前言
AI技术正以前所未有的速度迭代,各类智能体和开发工具层出不穷。为了深入探索AI驱动的研发流程闭环,并真实地摸清当前AI能力的边界,我决定:从0到1,独立开发一个相对复杂的系统,全程由AI负责执行,而"人"只扮演管理者的角色。
本文将完整复盘这个项目的启动、开发与调试阶段。关于后续的项目部署、迭代与运维等环节,我会在系列文章的后续章节中持续更新,敬请期待。
概览
使用的AI工具链
- 核心开发:Cursor + 2个OpenClaw
- 辅助工具:Speckit、GSD (get-shit-done)
- 需求探讨:DeepSeek Chat + OpenClaw
项目整体架构
OrangeHome 无代码/低代码搭建平台整体架构:
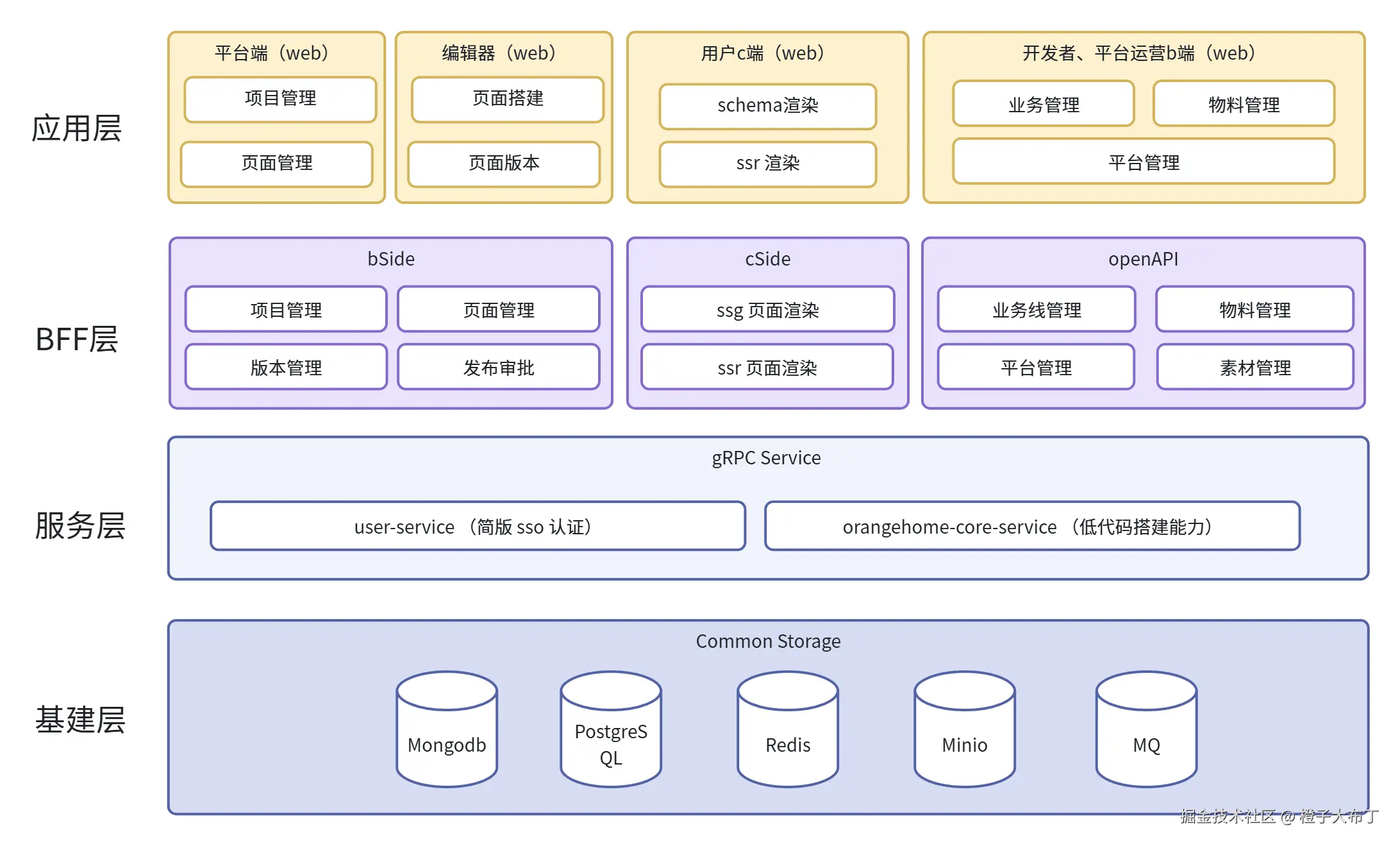
项目仓库
采用多仓库协作模式,与真实研发场景高度贴合:
| 仓库名称 | 仓库类型 | 仓库描述 | 仓库地址 |
|---|---|---|---|
| orangehome-main-monorepo | Rush monorepo | 应用层仓库,包含BFF和Web | github.com/ponyorange/... |
| orangehome-materials | Turbo repo | 低代码平台物料 | github.com/ponyorange/... |
| orangehome-core-service | 单仓 | 低代码搭建核心能力 | github.com/ponyorange/... |
| orangehome-user-service | 单仓 | 简版SSO认证 | github.com/ponyorange/... |
系统体验
欢迎访问在线体验地址:http://8.148.251.221:6010/platform
项目启动:从想法到方案
项目启动阶段主要包含三个关键步骤:明确需求 、输出技术方案 、制作UI。
明确需求
如果你的项目已经有明确的产品需求文档(PRD),可以直接跳过此步。
由于我是从零开始构思这个系统,只有模糊的想法,没有现成的产品文档。因此,我需要借助AI工具来输出一份完整、清晰的需求文档,为后续的开发奠定基础,确保我和AI都对"要做什么"有完全一致的理解。
这里我选择的是 DeepSeek Chat。原因有二:第一,免费;第二,其深度思考能力在自然语言理解领域表现优异,非常适合进行需求探讨。
操作流程:
- 让AI扮演资深产品经理:使用精心设计的提示词模板,与DeepSeek进行多轮对话,逐步完善需求。
