小记:这几天时间,一有空就拿起电脑库库码字中,距离上一篇发布也没隔很久好像🤔...不知不觉中,已经码了两万多字,其实当时码完组合数据类型就在考虑要不要拆开,后面想想,算了,就剩个文件读写,应该不会太长,没想到也花了一些时间🤯,不过还行,在预期时间内完成了基础的学习,接下来(搓搓手😎),准备再次尝试......
组合数据类型
分类
| 类别 | 具体类型 | 核心特征 |
|---|---|---|
| 序列类型 | 字符串(str)列表 (list)、元组 (tuple) | 有序(可通过索引访问),允许重复元素;列表可变,元组不可变 |
| 集合类型 | 集合 (set)、冻结集合 (frozenset) | 无序(无索引),不允许重复元素;集合可变,冻结集合不可变 |
| 映射类型 | 字典 (dict) | 以 "键值对(key:value)" 存储,key 唯一且不可变;3.7 后默认按插入顺序保存 |
列表
列表是有序可变序列 ,是若干元素的有序连续内存空间,元素可以是各种类型对象,列表中元素可以重复出现。所有元素放在一对方括号"\[\]"中,相邻元素之间用逗号分隔。
列表的创建与删除
python
# 创建
# 通过赋值语句创建
a_list=[1,2.0,[3,4],'hello']
b_list=[] # 空列表
print(a_list)
print(b_list)
# 调用list函数创建
a_list=list("hello")
b_list=list() # 空列表
print(a_list)
print(b_list)
'''
out:
[1, 2.0, [3, 4], 'hello']
[]
['h', 'e', 'l', 'l', 'o']
[]
'''
# 删除
del a_list
del b_list列表的基本操作
列表元素获取
python
# 通过赋值语句创建
a_list=[1,2.0,[3,4],'hello']
# 列表元素获取(当索引越界时会报错)
print(a_list[0])
# print(a_list[100]) # 越界报错: IndexError: list index out of range
# 列表的切片(与之前字符串的切片一样)
print(a_list[-100:200:1])
'''
out:
1
[1, 2.0, [3, 4], 'hello']
'''遍历列表元素
python
a_list=[1,2.0,[3,4],'hello']
# 直接遍历列表元素
for a in a_list:
print(a,end=" ")
print()
# 通过len函数计算列表长度,利用索引遍历元素
for i in range(0, len(a_list)):
print(a_list[i],end=" ")
'''
out:
1 2.0 [3, 4] hello
1 2.0 [3, 4] hello
'''- 列表元素修改
python
a_list=[1,2.0,[3,4],'hello']
# 利用索引修改元素
a_list[0]=10
print(a_list)
a_list[0]=10,"hello" # 只能是一个元素,因此会自动将它们变成一个元组
print(a_list)
# 通过切片操作批量修改元素
a_list[0:2]=[100,[2,3,4],'hello'] # 列表长度改变
print(a_list)
'''
out:
[10, 2.0, [3, 4], 'hello']
[(10, 'hello'), 2.0, [3, 4], 'hello']
[100, [2, 3, 4], 'hello', [3, 4], 'hello']
'''注意:切片赋值的本质是删除切片选中的所有元素,再把新的元素序列插入到该位置 ,而非 "一对一替换",因此,如果赋值的元素数量和切片选中的元素数量不一致,列表长度会被调整。
列表元素添加
python
a_list=[1,2.0,[3,4],'hello']
# append函数向列表末尾添加'一个'新元素
a_list.append((10,"hello"))
# a_list.append((10,"hello"), 20) 报错,明确只能添加一个元素
print(a_list)
# 使用extend函数向列表末尾添加'一个'可迭代对象中的所有元素
a_list.extend([100,[2,3,4],'hello'])
print(a_list)
# insert函数向列表指定索引位置添加'一个'新元素
a_list.insert(1,"insert")
print(a_list)
'''
out:
[1, 2.0, [3, 4], 'hello', (10, 'hello')]
[1, 2.0, [3, 4], 'hello', (10, 'hello'), 100, [2, 3, 4], 'hello']
[1, 'insert', 2.0, [3, 4], 'hello', (10, 'hello'), 100, [2, 3, 4], 'hello']
'''Python 中 "可迭代对象" 是指可以逐个取出元素的对象,常见的包括:列表(list)、元组(tuple)、集合(set)、字典(dict)、字符串(str)、range 对象等
列表元素随机排序
python
a_list=[1,2.0,[3,4],'hello']
# 通过random库中的shuffle函数可以实现打乱列表元素的顺序
import random
random.shuffle(a_list)
print(a_list)
'''
out:
[1, [3, 4], 'hello', 2.0]
'''注意:shuffle函数是在原列表的基础上操作的,并不会生成新的列表。
列表元素删除
python
a_list=[1,2.0,[3,4],'hello']
a_list.extend(a_list) # 扩大列表元素,方便演示
# 通过del删除指定索引处的元素
del a_list[0]
print(a_list)
# 使用pop方法删除并返回指定位置的列表元素,默认删除最后一个元素,越界抛异常
last_item=a_list.pop()
print(last_item)
print(a_list)
# 使用remove方法删除首次出现的指定元素,不存在则抛异常
a_list.remove(2.0)
print(a_list)
# 使用切片删除多个元素
a_list[0:2]=[]
print(a_list)
# 使用clear方法清空列表元素
a_list.clear()
print(a_list)
'''
out:
[2.0, [3, 4], 'hello', 1, 2.0, [3, 4], 'hello']
hello
[2.0, [3, 4], 'hello', 1, 2.0, [3, 4]]
[[3, 4], 'hello', 1, 2.0, [3, 4]]
[1, 2.0, [3, 4]]
[]
'''注意:当增加或者删除列表元素时,列表对象会自动进行内存扩展或收缩,从而保证元素之间没有间隙。
列表操作符
标准操作符
- 用于对象值比较 的关系运算符:>、<、>=、<=、==、!=。规则:列表比较的大前提是对应位置的元素必须是可比较类型(如数字、字符串、同类型容器)。先逐元素比(通过比较它们的unicode编码值,再比较长度)。
- 用于对象同一性测试的身份运算符: is和is not。
- 逻辑运算符:not、and、or
注意:元素类型必须可比较;== 比内容,is 比地址。
序列专用操作符
python
# 使用连接操作符+两边的对象必须是属于同一数据类型
a_list=[1,2.0,[3,4],'hello']
b_list=a_list
print(a_list + b_list)
# 使用重复操作符*
a_list=[1,2.0,[3,4],'hello']
b_list = a_list * 3
print(a_list)
print(b_list)
# 成员测试服in用于判断一个对象是否是给定序列对象中的元素
print("hello" in a_list)
'''
out:
[1, 2.0, [3, 4], 'hello', 1, 2.0, [3, 4], 'hello']
[1, 2.0, [3, 4], 'hello']
[1, 2.0, [3, 4], 'hello', 1, 2.0, [3, 4], 'hello', 1, 2.0, [3, 4], 'hello']
True
'''列表常用函数
列表常用函数也基本适用于元组和字符串,调用形式为<函数名>(参数列表)
- len()函数:返回列表元素个数
- max()、min()、sum()函数:分别用于求元素最大值、最小值,以及所有元素求和
python
a_list=['a','b','c','A','B','C','ba']
print(min(a_list))
print(max(a_list))
print(sum(range(1,11)))
'''
out:
A
c
55
'''- list()、tuple()函数:接受可迭代对象作为参数,list将可迭代对象转换为列表,tuple将可迭代对象转换为元组
