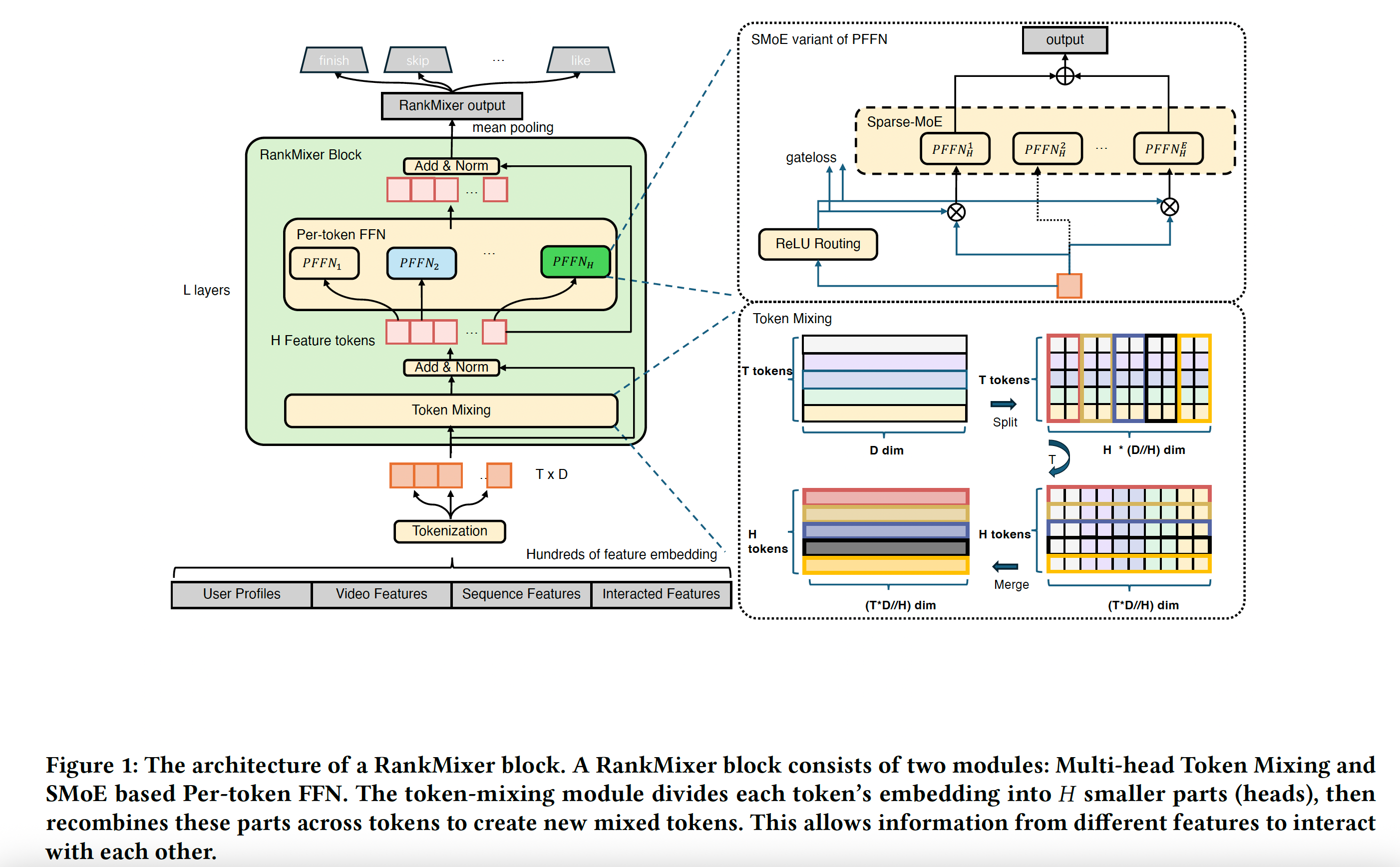
RankMixer主要是为了解决传统模型基于CPU时代设计模型MFU计算低效,不能很好的进行模型ScalingLaw扩展的问题。算法通过两步运算TokenMixing和PFFN,将特征在mixing阶段进行充分的混合,然后在PFFN阶段进行每个混合Token充分的交叉学习,可以学习出更多的高阶特征。
1.特征Token化
按照相似的特征语义,将特征进行分组,每组特征生成一个Embedding向量。然后对分组后的embeding向量进行concat拼接,拼接成e_input,然后对e_inpu按照d尺寸进行切分,然后进行Proj线性映射,生成最终的T个Token。
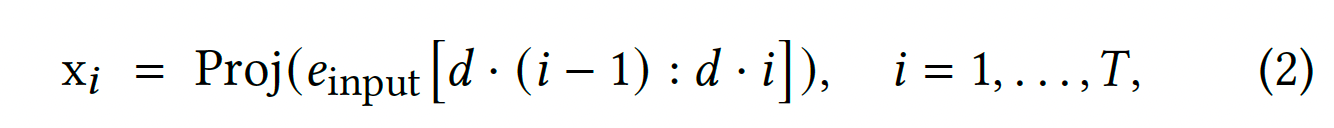
2.Token Mixing阶段
然后对T个token进行Split划分,按照dim维度,对每个Token进行切分,切分后的Token碎片形成多个Xt(i),每个Xt(i)就是headi的一部分输入。
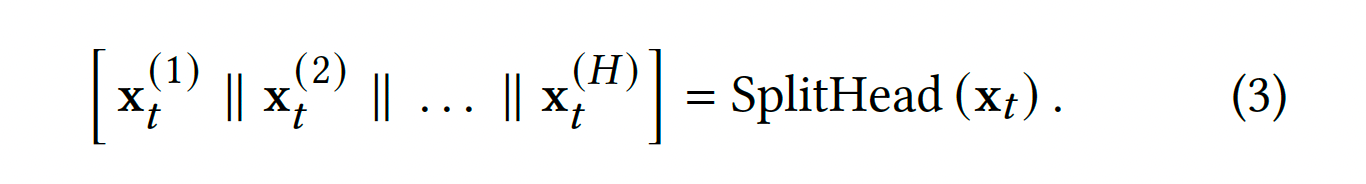
然后将所有headi拼接后,形成新的Token Sh,所有的H个head形成新的Token向量S.
