LLMs之Scaling Law之Cross-Entropy:《What Scales in Cross-Entropy Scaling Law?》翻译与解读
导读 :这篇论文把"交叉熵为什么会缩放"拆成了可解释、可验证、可应用的问题:作者通过 RBE 视角把 cross-entropy 精确分解为 Error-Entropy、Self-Alignment 和 Confidence,并用大规模实验发现,真正遵循幂律缩放的只有 Error-Entropy;因此,过去看到的 cross-entropy scaling law,更像是 Error-Entropy scaling law 的外在表现。这个结论不仅解释了小模型与大模型的差异,也为未来训练目标的设计提供了更明确的方向。
>> 背景痛点:
●cross-entropy scaling law 在超大规模下开始失真:论文指出,交叉熵缩放律长期被用来指导大模型训练,但近期证据表明,当模型规模继续增大时,cross-entropy 的下降速度会明显变慢,导致原本看似稳定的幂律规律失效。
●只看 cross-entropy,无法解释"为什么会缩放":作者认为,cross-entropy 作为一个整体并不真正"统一地缩放",它内部可能只有某个隐藏成分在起作用,因此需要把总损失拆开分析,才能找到真正驱动规律的部分。
●现有理论对 cross-entropy 的解释不够直接:论文指出,已有很多理论工作能解释误差类指标的缩放,但难以直接推广到 cross-entropy,这使得其理论基础仍不清晰。
>> 具体的解决方案:
● 提出 cross-entropy 的三项精确分解:作者把 cross-entropy 精确拆为三部分:Error-Entropy、Self-Alignment、Confidence,并给出数学推导与实验验证,证明这一分解可以准确刻画训练动态。
● 用 Rank-based Error(RBE)替代单纯概率视角:论文提出 RBE,即"正确 token 的排名",认为它比正确 token 的原始概率更能稳健反映模型性能,因为概率容易被 temperature、top-k、top-p 等采样策略扰动,而排序更稳定。
● 把"真正有效的缩放"单独识别出来:在三项分解中,作者发现只有 Error-Entropy 真正呈现稳定幂律缩放,因此提出 Error-Entropy Scaling Law,作为比原始 cross-entropy 更准确的模型缩放描述。
>> 核心思路步骤:
● 先定义可解释的错误度量 RBE:对每个样本,统计 ground-truth token 在预测分布中的排名,把"错得多远"转化为一个可比较的 rank 变量。
● 再按 RBE 分组重写 cross-entropy:作者将相同 RBE 的样本聚合,借助对数求和与分布重写,把原始 cross-entropy 改写成三个有明确含义的项。
● 三项分别对应不同优化目标:Error-Entropy 对应 RBE 分布的 Shannon entropy,目标是让正确 token 更靠前;Self-Alignment 对应 RBE 分布与得分分布之间的 KL 散度,表示模型输出分数与自身错误结构的对齐;Confidence 则对应归一化常数,反映模型整体"自信程度"。
● 用训练轨迹验证分解是有效的:实验显示,训练过程中 Error-Entropy 持续下降,Self-Alignment 最终也下降,而 Confidence 上升,且模型会先大幅优化 Error-Entropy,再逐步处理另外两项。
● 再做大规模缩放实验验证谁在真正缩放:作者在多个真实语言数据集上,用 32 个模型、覆盖五个数量级规模进行实验,发现只有 Error-Entropy 呈稳定幂律下降,Self-Alignment 和 Confidence 则基本不具备一致缩放规律。
>> 优势:
● 比原始 cross-entropy 更能拟合缩放行为:论文指出,Error-Entropy 的幂律拟合通常优于 cross-entropy 本身,说明它更接近"真正被缩放"的那一部分。
● 能解释小模型与大模型表现差异:作者用该分解解释了一个长期困惑:为什么 cross-entropy 在小模型上看起来很像幂律,但在大模型上会变差。答案在于,小模型里 Error-Entropy 占比高,而大模型中非缩放项占比上升。
● Error-Entropy 对采样策略更鲁棒:由于它只依赖 token 排名,不依赖具体概率值,因此对 temperature scaling、top-p sampling 等后处理不敏感,更适合做性能表征。
● 为训练目标设计提供直接启发:作者进一步提出可用降低 Confidence 权重的补偿损失,或者用 RL 风格的非可微目标来近似优化 Error-Entropy,为后续训练方法打开了新路径。
>> 论文的结论和观点(侧重经验与建议):
● cross-entropy 不是整体在缩放,而是内部某一项在缩放:论文的核心判断是,交叉熵中的 Error-Entropy 才是"真正会缩放"的部分,其他两项更多是在加入噪声或稀释整体规律。
● 大模型训练不要过度追逐 Confidence:作者经验上认为,随着模型变大,Confidence 在总损失中的占比会上升,但它与排名能力并不直接相关,因此当前训练可能过度强调了这一项。建议在训练目标里适度惩罚 Confidence,把优化重心拉回 Error-Entropy。
● rank 视角比概率视角更贴近"模型是否答对":论文强调,真正反映语言模型能力的不是某个 token 的绝对概率,而是正确 token 能否排到前面,因此用 rank-based error 更稳健、更接近实际性能。
● 中小模型上的经验规律不应直接外推到超大模型:作者认为,cross-entropy 在小规模上表现出的漂亮幂律,不能简单推断为大规模仍然成立;必须看组成项的比例变化,否则容易误判模型扩展趋势。
