多媒体中台在 B 站主要负责剪辑、拍摄、直播等业务场景的动效渲染,开发维护的 SDK 在后文统一称为特效 SDK。
传统的视频特效生产一般分三条链路:
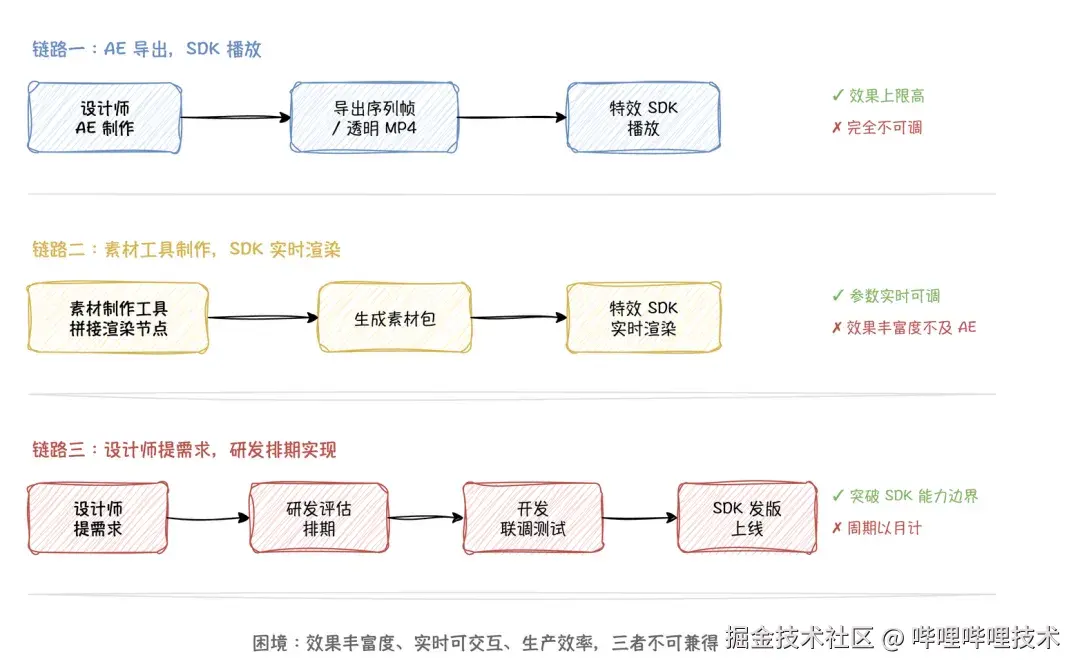
三条链路存在一个困境:效果丰富度、实时可交互、生产效率,三者不可兼得。
那么能不能让 AI 直接生成可实时预览并支持调参的动效?
"用自然语言描述需求、AI 生成可控动效"的模式我们称之为 Vibe Motion。我们沿着这个方向做了 Neon Vibe Motion:一个开源的基于 LLM 动效生成与实时控制平台。用自然语言描述你想要的效果,LLM 生成可执行的渲染代码和可调参数声明,在 HTML5 Canvas 上实时预览,调到满意后导出视频或独立网页。Neon 不绑定特定模型,支持任何兼容 OpenAI Chat Completions API 的 LLM。

相关工作
这个方向上已有很多人同时在探索,有同样困境的不止我们一家。
总结下来AI 驱动的动效生成目前有两条路线。
- 像素生成------文生视频,以 Sora、Veo、Seedance 等 AI 视频生成模型为代表,输入文本或图片,输出视频文件。这类模型擅长写实画面和影视级内容,但产出的是像素数据,生成完就不可编辑。
- 代码生成------LLM 输出可执行的渲染代码,产出的是可编辑、可参数化的动效程序。Neon 属于后者。
代码生成MG路线上,值得讨论的有两个产品:
Higgsfield Vibe Motion 是一个商业产品,与 Anthropic 合作,基于 Claude 模型,通过对话生成渲染代码来制作动效。支持实时编辑和参数调整,按 credit 付费。
Remotion 是一个开源的 React 视频框架,用 React 组件定义视频的每一帧。Remotion 官方已经提供了完整的 AI 集成方案:面向 LLM 的 system prompt、模块化的 skills 系统、以及一个"Prompt to Motion Graphics"的 SaaS 模板。
一、范式选择:结构化生成而非视频生成
AI做动效,第一个要回答的问题是:AI 应该输出什么?
