02 seq2seq
注意力机制由来,机器翻译
seq2seq架构,1encoder,2decoder,3中间语义张量c
翻译:欢迎来北京,welcome to Beijing
任务:1.编码,结果得到中间语义张量c
中文==通过GRU获得每个时间步的输出张量,最后将他们拼接成一个中间语义张量c(output就是拼接后的c,因为如果是hn的话,那么只包含有最后一个语义)既然如果讲义这么解释,最好还是解释为output。
解码:(GO/BOS,begin of sentence)和中间语义张量c,一起输入到解码器,
中间语义张量c和s0输入得到一个输出(h1和s1,welcome,两个相等)
但是与此同时s1+中间语义张量c+a1(这里a1可以理解包含有h1信息)
03 注意力机制的介绍
问题1,如果句子长/复杂,计算量大,并且模型准确率下降严重。
问题2,翻译时候,可能在不同语境下,同一个词具有不同的含义,但是网络读这些词没有区分度,没有考虑词与词之间的相关性,导致翻译效果差。
注意力机制实际上就是将人的感知方式,注意力行为应用在机器上,让机器学会感知数据中重要和不重要的方式。
③注意力机制的分类以及如何实现
对于模型的每一个输入项,可能是图片中的不同部分,or语句中的某个单词,分配一个权重,这个权重大小代表我们希望模型对该部分一个关注的程度。
这样一来,通过权重大小模拟人在处理信息的注意力侧重,有效提高模型的性能,并且在一定程度上降低计算量
分类:软注意(全局注意);硬注意(局部注意);自注意(内注意)
1.软注意soft/global attention,每个输入分配0-1权重,也即是某些部分关注多一点,某些部分关注少一点。
因为对所有信息都有考虑,但是考虑程度不一而已,所以相对来讲计算量大。
2.硬注意力hard/local attention,分配权重非0即1,要么关注,要么不关注。舍弃一些相关的项可以减少一些计算成本,但也可能丢失一些本应该注意的信息。【了解即可】
3.自注意力self attention,对每个输入分配的权重取决于输入项之间的相互作用,即通过内部表决应该关注哪些输入项,
和前两种相比,处理很长的输入时,具有并行计算的优势。
04 不带att的Encoder2Decoder
注意:注意力机制是一个通用的思想技术,不依赖于模型。接下来以E2D架构做解析。
抽象结构:输入x1-x4,encoder,得到语义编码c,输入到decoder,得到y1-y4
解释:输入句子对Source=<X1,⋯ ,Xm>Source=<X_1, \cdots, X_m>Source=<X1,⋯,Xm>
生成目标句子Target=<y1,⋯ ,yn>Target=<y_1, \cdots, y_n>Target=<y1,⋯,yn>
encoder就是对输入句子进行编码,将输入句子非线性变化转化为中间语义C=F(X1,⋯ ,Xm)C=F(X_1, \cdots, X_m)C=F(X1,⋯,Xm)
decoder根据中间语义C和之前生成的历史信息y1,⋯ ,yi−1y_1,\cdots, y_{i-1}y1,⋯,yi−1,生成yiy_iyi信息。yi=G(C,y1,⋯ ,yi−1)y_i=G(C, y_1, \cdots, y_{i-1})yi=G(C,y1,⋯,yi−1)
05 带att的Encoder2Decoder
举例说明为何加att,
比如source="Tom chase Jerry.",输出的target为"汤姆追逐杰瑞"。
-在普通E2D结构中,source里每个单词对翻译目标单词的"杰瑞"贡献相同,很明显这里不合适,显然Jerry对于翻译成"杰瑞"更重要。
-如果引入att,在生成"杰瑞"的时候,应该体现出英文单词对于翻译当前中文单词不同的影响程度。比如给出一个例子概率分布值,(Tom 0.3)(chase 0.2)(Jerry 0.5)每个单词对翻译成杰瑞时,注意力分配给出不同英文单词的注意力大小
结构:
输入(x1--x4),但是经过encoder后,会产生中间语义张量(c1-c3),最后经过decoder得到(y1-y3)
大致y1=f1(C1);y2=f1(C2,y1);y3=f1(C3,y1,y2)y_1=f1(C_1);y_2=f1(C_2,y_1);y_3=f1(C_3,y_1,y_2)y1=f1(C1);y2=f1(C2,y1);y3=f1(C3,y1,y2)
对应每个C可能对应着不同的语句单词注意力分配权重,可能为
