引言:打开编译器的"黑盒"
上一篇我们知道了编译器是一个"翻译器"------输入源程序,输出目标程序。但这个翻译过程内部到底发生了什么?
如果打开编译器这个"黑盒",我们会看到两大部分:
- 分析 (Analysis) --- 也叫前端 (Front End):拆解源程序,理解它的结构和含义
- 综合 (Synthesis) --- 也叫后端 (Back End):根据理解的结果,构造出目标程序
进一步细化,编译过程由 六个阶段 (phases) 组成,外加一个贯穿始终的符号表 (Symbol Table)。本文将用龙书中最经典的例子------一行赋值语句------带你走完编译的全过程。
一、编译器的整体结构
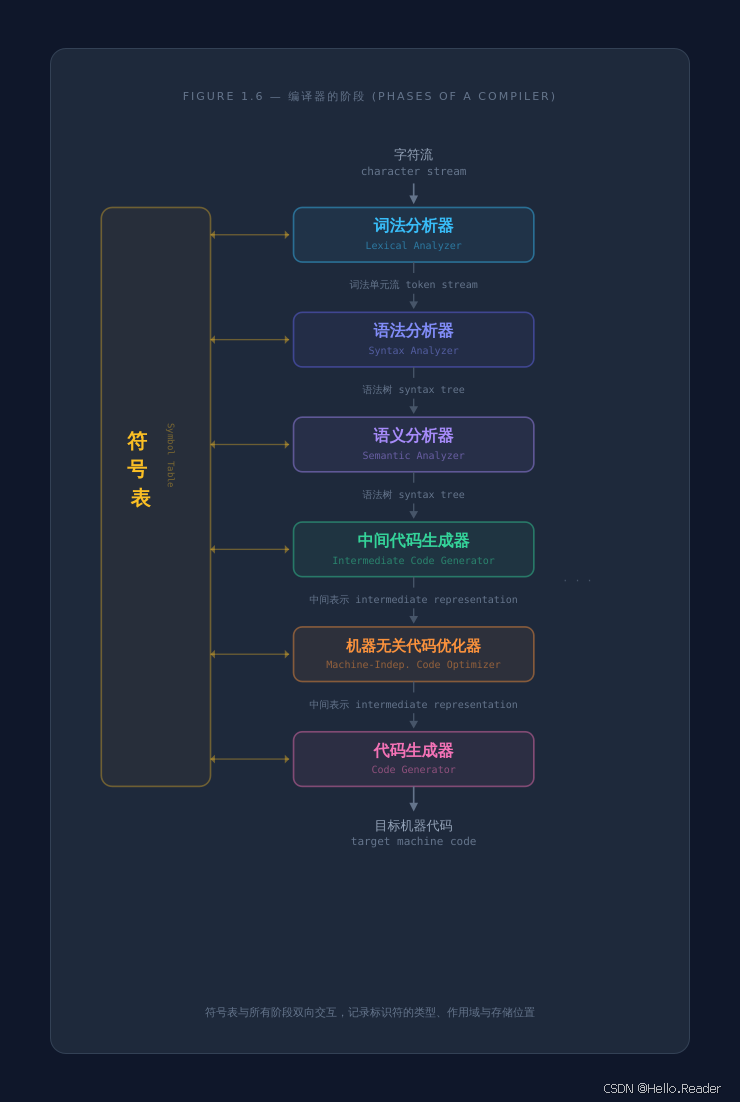
前三个阶段属于前端 (分析),后三个阶段属于后端(综合),符号表管理贯穿整个过程。
二、经典例子:编译一行赋值语句
我们用龙书中贯穿全章的经典例子来走完每个阶段:
c
position = initial + rate * 60这是一条简单的赋值语句。假设 position、initial 和 rate 都是已声明的浮点型变量,60 是一个整数常量。
阶段一:词法分析 (Lexical Analysis / Scanning)
任务 :将字符流分解为有意义的词素 (lexeme) ,并为每个词素生成一个词法单元 (token)。
输入 :字符流 p o s i t i o n = i n i t i a l + r a t e * 6 0
处理过程:词法分析器逐字符扫描,识别出以下词素:
| 序号 | 词素 (Lexeme) | 词法单元 (Token) | 说明 |
|---|---|---|---|
| 1 | position |
<id, 1> |
标识符,指向符号表第1项 |
| 2 | = |
<=> |
赋值运算符 |
| 3 | initial |
<id, 2> |
标识符,指向符号表第2项 |
| 4 | + |
<+> |
加法运算符 |
| 5 | rate |
<id, 3> |
标识符,指向符号表第3项 |
| 6 | * |
<*> |
乘法运算符 |
| 7 | 60 |
<60> |
整数常量 |
输出:词法单元流
<id,1> <=> <id,2> <+> <id,3> <*> <60>关键点:
- 空格被丢弃(它们只是分隔符,不携带语义信息)
- 每个标识符只存储一次到符号表中,token 通过指针引用
- token 的第一个分量(如
id、=、+)是抽象符号,用于后续语法分析 - token 的第二个分量(如
1、2、3)是属性值,指向符号表条目
符号表状态:
