企业级文档自动化处理实战:合同/财报/标书智能解析系统搭建指南
一、技术架构全景图
文档自动化处理的核心挑战在于:如何将非结构化文档(PDF/Word/扫描件)转化为结构化数据,并通过LLM进行深度理解。
┌─────────────────────────────────────────────────────────────┐
│ 文档自动化处理流水线 │
├─────────────┬─────────────┬─────────────┬──────────────────┤
│ 文档接入层 │ 解析引擎层 │ 智能分析层 │ 应用输出层 │
├─────────────┼─────────────┼─────────────┼──────────────────┤
│ • PDF/Word │ • OCR识别 │ • NER实体 │ • 结构化报表 │
│ • 扫描件 │ • 版面分析 │ 提取 │ • 风险预警 │
│ • 图片 │ • 表格还原 │ • 条款分类 │ • 问答系统 │
│ • 邮件附件 │ • Markdown │ • 语义检索 │ • API接口 │
│ │ 转换 │ • 摘要生成 │ │
└─────────────┴─────────────┴─────────────┴──────────────────┘架构图
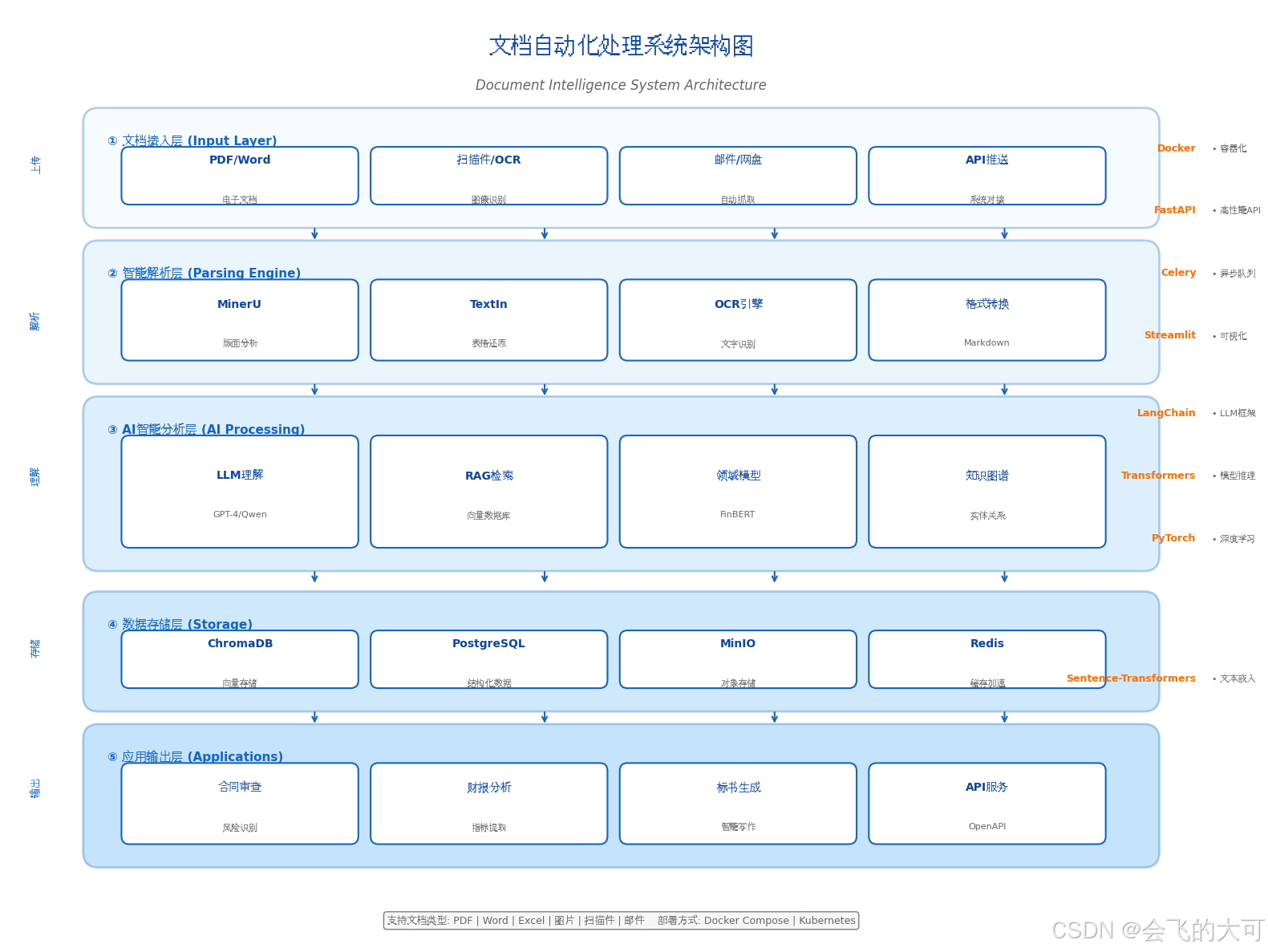
二、环境准备与基础安装
2.1 系统环境要求
| 组件 | 最低配置 | 推荐配置 |
|---|---|---|
| CPU | 4核 | 8核+ |
| 内存 | 16GB | 32GB+ |
| 存储 | 50GB SSD | 200GB NVMe |
| GPU | 可选 | RTX 3060+(加速推理) |
| 操作系统 | Ubuntu 20.04/22.04 | Ubuntu 22.04 LTS |
2.2 基础依赖安装
bash
# 1. 系统依赖更新
sudo apt-get update && sudo apt-get upgrade -y
# 2. 安装Python 3.10+ 和基础工具
sudo apt-get install -y python3.10 python3.10-pip python3.10-venv \
git wget curl tesseract-ocr tesseract-ocr-chi-sim \
poppler-utils libmagic1
# 3. 安装Docker(用于部署文档解析服务)
curl -fsSL https://get.docker.com | sudo sh