CTom=g(0.6∗f2(Tom),0.2∗f2(chase),0.2∗f2(Jerry))C_{Tom}=g( 0.6*f2(Tom), 0.2*f2(chase), 0.2*f2(Jerry) )CTom=g(0.6∗f2(Tom),0.2∗f2(chase),0.2∗f2(Jerry))
Cchase=g(0.2∗f2(Tom),0.7∗f2(chase),0.1∗f2(Jerry))C_{chase}=g( 0.2*f2(Tom), 0.7*f2(chase), 0.1*f2(Jerry) )Cchase=g(0.2∗f2(Tom),0.7∗f2(chase),0.1∗f2(Jerry))
CJerry=g(0.3∗f2(Tom),0.2∗f2(chase),0.5∗f2(Jerry))C_{Jerry}=g( 0.3*f2(Tom), 0.2*f2(chase), 0.5*f2(Jerry) )CJerry=g(0.3∗f2(Tom),0.2∗f2(chase),0.5∗f2(Jerry))
C最简单就是加权和而已。
06 注意力概率分布的计算方式
如何得到注意力概率分布
07 soft-att的讲解
att机制可以看作,target每个单词是对source每个单词的加权求和,而权重是source中每个单词对target中每个单词的重要程度。
att计算3步
1.Q和K进行相似度计算,得到att-score
2.对att-score进行softmax归一化,得到权重矩阵
3.权重矩阵与V进行加权求和
V可以理解为看到的原始信息,实际的tom
K就是单词经过encoder之后的key(如tom,经过encoder后有一个key)
Q,就是我要进行翻译了,然后找对应哪个词和我的相似度最高。
没问题,那咱们就顺着刚才"找书"的思路,把这个"匹配"和"拿书"的过程用数学公式具体算一下。
为了让你看得更清楚,我们假设向量简化为 1个数字(实际中可能是512个数字),并且只做一次计算。
🧮 场景:正在翻译"杰瑞"
当前状态:
- Decoder 正在生成"杰瑞",发出的 Query (QQQ) 是数字 2.0(代表"寻找人名"的特征)。
- Encoder 已经处理好了输入句子,提供了以下数据:
1. 准备数据 (Key 和 Value)
Encoder 为每个单词生成了 Key (KKK) 和 Value (VVV):
| 单词 | Key (KKK) (特征标签) | Value (VVV) (实际内容) | 含义 |
|---|---|---|---|
| Tom | 1.0 | 10 | 标签像人名,内容是Tom |
| chase | 0.1 | 20 | 标签像动词,内容是chase |
| Jerry | 2.0 | 30 | 标签像人名,内容是Jerry |
注意:你会发现 Jerry 的 Key (2.0) 和我们的 Query (2.0) 很像,这意味着它们很匹配。
📝 第一步:计算相似度得分
公式 :Score=Q×K \text{Score} = Q \times K Score=Q×K
(拿着你的需求 Q,去和每个单词的标签 K 做乘法)
- 对 Tom :2.0×1.0=2.02.0 \times 1.0 = \mathbf{2.0}2.0×1.0=2.0
- 对 chase :2.0×0.1=0.22.0 \times 0.1 = \mathbf{0.2}2.0×0.1=0.2
- 对 Jerry :2.0×2.0=4.02.0 \times 2.0 = \mathbf{4.0}2.0×2.0=4.0
结果:Jerry 的得分 (4.0) 最高,说明它最相关。
📊 第二步:计算概率分布
公式 :α=Softmax(Score) \alpha = \text{Softmax}(\text{Score}) α=Softmax(Score)
(把得分变成百分比,让模型知道该"看"谁)
- 计算指数 (简单理解):得分越高,指数越大。
- Tom: e2.0≈7.4e^{2.0} \approx 7.4e2.0≈7.4
- chase: e0.2≈1.2e^{0.2} \approx 1.2e0.2≈1.2
- Jerry: e4.0≈54.6e^{4.0} \approx 54.6e4.0≈54.6
- 归一化 (算占比):
- 总和 ≈7.4+1.2+54.6=63.2\approx 7.4 + 1.2 + 54.6 = 63.2≈7.4+1.2+54.6=63.2
- Tom 的权重 :7.4÷63.2≈0.127.4 \div 63.2 \approx \mathbf{0.12}7.4÷63.2≈0.12 (12%)