- zip()函数:接受可迭代对象作为参数,将其中对应的元素打包生成一个元组元素,并返回由这些元组元素组成的zip对象。注意:当两个列表中元素个数不相等时,舍弃多余元素
python
a_list=['a','b','c','A','B','C','ba']
b_list=[1,2,3,4]
c_list=zip(a_list,b_list)
print(c_list)
print(list(c_list))
'''
out:
<zip object at 0x0000027BA078EBC0>
[('a', 1), ('b', 2), ('c', 3), ('A', 4)]
'''- enumerate()函数:将一个可迭代对象组合为一个数据对的序列,每个数据对表示为索引和数据值的元组
python
a_list=[1,2,3,4]
for i in enumerate(a_list):
print(i,end=" ")
'''
out:
(0, 1) (1, 2) (2, 3) (3, 4)
'''- sorted()函数:接受一个可迭代对象,将元素按正序(也叫升序,默认:reverse=False)或逆序排列,返回一个排序后的新列表,不改变原列表元素排序顺序
python
a_list=[1,3,2,4]
print(sorted(a_list))
print(sorted(a_list, reverse=True))
print(sorted("hello", reverse=False))
'''
out:
[1, 2, 3, 4]
[4, 3, 2, 1]
['e', 'h', 'l', 'l', 'o']
'''- reversed()函数:接受一个可迭代对象,返回一个反向遍历的迭代器对象,可利用此迭代器对象遍历其中元素,只能遍历一次,如果需要再次查看迭代器内容,需要重新创建该迭代器对象。不改变原对象元素排序顺序
python
a_list=[1,3,2,4]
b_reversed=reversed(a_list)
print(b_reversed)
for i in b_reversed:
print(i,end=" ")
print()
print(list(b_reversed))
# list.reverse()虽然也是反向遍历,但是它是直接反转原列表顺序,修改的是原列表(后面会讲到,先提一嘴)
a_list.reverse()
print(a_list)
'''
out:
<list_reverseiterator object at 0x000001D91A5E8E20>
4 2 3 1
[]
[4, 2, 3, 1]
'''列表常用方法
调用形式:列表对象.<方法名>(参数列表)
- count()方法:统计指定元素在列表中出现的次数
- index()方法:返回指定元素在列表中首次出现的索引,不存在则抛出异常
- sort()方法:按照指定规则原地对列表进行排序,默认升序排列
python
a_list=[1,2.0,3,'hello', 'x', 1]
b_list=[1,2,13,4,15]
# count统计元素出现次数
print(a_list.count(1))
print(a_list.count(5))
# index获取元素第一次出现索引
print(a_list.index("hello"))
# sort对元素进行排序
import random
random.shuffle(b_list)
print("b_list=",b_list)
b_list.sort(reverse=True) # 降序排序,默认为False:升序
print("降序排序=",b_list)
# 自定义比较规则
print("a_list=",a_list) # a_list中元素类型不同,因此不能直接通过sort进行排序,必须自定义比较规则
a_list.sort(key=lambda x: len(str(x))) # x表示列表的每一个元素,将x转为字符串,根据字符串的长度进行比较
print("根据字符串的长度进行比较=",a_list)
a_list.sort(key=lambda x: str(x)) # 根据字符串进行比较,比较字符串的每一个字符的Unicode编码大小来决定
print("根据字符串进行比较=",a_list)
a_list.sort(key=str) # 根据字符串进行比较,与上面是等价的
print("根据字符串进行比较=",a_list)
'''
out:
2
0
3
b_list= [1, 15, 13, 4, 2]
降序排序= [15, 13, 4, 2, 1]
a_list= [1, 2.0, 3, 'hello', 'x', 1]
根据字符串的长度进行比较= [1, 3, 'x', 1, 2.0, 'hello']
根据字符串进行比较= [1, 1, 2.0, 3, 'hello', 'x']
根据字符串进行比较= [1, 1, 2.0, 3, 'hello', 'x']
'''注意:sort()方法和内置函数sorted()均可对列表进行排序,区别是sort是原地排序,即修改原列表元素顺序,而sorted是返回新排序的列表,不会修改原列表元素顺序。
- reverse()方法:原地反向排列列表元素,与之前的reversed()函数类型,不同的是reverse是原地反向排序,原列表顺序改变,而reversed()则是返回一个反向遍历的迭代器对象,并不修改原列表顺序
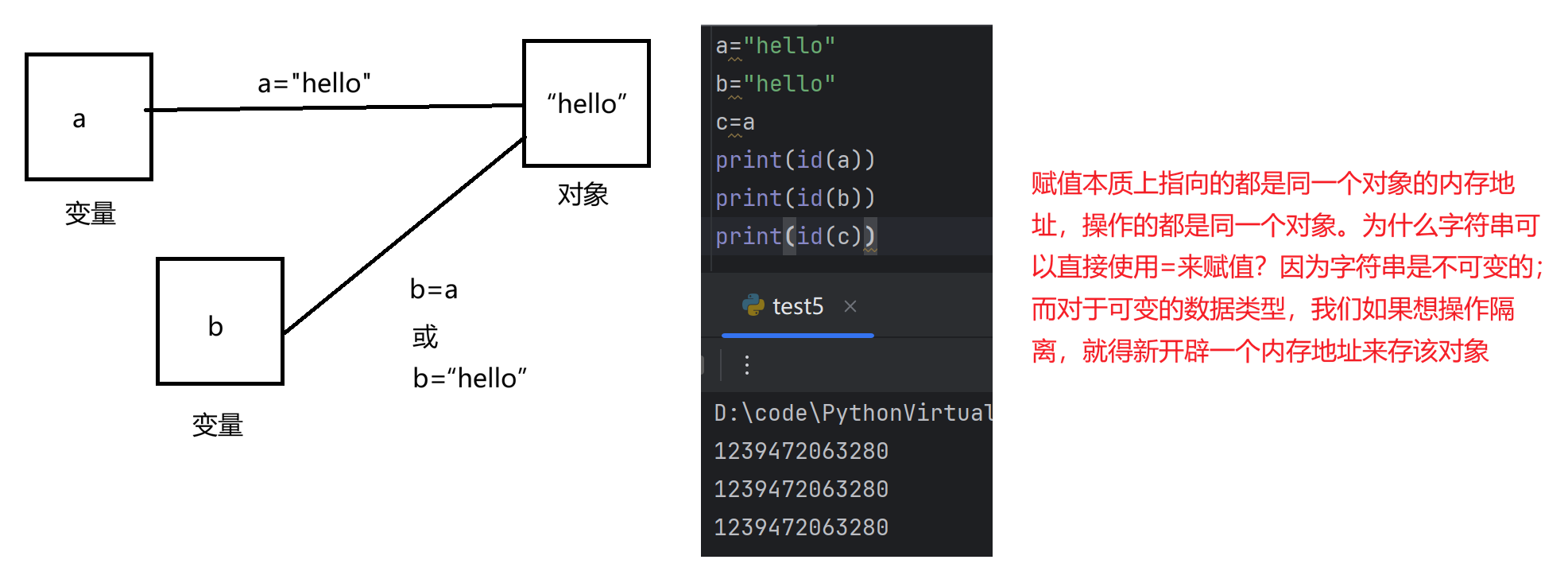
- copy()方法:复制列表中的所有元素,生成一个新列表(注意:直接使用=进行赋值,本质是给对象起了一个别名,多个变量同时指向同一个对象)
python
a_list=[1,2.0,3,'hello', 'x', 1]
b_list=a_list # 指向同一个内存地址
c_list=a_list.copy() # 重新开辟一块内存地址,存的内容与a_list一致
d_list=[1,2.0,3,'hello', 'x', 1] # 与copy效果一致
print(id(a_list))
print(id(b_list))
print(id(c_list))
print(id(d_list))
'''
out:
2179211383040
2179211383040
2179211384896
2179211549504
'''这里可能就有疑问了,为什么上面字符串a="hello",b="hello"它们指向的内存地址一致,但是,对于列表a=1,2,3,b=1,2,3它们的内存地址为什么又不一致了?
从可变与不可变角度出发,对于不可变类型,只有整数,字符串有缓存池 ,每次赋值会先查看是否有缓存,如果有则直接复用,没有则新建。需要特别注意的是,其他不可变类型都没有缓存池,仅小整数(-5~256)、简单字面量字符串会被缓存复用,浮点数、元组、大整数等均无此机制,因为缓存的目的是节省内存 + 提升效率,不可变对象无法被修改,复用同一个对象完全无风险,所以对使用频率高、值范围小的不可变类型(如小整数、简单字符串)做缓存,性价比很高。而可变类型(列表、字典等)则无任何缓存,每次创建都是全新对象,保证独立性。
元组
元组是有序不可变序列 ,一旦创建元组就不允许改变其中元素的值,也无法为元组增加或删除元素。元组的元素可以是各种类型对象,元素可以重复出现。所有元素放在一对方括号"()"中,相邻元素之间用逗号分隔。
元组的创建与删除
python
# 使用赋值语句创建
a_tuple=(1,2.0,"word",print(5),False,(1,2),[1,2,3],{'a':1,'b':2,'c':3})
print(a_tuple)
# 创建一个元素的元组
b_tuple=(1,)
print(b_tuple)
# 使用非空元组时,一对原括号可以省略,python将一组用逗号分隔的数据自动默认为元组
b_tuple=1,
print(b_tuple)
b_tuple=1,2,3
print(b_tuple)
# 创建一个空元组
c_tuple=()
print(c_tuple)
# 使用tuple函数创建:可将一个可迭代对象转换为元组
d_tuple=tuple(range(1,5))
print(d_tuple)
# 删除元组
del d_tuple
# print(d_tuple) #报错
'''
out:
5
(1, 2.0, 'word', None, False, (1, 2), [1, 2, 3], {'a': 1, 'b': 2, 'c': 3})
(1,)
(1,)
(1, 2, 3)
()
(1, 2, 3, 4)
'''元组与列表的区别
- 列表可变,有针对部分元素的增删改操作;元组不可变,即数据一旦定义就不允许通过任何方式改变;
- 都属于有序序列,支持双向索引与切片操作,支持运算符等操作;
- 元组与列表可相互转换,通过tuple函数可将一个可迭代对象转为元组,通过list函数可将一个可迭代对象转为列表;
- 元组可看成是被冻结、锁住的列表,是不可改变的,它的访问和处理速度以及安全性比列表更好;
- 作为不可变序列,元组可以作为字典的键,也可以作为集合的元素,而列表是可变序列,不可以作为字典的键,列表或包含列表的元组也不可以作为集合的元素。
对于5,为什么?
