摘要:在电商数据分析、竞品监控、商品比价、批量上架等场景中,淘宝商品的详情主图与SKU信息(规格、价格、库存、对应图片)是核心数据。手动下载主图、整理SKU信息效率极低,本文将详解3种全自动获取方案(API正规调用、Python爬虫实现、第三方工具批量采集),涵盖环境准备、代码实现、反爬应对、数据存储全流程,新手可直接复用代码,高效完成数据采集需求,同时规避平台反爬风险,兼顾合规性与实操性。
关键词:淘宝商品数据;主图获取;SKU采集;Python爬虫;淘宝API;全自动采集
一、前言
随着电商行业的快速发展,无论是电商运营、数据分析从业者,还是个人开发者,经常需要批量获取淘宝商品的详情主图(首图、轮播图)和SKU信息(如颜色、尺寸、价格、库存、SKU对应图)。手动操作不仅耗时耗力,且容易出现数据遗漏、格式混乱等问题,尤其面对上百、上千个商品时,全自动采集成为必然选择。
本文将针对淘宝商品详情主图+SKU信息的全自动获取,提供3种不同难度的实现方案,适配不同需求场景:API方案(合规稳定,适合长期使用)、Python爬虫方案(灵活定制,适合技术开发者)、第三方工具方案(零代码,适合非技术人员)。每种方案均附详细步骤和实操代码,确保大家能快速落地使用,同时重点讲解反爬机制应对技巧,避免账号或IP被封禁。
二、API测试
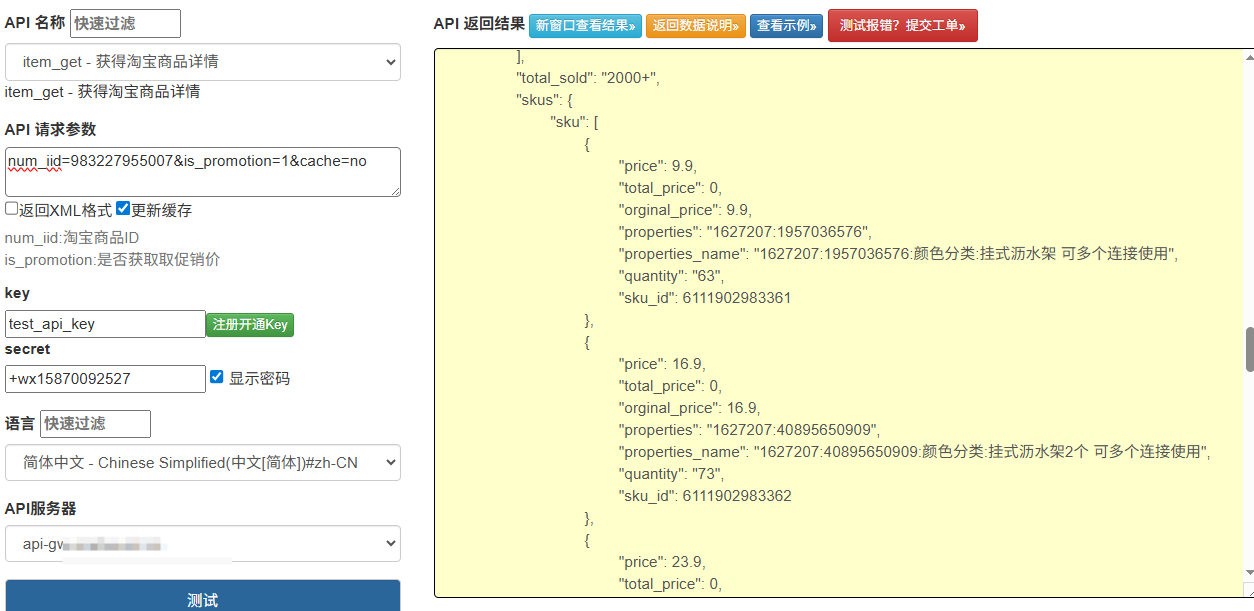
1、注册开发平台账号,获取api测试key和密钥
2、查看API文档,请求参数、响应参数
3、传参测试API
4、接收响应数据,检查数据是否准确
三、数据存储与后续处理
无论采用哪种方案,采集到的主图和SKU信息都需要进行合理存储和处理,便于后续使用:
4.1 数据存储方式
-
Excel/Csv:适合少量数据(几百个商品),便于查看、编辑和分享,本文代码中已实现导出Excel功能。
-
数据库:适合大量数据(上千个商品),推荐使用MySQL、SQLite等数据库,将SKU信息和主图URL存入数据库,便于后续查询和批量处理。
-
本地文件夹:主图图片建议按商品ID分类保存(如创建"商品ID_商品标题"文件夹,存放该商品的所有主图和SKU图),便于管理和查看。
4.2 后续处理技巧
-
主图下载:采集到主图URL后,可通过Python代码批量下载图片(使用requests.get()请求URL,保存到本地)。
-
数据去重:批量采集时,可能出现重复数据,可通过pandas的drop_duplicates()方法去重,或在数据库中设置唯一索引(如商品ID+SKU ID)。
-
数据清洗:清洗无效数据(如空价格、空规格),统一数据格式(如价格转为数值类型、库存统一单位),便于后续分析。
-
定时采集:若需要定期获取商品数据(如监控竞品价格、库存),可使用Windows任务计划、Linux Crontab,结合Python脚本,实现定时全自动采集。
四、常见问题与解决方案
在全自动获取过程中,可能会遇到各种问题,以下是常见问题及解决方案,帮助大家快速排查:
5.1 问题1:API调用失败,提示"授权失效"
解决方案:Session有效期已过,重新获取Session(通过淘宝开放平台授权流程);检查AppKey、AppSecret是否正确,应用是否审核通过。
5.2 问题2:爬虫爬取失败,提示"页面加载超时""IP被封禁"
解决方案:检查网络连接;更换代理IP;增加请求间隔;更新Cookie;关闭浏览器自动化检测配置;分批次爬取,降低请求频率。
5.3 问题3:采集到的主图是缩略图,不是高清图
解决方案:淘宝主图URL通常包含尺寸参数(如"_400x400.jpg""_50x50.jpg"),删除尺寸参数或改为"_800x800.jpg""_1000x1000.jpg",即可获取高清图;部分接口返回的主图URL本身就是高清图,可直接使用。
5.4 问题4:SKU信息缺失,无法获取部分SKU的价格、库存
解决方案:API方案:检查fields参数是否包含SKU相关字段,确保账号有获取SKU信息的权限;爬虫方案:确保模拟点击所有SKU选项,等待页面加载完成后再提取;部分商品SKU信息未公开,无法获取,属于正常情况。
5.5 问题5:第三方工具采集的数据不完整
解决方案:更新工具到最新版本;登录淘宝账号后再采集;检查商品URL是否正确;更换其他第三方工具尝试。