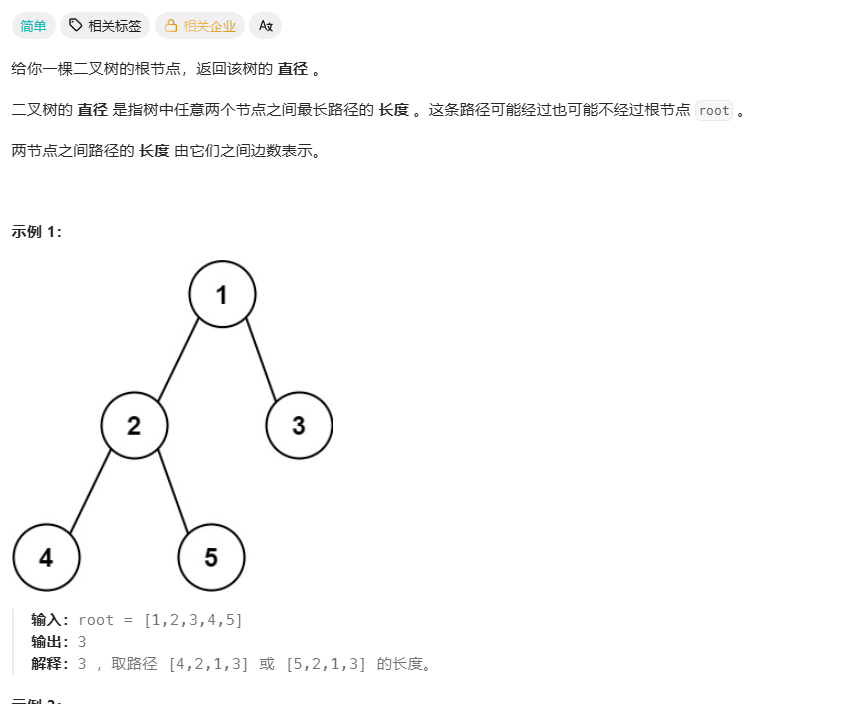
543.二叉树的直径
1.题目回顾
二叉树的直径(Diameter of Binary Tree) 是 LeetCode 第 543 题。
- 定义: 给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。
- 关键点: 这条路径可能穿过根节点,也可能不穿过。
- 度量标准: 路径长度由它们之间的"边数"表示,而不是节点数。例如,两个相邻节点的直径为 1。
2.核心思路
注意:在标准的"二叉树直径"解法中,通常使用的是深度优先搜索(DFS)配合全局变量更新 。图片中的"双哈希表"通常用于解决"克隆图"或"复杂链表复制"等问题。为了确保你学到的是针对"二叉树直径"最正确、最高效的解法,这里的核心思路将修正为 "递归分解与全局状态维护"。
我们可以将这个问题看作是一个 "自底向上" 的信息传递过程
- 局部视角(子问题): 对于树中的任意一个节点
node,经过它的最长路径 =左子树的最大深度+右子树的最大深度。 - 全局视角(最优解): 树的直径 = 所有节点中,"左深度 + 右深度"的最大值。
- 递归的作用: 递归函数负责两件事:
- 返回值(向上汇报): 告诉父节点,"我这一侧最深能到多少层"(即
max(left, right) + 1)。 - 副作用(横向更新): 在计算过程中,顺便算出经过当前节点的直径,并尝试更新全局最大值。
- 返回值(向上汇报): 告诉父节点,"我这一侧最深能到多少层"(即
这种思路避免了重复计算,将时间复杂度控制在 O(N) 。
3.算法详细步骤
为了清晰地实现上述逻辑,我们需要定义一个辅助递归函数(通常命名为 depth 或 dfs)。
初始化
创建一个成员变量 maxDiameter,初始化为 0。它将作为"全局记录器",随时保存目前发现的最长路径。
递归函数的执行流程
当函数被调用处理节点 node 时:
- 终止条件(Base Case): 如果
node为空(null),说明这条路走不通了,返回深度 0。 - 递归探索(Divide):
- 调用自身处理左孩子,得到
leftDepth。 - 调用自身处理右孩子,得到
rightDepth。
- 调用自身处理左孩子,得到
- 计算当前直径(Conquer & Update):
- 经过当前节点的路径长度 =
leftDepth + rightDepth。 - 比较这个长度和全局变量
maxDiameter,保留较大者。
- 经过当前节点的路径长度 =
- 返回当前深度(Return):
- 为了配合父节点的计算,我们需要返回当前子树的最大深度。
- 公式:
Math.max(leftDepth, rightDepth) + 1。
最终结果
主函数调用递归入口后,直接返回 maxDiameter 即可。
4.代码实现 (Java & Kotlin)
以下是基于上述思路的标准解法代码。
Java 版本
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
// 全局变量,用于记录遍历过程中遇到的最大直径
private int maxDiameter = 0;
public int diameterOfBinaryTree(TreeNode root) {
// 启动递归
depth(root);
return maxDiameter;
}
/**
* 辅助函数:计算以 node 为根的子树的最大深度
* @param node 当前节点
* @return 当前子树的最大深度(边数)
*/
private int depth(TreeNode node) {
// 1. 终止条件
if (node == null) {
return 0;
}
// 2. 递归获取左右子树深度
int leftDepth = depth(node.left);
int rightDepth = depth(node.right);
// 3. 【关键】更新全局最大直径
// 经过当前节点的路径长度 = 左边深度 + 右边深度