- chase 的权重 :1.2÷63.2≈0.021.2 \div 63.2 \approx \mathbf{0.02}1.2÷63.2≈0.02 (2%)
- Jerry 的权重 :54.6÷63.2≈0.8654.6 \div 63.2 \approx \mathbf{0.86}54.6÷63.2≈0.86 (86%)
结果 :模型决定 86% 的注意力给 Jerry,12% 给 Tom,忽略 chase。
🎁 第三步:加权求和
公式 :C=∑(权重×Value) C = \sum (\text{权重} \times \text{Value}) C=∑(权重×Value)
(根据注意力的多少,提取对应的内容 Value)
我们要把每个单词的 Value 乘以它的 权重,然后加起来:
C=(0.12×10)+(0.02×20)+(0.86×30) C = (0.12 \times 10) + (0.02 \times 20) + (0.86 \times 30) C=(0.12×10)+(0.02×20)+(0.86×30)
计算一下:
- Tom 贡献:1.21.21.2
- chase 贡献:0.40.40.4
- Jerry 贡献:25.825.825.8
C=1.2+0.4+25.8=27.4 C = 1.2 + 0.4 + 25.8 = \mathbf{27.4} C=1.2+0.4+25.8=27.4
🏁 最终结果
- 上下文向量 CCC 是 27.4。
- 这个数字非常接近 Jerry 的原始内容 (30),但也混合了一点点 Tom 的信息。
- Decoder 拿到这个 27.4 ,就会非常有把握地输出中文单词:"杰瑞"。
08 hard-att和self-att的讲解
硬注意力,直接删除不相关的。强化学习用,《白话强化学习》
self-att,谷歌2017transformer,上述att是发生于source和target之间的,而self-att发生于source内部之间,target内部之间的。
the law will never be prefer, but its application should be just, this is what we are missing, in my opinion.
第二分句的its就是指law,law和每个单词之间计算,its和law
其他计算得到的是语法信息。
🎯 硬注意力 (Hard Attention)
你的理解"直接删除不相关的"非常形象,这在学术上被称为**"离散化选择"**。
- 核心思想 :它是一种**"非此即彼"**的机制。
- 软注意力(之前学的) :是给所有词分配权重,比如
(Tom: 0.12, chase: 0.02, Jerry: 0.86),虽然 Jerry 最高,但 Tom 的信息也没完全丢。 - 硬注意力 :是直接**"拍板"。模型决定只看 Jerry,那么 Tom 和 chase 的信息就被彻底切断**(权重为0)。
- 软注意力(之前学的) :是给所有词分配权重,比如
- 为什么要用强化学习?
- 不可导的问题 :普通的神经网络靠"反向传播"来修正误差(比如:预测偏了一点点,往回改一点点)。但是"做选择"这个动作(比如:从三个词里挑 一个)是不可导的。你不能说"我往'选Tom'这个方向偏一点点",因为要么选,要么不选。
- 解决方案 :因为没法直接通过梯度下降来训练,所以我们需要用强化学习。把模型看作一个"智能体",它做出的"选择"是"动作",最后翻译得准不准是"奖励"。通过不断的试错(猜错了受惩罚,猜对了得奖励),让模型学会如何"硬"选择。
🤝 自注意力 (Self-Attention)
你抓住了自注意力的精髓------"内部关联"。它是 Google 在 2017 年 Transformer 论文中提出的核心概念。
-
核心区别:
- 普通注意力 (Cross-Attention) :发生在 Source 和 Target 之间(比如:拿着中文"杰瑞"去英文里找"Jerry")。
- 自注意力 (Self-Attention) :发生在 序列内部 。
- Encoder 自注意力:让英文句子里的每个词,都去看看句子里的其他词,以此搞懂句意。
- Decoder 自注意力:让中文句子里的每个词,看看前面生成的词,保证语法通顺。
-
深度解析你的例子:
"The law will never be perfect, but its application should be just..."
