本文主要讨论事务。
什么是事务(Transaction)?
事务是一组SQL语句打包为一个整体,在该组SQL语句的执行中,要么全部成功,要么全部失败。该组SQL语句可以是一条,也可以是多条。
我们用一个转账的例子来理解:
假设有A和B两个人,A需要向B转账100元,那么就需要经过两个步骤:
- A账户 - 100
- B账户 + 100
如果第一步成功,但是第二步失败,那么A转出去的100元(数据)就直接消失了。所以,为了防止这种情况,当第二步失败的时候,就需要将之前执行的所有命令回滚,将数据还原。这就是事务的作用。
事务的四大特性(ACID特性)
事务具有四大特性:
1、原子性(Atomicity)
可以说是最基本的一个特性,一组SQL要么全部执行成功,要么全都不执行,不会出现执行到一半的情况。这种不可分割的特性就是原子性。
2、一致性(Consistency)
事务执行完成之后,要保证数据正确并且符合预期。(执行前后,数据库的完整性约束不变)
一致性可以说是通过原子性、隔离性和持久性来实现的。
3、隔离性(Isolation)
多个事务之间不能相互影响,事务之间不能互相干扰。
4、持久性(Durability)
事务一旦提交,数据就会永久保存;就算数据库损坏、断电等情况数据都不会丢失。
如何使用事务
不是所有的存储引擎都支持事务。在MySQL中,可以说只有InnoDB才支持事务。
如果想要查看存储引擎,可以在MySQL中使用如下代码:
sql
show engines;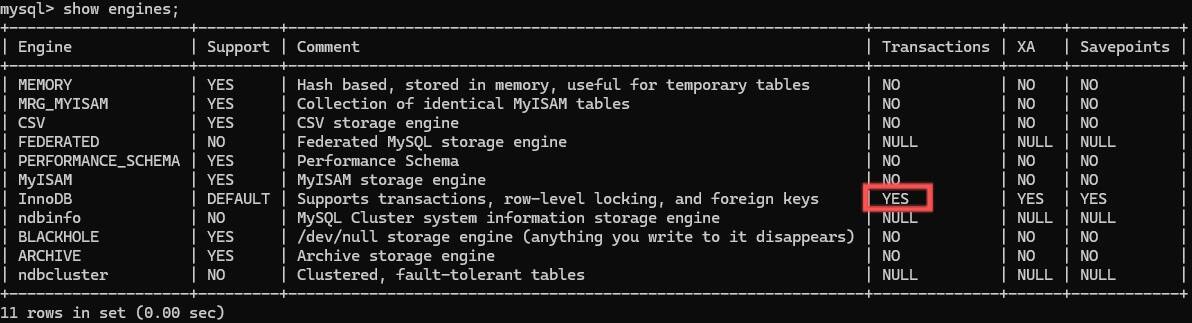
可以看到在这么多引擎中只有InnoDB支持。
使用语法
事务的使用标准语法如下:
sql
-- 1. 开启事务
-- 开始有两种语法,第一种是 START TRANSACTION
START TRANSACTION;
-- 第二种是直接BEGIN
BEGIN;
-- 书写时在两种语法中选择一种来开始事务
-- 2. 执行多条 SQL(增删改)
UPDATE ...;
INSERT ...;
DELETE ...;
-- 3. 提交事务(成功才执行)
COMMIT;
-- 4. 回滚事务(出错时执行)
ROLLBACK;如果事务全部执行成功,就输入 commit 提交数据保存起来;如果执行失败,就输入 rollback 回滚数据并关闭事务。
无论提交还是回滚,事务都会关闭。开启一个事务之后,所写的SQL语句就包含在这些事务当中,具有acid特性。
保存点
我们也可以手动设置保存点。就像玩游戏时的存档点一样,可以直接回滚读取到某一阶段的数据状态。
创建保存点的语法如下:
sql
SAVEPOINT 保存点名字;回到某个保存点:
sql
ROLLBACK TO 保存点名字;删除保存点:
sql
RELEASE SAVEPOINT 保存点名字;要注意的是,保存点不会自动生效。如果需要回滚到保存点,需要我们手动回滚。例如下面的例子:
sql
START TRANSACTION;
INSERT INTO t VALUES(1); -- 成功
SAVEPOINT sp1; -- 设置保存点
INSERT INTO t VALUES('abc'); -- 这里出错!(类型错误)语句执行失败的话,会自动回滚到最开始,不过也可以回滚到 sp1 的地方,上面的insert语句仍然有效。
来看一个完整例子:
sql
-- 1. 创建测试表(InnoDB引擎,支持事务)
CREATE TABLE test(
id INT PRIMARY KEY
) ENGINE=InnoDB;
-- 2. 开始事务
START TRANSACTION;
-- 插入第一条数据
INSERT INTO test VALUES(1);
-- 设置保存点 sp1
SAVEPOINT sp1;
-- 插入第二条数据
INSERT INTO test VALUES(2);
