一、环境部署与启动
🛑 准备工作(第 0 天):选对版本,事半功倍
版本选择: 不要追最新(如 1.19),也不要太旧(如 1.12)。
- 推荐: Flink 1.17 或 1.18(LTS 长期支持版,稳定,社区连接器支持好)。
- JDK: Java 8 或 Java 11(推荐 11,性能更好)。
- IDE: IntelliJ IDEA(必须)。
- 环境: 本地开发用
LocalExecutionEnvironment,依赖组件(Kafka, MySQL, Redis)用 Docker 一键启动(避免装环境浪费时间)
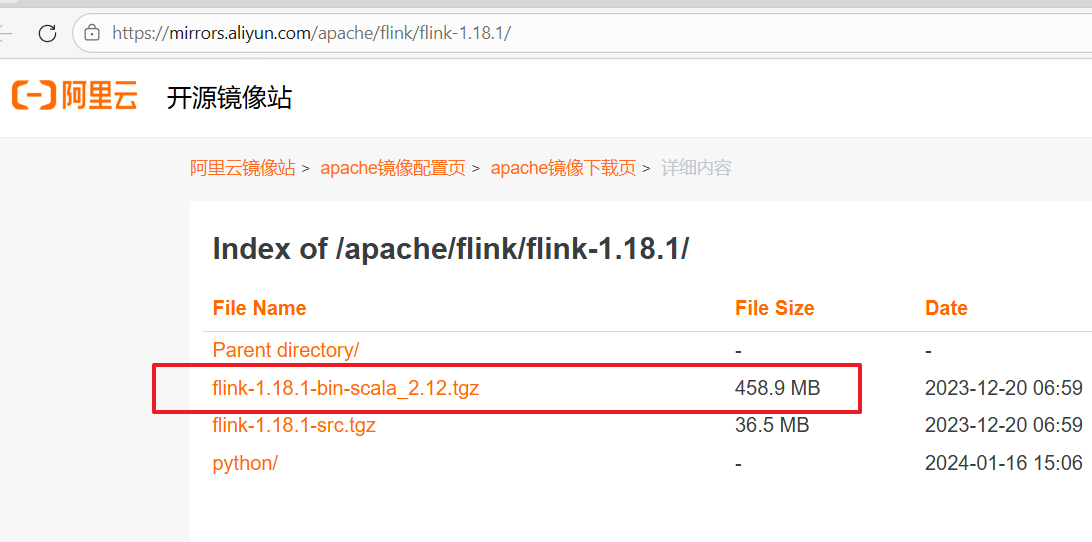
1.1、flink1.18下载
https://mirrors.aliyun.com/apache/flink/flink-1.18.1/
1.2、JDK11下载
国内下载地址,免登录
Index of java-local/jdk/11.0.2+7
java jdk 国内下载镜像地址
1)TUNA镜像 https://mirrors.tuna.tsinghua.edu.cn/Adoptium/
2)HUAWEI镜像 https://repo.huaweicloud.com/java/jdk/
3)injdk https://d.injdk.cn/download/openjdk
其他地址:
3) https://github.com/openjdk/jdk
等待安装结束, 配置环境变量(此处省略)
window + s 快捷键,输入env,进入环境变量配置
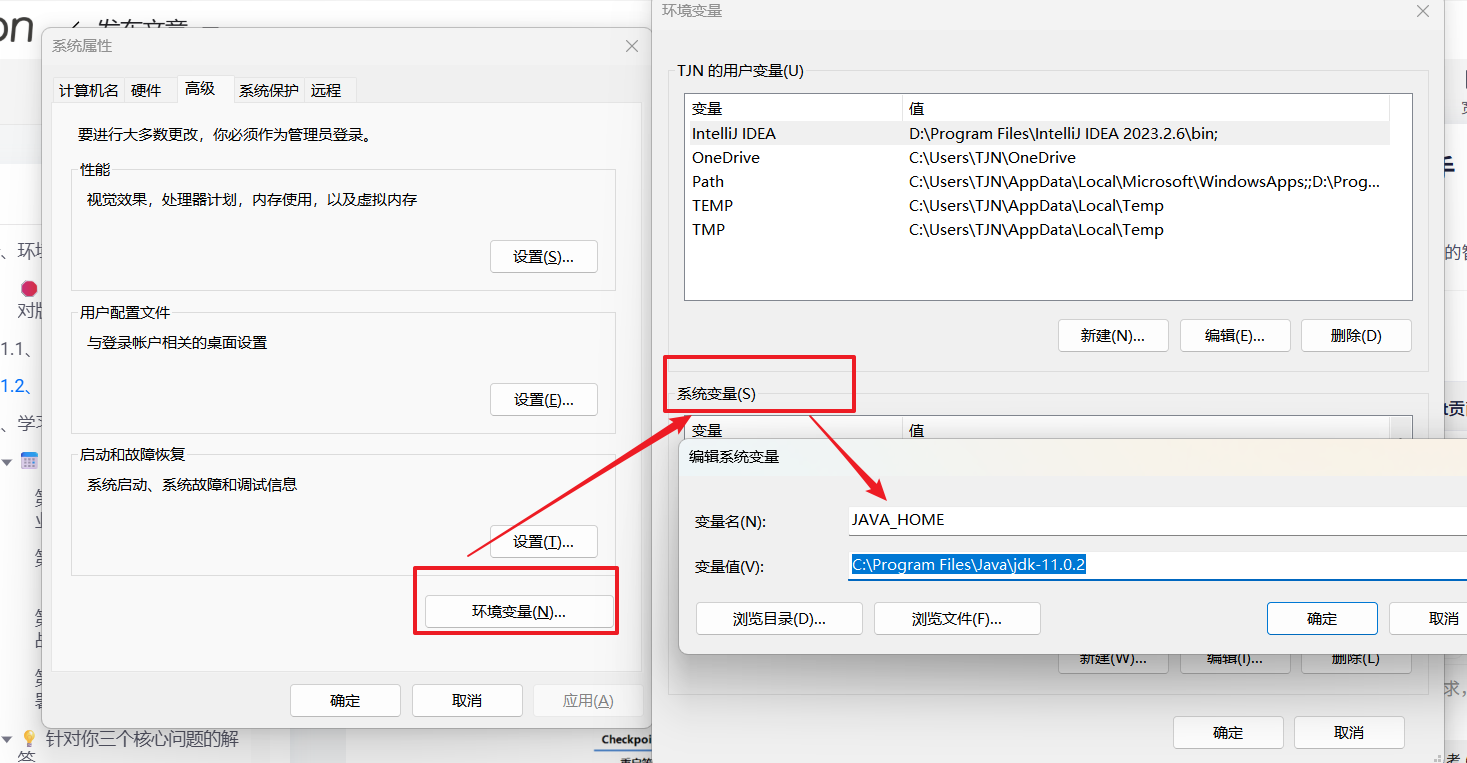
变量名:JAVA_HOME
变量值:C:\Program Files\Java\jdk-11.0.2(JDK的安装路径,这里以你自己的安装路径为准)
新建CLASSPATH 变量,变量值为:
.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar(注意前面是有一个点的),配置好之后如下图,这里是可以复制粘贴的
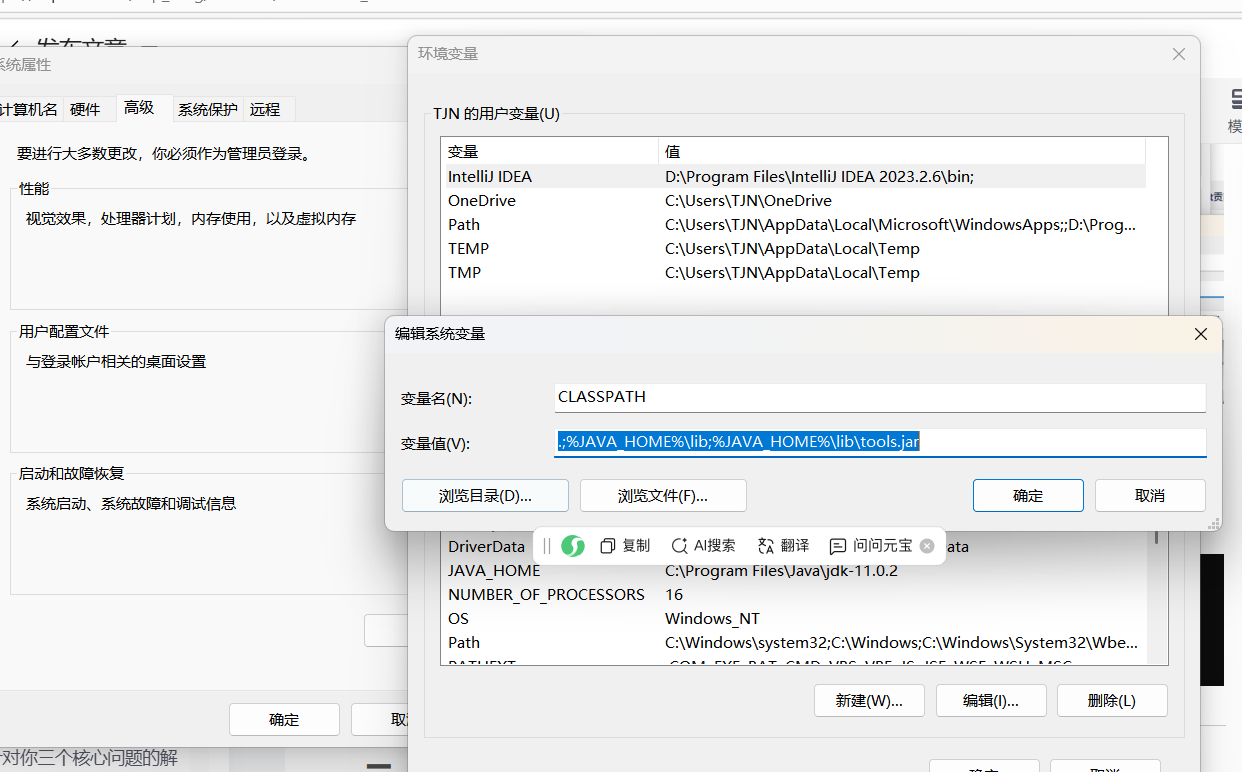
点击确定
配置path,找到path,双击或者点编辑,最后一行添加
输入 %JAVA_HOME%\bin
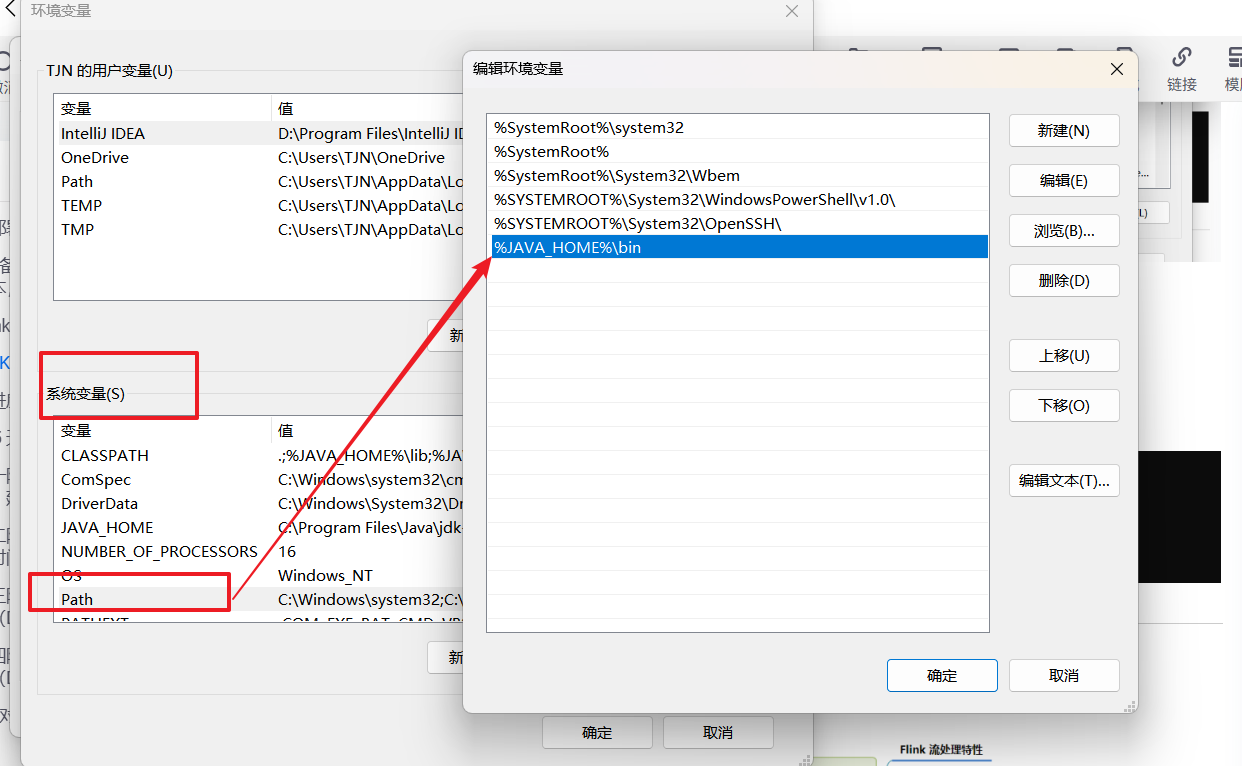
