一、二分类
1、 定义
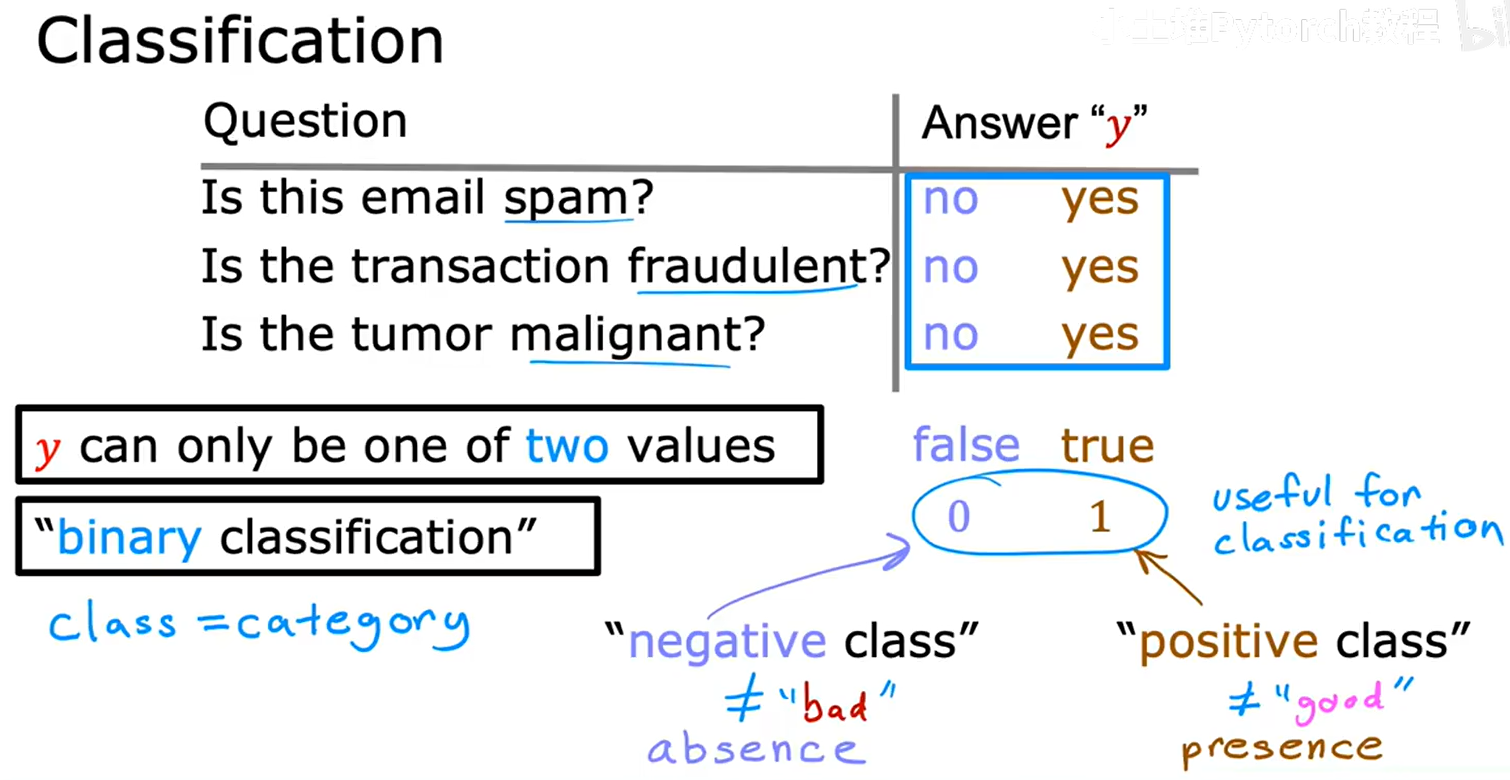
什么是分类问题?------输出变量 y 只能取少数几个离散值,而不是无限范围内的任意数值。
问题只有两个可能的输出,这被称为二分类。
- 0 = 负类 / 否 / 假(例如:非垃圾邮件、良性肿瘤)。
- 1 = 正类 / 是 / 真(例如:垃圾邮件、恶性肿瘤)。
- "正类"与"负类"并不代表好坏,仅代表某种属性的存在或缺失。
2、为什么线性回归不适合分类?