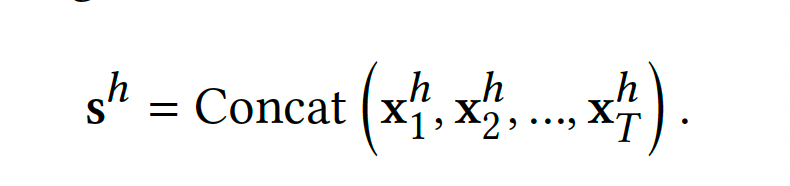
然后对Si_head加上原来的Xi形成最终的Si.
Per-token FFN
对每一个新的token Si,用独立的FFN前馈网络进行编码计算,激活函数使用Gelu,减少计算冗余,增加模型稀疏性,防止模型过拟合,增强模型的泛化能力。

Moe升级
对于每个Token的FFN前馈网络,为了进一步增加模型的参数容量,采用了Moe专家网络进行升级,专家网络的Gate用Relu函数取代原来的Topk+softmax的筛选方式,采用Relu动态学习的方式进行动态平衡。模型学习过程中采用了两个h路由,分别是htrain和hinfer,他们训练的过程中同时进行计算htrain和hinfer,用来计算最终的打分score,但是惩罚函数Lreg只对hinfer进行惩罚,增加hinfer的稀疏性。原理相当于htrain和hinfer学习了两套网络,hinfer去学习拟合htrain(有点蒸馏学习的思想),他们的打分最终是几乎相同的,但是hinfer由于有了惩罚项,h权重更稀疏泛化性更好,计算更少。其中每个Token使用的Ne专家数是相同的,数值通过数据和应用场景进行经验设置。