当模型读到 its 这个词时,它本身是模糊的(它指谁?)。
通过 Self-Attention 机制:
- its 变成 Query(提问者):发出信号"我是代词,我在找我的主人"。
- 句子里的
The,law,will,never... 变成 Key(回答者)。 - 计算匹配度 :
its的 Query 和law的 Key 匹配度最高(因为词性、单复数、语境都吻合)。 - 获取信息 :模型把
law的 Value(实际含义)提取出来,融合到its身上。
结果 :模型瞬间明白了,这里的
its不是指application,也不是指perfect,而是指 law。这就是你提到的"计算得到语法/指代信息"的过程。
===
下午课程
===
09 seq2seq架构加入att计算过程解释
①.注意力机制规则
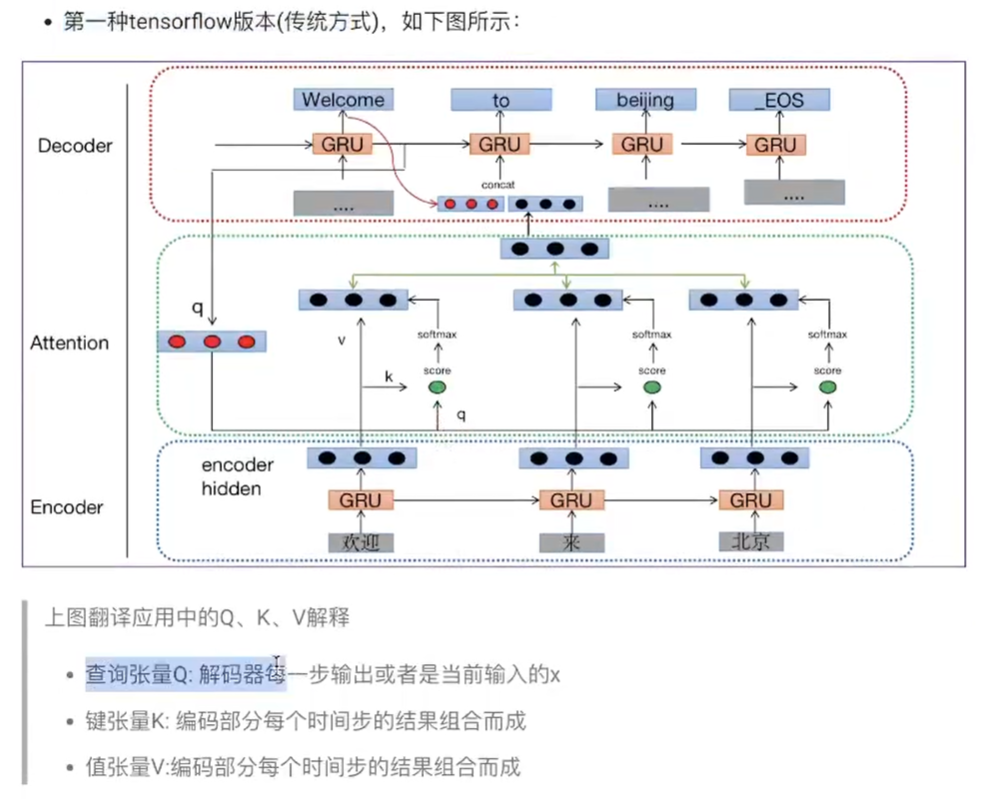
欢迎来北京==》"Welcome to Beijing"
1.分词:"欢迎","来","北京",假设编码每个词用3维向量表示。那么每个词就是13矩阵
2.q(也是13矩阵),比如我现在要对"欢迎"进行翻译,k组合起来就是3*3
q k=13,归一化不改变结构13,
最后翻译得到的和上一个翻译的词进行拼接(13)(13)
🧩 1. 初始状态:输入矩阵
假设句子是"欢迎 来 北京",分词后得到 3 个词。
每个词用 3维向量 表示。
那么,整个句子的输入矩阵 XXX 就是一个 3行3列 的矩阵(3个词,每个词3维):
X=x欢迎x来x北京=0.10.20.30.40.50.60.70.80.9 X = \begin{bmatrix} x_{欢迎} \\ x_{来} \\ x_{北京} \end{bmatrix} = \begin{bmatrix} 0.1 & 0.2 & 0.3 \\ 0.4 & 0.5 & 0.6 \\ 0.7 & 0.8 & 0.9 \end{bmatrix} X= x欢迎x来x北京 = 0.10.40.70.20.50.80.30.60.9
(注:这里只是假设的数值)
⚙️ 2. 生成 Q 和 K:维度的秘密变换
这里是关键点。如果 QQQ 和 KKK 保持是 1×31 \times 31×3,它们是无法算出有意义的"注意力分数"的。我们需要通过**线性变换(乘以权重矩阵 WWW)**来改变它们的维度。
通常在 Transformer 中,我们会把维度映射到一个新的空间(假设我们也设为 3 维,方便计算)。
-
Query (QQQ) :
假设我们现在是 Decoder,正在尝试翻译第一个词"Welcome"。
Decoder 会生成一个 Query 向量 qqq(代表"我想找表示'欢迎'含义的词")。
这个 qqq 是通过输入乘以权重矩阵 WQW^QWQ 得到的。
- 维度变化 :(1×3)×(3×3)→1×3(1 \times 3) \times (3 \times 3) \rightarrow \mathbf{1 \times 3}(1×3)×(3×3)→1×3。
- 所以,qqq 是一个 行向量。
-
Key (KKK) :
Encoder 会把输入句子 XXX 转换成 Keys。
