注:本文为 "浮点数运算" 相关译文,机翻未校。
略作重排,如有内容异常,请看原文。
csdn 篇幅所限,分篇连载。
Printing Floating-Point Numbers - An Always Correct Method
浮点数输出 ------ 一种完全正确的实现方法
Marc Andrysco
University of California, San Diego, USA
马克·安德里斯科
美国加州大学圣地亚哥分校
Ranjit Jhala
University of California, San Diego, USA
兰吉特·贾拉
美国加州大学圣地亚哥分校
Sorin Lerner
University of California, San Diego, USA
索林·勒纳
美国加州大学圣地亚哥分校
Abstract
摘要
Floating-point numbers are an essential part of modern software, recently gaining particular prominence on the web as the exclusive numeric format of Javascript. To use floating-point numbers, we require a way to convert binary machine representations into human readable decimal outputs. Existing conversion algorithms make trade-offs between completeness and performance. The classic Dragon4 algorithm by Steele and White and its later refinements achieve completeness --- i.e. produce correct and optimal outputs on all inputs --- by using arbitrary precision integer (bignum) arithmetic which leads to a high performance cost. On the other hand, the recent Grisu3 algorithm by Loitsch shows how to recover performance by using native integer arithmetic but sacrifices optimality for 0.5% of all inputs. We present Errol, a new complete algorithm that is guaranteed to produce correct and optimal results for all inputs by sacrificing a speed penalty of 2.4× to the incomplete Grisu3 but 5.2× faster than previous complete methods.
浮点数是现代软件的核心组成部分,近年来作为 JavaScript 唯一的数值格式,在 Web 领域尤为重要。使用浮点数需要将机器二进制表示转换为人类可读的十进制输出。现有转换算法在完备性 与性能 之间做取舍。斯蒂尔与怀特提出的经典 Dragon4 算法及其后续改进通过任意精度整数(大整数)运算实现完备性,即对所有输入都输出正确且最优的结果,但性能开销极高。与之相对,洛伊奇近期提出的 Grisu3 算法使用原生整数运算大幅提升性能,却会在 0.5% 的输入上牺牲最优性。本文提出全新完备算法 Errol,保证对所有输入输出正确且最优的结果;相比非完备的 Grisu3 速度慢 2.4 倍,但比此前的完备方法快 5.2 倍。
Categories and Subject Descriptors I.m Computing Methodologies: Miscellaneous
分类与主题描述 I.m 计算方法:其他
Keywords floating-point printing, dtoa, double-double
关键词 浮点数输出,双精度转十进制,双-双精度
1. Introduction
1. 引言
How should we print a floating-point number? Consider the following curious interaction with a recent Python REPL (v2.7.5)
浮点数应当如何输出?观察近期 Python 交互环境(v2.7.5)中的反常结果:
0.1 + 0.11
0.21000000000000002
The same counter-intuitive result is displayed by REPLs for JavaScript (node.js v0.10.30), Haskell (GHCi v7.10.1) and Ocaml (Ocaml v4.01.0). This puzzling behavior could be explained by rounding errors at one of two places: the actual computation or, in the focus of this paper, the printing phase.
JavaScript(node.js v0.10.30)、Haskell(GHCi v7.10.1)与 OCaml(OCaml v4.01.0)的交互环境均会出现同样反直觉的结果。这一异常现象可归因于两处舍入误差之一:实际计算过程,或本文关注的输出阶段。
The goal of the printing phase is to convert the machine-level binary representation of a floating-point number into a human-readable decimal representation with as few digits as needed to communicate the desired binary value. The conversion process is complicated by the fact that the machine can only represent a finite subset of the real numbers. Each binary machine-representable number corresponds to the set of real numbers in an interval around itself. The "wrong" output 0.21000000000000002 and the "right" output 0.21 may fall inside the same interval, and thus have exactly the same machine representation, making it hard for the output procedure to distinguish between the two. Hence, printing floating-point numbers is a surprisingly difficult problem with a distinguished line of work dating back several decades.
输出阶段的目标是将浮点数的机器级二进制表示转为人类可读的十进制表示,且位数尽可能少,同时能唯一还原目标二进制值。转换过程的难点在于:机器仅能表示实数的有限子集。每个机器可表示的二进制数对应其周围一段区间内的所有实数。看似"错误"的 0.21000000000000002 与"正确"的 0.21 可能落在同一区间内,因而拥有完全相同的机器表示,导致输出流程无法区分二者。因此,浮点数输出是一个难度远超预期的经典问题,相关研究已延续数十年。
In 1990, Steele and White published the first paper to precisely pin down what it means to correctly and optimally print a floating-point number 14. Intuitively, a (decimal) output is correct if it belongs inside the interval represented by the corresponding (binary) input. Furthermore, an output is optimal if it has the smallest number of digits among all the numbers in the interval represented by the input. Steele and White 14 show a recipe for designing correct and optimal algorithms and instantiate it in the Dragon4 algorithm for printing floating-point numbers. Unfortunately, Dragon4 relied on large integer ("bignum") arithmetic, incurring a high performance cost. Several authors including 5 and 1 devised improvements which optimized various steps that required slow bignum computations, making Dragon4 suitable for adoption inside various language run-times where it remained for about two decades. (Consequently, we can rest assured that the quirky behavior in the REPLs above is due to rounding and not conversion errors.)