这是因为字典和集合(set)的底层都是基于哈希表实现的,哈希表的核心要求是:
- 每个元素/键必须能通过
hash()函数生成一个固定不变的哈希值;- 通过哈希值快速定位元素位置,保证查询效率。
而可变对象的哈希值会随内容修改而变化 ,这会导致哈希表无法快速定位这个元素,破坏哈希表的核心逻辑。因此python规定:不可变且哈希值固定的对象才能作为字典键/集合的元素。
注意:如果元组的元素是可变序列,那么该元素仍然可以修改
pythona_tuple=(1,2.0,"word",print(5),False,(1,2),[1,2,3],{'a':1,'b':2,'c':3}) print(a_tuple) a_tuple[6][:]=[11,22,33,44,55,66] # a_tuple[6]表示取到索引为6的元素,即上面的列表,如果此时直接赋值是不可行的;但由于该元素是列表,因为列表是可变的,因此,对该元素使用切片[:]进行修改是可行的 print(a_tuple) ''' out: 5 (1, 2.0, 'word', None, False, (1, 2), [1, 2, 3], {'a': 1, 'b': 2, 'c': 3}) (1, 2.0, 'word', None, False, (1, 2), [11, 22, 33, 44, 55, 66], {'a': 1, 'b': 2, 'c': 3}) '''
字典
字典是一种典型的映射类型,由若干键值对元素构成的无序可变 组合数据类型,其每个元素由"键(key): 值(value)"构成,通过键数据找值数据。其中,键要求是任意不可变数据类型,即键必须是唯一,不重复,无法修改的;而值是可变、可重复、可修改的任意数据对象。所有元素放在一对花括号"{}"中,相邻元素之间用逗号分隔。
字典的创建与删除
python
# 使用赋值语句创建
a_dict = {'a':1, 'b':2, 'c':3, 'd':4, 'e':5}
print(a_dict)
# 使用dict函数创建
keys=['a', 'b', 'c', 'd', 'e']
values=[1,2,3,4]
# 打印zip查看生成的键值对对象
for i in zip(keys, values):
print(i,end=" ")
print()
a_dict=dict(zip(keys, values))
print(a_dict)
a_dict=dict(name='John', age=20, city='San Francisco')
print(a_dict)
# 创建一个空字典
b_dict={}
print(b_dict)
b_dict=dict()
print(b_dict)
# 使用dict.fromkeys()方法创建一个具有相同值的字典,如果没有给出字典值,默认为空
c_dict=dict.fromkeys(['a', 'b', 'c', 'd', 'e'],18)
print(c_dict)
# 删除元组
del c_dict
'''
out:
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
('a', 1) ('b', 2) ('c', 3) ('d', 4)
{'a': 1, 'b': 2, 'c': 3, 'd': 4}
{'name': 'John', 'age': 20, 'city': 'San Francisco'}
{}
{}
{'a': 18, 'b': 18, 'c': 18, 'd': 18, 'e': 18}
'''为什么使用dict函数创建字典时,需要zip函数辅助?
dict()函数仅支持关键字参数(比如:name="张三", ...)或键值对可迭代对象(比如:("name", "张三"), ...),不直接支持分开的键列表 + 值列表来创建字典,而zip函数的作用就是将两个独立序列根据位置转换为键值对可迭代对象。对于zip函数,需要注意的是它会以较短的序列为准,截断较长的序列。
字典的基本操作
字典元素获取
python
a_dict = {'a':1, 'b':2, 'c':3, 'd':4, 'e':5}
# 以键为索引获取字典的值,如果键不存在则报错
print(a_dict['a'])
# 使用get方法获取指定键的元素值,如果键不存在可返回参数指定的值,若省略该值则不返回
print(a_dict.get('a'))
print(a_dict.get('x', 'not exist'))
print(a_dict.get('x')) # 不返回数据,之前也说过,程序默认返回 None
'''
out:
1
1
not exist
None
'''字典元素的遍历
python
a_dict = {'a':1, 'b':2, 'c':3, 'd':4, 'e':5}
# 通过keys方法可以获得字典的键列表
keys=a_dict.keys()
print(keys)
# 通过values方法可以获得字典的值列表
values=a_dict.values()
print(values)
# 通过items方法可以获得字典的键值对列表
key_val=a_dict.items()
print(key_val)
# 迭代遍历字典时,默认遍历的是字典的键,如果需要遍历字典值或键值对则需要使用values和items
for k in a_dict:
print(k,end=" ")
print()
for v in a_dict.values():
print(v,end=" ")
'''
out:
dict_keys(['a', 'b', 'c', 'd', 'e'])
dict_values([1, 2, 3, 4, 5])
dict_items([('a', 1), ('b', 2), ('c', 3), ('d', 4), ('e', 5)])
a b c d e
1 2 3 4 5
'''像len()、max()、min()、sum()、sorted()、enumerate()、map()、filter()等内置函数以及测试运算符in对字典对象操作时,默认情况下都是作用于字典的键
字典元素的添加与修改
python
a_dict = {'a':1, 'b':2, 'c':3, 'd':4, 'e':5}
b_dict = {'b':1, 'f':2, 'g':3, 'h':4}
# 通过指定key为字典元素赋值
a_dict[6]='A' # 当key不存在时为添加
print(a_dict)
a_dict['a']=11 # 当key存在时为修改
print(a_dict)
# 通过update方法添加、修改字典:update方法将参数中另一个字典的键值对全部添加到当前字典对象中,如果存在相同key则修改
a_dict.update(b_dict)
print(a_dict)
# 通过setdefault方法添加字典元素:如果指定键存在则返回对应值,如果不存在则将参数作为键和值添加到字典中,然后返回它的值
print(a_dict.setdefault('a'))
print(a_dict)
print(a_dict.setdefault(88, 'new add')) # 将参数分别作为键和值加入到字典中并返回值
print(a_dict)
print(a_dict.setdefault(100)) # 没有给值,默认为None
print(a_dict)
'''
out:
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 6: 'A'}
{'a': 11, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 6: 'A'}
{'a': 11, 'b': 1, 'c': 3, 'd': 4, 'e': 5, 6: 'A', 'f': 2, 'g': 3, 'h': 4}
11
{'a': 11, 'b': 1, 'c': 3, 'd': 4, 'e': 5, 6: 'A', 'f': 2, 'g': 3, 'h': 4}
new add
{'a': 11, 'b': 1, 'c': 3, 'd': 4, 'e': 5, 6: 'A', 'f': 2, 'g': 3, 'h': 4, 88: 'new add'}
None
{'a': 11, 'b': 1, 'c': 3, 'd': 4, 'e': 5, 6: 'A', 'f': 2, 'g': 3, 'h': 4, 88: 'new add', 100: None}
'''字典元素的删除
python
