这篇文章是3D架构端到端立体匹配的开创者,时至今日,仍有很大的意义,例如IGEV,foundation stereo也使用了这种思路。
简单地说Dispnet是2D架构的开创者,相对于传统立体匹配的特征计算,gcnet使用的3D架构是在wh d也就是视差空间上做3D卷积,这里的就相对于传统立体匹配的代价聚合,能更好的在代价空间(cost valume)获取像素几何信息(geometry)和上下文信息(context)。
两者虽然都采用了编码与解码架构,但是很显然3D架构效果要优于2D架构,随着而来的问题是,3D架构内存和计算量很大,所以这里一直是3D架构的改进点,而之后raft stereo(2021)就是用迭代的思想避免了3D卷积,但是取得了比3D卷积更好的效果。IGEV(2022)立体匹配则是又把3D卷积加入了raft迭代视差(当然这是后话)。
GC-Net 网络结构详细分析
论文: End-to-End Learning of Geometry and Context for Deep Stereo Regression
作者: Alex Kendall et al., Skydio Research
会议: ICCV 2017
动机 :我们观察到,立体算法的许多具有挑战性的问题将受益于全局语义上下文的知识,而不是仅仅依赖于局部几何。例如,给定车辆挡风玻璃的反射表面,如果立体算法仅依赖反射表面的局部外观来计算几何形状,则它可能会出错。相反,理解该表面的语义上下文(它属于车辆)以推断局部几何形状将是有利的。在本文中,我们展示了如何端到端学习立体回归模型,并具有理解更广泛上下文信息的能力(这也是GCNet的目的)。
贡献 :本文的主要贡献是一种端到端深度学习方法,用于估计单个校正图像对中的每像素视差。我们的架构如图 1 所示。它通过形成成本量来明确地推理几何,同时还使用深度卷积网络公式来推理语义。我们通过两个关键思想来实现这一目标:• 我们学习直接从数据中合并上下文,采用 3-D 卷积来学习过滤高度 × 宽度 × 视差维度上的cost value,
• 我们使用soft argmin 函数,该函数是完全可微分的,并允许我们从视差成本量中回归子像素视差值。
目录
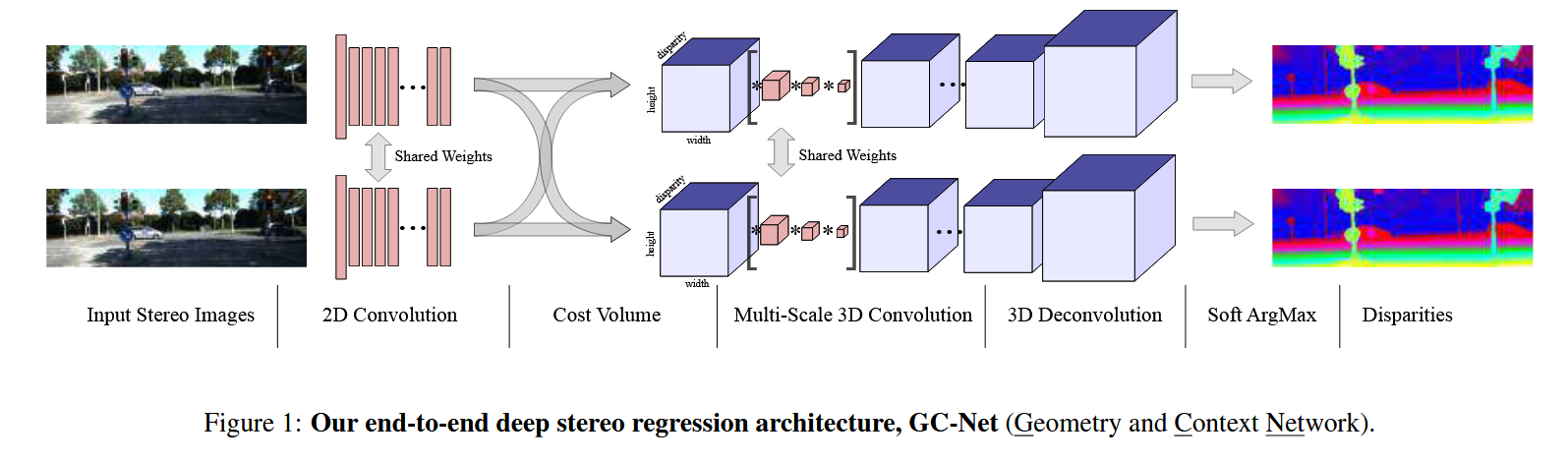
一、整体架构概览
1.1 端到端流程
GC-Net的完整端到端流程从左到右依次包含六个阶段:
输入立体图像对
↓
2D 卷积(一元特征提取,左右共享权重)
↓
代价体构建(Cost Volume)
↓
多尺度 3D 卷积(左右特征拼接,编码器)+ 3D 反卷积(解码器)
↓
Soft ArgMax(可微软 Argmin)
↓
视差图输出1.2 架构特点
- 左右两条对称的特征提取支路: 分别处理左图和右图
- 共享权重设计: 两路之间的权重完全相同,体现孪生网络结构
- 3D代价体: 在视差维度上呈现为一个三维体积(disparity × height × width)
- 沙漏结构: 多尺度3D卷积-反卷积进行上下文学习
- 可微输出: 通过Soft ArgMax逐像素输出视差
二、符号约定
| 符号 | 含义 |
|---|---|
| H H H | 输入图像高度 |
| W W W | 输入图像宽度 |
| C C C | 输入图像通道数(灰度为1,彩色为3) |
| F F F | 特征通道数,实验中 F = 32 F=32 F=32 |
| D D D | 最大视差值,实验中 D = 192 D=192 D=192 |
实验参数配置
| 数据集 | 参数设置 |
|---|---|
| Scene Flow | F = 32 , H = 540 , W = 960 , D = 192 F=32, H=540, W=960, D=192 F=32,H=540,W=960,D=192 |