● Error-Entropy 可能连接语言模型与信息论学习:论文把 Error-Entropy 与信息论学习(ITL)中的 error entropy 联系起来,认为这可能为 LLM 训练目标和理论分析提供新的跨领域视角。
● 未来可尝试两类路线:一类是构造可微的替代损失,显式偏向 Error-Entropy;另一类是把 Error-Entropy 直接作为 RL 式奖励,绕开不可微问题,作为补充训练思路。
目录
[《What Scales in Cross-Entropy Scaling Law?》翻译与解读](#《What Scales in Cross-Entropy Scaling Law?》翻译与解读)
[What scales in cross-entropy scaling law?交叉熵缩放定律中的尺度是什么?](#What scales in cross-entropy scaling law?交叉熵缩放定律中的尺度是什么?)
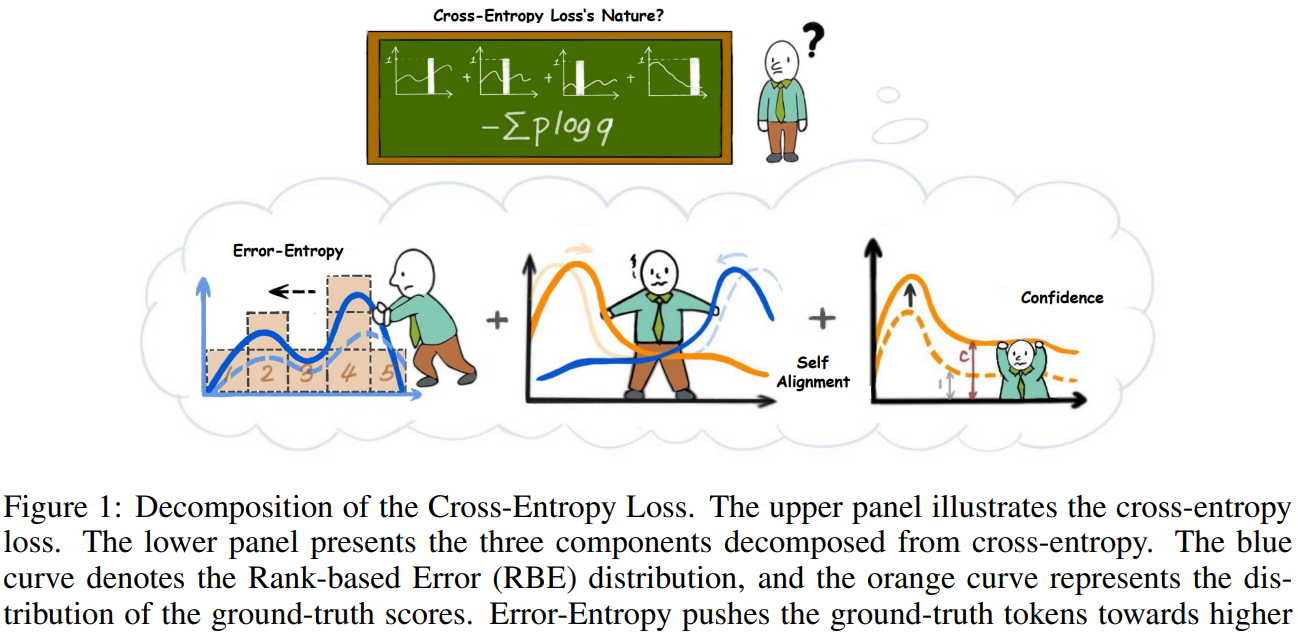
[Figure 1:Decomposition of the Cross-Entropy Loss. The upper panel illustrates the cross-entropy loss. The lower panel presents the three components decomposed from cross-entropy. The blue curve denotes the Rank-based Error (RBE) distribution, and the orange curve represents the distribution of the ground-truth scores. Error-Entropy pushes the ground-truth tokens towards higher ranks. Self-Alignment aligns the probability score distribution with RBE distribution. And Confidence term increases the norm of the probability score.图 1:交叉熵损失的分解。上图展示了交叉熵损失。下图呈现了从交叉熵分解出的三个组成部分。蓝色曲线表示基于排名的错误(RBE)分布,橙色曲线表示真实分数的分布。错误熵将真实标记推向更高的排名。自对齐使概率分数分布与 RBE 分布对齐。而置信度项增加了概率分数的范数。](#Figure 1:Decomposition of the Cross-Entropy Loss. The upper panel illustrates the cross-entropy loss. The lower panel presents the three components decomposed from cross-entropy. The blue curve denotes the Rank-based Error (RBE) distribution, and the orange curve represents the distribution of the ground-truth scores. Error-Entropy pushes the ground-truth tokens towards higher ranks. Self-Alignment aligns the probability score distribution with RBE distribution. And Confidence term increases the norm of the probability score.图 1:交叉熵损失的分解。上图展示了交叉熵损失。下图呈现了从交叉熵分解出的三个组成部分。蓝色曲线表示基于排名的错误(RBE)分布,橙色曲线表示真实分数的分布。错误熵将真实标记推向更高的排名。自对齐使概率分数分布与 RBE 分布对齐。而置信度项增加了概率分数的范数。)
[6 Conclusion](#6 Conclusion)
《What Scales in Cross-Entropy Scaling Law?》翻译与解读
|------------|--------------------------------------------------------------------------------------------------------------|
| 地址 | 论文地址:https://arxiv.org/abs/2510.04067 |
| 时间 | v1 2025 年 10 月 5 日 v2 2026 年 2 月 28 日 |
| 作者 | 清华大学 |
Abstract
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| The cross-entropy scaling law has long served as a key tool for guiding the development of large language models. It shows that cross-entropy loss decreases in a predictable power-law rate as the model size increases. However, recent evidence indicates that this law breaks down at very large scales: the loss decreases more slowly than expected, which causes significant trouble for developing large language models. In this paper, we hypothesize that the root