AI 智能体全流程实战:从 0 搭一个门店运营助手,用 API + 工具搜索 + 编码代理做出可复现闭环
基于 2026-05-29 到 2026-05-30 多条 AI 热点,拆解为什么智能体应该增强人而不是替代人,并落到一个餐饮场景的最小可用实现
先给最终效果:这篇不是聊抽象趋势,而是带你做一个能跑起来的最小原型。
我们要完成的产出有 3 个:
- 一个门店运营助手 API,能回答小龙虾门店的库存、活动、差评处理和文案生成问题。
- 一个简化版 Tool Search 机制,避免把所有工具一股脑塞进上下文,减少智能体的选择混乱。
- 一个编码代理协作流程,让 AI 帮你写脚本、跑实验、提建议,但最后由人审核,不把它当全自动背锅机。
如果你是开发者,这是一套可复现的最小架构;如果你是技术运营或副业实践者,这也是一个能快速验证行业场景的样板。
工具资源导航
如果你看完这波热点,想顺手把方案跑起来或者把账号环境补齐,这两个入口可以先收藏:
- JKS工具站:工具网站,真实靠谱,可开发票。
- YT SuperStore:工具网站,真实靠谱,可开发票。
文中工具入口属于资源信息整理,请结合平台规则和自身需求判断。
一、先看热点:这波新闻真正有价值的信号是什么
事实描述
- 2026-05-29,TechCrunch 讨论了企业过度 AI 上头的问题:决定用 AI 替代岗位的人,往往又最不了解这些岗位到底在做什么。
- 同样是 2026-05-29,Cognition 的 Scott Wu 提到,AI 编码代理不应该替代人类,Devin 的目标也不是把工程师整体踢出工位。
- 还是 2026-05-29,TechCrunch 的另一篇报道提到 Aaron Levie 对不少 CEO 的判断相当直白:很多人有点 AI psychosis。翻译成人话,就是把 AI 想象得比实际流程能力更全能。
- 2026-05-30,MarkTechPost 报道 Hermes Agent 为 MCP 加入 Tool Search,用来解决上下文膨胀问题。报道提到,Anthropic Evals 显示这套方法在 Opus 4 上把准确率从 49% 提升到 74%。
- 也是 2026-05-30,MarkTechPost 介绍了 AgentTrove:一个包含 170 万条 agentic traces 的开源数据集合,采用 ShareGPT 风格布局,适合做日志整理和后续训练数据清洗。
- 2026-05-29,OpenAI News 介绍 Braintrust 如何把客户请求转成代码:工程师使用 Codex 和 GPT-5.5 更快地做实验和开发。
观点分析
这几条新闻连起来看,结论很清楚:
真正往前走的方向,不是用 AI 直接替掉人,而是把 AI 接到真实工作流里。
换句话说,行业现在更像是从 3 个阶段进化:
- 从聊天演示,进入工具调用。
- 从工具调用,进入工作流编排。
- 从工作流编排,进入人类审核 + 日志沉淀 + 持续优化。
所以本文下面的实战,不是去复刻某家产品,而是基于这些公开信号,搭一个你能自己改、自己测、自己上线的小系统。
二、场景定义:做一个小龙虾门店运营助手
为什么选实体行业?因为它最能验证一句话:AI 不懂业务细节时,特别容易一本正经地胡说。
我们把场景限定为一个小龙虾门店,助手要解决 4 类问题:
- 查询套餐和库存
- 查询活动规则
- 总结用户评价
- 生成社群文案与回复建议
技术栈
- Python 3.11
- FastAPI
- requests
- 本地 Python 字典模拟工具数据
- 任意兼容消息接口的大模型 API