sudo usermod -aG docker $USER
newgrp docker
# 4. 创建工作目录
mkdir -p ~/doc-ai/{contracts,reports,bids,models,storage}
cd ~/doc-ai
python3.10 -m venv venv
source venv/bin/activate2.3 核心Python依赖
创建 requirements.txt:
txt
# 文档解析核心库
docling>=2.5.0 # IBM开源文档解析
marker-pdf>=0.3.0 # 高质量PDF转Markdown
pdfplumber>=0.11.0 # PDF表格提取
pymupdf>=1.24.0 # 快速PDF处理
python-docx>=1.1.0 # Word处理
pillow>=10.0.0 # 图像处理
# LLM与RAG框架
langchain>=0.3.0
langchain-community>=0.3.0
langchain-openai>=0.2.0
openai>=1.35.0
qwen-agent>=0.3.0 # 通义千问生态
# 向量数据库与嵌入
chromadb>=0.5.0
sentence-transformers>=3.0.0
faiss-cpu>=1.8.0 # 或 faiss-gpu
# 金融NLP专用
transformers>=4.40.0
torch>=2.3.0
finbert-embedding>=0.1.0
# 其他工具
pandas>=2.2.0
numpy>=1.26.0
streamlit>=1.38.0 # 界面展示
fastapi>=0.115.0 # API服务
uvicorn>=0.30.0
pydantic>=2.8.0
python-multipart>=0.0.9安装依赖:
bash
pip install -r requirements.txt三、合同智能解析实战
3.1 技术选型:MinerU + LLM方案
MinerU 是当前开源领域文档解析的标杆工具,支持复杂版面分析、表格识别、公式提取。
步骤1:安装MinerU
bash
# 安装MinerU(支持CPU/GPU)
pip install mineru>=0.9.0
# 下载模型权重
git clone https://github.com/opendatalab/MinerU.git mineru-src
cd mineru-src
pip install -e .