1990 年,斯蒂尔与怀特首次发表论文,精确定义了浮点数正确 且最优 输出的含义 14。直观来说,十进制输出落在对应二进制输入所表示的区间内即为正确 ;输出在该区间内拥有最少位数即为最优。斯蒂尔与怀特 14 给出了设计正确且最优算法的框架,并在浮点数输出算法 Dragon4 中实现。遗憾的是,Dragon4 依赖大整数运算,性能开销极高。包括 5、1 在内的多项工作对 Dragon4 进行优化,替换了耗时的大整数计算步骤,使其得以在各类语言运行时中使用,并沿用近二十年。(由此可以确认,上述交互环境中的异常行为源于舍入误差,而非转换错误。)
This state of affairs remained until 2010 when Florian Loitsch presented the Grisu3 algorithm. Grisu3 achieved dramatic (up to 12.5×) improvements in efficiency by mostly replacing bignum computations with native 64-bit arithmetic 10. Unfortunately, the speedup came at a price. Grisu3 is incomplete in that for about 0.5% of all inputs, the algorithm produces correct but suboptimal outputs, i.e. without the fewest number of digits. Loitsch showed how the sub-optimality could be detected at run-time, and in such cases the algorithm could revert to a slower but optimal Dragon4 conversion. As printing floating-point numbers is a performance critical issue in JavaScript engines, where all numbers are floats, Grisu3 was rapidly adopted by major browser engines including Chrome, Firefox and WebKit.
这一局面持续至 2010 年,弗洛里安·洛伊奇提出 Grisu3 算法。Grisu3 几乎完全用原生 64 位运算替代大整数运算,效率大幅提升(最高达 12.5 倍)10。但这一加速存在代价:Grisu3 并非完备算法,约 0.5% 的输入会得到正确但非最优的输出,即位数并非最少。洛伊奇给出了运行时检测非最优性的方法,此类情况可回退到较慢但最优的 Dragon4 转换。由于 JavaScript 引擎中所有数值均为浮点数,浮点数输出是性能关键环节,Grisu3 迅速被 Chrome、Firefox、WebKit 等主流浏览器引擎采用。
In this paper, we present Errol, a new algorithm for the output conversion of floating-point numbers that is complete and 5.2× faster than Dragon4. We achieve this via the following contributions.
本文提出 Errol,一种全新的浮点数输出转换算法,具备完备性,且比 Dragon4 快 5.2 倍。主要贡献如下:
-
First, we generalize Grisu-style approximate conversion algorithms into framework parameterized by an abstract high-precision HP data-type that is used to compute a narrow (resp. wide) interval which provides over- (resp. under-) approximations of the optimal decimal (§ 3).
将 Grisu 类近似转换算法泛化为一个以抽象高精度 HP 数据类型为参数的框架,用于计算窄区间 与宽区间,分别对最优十进制结果做上近似与下近似(§ 3)。
-
Second, we instantiate the framework by implementing HP numbers using Knuth's double-double representation 9. The resulting algorithm, Errol1, is efficient due to novel algorithms for the key arithmetic operations. Surprisingly, we show that the double-double representation shrinks sub-optimality by an order of magnitude because Errol1 computes the narrow and wide intervals more precisely than Grisu3 (§ 4).
使用高德纳的双-双精度表示 9 实现 HP 数值,实例化该框架,得到算法 Errol1。该算法通过全新的核心算术运算实现高效执行。出乎意料的是,双-双精度表示使非最优情况减少一个数量级,因为 Errol1 计算的窄、宽区间比 Grisu3 更精确(§ 4)。
-
Third, we show empirically that further precision is useless as the errors are due to pathological values that are guaranteed to fall outside the scope of Grisu-style approximate conversion. Guided by the data, we formally characterize the region containing such pathological values, allowing us to simply fall back on an exact conversion for such inputs. We find the resulting algorithm, Errol2, to be optimal on 99.9999999% of all inputs (§ 5).
实验表明,继续提升精度无意义,误差源于病态值,这类值必然超出 Grisu 类近似转换的处理范围。基于实验数据,本文形式化刻画病态值所在区域,对此类输入直接回退到精确转换。最终算法 Errol2 对 99.9999999% 的输入均输出最优结果(§ 5)。
-
Fourth, even outside the pathological space, Grisu-style approximation may yield sub-optimal results. We develop a novel necessary condition for an input to yield sub-optimal outputs and use it to develop a constraint-based synthesis algorithm that efficiently pre-computes all (141) inputs where Errol2 may yield the sub-optimal conversion. This tabulation yields Errol3 which is guaranteed to return correct and optimal conversion for all inputs (§ 6).
即使在病态区域之外,Grisu 类近似仍可能产生非最优结果。本文提出输入产生非最优输出的全新必要条件,并据此设计基于约束的合成算法,高效预计算出 Errol2 可能产生非最优转换的全部(141 个)输入。将这些输入制表后得到 Errol3,保证对所有输入输出正确且最优的结果(§ 6)。
Finally, we present an empirical evaluation comparing Errol3 against the state of the art. We show that it is 2.5× slower than an incomplete Grisu3, 2.4× slower than Grisu3 made complete via dynamic checking, and 5.2× faster than Dragon4, the previous complete conversion method (§ 7).
最后,本文通过实验对比 Errol3 与现有最优算法:相比非完备的 Grisu3 慢 2.5 倍,相比动态检查补齐完备性的 Grisu3 慢 2.4 倍,比此前的完备转换方法 Dragon4 快 5.2 倍(§ 7)。
2. Preliminaries
2. 预备知识
We begin with some preliminaries about the properties of floating-point numbers and their representation that are needed to understand our algorithm for output conversion.
首先介绍浮点数的性质与表示方法,这些是理解本文输出转换算法的基础。
2.1 Representation
2.1 表示方法
Machines use floating-point number representations to approximate real number computations.
机器使用浮点数表示来近似实数计算。
Floating-Point Representations. A real is a value on the real number line. A floating-point format defines a finite set of representable numbers (or just representations) where each representation covers a wide range (i.e. interval) of the real number line. Variables that name representations will always be adorned with a hat, such as v ^ \hat{v} v^ and are denoted with the type F P FP FP. Note that unlike integers, which have equal-width gaps between numbers, floating-point representations have a large range of possible gaps with small representations closely packed together and large representations spread far apart.