| KITTI | F = 32 , H = 388 , W = 1240 , D = 192 F=32, H=388, W=1240, D=192 F=32,H=388,W=1240,D=192 |
三、模块一:一元特征提取
3.1 功能定位
一元特征提取模块的作用是:
- 将原始像素强度映射为对光度歧义更鲁棒的深度特征描述子
- 融合局部上下文信息
- 左右两幅图像分别经过完全相同、参数共享的网络处理
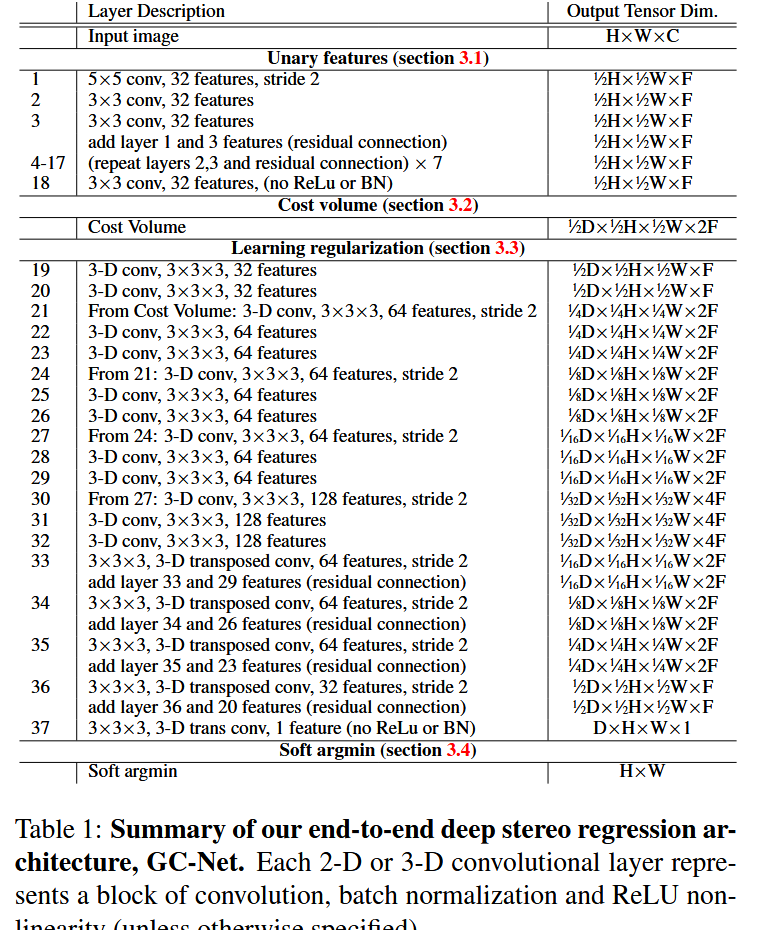
3.2 层结构详解
| 层编号 | 操作描述 | 输出张量维度 | 说明 |
|---|---|---|---|
| 输入 | --- | H × W × C H \times W \times C H×W×C | 原始图像 |
| 第1层 | 5×5卷积,32通道,stride=2 | 1 2 H × 1 2 W × F \frac{1}{2}H \times \frac{1}{2}W \times F 21H×21W×F | 初始下采样,分辨率降为原来的1/2 |
| 第2层 | 3×3卷积,32通道 | 1 2 H × 1 2 W × F \frac{1}{2}H \times \frac{1}{2}W \times F 21H×21W×F | 残差块第一个卷积 |
| 第3层 | 3×3卷积,32通道 | 1 2 H × 1 2 W × F \frac{1}{2}H \times \frac{1}{2}W \times F 21H×21W×F | 残差块第二个卷积 |
| 残差连接 | 第1层 + 第3层特征相加 | 1 2 H × 1 2 W × F \frac{1}{2}H \times \frac{1}{2}W \times F 21H×21W×F | 第一个残差块完成 |
| 第4--17层 | 重复(第2、3层 + 残差连接) × 7 | 1 2 H × 1 2 W × F \frac{1}{2}H \times \frac{1}{2}W \times F 21H×21W×F | 共8个残差块(第1个 + 重复7个) |
| 第18层 | 3×3卷积,32通道,无ReLU、无BN | 1 2 H × 1 2 W × F \frac{1}{2}H \times \frac{1}{2}W \times F 21H×21W×F | 最终一元特征输出层 |
3.3 关键设计说明
初始下采样(第1层)
采用步长为2的5×5卷积,同时:
- 提取局部特征
- 将分辨率降低一半
- 大幅减少后续计算量
重要: 这也是导致代价体本身处于半分辨率的原因。
残差块(第2--17层)
- 总数: 8个残差块
- 组成: 每个残差块由两个串联的3×3卷积组成
- 残差连接: 将输入直接加到输出上
- 作用:
- 缓解梯度消失
- 保留低层特征信息
- 激活方式: 每层卷积后均接 Batch Normalization + ReLU(除最后一层外)
最后一层无BN/ReLU(第18层)
这是一个重要的设计细节:
- 原因: 去掉最后一层的BN是为了允许网络自由学习代价值的缩放比例
- 效果: 即后续softmax的"温度"参数
- 目的: 使Soft argmin的概率分布趋向单峰,避免多峰分布导致的估计偏差
权重共享
- 左右两路完全共享同一套参数
- 好处: 强制网络学习对左右图像具有一致性的特征表示
- 作用: 有助于找到正确的像素对应关系
四、模块二:代价体构建
4.1 构建方式