点击确定
windows + R, 输入cmd
JAVA --version,打印JAVA版本号说明配置环境成功

1.3、maven下载安装
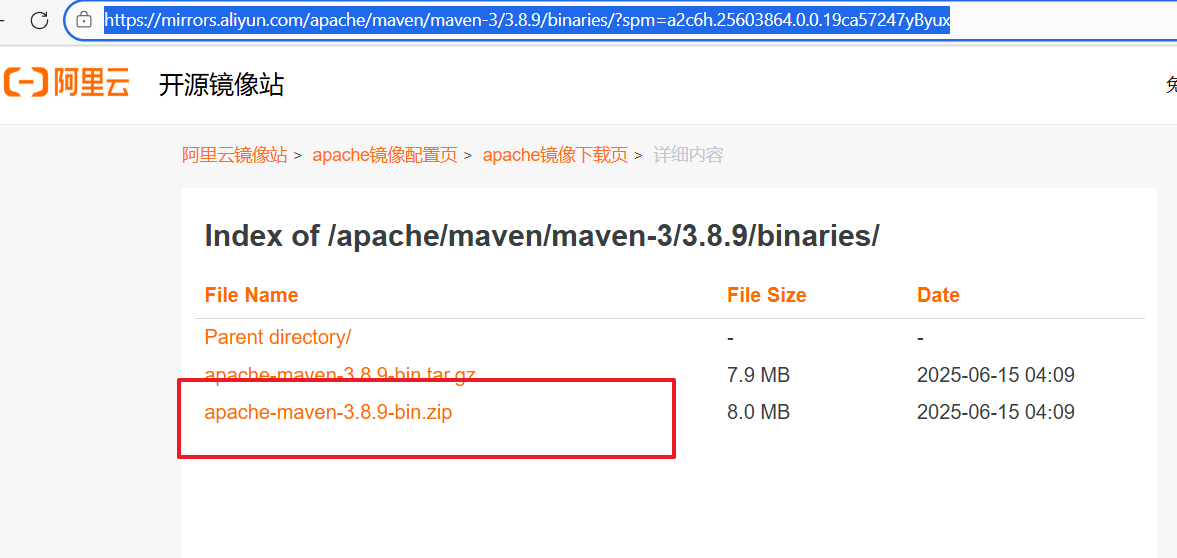
把下载好的 apache-maven-xxx-bin.zip 解压到一个不带中文、不带空格的路径D:\Program Files\apache-maven-3.8.9
目录结构说明:bin:包含 mvn 命令
conf:配置文件所在目录
lib:依赖 jar 包
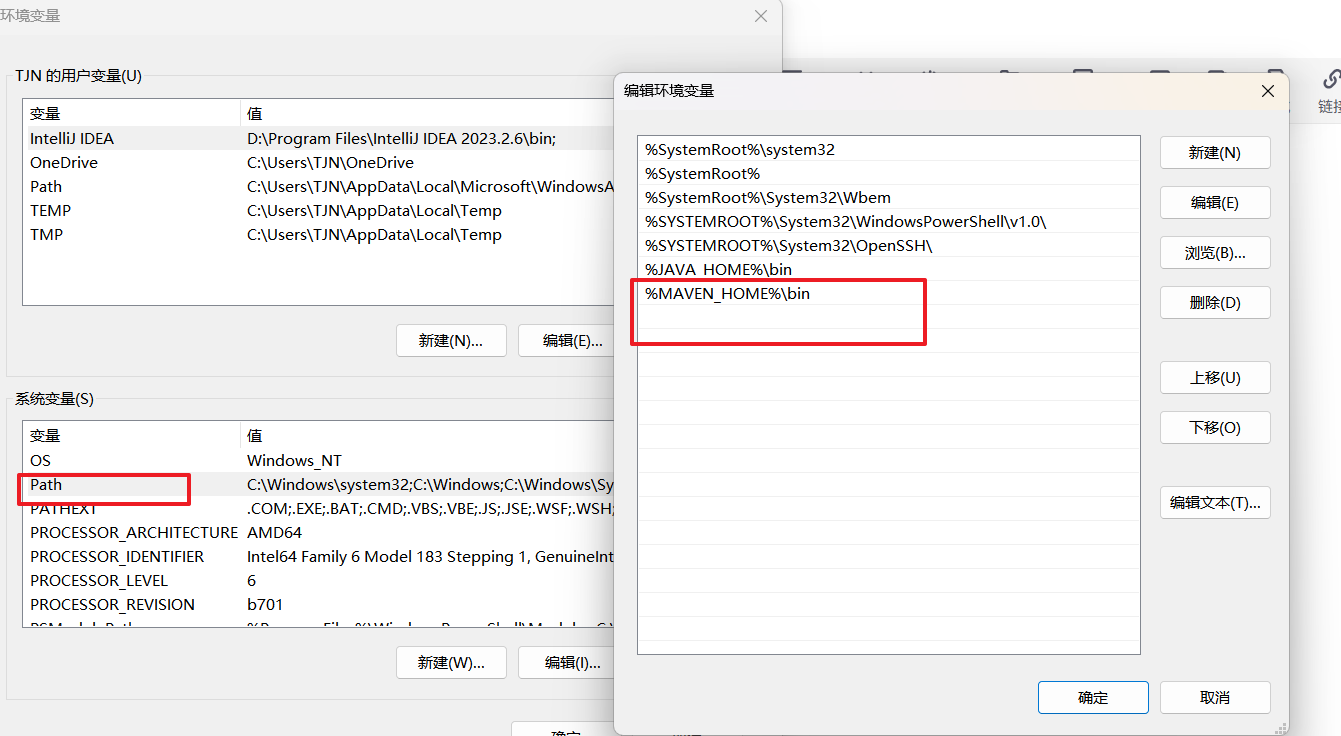
配置环境变量(关键步骤)
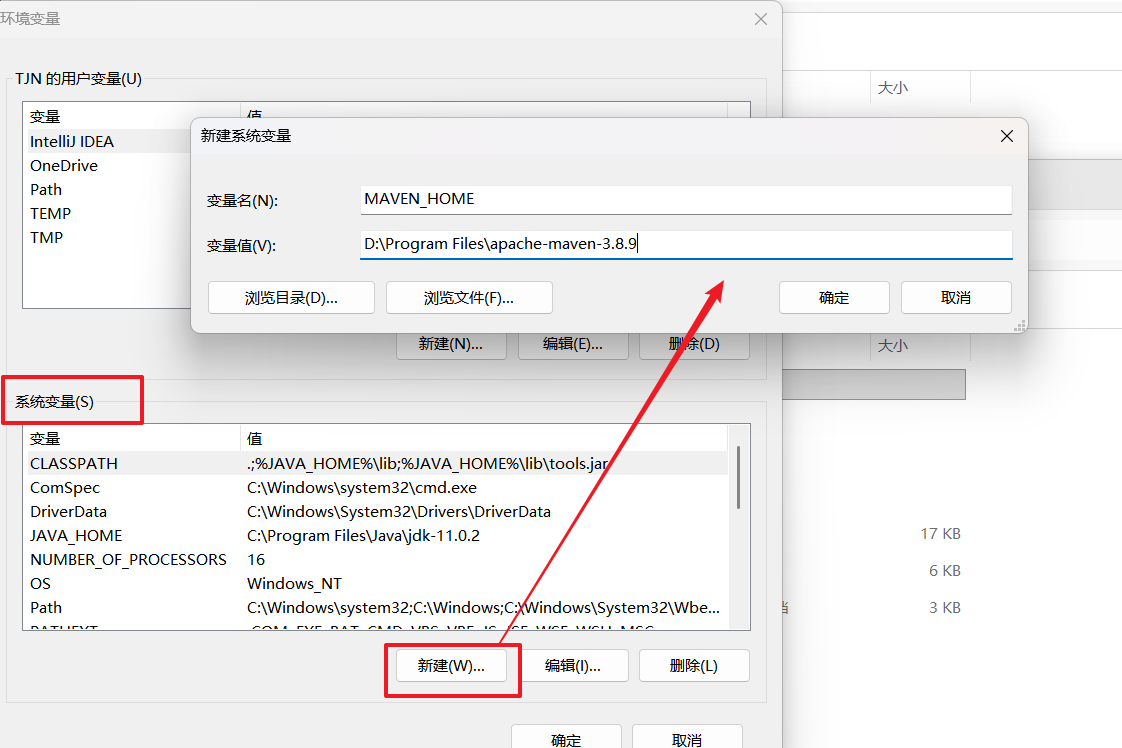
- 新建 MAVEN_HOME
此电脑 → 右键属性 → 高级系统设置 → 环境变量
系统变量 → 新建
变量名:MAVEN_HOME
变量值:你的 Maven 路径,如 D:\Program Files\apache-maven-3.8.9
- 配置 Path
找到系统变量里的 Path → 编辑
新建:
%MAVEN_HOME%\bin
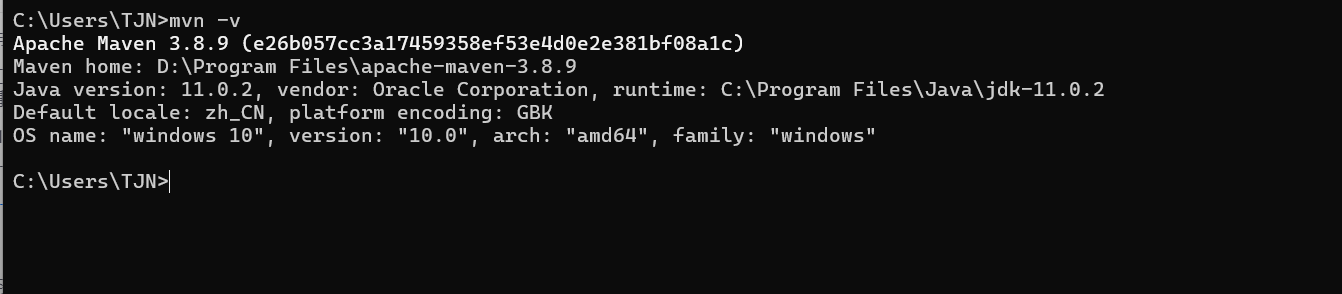
验证是否安装成功
打开 cmd,输入
bash
mvn -v如果出现版本信息,说明安装成功。
配置阿里云镜像(解决下载慢)
Maven 官方仓库在国外,下载极慢,必须换成阿里云镜像。
打开 conf/settings.xml,找到 <mirrors> 标签,添加:
XML
<mirrors>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
</mirrors>1.4、下载IDEA
idea配置maven环境和java环境
二、学习进度
15 天速成的核心策略是:不求甚解原理,只求跑通场景。 不要一开始就去读源码或钻研底层分布式理论,以"构建一个能跑的数据管道"为目标。
📅 15 天学习路线图
第一阶段:跑通第一个作业,建立信心(Day 1 - Day 3)
目标: 不纠结概念,先让代码跑起来,看到数据流动。
Day 1: 跑通一个demo
第一步:新建 Maven 项目
- 打开 IDEA,点击
New Project。 - 左侧选择