浮点数表示 :实数是数轴上的取值。浮点数格式定义一组有限的可表示数(简称表示),每个表示覆盖数轴上一段区间。表示的变量均带帽标记,如 v ^ \hat{v} v^,类型记为 F P FP FP。与间距均匀的整数不同,浮点数表示的间距跨度极大:小数值密集分布,大数值间距稀疏。
High-Precision Representations. A high-precision floating-point number refers to a custom format with higher precision than representations supported by the native machine's architecture. Variables for high-precision numbers are adorned with a tilde, such as v ˉ \bar{v} vˉ , and are denoted with the type H P HP HP. High-precision numbers can be implemented in a variety of ways, e.g. big-integers libraries or structures.
高精度表示 :高精度浮点数指精度高于原生机器架构支持格式的自定义表示。高精度数值变量带波浪线标记,如 v ˉ \bar{v} vˉ,类型记为 H P HP HP。高精度数值可通过多种方式实现,例如大整数库或自定义结构体。
IEEE-754. F P FP FP representations consist of a fixed radix (or base), a fixed-width significand, and a fixed-width exponent of the form:
significand × radix exponent \text{significand} \times \text{radix}^{\text{exponent}} significand×radixexponent
IEEE-754 标准 : F P FP FP 表示由固定基数、固定宽度尾数与固定宽度指数组成,形式为:
尾数 × 基数 指数 \text{尾数} \times \text{基数}^{\text{指数}} 尾数×基数指数
The significand consists of a sequence of N digits d 1 ... d N d_1 \dots d_N d1...dN where each digit d i d_i di is in the range defined by the radix: 0 ≤ d i < radix 0 \le d_i < \text{radix} 0≤di<radix The IEEE-754 standard defines a set of floating-point formats, including the ubiquitous double-precision (double) and single-precision (float) binary formats. For the sake of simplicity, the remainder of this paper will exclusively discuss double numbers unless otherwise specified.
尾数由 N 位数字 d 1 ... d N d_1 \dots d_N d1...dN 组成,每位 d i d_i di 满足基数限定范围: 0 ≤ d i < 基数 0 \le d_i < \text{基数} 0≤di<基数。IEEE-754 标准定义了多种浮点数格式,包括广泛使用的二进制双精度(double)与单精度(float)格式。为简化表述,本文其余部分若无特殊说明,均仅讨论双精度数。
Normal Representations. A single number can be represented by multiple floating-point representations; e.g. 0.12 × 10 2 0.12 \times 10^2 0.12×102 and 1.2 × 10 1 1.2 \times 10^1 1.2×101 represent the same decimal number. A normal representation is a floating-point number where there is a single, non-zero digit left of the radix point. Each floating-point number has a unique normal representation; e.g. 1.2 × 10 1 1.2 \times 10^1 1.2×101 is the unique normal representation of the above number. However, the normal representation does not offer sufficient coverage for very small values close to zero. To expand the range of representable small numbers and enable "gradual underflow", the IEEE-754 standard defines the notion of a subnormal number where the significand begins with a leading 0 bit followed by several lower order bits.
规格化表示 :同一个数可由多种浮点数表示,例如 0.12 × 10 2 0.12 \times 10^2 0.12×102 与 1.2 × 10 1 1.2 \times 10^1 1.2×101 表示同一个十进制数。规格化表示指小数点左侧仅有一位非零数字的浮点数。每个浮点数拥有唯一的规格化表示,例如上述数的唯一规格化表示为 1.2 × 10 1 1.2 \times 10^1 1.2×101。但规格化表示无法覆盖接近零的极小数值。为扩展可表示的小数范围并支持渐进下溢 ,IEEE-754 标准定义了非规格化数:尾数以 0 开头,后续为若干低位比特。
2.2 Conversion
2.2 转换
As the FP numbers are finite, an arbitrary real number is unlikely to fall exactly upon an F P FP FP value. Next, we describe how reals are rounded to FP values in the IEEE-754 standard, and the notion of rounding to define correct and optimal conversion from floating point to decimal format.
由于 F P FP FP 数有限,任意实数很难恰好落在 F P FP FP 可表示值上。下文介绍 IEEE-754 标准中实数向 F P FP FP 值的舍入规则,并基于舍入定义浮点数到十进制的正确 与最优转换。
Neighbors. For each representation v ^ \hat{v} v^ (except at the extremes) there exists a successor representation denoted as v ^ + \hat{v}^+ v^+ which is the next (larger) representation, and a predecessor representation denoted as v ^ − \hat{v}^- v^− which is the previous (smaller) representation. Thus, for each real number there is a pair of adjacent neighbors v ^ \hat{v} v^ and v ^ + \hat{v}^+ v^+ such that the real is in the interval between the neighbors.
邻值 :对每个表示 v ^ \hat{v} v^(边界值除外),存在后继表示 v ^ + \hat{v}^+ v^+(更大的下一个值)与前驱表示 v ^ − \hat{v}^- v^−(更小的上一个值)。因此,每个实数都落在一对相邻邻值 v ^ \hat{v} v^ 与 v ^ + \hat{v}^+ v^+ 之间的区间内。
Midpoints. A midpoint m ˉ \bar{m} mˉ is the real value exactly between two adjacent representations. Formally, for a representation v ^ \hat{v} v^ , we define the succeeding and preceding midpoints respectively as:
中点 :中点 m ˉ \bar{m} mˉ 是两个相邻表示正中间的实数值。形式化地,对表示 v ^ \hat{v} v^,后继中点与前驱中点分别定义为:
m ˉ + ≐ v ^ + v ^ + 2 m ˉ − ≐ v ^ − + v ^ 2 \bar{m}^+ \doteq \frac{\hat{v}+\hat{v}^+}{2} \quad \bar{m}^- \doteq \frac{\hat{v}^-+\hat{v}}{2} mˉ+≐2v^+v^+mˉ−≐2v^−+v^
The midpoints are not representable using the native representation format but can be represented by most high-precision representations that provide at least a single additional bit.