- 维度变化 :(3×3)×(3×3)→3×3(3 \times 3) \times (3 \times 3) \rightarrow \mathbf{3 \times 3}(3×3)×(3×3)→3×3。
- 这里 KKK 矩阵的每一行,代表"欢迎"、"来"、"北京"各自的 Key。
🧮 3. 计算注意力分数:矩阵乘法
现在我们要计算 QQQ 和 KKK 的相似度。
- 你的公式 :Q×KQ \times KQ×K
- 维度检查 :(1×3)×(3×3)(1 \times 3) \times (3 \times 3)(1×3)×(3×3)
- 结果维度 :1×31 \times 31×3
这就对了!
计算结果是一个 1×31 \times 31×3 的向量 (我们叫它 Scores)。
这个向量里的 3 个数字,分别代表:
- "Welcome" 和 "欢迎" 的匹配度
- "Welcome" 和 "来" 的匹配度
- "Welcome" 和 "北京" 的匹配度
📊 4. 归一化与加权求和
-
Softmax :
对这个 1×31 \times 31×3 的
Scores向量做 Softmax。结构不变,还是 1×31 \times 31×3,但数值变成了概率(比如
[0.8, 0.1, 0.1])。这意味着模型觉得 80% 应该关注"欢迎"。 -
乘以 Value (VVV) :
我们需要把概率乘到 Value 上。VVV 的维度和 KKK 一样,也是 3×33 \times 33×3(3个词,每个词3维)。
Attention Output=Weights(1×3)×V(3×3) \text{Attention Output} = \text{Weights}{(1 \times 3)} \times V{(3 \times 3)} Attention Output=Weights(1×3)×V(3×3)
结果维度 :1×31 \times 31×3。这个结果就是一个上下文向量 ccc。它融合了"欢迎"、"来"、"北京"的信息,但重点突出了"欢迎"。
🔗 5. 关于"拼接"
你最后提到:"和上一个翻译的词进行拼接"。
这里要注意,Transformer 和 RNN 的处理方式不同:
- 如果是 RNN :确实是把生成的词向量(1×31 \times 31×3)作为下一个时间步的输入。
- 如果是 Transformer :
它通常不是 简单地把词向量拼起来。
而是把刚才算出来的 Attention Output (1×31 \times 31×3) 传入前馈神经网络(Feed Forward Network),经过变换和激活,最后通过 Linear + Softmax 预测出下一个单词(比如 "Welcome")。
总结一下你的计算流:
- 输入 :1×31 \times 31×3 (q) 和 3×33 \times 33×3 (K, V)
- 乘法 :q×KT→1×3q \times K^T \rightarrow 1 \times 3q×KT→1×3 (分数)
- 归一化 :Softmax →1×3\rightarrow 1 \times 3→1×3 (权重)