markdown
**提示词示例:**
请扮演一位资深产品经理,协助我完成一份标准的产品需求文档(PRD)。我将提供产品背景信息,请按照以下结构生成初稿,使用Markdown格式。
【产品名称】[填写产品名称]
【目标用户】[描述主要用户画像]
【核心痛点】[列出用户当前面临的问题]
【核心想法】[描述你的产品功能想法,可零散列出]
【业务目标】[可选,如提升转化率、降低客诉等量化指标]
请按以下章节输出:
1. 文档修订记录(版本、日期、作者、变更说明)
2. 项目背景与目标(包含背景、业务目标、衡量指标OKR/KPI)
3. 用户角色与用户故事(至少2个典型角色,每个角色对应2-3个用户故事)
4. 功能范围(按P0/P1/P2优先级分类,用表格形式)
5. 业务流程图(用Mermaid语法描述主流程)
6. 功能详情(重点描述P0功能,每个功能包含:功能描述、前置条件、正常流程、异常流程、字段定义)
7. 非功能性需求(性能、安全、兼容性、可扩展性等)
8. 数据埋点需求(建议列出需要追踪的关键事件)
9. 附录与术语表
要求:
- 逻辑清晰,避免歧义
- 异常流程至少覆盖3种常见边界情况
- 验收标准需明确可量化- 多角色审查(可选,更严谨) :在第一版PRD生成后,可以让AI分别扮演后端开发、前端开发和测试工程师的角色,对PRD进行交叉审查,找出潜在问题并提出修改建议。
markdown
**提示词示例:**
请分别扮演【后端开发工程师】、【前端开发工程师】和【测试工程师】三个角色,对以下PRD内容进行审查。我将粘贴具体章节,请从每个角色的角度指出问题,并给出修改建议。
审查重点:
- 后端开发:关注数据一致性、接口设计、性能瓶颈、安全风险、扩展性
- 前端开发:关注交互细节、状态管理、异常反馈、兼容性、用户体验
- 测试工程师:关注逻辑完整性、边界条件、测试点覆盖、可测性
请按以下格式输出:
【后端开发视角】
- 问题点1:描述问题 → 建议修改
- 问题点2:...
【前端开发视角】
...
【测试工程师视角】
...
最后,请总结你认为最重要的3个待优化项。- 产出:根据反馈再次完善,最终得到一份高质量的系统需求文档和各子系统的详细需求文档。
个人体会:AI在这里产出的需求文档,其结构清晰度和逻辑严谨性,已经超越了绝大多数我见过的PM所写的PRD。强烈推荐大家尝试一下。
技术方案
核心原则:你负责架构设计和技术选型,AI负责完善技术细节。
为什么不直接把需求文档丢给AI,让它全权负责技术方案呢?难道AI的架构能力不强吗?