a_dict = {'a':1, 'b':2, 'c':3, 'd':4, 'e':5, 'f':2, 'g':3, 'h':4}
# 通过del删除指定键对应的元素
del a_dict['a']
print(a_dict)
# 通过pop方法删除指定键的元素并返回键对应的值
del_item_val=a_dict.pop('b') # 返回key对应的val
print(del_item_val)
print(a_dict)
del_item_val=a_dict.pop('c','not exist') # 弹出并返回键对应的值
print(del_item_val)
print(a_dict)
del_item_val=a_dict.pop('x','not exist') # 如果键不存在,则返回指出参数值,否则返回None
print(del_item_val)
print(a_dict)
# 通过popitem方法删除字典的一个键值对并返回包含该删除的键值对的元组
# 注意:Python 3.7+ 中,dict.popitem() 遵循*后进先出*,删除最后插入的键值对;Python 3.6 及更早版本,popitem() 随机删除,无固定顺序;
del_tuple=a_dict.popitem()
print(del_tuple)
print(a_dict)
# 使用clear清空字典
a_dict.clear()
print(a_dict)
'''
out:
{'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 2, 'g': 3, 'h': 4}
2
{'c': 3, 'd': 4, 'e': 5, 'f': 2, 'g': 3, 'h': 4}
3
{'d': 4, 'e': 5, 'f': 2, 'g': 3, 'h': 4}
not exist
{'d': 4, 'e': 5, 'f': 2, 'g': 3, 'h': 4}
('h', 4)
{'d': 4, 'e': 5, 'f': 2, 'g': 3}
{}
'''集合
集合是无序可变 的容器对象,元素存储顺序与添加顺序不一致,不支持索引访问,同一个集合的元素不允许重复 ,集合中每一个元素是唯一的,**元素只能是数字、字符串、元组等不可变类型数据,**所有元素放在一对花括号"{}"中,相邻元素之间用逗号分隔。
集合的创建和删除
python
# 使用赋值语句直接创建
a_set={1,2,3,4,5,6,7,8,9}
print(type(a_set))
print(a_set)
# 使用set函数创建:接受一个可迭代对象参数,将其转换为集合(字典默认操作的是key,会自动去除重复元素)
a_set=set([1,1,'a',(1,2)])
print(a_set)
a_set=set({1:'a',2:'b'})
print(a_set)
a_set=set("hello world")
print(a_set)
# a_set=set([1,1,'a',[1,2]]) # 如果可迭代对象中含有可变类型对象,则转换失败抛出异常
# 注意:直接使用{}创建的是空字典而不是空集合
b_set={}
print(type(b_set))
# 创建空集合可以使用set函数
b_set=set()
print(type(b_set))
# 删除集合
del b_set
'''
out:
<class 'set'>
{1, 2, 3, 4, 5, 6, 7, 8, 9}
{1, 'a', (1, 2)}
{1, 2}
{'w', 'l', ' ', 'o', 'd', 'e', 'h', 'r'}
<class 'dict'>
<class 'set'>
'''集合的基本操作
集合的运算
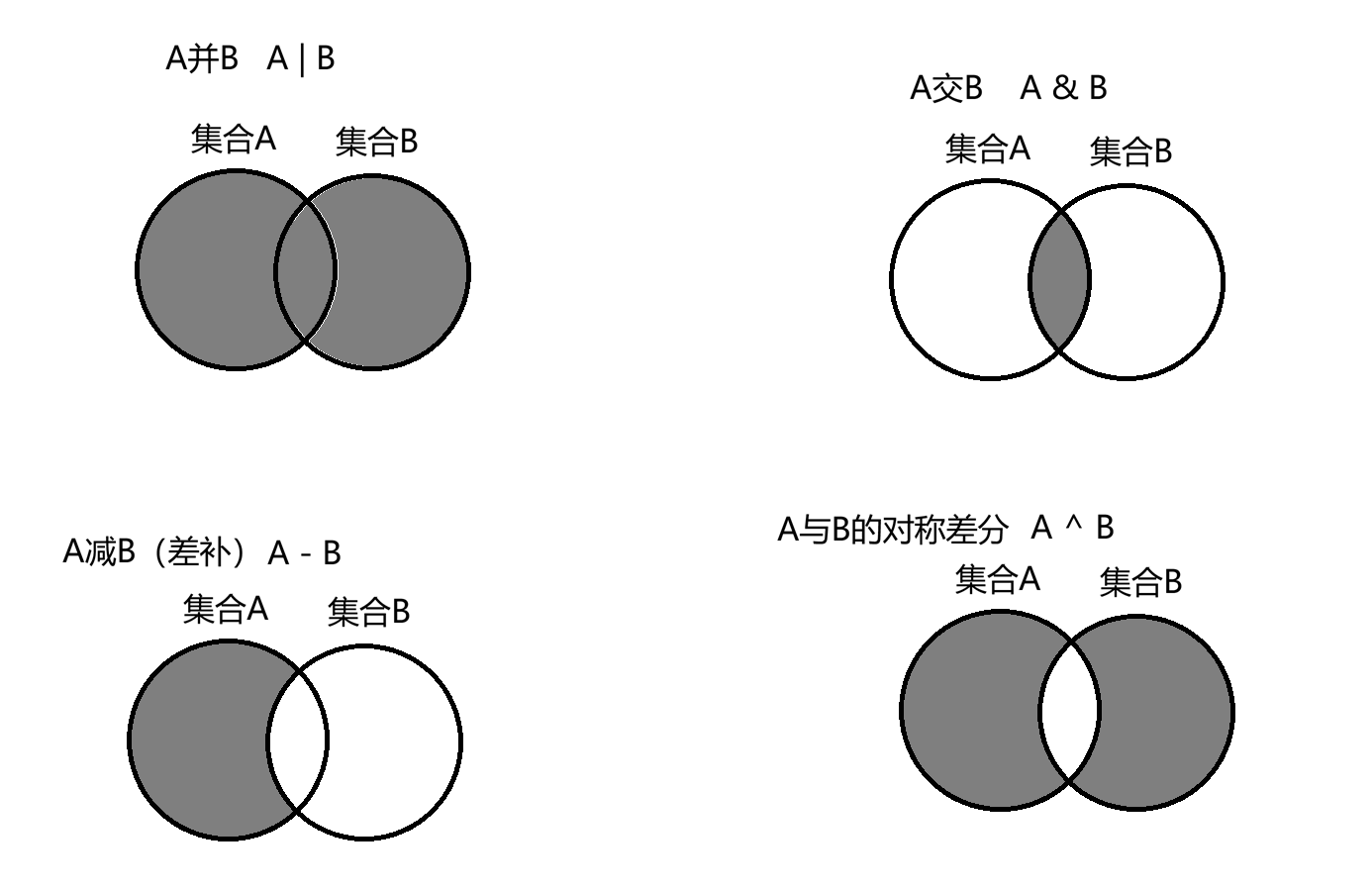
主要包括并(|)、交(&)、差补(-)、对称差分(^)、相等(==)、不相等(!=)、子集(>= or <=)、真子集(> or <)等,还有成员测试运算符 in 和 not in。
A并B(A | B):把两个集合合在一起,去重;
A交B(A & B):两个集合相同的部分;
A减B(A - B):A集合中独有的部分;
A与B的对称差分(A ^ B):A和B双方独有的部分;
A等于B(A == B):两个集合的元素、大小都相等;
A不等于B(A != B):两个集合的元素或大小不相等;
A是B的子集(A <= B or B >= A):A中的所有元素都在B中,包括B本身;
A是B的真子集(A < B or B > A):A中的所有元素都在B中,不包括B本身。
python
a_set={1,2,3,4,5,6,7,8,9}
b_set={1,2,3,4,5,6,7,8,10}
c_set={1,2,3,4,5,6,7,8}
d_set={1,3,4,5,6,7,8,2}
print(a_set|b_set) # 并:{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
print(a_set&b_set) # 交:{1, 2, 3, 4, 5, 6, 7, 8}
print(a_set-b_set) # 差补:{9}
print(a_set^b_set) # 对称差分:{9, 10}
print(a_set!=b_set) # 不相等:True
print(c_set==d_set) # 相等:True
print(c_set>=d_set) # 子集:True(包括自己)
print(a_set>=d_set) # 子集:True
print(a_set>d_set) # 真子集:True
print(c_set>d_set) # 真子集:False集合元素的添加与删除
python
a_set={2,3,4,5,6,7,8,9,1}
b_set={1,2,3,4,5,11,22,33,44,55}
# 使用add方法添加新元素:如果元素已存在则忽略
a_set.add(10)
a_set.add(1)
print(a_set)
# 使用update方法用于集合的合并,同时去除重复元素
a_set.update(b_set)
print(a_set)
# 使用pop随机删除集合中任一元素并返回,如果集合为空则抛异常(默认删除哈希值最小的元素)
del_element=a_set.pop()
print(del_element)
print(a_set)
# 使用remove和discard方法删除集合指定元素,如果元素不存在,remove会抛异常,discard会忽略
a_set.remove(2)
print(a_set)
a_set.discard(2)
print(a_set)
# 使用clear方法清空集合元素
a_set.clear()
print(a_set)
'''
out:
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 22, 33, 44, 55}
1
{2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 22, 33, 44, 55}
{3, 4, 5, 6, 7, 8, 9, 10, 11, 22, 33, 44, 55}
{3, 4, 5, 6, 7, 8, 9, 10, 11, 22, 33, 44, 55}
set()
'''集合常用函数
内置的len、max、min、sum、sorted等函数均适用集合
补充:字符串常用方法
字符串属于有序不可变序列,除了索引、切片、运算符操作和内置函数外,还有一些自身方法。需要注意,因为字符串不可变,因此这些方法均是返回处理后的新串,并不会修改原字符串。
- encode()方法: 可以按照指定编码格式将字符串编码成字节串;**decode():**方法可以使用正确的编码格式对字节串解码得到字符串。默认均采用UTF-8编码格式
python
s="中国"
# 使用add方法添加新元素:如果元素已存在则忽略
new_s=s.encode()
print(new_s)
s=new_s.decode()
print(s)
# print(new_s.decode("gbk")) # 如果编码与解码的格式不同就会报错,默认均使用utf-8
'''
out:
b'\xe4\xb8\xad\xe5\x9b\xbd'
中国
'''- index() / find()方法: 用来查找一个字符串在另一个字符串中首次出现的位置,find方法不存在时返回-1,而index抛异常;**rindex() / rfind()方法:**用来查找一个字符串在另一个字符串中最后一次出现的位置,rfind方法不存在时返回-1,而rindex抛异常。均可指定范围(左闭右开区间),默认是整个字符串