中点无法用原生格式表示,但多数至少多一位精度的高精度表示均可表示中点。
Rounding: Intervals & Functions. Recall that a given value v ^ \hat{v} v^ is surrounded by the midpoints m ˉ − \bar{m}^- mˉ− and m ˉ + \bar{m}^+ mˉ+. Any real r r r in the range m ˉ − < r < m ˉ + \bar{m}^- < r < \bar{m}^+ mˉ−<r<mˉ+ is rounded to v ^ \hat{v} v^. If the real falls exactly on a midpoint between two floating-point numbers, the standard dictates that the value must be rounded to the even floating-point number, which is the number whose last bit is 0 (as opposed to odd numbers whose last bit is 1). Thus, the rounding interval of a binary representation v ^ \hat{v} v^ is the range m ˉ − , m ˉ + \\bar{m}\^-, \\bar{m}\^+ mˉ−,mˉ+ when v ^ \hat{v} v^ is even or ( m ˉ − , m ˉ + ) (\bar{m}^-, \bar{m}^+) (mˉ−,mˉ+) when v ^ \hat{v} v^ is odd. The rounding function f l t flt flt takes a real number and rounds it to the nearest floating-point representation. Thus, for any number r r r in the rounding interval of v ^ \hat{v} v^, f l t ( r ) ≐ v ^ flt(r) \doteq \hat{v} flt(r)≐v^.
舍入:区间与函数 :给定值 v ^ \hat{v} v^ 被中点 m ˉ − \bar{m}^- mˉ− 与 m ˉ + \bar{m}^+ mˉ+ 包围。满足 m ˉ − < r < m ˉ + \bar{m}^- < r < \bar{m}^+ mˉ−<r<mˉ+ 的任意实数 r r r 均舍入为 v ^ \hat{v} v^。若实数恰好落在两个浮点数的中点上,标准规定舍入到偶数浮点数 ,即最低位为 0 的数(区别于最低位为 1 的奇数)。因此,二进制表示 v ^ \hat{v} v^ 的舍入区间: v ^ \hat{v} v^ 为偶数时是 m ˉ − , m ˉ + \\bar{m}\^-, \\bar{m}\^+ mˉ−,mˉ+,为奇数时是 ( m ˉ − , m ˉ + ) (\bar{m}^-, \bar{m}^+) (mˉ−,mˉ+)。舍入函数 f l t flt flt 将实数舍入到最近的浮点数表示。对 v ^ \hat{v} v^ 舍入区间内的任意数 r r r,有 f l t ( r ) ≐ v ^ flt(r) \doteq \hat{v} flt(r)≐v^。
Conversion: Correctness & Optimality. Let v ^ \hat{v} v^ be a binary input representation and let r r r be the decimal number produced as the conversion output. The conversion from v ^ \hat{v} v^ to r r r is correct if r r r falls in rounding interval of v ^ \hat{v} v^ (i.e. f l t ( r ) = v ^ flt(r)=\hat{v} flt(r)=v^). The length of a real r r r is the number of decimal digits required to write the significand as a string. For example, the length of 1.24 × 10 5 1.24 \times 10^5 1.24×105 is 3. The conversion from v ^ \hat{v} v^ to r r r is optimal if r r r is the value in the rounding interval of v ^ \hat{v} v^ with the smallest length, i.e. if every value in the rounding interval of v ^ \hat{v} v^ has length at least as large as r r r. Note that there may exist multiple, unique values of r r r of optimal length.
转换:正确性与最优性 :设 v ^ \hat{v} v^ 为二进制输入表示, r r r 为转换输出的十进制数。若 r r r 落在 v ^ \hat{v} v^ 的舍入区间内(即 f l t ( r ) = v ^ flt(r)=\hat{v} flt(r)=v^),则从 v ^ \hat{v} v^ 到 r r r 的转换是正确 的。实数 r r r 的长度指尾数字符串的十进制位数,例如 1.24 × 10 5 1.24 \times 10^5 1.24×105 的长度为 3。若 r r r 是 v ^ \hat{v} v^ 舍入区间内长度最小的值,则转换是最优 的,即区间内所有值的长度均不小于 r r r。注意可能存在多个不同的最优长度 r r r。
3. A Generic Conversion Framework
3. 通用转换框架
Our work builds on the Grisu3 algorithm of Loitsch 10. In this section, we distill the insights from Grisu3 into a general conversion framework parameterized by an abstract high-precision representation H P HP HP and discuss the requirements on H P HP HP that ensure correctness and optimality. In § 4, we instantiate the framework with a novel H P HP HP type that is more accurate although slower than Grisu3.