最直觉的答案是让 AI 直接输出视频文件。然而当前的文生视频模型生成的视频动效存在明显的可控缺陷,视频生成完就固化了------颜色不对、速度太快、文字想改,都得重新抽一遍,没有任何迭代的连续性。而且贵。
我们选了另一条路:让 LLM 生成动效程序,而非视频文件。
但"动效程序"本身也有不同的形态。从我们当时的视角看,素材包至少有三种存在方式:
第一种:声明式配置包。 这是我们特效 SDK 链路二的做法。素材包是一份 JSON 配置,描述用哪些渲染节点、怎么连接、参数是多少。SDK 内部有一组预置的渲染能力(粒子发射器、模糊、色彩变换等),JSON 负责调度它们的组合。表现力的上限等于预置能力的并集------SDK 没有的能力,JSON 再怎么写都做不出来。
第二种:引擎脚本 + 自定义 Shader。 这是 Unity、Unreal、Cocos 等游戏引擎的做法。用户可以写脚本控制渲染逻辑,写 shader 控制像素级表现。理论表现力的上限等于 GPU 的上限。但代价是 API 面很复杂------脚本要遵守引擎的生命周期约定(OnUpdate、OnRender),shader 要遵守渲染管线约定(顶点格式、uniform 绑定、pass 定义)。写出正确代码的门槛很高。
第三种:可执行渲染代码。 这是 Neon 的做法。素材包里的 code 字段是一段完整的渲染函数,直接操作 HTML Canvas 2D context。没有预置原子的边界限制,也没有引擎管线的约定束缚。一个函数,一块画布,LLM 想怎么画就怎么画。

我们选可执行渲染代码, 原因很务实:LLM 写 Canvas 2D 的成功率远高于写引擎脚本 + shader。我们最初尝试过后者,结果不理想------渲染代码能成功执行的比例很低,而且 LLM 难以建立画面与代码之间的对应关系,它能写出语法正确的 shader,但不知道渲染出来长什么样。相比之下,LLM 训练数据中有大量 Canvas 2D API 示例,对"这行代码画出来是什么"有先天明确的认知。
这是当下验证方向的务实选择:先把链路跑通,验证可行性,再去搭建符合业务需求并且 AI friendly 的脚本引擎 + shader 脚手架。
同样走代码生成路线的还有 Remotion,但架构重心不同:
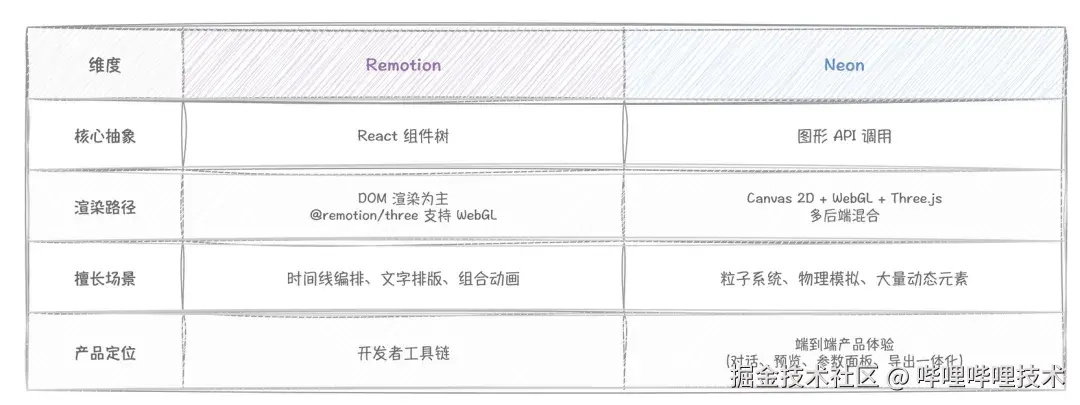
两者不互斥。Remotion 擅长的时间线编排恰好是 Neon 目前的短板,未来有可能引入 Remotion 做时间线编排层,底层保留图形管线。
顺着这个方案走下来,还有一个额外收获:素材包本身变成了自包含的。传统素材包离开 SDK 无法运行;Neon 的 MotionDefinition 自带渲染逻辑,一个 HTML 文件浏览器打开就能独立运行。
具体来说,MotionDefinition 包含:
-
code --- 可执行的 Canvas 2D 渲染代码。这段代码接收当前时间和参数,在每一帧绘制画面。
-
parameters --- LLM 根据效果语义声明的可调参数。比如一个赛博朋克风格的柱状图动效,LLM 会声明 primaryColor(主色)、barCount(柱子数量)、speed(动画速度)等参数,每个参数都有类型、默认值和取值范围。
-
duration / durationCode --- 动效时长。可以是固定值,也可以是一段表达式(比如根据视频素材的实际长度动态计算)。
-