python
s="hello world"
# 使用find方法查找字符串
ll_index=s.find("ll") # 字符串起始字符位置
print(ll_index)
l_rindex=s.rfind("l")
print(l_rindex)
print(s.find("d",0,7)) # 指定[0,7)区间内查找字符d
'''
out:
2
9
-1
'''- **count()方法:**统计一个字符串在另一个字符串内出现的次数。可指定范围(左闭右开区间),默认是整个字符串
- split()方法: 以指定字符为分隔符从字符串左侧开始分隔;**rsplit()方法:**以指定字符为分隔符从字符串右侧开始分隔。
注意:
- 如果未指定分隔符,则字符串中任何连续空白符号(如空格、换行符、制表符等)都被认为是一个分隔符,且自动忽略字符串首尾的空白字符;
- 如果指定分隔符,将严格按照指定的分隔符逐字符分割:每遇到一个空格就切分一次;若中间n个分隔符连续出现,中间没有其他字符,就会生成n-1个分隔符;若字符串开头 / 结尾就是分隔符,开头 / 结尾也会生成分隔符;
- 可通过maxsplit参数指定最大分隔次数。
- **join()方法:**将可迭代对象(这里的可迭代对象必须是字符串,否则会抛异常)中所有元素连接成一个字符串(格式为:连接符.join(可迭代对象))
python
# 通过split与join删除字符串中多余的空格
s=" hello world "
# 格式:空格 + 空格 + 空格 + hello + 空格 + 空格 + 空格 + world + 空格 + 空格 + 空格
# 使用split方法分隔字符串
s_list=s.split()
print(s_list)
# 需要特别注意
s1_list=s.split(" ") # 指定空格分隔符:['', '', '', 'hello', '', '', 'world', '', '', '']
print(s1_list)
# 通过join方法连接
new_s=" ".join(s_list)
print(new_s)
'''
out:
['hello', 'world']
['', '', '', 'hello', '', '', 'world', '', '', '']
hello world
'''- **lower()、upper()、capitalize()、title()、swapcase()方法:**用来将字符串转为小写、大写、首字母大写、每个单词首字母大写、大小写互换
- **replace()方法:**用于字符串替换,默认替换字符串中指定的所有字符或子字符串,可以指定替换次数
- **strip()、rstrip()、lstrip()方法:**分别用来删除字符串两次、右侧、左侧的连续空白或指定字符
python
s=" What is Your Name###"
# 大小写转换
print(s.lower())
print(s.upper())
print(s.capitalize())
print(s.title())
print(s.swapcase())
# replace替换字符串,格式str.replace(待替换字符串,新字符串,次数)
print(s.replace("Name", "Email", 1))
# strip删除字符串两侧空白字符或指定字符
print(s.lstrip())
print(s.rstrip("#"))
'''
out:
what is your name###
WHAT IS YOUR NAME###
what is your name###
What Is Your Name###
wHAT IS yOUR nAME###
What is Your Email###
What is Your Name###
What is Your Name
'''推导式
通过非常简洁的形式对可迭代对象中的元素进行遍历,过滤或再计算,快速构建满足特点需求的新对象。
列表推导式
基本格式:最终收集结果 for 变量 in 序列 if 条件。逻辑上等价于一个循环结构,或者嵌套的循环结构。
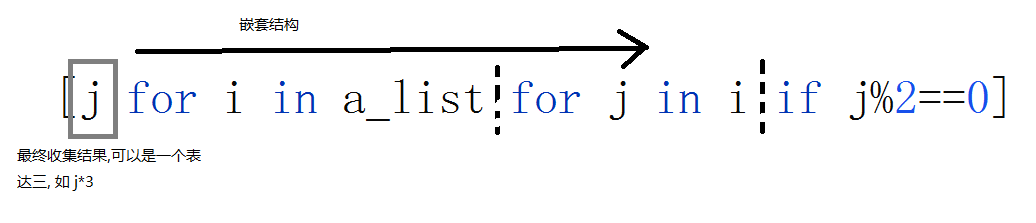
python
# 找1~9的偶数组成的列表
a_list=[x for x in range(1,10) if x%2==0]
print(a_list)
# 等价形式
b_list=[]
for x in range(1,10):
if x%2==0:
b_list.append(x)
print(b_list)
# 嵌套结构的推导式:找出列表内所有偶数
a_list=[[1,1,2,6],[-1,20,5],[9,6,6]]
expre=[j for i in a_list for j in i if j%2==0]
print(expre)
# 等价形式
b_list=[]
for i in a_list:
for j in i:
if j%2==0:
b_list.append(j)
print(b_list)
'''
out:
[2, 4, 6, 8]
[2, 4, 6, 8]
[2, 6, 20, 6, 6]
[2, 6, 20, 6, 6]
'''字典推导式
字典推导式于列表推导式类似,只是定界符采用一对花括号,每个元素为键:值对形式
python
keys=["name","age"]
values=["tom",18]
a_dict={k:v for k,v in zip(keys,values)}
print(a_dict)
'''
out:
{'name': 'tom', 'age': 18}
'''集合推导式
也是采用一对花括号作为定界符,只是收集结果处只是一个值而非键值对形式
python
a_set={i for i in range(20) if i%3==0}
print(a_set)
'''
out:
{0, 3, 6, 9, 12, 15, 18}
'''推导式只是使用更加简洁的方式来构建可迭代对象,并不是必须的。
迭代器对象
迭代器式一个可以记住遍历位置的对象,会从一组数据的第一个位置开始访问,只进不退,直到访问完所有元素。迭代器有两个基本函数:获取迭代器对象函数:iter();获取当前指向对象并后移:next()
python
a_list=[1,2,3,4,5]
# 获取列表的迭代器对象
it=iter(a_list)
for i in range(len(a_list)):
# 通过next(迭代器对象)获取元素
print(next(it),end=" ")
'''
out:
1 2 3 4 5
'''生成器表达式
列表推导式具有运行速度快,形式简单等优点,但是使用时是一次生成整个列表,在大数据量的情况下,会造成较大的内存压力,而生成器表达式与列表表达式很相似,只是它是在需要的时候才生成新元素,并不是一次性构建整个列表,更适合大数据量的情况。
- 生成表达式与列表表达式基本一致,只不过界定符换成了一对括号;
- 使用时,直接把生成器对象作为迭代器对象使用,通过next()函数来访问元素;
- 当所有元素访问完,想重新访问其中元素,必须重新创建该生成器对象。
python
g=(i for i in range(1,3))
print(type(g))
# 使用next函数逐个遍历
print(next(g))
print(next(g))
# print(next(g)) # 抛异常,因为所有元素已经遍历完
# 想再次遍历需要重新生成
g=(i for i in range(1,3))
# 利用循环结构遍历其中元素
for i in g:
print(i,end=" ")
'''
out:
<class 'generator'>
1
2
1 2
'''文件的基本操作
文件的打开
使用python提供的内置函数open()创建文件对象,并按照指定模式打开要操作的文件。
格式:<文件对象>=open(<文件名 / 文件路径> ,\<打开模式\> ,\<缓冲区设置策略\>)
- <文件名 / 文件路径>:指定被打开的我呢见名称,可以是文本文件或二进制文件,如果文件不在当前py文件的目录下,还需要指定完整路径;
- <打开模式>:指打开文件后的处理方式,默认是只读('r')
|----------|-------------------------------------------|
| 打开模式 | 功能 |
| r | 只读模式打开文件(默认方式),如果文件不存在,则抛出异常 |