# 初始化配置
magic-pdf --help # 首次运行自动下载模型步骤2:合同解析核心代码
创建 contract_parser.py:
python
import os
import json
import re
from datetime import datetime
from typing import Dict, List, Optional
from pathlib import Path
from magic_pdf.data.data_reader_writer import FileBasedDataReader
from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze
from magic_pdf.data.dataset import PymuDocDataset
from magic_pdf.config.enums import SupportedPdfParseMethod
class ContractParser:
"""合同智能解析器"""
def __init__(self, model_dir: Optional[str] = None):
self.model_dir = model_dir
self.ner_patterns = {
'party_a': r'[甲方|出售方|转让方|发包方|委托方][::]\s*([^\n]+)',
'party_b': r'[乙方|购买方|受让方|承包方|受托方][::]\s*([^\n]+)',
'amount': r'(?:人民币|¥|¥)\s*([0-9,]+(?:\.[0-9]{1,2})?)\s*[元整]*',
'date': r'(\d{4}年\d{1,2}月\d{1,2}日|\d{4}-\d{2}-\d{2})',
'contract_no': r'合同编号[::]\s*([^\n]+)',
}
def parse_pdf(self, pdf_path: str) -> Dict:
"""解析PDF合同"""
print(f"正在解析: {pdf_path}")
# 1. 读取PDF
reader = FileBasedDataReader("")
pdf_bytes = reader.read(pdf_path)
dataset = PymuDocDataset(pdf_bytes)
# 2. 分析文档类型并解析
if dataset.classify() == SupportedPdfParseMethod.OCR:
result = doc_analyze(dataset, ocr=True)
else:
result = doc_analyze(dataset, ocr=False)
# 3. 提取Markdown格式内容
markdown_content = result.get_markdown()
# 4. 结构化提取
structured_data = self._extract_structure(markdown_content)
return {
'file_name': Path(pdf_path).name,
'parse_time': datetime.now().isoformat(),
'markdown': markdown_content,
'structured': structured_data,
'metadata': result.get_metadata()
}
def _extract_structure(self, text: str) -> Dict:
"""使用规则+LLM提取结构化信息"""
data = {
'parties': {},
'key_dates': [],
'financial_terms': [],
'clauses': [],
'risks': []
}
# 正则提取基础信息
for key, pattern in self.ner_patterns.items():
matches = re.findall(pattern, text)
if matches:
data['parties'][key] = matches
# 条款分类(基于关键词)
clause_keywords = {
'payment': ['付款', '支付', '结算', '发票'],
'delivery': ['交付', '交货', '验收', '物流'],
'liability': ['违约', '赔偿', '责任', '保证金'],
'termination': ['解除', '终止', '撤销', '退出'],
'confidentiality': ['保密', '机密', '知识产权']
}
lines = text.split('\n')
for line in lines:
line = line.strip()
if len(line) > 10 and ('条' in line or '款' in line or '章' in line):
clause_type = 'general'
for ctype, keywords in clause_keywords.items():
if any(kw in line for kw in keywords):
clause_type = ctype
break
data['clauses'].append({
'text': line[:200],
'type': clause_type
})
return data
def risk_analysis(self, structured_data: Dict, llm_client=None) -> List[Dict]:
"""风险条款识别(可接入LLM)"""
risks = []
# 基于规则的风险识别
high_risk_keywords = [
'无限责任', '单方解除', '自动续期', '不得转让',
'全部权利', '独家授权', '永久授权'
]
for clause in structured_data.get('clauses', []):
text = clause['text']
for keyword in high_risk_keywords:
if keyword in text:
risks.append({
'clause': text,
'risk_type': 'high',
'keyword': keyword,
'suggestion': f'建议审查"{keyword}"相关条款的合理性'
})
# LLM深度分析(可选)
if llm_client and len(structured_data['markdown']) > 100:
prompt = f"""作为法务专家,请分析以下合同条款的潜在风险:
{structured_data['markdown'][:3000]}
请识别:
1. 对甲方不利的条款
2. 对乙方不利的条款
3. 模糊不清的表述
4. 缺失的关键条款
输出JSON格式:{{"risks": [{{"type": "", "description": "", "severity": ""}}]}}"""
try:
response = llm_client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.1
)
llm_risks = json.loads(response.choices[0].message.content)
risks.extend(llm_risks.get('risks', []))
except Exception as e:
print(f"LLM分析失败: {e}")
return risks
# 使用示例
if __name__ == "__main__":
parser = ContractParser()
# 解析合同
result = parser.parse_pdf("./contracts/sample_contract.pdf")
# 保存结果
with open("./output/contract_result.json", "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)
# 风险分析
risks = parser.risk_analysis(result['structured'])
print(f"识别到 {len(risks)} 个风险点")
for risk in risks[:5]:
print(f"- [{risk['risk_type']}] {risk['clause'][:50]}...")3.2 批量处理与API服务
创建 contract_api.py(FastAPI服务):
python
from fastapi import FastAPI, File, UploadFile, BackgroundTasks
from fastapi.responses import JSONResponse
import tempfile
import os
from contract_parser import ContractParser