postProcessCode --- 可选的 WebGL 后处理 shader 代码,用于叠加全屏效果(发光、模糊、色彩校正等)。
这个选择带来了几个直接好处。
- 实时可调。 用户拿到的是一个可运行的程序。拖动滑块改颜色,Canvas 上的画面立刻变化。
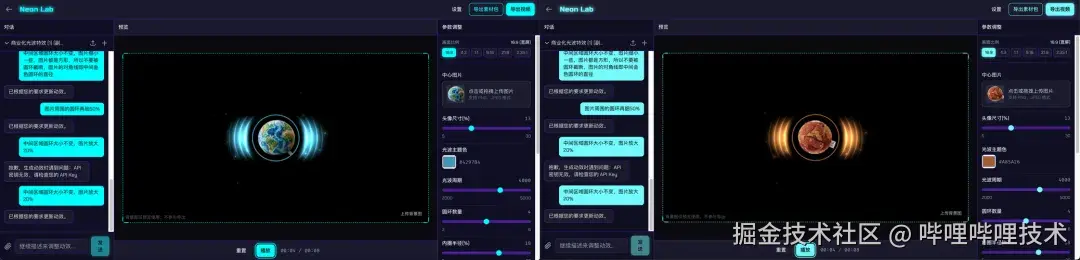
- 确定性输出。 在同一设备和浏览器环境下,相同的参数和相同的随机种子,产出逐帧一致的渲染结果。预览看到什么,导出就是什么。
- 多格式导出。 同一份 MotionDefinition,可以导出为 MP4 视频、零依赖的独立 HTML 网页、或包含完整对话和参数快照的 .neon 会话归档。一份代码,多种交付形态。
Neon 后续的架构------渲染引擎、参数系统、导出流水线------都围绕这个前提展开。
二、渲染引擎的演进
渲染引擎后面的几次演进,本质上都在平衡两件事:LLM 现在能稳定写出什么,和我们真正想要什么效果。
起步:Canvas 2D
第一版渲染引擎选了 Canvas 2D API,选型理由在上一章已经讲过。
对于我们的目标场景------扁平动效、数据可视化、文字动画、粒子系统------Canvas 2D 完全够用。更重要的是,生成的代码,设计师或前端开发者可以直接理解逻辑、手动微调,不需要图形学背景。
渲染循环的实现用 requestAnimationFrame 驱动,逐帧渲染,每帧调用 LLM 生成的渲染函数renderframe,传入当前时间戳、可调参数值和 Canvas Context。
后处理层:WebGL Shader
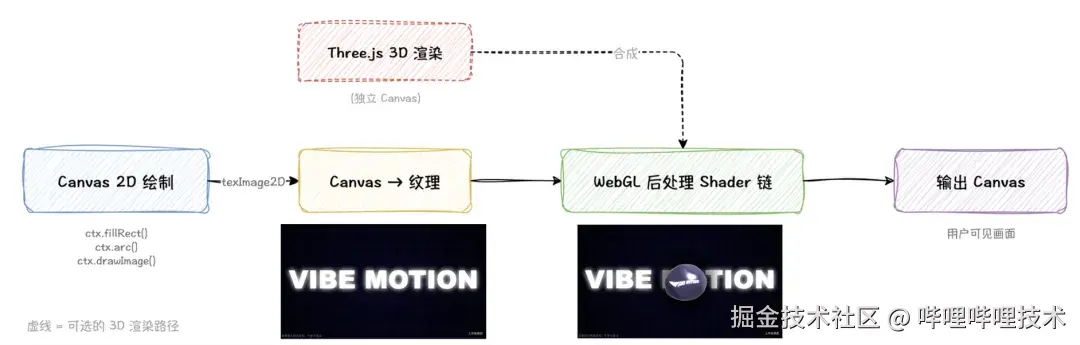
然而 Canvas 2D 的实际视觉表现力存在明显的天花板。例如纯 2D 绘图很难做出发光(bloom)、运动模糊、色彩分离这类全尺寸后处理效果。我们的方案是在 Canvas 2D 之上再叠加一层 WebGL 进行后处理。
此方案流程是:Canvas 2D 先画完一帧的内容,然后把整个 Canvas 作为纹理传给 WebGL,跑一遍全屏 shader 链(bloom、blur、色彩校正、畸变等),最终输出到用户可见的 Canvas 上。
至于后处理 shader 怎么来,我们探索过两条路:
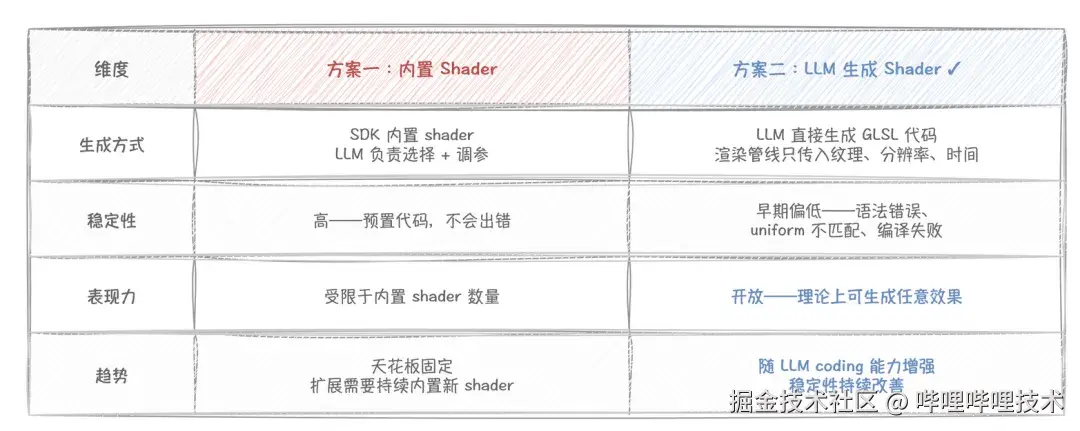
两种方案都支持用户拖动参数面板实时修改效果。随着 LLM 的 coding 能力持续增强,方案二的稳定性问题逐步缓解,最终保留了该方案。
3D 探索:Three.js
Canvas 2D 实践之后表现力天花板越来越明显。我们尝试引入 Three.js 来支持 3D 动效。
采用双 Canvas 方案------一个 Canvas 跑 2D 渲染,一个跑 Three.js 的 3D 渲染,最后 blend合成到一起。MotionDefinition 的格式可以保持不变,渲染函数的签名也一致,3D 场景只是多了一种渲染模式。
从我们目前的效果来看,3D 仍处于玩具水平。Three.js 本身能力很强,但尝试下来 LLM 生成的 3D 场景代码质量并不高------灯光、材质、相机角度的配合需要很强的美术直觉、设计感,这恰恰是纯文字的 LLM 的短板。
3D 是一个值得继续探索的方向,但目前还不是 Neon 的核心竞争力。如果要认真做 3D 动效,可能需要投入更多人力去搭建一套对 AI 更友好的 3D 脚手架、更丰富的渲染效果抽象层------降低 LLM 生成 3D 场景代码的门槛。
