写在前面
上下文切换因为会导致消耗大量的CPU资源,导致CPU升高,所以上下文切换也是最常见的性能杀手之一。本文就一起来看下这部分内容吧。
1:基础内容介绍
1.1:什么是上下文切换?
CPU在执行的时候需要两部分的内容,寄存器中要执行的程序信息,以及程序计数器中执行的位置信息。这两部分内容也就是所谓的上下文。在执行的过程中比如从一个线程切换到另外一个线程执行,那么寄存器,和程序计数器中的信息就需要替换为要执行的线程的。这个过程我们就叫做上下文切换。其中,老线程的上下文下信息会被暂存到内核中,以待下次运行使用。
注意这个切换的过程是要消耗CPU资源的,并且此期间CPU是干不了活的。
2.1:常见的上下文切换有哪些类型?
2.1.1:进程上下文切换

进程是操作系统调度的基本单元,拥有独立的虚拟内存等资源信息,所以进程的上下文切换,除了要切换CPU寄存器,程序计数器的信息外,还需要切换虚拟内存等资源信息。所以进程上下文切换的成本是比较高的。但是对于实际的线上环境部署,现在一般都是使用docker部署的,不考虑系统进程的话只会有一个应用进程在跑,所以出现问题一般不会是进程上下文切换导致的。
2.1.2:线程上下文切换
线程的上下文切换是我们需要重点关注的,线上出现的上下文切换问题一般都属于线程上下文切换。
线程的上下文切换就是要暂存CPU寄存器和程序计数器的的内容到内核中,并加载新线程的程序信息到寄存器和计数器中。当然这里是属于同一个进程内的两个线程的上下文切换的情况。另外一种情况是属于不同的进程的线程的上下文切换,这种其实就是进程的上下文切换了,不用过多关注。
所以,线程的上下文切换其实是比进程的上下文切换有优势的,所以一般现在开发的都是单进程,多线程的程序,而非多进程程序了。
2.1.3:中断上下文切换
当CPU收到了来自硬件的中断信号后,也会暂存当前的执行信息,转而执行中断程序,比如获取来自网卡的网络信息,或者是来自键盘的录入信息等。中断的优先级是高于进程优先级的,所以可以暂停进程的执行。
CPU根据中断信号中携带的信息,可以查找到需要执行的中断程序。
最后还有系统调用也会引起上下文切换,因为系统调用后就会从用户态切换到内核态运行,所以肯定是会发生上下文切换,以及,系统调用完成后,重新从内核态切回到用户态,如下图:
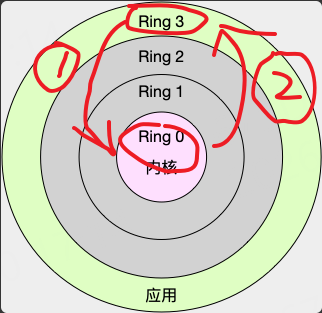
注意这里Ring1和Ring2在Linux中没有用到。
但是,因为不会切换到其他线程,也不会切换到其他进程,所以系统调用的过程我们一般称之为特权模式切换,而非上下文切换,但要知道会引起上下文切换这点,因为也是个潜在的问题(比如程序频繁的调用file.read()也是可能出现问题的)。
3:案例演示
我本地是单核的虚拟机环境,如果你配置比较高,可以适当调节参数,以便更好的看到实验效果。
没有实际的案例演示,就看不到实际的效果,看不到实际的效果,就会总会有种空中楼阁的感觉。所以这部分就来看下实际的案例演示。
开始之前,先来看下正常情况的指标:
root@dongyunqi:/home/dongyunqi# vmstat 1 1
procs -----------memory---------- ---swap-- -----io---- -system-- -------cpu-------
r b swpd free buff cache si so bi bo in cs us sy id wa st gu
1 0 0 874696 65436 726536 0 0 2 5 49 13 0 1 99 0 0 0此时cs列的值是13,是比较小的。接着开始实验。执行命令sysbench --threads=10 --max-time=300 threads run模拟十个线程执行:
root@dongyunqi:/home/dongyunqi# sysbench --threads=10 --max-time=300 threads run
WARNING: --max-time is deprecated, use --time instead
sysbench 1.0.20 (using system LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 10
Initializing random number generator from current time
Initializing worker threads...