| 条目 | 变量名 | 类型 | ...其他属性 |
|---|---|---|---|
| 1 | position | float | ... |
| 2 | initial | float | ... |
| 3 | rate | float | ... |
阶段二:语法分析 (Syntax Analysis / Parsing)
任务 :根据 token 流构造一棵语法树 (syntax tree),描述程序的语法结构。
输入 :<id,1> <=> <id,2> <+> <id,3> <*> <60>
处理过程:语法分析器根据语言的文法规则,构造出如下语法树:
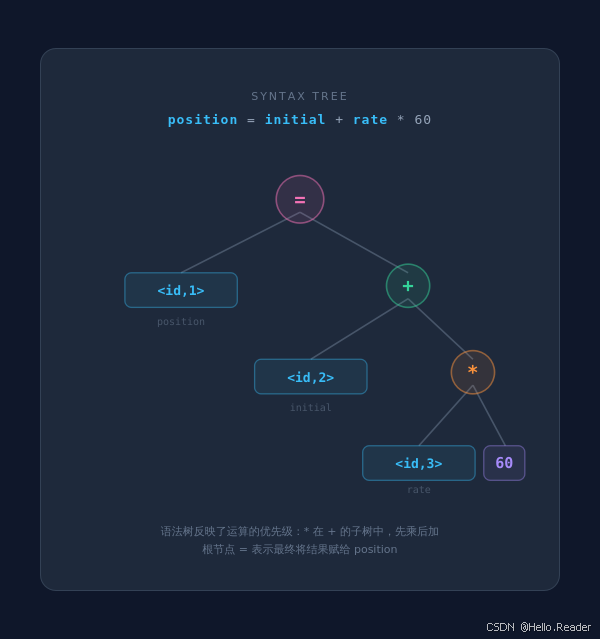
这棵树告诉我们:
*(乘法) 在+(加法) 的子树中 → 乘法先于加法执行- 整棵树的根是
=→ 最后将右侧的计算结果赋给position - 树的结构自然地反映了运算的优先级 和结合性
关键点:
- 语法分析器不关心变量的具体值,它只关心结构是否合法
- 如果写了
position = initial + * 60,语法分析器会报告语法错误 (syntax error) - 语法树的构造依赖于文法 (grammar)------这将在第4章深入讨论
阶段三:语义分析 (Semantic Analysis)
任务 :利用语法树和符号表信息检查源程序的语义一致性 ,主要是类型检查 (type checking)。
输入:上一步的语法树
处理过程:
- 检查语法树中每个运算符的操作数类型是否匹配
- 发现
rate(float)和60(int)相乘------需要类型转换 - 插入一个
inttofloat节点,将整数 60 转换为浮点数 60.0
输出:标注了类型信息的语法树
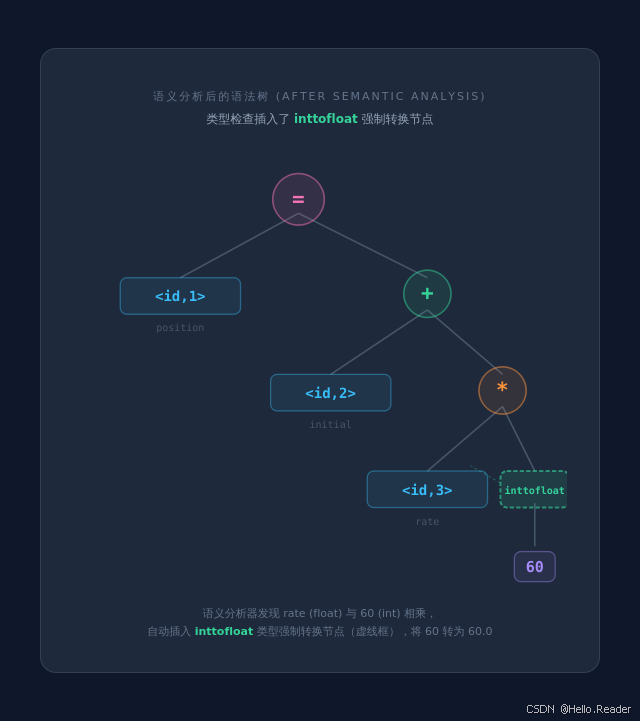
关键点:
- 语义分析发现的是含义层面的错误,而非结构层面的
- 例如:用浮点数做数组下标、类型不兼容的赋值等
- 类型强制 (coercion):编译器自动插入类型转换(如 int→float)
- 有些语言的语义检查更严格(如 Rust 的所有权检查),也在这个阶段完成
阶段四:中间代码生成 (Intermediate Code Generation)
任务 :将语法树翻译为一种中间表示 (Intermediate Representation, IR) ------通常是三地址码 (three-address code)。
输入:标注类型信息的语法树
输出:三地址码
t1 = inttofloat(60)
t2 = id3 * t1
t3 = id2 + t2
id1 = t3什么是三地址码?