- 输出 :权重 ×V→1×3\times V \rightarrow 1 \times 3×V→1×3 (上下文向量)
10 pytorch版本att计算过程
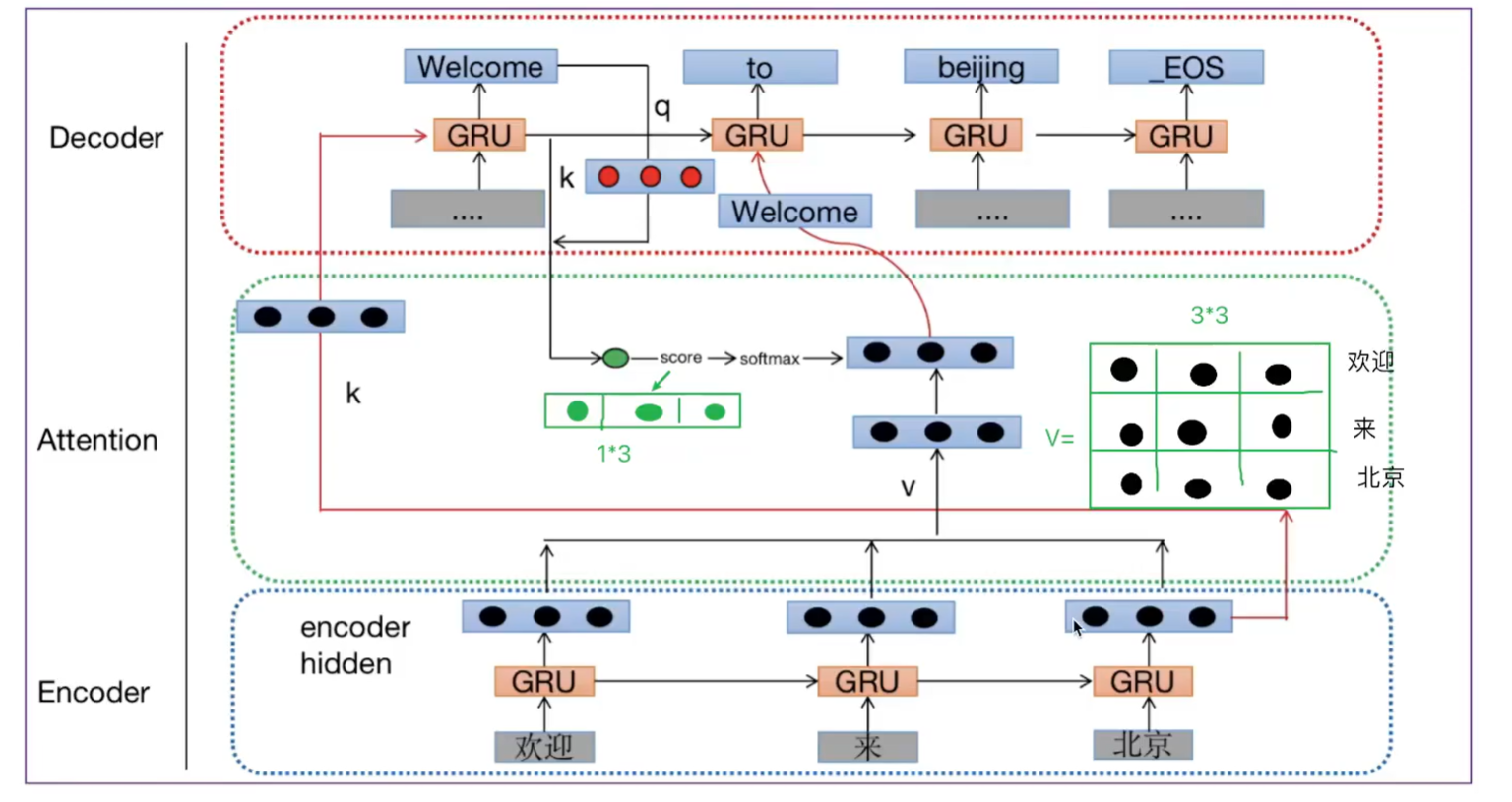
没问题!其实你的逻辑完全没问题,咱们只需要把最后那个"拼接"的环节调整一下,换成 PyTorch 里标准的处理流程就行。
在 PyTorch 的 Transformer 架构里,算出上下文向量后,通常不是直接拿去拼接,而是经过一个前馈网络处理,最后通过线性层输出。
下面我直接把你的例子"翻译"成 PyTorch 的代码逻辑:
📐 1. 准备数据与维度定义
首先,我们要把"欢迎 来 北京"变成 PyTorch 能认出的张量。
python
import torch
import torch.nn as nn
import torch.nn.functional as F
# 假设参数
batch_size = 1 # 一次处理一句话
seq_len = 3 # 3个词:欢迎,来,北京
d_model = 3 # 每个词向量维度是3
# 1. 模拟输入数据 (Encoder的输出)
# 形状: [3, 3] -> PyTorch通常习惯 [Seq_Len, Batch, Dim] 或者 [Batch, Seq_Len, Dim]
# 这里为了方便理解矩阵乘法,我们使用 [Batch, Seq_Len, Dim]
x = torch.tensor([
[[0.1, 0.2, 0.3], # "欢迎"
[0.4, 0.5, 0.6], # "来"
[0.7, 0.8, 0.9]] # "北京"
], dtype=torch.float32) # 形状: [1, 3, 3]⚙️ 2. 线性变换 (生成 Q, K, V)
在 PyTorch 中,我们通常使用 nn.Linear 来完成你提到的"乘以权重矩阵"这一步。
python
# 定义线性层 (模拟权重矩阵 Wq, Wk, Wv)
# 输入维度3,输出维度3 (为了演示方便,实际中可能会变)
linear_q = nn.Linear(3, 3)
linear_k = nn.Linear(3, 3)
linear_v = nn.Linear(3, 3)
# 假设 Decoder 当前的状态 (Query)
# 比如我们刚开始翻译,输入了一个 <BOS> 标记,或者是一个全零向量作为初始查询
q_input = torch.randn(1, 1, 3)
# 计算 Q, K, V
q = linear_q(q_input) # 形状: [1, 1, 3] (Batch, Query_Len, Dim)
k = linear_k(x) # 形状: [1, 3, 3] (Batch, Source_Len, Dim)
v = linear_v(x) # 形状: [1, 3, 3]🧮 3. 计算注意力分数 (矩阵乘法)
这里对应你提到的 q k = 1*3。在 PyTorch 中,我们需要转置 K 才能进行矩阵乘法。
python