app = FastAPI(title="合同智能解析API")
parser = ContractParser()
@app.post("/parse/contract")
async def parse_contract(file: UploadFile = File(...)):
"""单文件解析接口"""
# 保存临时文件
suffix = Path(file.filename).suffix
with tempfile.NamedTemporaryFile(delete=False, suffix=suffix) as tmp:
content = await file.read()
tmp.write(content)
tmp_path = tmp.name
try:
result = parser.parse_pdf(tmp_path)
return JSONResponse(content={
"success": True,
"filename": file.filename,
"data": result
})
finally:
os.unlink(tmp_path)
@app.post("/batch/parse")
async def batch_parse(files: List[UploadFile] = File(...)):
"""批量解析接口"""
results = []
for file in files:
suffix = Path(file.filename).suffix
with tempfile.NamedTemporaryFile(delete=False, suffix=suffix) as tmp:
content = await file.read()
tmp.write(content)
tmp_path = tmp.name
try:
result = parser.parse_pdf(tmp_path)
results.append({
"filename": file.filename,
"status": "success",
"data": result
})
except Exception as e:
results.append({
"filename": file.filename,
"status": "error",
"error": str(e)
})
finally:
os.unlink(tmp_path)
return {"success": True, "results": results}
# 启动命令:uvicorn contract_api:app --host 0.0.0.0 --port 8000四、财报智能分析实战
4.1 技术方案:TextIn + 金融LLM
财报解析的核心难点在于表格结构还原 和财务指标计算 。推荐使用 TextIn 的PDF转Markdown服务(大模型加速器)结合 FinBERT 进行金融语义理解。
步骤1:TextIn接入配置
bash
# 注册TextIn获取API Key: https://www.textin.com
export TEXTIN_APP_ID="your_app_id"
export TEXTIN_SECRET_CODE="your_secret_code"创建 financial_report.py:
python
import os
import requests
import base64
import json
from typing import Dict, List
import pandas as pd
from transformers import BertTokenizer, BertForSequenceClassification
import torch
class FinancialReportAnalyzer:
"""财报智能分析器"""
def __init__(self):
self.textin_url = "https://api.textin.com/ai/service/v1/pdf_to_markdown"
self.app_id = os.getenv("TEXTIN_APP_ID")
self.secret_code = os.getenv("TEXTIN_SECRET_CODE")
# 加载金融情感分析模型
self.tokenizer = BertTokenizer.from_pretrained("ProsusAI/finbert")
self.finbert = BertForSequenceClassification.from_pretrained("ProsusAI/finbert")
self.finbert.eval()
def parse_pdf(self, pdf_path: str) -> Dict:
"""调用TextIn解析财报PDF"""
with open(pdf_path, "rb") as f:
pdf_base64 = base64.b64encode(f.read()).decode('utf-8')
headers = {
"x-ti-app-id": self.app_id,
"x-ti-secret-code": self.secret_code,
"Content-Type": "application/json"
}
payload = {
"file_base64": pdf_base64,
"page_start": 0,
"page_count": 100,
"table_flavor": "md", # Markdown格式表格
"parse_mode": "scan", # 扫描件优化
"apply_document_tree": True # 保留文档结构
}
response = requests.post(
self.textin_url,
headers=headers,
json=payload,
timeout=120
)
if response.status_code == 200:
result = response.json()
return self._process_textin_result(result)
else:
raise Exception(f"TextIn解析失败: {response.text}")
def _process_textin_result(self, api_result: Dict) -> Dict:
"""处理TextIn返回结果"""
markdown = api_result.get("result", {}).get("markdown", "")
# 提取表格数据
tables = self._extract_tables(markdown)
# 提取关键财务指标
metrics = self._extract_financial_metrics(markdown)
# 管理层讨论情感分析
mdna_sentiment = self._analyze_sentiment(markdown)
return {
"markdown": markdown,
"tables": tables,
"metrics": metrics,
"sentiment": mdna_sentiment,
"structure": self._extract_structure(markdown)
}
def _extract_tables(self, markdown: str) -> List[pd.DataFrame]:
"""提取Markdown表格并转为DataFrame"""
tables = []
lines = markdown.split('\n')
table_lines = []
in_table = False
for line in lines:
if '|' in line and '---' not in line:
if not in_table:
in_table = True
table_lines = [line]
else:
table_lines.append(line)
else:
if in_table and table_lines:
# 解析表格
rows = []
for tl in table_lines:
cells = [c.strip() for c in tl.split('|')[1:-1]]
rows.append(cells)
if len(rows) > 1:
df = pd.DataFrame(rows[1:], columns=rows[0])
tables.append(df)
in_table = False
table_lines = []
return tables
def _extract_financial_metrics(self, text: str) -> Dict:
"""提取关键财务指标(基于正则+NER)"""
metrics = {}
# 营收模式
revenue_patterns = [
r'营业收入[::]?\s*([0-9,]+(?:\.[0-9]+)?)\s*亿元?',
r'营收[::]?\s*([0-9,]+(?:\.[0-9]+)?)\s*亿元?'