cause lies in the fact that cross-entropy itself does not truly scale; instead, only one of its hidden components does. To investigate this, we introduce a novel decomposition of cross-entropy into three parts: Error-Entropy, Self-Alignment, and Confidence. We show both theoretically and empirically that this decomposition precisely captures the training dynamics and optimization objectives. Through extensive experiments on multiple datasets and 32 models spanning five orders of magnitude in size, we find that only error-entropy follows a robust power-law scaling, while the other two terms remain largely invariant. Moreover, error-entropy constitutes the dominant share of cross-entropy in small models but diminishes in proportion as models grow larger. This explains why the cross-entropy scaling law appears accurate at small scales but fails at very large ones. Our findings establish the error-entropy scaling law as a more accurate description of model behavior. We believe it will have wide applications in the training, understanding, and future development of large language models. | 交叉熵缩放定律 长期以来一直是指导大型语言模型开发的关键工具。它表明,随着模型规模的增大,交叉熵损失以可预测的幂律速率下降。然而,最近的证据表明,这一规律在非常大的规模下失效:损失下降的速度比预期的要慢,这给大型语言模型的开发带来了很大的麻烦。在本文中,我们假设根本原因在于交叉熵本身并不真正缩放;相反,只有其隐藏的组成部分之一会缩放。为了探究这一点,我们将交叉熵分解为三个部分:误差熵、自对齐和置信度。我们从理论上和实证上都表明,这种分解能够精确地捕捉训练动态和优化目标。通过在多个数据集和 32 个模型(规模跨越五个数量级)上进行的大量实验,我们发现只有误差熵遵循稳健的幂律缩放,而其他两个项则基本保持不变。此外,在小型模型中,误差熵在交叉熵中占主导地位,但随着模型规模的增大,其占比会逐渐降低。这解释了为何交叉熵缩放定律在小规模模型中看似准确,但在非常大规模的模型中却失效。我们的研究结果确立了误差熵缩放定律是对模型行为更准确的描述。我们相信它将在大型语言模型的训练、理解以及未来发展中得到广泛应用。 |
1、Introduction
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| The cross-entropy scaling law has played a vital role in the development of large language models. This empirical law states that as model size and dataset size increase, the cross-entropy loss decreases in a predictable power-law manner (Kaplan et al., 2020). Its influence is both practical and theoretical. On the practical side, it has become an indispensable tool for training large language models, such as balancing model parameters and data scale (Hoffmann et al., 2022), extrapolating performance from smaller models to larger ones (Wei et al., 2022a), and tuning training hyperparameters (Kadra et al., 2023; Li et al., 2025). On the theoretical side, it has opened a gateway for understanding the principles of intelligence itself. Researchers have proposed various theories to explain why such a law emerges (Bahri et al., 2024; Zhang, 2024; Michaud et al., 2024), hoping that these explanations will shed light on the nature of artificial intelligence. However, the