# 矩阵乘法: Q * K^T
# q: [1, 1, 3]
# k.transpose(-2, -1): [1, 3, 3] -> 转置后变成 [1, 3, 3] (最后两维互换)
# 结果 scores: [1, 1, 3] -> 代表 Q 对 Source 中 3 个词的打分
scores = torch.matmul(q, k.transpose(-2, -1))
# 缩放 (Scaling) - PyTorch 标准操作,防止数值过大
# 除以根号下维度 (sqrt(3))
scores = scores / torch.sqrt(torch.tensor(3.0))📊 4. 归一化与加权求和
对应你提到的"归一化不改变结构"和"最后翻译得到的..."。
python
# 1. Softmax 归一化 (得到概率分布)
# dim=-1 表示在最后一个维度上进行归一化 (即对那3个分数求和变1)
attention_weights = F.softmax(scores, dim=-1)
# 形状: [1, 1, 3] -> 比如 [0.8, 0.1, 0.1]
# 2. 加权求和 (Context Vector)
# 权重 * V
# [1, 1, 3] * [1, 3, 3] -> 结果形状 [1, 1, 3]
context_vector = torch.matmul(attention_weights, v)🔗 5. PyTorch 的后续处理 (替代"拼接")
你提到的"和上一个翻译的词拼接",在 Transformer 的 PyTorch 实现中,通常是把这个 context_vector 送入一个前馈网络,然后输出预测结果。
python
# 1. 前馈网络 (Feed Forward) - 这是一个简单的全连接层
# 这里模拟一下,实际 Transformer 里会有两层线性变换加激活函数
ffn = nn.Linear(3, 3)
# 2. 输出处理
output = ffn(context_vector) # 形状: [1, 1, 3]
# 3. 预测下一个词
# 最后通常会接一个 Linear(d_model, vocab_size) 然后做 Softmax 来预测单词
# 比如输出 [0.1, 0.9, 0.0],对应词表里的 "Welcome"在写论文的"注意力机制"这一小节时,核心原则是:用数学语言描述逻辑,而不是用代码描述逻辑。
审稿人想看到的是清晰的公式推导和直观的机制解释,而不是你代码里的 Linear 或 MatMul 函数调用。
结合你之前对 Q、K、V 的理解,我为你整理了一个标准的论文写作模板(适用于大多数深度学习论文),你可以直接参考这个结构来填充内容。
📝 论文写作模板:注意力机制小节
通常这一节会放在"方法"章节的子节,比如 3.2 多头自注意力机制。
1. 文字描述:定性与直觉
首先用一两句话概括你为什么要用这个机制,以及它的作用。
写作示例:
"为了捕捉输入序列中的长距离依赖关系并动态提取关键特征,我们采用了缩放点积注意力机制。该机制允许模型在处理序列中的每个位置时,能够根据内容的相关性,自适应地关注输入的不同部分。"
2. 数学公式:核心定义
这是最关键的部分。你需要把 Q、K、V 的计算过程形式化。不要写代码逻辑,要写矩阵运算。
第一步:定义输入与变换