本文工作基于洛伊奇的 Grisu3 算法 10。本节将 Grisu3 的核心思想提炼为以抽象高精度表示 H P HP HP 为参数的通用转换框架,并讨论保证正确性与最优性对 H P HP HP 的要求。§ 4 将用一种全新的 H P HP HP 类型实例化该框架,该类型比 Grisu3 更精确,但速度稍慢。
3.1 Generic Conversion Algorithm
3.1 通用转换算法
Recall that a correct and optimal decimal conversion of a number v ^ \hat{v} v^ is the shortest decimal in the rounding interval of v ^ \hat{v} v^. The key insight in Grisu3, illustrated in Figure 1, is to:
如前所述,数 v ^ \hat{v} v^ 的正确且最优十进制转换是其舍入区间内最短的十进制数。Grisu3 的核心思想如图 1 所示,分为两步:
-
Compute narrow boundaries n ˉ − \bar{n}^- nˉ−, n ˉ + \bar{n}^+ nˉ+ such that:
计算窄边界 n ˉ − \bar{n}^- nˉ−、 n ˉ + \bar{n}^+ nˉ+,满足:
m ˉ − < n ˉ − < v ^ < n ˉ + < m ˉ + \bar{m}^- < \bar{n}^- < \hat{v} < \bar{n}^+ < \bar{m}^+ mˉ−<nˉ−<v^<nˉ+<mˉ+ -
Compute shortest decimal in the interval n ˉ − , n ˉ + \\bar{n}\^-, \\bar{n}\^+ nˉ−,nˉ+
计算区间 n ˉ − , n ˉ + \\bar{n}\^-, \\bar{n}\^+ nˉ−,nˉ+ 内的最短十进制数
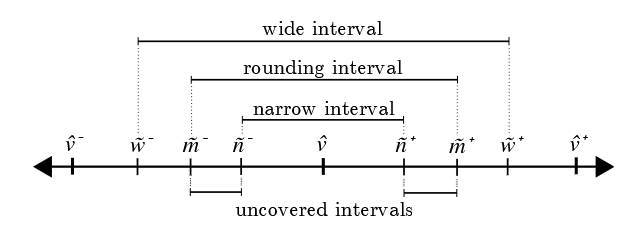
Figure 1: Representations, Midpoints and Boundaries: v ^ \hat{v} v^ denotes a native, machine representable floating point number with neighbors v ^ − \hat{v}^- v^− and v ^ + \hat{v}^+ v^+; m ˉ − \bar{m}^- mˉ− and m ˉ + \bar{m}^+ mˉ+ denote exact midpoints; n ˉ − \bar{n}^- nˉ− and n ˉ + \bar{n}^+ nˉ+ denote the narrow (or conservative) boundaries; w ˉ − \bar{w}^- wˉ− and w ˉ + \bar{w}^+ wˉ+ denote wide boundaries; and the uncovered intervals denote the portion of the rounding interval not covered by the narrow interval.
图 1:表示、中点与边界: v ^ \hat{v} v^ 表示原生机器可表示浮点数,邻值为 v ^ − \hat{v}^- v^− 与 v ^ + \hat{v}^+ v^+; m ˉ − \bar{m}^- mˉ− 与 m ˉ + \bar{m}^+ mˉ+ 表示精确中点; n ˉ − \bar{n}^- nˉ− 与 n ˉ + \bar{n}^+ nˉ+ 表示窄(保守)边界; w ˉ − \bar{w}^- wˉ− 与 w ˉ + \bar{w}^+ wˉ+ 表示宽边界;未覆盖区间指舍入区间中未被窄区间覆盖的部分。
By relaxing the constraints of using exact midpoints m ˉ − \bar{m}^- mˉ−, m ˉ + \bar{m}^+ mˉ+, Grisu3 can use efficient operations over limited-precision numbers (instead of Dragon4's bignum) to yield provably correct albeit possibly suboptimal conversions.
通过放宽对精确中点 m ˉ − \bar{m}^- mˉ−、 m ˉ + \bar{m}^+ mˉ+ 的依赖,Grisu3 可使用低精度数值上的高效运算(替代 Dragon4 的大整数运算),得到可证明正确、但可能非最优的转换结果。
Scaled Narrow Intervals. A triple ( e , n ˉ − , n ˉ + ) (e, \bar{n}^-, \bar{n}^+) (e,nˉ−,nˉ+) is a scaled narrow interval for v ^ \hat{v} v^ if there exists n ˉ − \bar{n}^- nˉ−, n ˉ + \bar{n}^+ nˉ+ such that:
缩放窄区间 :若存在 n ˉ − \bar{n}^- nˉ−、 n ˉ + \bar{n}^+ nˉ+ 满足以下条件,则三元组 ( e , n ˉ − , n ˉ + ) (e, \bar{n}^-, \bar{n}^+) (e,nˉ−,nˉ+) 是 v ^ \hat{v} v^ 的缩放窄区间:
- n ˉ + ∈ ( 1 , 10 ] 2. n ˉ − ≈ 10 − e × n ˉ − 3. n ˉ + ≈ 10 − e × n ˉ + 4. m ˉ − < n ˉ − < v ^ < n ˉ + < m ˉ + \begin{align*} 1 . &\quad \bar{n}^+ \mathrel{\in} (1,10] \\ 2 . &\quad \bar{n}^- \mathrel{\approx} 10^{-e} \times \bar{n}^- \\ 3 . &\quad \bar{n}^+ \mathrel{\approx} 10^{-e} \times \bar{n}^+ \\ 4 . &\quad \bar{m}^- < \bar{n}^- < \hat{v} < \bar{n}^+ < \bar{m}^+ \end{align*} 1.2.3.4.nˉ+∈(1,10]nˉ−≈10−e×nˉ−nˉ+≈10−e×nˉ+mˉ−<nˉ−<v^<nˉ+<mˉ+
Intuitively, a scaled narrow interval for v ^ \hat{v} v^ corresponds to a narrow interval for v ^ \hat{v} v^ where the boundaries are scaled by 10 − e 10^{-e} 10−e to ensure that the upper bound n ˉ + \bar{n}^+ nˉ+ is in ( 1 , 10 ] (1,10] (1,10]. Note that the last requirement allows us to compute the (scaled) narrow intervals approximately, e.g. using H P HP HP numbers, as long as the (unscaled) boundaries reside within the exact midpoints m ˉ − \bar{m}^- mˉ− and m ˉ + \bar{m}^+ mˉ+. Finally, only the upper boundary n ˉ + \bar{n}^+ nˉ+ must be in the interval ( 1 , 10 ] (1,10] (1,10], hence we observe that the exponent is e ≈ ⌊ log 10 n ˉ + ⌋ e \approx \lfloor \log_{10} \bar{n}^+ \rfloor e≈⌊log10nˉ+⌋.