]
for pattern in revenue_patterns:
match = re.search(pattern, text)
if match:
metrics['revenue'] = float(match.group(1).replace(',', ''))
break
# 净利润
profit_patterns = [
r'归母净利润[::]?\s*([0-9,]+(?:\.[0-9]+)?)\s*亿元?',
r'净利润[::]?\s*([0-9,]+(?:\.[0-9]+)?)\s*亿元?'
]
for pattern in profit_patterns:
match = re.search(pattern, text)
if match:
metrics['net_profit'] = float(match.group(1).replace(',', ''))
break
# 同比增长率
growth_pattern = r'同比增长[::]?\s*([0-9]+(?:\.[0-9]+)?)%'
matches = re.findall(growth_pattern, text)
if matches:
metrics['growth_rates'] = [float(m) for m in matches[:3]]
# 毛利率
margin_pattern = r'毛利率[::]?\s*([0-9]+(?:\.[0-9]+)?)%'
match = re.search(margin_pattern, text)
if match:
metrics['gross_margin'] = float(match.group(1))
return metrics
def _analyze_sentiment(self, text: str) -> Dict:
"""使用FinBERT分析管理层讨论情感倾向"""
# 分段处理长文本
segments = [text[i:i+512] for i in range(0, min(len(text), 2048), 512)]
sentiments = []
for segment in segments:
inputs = self.tokenizer(
segment,
return_tensors="pt",
truncation=True,
max_length=512
)
with torch.no_grad():
outputs = self.finbert(**inputs)
probs = torch.softmax(outputs.logits, dim=1)
sentiment = torch.argmax(probs, dim=1).item()
confidence = probs[0][sentiment].item()
sentiments.append((sentiment, confidence))
# 统计整体情感
labels = ["negative", "neutral", "positive"]
avg_sentiment = sum([s[0] for s in sentiments]) / len(sentiments)
avg_confidence = sum([s[1] for s in sentiments]) / len(sentiments)
return {
"overall": labels[round(avg_sentiment)],
"confidence": round(avg_confidence, 3),
"segments": len(sentiments)
}
def generate_summary(self, analysis_result: Dict, llm_client=None) -> str:
"""生成财报摘要"""
metrics = analysis_result['metrics']
sentiment = analysis_result['sentiment']
summary_prompt = f"""基于以下财务数据生成专业分析师级别的财报摘要:
关键指标:
- 营业收入: {metrics.get('revenue', 'N/A')} 亿元
- 净利润: {metrics.get('net_profit', 'N/A')} 亿元
- 同比增长率: {metrics.get('growth_rates', [])}
- 毛利率: {metrics.get('gross_margin', 'N/A')}%
管理层讨论情感倾向: {sentiment['overall']} (置信度: {sentiment['confidence']})
要求:
1. 用3-5个要点总结核心业绩
2. 分析增长驱动因素
3. 提示潜在风险点
4. 给出投资评级建议(买入/持有/减持)
输出格式为Markdown列表。"""
if llm_client:
response = llm_client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": summary_prompt}],
temperature=0.3
)
return response.choices[0].message.content
else:
return self._rule_based_summary(metrics, sentiment)
def _rule_based_summary(self, metrics: Dict, sentiment: Dict) -> str:
"""基于规则的摘要生成(无LLM时备用)"""
summary = []
if 'revenue' in metrics and 'net_profit' in metrics:
summary.append(f"## 核心业绩\n")
summary.append(f"- 营收 {metrics['revenue']} 亿元,净利润 {metrics['net_profit']} 亿元")
if 'growth_rates' in metrics and metrics['growth_rates']:
avg_growth = sum(metrics['growth_rates']) / len(metrics['growth_rates'])
trend = "增长强劲" if avg_growth > 20 else "稳健增长" if avg_growth > 10 else "增长放缓"
summary.append(f"- 同比{trend},平均增长率 {avg_growth:.1f}%")
summary.append(f"\n## 管理层态度\n")
summary.append(f"- 管理层讨论整体呈 **{sentiment['overall']}** 倾向")
return "\n".join(summary)
# 使用示例
if __name__ == "__main__":
analyzer = FinancialReportAnalyzer()
# 解析财报
result = analyzer.parse_pdf("./reports/annual_report_2023.pdf")
# 生成摘要
summary = analyzer.generate_summary(result)
print(summary)
# 导出表格
for i, table in enumerate(result['tables']):
table.to_csv(f"./output/table_{i}.csv", index=False)4.2 财报对比分析
创建 report_comparator.py 实现多期财报对比:
python
class FinancialComparator:
"""财报对比分析器"""
def compare_periods(self, reports: List[Dict]) -> Dict:
"""多期财报对比"""
comparison = {
'trends': {},
'yoy_changes': [],
'anomalies': []
}
# 提取各期关键指标
periods = []
for report in reports:
metrics = report['metrics']
periods.append({
'revenue': metrics.get('revenue'),
'profit': metrics.get('net_profit'),
'margin': metrics.get('gross_margin')
})
# 计算同比变化
for i in range(1, len(periods)):
prev, curr = periods[i-1], periods[i]
changes = {}