maxDiameter = Math.max(maxDiameter, leftDepth + rightDepth);
// 4. 返回当前节点的最大深度给父节点使用
// 深度 = 左右子树中较深的那个 + 1(当前节点到子节点的边)
return Math.max(leftDepth, rightDepth) + 1;
}
}Kotlin版本
/**
* Example:
* var ti = TreeNode(5)
* var v = ti.`val`
* Definition for a binary tree node.
* class TreeNode(var `val`: Int) {
* var left: TreeNode? = null
* var right: TreeNode? = null
* }
*/
class Solution {
// 使用成员变量存储最大直径
private var maxDiameter = 0
fun diameterOfBinaryTree(root: TreeNode?): Int {
depth(root)
return maxDiameter
}
private fun depth(node: TreeNode?): Int {
// 1. 终止条件:空节点深度为 0
if (node == null) return 0
// 2. 递归计算左右深度
val leftDepth = depth(node.left)
val rightDepth = depth(node.right)
// 3. 更新全局最大值
// Kotlin 中使用 maxOf 或者 Math.max
maxDiameter = maxOf(maxDiameter, leftDepth + rightDepth)
// 4. 返回当前子树深度
return maxOf(leftDepth, rightDepth) + 1
}
}5.复杂度分析
假设二叉树的节点数量为 N 。
时间复杂度: O(N)
- 分析: 我们的算法本质上是一次后序遍历 。递归函数
depth对树中的每一个节点都访问且仅访问了一次。 - 结论: 无论树的形状如何(平衡或不平衡),我们都需要检查所有节点来计算深度和更新直径,因此时间复杂度是线性的。
空间复杂度: O(H)
其中 H 是树的高度。
- 分析: 空间消耗主要来自于递归调用栈(Call Stack)。
- 最好情况: 树是完全平衡的,高度 H=logN ,空间复杂度为 O(logN) 。
- 最坏情况: 树退化成链表(例如每个节点只有左孩子),高度 H=N,此时递归栈深度达到 N ,空间复杂度为 O(N)。
23.合并K个升序链表

1.题目回顾
- 输入: 一个包含 KK 个链表的数组
lists,每个链表都已经按升序排列。 - 输出: 将所有链表合并为一个升序链表,并返回合并后的头节点。
- 暴力法核心: 顺序遍历数组,不断将当前链表合并到结果链表中。
2.核心思路:顺序两两合并
这种方法的本质是累积合并。
- 初始化结果: 我们可以把结果链表
result初始化为null(或者数组中的第一个链表)。 - 遍历数组: 依次取出
lists中的每一个链表。 - 两两合并: 调用基础的
mergeTwoLists函数,将当前的result和取出的链表进行合并,合并后的新链表再次赋值给result。 - 重复: 直到遍历完数组中的所有链表。
3.算法详细步骤
为了让你更清楚流程,我们模拟一下:
准备基础函数
首先,你需要一个能够合并两个有序链表的辅助函数(这是 LeetCode 第 21 题的解法)。使用双指针法,谁小谁就先被接上。
累积合并过程
- 设
result = null。 - 第 1 轮: 合并
result(null) 和lists[0],result变成了lists[0]的内容。 - 第 2 轮: 合并
result和lists[1],result变成了前两个链表合并后的长链表。 - 第 3 轮: 合并
result和lists[2],result变得更长了。 - ...