三层叠加后的完整渲染管线如下:
三、让 LLM 生成"能用"的代码
实践下来,单次 LLM 调用,一次产出代码能运行的概率在~90%,效果符合预期的概率在~20%。
动效代码对"能用"的定义很苛刻,不仅语法要对、运行不能报错、视觉效果要符合用户预期、性能不能太拉不然拖垮浏览器。任何一个环节出问题,给用户看到的就是开天窗,一个空白 Canvas 或一个无响应的页面。
要提升成功率,关键不在写更复杂的system prompt,而是在生成链路上加了多层质量门控。
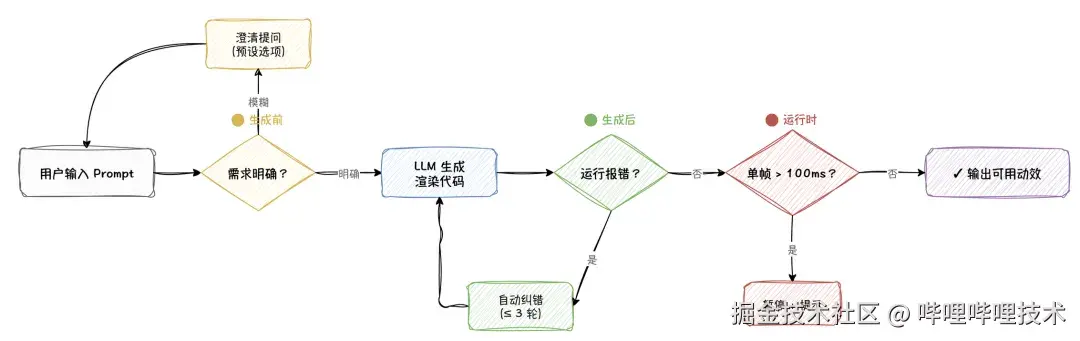
澄清:生成前先问清楚
用户说"做个炫酷的动画",LLM 怎么办?猜什么样的算炫酷。猜错了用户不满意,重新生成,再猜,再重试。这样几轮下来体验是很差的。
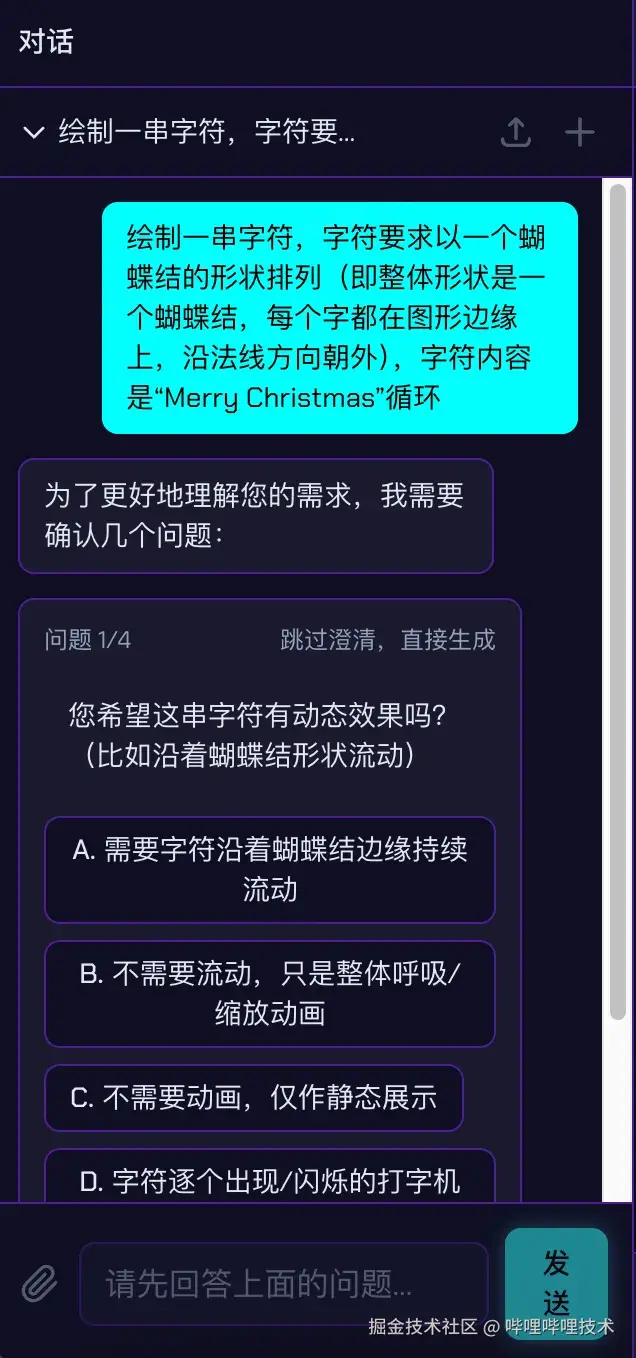
我们加了一个设计需求澄清环节。LLM 收到用户模糊需求 prompt 后,不马上生成代码,而是先提出 1 到 5 个定向问题,每个问题附带 3 个以上的预设选项。比如:
- "主色调想要什么?" --- 选项:赛博朋克蓝 / 暖金色 / 渐变彩虹 / 自定义
- "动画节奏?" --- 选项:缓入缓出 / 弹性 / 匀速
- "元素数量?" --- 选项:少量(3-5) / 中等(10-20) / 密集(50+)
用户点选或自定义回答之后,LLM 基于明确的需求再生成代码。预设选项降低了用户的输入成本------不需要精确描述,选一个最接近的就行。
自动纠错:生成后自动修
LLM 生成的代码经常有 bug。例如JavaScript语法错误、引用未定义的变量、Canvas API 调用参数错误等等。
一个方案是让用户看到报错信息,然后手动修改代码或重新描述需求。但我们的用户很大是不懂代码的设计师,看到红红的报错 TypeError: Cannot read properties of undefined 并不能帮助他们解决问题。
Neon 的方案是自我感知自动修复:检测到运行时异常后,把出错的代码和错误信息一起发回给 LLM,让它自己修。最多会尝试 3 轮。多数情况下,LLM 能在 1 到 2 轮内修好问题。在给足错误的具体位置和原因,修bug比写容易多了。
3 轮之后仍然失败的,就向用户展示错误信息和"重新生成"按钮。不无限重试,因为如果 3 轮修不好,大概率是一开始生成的代码方案本身有问题,需要用户换一种描述。
帧耗时检测:运行时兜底
还有一类问题是渲染卡顿。
LLM 偶尔会生成计算量爆炸的代码------循环嵌套太深、每帧创建大量对象、在 requestAnimationFrame 里做同步的cpu密集计算。单帧渲染耗时几秒甚至十几秒,页面完全卡死,用户只能强制刷新。
于是加了帧耗时检测:单帧渲染超过 100ms 就自动暂停,弹 toast 告诉用户渲染代码太卡。用户可以调参数降低复杂度,或者让 LLM 重新生成。
不同模型的生成效果
Neon 不绑定特定模型,支持任何兼容 OpenAI Chat Completions API 的 LLM。以下是不同模型对同一 prompt 的生成效果:
"Create a parallax timeline using floating glass cards. Glide smoothly through 3D space, bringing each milestone into sharp focus with a depth-of-field effect."