对于每个视差层级 d ∈ { 0 , 1 , . . . , D m a x } d \in \{0, 1, ..., D_{max}\} d∈{0,1,...,Dmax},将左图特征图与右图向右偏移 d d d 个像素后的特征图在通道维度上拼接(concatenate):
Cost Volume ∈ R 1 2 D × 1 2 H × 1 2 W × 2 F \text{Cost Volume} \in \mathbb{R}^{\frac{1}{2}D \times \frac{1}{2}H \times \frac{1}{2}W \times 2F} Cost Volume∈R21D×21H×21W×2F
说明: 由于一元特征已被下采样2倍,视差维度也相应为 D / 2 D/2 D/2
4.2 为何用拼接而非距离度量
论文明确对比了三种代价体构建方式:
| 构建方式 | 特点 | 论文结论 |
|---|---|---|
| 特征相减 | 只保留差异信息 | 性能较差 |
| 距离度量(如点积) | 将特征维度压缩为标量 | 性能较差,丢失绝对语义信息 |
| 特征拼接(本文选择) | 保留完整的左右特征 | 性能最优 ✅ |
4.3 使用拼接的核心理由
- 保留绝对特征表示:而非仅保留相对差异
- 赋予语义学习能力:后续3D卷积可以对代价体中的特征一元项进行操作
- 网络能力对比 :
- 距离度量:只能学习"特征是否相似"
- 拼接方式:可以学习"这对特征属于什么语义类别"
五、模块三:3D卷积上下文学习
该模块是整个网络最复杂的部分,是一个在代价体上运行的三维编码器-解码器(Encoder-Decoder)结构。
5.1 为什么需要3D卷积
即使是深度特征,在无纹理区域(如天空、墙面)中:
- 代价曲线(cost curve)沿视差维度仍可能是平坦的
- 产生多峰分布
- 无法可靠地确定最优视差
解决方案: 3D卷积可以同时在 height、width、disparity 三个维度上建立感受野,利用空间上下文信息来"填补"这些模糊区域的视差估计。
5.2 编码器部分(下采样路径)
编码器共有4个下采样级别,每级有两个3D卷积:
| 层编号 | 操作 | 输出维度 | 说明 |
|---|---|---|---|
| 第19层 | 3D conv 3×3×3,32通道 | 1 2 D × 1 2 H × 1 2 W × F \frac{1}{2}D \times \frac{1}{2}H \times \frac{1}{2}W \times F 21D×21H×21W×F | 在代价体上的初始3D卷积 |
| 第20层 | 3D conv 3×3×3,32通道 | 1 2 D × 1 2 H × 1 2 W × F \frac{1}{2}D \times \frac{1}{2}H \times \frac{1}{2}W \times F 21D×21H×21W×F | 与第19层构成第0级(不下采样) |
| 第21层 | 3D conv 3×3×3,64通道,stride=2 | 1 4 D × 1 4 H × 1 4 W × 2 F \frac{1}{4}D \times \frac{1}{4}H \times \frac{1}{4}W \times 2F 41D×41H×41W×2F | 第1级编码器,分辨率降半 |
| 第22层 | 3D conv 3×3×3,64通道 | 1 4 D × 1 4 H × 1 4 W × 2 F \frac{1}{4}D \times \frac{1}{4}H \times \frac{1}{4}W \times 2F 41D×41H×41W×2F | |