直观来说, v ^ \hat{v} v^ 的缩放窄区间是将窄区间边界缩放 10 − e 10^{-e} 10−e 得到的,保证上界 n ˉ + \bar{n}^+ nˉ+ 落在 ( 1 , 10 ] (1,10] (1,10] 内。最后一条约束允许用 H P HP HP 数值近似计算(缩放)窄区间,只需保证(未缩放)边界落在精确中点 m ˉ − \bar{m}^- mˉ− 与 m ˉ + \bar{m}^+ mˉ+ 之间即可。仅需上边界 n ˉ + \bar{n}^+ nˉ+ 落在 ( 1 , 10 ] (1,10] (1,10] 内,因此指数 e ≈ ⌊ log 10 n ˉ + ⌋ e \approx \lfloor \log_{10} \bar{n}^+ \rfloor e≈⌊log10nˉ+⌋。
Algorithm. Figure 2 formalizes the above intuition in a generic algorithm to convert an input F P FP FP value v ^ \hat{v} v^ into decimal form comprising a pair of a sequence of digits d 1 , ... , d N d_1, \dots, d_N d1,...,dN and an exponent e e e denoting the decimal value 0. d 1 ... d N × 10 e 0.d_1 \dots d_N \times 10^e 0.d1...dN×10e. (Although this differs slightly from the normal format -- with a leading non-zero digit -- we can normalize by shifting the decimal point to the right.) The convert algorithm is split into two procedures, narrow_interval and digits, corresponding to the steps described above. The first phase narrow_interval begins with the input v ^ \hat{v} v^ and computes a scaled narrow interval ( e , n ˉ − , n ˉ + ) (e, \bar{n}^-, \bar{n}^+) (e,nˉ−,nˉ+) for v ^ \hat{v} v^. The second phase digits uses the scaled narrow interval to compute the final output digits corresponding to the shortest decimal value within the scaled narrow interval n ˉ − , n ˉ + \\bar{n}\^-, \\bar{n}\^+ nˉ−,nˉ+. Next, we describe the two steps in detail.
算法 :图 2 将上述思路形式化为通用算法,将 F P FP FP 输入 v ^ \hat{v} v^ 转换为十进制形式:由数字序列 d 1 , ... , d N d_1, \dots, d_N d1,...,dN 与指数 e e e 组成,表示十进制值 0. d 1 ... d N × 10 e 0.d_1 \dots d_N \times 10^e 0.d1...dN×10e。(虽与首位非零的规格化格式略有差异,可通过右移小数点完成规格化。)转换算法分为 narrow_interval 与 digits 两个过程,对应上述两步。第一阶段 narrow_interval 以输入 v ^ \hat{v} v^ 为参数,计算其缩放窄区间 ( e , n ˉ − , n ˉ + ) (e, \bar{n}^-, \bar{n}^+) (e,nˉ−,nˉ+)。第二阶段 digits 利用缩放窄区间,计算区间 n ˉ − , n ˉ + \\bar{n}\^-, \\bar{n}\^+ nˉ−,nˉ+ 内最短十进制值对应的最终输出数字。下文详细介绍这两步。

Figure 2: A Generic Conversion Algorithm
图 2:通用转换算法
The functions boundary and multiply are deliberately left abstract. However, any concrete implementations must take care to ensure that despite errors introduced by rounding and propagation, the overall output is indeed a valid narrow interval for v ^ \hat{v} v^. Consequently, the narrow boundaries computed by boundary are chosen in a conservative fashion -- as shown in Figure 3 -- so that despite any rounding and propagation errors, the results remain within the actual midpoints, and hence form a valid narrow interval.
函数 boundary 与 multiply 刻意保留为抽象形式。但任何具体实现都必须保证:即使存在舍入与误差传播,最终输出仍是 v ^ \hat{v} v^ 的合法窄区间。因此,boundary 计算的窄边界采用保守方式选取(如图 3 所示),确保在任何舍入与误差传播下,结果仍落在真实中点之间,从而构成合法窄区间。
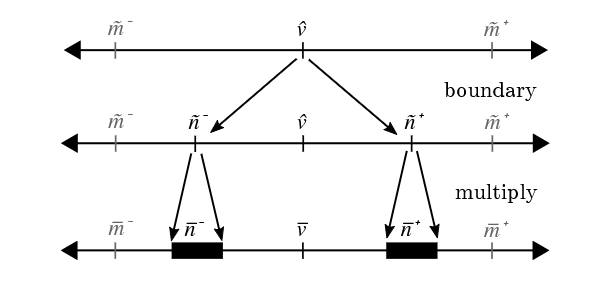
Figure 3: Error Propagation. The multiply operation computes the scaled interval ( n ˉ − , n ˉ + ) (\bar{n}^-, \bar{n}^+) (nˉ−,nˉ+) with error (as represented by the black boxes), creating the requirement that the narrow interval ( n ~ − , n ~ + ) (\tilde{n}^-, \tilde{n}^+) (n~−,n~+) be conservative enough to prevent overlap with the scaled midpoints m ˉ − \bar{m}^- mˉ− and m ˉ + \bar{m}^+ mˉ+.