三地址码的每条指令最多包含三个"地址"(操作数),形式为:
x = y op z其中 x、y、z 可以是变量名、常量或编译器生成的临时变量 (temporary variable) (如 t1、t2、t3)。
三地址码的关键特征:
- 每条指令只有一个运算符 → 明确了运算顺序(先乘后加)
- 编译器生成临时变量 → 保存中间计算结果
- 有些指令少于三个操作数 → 如
t1 = inttofloat(60)只有一个操作数
为什么需要中间代码?
- 中间代码是一种"通用语言",独立于源语言和目标机器
- 便于进行机器无关的优化
- 一个前端可以对接多个后端(不同目标机器),一个后端可以对接多个前端(不同源语言)
阶段五:代码优化 (Code Optimization)
任务:改进中间代码,使生成的目标代码更高效(通常是更快或更小)。
输入:
t1 = inttofloat(60)
t2 = id3 * t1
t3 = id2 + t2
id1 = t3优化过程:
- 常量折叠 (Constant Folding) :
inttofloat(60)可以在编译时计算,直接替换为60.0 - 临时变量消除 :
t3只被使用一次就赋给了id1,可以直接消除
输出:
t1 = id3 * 60.0
id1 = id2 + t1从4条指令缩减为2条------代码量减半,执行速度更快。
关键点:
- 优化是可选的阶段------即使不优化,编译器也能生成正确的代码
- 不同编译器优化程度差异很大------"优化编译器"会在这个阶段花费大量时间
- "优化"是个不精确的术语:编译器无法保证生成"最优"代码(这个问题通常是不可判定的),它只是尽力改进
- 第9章将系统地讨论各种优化技术
阶段六:代码生成 (Code Generation)
任务 :将中间代码翻译为目标机器的代码------分配寄存器、选择指令。
输入:
t1 = id3 * 60.0
id1 = id2 + t1输出:(假设一个简单的目标机器,有寄存器 R1、R2)
asm
LDF R2, id3 # 将 id3 (rate) 的值加载到寄存器 R2
MULF R2, R2, #60.0 # R2 = R2 * 60.0 (# 表示立即数)
LDF R1, id2 # 将 id2 (initial) 的值加载到寄存器 R1
ADDF R1, R1, R2 # R1 = R1 + R2
STF id1, R1 # 将 R1 的值存储到 id1 (position)指令含义:
LDF= Load Float(加载浮点数到寄存器)MULF= Multiply Float(浮点数乘法)ADDF= Add Float(浮点数加法)STF= Store Float(将寄存器值存储到内存)- 指令中的
F后缀表示操作的是浮点数 #60.0中的#表示这是一个立即数常量
关键点:
- 寄存器分配 (Register Allocation) 是代码生成中最关键的问题------寄存器数量有限,如何最高效地使用它们?
- 代码生成器必须了解目标机器的指令集、寄存器数量、寻址模式等
- 第8章将详细讨论代码生成技术
三、贯穿全程的符号表管理
符号表 (Symbol Table) 是编译器中的核心数据结构,记录源程序中所有标识符的相关信息。
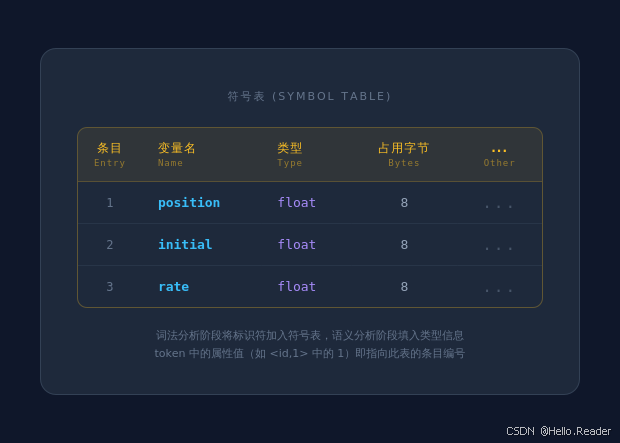
符号表存储哪些信息?