| 第23层 | 3D conv 3×3×3,64通道 | 1 4 D × 1 4 H × 1 4 W × 2 F \frac{1}{4}D \times \frac{1}{4}H \times \frac{1}{4}W \times 2F 41D×41H×41W×2F | 第1级结束,特征保留用于残差 |
| 第24层 | 3D conv 3×3×3,64通道,stride=2 | 1 8 D × 1 8 H × 1 8 W × 2 F \frac{1}{8}D \times \frac{1}{8}H \times \frac{1}{8}W \times 2F 81D×81H×81W×2F | 第2级编码器 |
| 第25层 | 3D conv 3×3×3,64通道 | 1 8 D × 1 8 H × 1 8 W × 2 F \frac{1}{8}D \times \frac{1}{8}H \times \frac{1}{8}W \times 2F 81D×81H×81W×2F | |
| 第26层 | 3D conv 3×3×3,64通道 | 1 8 D × 1 8 H × 1 8 W × 2 F \frac{1}{8}D \times \frac{1}{8}H \times \frac{1}{8}W \times 2F 81D×81H×81W×2F | 第2级结束,特征保留用于残差 |
| 第27层 | 3D conv 3×3×3,64通道,stride=2 | 1 16 D × 1 16 H × 1 16 W × 2 F \frac{1}{16}D \times \frac{1}{16}H \times \frac{1}{16}W \times 2F 161D×161H×161W×2F | 第3级编码器 |
| 第28层 | 3D conv 3×3×3,64通道 | 1 16 D × 1 16 H × 1 16 W × 2 F \frac{1}{16}D \times \frac{1}{16}H \times \frac{1}{16}W \times 2F 161D×161H×161W×2F | |
| 第29层 | 3D conv 3×3×3,64通道 | 1 16 D × 1 16 H × 1 16 W × 2 F \frac{1}{16}D \times \frac{1}{16}H \times \frac{1}{16}W \times 2F 161D×161H×161W×2F | 第3级结束,特征保留用于残差 |
| 第30层 | 3D conv 3×3×3,128通道,stride=2 | 1 32 D × 1 32 H × 1 32 W × 4 F \frac{1}{32}D \times \frac{1}{32}H \times \frac{1}{32}W \times 4F 321D×321H×321W×4F | 第4级(最深层)编码器 |
| 第31层 | 3D conv 3×3×3,128通道 | 1 32 D × 1 32 H × 1 32 W × 4 F \frac{1}{32}D \times \frac{1}{32}H \times \frac{1}{32}W \times 4F 321D×321H×321W×4F | |
| 第32层 | 3D conv 3×3×3,128通道 | 1 32 D × 1 32 H × 1 32 W × 4 F \frac{1}{32}D \times \frac{1}{32}H \times \frac{1}{32}W \times 4F 321D×321H×321W×4F | 瓶颈层,感受野最大 |
感受野说明
由于一元特征已下采样2倍,加上编码器4个步长为2的下采样:
- 最终下采样因子: 2 × 2 4 = 32 2 \times 2^4 = 32 2×24=32,即特征下采样到原始分辨率的1/32