不同模型对 "parallax"(视差)、"depth-of-field"(景深)等空间效果的理解和实现程度不同,这也是我们前面提到增加了澄清环节的原因。
小结
三层门控各司其职:澄清收窄需求、纠错修复问题、性能检测兜底。与其追求"一次做对",不如接受 LLM 会出错,用工程手段快速纠正。
但三层门控只能保证"代码能跑",短板是分阶段渲染的缺失。Neon 目前生成的动效大多"所有元素同时动",而好的动效有清晰的阶段------进场、变换、退场。LLM 很难自发产生这种概念。
我们计划在 MotionDefinition 中增加 phases 显式定义,让 LLM 先规划阶段结构,再填充渲染逻辑。这与剪辑软件中 Clip 的概念类似。
四、描述规则而非画面
上一章解决的是"代码能不能跑"的问题。但还有一个更前置的问题:用户应该怎么写 prompt?
直觉上,动效的 prompt 和文生视频差不多------描述画面就好。但 Vibe Motion 的产出物是代码而非像素,这决定了 prompt 要传达的信息本质不同。

文生视频的 prompt 描述的是画面应该长什么样------构图、色调、光影、镜头运动。模型的任务是把文字翻译成像素。一个典型的文生视频 prompt:
"金色粒子在深色背景上爆炸,电影感,景深模糊"
它描述的是视觉结果。用户不关心粒子怎么运动,只关心最终画面好不好看。
Vibe Motion 的 prompt 描述的是动效背后的运动规则------元素怎么出现、怎么移动、怎么消失,受什么力、以什么速度衰减。因为 LLM 生成的不是像素,而是一段可执行的渲染程序,prompt 需要传达的是程序的行为逻辑:
"粒子从画面中心向外发射,初速度快然后逐渐减速,有轻微随机偏转,生命周期末尾透明度渐隐,整体受一个向下的重力影响"
它描述的是运动系统的物理规则:发射源、速度衰减、随机扰动、生命周期、外力。
这个差别直接决定了产出物能不能调参。文生视频的 prompt 描述外观,模型输出像素,像素没有"系数"可言,结果不可调。Vibe Motion 的 prompt 描述规则,LLM 把规则写成代码,代码里是数学公式------比如用户说"粒子向外扩散,逐渐减速",LLM 写出的大概是:
ini
velocity = initialSpeed * Math.pow(damping, t)这行公式里的 initialSpeed 和 damping 就是天然的可调参数。不是后加的,是公式本身的一部分。LLM 把它们声明到 MotionDefinition 的 parameters 里,用户拖滑块改的就是这些系数。
参数可调并不是后面硬加上的能力,而是这套范式顺出来的结果。既然 prompt 描述的是规则,代码里自然会落成公式;公式一旦出现,可调参数也就跟着出来了。
这也解释了第三章的澄清环节为什么会问"节奏""数量""速度"这类问题------它们不是在收集画面描述,而是在收集运动规则的关键变量。
Prompt 工程的方向也因此不同。文生视频的 prompt 工程围绕"描述力"------怎么用语言精确描述画面(加 negative prompt、加风格词、加镜头术语)。Vibe Motion 的 prompt 工程围绕"规则表达力"------怎么高效地传达运动规则。从实践来看,几类表述对 LLM 的代码生成质量影响明显:用物理直觉词汇("弹性碰撞""阻尼振荡")比用感性描述("看起来有弹性")精确;用阶段性描述("先聚集,再爆炸,最后飘散")比单一描述("粒子爆炸")能产出更有节奏的动效;用约束("速度不超过 200px/s,粒子数量 50-100")比用形容词("密集的快速粒子")更可控。
五、参数系统与实时控制
上一章讲了因果链:规则 → 公式 → 系数 → 参数。这一章看具体实现。
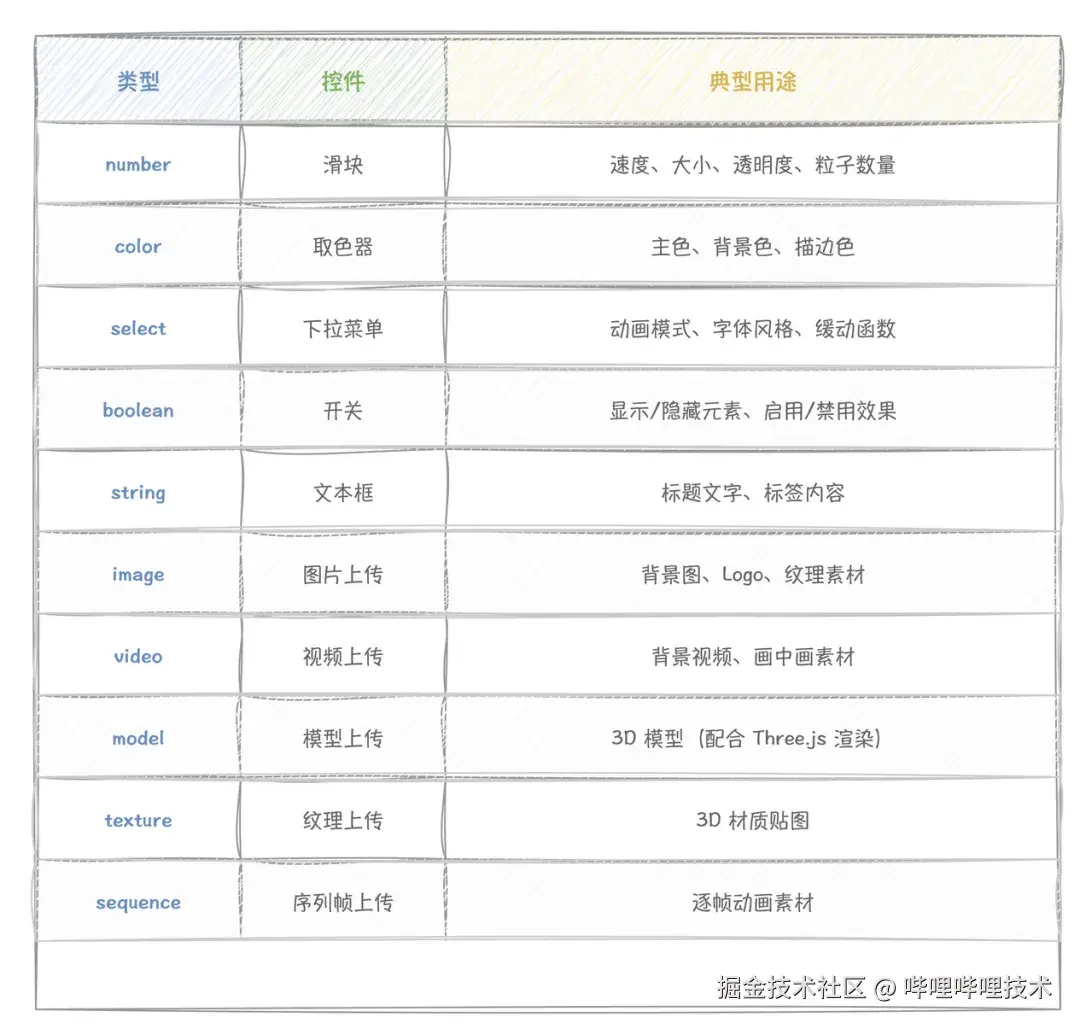