Maven。 - JDK :选择你安装的 JDK(建议 JDK 1.8 或 JDK 11,Flink 1.18 都支持,如果你不确定,选 1.8 最稳妥)。
- 点击
Next,填写项目名(例如flink-pro)。
- 点击
Finish。
第二步:修改 pom.xml(核心步骤)
- 打开项目根目录下的
pom.xml,删除里面所有内容 ,直接复制下面的代码进去。 我已经帮你配好了 Flink 核心依赖、日志依赖和阿里云镜像(下载更快)。
XML
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.juxin</groupId>
<artifactId>flink_pra</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<!-- 修正这里:必须是 Java 版本,不能是插件版本 -->
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.18.1</flink.version>
<java.version>11</java.version>
</properties>
<dependencies>
<!-- 1. Flink 核心依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 2. Flink 客户端依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 3. 日志依赖 (Flink 1.18 推荐组合) -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.36</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.17.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.17.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.17.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
</plugins>
</build>
</project>等待安装结束
新建一个测试demo
java
package com.juxin.day01;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
public class SimpleFlinkJob {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境 (本地模式)
// 这一步相当于启动了"迷你集群"
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度为 1,方便新手看日志,不然日志会乱序
env.setParallelism(1);
// 2. 创建数据源 (模拟数据:1, 2, 3, 4, 5)
DataStream<Integer> dataStream = env.fromElements(1, 2, 3, 4, 5);
// 3. 简单算子处理 (每个数字乘以 10)
DataStream<Integer> resultStream = dataStream.map(value -> {
// 这里可以打断点调试
System.out.println("正在处理数据:" + value);
return value * 10;
});
// 4. 打印结果到控制台
resultStream.print();
// 5. 提交执行
// 程序会卡在这里,直到任务结束或被手动停止
env.execute("我的第一个 Flink 任务");
}
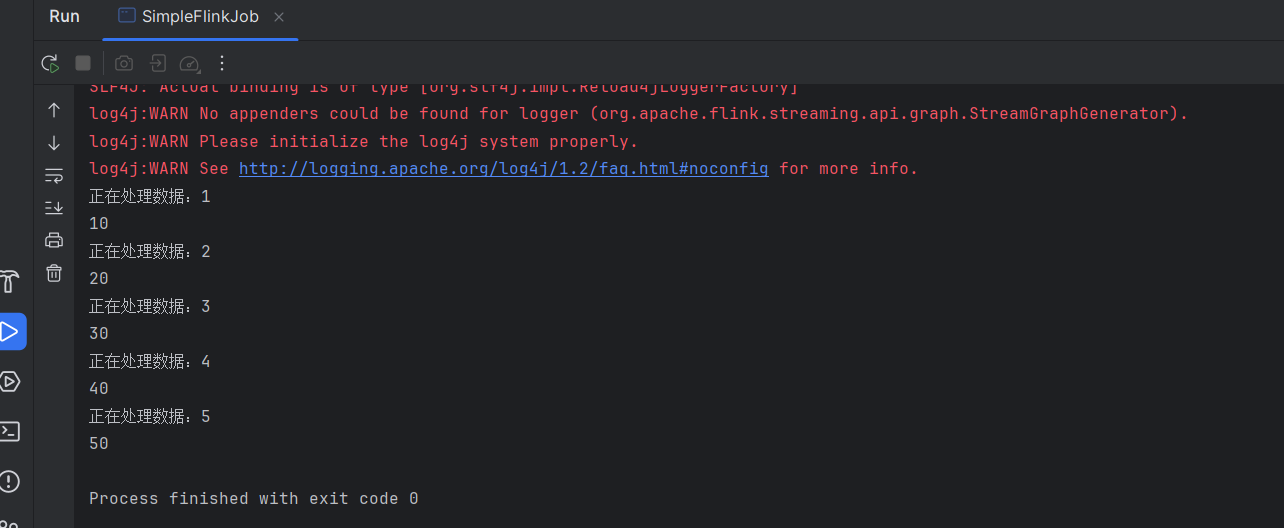
}运行,日志打印如下
Day 2: 对接 Kafka (最核心源)
- 任务: 用 Docker 启动 Kafka。写 Flink 程序从 Kafka 读字符串,打印到控制台。
- 重点: 引入
flink-connector-kafka。配置FlinkKafkaConsumer(或新的KafkaSource)。 - 验证: 往 Kafka 发消息,看 IDEA 控制台有没有输出。
2.1、pom.xml里面添加依赖
XML
<!-- Kafka -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.1</version>
</dependency>2.2、docker安装kafka
第一步:创建网络
docker network create kafka-net如果提示网络已存在,可以忽略,或者先删除:
docker network rm kafka-net
第二步:启动 Zookeeper
docker run -d \
--name zookeeper \
--network kafka-net \
-p 2181:2181 \
-e ZOOKEEPER_CLIENT_PORT=2181 \
-e ZOOKEEPER_TICK_TIME=2000 \
swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/zookeeper:latest等 10 秒,让 Zookeeper 完全启动。
第三步:启动 Kafka
- strimzi/kafka = Kubernetes 专用镜像 → 不支持 docker 环境变量启动
- bitnami/kafka = Docker 标准镜像 → 完美支持 KAFKA_ 环境变量*
XML
docker run -d \
--name kafka \
--network kafka-net \
-p 9092:9092 \
-e KAFKA_BROKER_ID=1 \
-e KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \
-e KAFKA_CFG_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
-e KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092 \
-e ALLOW_PLAINTEXT_LISTENER=yes \
-e KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \
swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/bitnami/kafka:3.7✅ 验证启动成功
# 查看容器状态
docker ps
# 应该看到两个 Up 状态的容器
XML
# 进入 Kafka 容器
docker exec -it kafka bash
# 1. 查看 Broker 列表(能通就说明服务活了)
kafka-broker-api-versions.sh --bootstrap-server localhost:9092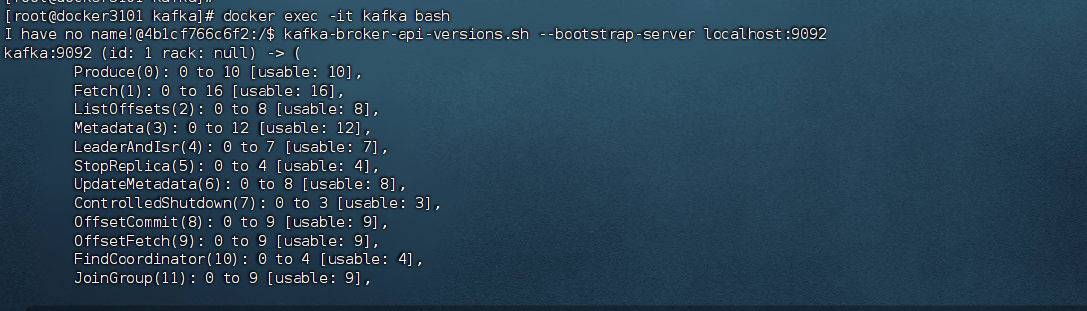