- KITTI数据集示例 ( H = 388 , D = 192 H=388, D=192 H=388,D=192):
- 最深层特征对应的感受野覆盖原图中约 388 / 32 ≈ 12 388/32 \approx 12 388/32≈12 个像素高度单元
- 但实际通过多层卷积叠加,感受野远大于此
- 能够覆盖整个场景范围
5.3 解码器部分(上采样路径)
解码器通过3D转置卷积 (3D Transposed Convolution)逐步恢复分辨率,并在每一级通过残差连接融合编码器对应层的特征:
| 层编号 | 操作 | 输出维度 | 残差融合 |
|---|---|---|---|
| 第33层 | 3D 转置卷积 3×3×3,64通道,stride=2 | 1 16 D × 1 16 H × 1 16 W × 2 F \frac{1}{16}D \times \frac{1}{16}H \times \frac{1}{16}W \times 2F 161D×161H×161W×2F | + 第29层特征 |
| 第34层 | 3D 转置卷积 3×3×3,64通道,stride=2 | 1 8 D × 1 8 H × 1 8 W × 2 F \frac{1}{8}D \times \frac{1}{8}H \times \frac{1}{8}W \times 2F 81D×81H×81W×2F | + 第26层特征 |
| 第35层 | 3D 转置卷积 3×3×3,64通道,stride=2 | 1 4 D × 1 4 H × 1 4 W × 2 F \frac{1}{4}D \times \frac{1}{4}H \times \frac{1}{4}W \times 2F 41D×41H×41W×2F | + 第23层特征 |
| 第36层 | 3D 转置卷积 3×3×3,32通道,stride=2 | 1 2 D × 1 2 H × 1 2 W × F \frac{1}{2}D \times \frac{1}{2}H \times \frac{1}{2}W \times F 21D×21H×21W×F | + 第20层特征 |
| 第37层 | 3D 转置卷积 3×3×3,1通道,stride=2,无ReLU、无BN | D × H × W × 1 D \times H \times W \times 1 D×H×W×1 | --- |
第37层特殊处理
- 输出通道数: 1(每个像素位置对应一条长度为D的代价曲线)
- 激活函数: 无BN/ReLU
- 输出内容: 原始代价值,供后续Soft Argmin使用
- 上采样作用:
- stride=2的反卷积将 1 2 D \frac{1}{2}D 21D 恢复到 D D D
- 将 1 2 H \frac{1}{2}H 21H 恢复到 H H H、 1 2 W \frac{1}{2}W 21W 恢复到 W W W
- 对齐原始输入分辨率
5.4 残差连接的作用
解码器中每次上采样后都与编码器对应层的特征相加(跳跃连接):
| 特征类型 | 特点 | 作用 |
|---|---|---|
| 上采样特征 | 感受野大,包含大范围上下文信息 | 全局语义理解 |
| 编码器高分辨率特征 | 保留了精细的空间细节和边缘信息 | 空间精细度 |
| 融合结果 | 既能利用全局语义上下文进行视差推断,又能保留物体边缘、薄结构等精细几何信息 | 避免视差图过度平滑 |
六、模块四:可微软Argmin
6.1 问题背景
传统argmin操作存在两个根本性缺陷:
- 输出离散性: 输出是离散整数,无法达到亚像素精度
- 不可微分: 无法进行端到端反向传播训练
6.2 Soft Argmin定义