- 名字:变量/函数/类的标识符
- 类型:int, float, char\[\], struct, 函数签名等
- 作用域:在哪个代码块中可见
- 存储位置:内存地址或栈偏移量
- 对于函数:参数数量、参数类型、参数传递方式、返回类型
哪些阶段使用符号表?
- 词法分析:将新标识符加入符号表
- 语法分析:查询标识符的声明信息
- 语义分析:获取类型信息进行类型检查
- 中间代码生成:查询类型以确定运算指令
- 代码生成:查询存储分配信息以生成地址
四、阶段的分组与"遍" (Passes)
在实际实现中,上述六个逻辑阶段不一定对应六次独立的处理。多个阶段可以合并为一个遍 (pass)------读一次输入文件,写一次输出文件。
典型的分组方式:

前端/后端分离的工程价值:
通过精心设计的中间表示,可以实现前端和后端的解耦:
┌──────────┐
C 前端 ─────────>│ │─────────> x86 后端
│ 中间 │
Java 前端 ──────>│ 表示 │─────────> ARM 后端
│ (IR) │
Python 前端 ────>│ │─────────> RISC-V 后端
└──────────┘- m 种源语言 + n 种目标机器 只需要 m + n 个组件(而不是 m × n 个编译器)
- LLVM 就是这种架构的成功实践:Clang(C/C++)、Rust、Swift 等语言共享 LLVM 后端
五、编译器构造工具
龙书提到了几类帮助构建编译器的工具:
| 工具类别 | 功能 | 代表工具 |
|---|---|---|
| 语法分析器生成器 | 从文法自动生成语法分析器 | Yacc, Bison, ANTLR |
| 扫描器生成器 | 从正则表达式自动生成词法分析器 | Lex, Flex |
| 语法制导翻译引擎 | 遍历分析树并生成中间代码 | --- |
| 代码生成器的生成器 | 从规则自动生成代码生成器 | BURG |
| 数据流分析引擎 | 分析程序中值的传播方式 | --- |
| 编译器构造工具包 | 上述工具的集成套件 | LLVM |
六、六阶段完整图解总结
让我们用一张表把整个编译过程梳理清楚:
| 阶段 | 名称 | 输入 | 输出 | 核心任务 | 详细章节 |
|---|---|---|---|---|---|
| 1 | 词法分析 | 字符流 | token流 | 识别词素,生成token | Ch3 |
| 2 | 语法分析 | token流 | 语法树 | 检查语法结构,构造树 | Ch4 |
| 3 | 语义分析 | 语法树 | 标注语法树 | 类型检查,插入类型转换 | Ch6 |
| 4 | 中间代码生成 | 标注语法树 | 三地址码等 IR | 生成中间表示 | Ch6 |
| 5 | 代码优化 | IR | 优化后的 IR | 常量折叠、死代码消除等 | Ch8-9 |
| 6 | 代码生成 | 优化后的 IR | 目标机器代码 | 寄存器分配、指令选择 | Ch8 |
| --- | 符号表管理 | --- | --- | 贯穿全程,存储标识符信息 | Ch2 |
七、思考题
Q1: 如果编译器不做优化阶段,程序还能正确运行吗?
答:能 。优化是可选的,它只影响性能,不影响正确性。事实上,在开发调试阶段,关闭优化(如
gcc -O0)能让调试更容易,因为生成的代码与源代码的对应关系更直接。
Q2: 为什么不直接从源代码生成目标代码,而要经过中间代码?
答:中间代码是前端和后端之间的"契约"。它使得前端和后端可以独立开发和替换(m+n vs m×n 的优势)。同时,在中间代码层面可以做与机器无关的优化,这些优化对所有目标机器都有效。
Q3: position = initial + rate * 60 如果 rate 没有被声明,编译器会在哪个阶段报错?
答:取决于编译器的实现。词法分析阶段可以识别
rate是一个标识符,但不检查它是否被声明。语义分析阶段 会发现符号表中没有rate的条目,从而报告"未声明的变量"错误。