-- 设置保存点 sp2
SAVEPOINT sp2;
-- 插入第三条数据
INSERT INTO test VALUES(3);
-- 3. 回滚到保存点 sp2
ROLLBACK TO sp2;
-- 4. 提交事务
COMMIT;
-- 查询结果
SELECT * FROM test;执行后会直接回滚到保存点 sp2 ,第三条插入数据被回滚掉没有执行成功和保存。
事务自动提交
如果觉得每次都要手动commit太麻烦,我们还可以设置自动提交。
sql
-- 关闭自动提交
SET autocommit = 0;
SET autocommit = OFF;
-- 开启自动提交
SET autocommit = 1;
SET autocommit = ON;当开启自动提交后,每条SQL单独一个事务,执行完就自动提交。
关闭自动提交之后,后面的语句只能手动提交。
【注意】自动提交只会对开启后的语句生效;在开启自动提交之前的语句如果没有手动提交是无法保存的!
已经提交的语句,如果没有设置保存点是无法回滚的。
事务的隔离性和隔离级别
上面我们提到,事务的隔离性为:多个事务之间不能互相干扰,彼此是相互隔离的。
在实际事务操作中,多个事务之间可能会存在以下的并发问题:
脏读: 一个事务读到了另一个事务还没提交的数据。如果对方回滚,那么读到的就是假数据。
**不可重复读 :**一个事务内两次查询的结果不一样,因为中间被别的事务修改并提交了。
**幻读:**一个事务内,两次查询行数不一样,因为别的事务插入 / 删除了数据。
为了减轻这些情况,给事务设置了四个隔离级别,安全性从低到高,性能从高到低:
-
读未提交D(READ UNCOMMITTE)
可能出现:脏读、不可重复读、幻读
但是性能最好 -
读已提交(READ COMMITTED)
能避免:脏读
可能出现:不可重复读、幻读
是Oracle、SQL Server 默认的隔离级别 -
可重复读(REPEATABLE READ)
能避免:脏读、不可重复读
可能出现:幻读(MySQL InnoDB 靠间隙锁基本解决) -
串行化(SERIALIZABLE)
全部问题都能解决
但性能最差,像排队执行
查看当前的隔离级别
要查看当前的隔离级别,可以使用下面的代码:
sql
SELECT @@transaction_isolation;如果要设置事务的级别,代码如下:
sql
-- 读未提交
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
-- 读已提交
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- 可重复读
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- 串行化
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;使用场景
四种隔离级别有各自的优缺点,它们的适用场景大多可以总结如下:
|------------------------|--------------------------------------------------------------|
| 隔离级别 | 场景 |
| READ UNCOMMITTED(读未提交) | 性能最高,但最不安全,允许脏读,。因此基本不会使用 |
| READ COMMITTED(读已提交) | 解决脏读,但允许不可重复读,性能好,并发高,因此在大多数互联网在线业务会使用。例如订单系统,用户中心或支付相关等 |
| REPEATABLE READ(可重复读) | 解决脏读、不可重复读,适合对数据一致性要求稍高 的场景。例如需要统计、对账、报表的场景 |
| SERIALIZABLE(串行化) | 完全串行执行,最安全,但是性能最差。所以在日常开发几乎不用,因为过于缓慢。 |