注意:下面代码是教学原型,用来演示思路与最小闭环,不是 Hermes、Devin、Codex 的官方实现。
三、全流程实战:从 0 跑通一个最小可用 Agent

第 1 步:安装依赖
bash
pip install fastapi uvicorn requests pydantic
第 2 步:准备工具注册表
先别一上来把 20 个工具全喂给模型。Hermes Agent 的新闻已经提醒我们:工具越多,上下文越容易膨胀。
所以先做一个简化版工具中心:
python
from fastapi import FastAPI
from pydantic import BaseModel
import os
import requests
app = FastAPI()
TOOLS = [
{
'name': 'menu_query',
'description': '查询小龙虾套餐、口味、价格和库存',
'keywords': '小龙虾', '套餐', '价格', '库存', '口味', '双人餐'
},
{
'name': 'promo_lookup',
'description': '查询满减、代金券、社群活动规则',
'keywords': '活动', '优惠', '满减', '代金券', '社群', '文案'
},
{
'name': 'review_summary',
'description': '查询最近差评和高频反馈',
'keywords': '差评', '评价', '出餐慢', '辣度', '分量', '口碑'
}
]
DATA = {
'menu_query': {
'88元双人餐': {'stock': 12, 'taste': '蒜香', '麻辣', 'note': '晚高峰库存波动较大'}
},
'promo_lookup': {
'today': '满 100 减 15', '社群接龙送酸梅汤'
},
'review_summary': {
'top_issues': '出餐慢', '辣度不稳定',
'top_praise': '分量足', '蒜香口味稳定'
}
}
第 3 步:先搜索工具,再暴露少量 schema
Hermes Agent 报道里的重点,不只是 Tool Search 这 2 个单词,而是它背后的思路:先找最相关的工具,再把有限的工具说明给模型。
原文提到的是 BM25 和渐进式 schema 披露。为了可复现,这里用一个更简单的关键词召回版:
python
def search_tools(query, topk=2):
scored = \[\]
for tool in TOOLS:
score = sum(1 for k in tool'keywords' if k in query)
if score > 0:
scored.append((score, tool))
scored.sort(key=lambda x: x0, reverse=True)
result = tool for _, tool in scored\[:topk]
return result if result else TOOLS:1
def run_tool(name):
return DATA.get(name, {})
第 4 步:接入模型 API,限制它只能基于工具结果回答
这里的关键不是模型有多大,而是提示词要把边界写清楚。
python
def call_llm(query, selected_tools, tool_results):
base_url = os.getenv('LLM_BASE_URL')