图 3:误差传播。乘法运算计算缩放区间 ( n ˉ − , n ˉ + ) (\bar{n}^-, \bar{n}^+) (nˉ−,nˉ+) 时会引入误差(黑色方框表示),因此要求窄区间 ( n ~ − , n ~ + ) (\tilde{n}^-, \tilde{n}^+) (n~−,n~+) 足够保守,避免与缩放中点 m ˉ − \bar{m}^- mˉ− 与 m ˉ + \bar{m}^+ mˉ+ 重叠。
3.2 Step 1: Compute Narrow Interval
3.2 步骤 1:计算窄区间
The first phase computes the scaled narrow interval ( e , n ˉ − , n ˉ + ) (e, \bar{n}^-, \bar{n}^+) (e,nˉ−,nˉ+) for the input v ^ \hat{v} v^. First, the (unscaled) boundary n ˉ − \bar{n}^- nˉ−, n ˉ + \bar{n}^+ nˉ+ is computed directly from the input v ^ \hat{v} v^ by the function boundary. Second, the exponent e e e is directly computed from the upper boundary n ˉ + \bar{n}^+ nˉ+ by scaling it to ensure that its significand lies in the range [1, 10). That is, the exponent e e e is computed as the value ⌊ log 10 n ~ + ⌋ \lfloor \log_{10} \tilde{n}^+ \rfloor ⌊log10n~+⌋. Finally, using the exponent, the scaled narrow boundaries are computed by multiplying the narrow boundaries by 10 − e 10^{-e} 10−e.
第一阶段计算输入 v ^ \hat{v} v^ 的缩放窄区间 ( e , n ˉ − , n ˉ + ) (e, \bar{n}^-, \bar{n}^+) (e,nˉ−,nˉ+)。首先,通过 boundary 函数从输入 v ^ \hat{v} v^ 直接计算(未缩放)边界 n ˉ − \bar{n}^- nˉ−、 n ˉ + \bar{n}^+ nˉ+。其次,从上边界 n ˉ + \bar{n}^+ nˉ+ 直接计算指数 e e e,将其缩放至尾数落在 [1, 10) 区间内,即指数 e = ⌊ log 10 n ~ + ⌋ e = \lfloor \log_{10} \tilde{n}^+ \rfloor e=⌊log10n~+⌋。最后,用指数将窄边界乘以 10 − e 10^{-e} 10−e,得到缩放窄边界。
3.3 Step 2: Compute Digits
3.3 步骤 2:计算数字
Once we have calculated the scaled narrow interval and corresponding exponent e e e, we can extract the digits using Steele & White's method 14.
得到缩放窄区间与对应指数 e e e 后,可使用斯蒂尔与怀特的方法 14 提取数字。
One approach would simply generate digits of the upper bound in the following manner. Recall that the upper bound is scaled to be of the form d 1 . d 2 ... d N d_1.d_2 \dots d_N d1.d2...dN -- a result of falling in the range [1, 10). Thus, the leading digit is retrieved by simply truncating the value to an integer, leaving a remainder bound comprising the digits 0. d 2 ... d N 0.d_2 \dots d_N 0.d2...dN. The remainder is multiplied by 10 to return it to the decimal format d 2 . d 3 ... d N d_2.d_3 \dots d_N d2.d3...dN. The process can be iteratively performed N times, until all decimal digits are exhausted and the remainder is zero.
一种简单方法是直接生成上界的数字:上界已缩放为 d 1 . d 2 ... d N d_1.d_2 \dots d_N d1.d2...dN 形式(落在 [1, 10) 区间内)。取整数部分得到首位数字,剩余部分为 0. d 2 ... d N 0.d_2 \dots d_N 0.d2...dN。将剩余部分乘以 10,回到 d 2 . d 3 ... d N d_2.d_3 \dots d_N d2.d3...dN 格式。重复该过程 N 次,直至所有十进制数字提取完毕且余数为零。
While this process yields a correct result that is in the rounding interval of the input v ^ \hat{v} v^, it does not yield the optimal value with the shortest digit sequence. To recover optimality, Steele & White 14 make clever use of the lower boundary n ˉ − \bar{n}^- nˉ−: they simultaneously perform the above extraction process on both boundaries, generating two sequences of digits: d 1 + d 2 + ... d_1^+ d_2^+ \dots d1+d2+... and d 1 − d 2 − ... d_1^- d_2^- \dots d1−d2−..., and repeating the process until it finds the first pair of digits that differ i.e. the first k k k such that d k − ≠ d k + d_k^- \neq d_k^+ dk−=dk+. The sequence of digits that is then output is the upper sequence 0. d 1 + d 2 + ... d k + 0.d_1^+ d_2^+ \dots d_k^+ 0.d1+d2+...dk+ which is identical to the lower sequence except at the very last digit.
该过程能得到落在输入 v ^ \hat{v} v^ 舍入区间内的正确结果,但无法得到位数最短的最优值。为恢复最优性,斯蒂尔与怀特 14 巧妙利用下边界 n ˉ − \bar{n}^- nˉ−:同时对上下边界执行上述提取过程,生成两组数字序列 d 1 + d 2 + ... d_1^+ d_2^+ \dots d1+d2+... 与 d 1 − d 2 − ... d_1^- d_2^- \dots d1−d2−...,重复至找到第一对不同数字,即首个满足 d k − ≠ d k + d_k^- \neq d_k^+ dk−=dk+ 的 k k k。输出上界序列 0. d 1 + d 2 + ... d k + 0.d_1^+ d_2^+ \dots d_k^+ 0.d1+d2+...dk+,该序列与下界序列仅最后一位不同。
Looking at it another way, the algorithm iteratively generates the digits of the upper bound n ˉ + \bar{n}^+ nˉ+, forming the sequence ( d 1 + , d 1 + . d 2 + , d 1 + . d 2 + d 3 + , ... ) (d_1^+, d_1^+.d_2^+, d_1^+.d_2^+d_3^+, \dots) (d1+,d1+.d2+,d1+.d2+d3+,...) The process terminates once the generated number falls within the rounding interval. Figure 4 visually shows this process for the sample boundaries n ˉ − = 1.212 \bar{n}^-=1.212 nˉ−=1.212 and n ˉ + = 1.234 \bar{n}^+=1.234 nˉ+=1.234. In this example, the algorithm produces the correct and optimal number 1.23.