LLM 在生成 MotionDefinition 时,会根据效果的语义自动声明一组可调参数。我们支持 10 种参数类型:
参数的流转路径很直接:LLM 在 MotionDefinition 的 parameters 字段中声明参数的名称、类型、默认值和取值范围;前端根据声明自动生成对应的 UI 控件;用户在参数面板修改值后,新值立即注入渲染函数的 params 对象,Canvas 在下一帧就反映变化。
很多动效的时长不是固定的。比如一个视频转场效果,总时长取决于用户上传的视频有多长。如果在 MotionDefinition 中写死 duration: 5000,用户上传一个 10 秒的视频就会被截断。
我们的方案是 durationCode------一段在运行时求值的表达式。LLM 可以生成类似 Math.max(params.video1.videoDuration, params.video2.videoDuration) 的表达式,时长随素材变化自动调整。静态 duration 作为 fallback,durationCode 求值失败时兜底。
六、导出体系:从预览到交付
设计师最终需要一个可以交付的产物------视频文件、可嵌入的网页、或者能分享给同事的项目归档。
视频导出
视频导出是最直接的需求。我们在浏览器端完成编码,无需上传服务器。
导出流程是:创建一个离屏 Canvas,按目标帧率(24 / 30 / 60 fps)逐帧调用渲染函数,每帧提取像素数据送入编码器。确定性渲染在这里发挥作用------同样的参数和种子保证导出结果和预览完全一致。
我们还支持 Alpha 通道导出。输出是一个 ZIP 包,包含 RGB.mp4 和 Alpha.mp4 两个文件,设计师可以直接拖进 After Effects 或 Premiere 做合成。分辨率支持 720p、1080p 和 4K。
HTML 资产包
一键导出一个零依赖的单个 .html 文件,里面内嵌了渲染代码、资源文件和一个简单的参数面板。
用户可以选择暴露哪些参数。导出后这个 HTML 可以直接在浏览器打开、部署到 CDN、或者发给开发者做集成。不需要安装任何依赖,不需要搭建环境,双击就能跑。
实际场景中,设计师做完效果导出 HTML,丢给前端同事,前端看到实时效果后直接把代码集成进项目。这比传统的"设计师出设计稿 → 前端还原"流程更顺畅。
会话归档
Neon 的对话过程本身也是有价值的------prompt 怎么写的、LLM 做了什么澄清、参数调了几轮。这些上下文对复现和迭代都很重要。
.neon 会话归档文件把完整对话、当前 MotionDefinition、所有参数快照和附件打包成一个 JSON 文件。可以跨设备迁移、团队内共享,也可以做版本备份。支持批量导出多个对话到一个文件。
七、动效复刻:从视频到可编辑程序
设计师经常会遇到一个场景:看到一个喜欢的动效,想做一个类似的。传统做法是肉眼分析运动规律,然后在 AE 里手工重建------费时费力,而且重建出来的只是视觉上的近似,没有参数化的调整能力。
我们尝试用 VLM 自动化这个过程:用户上传一段参考视频,系统分析画面内容,生成可编辑的动效代码。这个方向经历了两个版本的探索。
第一版:全自动流水线
最初的思路很直觉------让 VLM 看视频帧,直接生成渲染代码,然后自动跑 5 轮迭代优化,每轮对比参考帧和渲染帧、修改代码、再对比。用户等着拿结果就行。
问题出在第一步。VLM 的分析质量不稳定,有时候对运动方向、元素数量、时间节奏的理解是错的。但这个错误对用户不可见------系统拿着错误的理解直接生成代码,然后在错误的基础上迭代 5 轮。迭代确实在"优化",但优化的方向是错的。5 轮 API 调用花出去了,结果和用户想要的效果毫无关系。
核心问题是:VLM 的分析质量不确定,全自动流水线放大了这个不确定性。