并非如此。我甚至相信AI在这方面的能力远超大多数高级工程师。但问题在于,如果你不能理解和驾驭AI的设计,你就无法掌控整个项目。项目初期一切顺利,但到了后期进行功能扩展或Bug修复时,代码可能会变得一团糟,让你怀疑AI的能力。这不是AI不行,而是你没有驾驭它。就像一个不会开车的人,出了车祸只会责怪车不好。
当然,如果你完全没有头绪,完全可以与AI探讨。你可以拿着AI提供的技术方案,追问它为什么这样设计,有什么瓶颈,有没有其他替代方案。这个过程本身就是向AI学习、最终在思想上超越AI的过程。只有这样,你才能真正地领导AI,而不是被AI领导。AI的价值在于降低了学习成本,帮你快速答疑解惑。
因此,在AI时代,软件工程师的核心价值在于架构审美能力、业务价值判断能力和独立思考能力。如果你盲目相信AI,那么你的上限就是AI的上限。而如果你能保持独立思考,不断质疑AI的回答,你将永远凌驾于AI之上。
我的架构设计思路
- 为什么拆分user-service? 提供统一的认证能力,相当于一个简版的单点登录(SSO)服务,解耦用户管理与核心业务。
- 为什么拆分core-service? 封装低代码搭建的所有通用能力(如Schema解析、组件渲染引擎等),让上层的BFF和前端应用无需关心复杂的内部实现细节。
- 编辑器如何设计? 采用轻内核、高扩展的插件化架构。内核只负责管理生命周期和全局状态,其余所有功能(如拖拽、图层、属性面板)都通过插件实现,确保核心稳定,功能灵活。
- 这里不过多探讨,本文主要侧重于ai研发工作流。
技术选型思考
- 后端语言:Go vs Node.js? Go在高并发、性能和内存占用上有先天优势。但本项目的重点在于探索AI能力,而非追求极致性能。同时,为了确保我能更好地驾驭AI,我选择了我更熟悉的Node.js生态。
- 框架:NestJS vs Koa? API网关、简单的接口服务可以用Koa。但对于这个中大型、业务逻辑复杂的系统,NestJS的模块化、依赖注入和面向切面编程(AOP)能力更胜一筹,因此选择NestJS。
- 数据库:MongoDB vs PostgreSQL? 核心业务数据(如用户、项目、页面)结构稳定、关联性强,选择PostgreSQL。而物料、Schema等更倾向于文档形态的数据,结构可能频繁变化,选择MongoDB。
- Monorepo工具:Turbo vs Rush? 超大型企业级项目、对依赖管理有极致要求的选择Rush。我的主应用层虽然复杂,但更追求现代化的构建速度和简洁的配置体验,因此选择了Turbo Repo。
- 状态管理:Redux vs Zustand? 除非是跨框架/跨应用的超大全局状态,否则绝大多数场景下,Zustand配合SWR就能以更少的代码量完美覆盖。因此,我们选择Zustand。
以上这些选型,你完全可以借助AI作为"高级XX工程师"来获得选型建议和论证。在这个过程中,你不仅能做出决策,更能学到背后的权衡逻辑,但前提是你必须保持思考,而不是一味采纳。
核心数据设计
- 数据表设计:我先根据需求设计出第一版,再让AI帮我完善字段、索引和关联关系。
- 数据协议(Schema)设计:这是整个低代码系统的核心。整个系统的价值,就在于编辑器能否方便快捷地输出这份Schema,而C端能否高性能、高还原度地渲染这份Schema。
我设计的核心Schema结构如下:
js
{
"id": "comp_id_xx",
"type": "VideoPlayer",
"props": {}, // 组件属性
"actions": {}, // 组件事件,支持一些JS纯函数的执行
"style": {}, // 组件样式,主要控制布局和整体风格
"elementStyles": { // 复杂组件内部元素的样式配置
"playButton": {} // 例如,播放按钮的样式
}
} 在AI时代,Schema的生成不再高度依赖拖拉拽,完全可以交给AI来完成。因此,在Schema设计上,我们要考虑让AI更容易理解,例如使用更语义化的字段名。未来,90%的低代码搭建操作将由AI完成,拖拉拽将退化为高级功能,仅用于人工微调细节。
技术方案落地
当核心设计完成后,就可以借助AI生成完整的、可落地的技术方案。
markdown