api_key = os.getenv('LLM_API_KEY')
model = os.getenv('LLM_MODEL', 'gpt-5.5')
if not base_url or not api_key:
return '未配置模型 API,当前返回本地调试结果:建议先主推 88 元双人餐,强调蒜香口味稳定,并提醒晚高峰提前下单。'
messages = [
{
'role': 'system',
'content': '你是门店运营助手。只能依据给定工具结果回答;若工具结果不足,明确说明缺失信息,不要编造库存、规则和评价。'
},
{
'role': 'user',
'content': f'用户问题:{query}\n可用工具:{selected_tools}\n工具结果:{tool_results}'
}
]
payload = {
'model': model,
'messages': messages
}
headers = {
'Authorization': f'Bearer {api_key}'
}
resp = requests.post(base_url, json=payload, headers=headers, timeout=60)
data = resp.json()
return data.get('choices', [{}])[0].get('message', {}).get('content', data)第 5 步:暴露接口,跑通最小闭环
python
class ChatReq(BaseModel):
query: str
@app.post('/chat')
def chat(req: ChatReq):
selected = search_tools(req.query)
tool_results = {tool'name': run_tool(tool'name') for tool in selected}
answer = call_llm(req.query, selected, tool_results)
return {
'selected_tools': tool\['name' for tool in selected],
'tool_results': tool_results,
'answer': answer
}
启动:
bash
uvicorn app:app --reload
测试:
bash
http POST :8000/chat query='今晚销量下滑,帮我看看 88 元双人餐库存,并写一条社群文案'
如果一切正常,你会得到一个完整流程:
- 先匹配到 menu_query 和 promo_lookup
- 再读取库存与活动
- 最后生成文案和建议
这就比直接丢一句 帮我想想办法 更靠谱,因为它至少先查了业务事实。
四、把编码代理放对位置:它是副驾,不是方向盘
OpenAI News 提到 Braintrust 用 Codex 和 GPT-5.5 把客户请求转成代码、加快实验速度;Cognition 的 Scott Wu 又强调,编码代理不该替代人类。
这两条放在一起,特别像一个工程团队该有的现实主义:
让 AI 写代码可以,但别让它独占生产权限。
比如门店老板提出一个需求:
text
把最近 7 天差评里的 出餐慢、辣度不稳定、分量 三类问题做成日报,并输出 markdown 文件。
你可以把这段直接交给编码代理,让它生成脚本、补测试、给出运行说明;但最后必须有人做 3 件事:
- 看需求是否被正确理解
- 看代码是否越权访问数据