第二版:用户参与的分阶段流程
我们把"分析"和"生成"拆开,中间插入用户确认环节。
抽帧。 用户上传视频后,浏览器端从视频中均匀采样 16 个关键帧。
结构化分析。 16 帧发给 VLM,从 10 个维度提取特征:视觉元素的形状和数量、运动轨迹和缓动函数、时间阶段划分、背景类型、色彩方案、模糊和发光效果等。
核心特征精炼。 初次分析容易泛泛而谈------"有一些粒子在移动"。我们加了一轮精炼:VLM 从初次分析中识别出 1 到 3 个定义这个效果身份的核心视觉特征,评估初次描述是否足够精确,不够的就补充具体数值。比如"粒子"会被精炼为"约 80 个圆形粒子,半径 2-5px,从画面中心向外扩散,速度先快后慢,带高斯模糊拖尾"。
用户确认。 分析结果展示给用户。用户可以确认,也可以补充修正------比如"这不是粒子扩散,是烟花爆炸,先上升再炸开"。修正内容会和分析结果一起传给后续的代码生成环节。第一版没有这个环节,VLM 理解错了用户无从纠正,后续迭代全在错误方向上浪费算力。
代码生成与迭代优化。 确认后,系统基于分析结果和参考帧生成 Canvas 渲染代码,然后自动进入迭代优化------VLM 对比参考帧和渲染帧,找出差异最大的 2 到 3 个问题,针对性修改代码。每轮只修最突出的几个问题,不是全部,避免改一处坏三处。如果某轮迭代的分数下降,自动回退到最佳版本重新尝试;如果连续多轮分数持平,说明陷入了局部最优,系统会尝试更大幅度的改动来跳出当前方案。
两版的核心差异

从我们的尝试来看,第二版在简单动效(粒子、渐变、几何变换)上的复刻效果还不错,时间线排布上也有明显好转------元素的进场、变换、退场节奏更接近原始效果。复杂动效仍然差距明显。

另外我们也意识到:逐像素复刻在现阶段是ROI很低的目标。就目前的模型能力而言,LLM 没有像素级的视觉精度,高保真复制不是它擅长的事。批量生成多个变体再从中挑选,才应该是它的主要发力点。
八、Neon Skill:从 GUI 到 Agent Skill
Neon Lab 是面向设计师的交互形态------对话、预览、调参、导出,全在浏览器里完成。但我们希望动效生成能力也能脱离 GUI 使用。
我们把 Neon 的动效生成能力封装成了 Claude Code 的 Skill。核心动机有下面两个。
一个是复用 Claude Code 的工程能力。Neon Lab 里的Agent设计比较简单, LLM 调用是孤立的,每次对话只有用户的 prompt 和系统预设。但在 Claude Code 里,LLM 能看到整个动效项目的文件结构、读取相关代码、理解当前环境上下文。比如用户说"给这个 dashboard 做一个数据加载动画",Claude Code 可以先读 dashboard 的代码,理解数据结构和配色方案,再生成风格匹配的动效。这种上下文感知能力,我们在浏览器里的 Neon Lab 很难做到。
更关键自我迭代能力。多轮对话中,LLM 能关注到用户之前的偏好:"不要紫色""动画速度偏快""粒子数量不要太多"。生成动效后,Claude Code 会调用渲染工具输出视频,自己看效果,不满意就改代码、再渲染、再比对,多轮迭代直到符合预期。
第二个是面向 Agent 的工具接口。比如你让养的🦞(OpenClaw)为某个视频添加动效时,直接调用这个 Skill 就行,不需要通过繁琐的 GUI 交互。动效生成的消费者从设计师逐渐扩展到AI Agent。
同一个渲染引擎,两个前端
Neon Lab 通过网页内的 LLM 调用生成渲染代码,Neon Skill 通过 Claude Code 这类Coding Agent生成渲染代码。目标和结果一致,过程不同。
整个系统拆成三个独立产物:
- 渲染 bundle --- 从 Neon Lab 的渲染模块独立打包出来的一份 HTML + JS。包含 Canvas/WebGL 渲染器、H.264 编码器等所有运行时依赖。