- 第 K 轮: 合并完毕,返回最终的
result。
4. 代码实现 (Java & Kotlin)
Java版本
// 定义链表节点
class ListNode {
int val;
ListNode next;
ListNode() {}
ListNode(int val) { this.val = val; }
ListNode(int val, ListNode next) { this.val = val; this.next = next; }
}
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
if (lists == null || lists.length == 0) return null;
// 初始化结果链表为 null
ListNode result = null;
// 遍历数组中的每一个链表
for (ListNode list : lists) {
// 将当前的结果链表与当前遍历到的链表进行合并
result = mergeTwoLists(result, list);
}
return result;
}
// 辅助函数:合并两个有序链表(经典的双指针法)
private ListNode mergeTwoLists(ListNode l1, ListNode l2) {
// 如果其中一个为空,直接返回另一个
if (l1 == null) return l2;
if (l2 == null) return l1;
// 保证 l1 的头节点值较小,方便后续处理
if (l1.val > l2.val) {
return mergeTwoLists(l2, l1);
}
// 递归或迭代连接节点(这里使用迭代写法)
ListNode dummy = new ListNode(0);
ListNode curr = dummy;
while (l1 != null && l2 != null) {
if (l1.val < l2.val) {
curr.next = l1;
l1 = l1.next;
} else {
curr.next = l2;
l2 = l2.next;
}
curr = curr.next;
}
// 接上剩余未遍历完的部分
curr.next = (l1 != null) ? l1 : l2;
return dummy.next;
}
}Kotlin版本
// 定义链表节点
class ListNode(var `val`: Int) {
var next: ListNode? = null
}
class Solution {
fun mergeKLists(lists: Array<ListNode?>): ListNode? {
if (lists.isEmpty()) return null
var result: ListNode? = null
// 遍历并两两合并
for (list in lists) {
result = mergeTwoLists(result, list)
}
return result
}
// 辅助函数:合并两个有序链表
private fun mergeTwoLists(l1: ListNode?, l2: ListNode?): ListNode? {
if (l1 == null) return l2
if (l2 == null) return l1
val dummy = ListNode(0)
var curr: ListNode? = dummy
var p1 = l1
var p2 = l2
while (p1 != null && p2 != null) {
if (p1.`val` < p2.`val`) {
curr?.next = p1
p1 = p1.next
} else {
curr?.next = p2
p2 = p2.next
}
curr = curr?.next
}
// 接上剩余部分
curr?.next = p1 ?: p2
return dummy.next
}
}5.复杂度分析
假设 KK 为链表的数量, NN 为所有链表中节点的总数。
时间复杂度: O(K×N) 或更精确地说是 O(N×K)的变种
- 假设平均每个链表有 M 个节点,那么 N=K×M 。
- 第 1 次合并:处理 M 个节点。
- 第 2 次合并:处理 2M 个节点。
- 第 3 次合并:处理 3M 个节点。
- ...
- 第 K 次合并:处理 K×M 个节点。
- 总操作次数约为 M×(1+2+...+K)=M×K(K+1) 。
- 忽略常数后,时间复杂度约为 O(N×K) 。
- 缺点: 当 K 很大时,效率会显著低于优先队列法( O(NlogK))或分治法。
空间复杂度: O(1)
- 我们只需要常数级别的额外空间来存放指针(
dummy,curr等)。 - 合并过程是在原节点上修改指针指向,没有开辟新的节点空间(不考虑递归调用栈的话,迭代写法就是 O(1) )。5.