cross-entropy scaling law has recently faced growing skepticism, both in practice and in theory. Practitioners have raised concerns about whether the law can continue to provide accurate predictions on larger scales. Empirical studies show that while cross-entropy decreases with an accurate power-law trend for small models, this trend becomes noticeably slower for very large models (Kaplan et al., 2020; Chen et al., 2025). On the theoretical side, the situation is equally unsettled. Although most existing theoretical frameworks can somehow prove the scaling law for error-based metrics, such as mean squared error (Lyu et al., 2025), they cannot directly generalize to cross-entropy loss. Thus, the theoretical foundation of this law is still unclear. These problems have fueled skepticism about whether cross-entropy truly scales, and in turn, they undermine confidence in scaling up models as a reliable path forward. | 交叉熵缩放定律在大型语言模型的发展中发挥了至关重要的作用。这一经验法则表明,随着模型规模和数据集规模的增大,交叉熵损失会以可预测的幂律方式降低(Kaplan 等人,2020 年)。其影响既具有实际意义,也具有理论意义。在实际应用方面,它已成为训练大型语言模型不可或缺的工具,例如平衡模型参数和数据规模(Hoffmann 等人,2022 年)、从小型模型推断出大型模型的性能(Wei 等人,2022a 年)以及调整训练超参数(Kadra 等人,2023 年;Li 等人,2025 年)。在理论方面,它为理解智能本身的原理开辟了道路。研究人员提出了各种理论来解释为何会出现这样的规律(Bahri 等人,2024 年;Zhang,2024 年;Michaud 等人,2024 年),希望这些解释能为人工智能的本质提供启示。 然而,交叉熵缩放定律最近在实践和理论层面都面临着越来越多的质疑。从业者们对这一规律能否在更大规模上继续提供准确预测表示担忧。实证研究表明,虽然对于小型模型而言,交叉熵会随着准确的幂律趋势而降低,但对于非常大的模型,这种趋势会明显变慢(Kaplan 等人,2020 年;Chen 等人,2025 年)。从理论角度来看,情况同样不明朗。尽管大多数现有的理论框架能够在某种程度上证明基于误差的指标(如均方误差)的缩放规律(Lyu 等人,2025 年),但它们无法直接推广到交叉熵损失。因此,这一规律的理论基础仍不明确。这些问题引发了人们对交叉熵是否真正缩放的怀疑,进而削弱了对扩大模型规模作为可靠前进道路的信心。 |
| In this work, we hypothesize that it is not cross-entropy loss itself that truly scales, but rather a dominant component hidden within it. This component gives the illusion that the cross-entropy itself follows a scaling law. Identifying this scaling component would therefore be of significant value. On the practical side, it would provide a more reliable law to guide the development of large language models. On the theoretical side, it could offer a better objective for investigating the principles of artificial intelligence. Motivated by this, the research question of this paper is: To address this question, we begin by introducing a novel decomposition of cross-entropy. Specifically, we propose an error-based metric rooted in ranking, termed Rank-based Error (RBE). Unlike cross-entropy, which measures the probability score of the correct token, RBE equals the rank of the correct token. For example, if four other tokens are scored higher than the ground truth, then the RBE is 4. Building