假设输入序列为 X∈Rn×dmodelX \in \mathbb{R}^{n \times d_{model}}X∈Rn×dmodel(这里 nnn 是序列长度,dmodeld_{model}dmodel 是维度,对应你例子中的 3)。
公式表达:
我们首先通过三个可学习的线性变换矩阵 WQ,WK,WVW^Q, W^K, W^VWQ,WK,WV,将输入 XXX 映射为查询 QQQ、键 KKK 和值 VVV:
Q=XWQ,K=XWK,V=XWV Q = XW^Q, \quad K = XW^K, \quad V = XW^V Q=XWQ,K=XWK,V=XWV其中 WQ,WK∈Rdmodel×dkW^Q, W^K \in \mathbb{R}^{d_{model} \times d_k}WQ,WK∈Rdmodel×dk,WV∈Rdmodel×dvW^V \in \mathbb{R}^{d_{model} \times d_v}WV∈Rdmodel×dv。
第二步:定义注意力函数
直接给出那个著名的公式。
公式表达:
注意力分数的计算通过查询 QQQ 与键 KKK 的点积实现,随后通过 Softmax 函数归一化得到权重,最后对值 VVV 进行加权求和。具体计算公式如下:
Attention(Q,K,V)=softmax(QKTdk)V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V其中,除以 dk\sqrt{d_k}dk 是为了防止点积结果过大导致 Softmax 函数进入梯度极小的饱和区,从而阻碍反向传播。
3. 机制解释:结合你的例子
在公式之后,最好用一段文字解释这个公式在你的任务(比如机器翻译)中具体意味着什么。这里就可以把你理解的"Tom chase Jerry"融合进去。
写作示例:
"具体而言,在翻译任务中,解码器生成的查询向量 QQQ 代表当前目标词(如'杰瑞')的语义需求。该向量与源句子中每个词的键向量 KKK(如'Tom', 'chase', 'Jerry')进行相似度计算。
计算得到的注意力权重矩阵反映了源词对当前目标词的重要性分布。例如,当模型预测'杰瑞'时,对应'Jerry'的键向量将获得最高的注意力权重,从而使模型能够从对应的值向量 VVV 中精准提取相关信息,忽略无关词汇的干扰。"
4. 进阶:如果是多头注意力
如果你的模型用了 Multi-Head,需要简单补充一句:
写作示例:
"为了从不同的表示子空间中捕捉多样化的语义信息,我们采用了多头注意力机制。我们将 Q,K,VQ, K, VQ,K,V 投影到 hhh 个不同的子空间并行计算注意力,最后将结果拼接并通过线性层输出:
MultiHead(Q,K,V)=Concat(head1,...,headh)WO \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO其中 headi=Attention(QWiQ,KWiK,VWiV)\text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)headi=Attention(QWiQ,KWiK,VWiV)。"