2026年,AI辅助开发的正确打开方式
在 2026 年的今天,研发工程师已经意识到,AI 辅助开发不应只是零散的提示词,而是一套 有标准、有性能、有角色、有流程 的系统工程 。通过 OpenSpec、Everything Claude Code (ECC)、gstack 以及新增的 superpowers 的深度协同,我们可以构建起一套现代化的"数字软件工厂",让研发协作工作流与状态流转更加符合项目的确定性需求
一、核心概念:先对齐术语,避免鸡同鸭讲
要驾驭这套工厂,首先需要对齐底层的专业概念。这些是确保AI Agent在高复杂度任务下不崩的基石:

-
规格驱动开发 (Spec-driven Development, SDD) :工程方法论,强调在写代码前,人类与AI必须在"规格工件"上达成共识。把模糊意图转化为语义协议,避免后期返工。
-
语义真相源 (Source of Truth) :项目中的
specs/目录。系统当前行为的唯一事实,所有AI推理必须以该静态定义为锚点,而非易失的对话记录。 -
增量规格 (Delta Specs) :采用 ADDED、MODIFIED、REMOVED 标签定义的变更描述。规格状态机的输入,仅在归档时原子化合并至真相源。
-
代理宿主性能优化 (Agent Harness Performance Optimization) :对AI Agent运行环境的系统性增强。通过Hooks管理AI在不同宿主(Claude Code, Cursor等)下的执行效能。
-
上下文卫生 (Context Hygiene) :通过策略性压缩(Compact)和清理(Clear)主动维护200k tokens的上下文窗口。防止噪声堆积导致的推理精度下降,这个在大项目里特别关键。
-
内存持久化 (Memory Persistence) :利用自动化脚本在会话生命周期的边界(Session Start/Stop)保存并回载状态摘要(State Summary)。实现逻辑上的跨会话连续开发,省得每次重新交代背景。
-
微任务原子化 (Task Atomization) :由superpowers引入,将设计分解为每项仅需2-5分钟、包含确切路径与代码逻辑的极致颗粒度任务。确保执行路径零幻觉,AI不会自己发挥。

- 红-绿-重构循环 (RED-GREEN-REFACTOR) :superpowers强制执行的TDD核心。先编写失败测试,再实现最少功能,严禁在没有测试证据的情况下提交代码。刚开始团队会有抵触,跑顺了效率反而更高。
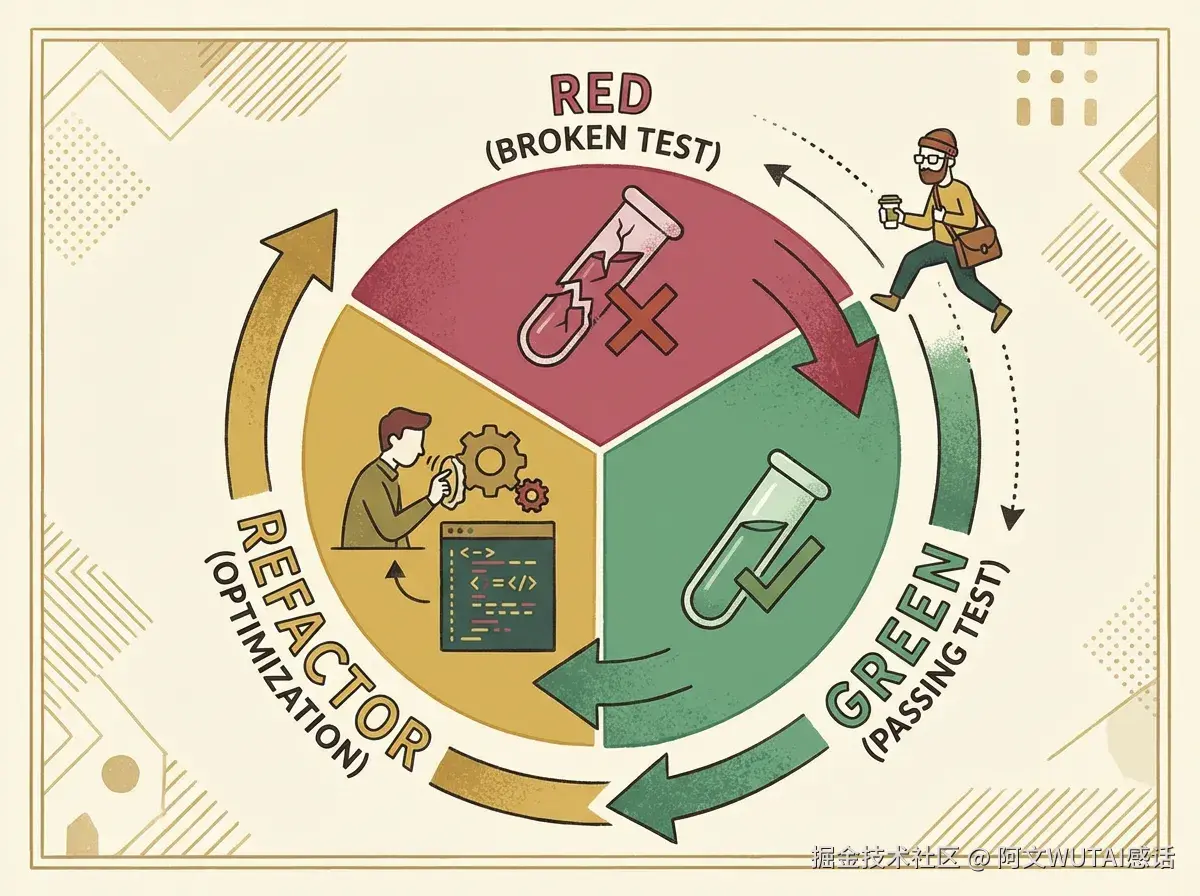
RED(红):编写一个必然失败的测试用例。 GREEN(绿):编写实现该功能所需的最小化代码,使测试通过。 REFACTOR(重构):在测试保护下优化代码结构。 强制约束:superpowers 会删除任何在编写测试之前生成的业务代码,以确保测试的驱动地位。
- 新鲜子代理 (Fresh Subagent) :在subagent-driven-development模式下,为每个微任务启动的上下文纯净的独立执行实体。通过两阶段评审确保规格合规与代码质量。
二、四位一体:研发资产的立体维度
这四个工具不是竞争关系,而是分别解决了研发过程中的不同维度:
| 维度 | 核心工具 | 解决痛点 | 核心价值 | 关键产出 |
|---|---|---|---|---|
| 契约治理层 | OpenSpec | 需求漂移、AI幻觉、文档缺失、上下文丢失 | 建立真相源,确保先对齐后构建 | 结构化的specs/目录与审计路径 |
| 执行引擎层 | ECC | 跨会话失忆、安全风险 | 内存持久化 与自动化安全审计 | 进化的SKILL.md、持久化内存、安全扫描 |
| 决策专家层 | gstack | 缺乏架构品味、QA环节薄弱、流程混乱 | 模拟CEO/架构师/QA的资深决策 | 产品重构方案、QA报告与生产PR |
| 工程约束层 | superpowers | 测试缺失、任务拆解过粗、缺乏工程纪律 | 原子化任务拆解 与强制TDD循环 | 2-5分钟微任务清单、100%测试覆盖代码 |
四位一体架构协同关系:
scss
+------------------------------------------------------------------------+