| w | 只写模式打开文件,如果文件已存在,先清除原来的内容 |
| x | 创建一个新文件,只写模式打开文件,如果文件已存在则抛出异常 |
| a | 追加模式打开文件,若文件存在,将要写入的数据追加在原文件内容之后 |
| b | 二进制文件模式 |
| t | 文本文件模式(默认方式) |
| + | 为基础模式增加读 / 写的权限,使其同时拥有读和写的能力,用于更改文件内容 |
[open函数的打开模式]
需要注意的是:
- '+'是权限修饰符,只为基础模式增加读 / 写权限,让权限通过拥有读和写的能力;没有单独的
+模式,必须搭配r/w/a,且'+'不改变核心行为(如:r+不会清空文件(和r一致),w+依然会清空文件(和w一致),a+依然是追加写入(和a一致))- 凡是带'r'的文件打开模式,都是打开已经存在的文件,如果文件不存在则打开失败,抛出异常;
- 凡是带'w'和'a'的文件打开模式,如果文件存在则正常打开,如果文件不存在则会创建一个新文件并打开;
- Windows 系统 :
open()不指定编码时,默认用 GBK 打开文本文件,因此,在打开文件时,可以在open函数的参数中添加encoding="utf-8"的参数来设置编码方式。
文本文件:(纯字符:txt、py、md、csv、json、log等)二进制文件:(非纯字符:图片、视频、音频等)
- <缓冲区设置策略>:缓冲区是内存中暂存数据的存储区域,表示为一个整数,默认值1表示缓存模式,用于文本文件;0表示不缓存,用于二进制文件;>1表示缓冲区大小
文件的关闭
当不需要读写文件时,应该关闭文件,释放文件占用的系统资源。
格式:<文件对象>.close()
文件的读写
读文件
- read()方法:读取文本文件或二进制文件中的数据,分别返回字符串和字节串;可以设置参数,指定读取的字节或字符数,默认参数为负数,表示读取文件全部内容
- readline()方法:适合从文本文件中读取一行数据并以字符串返回
- readlines()方法:以行为单位读取多行数据,每行数据作为一个字符串元素存入列表中返回;可以指定参数表示读取指定字节或字符数的相应行数(读取到该字节所在的那一行)
需要注意:
- 三个读方法均会读取每行末尾的换行符 '\n',当读取到的数据为空(包括空串,空列表)时,表示文件读取结束
- 如果有参数指定读取的字节或字符数,依据字节数还是依据字符数是根据读取的文件是二进制文件还是文本文件,即文本文件是字符数,二进制文件是字节数
写文件
- write()方法:参数指定要写入的内容,必须是字符串或字节串,返回写入的字节数
- writelines()方法:向文件写入字符串元素组成的列表
需要注意:
- 两个写方法均不会自动写入换行,如果需要换行,必须自己在写入的内容中加上换行符
文件指针定位函数
每个打开的文件都有一个隐含的文件指针用于标识文件读写操作的当前位置(本质是一个从文件头部开始对字节计数的整型变量),文件打开模式不同,文件指针的初始位置也不同,每当读写一定数目的字节,文件指针就后移相应字节数。
- **tell()方法:**返回文件指针的当前位置,即下一次的读写操作将从该位置开始
- **seek(offset, from)方法:**用于设置文件指针移动到的位置,offset用于指定指针要移动的字节数,from指定偏移位置的指针基点(默认情况form=0,表示以文件开头作为指针移动的参考位置;from=1,表示以当前位置为参考位置;from=2,表示以文件末尾作为参考位置)
open函数的权限 =3 大基础权限(r/w/a) + 2 种格式(t/b) + 1 个增强符(+),其中t为默认格式,可省略- 文件的读 / 写都是根据文件指针的位置开始往后写,如果后面有内容则覆盖(除了w权限,是在打开文件时就将所有内容都清除)
python
'''
test.txt:
hello world
我爱你,中国
111
'''
f=open("test.txt","r+",encoding="utf-8") # 从文件开头开始,以读写的权限打开文件
# 读取全部内容
print(f.read())
# 已经读取完全部内容,想再次遍历需要重新生成或者使用seek设置指针位置
f.seek(0) # 将文件指针重新指向文件开头
print(f.tell())
print(f.read(8)) # 读取前8个字符
print(f.readline()) # 从当前文件指针位置开始读取一行(遇到换行符或结束符停止)
print(f.readlines(7)) # 7个字符,刚好是第三行字符的开始,因此会读取第二和第三行数据
# 写入数据
print(f.write("\n新添加内容\n")) # 默认是不换行的,如果需要换行要自己添加;返回写入的字符数
f.writelines(["新内容1\n", "新内容2\n"])
# 关闭文件资源
f.close()
'''
test.txt:
hello world
我爱你,中国
111
新添加内容
新内容1
新内容2
'''
'''
out:
hello world
我爱你,中国
111
0
hello wo
rld
['我爱你,中国\n', '111']
7
'''使用with读取文件
文件操作一般步骤为:打开文件 -> 读写文件 -> 关闭文件。但是如果在读写过程中出现异常会导致close无法调用,文件无法正常关闭。而使用with语句来操作文件,它可以自动管理上下文资源,即使异常也会自动调用close方法关闭文件。
with还支持一次打开多个文件。
python
# 同时打开3个文件
with open("1.txt", "r", encoding="utf-8") as f1, \
open("2.txt", "w", encoding="utf-8") as f2, \
open("3.txt", "r+", encoding="utf-8") as f3:
f1.read()
f2.write("test")
# 文件操作完不必自己显示关闭文件,with会自动管理os模块操作文件与目录
os模块
主要提供了操作文件与文件夹的函数
|-------------------------|-----------------------|
| 函数 | 说明 |
| remove(filename) | 删除指定的文件,如果文件不存在,则抛出异常 |
| rename(oldname,newname) | 重命名文件或文件夹 |
| getcwd() | 查看当前工作目录 |
| listdir(path) | 返回指定目录下所有文件和文件夹元素的列表 |
| mknod(filename) | 创建空文件 |
| mkdir(path) | 创建目录 |
| makedirs(path) | 创建多层目录 |
| rmdir(path) | 删除指定目录(只能删除空目录) |
| chdir(path) | 改变当前工作目录到指定路径 |
os.path模块
主要提供了路径判断、切分、连接及文件夹遍历等函数
|--------------------|-------------------|
| 函数 | 说明 |
| abspath(path) | 返回指定路径的绝对路径 |
| basename(path) | 返回指定路径最后的文件名部分 |
| dirname(path) | 返回指定路径的目录名部分 |
| exists(path) | 判断给定的路径、目录或文件是否存在 |
| isabs(path) | 判断给定的path是否为绝对路径 |
| isdir(path) | 判断给定的path是否为目录 |
| isfile(path) | 判断给定的path是否为文件 |
| getsize(filename) | 获取给定文件的大小 |
| getctime(filename) | 获取给定文件的创建时间 |
| getmtime(filename) | 获取给定文件的最后一次修改时间 |
| getatime(filename) | 获取给定文件的最后一次访问时间 |
python
import os.path as op
# 判断文件路径是否存在
print(op.exists("D://code//machineLearning//demo//test5.py"))
# 获取给定文件的最后一次修改时间
last_alter_time=op.getmtime("test.txt") # 获取到的是一个时间戳
# 将时间戳转成本地时间
import time
local_time = time.ctime(last_alter_time)
print(local_time)
'''