for key in ['revenue', 'profit', 'margin']:
if prev[key] and curr[key]:
change = (curr[key] - prev[key]) / prev[key] * 100
changes[key] = round(change, 2)
# 异常检测(变化超过50%)
if abs(change) > 50:
comparison['anomalies'].append({
'metric': key,
'period': i,
'change': change
})
comparison['yoy_changes'].append(changes)
return comparison五、标书智能生成与解析
5.1 标书解析:RAG增强检索方案
标书通常包含点对点应答 和技术方案两大部分,需要结合向量检索和生成技术。
步骤1:搭建RAG环境
bash
# 安装RAG依赖
pip install langchain-chroma langchain-community sentence-transformers
# 下载中文嵌入模型
python -c "from sentence_transformers import SentenceTransformer; \
model = SentenceTransformer('BAAI/bge-large-zh-v1.5'); \
model.save('./models/bge-large-zh')"步骤2:标书RAG系统实现
创建 bid_rag_system.py:
python
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import SentenceTransformerEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import TextLoader, PyPDFLoader
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
import os
class BidDocumentRAG:
"""标书智能问答系统"""
def __init__(self, persist_dir="./storage/bid_chroma"):
self.persist_dir = persist_dir
self.embedding = SentenceTransformerEmbeddings(
model_name="./models/bge-large-zh"
)
self.vectorstore = None
self.qa_chain = None
def ingest_documents(self, doc_paths: List[str]):
"""摄入标书文档"""
documents = []
for path in doc_paths:
if path.endswith('.pdf'):
loader = PyPDFLoader(path)
else:
loader = TextLoader(path, encoding='utf-8')
docs = loader.load()
documents.extend(docs)
# 智能分块(保持段落完整性)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=50,
separators=["\n\n", "\n", "。", ";", " ", ""]
)
chunks = text_splitter.split_documents(documents)
# 构建向量库
self.vectorstore = Chroma.from_documents(
documents=chunks,
embedding=self.embedding,
persist_directory=self.persist_dir
)
self.vectorstore.persist()
print(f"已摄入 {len(documents)} 个文档,切分为 {len(chunks)} 个片段")
def setup_qa_chain(self, llm_client=None):
"""配置问答链"""
if not self.vectorstore:
self.vectorstore = Chroma(
persist_directory=self.persist_dir,
embedding_function=self.embedding
)
retriever = self.vectorstore.as_retriever(
search_type="mmr", # 最大边际相关性
search_kwargs={"k": 5, "fetch_k": 20}
)
self.qa_chain = RetrievalQA.from_chain_type(
llm=llm_client or ChatOpenAI(temperature=0.1),
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={
"prompt": self._get_bid_prompt()
}
)
def _get_bid_prompt(self):
"""标书专用提示模板"""
from langchain.prompts import PromptTemplate
template = """你是招投标专家,基于以下标书内容回答问题。
上下文:
{context}
问题:{question}
要求:
1. 如果涉及点对点应答,明确回答"满足"或"不满足"并说明理由
2. 引用具体的章节编号或页码
3. 如果不确定,明确说明"根据现有文档无法确定"
4. 保持专业、简洁的商务语言风格
回答:"""
return PromptTemplate(
template=template,
input_variables=["context", "question"]
)
def query(self, question: str) -> Dict:
"""查询标书内容"""
if not self.qa_chain:
raise ValueError("请先调用 setup_qa_chain() 初始化")
result = self.qa_chain.invoke({"query": question})
return {
"answer": result["result"],
"sources": [
{
"content": doc.page_content[:200],
"source": doc.metadata.get("source", "unknown"),
"page": doc.metadata.get("page", 0)
}
for doc in result["source_documents"]
]
}
def generate_point_response(self, requirements: List[str]) -> List[Dict]:
"""自动生成点对点应答"""
responses = []
for req in requirements:
# 检索相关内容
docs = self.vectorstore.similarity_search(req, k=3)
context = "\n".join([d.page_content for d in docs])
# 生成应答
prompt = f"""针对以下招标要求生成点对点应答:
招标要求:{req}
参考内容:{context}
请生成:
1. 应答结论(完全满足/部分满足/不满足)
2. 详细说明(2-3句话)
3. 证明材料(如有)
格式:JSON"""
response = self.qa_chain.llm.invoke(prompt)
responses.append({
"requirement": req,
"response": response.content,
"evidence": [d.metadata for d in docs]
})
return responses
# 使用示例
if __name__ == "__main__":
rag = BidDocumentRAG()
# 摄入历史标书和产品文档
rag.ingest_documents([
"./bids/history_bid_2023.pdf",
"./bids/product_spec_v2.docx",
"./bids/company_profile.pdf"
])
# 初始化问答链
rag.setup_qa_chain()
# 查询示例
result = rag.query("投标有效期是多久?是否支持远程部署?")