**提示词示例:**
请基于以下需求和技术背景,为我生成一份完整、可落地的后端技术方案。请以资深后端架构师的视角输出,使用Markdown格式,内容需具体、可执行。
【需求摘要】
(粘贴PRD中的核心功能、业务流程、非功能性需求摘要,或用简洁语言描述)
【技术选型与框架】
- 开发语言/框架:[例如 Java 17 + Spring Boot 3.x]
- 数据库:[例如 MySQL 8.0 + MyBatis-Plus]
- 缓存:[例如 Redis 7.x]
- 消息队列:[例如 RocketMQ / Kafka]
- 部署环境:[例如 Kubernetes / 阿里云ECS]
- 其他中间件:[例如 Elasticsearch、MinIO]
【约束与要求】
- 性能指标:[如 QPS ≥ 2000,接口响应时间 ≤ 200ms]
- 数据一致性:[如最终一致性/强一致性]
- 安全要求:[如接口防刷、敏感数据加密]
- 已有系统集成:[说明需要与哪些内部系统对接]
请按以下章节输出详细技术方案:
1. **总体架构设计**
- 系统架构图(使用Mermaid语法绘制分层架构或微服务拓扑)
- 模块划分及职责说明(核心模块、支撑模块)
- 关键技术选型理由(简要说明为什么选择这些技术)
1. **核心模块详细设计**
- 针对【列出2-3个核心业务模块】分别描述:
- 模块内部类/组件职责
- 核心流程时序图(Mermaid)
- 关键业务逻辑处理步骤
1. **API接口设计**
- 接口风格:[RESTful / GraphQL / gRPC]
- 统一响应结构示例
- 核心接口列表(至少覆盖主要功能,包含:接口路径、方法、请求参数、响应示例、权限要求、限流策略)
1. **数据库设计**
- ER图(Mermaid erDiagram)
- 核心表结构(表名、字段、类型、索引、说明,至少5张核心表)
- 数据分库分表策略(如需要)
- 数据归档与清理策略
1. **关键技术方案**
- 缓存设计(哪些数据缓存、更新策略、穿透/雪崩应对)
- 消息队列应用场景(解耦、削峰、异步处理的具体场景)
- 分布式事务方案(如适用)
- 定时任务/调度设计
- 文件/对象存储方案
1. **非功能性设计**
- 高可用设计(多活/主备、故障转移)
- 可扩展性设计(水平扩展、微服务拆分原则)
- 安全性设计(认证授权、数据加密、防攻击)
- 监控与告警(关键指标、日志规范)
1. **部署与运维**
- 容器化与编排(Dockerfile要点、K8s部署清单概览)
- 环境配置管理(环境变量、配置中心)
- 发布策略(灰度发布、回滚机制)
1. **风险评估与应对**
- 技术风险(如性能瓶颈、依赖单点)
- 应对措施
要求:
- 每个设计决策需附带简短的"为什么"说明。
- 数据库索引必须明确,避免全表扫描。
- API示例需包含错误码设计。
- 如涉及外部依赖,需说明集成方式。- 产出:一份完整系统的技术方案和每个子系统的详细技术方案。一份整体的技术方案能让AI时刻明晰当前开发的模块在整个系统中的角色和位置,从而保证产出的代码更符合整体设计。
UI设计
为了保证系统整体风格一致,纯粹的"自然语言"控制UI细节是困难的,因此UI设计环节必不可少。
- 确定设计语言:首先确定一个主题色,然后让AI基于此生成一套完整、规范的配色方案,奠定整体设计语言。
- 生成原型:使用画板绘制草图,大致说明模块布局,并辅以自然语言描述。然后将这些输入给Cursor,让它生成一个完整的HTML文件。可以多尝试几次,从中挑选最满意的一个作为UI参考。
- 指导开发:在后续系统实现时,将这个HTML文件作为UI参考提供给Cursor,它能生成高度一致的真实页面,确保UI的完美呈现。
需求实现:AI Coding的战场
下面介绍我在这场实战中使用的AI编程工具和核心工作流。
- Cursor:订阅了Pro版,20美元/月,但因为用超了(主要是GPT和Opus模型成本较高),当月总花费约50美元(约合人民币350元)。
- OpenClaw:在Coze平台搭建,每月49元,获得40万积分。积分消耗也很快,主要使用的是Kimi 2.5模型。
