论文中首先提到,并不是所有的数据增强的方式都能提高模型性能,有的能够提高性能,有的会使模型性能减少,那着两者之间的不同点在哪里呢,于是作者使用频率的角度来解释这种差异性。
一、Fourier heat map

这一段其实是整篇论文最核心的方法,作者想回答的问题非常简单:CNN到底对哪些频率最敏感?不是图像有哪些频率,而是在问,如果我只往图像中加一种频率的噪声,模型会不会崩?
Fourier Basis ,论文中是这样定义的Ui,j∈Rd1xd2U_{i,j}\in R^{d_1xd_2}Ui,j∈Rd1xd2,满足∣∣Ui,j∣∣2=1||U_{i,j}||2 = 1∣∣Ui,j∣∣2=1,并且F(Ui,j)F(U{i,j})F(Ui,j),只在频谱上的一个点有能量:(i,j),以及其共轭对称点。翻译了论文,还是不知道这个Fourier Basis什么意思,接下来研究goole的代码。
代码中有一个这个函数 generate_freq_heatmap,看了这个函数,可以这样理解,对于一个H X W的图像,FFT之后得到 H X W的频谱,频谱中的每个位置F(u,v) 对应一个二维频率,然后遍历整个H X W的频谱,每次遍历,生成当前位置为0.5+0.5j,共轭位置为0.5-0.5j,其他位置为0的频谱图,然后反傅里叶变换后,归一化,就生成了由单一频率组成的图片。
这里来深入理解下像素和频率的关系:
- 频率图 ,例如 w=64, h=32的图像,傅里叶变换后的 频域,大小也是w=64,h=32, 也就是在x方向,有64个频点 ,在y 方向有32个频点。
- 频点,可以这样理解,5/64,是64个像素振荡5次,3/32是32个像素震荡3次;还可以这样理解,例如64个像素震荡5次,那1个像素是多少周期呢,5/64 = 0.078125 周期/像素,意思是1个像素是多少周期,最高奈奎斯特频率是 32/64 = 0.5 周期。
- Fy=3,x=5 = 0.5 + 0.8j ,Fy=3,x=5代表一种频率,水平方向每64/5 = 12.8个像素完成1个周期,垂直方向32/3=10.67个像素完成1个周期。共轭值Fy=-3,x=-5 = 0.5 - 0.8j
- Fy=3,x=5 = 0.5 + 0.8j 和Fy=-3,x=-5 = 0.5 - 0.8j A = 0.5+0.8j ,θ=2π(5x64+3y32)\theta =2\pi (\frac{5x}{64} + \frac{3y}{32})θ=2π(645x+323y),振幅是∣A∣=0.52+0.82=0.943|A| = \sqrt{0.5^2 + 0.8^2} = 0.943∣A∣=0.52+0.82 =0.943 相位ϕ=tan−1(0.80.5)=58度\phi = tan^{-1}(\frac{0.8}{0.5}) = 58度ϕ=tan−1(0.50.8)=58度