print(f"回答:{result['answer']}")
print(f"参考来源:{result['sources']}")5.2 标书自动生成
创建 bid_generator.py 实现基于模板的标书生成:
python
from docx import Document
from docx.shared import Pt, Inches
from docx.enum.text import WD_ALIGN_PARAGRAPH
import json
class BidGenerator:
"""标书智能生成器"""
def __init__(self, template_path: str):
self.template = Document(template_path)
self.rag_system = None
def set_rag_system(self, rag: BidDocumentRAG):
"""接入RAG系统获取内容"""
self.rag_system = rag
def generate_tech_proposal(self, bid_reqs: List[Dict], output_path: str):
"""生成技术方案部分"""
doc = Document()
# 标题
title = doc.add_heading('技术方案建议书', 0)
title.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 点对点应答表
doc.add_heading('一、点对点应答', level=1)
table = doc.add_table(rows=1, cols=3)
table.style = 'Light Grid Accent 1'
# 表头
hdr_cells = table.rows[0].cells
hdr_cells[0].text = '序号'
hdr_cells[1].text = '招标要求'
hdr_cells[2].text = '应答内容'
# 填充应答
for i, req in enumerate(bid_reqs, 1):
row_cells = table.add_row().cells
row_cells[0].text = str(i)
row_cells[1].text = req['description']
if self.rag_system:
# 基于RAG生成应答
result = self.rag_system.query(req['description'])
row_cells[2].text = result['answer']
else:
row_cells[2].text = "完全满足。详见技术方案。"
# 详细方案章节
doc.add_heading('二、详细技术方案', level=1)
sections = [
('2.1 系统架构', 'architecture'),
('2.2 功能实现', 'functions'),
('2.3 项目实施计划', 'implementation'),
('2.4 售后服务', 'service')
]
for title, key in sections:
doc.add_heading(title, level=2)
if self.rag_system:
content = self.rag_system.query(f"{title}的具体内容")
doc.add_paragraph(content['answer'])
else:
doc.add_paragraph(f"此处插入{title}相关内容...")
# 保存
doc.save(output_path)
print(f"标书已生成: {output_path}")
# 使用示例
if __name__ == "__main__":
generator = BidGenerator("./templates/bid_template.docx")
# 接入RAG(可选)
rag = BidDocumentRAG()
rag.ingest_documents(["./product_docs/"])
rag.setup_qa_chain()
generator.set_rag_system(rag)
# 定义招标要求
requirements = [
{"id": "1.1", "description": "支持高并发处理,QPS不低于1000"},
{"id": "1.2", "description": "提供7×24小时技术支持服务"},
{"id": "1.3", "description": "系统可用性达到99.99%"}
]
# 生成标书
generator.generate_tech_proposal(requirements, "./output/bid_proposal.docx")六、系统集成与部署
6.1 Docker Compose部署配置
创建 docker-compose.yml:
yaml
version: '3.8'
services:
# 文档解析API服务
doc-parser-api:
build: ./api
ports:
- "8000:8000"
volumes:
- ./models:/app/models:ro
- ./storage:/app/storage
- ./uploads:/app/uploads
environment:
- TEXTIN_APP_ID=${TEXTIN_APP_ID}
- TEXTIN_SECRET_CODE=${TEXTIN_SECRET_CODE}
- OPENAI_API_KEY=${OPENAI_API_KEY}
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
# 向量数据库
chroma:
image: chromadb/chroma:latest
ports:
- "8001:8000"
volumes:
- ./storage/chroma:/chroma/chroma
# 前端界面(Streamlit)
web-ui:
build: ./ui
ports:
- "8501:8501"
environment:
- API_ENDPOINT=http://doc-parser-api:8000
# 任务队列(Celery + Redis)
redis:
image: redis:7-alpine
ports:
- "6379:6379"
worker:
build: ./api
command: celery -A tasks worker --loglevel=info
volumes:
- ./storage:/app/storage
depends_on:
- redis
environment:
- REDIS_URL=redis://redis:6379/0
volumes:
chroma_data:6.2 监控与运维脚本
创建 monitor.py:
python
import psutil
import requests
import json
from datetime import datetime
class SystemMonitor:
"""系统监控"""
def check_health(self):
"""健康检查"""
status = {
'timestamp': datetime.now().isoformat(),
'system': {
'cpu_percent': psutil.cpu_percent(interval=1),
'memory_percent': psutil.virtual_memory().percent,
'disk_usage': psutil.disk_usage('/').percent
},
'services': {}
}
# 检查各服务
services = {
'api': 'http://localhost:8000/health',
'chroma': 'http://localhost:8001/api/v1/heartbeat',
'web_ui': 'http://localhost:8501'
}
for name, url in services.items():
try:
resp = requests.get(url, timeout=5)
status['services'][name] = 'healthy' if resp.status_code == 200 else 'unhealthy'
except Exception as e:
status['services'][name] = f'error: {str(e)}'
return status
def alert_if_needed(self, status: Dict):
"""异常告警"""
sys = status['system']
alerts = []
if sys['cpu_percent'] > 90:
alerts.append(f"CPU使用率过高: {sys['cpu_percent']}%")
if sys['memory_percent'] > 85:
alerts.append(f"内存使用率过高: {sys['memory_percent']}%")
if sys['disk_usage'] > 90:
alerts.append(f"磁盘使用率过高: {sys['disk_usage']}%")
# 发送告警(可接入钉钉/企业微信)
if alerts:
print(f"[ALERT] {datetime.now()}: {alerts}")
if __name__ == "__main__":
monitor = SystemMonitor()
status = monitor.check_health()
print(json.dumps(status, indent=2, ensure_ascii=False))
monitor.alert_if_needed(status)七、完整操作流程总结
7.1 一键启动脚本
创建 start.sh:
bash
#!/bin/bash
echo "🚀 启动文档自动化处理系统..."
# 1. 环境检查
if [ -z "$TEXTIN_APP_ID" ]; then
echo "❌ 错误: 未设置 TEXTIN_APP_ID"
exit 1
fi
# 2. 创建目录结构
mkdir -p storage/{chroma,uploads,outputs}
mkdir -p logs
# 3. 启动服务
docker-compose up -d
# 4. 等待服务就绪
echo "⏳ 等待服务启动..."
sleep 10
# 5. 健康检查
curl -s http://localhost:8000/health > /dev/null
if [ $? -eq 0 ]; then
echo "✅ API服务运行正常"
else
echo "⚠️ API服务可能未就绪,请检查日志: docker-compose logs doc-parser-api"
fi
echo ""
echo "🎉 系统启动完成!"
echo "📊 Web界面: http://localhost:8501"
echo "🔌 API文档: http://localhost:8000/docs"
echo ""
echo "使用示例:"
echo " curl -X POST -F 'file=@contract.pdf' http://localhost:8000/parse/contract"7.2 性能优化建议
| 优化项 | 具体措施 | 预期效果 |
|---|---|---|
| 解析加速 | 启用GPU加速(CUDA) | 速度提升5-10倍 |
| 批量处理 | 使用Celery异步队列 | 支持并发100+任务 |
| 缓存策略 | Redis缓存解析结果 | 重复文档秒级响应 |
| 模型量化 | 使用INT8量化模型 | 内存占用减少50% |
| 分块策略 | 按语义段落切分 | 检索准确率提升20% |
八、总结与展望
本文实战方案覆盖了合同解析 、财报分析 、标书生成三大核心场景,技术栈选型遵循以下原则:
- 解析层:MinerU(开源)+ TextIn(商业API)双轨方案,兼顾成本与精度
- 理解层:LangChain + 领域专用模型(FinBERT),确保金融/法律语义准确
- 应用层:RAG架构 + 生成式AI,实现从"检索"到"生成"的闭环
建议团队从合同审查场景切入,逐步扩展至全文档生命周期管理。
下一步可探索方向:
- 多模态文档理解(图表、印章、手写体)
- 私有化大模型部署(Llama 3/Qwen 72B)
- 智能工作流编排(审批流自动触发)
参考技术栈:
- 文档解析:MinerU, TextIn, Marker
- LLM框架:LangChain, Qwen-Agent
- 向量库:Chroma, FAISS