对代价体中每个像素位置的代价向量 { c d } d = 0 D m a x \{c_d\}{d=0}^{D{max}} {cd}d=0Dmax,soft argmin定义为:
d ^ = soft argmin : = ∑ d = 0 D m a x d ⋅ σ ( − c d ) \hat{d} = \text{soft argmin} := \sum_{d=0}^{D_{max}} d \cdot \sigma(-c_d) d^=soft argmin:=d=0∑Dmaxd⋅σ(−cd)
其中:
- σ ( ⋅ ) \sigma(\cdot) σ(⋅) 为softmax函数
- − c d -c_d −cd 表示先对代价取负值转换为概率
- 代价越小,概率越大
6.3 计算步骤
1. 对每个视差 d 的代价 c_d 取负值 → -c_d
↓
2. 在视差维度上做 softmax → σ(-c_d)(归一化概率)
↓
3. 以概率为权重,对所有视差值 d 做加权求和 → 最终视差预测 d̂6.4 单峰 vs 多峰分布
| 分布类型 | Soft Argmin表现 | 解决方案 |
|---|---|---|
| 单峰分布 | 准确逼近真实argmin | --- |
| 多峰分布(双峰+平坦区) | 输出为各峰加权平均,出现偏差 | 依赖网络正则化使分布趋向单峰 |
| 多峰分布 + 预缩放 | 网络可学习对代价值进行缩放,使softmax更"尖锐" | 第18层不加BN,允许网络自由学习代价尺度 |
关键洞察: 这正是第18层(一元特征最后一层)去掉BN的根本原因。BN会将代价值归一化到固定量级,阻止网络学习控制softmax温度所需的任意缩放。
七、完整网络结构示意
左图 (H×W×C) 右图 (H×W×C)
│ │
└──────── 共享权重 2D CNN ─────┘
(第1-18层)
↓
左特征 ½H×½W×F 右特征 ½H×½W×F
│
代价体构建(拼接)
│
代价体 ½D×½H×½W×2F
│
┌──────────┴──────────────────────────────────────┐
│ 3D 编码器-解码器 │
│ │
│ 第19-20层: 初始3D卷积(½D×½H×½W) │
│ ↓ │
│ 第21-23层: 编码器级1(¼D×¼H×¼W),64通道 │
│ ↓ │
│ 第24-26层: 编码器级2(⅛D×⅛H×⅛W),64通道 │
│ ↓ │
│ 第27-29层: 编码器级3(1/16D×1/16H×1/16W),64通道 │
│ ↓ │
│ 第30-32层: 编码器级4(1/32D×1/32H×1/32W),128通道│
│ ↓ │
│ 【瓶颈】 │
│ ↓ │
│ 第33层: 解码器级3 + 残差(←第29层) │
│ ↓ │
│ 第34层: 解码器级2 + 残差(←第26层) │
│ ↓ │
│ 第35层: 解码器级1 + 残差(←第23层) │
│ ↓ │
│ 第36层: 解码器级0 + 残差(←第20层) │
│ ↓ │
│ 第37层: 最终3D反卷积,1通道,stride=2 │
└──────────────────────────────────────────────────┘
│
正则化代价体 D×H×W×1
│
Soft Argmin
│
视差图输出 H×W八、训练细节
8.1 训练配置
| 配置项 | 值 |
|---|---|
| 框架 | TensorFlow |
| 优化器 | RMSProp |
| 学习率 | 1 × 10 − 3 1 \times 10^{-3} 1×10−3(恒定) |
| Batch size | 1 |
| 输入裁剪 | 256×512(随机位置裁剪) |