on this notion, we decompose cross-entropy exactly into the sum of three terms: Error-Entropy, Self-Alignment, and Confidence, which is illustrated in Fig. 1. Among them, Error-Entropy measures the entropy of the RBE distribution. Minimizing this quantity effectively pushes the correct token toward higher ranks and thus makes the model's predictions more accurate. The other two terms characterize how the model aligns probability scores with the RBE distribution. Through both qualitative and quantitative analysis, we demonstrate that this decomposition accurately reflects the training dynamics of language models. | 在本研究中,我们假设真正缩放的并非交叉熵损失本身,而是隐藏在其内部的一个主导成分。正是这一成分造成了交叉熵本身遵循缩放规律的错觉。因此,识别这一缩放成分将具有重要意义。从实际角度来看,它将为大型语言模型的发展提供更可靠的指导法则。从理论角度来看,它能为探究人工智能原理提供更好的目标。受此启发,本文的研究问题是: 为了解决这个问题,我们首先引入了一种新的交叉熵分解方法。具体来说,我们提出了一种基于排序的误差度量,称为基于排名的误差(RBE)。与交叉熵不同,交叉熵衡量的是正确标记的概率得分,而 RBE 等于正确标记的排名。例如,如果其他四个标记的得分高于真实值,那么 RBE 就是 4。基于这一概念,我们精确地将交叉熵分解为三个项的总和:误差熵、自对齐和置信度,如图 1 所示。其中,误差熵衡量的是 RBE 分布的熵。最小化这一量值能有效地将正确标记推向更高的排名,从而使模型的预测更准确。另外两项则表征了模型如何将概率得分与 RBE 分布对齐。通过定性和定量分析,我们发现误差熵和自对齐项在模型训练过程中起着关键作用,而置信度项则对模型的泛化能力有影响。此外,我们还发现 RBE 能够更好地解释模型的预测错误,从而为模型的改进提供了新的视角。 |
| Building on this decomposition, we investigate the scaling behavior of these components and find that only Error-Entropy truly scales. We refer to it as the Error-Entropy Scaling Law. Concretely, we conduct experiments on multiple real-world language datasets using 32 models spanning five orders of magnitude in size. 1 We then evaluate the scaling behavior of cross-entropy alongside its three components. The results are clear. (1) Error-Entropy decreases according to a power law with model size, whereas the other two terms remain random for different model sizes. (2) The power-law fit of Error-Entropy is even better than that of cross-entropy. It indicates that the Error-Entropy scaling law is potentially the reason why cross-entropy approximately exhibits scaling behavior. We believe that our decomposition of cross-entropy and the discovery of the Error-Entropy scaling law provide a better description of how language models actually scale, and open the door to broad applications. As one example, this framework helps resolve a long-standing puzzle (Kaplan et al., 2020; Chen et al., 2025): why does the cross-entropy scaling law appear accurate for small models but break down for larger ones? The answer lies in the proportion of Error-Entropy. It dominates in small models, making cross-entropy follow a clean power law, but its declining share in larger models allows non-scaling terms to dominate, breaking the law. This specific example highlights how Error-Entropy can sharpen our understanding of model behavior. More broadly, we expect that it will have wide-ranging implications, such as guiding the design and training of large language models, probing model mechanisms, and finding fundamental theories of artificial intelligence. | 在此分解的基础上,我们研究了这些组成部分的缩放行为,发现只有误差熵真正具有缩放性。