax_hmtls', 'attr', 'data-date')}"难点五:7天时间窗口
问题描述:
需要抓取最近7天的新闻,反映该网站更新频率较高。
解决方案:
动态时间范围计算:
javascript
// 获取时间范围节点
{
"variable-name": ["start_date", "end_date"],
"variable-value": [
"${date.format(date.addDays(date.now(),-7),'yyyy-MM-dd')}", // 7天前
"${date.format(date.addDays(date.now(),1),'yyyy-MM-dd')}" // 明天
]
}四、核心代码实现解析
4.1 属性提取器
javascript
// 伪代码:HTML属性提取器
class AttributeExtractor {
extractDataId(html, selector = '#new_ajax_hmtls', attribute = 'data-id') {
// 使用DOM解析
const element = this.findElement(html, selector);
if (!element) return null;
// 获取属性值
return element.getAttribute(attribute);
}
extractMultipleAttributes(html, selector, attributes) {
const element = this.findElement(html, selector);
if (!element) return {};
const result = {};
attributes.forEach(attr => {
result[attr] = element.getAttribute(attr);
});
return result;
}
findElement(html, selector) {
// 简化的DOM解析逻辑
// 实际使用Cheerio或jsdom
return null;
}
}4.2 偏移分页控制器
javascript
// 伪代码:偏移分页控制器
class OffsetPaginationController {
constructor(maxPage = 2) {
this.maxPage = maxPage;
this.currentPage = null;
}
getNextPage() {
if (this.currentPage === null) {
return 1; // 首次请求使用1
}
return this.currentPage + 1;
}
shouldContinue() {
if (this.currentPage === null) return true;
return this.currentPage <= this.maxPage;
}
updatePage(response) {
// 更新当前页,下次请求使用page+1
if (this.currentPage === null) {
this.currentPage = 2; // 首次响应后,下次从2开始
} else {
this.currentPage++;
}
}
}
// 使用示例
const paginator = new OffsetPaginationController(2);
while (paginator.shouldContinue()) {
const page = paginator.getNextPage();
await fetchPage(page);
paginator.updatePage();
}4.3 URL构建器
javascript
// 伪代码:ID到URL的转换器
class UrlBuilder {
constructor(baseUrl, idPlaceholder = '${id}') {
this.template = baseUrl; // https://.../article_details/${id}.html
this.placeholder = idPlaceholder;
}
buildFromId(id) {
return this.template.replace(this.placeholder, id);
}
buildFromIdList(idList) {
return idList.map(id => this.buildFromId(id));
}
}
// 使用示例
const builder = new UrlBuilder(
'https://www.adsalecprj.com/en/news/article_details/${id}.html'
);
const url = builder.buildFromId('12345');
// https://.../article_details/12345.html五、与前五个案例的对比分析
5.1 核心差异点对比
| 维度 | 雅式橡塑网 | icis新闻 | polymerupdate博客 | polymerupdate新闻 | bioplasticsnews | chemanalyst |
|---|---|---|---|---|---|---|
| 数据存储位置 | data-id属性 | JSON嵌套HTML | JSON对象 | HTML文本 | HTML属性 | HTML文本 |
| ID格式 | 纯数字 | URL中数字 | 对象属性 | URL中数字 | post-数字 | URL中数字 |
| 提取方式 | 属性提取 | 复杂正则 | 对象属性 | 简单正则 | 正则提取 | 简单正则 |
| 分页起始 | page从2开始 | page从1开始 | page从1开始 | page从1开始 | page从1开始 | page从1开始 |
| 分页上限 | 2页 | 4页 | 1页 | 1页 | 动态 | 23页 |
| 时间窗口 | 7天 | 90天 | 30天 | 7天 | 90天 | 7天 |
| 解析复杂度 | ⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐ | ⭐⭐ | ⭐ |
5.2 差异化技术难点
雅式橡塑网
data-id属性提取
分页偏移控制
纯数字直接使用
前五个案例
HTML文本提取
JSON解析
正则提取
5.3 ID提取方式演进
URL正则提取
chemanalyst
对象属性提取
polymerupdate博客
双列表关联
bioplasticsnews
复杂正则
icis新闻
属性直接提取
雅式橡塑网
六、性能优化与最佳实践
6.1 属性提取优化
javascript
// 批量属性提取
const attributes = extract.selectors(resp.html, '#new_ajax_hmtls', 'attrs');
const dataId = attributes['data-id'];
const dataTitle = attributes['data-title'];6.2 分页控制优化
| 场景 | 首次page | 后续page | URL模板 |
|---|---|---|---|
| 常规分页 | 1 | page+1 | ?page=${page} |
| 偏移分页 | 1 | page+1(但page从2开始) | ?page=${page} |
| 路径分页 | 1 | page+1 | /page/${page}/ |
6.3 数据类型转换
javascript
// 安全的类型转换
function safeToInt(value) {
if (value === null || value === undefined) return null;
const intValue = parseInt(value);
return isNaN(intValue) ? null : intValue;
}
// 使用示例
const newsId = safeToInt(news_urllist[index]);七、总结与经验分享
7.1 核心收获
- 属性提取技术 :学会从HTML标签的
data-*属性中提取数据 - 分页偏移控制:处理非标准分页起始值
- 纯数字直接使用:简化数据处理流程
- 单元素多属性:同一个元素可能包含多个数据字段
7.2 可复用经验
- 识别数据埋点 :通过浏览器开发者工具查看元素属性,发现
data-*存储的数据 - 精确属性提取 :使用
attr参数指定要提取的属性名 - 分页逻辑分析:仔细分析URL参数变化规律,发现特殊分页逻辑
- 数据类型预判:提前确认ID格式,选择合适的处理方式
7.3 适用场景
该爬虫设计模式适用于:
- 使用HTML5
data-*属性存储数据的网站 - 分页逻辑非标准的场景
- ID已经是纯数字格式的网站
- 前端JavaScript驱动的动态网站
八、附录:核心配置对照表
| 节点类型 | 核心作用 | 关键技术点 |
|---|---|---|
| 获取时间范围 | 动态计算7天窗口 | date.addDays(now,-7) |
| 执行SQL(查询) | 获取已抓取记录 | like '%adsalecprj.com%' |
| 抓取新闻地址列表 | GET请求列表页 | ?page=${page} |
| 新闻地址列表 | 属性提取 | attr参数提取data-id |
| 新闻地址 | URL构建+ID转换 | 直接拼接,toInt() |
| 开始抓取 | 获取新闻详情页 | 无代理 |
| 定义变量 | 结构化提取 | 标题/时间/作者/内容 |
| 执行SQL(插入) | 存储数据 | source='adsalecprj' |
通过以上设计,该爬虫成功应对了HTML属性数据埋点和分页偏移控制的双重挑战,实现了对雅式橡塑网新闻网站的高效增量抓取。其中的属性提取技术、偏移分页控制等思路,对于处理前端数据埋点类网站的爬虫开发具有很高的参考价值。