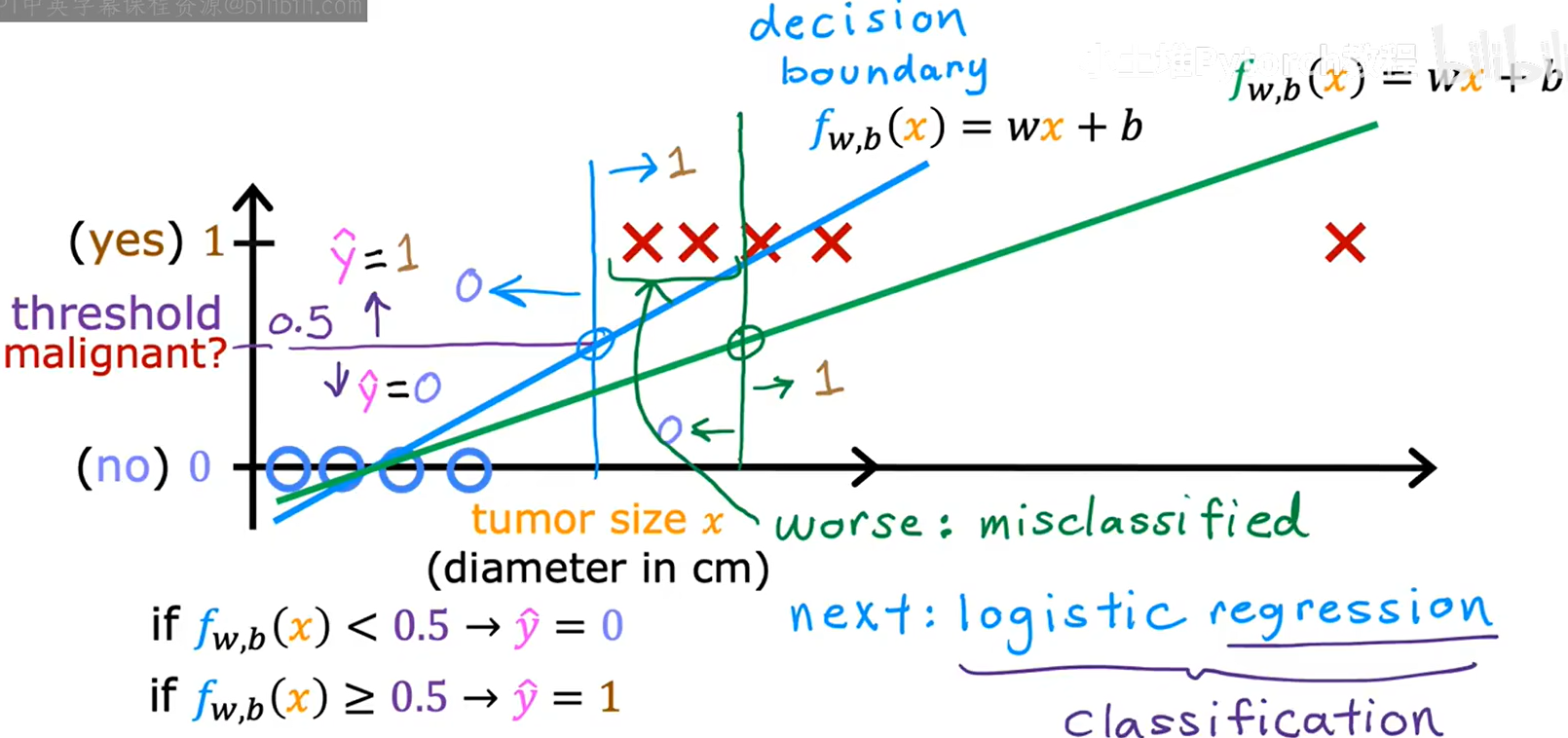
如下图,你可能会想:"既然 y 是 0 或 1,我能不能直接用线性回归画一条直线,然后设定一个阈值(比如 0.5)来分类呢?"
- 方法:如果预测值 <0.5 ,则预测为 0;如果 ≥0.5 ,则预测为 1。
- 问题 :线性回归对异常值非常敏感,会导致分类边界发生不合理的偏移。
- 假设在数据集的最右侧增加了一个非常大的训练样本(一个巨大的良性肿瘤)
- 后果:线性回归为了拟合这个新点,会将直线"拉"向右边,导致斜率变平缓。
- 决策边界移动:原本合理的决策边界(垂直线)被迫向右移动。
- 错误:这导致原本应该被分类为"恶性"的肿瘤,现在被错误地分类为"良性"。
结论 :仅仅因为数据集中增加了一个远离主群体的样本,就改变了我们对其他数据的分类标准,这是不合理的。因此,线性回归不是解决分类问题的好算法。
二、分类算法:逻辑回归【此次项目用不上】
虽然名字里有"回归",但它实际上是一种分类算法。这个名字是历史遗留原因,不要被误导。
核心优势:
- 逻辑回归的输出值永远在 0 到 1 之间。
- 它不会出现线性回归那样因为个别异常值而导致决策边界剧烈移动的问题。
- 它是目前最流行、应用最广泛的分类算法之一。
具体的见下述链接"6、逻辑回归"

三、过拟合问题
四、正则化解决过拟合问题