Fy=3,x=5=0.5+0.8j=∣F(3,5)∣ejϕFy=3,x=5 = 0.5 + 0.8j = |F(3,5)| e^{j\phi}Fy=3,x=5=0.5+0.8j=∣F(3,5)∣ejϕ
F3,5=0.5+0.8j=1.886cos(2π(5x64+3y32))F3,5 = 0.5 + 0.8j = 1.886cos(2\pi (\frac{5x}{64} + \frac{3y}{32}))F3,5=0.5+0.8j=1.886cos(2π(645x+323y))
这个是这个频点真正的意义
实验
Fy=0,x=5 = 0.5 + 0.5j,应该是,纵向就是y方向没有频率变化,横向64个像素,有一个震荡5次的波,这个波是 2∗0.52+0.52cos(2π(5x64))2*\sqrt{0.5^2 + 0.5^2} cos(2\pi (\frac{5x}{64}))2∗0.52+0.52 cos(2π(645x)),现在将这个频率使用傅里叶变换后,变成图片,可视化出来:
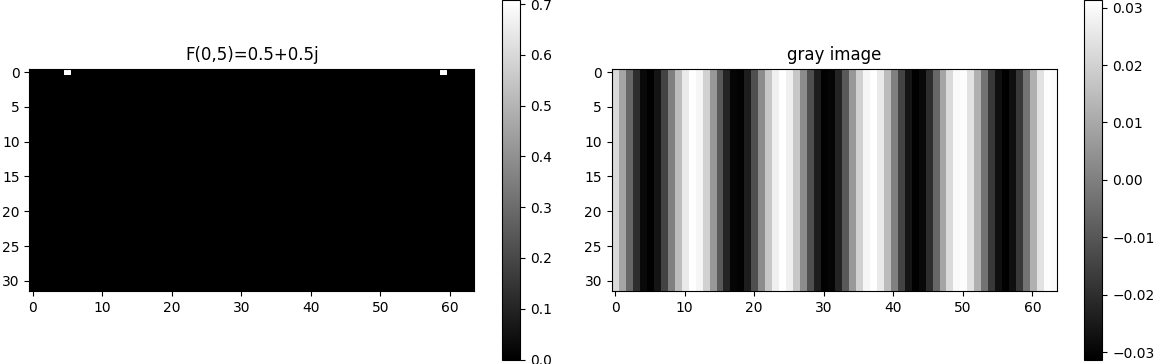
F(10,0) = 0.5+0.5j
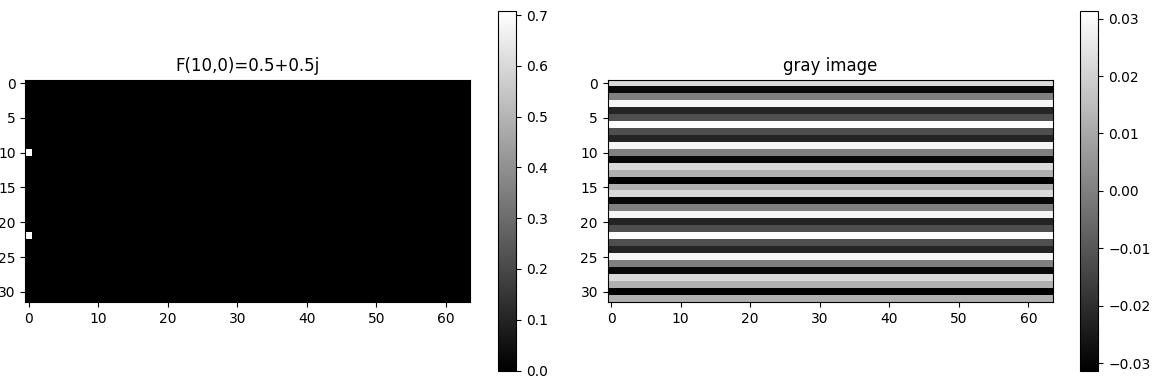
F(10,5) = 0.5+0.5j
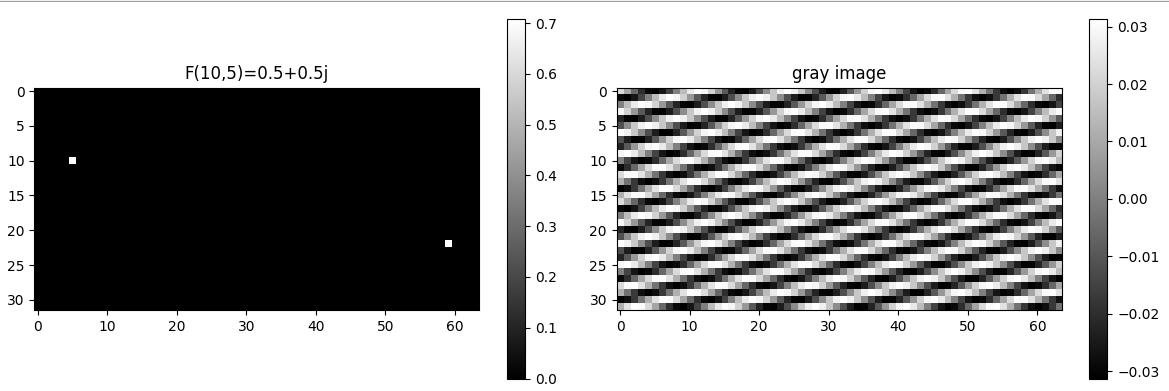
然后我们分析下F(0,5)=0.5+0.5j 和 F(0,5)=0.5+0.8j二者的区别,两者的频点完全一致,即条纹的方向,周期,密度完全一致,改变的是频率的振幅和相位,
- 振幅由0.707x2增大为0.943x2,黑更黑,白更白,对比度提高
- 相位由45度增大为58度,意味者条纹整体平移了一点点
所以,振幅决定的是,条纹有多亮,相位决定条纹从哪里开始
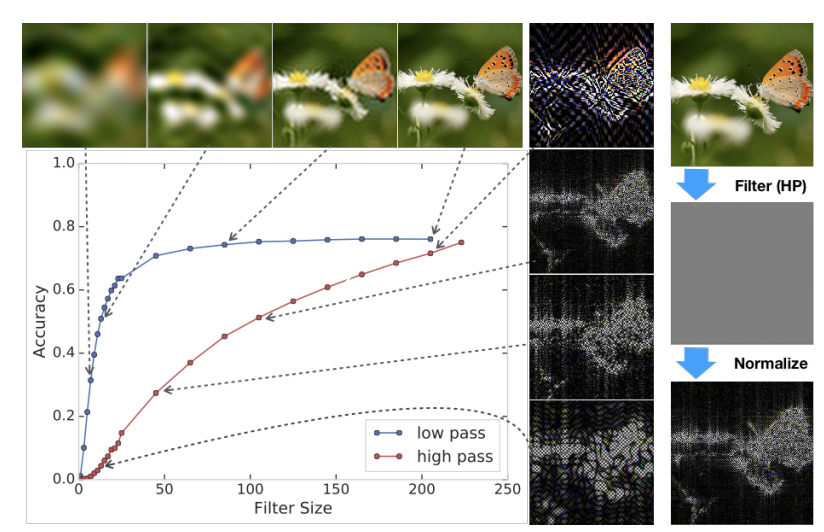
二、The robustness problem
数据和labels之间有许多相关性,模型可以利用这些相关性来很好地泛化,然而,如果这些统计量在测试的时候遭到破坏,利用这些充分统计量将导致模型性能急剧下降。
CNN往往会学习"最容易利用的特征",而不是一定学习"真正因果意义的特征",论文举了一个例子,作弊版的MNIST,意思是作者故意修改了MNIST数据集,所有类别0的图片,左上角某个像素置为1;类别为1的图片,左上角旁边某个像素置为1;类别2,再换一个位置。。。也就是,一个像素的位置,直接编码了类别。按照人的理解,网络应该学到的是数字本身的笔画结构,但是对于CNN来说,优化目标是最小化类别差,CNN在学习的时候,发现了,使用右上角的某些像素值,可以非常容易优化,所以网络学到的是,左上角哪个位置的像素值为1,而不是整个数字形状,这个是所谓的**捷径学习**