out:
True
Wed Mar 25 10:22:14 2026
'''JSON文件操作
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,是js对象的字符串表示法,本质是一个字符串。
它是一个由花括号"{}"括起来的无序键值对集合,结构:{key1: val1, key2: val2, ...}。
JSON的常用数据类型
- 字符串(string):放在一对双引号中(比如:"name");
- 数值(number):可以是整型或浮点型(比如:10,20.0);
- 布尔值:true和false;
- 数组(array):放在一对方括号中(比如:1,2,3);
- 对象(object):放在一对花括号中,key描述对象的属性,val描述对象的属性值(比如:{"name" : "tom", "age" : 18})。
javascript
// JSON数据示例
{
"name":"坤坤",
"age":2.5,
"interest":["唱","跳","rap","篮球"],
// 对象的属性还可以是另一个对象(嵌套)
"contactInformation":{
"type":"email",
"number":"1234567@aaa.com",
"isStillUsing":true
}
}JSON文件:将JSON数据保存为扩展名为.json的文件,称为JSON文件。
|----------------|--------------|----------------|--------------|
| Python数据类型 | JSON数据格式 | Python数据类型 | JSON数据格式 |
| dict | object | True | true |
| list,tuple | array | False | false |
| str | string | None | null |
| int,float | number | | |
使用JSON模块进行读写操作
读操作
- json.loads(str)函数:将一个JSON对象转换为一个Python对象,最常见的就是将字符串转为字典数据类型;
- json.load()函数:用于从json文件中读取数据并转换为python对象,第一个参数为json文件对象。
注意:因为json的字符串必须使用双引号作为定界符,因此更推荐python的字符串使用单引号,这样可以避免转义操作
python
'''
test.json:
{
"name":"坤坤",
"age":2.5,
"interest":["唱","跳","rap","篮球"],
"contactInformation":{
"type":"email",
"number":"1234567@aaa.com",
"isStillUsing":true
}
}
'''
# 导入python的标准库json,用来便携操作json数据
import json
# 将json字符串转为py对象
py_obj=json.loads('{"name":"tom", "age":18}') # py的字符串使用''包裹,而内部json的字符串使用""包裹,这样可以避免转义操作
print(type(py_obj))
print(py_obj)
# 使用load读取json文件内容并将其转为py对象
# 使用with自动管理文件对象
with open("test.json","r",encoding="utf-8") as f:
data=json.load(f)
print(type(data))
print(data)
'''
out:
<class 'dict'>
{'name': 'tom', 'age': 18}
<class 'dict'>
{'name': '坤坤', 'age': 2.5, 'interest': ['唱', '跳', 'rap', '篮球'], 'contactInformation': {'type': 'email', 'number': '1234567@aaa.com', 'isStillUsing': True}}
'''写操作
- json.dumps(obj)函数:可以将python对象转为json字符串,默认情况下,只能用于字典类型;
- json.dump()函数:可以将python对象转换成json数据保存到json文件中。
python
# 导入python的标准库json,用来便携操作json数据
import json
# 将py对象转为json字符串
a_dict={'name': 'tom', 'age': 18}
js_str=json.dumps(a_dict)
print(type(js_str))
print(js_str)
# 使用dump将py对象转为json数据并写入json文件中
# 使用with自动管理文件对象
music_dict_list=[{'歌名':'恋人',"歌手":"李荣浩"},{'歌名':'明天的记忆',"歌手":"孙燕姿"}]
with open("test1.json","w",encoding="utf-8") as f: # 文件不存在,会创建并写入
'''**ensure_ascii的作用:控制是否把中文/特殊字符转成Unicode编码,默认为True(在True的情况下会看不到实际中文,全是Unicode转义序列)**'''
json.dump(music_dict_list,f,ensure_ascii=False)
'''
out:
<class 'str'>
{"name": "tom", "age": 18}
'''
'''
test1.json:
[{"歌名": "恋人", "歌手": "李荣浩"}, {"歌名": "明天的记忆", "歌手": "孙燕姿"}]
ctrl+alt+l:进行格式化
[
{
"歌名": "恋人",
"歌手": "李荣浩"
},
{
"歌名": "明天的记忆",
"歌手": "孙燕姿"
}
]
'''CSV文件操作
CSV(Comma Seperated Values)是一种以逗号为分隔符的纯文本文件格式,通常用于存储电子表格数据。它的第一行通常为列名或字段名,其余每行存储一个样本或记录(二维表格,只是每一列通过逗号分隔)
使用csv模块进行读写操作
- reader()函数:用于csv文件的读操作,创建并返回一个可迭代的读对象,每次迭代以字符串列表形式返回文件中的一行数据;
- writer()函数:用于csv文件的写操作,创建并返回一个可迭代的写对象,通过写对象的writerow()和writerows()方法将数据写入目标文件。
python
'''
score.csv:
id,score
1,60
2,98
3,87 # 最后一行处缺少一个换行符
'''
# 导入python的标准库csv,用来简化csv文件的读写操作
import csv
# python官方csv文档明确规定必须加:newline='',这样可以避免跨平台的换行符问题
with open('score.csv',"r",encoding="utf-8", newline='') as csvfile:
read_it=csv.reader(csvfile) # 返回一个reader迭代器对象:逐行读取、懒加载
print(type(read_it))
for row in read_it:
print(row)
# 迭代器已经全部遍历完,文件指针到达末尾,如果此时想再次遍历,需要使用之前提到的seek
csvfile.seek(0)
print("第二次遍历:")
next(read_it) # 跳过第一行(表头)
for row in read_it:
print(row)
# 待写入数据
data=[[9,100],[10,79],[20,81]]
with open('score.csv',"a",encoding="utf-8", newline='') as csvfile:
wr_it=csv.writer(csvfile)
# writerow()必须传入一行数据的列表,此时通过追加打开,因为该文件最后一行没有换行符(末尾没有一行空行),会导致第一个待写入数据接到上一行中
# 可以通过文件对象先写入一个换行符再写入数据
csvfile.write("\n")
# 直接写入多行数据
wr_it.writerows(data)
'''
score.csv:
id,score
1,60
2,98
3,87
9,100
10,79
20,81
#这一行就是末尾空行,下次如果再想写入则不需要先写入换行符了,上面需要的原因是score文件是我自己写的,在最后一行87处并没有换行符导致