🧹 管理命令
| 操作 | 命令 |
|---|---|
| 查看日志 | docker logs kafka |
| 停止容器 | docker stop kafka zookeeper |
| 启动容器 | docker start kafka zookeeper |
| 删除容器 | docker rm -f kafka zookeeper |
| 删除网络 | docker network rm kafka-net |
⚠️ 注意事项
- 顺序很重要:必须先启动 Zookeeper,等 10 秒后再启动 Kafka
- 网络必须一致 :两个容器都要加入
kafka-net网络,这样 Kafka 才能通过容器名zookeeper访问它
- Day 3: 对接 MySQL (最核心汇)
- 任务: 将 Kafka 的数据写入 MySQL。
- 重点: 引入
flink-connector-jdbc。编写JdbcSink。 - 避坑: 注意数据库连接池配置,不要每次插入都新建连接。
第二阶段:攻克核心难点(时间 & 并行)(Day 4 - Day 7)
目标: 解决你提到的"事件时间、算子个数"困惑。
- Day 4: 理解并行度 (Parallelism)
- 任务: 修改 Day 2 的代码,设置
.setParallelism(4)。在 map 算子里打印Thread.currentThread().getName()或getRuntimeContext().getIndexOfThisSubtask()。 - 理解: 观察日志,发现数据是被多线程/多任务处理的。
- 结论: 并行度 = 同时处理数据的线程数。卡顿时调大,数据少时调小。
- 任务: 修改 Day 2 的代码,设置
- Day 5: 事件时间 (Event Time) 初探
- 任务: 模拟带时间戳的数据(JSON 格式,含
timestamp字段)。使用assignTimestampsAndWatermarks。 - 理解: 为什么不用服务器接收时间?因为网络有延迟,数据产生时间才代表业务真相。
- 任务: 模拟带时间戳的数据(JSON 格式,含
- Day 6: 窗口 (Window) 与 水位线 (Watermark)
- 任务: 实现"每 5 秒统计一次过去 1 分钟的数据"。
- 重点:
window(TumblingEventTimeWindows.of(...))。理解 Watermark 是"触发窗口的信号"。 - 验证: 故意发送一条旧时间的数据,观察它是否被丢弃或进入侧输出流。
- Day 7: 状态 (State) 与 容错 (Checkpoint)
- 任务: 开启 Checkpoint (
env.enableCheckpointing(5000))。实现一个累加器(记录总条数)。 - 验证: 在程序运行中强制杀掉进程,重启,看数字是否接得上(需要配合 MemoryStateBackend 或 RocksDB)。
- 意义: 这是 Flink 不丢数据的核心。
- 任务: 开启 Checkpoint (
第三阶段:全链路连接器实战(Day 8 - Day 11)
目标: 解决你提到的 MQTT, Redis, TDengine 需求。
- Day 8: Redis 读写
- 依赖:
flink-connector-redis(社区版,选 Star 多的,如itnovel/flink-connector-redis)。 - 任务: 将聚合结果存入 Redis,供前端查询。
- 依赖:
- Day 9: TDengine 对接
- 现状: TDengine 官方提供了 Flink Connector。
- 任务: 去 TDengine 官网下载对应的 Flink 连接器 Jar 包,或配置 Maven 依赖。
- 注意: 时序数据库写入对顺序敏感,注意 Flink 乱序问题。
- Day 10: MQTT 对接
- 现状: MQTT 通常作为 Source。社区有
flink-connector-mqtt。 - 任务: 订阅一个 Topic,将消息转入 Kafka 或直接处理。
- 警告: MQTT 连接器稳定性不如 Kafka,生产环境建议 MQTT -> Kafka -> Flink,让 Kafka 做缓冲。
- 现状: MQTT 通常作为 Source。社区有
- Day 11: 整合大作业
- 任务: 搭建一个完整流程:
MQTT/Kafka (Source) -> Flink (清洗/聚合) -> MySQL/Redis/TDengine (Sink)。 - 目标: 这是一个可以演示的 Demo。
- 任务: 搭建一个完整流程:
第四阶段:验证、调试与部署(Day 12 - Day 15)
目标: 解决"准确率验证"和"恐惧失败"的问题。
- Day 12: 如何验证准确率?