- 看输出是否真的能给门店决策带来帮助
别把 AI 当成实习生、架构师、测试同学和背锅侠四合一,那样通常会收获一个非常勤奋的事故制造器。
五、调试排错:最常见的坑,不在模型,在流程
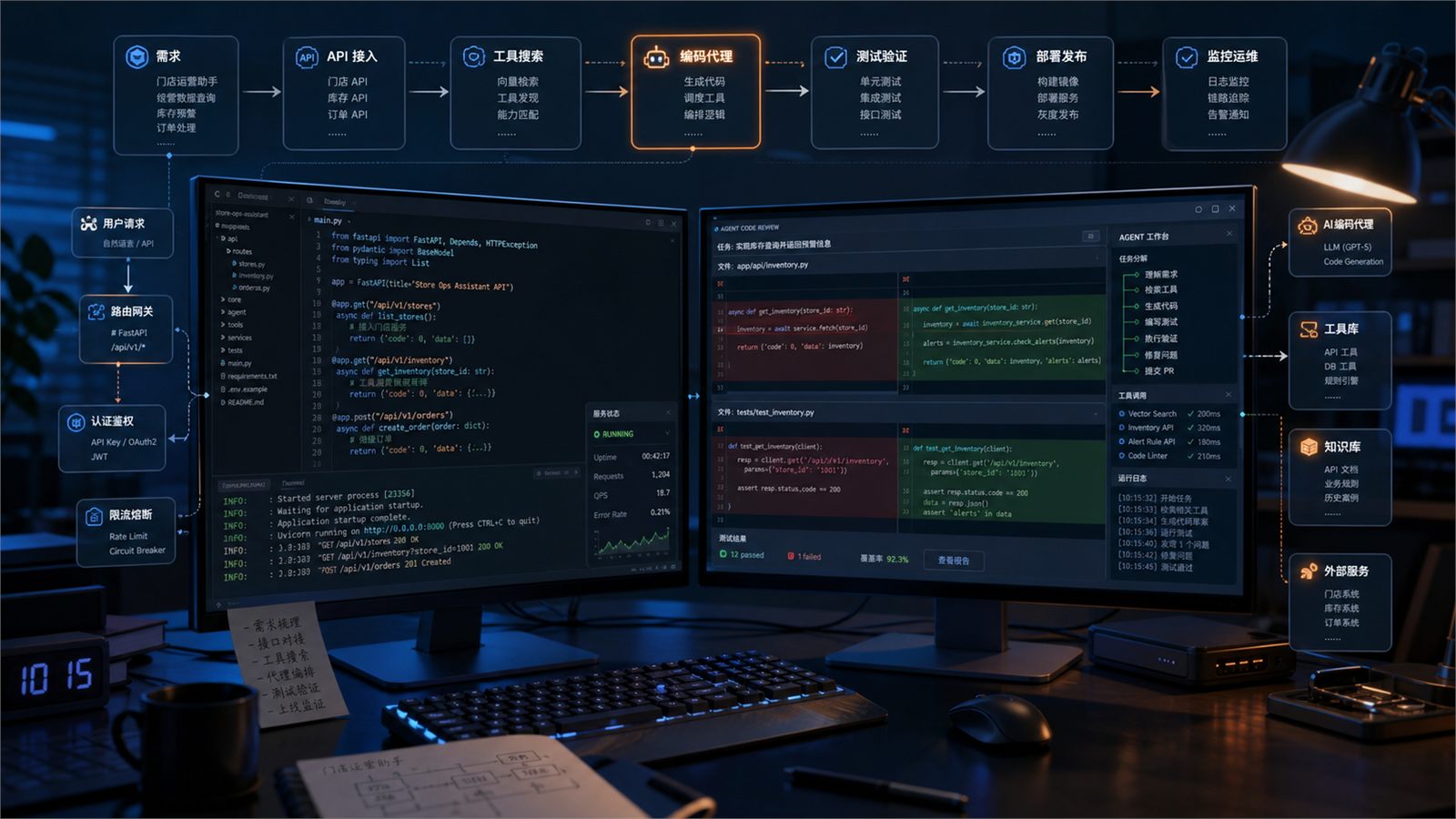
1. 工具太多,模型开始乱选
现象:一口气暴露所有工具,回答质量明显下降。
修复:先做 Tool Search,只给 top-k 工具。Hermes Agent 的新闻已经证明,这类思路对准确率有明显帮助。
2. 模型会编业务细节
现象:库存没查到,它也敢说 还剩很多。
修复:系统提示词里明确写只能依据工具结果回答;缺数据就老实说缺数据。
3. 你以为是 AI 不行,其实是你没把业务说清楚
TechCrunch 2026-05-29 那几篇报道最值得开发者警惕的一点就是:很多决策者高估 AI,往往是因为低估了具体岗位里的隐性知识。
比如小龙虾门店的 出餐慢,可能不是厨房问题,而是外卖高峰打包瓶颈;辣度不稳定,可能是后厨勺量没统一;这些东西不进工具数据,模型再聪明也只能靠猜。
4. 编码代理直接改线上
不建议。先生成脚本、测试、PR,再由人审。Scott Wu 的判断很实在:代理适合增强工程师,而不是越过工程师。
5. 只上线,不留 trace
AgentTrove 的价值不只是数据量大,而是提醒我们:agent 的优化离不开高质量交互轨迹。
最小做法就是把每次请求沉淀成结构化日志:
python
trace = {
'query': req.query,
'selected_tools': tool\['name' for tool in selected],
'tool_results': tool_results,
'final_answer': answer
}
后面无论你做评估、回放,还是整理成 ShareGPT 风格数据,都会轻松很多。
六、上线建议:先做读操作,再碰写操作

如果你准备把这个原型真的放进业务里,我建议按下面顺序走:
1. 先做只读场景
先让它查库存、查活动、总结评论、写文案。别一开始就让它自动改价、自动发券、自动下架套餐。
2. 给高风险动作加人工确认
发券、退款、批量回复、改促销规则,这些都应该保留人工按钮。
3. 做成本控制
- 先搜工具,减少无效上下文
- 常见问答做缓存
- 把日志分层保存,别每次都全量回放
4. 做合规和数据边界
- 不要把用户手机号、地址、支付信息原样发给模型
- 对门店经营数据做最小暴露
- 给工具调用留审计记录
- 结合平台规则和自身业务要求判断可上线范围
七、对开发者、技术运营和副业实践者的启发
对开发者
别再只卷提示词了。2026 年更值钱的是:工具编排、上下文控制、日志评估、人类审核机制。
对技术运营
你最重要的资产不是会不会写 prompt,而是能不能把门店、客服、销售、履约这些流程拆成可调用的工具节点。
对想做副业项目的人
比起做一个全能聊天壳子,更现实的路线是切一个垂直场景:餐饮、教育、招聘、门店管理、售后知识库。先把 3 到 5 个高频动作跑通,就比空喊 AI 赋能有用得多。
结尾总结
把这几条热点放在一起看,我的结论很明确:
- AI 编码代理会越来越能干,但短期内不该替代人
- Tool Search 这类机制会越来越重要,因为工具一多,上下文就会膨胀
- 真正的护城河,不是会不会接一个模型,而是你能不能把业务流程结构化、可调用、可审计、可复现
所以这篇实战的重点,其实不是教你做一个会聊天的助手,而是教你做一个先查事实、再给建议、最后由人兜底的系统。
这套思路,放在小龙虾门店能成立,换到别的实体行业,大概率也成立。