'''
'''
out:
<class '_csv.reader'>
['id', 'score']
['1', '60']
['2', '98']
['3', '87']
第二次遍历:
['1', '60']
['2', '98']
['3', '87']
'''使用Pandas读写CSV文件
python的第三方库Pandas提供了更简单、快速、便携的方式读写csv文件,返回一个DataFrame类型的python对象。
DataFrame对象
DataFrame对象是pandas中常用的数据结构之一,每个DataFrame对象由行索引(index)、列索引(columns)和值(values)三部分组成,很类似与一个Excel表格。
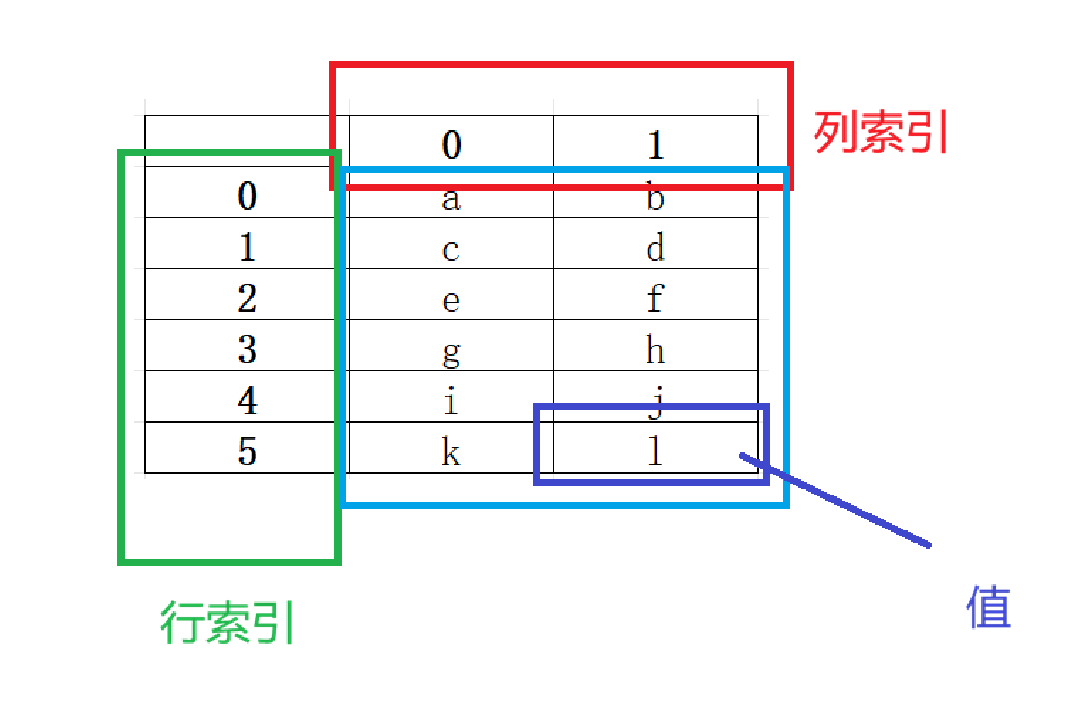
csv文件操作
- read_csv()函数:该函数可直接快速打开、读取并分析csv文件,将数据存储在DataFrame对象中;
参数:
**filepath_or_buffer:**csv文件路径;
sep / delimiter: 字段分隔符,默认 '
,';header: 指定表头行,
0→ 第一行做表头(默认);None→ 无表头;names: 自定义列名(配合
header=None使用);**index_col:**指定某一列作为行索引;
**usecols:**只读取指定列;
skiprows:跳过前 N 行;
nrows:只读取前 N 行;
skip_blank_lines:跳过文件中的空行,默认
True;encoding: 文件编码,默认为**
utf-8;**dtype:指定列数据类型(如
dtype={'id':int, 'score':float});na_values:将指定值识别为空值 NaN;
**parse_dates:**将指定列解析为日期格式。
- to_csv()函数:将DataFrame对象写入csv文件。
参数:
**path_or_buf:**保存的文件路径;
index: 是否写入行索引,默认
True→ 会多出一列索引;mode: 写入模式:
w→ 覆盖写入(默认),a→追加写入;**columns:**指定要保存的列
encoding: 文件编码,默认为**
utf-8;****
sep:**分隔符,默认 ',';na_rep:空值替换字符(如
na_rep='',空值显示为空);date_format: 日期列格式化(如
date_format='%Y-%m-%d');line_terminator:行结束符,默认
\n,自动处理跨平台换行;chunksize:大文件分块写入。
python
# 安装第三方库pandas并导入
import pandas as pd
'''
score.csv:
id,score
1,60
2,98
3,87
9,100
10,79
20,81
'''
# 读取当前目录下的score.csv文件,指定索引列为字段值为学号的列,header=0忽略现有列名,names自定义列名
csv_df=pd.read_csv("score.csv",index_col="学号",header=0,names=['学号','成绩'])
# 打印DataFrame对象
print(csv_df)
'''
out:
成绩
学号 # 为什么学号这一行会在下面?因为我们指定学号这行为行索引;而且,需要注意的是,当我们自定义列名后,如果还想指定行索引,必须使用自定义的列名
1 60
2 98
3 87
9 100
10 79
20 81
'''
# 不写入索引列
csv_df.to_csv("pd_score.csv",mode="w",index=False)
'''
pd_score.csv:
成绩
60
98
87
100
79
81
'''Excel文件操作
Excel文件与csv文件很相似,但它除了文本数据,还可以包含表格、样式、工作表等,因此在对Excel文件进行操作时,往往更复杂,而使用Pandas来对文件进行操作会快速、便捷很多。
需要注意的是,使用Pandas操作excel文件前,必须先安装openpyxl库。
使用Pandas模块读写Excel文件
- read_excel()方法:用于读取Excel文件,返回一个DataFrame对象(读取单个表)或DataFrame对象组成的字典(读取多个表时);
参数:
io:指定excel文件的路径;
sheet_name:指定读取的工作表,可以是工作表索引(默认0,表示第一个表)、名称和None(所有表);
header:指定表头行,默认0,表示第一行,None表示无表头;
names:自定义列名;
index_col:指定列作为行索引;
usecols:仅读取指定列,如
'A:C'、[0,2]、['姓名','成绩'];skiprows:跳过开头 / 指定行,如2 (跳前 2 行)、
[1,3](跳指定行);nrows:仅读取前 N 行;
skipfooter:指定跳过末尾n行;
dtype:强制指定列数据类型,如{'学号': str, '年龄': int};
parse_dates:自动解析日期列,如
['日期']、True。
- to_excel()方法:将DataFrame数据写入Excel文件,权限为w,如果想使用追加权限或者写入多个表,可以使用ExcelWriter()方法,这里就不介绍了。
参数:
excel_writer:指定excel文件的路径;
sheet_name:设置工作表名称;
index:是否写入行索引,默认True,写入行索引;
header:是否写入列名,True (默认);
columns:仅写入指定列;
na_rep:缺失值填充字符,默认空串;
float_format:浮点数格式化,如
'%.2f'(保留两位小数);startrow/startcol:起始写入行 / 列,如1 表示从第 2 行开始;
engine:写入引擎,
openpyxl(必选,xlsx 格式)。
python
# 安装第三方库pandas并导入
import pandas as pd
'''
test.xlsx:
sheet1:
学号 成绩
1 30
2 90
3 87
info:
学号 姓名 年龄 性别
1 小明 10 男
2 小红 11 女
3 小黑 11 男
course:
课程 主讲人
python基础 黄老师
数据结构 王老师
数据分析 李老师
'''
# 读取当前目录下的test.xlsx文件,指定读取info表,指定读取学号、姓名和年龄三列,指定学号列为索引列(该索引列需要被读取出来,否则会报错)
excel_df=pd.read_excel("test.xlsx",sheet_name="info",usecols=["学号","姓名","年龄"],index_col="学号")
# 打印DataFrame对象
print(excel_df)
# 读取当前目录下的test.xlsx文件,读取所有表,header=0默认值,第一列为列名
excel_dir=pd.read_excel("test.xlsx",sheet_name=None)
# 打印由DataFrame组成的字典对象(表名:表的数据对象)
print(excel_dir)
'''
out:
姓名 年龄
学号
1 小明 10
2 小红 11
3 小黑 11
{'sheet1': 学号 成绩
0 1 30
1 2 90
2 3 87, 'info': 学号 姓名 年龄 性别
0 1 小明 10 男
1 2 小红 11 女
2 3 小黑 11 男, 'course': 课程 主讲人
0 python基础 黄老师
1 数据结构 王老师
2 数据分析 李老师}
'''
# 从字典中取出sheet1表
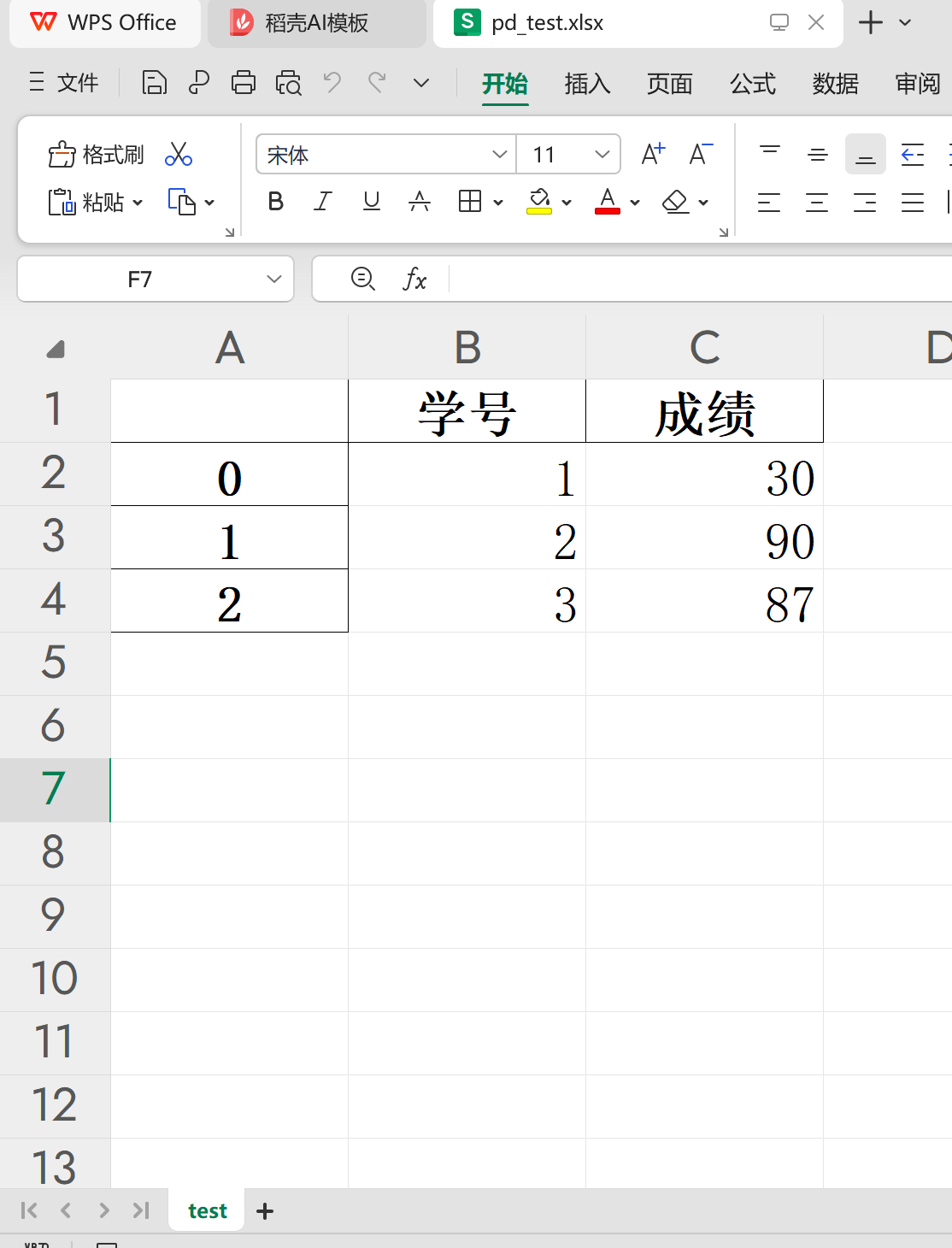
info_df=excel_dir["sheet1"]
# 默认写入行索引,指定工作表名称
info_df.to_excel("pd_test.xlsx",sheet_name="test")
'''
pd_test.xlsx:
test:
学号 成绩
0 1 30
1 2 90
2 3 87
'''
python基础到这里就算结束了,后面的文件操作部分,很多跟第三方库如Pandas相关,本来不是很想写,但是对比了一些其他操作,Pandas还是太方便了😃,后续看看有没有需要,可能会出像numpy、matplotlib和pandas相关库的使用,就这样吧。最后,如果觉得文章对你有帮助就点个赞和收藏吧😘
本文章部分内容参考由 于晓梅 李贞 郑向伟 朱磊编著的《Python数据分析案例教程》书籍