| 输入归一化 | 像素值归一化至 − 1 , 1 -1, 1 −1,1 |
| 损失函数 | L1回归损失(仅在有标注的像素上计算均值) |
8.2 训练阶段
| 阶段 | 数据集 | 迭代次数 | 硬件 | 时间 |
|---|---|---|---|---|
| 预训练 | Scene Flow | ~150k | 单张Nvidia Titan-X | 约2天 |
| 微调 | KITTI | 50k | 单张Nvidia Titan-X | --- |
8.3 损失函数
L = 1 N ∑ n = 1 N ∥ d n − d ^ n ∥ 1 \mathcal{L} = \frac{1}{N} \sum_{n=1}^{N} \left\| d_n - \hat{d}_n \right\|_1 L=N1n=1∑N dn−d^n 1
其中:
- N N N 为有效像素数(有标注的像素)
- d n d_n dn 为真值视差
- d ^ n \hat{d}_n d^n 为预测视差
- ∥ ⋅ ∥ 1 \|\cdot\|_1 ∥⋅∥1 为L1范数(绝对值)
九、参数量与速度
9.1 不同架构变体对比
| 模块变体 | 参数量 | 推理时间 | 性能 |
|---|---|---|---|
| 仅一元特征(无3D卷积) | 0.16M | 0.29ms | 基准 |
| 单尺度3D上下文 | 0.24M | 0.84ms | 中等提升 |
| 完整GC-Net(层次化3D) | 3.5M | 0.95ms | 最优 ✅ |
9.2 关键观察
- 层次化3D结构相比单尺度3D:
- 参数量增加:约14倍(0.24M → 3.5M)
- 推理时间增加:几乎没有额外增加(0.84ms → 0.95ms)
- 性能提升:显著提升(MAE从7.27降至2.51像素)
结论: 通过多尺度特征分解,可以用相对较少的额外计算代价获得大幅的精度提升。
十、关键设计决策总结
10.1 设计决策对比表
| 设计决策 | 替代方案 | 选择理由 |
|---|---|---|
| 特征拼接构建代价体 | 特征相减 / 点积距离 | 保留绝对语义特征,赋予网络学习语义的能力 |
| 层次化3D编解码器 | 单尺度3D卷积 / 无3D卷积 | 大感受野获取全局上下文,计算开销低 |
| 解码器残差连接 | 纯上采样 | 融合高分辨率细节,保留边缘和精细结构 |
| Soft Argmin回归 | 硬分类 / 软分类 | 可微分 + 亚像素精度 + 端到端训练 |
| 一元特征最后层去掉BN | 保留BN | 允许网络自由学习代价值缩放(softmax温度) |
| 左右权重共享 | 独立权重 | 强制学习一致的对应特征表示 |
10.2 创新点总结
| 创新维度 | 具体创新 |
|---|---|
| 代价体设计 | 改进的特征拼接方式 + 保留绝对语义 |
| 3D上下文 | 层次化编码器-解码器 + 多尺度感受野 |
| 微分输出 | Soft Argmin可微的亚像素视差回归 |
| 权重共享 | 孪生网络架构,学习鲁棒的特征表示 |
| 细节保留 | 跳跃连接融合多尺度信息,避免视差平滑 |
总结对比:GC-Net vs DispNet
| 方面 | DispNet | GC-Net |
|---|---|---|
| 代价体构建 | 1D相关层 | 特征拼接 |
| 上下文编码 | 多尺度2D卷积 | 多尺度3D卷积 |
| 感受野 | 相对较小 | 大(三维) |
| 精度 | 接近SOTA | 更优 |
| 速度 | 快 | 相对较慢 |
| 语义学习 | 有限 | 更强 |
| 计算复杂度 | 低 | 高 |
| 出版年份 | 2016 | 2017 |