我们将其称为误差熵缩放定律。具体而言,我们在多个真实世界的语言数据集上使用了 32 个模型,这些模型的规模跨越了五个数量级。然后,我们评估了交叉熵及其三个组成部分的缩放行为。结果清晰明了。(1)误差熵随着模型规模的增大呈幂律下降,而其他两个项对于不同规模的模型则保持随机。(2)误差熵的幂律拟合甚至比交叉熵更好。这表明误差熵缩放定律可能是交叉熵近似表现出缩放行为的原因。 我们认为,我们对交叉熵的分解以及误差熵缩放定律的发现,为语言模型的实际缩放行为提供了更好的描述,并为广泛的应用打开了大门。以一个例子来说,这个框架有助于解决一个长期存在的谜题(Kaplan 等人,2020 年;Chen 等人,2025 年):为什么交叉熵缩放定律在小型模型中看起来准确,但在大型模型中却失效?答案在于误差熵的比例。它在小型模型中占主导地位,使得交叉熵遵循清晰的幂律,但在大型模型中其份额下降,使得非缩放项占主导地位,从而打破了该定律。这个具体的例子突显了误差熵如何能加深我们对模型行为的理解。更广泛地说,我们预计它将产生广泛的影响,例如指导大型语言模型的设计和训练、探究模型机制以及寻找人工智能的基本理论。 |
What scales in cross-entropy scaling law?交叉熵缩放定律中的尺度是什么?
Figure 1:Decomposition of the Cross-Entropy Loss. The upper panel illustrates the cross-entropy loss. The lower panel presents the three components decomposed from cross-entropy. The blue curve denotes the Rank-based Error (RBE) distribution, and the orange curve represents the distribution of the ground-truth scores. Error-Entropy pushes the ground-truth tokens towards higher ranks. Self-Alignment aligns the probability score distribution with RBE distribution. And Confidence term increases the norm of the probability score. 图 1:交叉熵损失的分解。上图展示了交叉熵损失。下图呈现了从交叉熵分解出的三个组成部分。蓝色曲线表示基于排名的错误(RBE)分布,橙色曲线表示真实分数的分布。错误熵将真实标记推向更高的排名。自对齐使概率分数分布与 RBE 分布对齐。而置信度项增加了概率分数的范数。
6 Conclusion
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| In this paper, we propose a mathematical decomposition of the cross-entropy loss and conduct wide-ranged experiments to find out the truly scaled component. Results show that our decomposition clearly characterizes model behavior during training. Based on our decomposition, we find that Error-Entropy is the truly scaled part hidden within cross-entropy, while the other two components do not scale. The proposed decomposition and new scaling law provide a novel perspective to understand model behavior, such as how models assign probability scores and why the rate of cross-entropy scaling slows down. We believe they will facilitate a more fundamental understanding of model mechanics and may enable new training paradigms in the future. | 在本文中,我们提出了交叉熵损失的数学分解,并进行了广泛的实验以找出真正可缩放的成分。结果表明,我们的分解清晰地刻画了模型在训练过程中的行为。基于我们的分解,我们发现误差熵是隐藏在交叉熵中的真正可缩放部分,而其他两个部分则不可缩放。所提出的分解和新的缩放规律为理解模型行为提供了新的视角,例如模型如何分配概率分数以及交叉熵缩放速度减慢的原因。我们相信,它们将有助于更深入地理解模型机制,并可能在未来促成新的训练范式。 |