换一种视角,算法迭代生成上界 n ˉ + \bar{n}^+ nˉ+ 的数字,构成序列 ( d 1 + , d 1 + . d 2 + , d 1 + . d 2 + d 3 + , ... ) (d_1^+, d_1^+.d_2^+, d_1^+.d_2^+d_3^+, \dots) (d1+,d1+.d2+,d1+.d2+d3+,...),当生成的数落入舍入区间时终止。图 4 以边界 n ˉ − = 1.212 \bar{n}^-=1.212 nˉ−=1.212、 n ˉ + = 1.234 \bar{n}^+=1.234 nˉ+=1.234 为例直观展示该过程,算法输出正确且最优的数 1.23。
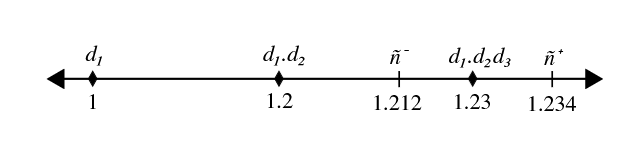
Figure 4: Correct and optimal digits generation. The lower bound is n ˉ − = 1.212 \bar{n}^-=1.212 nˉ−=1.212, and the upper bound is n ˉ + = 1.234 \bar{n}^+=1.234 nˉ+=1.234. Diamonds denote the output digits at every iteration of the process. The process generates the digits of n ˉ + \bar{n}^+ nˉ+ one digit at a time, terminating once the output digits exceed the previous bound.
图 4:正确且最优的数字生成。下边界为 n ˉ − = 1.212 \bar{n}^-=1.212 nˉ−=1.212,上边界为 n ˉ + = 1.234 \bar{n}^+=1.234 nˉ+=1.234。菱形表示每轮迭代的输出数字。过程逐位生成 n ˉ + \bar{n}^+ nˉ+ 的数字,当输出数字超过下边界时终止。
Theorem 1. The function digits ( n ˉ − , n ˉ + ) (\bar{n}^-, \bar{n}^+) (nˉ−,nˉ+) returns the optimal (shortest) decimal value in the interval n ˉ − , n ˉ + \\bar{n}\^-, \\bar{n}\^+ nˉ−,nˉ+.
定理 1 :函数 digits ( n ˉ − , n ˉ + ) (\bar{n}^-, \bar{n}^+) (nˉ−,nˉ+) 返回区间 n ˉ − , n ˉ + \\bar{n}\^-, \\bar{n}\^+ nˉ−,nˉ+ 内最优(最短)的十进制值。
By construction, the output digits are guaranteed to be correct: the sequence of digits is guaranteed to be less than n ˉ + \bar{n}^+ nˉ+ and the algorithm terminates once digits is greater than n ˉ − \bar{n}^- nˉ−. To show that the generated digits are optimal, i.e. they are the shortest sequence between n ˉ − \bar{n}^- nˉ− and n ˉ + \bar{n}^+ nˉ+, we refer to Theorem 6.2 in 10.
构造保证输出数字正确:数字序列一定小于 n ˉ + \bar{n}^+ nˉ+,且当数字大于 n ˉ − \bar{n}^- nˉ− 时算法终止。生成数字最优(即 n ˉ − \bar{n}^- nˉ− 与 n ˉ + \bar{n}^+ nˉ+ 之间最短序列)的证明参见文献 10 定理 6.2。
3.4 Optimality Verification
3.4 最优性验证
The above process computes a decimal output that is both correct and optimal within narrow boundaries; however, the output is not necessarily optimal within the larger rounding interval. In particular, the uncovered interval depicted in Figure 1, may contain a shorter decimal than any in the narrow interval considered by digits, and hence convert may fail to generate the shortest possible decimal output in the rounding interval.
上述过程在窄边界内计算出正确且最优的十进制输出,但在更大的舍入区间内不一定最优。特别地,图 1 中的未覆盖区间可能包含比 digits 函数在窄区间内找到的更短十进制数,因此 convert 可能无法生成舍入区间内最短的十进制输出。
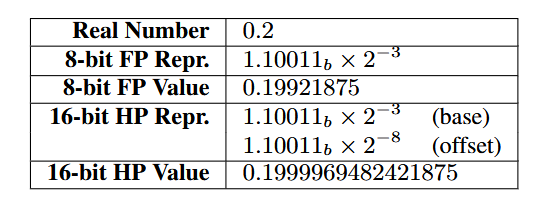
Figure 5: Representing 0.2 in FP and HP
图 5:0.2 在浮点格式与半精度浮点格式中的表示
base(基值)
offset(偏移)
Loitsch's Grisu3 algorithm introduces an a posteriori optimality verification step. Grisu3 computes a second decimal output over the wide interval that is guaranteed optimal (or shorter) but not necessarily correct, as it includes points outside the rounding interval. Nevertheless, if the length of the original and second outputs are equal, then the original output must be optimal 10. Of course, there may be shorter decimals inside the wide interval but not inside the rounding interval. In this case, the verification would produce a false negative, errantly claiming the output is sub-optimal.
洛伊奇的 Grisu3 算法引入后验最优性验证步骤。Grisu3 在宽区间上计算第二个十进制输出,该输出保证最优(或更短),但不一定正确,因为宽区间包含舍入区间外的点。但若原输出与第二个输出长度相同,则原输出一定最优 10。当然,宽区间内可能存在更短但不在舍入区间内的十进制数,此时验证会产生假阴性,错误判定输出非最优。
- 浮点数输出 | 一种完全正确的实现方法(2)-CSDN博客
https://blog.csdn.net/u013669912/article/details/159588937