- CLI 渲染工具 --- 一个 Node.js 命令行工具,内置渲染 bundle。通过 Playwright 启动 headless Chrome,加载渲染 bundle,注入 MotionDefinition,逐帧渲染并编码输出 MP4。
- Skill 指令文件 --- 指导 Coding Agent 怎么生成
.neon文件、调用 CLI 渲染。
其中 .neon 文件是通用草稿。GUI 里生成的效果可以导出 .neon,在 CLI 里渲染;CLI 产出的 .neon 也可以拖进 GUI 里预览和调参。
Skill 的组成:不只是一段 prompt
Neon Lab 的 system prompt 是一段很长的提示词,把渲染规范、参数格式、示例代码全揉在一起。这在WebUI 对话框里勉强能用,但对 Claude Code 来说并不是好的做法。 Skill 应该是模块化的参考文档,Coding Agent按需加载。
于是我们把 system prompt 拆解成了几份独立的参考文档:
- SKILL.md --- 入口文件,定义 Skill 的触发条件和工作流程
- CANVAS-GUIDE.md / WEBGL-GUIDE.md / POSTPROCESS-GUIDE.md --- 三种渲染模式的代码编写规范
- PARAMETERS.md --- 10 种参数类型的声明格式
- EXAMPLES.md --- 完整可运行的动效示例
Claude Code 在生成动效时,先读取 SKILL.md 理解整体流程,再按需加载对应的渲染规范。不需要每次都把所有prompt指令塞进上下文。这在长对话中尤其重要,避免 context window 被无关的规范文档占满,影响LLM的注意力,提升模型性能。
CLI天生适配动效复刻的需求
第七章讲的动效复刻,在 GUI 里依赖浏览器端抽帧和 VLM 对话。我们在 CLI 端也做了一套复刻 Skill,思路一致但交互方式不同。
CLI 复刻的流程是:用 FFmpeg 从参考视频中抽取key帧,Claude Code 分析后为每个动画阶段提取"灵魂特征"。提取的特征不是像素级别描述文本,而是可量化的运动指标(例如运动方向、缓动曲线、空间变化幅度等)。在生成初版 .neon 后渲染出视频文件,把原始key帧和渲染帧拼成对比图,喂给 Claude Code进行逐阶段比对,每轮只改差异性最大的问题。
和 GUI 复刻相比,CLI 的优势在于 Claude Code 能直接读写文件、调用脚本、管理多轮迭代的目录结构。
写在最后
这些技术选型其实都可以换掉:Canvas 2D、WebGL、Three.js、h264-mp4-encoder,那 Neon 的核心是什么?
我们认为平台核心是 MotionDefinition,以及围绕它的上游能力:自然语言 → 运动规则 → 可执行代码 → 可调参数。其中渲染链路和导出格式可以看作适配层,可插拔不同的技术选型。
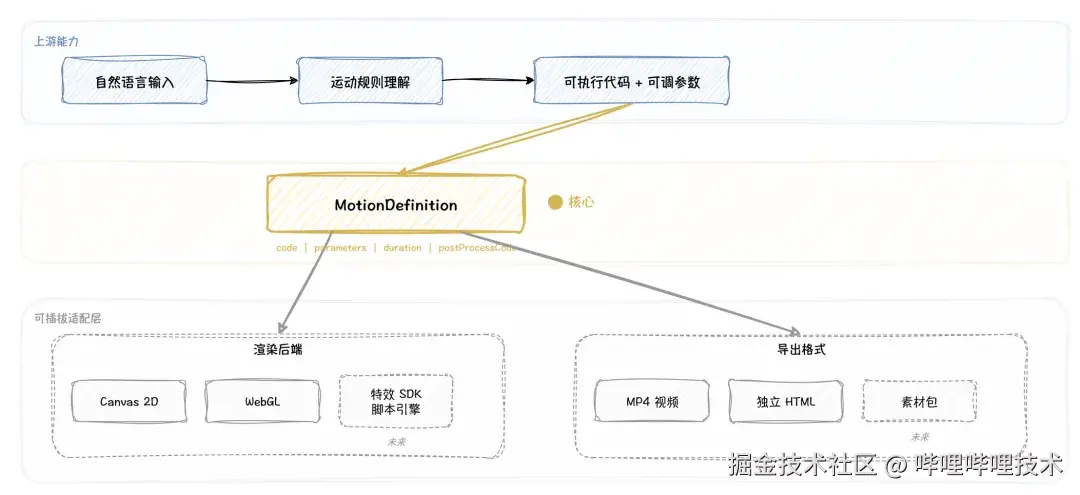
未来工作的重点:回到特效 SDK 本身,把它改造成更 AI Friendly 的脚本引擎 + shader 体系。
MotionDefinition 不变,变的只是下游渲染链路。不只是渲染后端可以换。
前面章节讲的澄清、纠错、分阶段复刻等环节,本质上都是在补偿当前模型能力的不足。随着基础模型持续迭代,这些 workflow 中的一部分必然会变得冗余。我们对此有预期,也乐见其成,workflow 越精简,其实用户体验越好。
Vibe Motion 作为一个品类才刚起步,天花板在哪,我们也不知道。
Neon 的基础版本已在 GitHub 开源,如果你也在探索类似的方向,欢迎一起交流~
项目地址:github.com/S1mpleSonny...
-End-
作者丨森破