- 方法 1 (对账): 在 Source 端打一条"计数日志",在 Sink 端统计入库条数,两者应一致。
- 方法 2 (侧输出流): 将解析失败、格式错误的数据打入
Side Output,单独打印日志,确保主流程数据干净。 - 方法 3 (单元测试): 使用 Flink 的
MiniCluster在本地跑单元测试(不依赖外部 Kafka),验证算子逻辑。
- Day 13: 调试与监控
- 任务: 学会看 Flink Web UI (localhost:8081)。
- 重点: 看 Backpressure (反压),看 Checkpoint 是否成功。如果 Checkpoint 失败,程序重启会丢数据。
- Day 14: 异常处理与重试
- 任务: 模拟 Sink 端(如 MySQL)挂掉。配置 Flink 的重启策略 (
RestartStrategies)。 - 心态: 知道程序挂了会自动重启,你就不会慌了。
- 任务: 模拟 Sink 端(如 MySQL)挂掉。配置 Flink 的重启策略 (
- Day 15: 打包与总结
- 任务: 使用
maven-shade-plugin打包成 fat jar。 - 动作: 尝试在本地提交运行这个 Jar 包。
- 复盘: 整理这 15 天的代码,形成自己的模板库。
- 任务: 使用
💡 针对你三个核心问题的解答
1. 关于 Source 和 Sink 的"拿来即用"包
不要自己造轮子,Flink 生态很成熟。以下是 稳定版本推荐 (基于 Flink 1.17+):
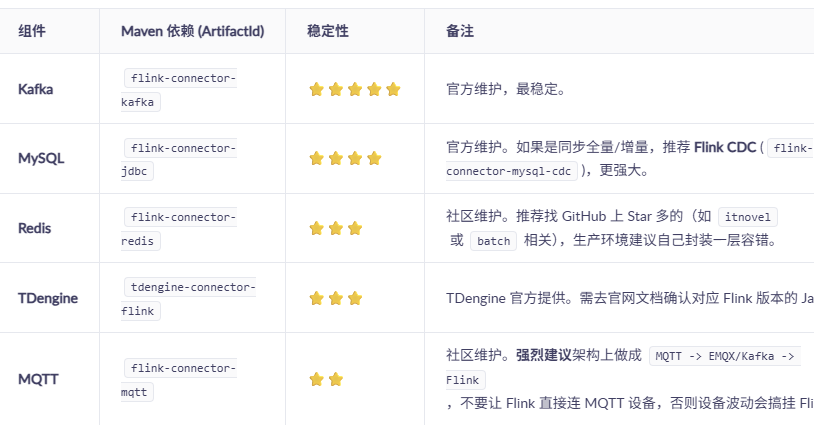
Maven 依赖示例 (pom.xml):
java
<!-- 核心 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.17.1</version>
</dependency>
<!-- Kafka -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.1</version>
</dependency>
<!-- JDBC (MySQL) -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>3.1.1-1.17</version> <!-- 注意版本号对应 -->
</dependency>2. 关于"事件时间、算子个数"及"准确率验证"
- 算子个数 (并行度):
- 怎么设? 本地开发
setParallelism(1)方便看日志。生产环境设为 CPU 核心数的 1-2 倍。 - 怎么验证? 在代码里加
System.out.println("Task Index: " + getRuntimeContext().getIndexOfThisSubtask());。如果看到 0, 1, 2, 3 都有日志,说明并行生效了。
- 怎么设? 本地开发
- 事件时间 (Event Time):
- 核心痛点: 数据乱序。
- 怎么验证准确率?
- Watermark 日志: 打开 Flink Web UI,看 Watermark 是否在增长。
- 侧输出流 (Side Output): 把"迟到数据"单独输出到一个文件。如果侧输出流为空,说明水位线设置合理,数据都在窗口内。
- 端到端对账: 源端(如 Kafka)有个 Offset,目标端(如 MySQL)有个 Count。
Kafka MaxOffset - MinOffset应该约等于MySQL Count(允许少量重试误差)。
- 状态一致性:
- 只要 Checkpoint 开启且成功 ,Flink 保证
Exactly-Once(精确一次)。这是验证准确率的基石。如果 Checkpoint 红了,数据就可能不准。
- 只要 Checkpoint 开启且成功 ,Flink 保证
3. 关于"心气没了"和"恐惧"
这是学习新技术最大的敌人。我的建议是:
- 本地优先: 前 10 天不要碰服务器集群,就在 IDEA 里跑
LocalEnvironment。报错立刻能看到堆栈,改完立刻能跑,反馈循环短。 - 硬编码配置: 学习阶段,不要把配置放在 Nacos 或外部文件,直接写死在 Java 代码里。减少外部依赖带来的挫败感。
- 允许脏数据: 刚开始不要追求 100% 完美。先跑通"快乐路径"(数据正常的情况)。异常处理(如 Kafka 挂了)放到第 14 天再考虑。
- 抄代码: 去 GitHub 搜
flink java example,找 Star 多的,直接拉下来跑。能跑通官方示例,信心就回来了一半。
🚀 给你的第一个任务 (今天就开始)
不要等明天。现在打开 IDEA,创建一个 Maven 项目,粘贴下面的代码,运行它。如果控制台输出了数字,你就算入门了。
java
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
public class QuickStart {
public static void main(String[] args) throws Exception {
// 1. 获取执行环境 (本地模式)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度为 1,方便新手看日志
env.setParallelism(1);
// 2. 模拟数据源 (1, 2, 3, 4, 5)
DataStream<Integer> dataStream = env.fromElements(1, 2, 3, 4, 5);
// 3. 简单处理 (乘以 2)
DataStream<Integer> resultStream = dataStream.map(value -> {
System.out.println("处理中:" + value); // 验证算子执行
return value * 2;
});
// 4. 输出结果
resultStream.print();
// 5. 执行
env.execute("我的第一个 Flink 任务");
}
}记住:Flink 只是一个工具,你的业务价值才是核心。15 天后,你不需要成为专家,只需要能把它用在你的项目里,你就赢了。加油!