Threads started!看下此时cs情况:
dongyunqi@dongyunqi:~$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- -------cpu-------
r b swpd free buff cache si so bi bo in cs us sy id wa st gu
4 0 0 873196 65448 726540 0 0 2 5 49 13 0 1 99 0 0 0
6 0 0 873196 65448 726540 0 0 0 0 1011 215835 17 83 0 0 0 0
6 0 0 873196 65448 726540 0 0 0 0 1010 236680 19 81 0 0 0 0
7 0 0 873196 65448 726540 0 0 0 0 973 227112 18 82 0 0 0 0
5 0 0 873196 65448 726540 0 0 0 0 1008 232630 16 84 0 0 0 0
^C已经飙升到20万+,效果很明显了。而且us sy两列加起来已经100%了,说明此时CPU已经跑满了,并且大部分都是sys即内核占用的,可以top来看下CPU:

查看是哪个进程导致的cs升高:
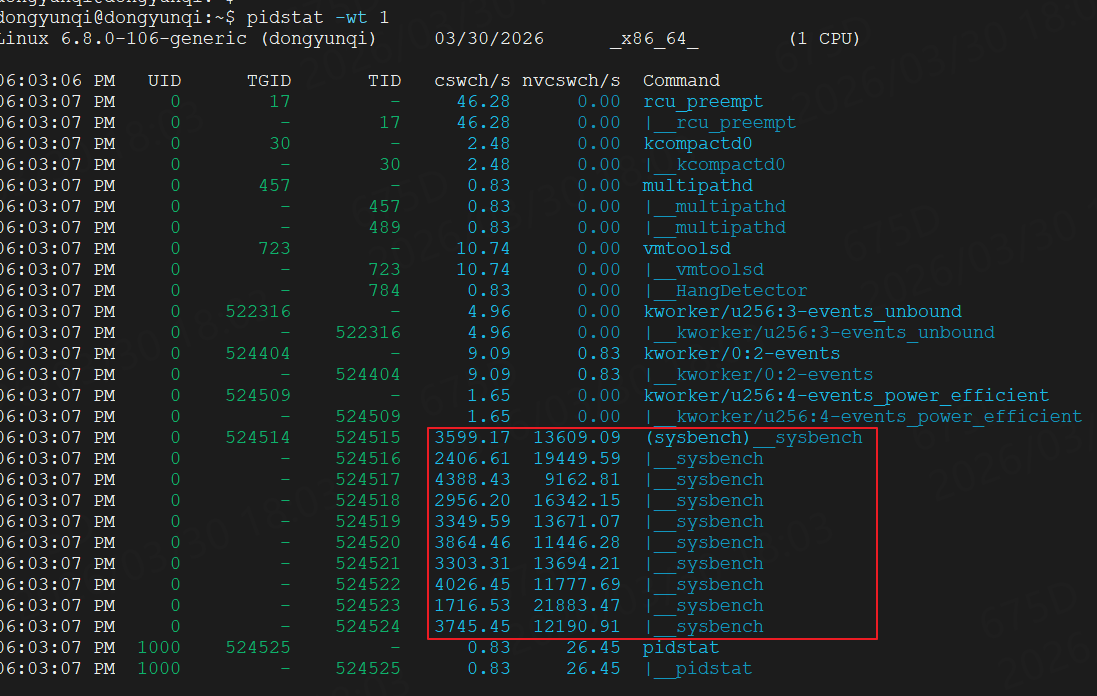
可以看到是sysbench。
写在后面
参考文章列表
上下文切换分析 。