一句话总结我的分工策略:Cursor + Speckit 负责开发后端服务和编辑器(复杂度高);OpenClaw + GSD 负责开发管理端(相对简单)和物料库。
Cursor + Speckit 工作流
Speckit是一个强大的工具,能将复杂的开发流程转化为结构化的指令,非常适合与Cursor协同工作。如果你的预算充足,推荐使用Opus 4.6或GPT 5.4模型;若预算有限,Kimi 2.5也是不错的选择。
-
初始化项目 :首先安装Speckit,并在项目根目录执行初始化命令。
bash specify init . --here --ai cursor-agent --force -
制定项目宪章 :通过
/speckit.constitution定义项目的核心原则、编码规范和架构约束。重点:在此说明本服务在整个系统中的地位,例如"这是一个低代码搭建系统的核心服务,整体架构是......,本服务的职责是......"。
-
功能规格 :使用
/speckit.specify粘贴需求文档,并附上UI文件路径及对应的模块信息,明确要"做什么"。 -
澄清模糊点 :使用
/speckit.clarify让AI指出需求中不明确的地方,并一一作答,确保需求无歧义。 -
生成技术方案 :使用
/speckit.plan粘贴我们之前准备好的技术方案,让AI生成可执行的计划。 -
拆解任务 :使用
/speckit.tasks让AI自动将计划拆解为可执行、可排序的任务列表。 -
一致性分析(复杂项目推荐) :对于编辑器这类复杂项目,可以使用
/speckit.analyze检查需求、计划和任务是否对齐。 -
编码实现 :最后,使用
/speckit.implement让AI按照计划和任务列表开始编码。
后续功能迭代流程:
所有变更,坚持"先改Spec,再改代码"的原则:
/speckit.specify:追加新功能、设计稿或验收标准。/speckit.clarify:自动检查新需求是否有歧义。/speckit.plan:自动生成或手动描述具体实现方案。/speckit.tasks:自动规划新任务的实施步骤。/speckit.implement:实现新功能。
OpenClaw + GSD 工作流
将你的GitHub用户名和临时Token提供给OpenClaw,它就能帮你创建仓库、推送和拉取代码。
- 对齐规范 :向OpenClaw明确开发规范。例如,每次开发都必须从主分支拉取新分支,完成后生成Pull Request (PR)链接。为此,我制作了一个
GitHub开发规范的Skill,可以共享给多个OpenClaw实例使用。 - 准备依赖数据 :确保OpenClaw能访问必要的接口文档。如果后端服务在本地,无法公网访问,可以导出一份接口文档发给它。要求OpenClaw在开发时严格依据文档进行Mock,并提供一个开关,方便后续切换到真实数据进行联调。只要文档准确,联调通常非常顺利。
- 安装GSD:让OpenClaw安装GSD(get-shit-done)工具,用于任务管理。
- 分发任务:将需求文档和技术方案发给OpenClaw,并用GSD生成具体的执行任务列表。
- 编码实现:让OpenClaw严格按照任务列表,一步一步编码实现。
- 实时预览:在开发过程中,可以要求OpenClaw打开浏览器,让你实时查看页面效果,及时反馈调整。
- 代码审查:开发完成后,OpenClaw会将PR链接发给你,进行代码审查和合并,完成闭环。
总结与展望
以上就是近期对AI Coding在复杂项目中应用的探索与实践。从项目启动、技术设计到编码实现,AI已经深度参与其中,并展现了惊人的效率。在不久的将来,开发范式将是 "人负责架构审美和业务价值的判断,AI负责实现与执行。" 所谓的母语编程时代即将到来!
在后续的系列文章中,我将继续探索AI在项目全生命周期中其他环节的应用,例如:
- 端到端测试:特别是复杂Bug的修复。
- 项目部署与运维:实现自动化的CI/CD和智能监控。
- AI在业务中的赋能:例如开发一个"页面搭建智能体"或"营销推广智能体",让AI直接服务于最终业务。
欢迎大家一起交流学习,共同探索AI时代的研发新范式。
(标题说的7天,是按每天8小时工时算的大概7天,实际上是利用下班时间零碎搞了差不多一个月)