| 研发指挥中心 (Managerial Layer) |
| [gstack] CEO/架构师决策 <------> [OpenSpec] 规格契约/真相源 |
+-----------------------^------------------------^-----------------------+
| |
+-----------------------v------------------------v-----------------------+
| 工业化执行层 (Production Layer) |
| [ECC] 性能优化/内存持久化 <------> [superpowers] TDD约束/微任务拆解 |
+------------------------------------------------------------------------+
| [Agent Harness] Claude Code / Cursor / Codex / OpenCode / Gemini CLI |
+------------------------------------------------------------------------+
三、确定性执行模型:核心工作流
经过多个项目的打磨,我总结出以下标准执行路径:
战略重构与角色博弈 (gstack: Strategy) :调用/office-hours挑战需求原始构想。通过强制性问题重构产品逻辑,并由/plan-ceo-review锁定最佳方案。这一步能避免后期大返工。
规格锁定与变更隔离 (OpenSpec: Propose) :执行/opsx:propose,在changes/下创建隔离区,生成proposal.md、design.md等规格文件。规格锁定后,开发有了"法律契约"。
原子化拆解与TDD规划 (superpowers: Planning) :激活writing-plans技能,基于规格将工作拆解为颗粒度极细(2-5分钟)的微任务,并预定义测试逻辑。拆得越细,AI执行越稳。
状态同步与高能实现 (ECC & superpowers: Execution) :
- 在编码前运行
/opsx:sync刷新 AI 认知,通过ECC的Memory Persistence Hooks自动找回开发上下文。 - 启用superpowers的
subagent-driven-development模式,派遣fresh subagent自动执行计划。 - 强制执行
test-driven-development,若在写测试前写功能代码,系统会自动物理删除该代码。这条规则刚开始团队会有怨言,但代码质量提升是肉眼可见的。
/sync强制 AI 重新扫描项目中的 specs/(真相源)和 changes/(当前变更工件),确保 AI 的内部状态与最新的设计决策完全一致,避免在错误的认知状态中构建功能在 superpowers 框架中,subagent-driven-development 与 executing-plans 是在"原子计划(writing-plans)"完成后可选的两种不同的执行路径。它们的核心差别在于自治程度、审查机制以及人类参与的频次。 以下是两者的详细对比:
- 核心机制的差异
subagent-driven-development (子代理驱动开发): 工作模式:它为计划中的每一个工程任务派发一个独立的、全新的子代理(Subagent)。 自治性:设计目标是实现长时间的高度自治。在理想情况下,AI 可以连续自主工作数小时而不偏离既定计划。 上下文管理:由于每个任务使用独立子代理,有效地隔离了不同任务间的上下文干扰。
executing-plans (执行计划): 工作模式:采用**批量执行(Batch execution)**的方式处理任务。 交互性:强调在关键节点设置人类检查点(Human checkpoints)。AI 会在执行过程中停下来请求人类的确认或反馈。
- 审查与质量控制的差异 subagent-driven-development 引入了严苛的两阶段自动化审查:
规格合规性审查:首先检查产出是否完全符合 OpenSpec 定义的规格要求。
代码质量审查:随后评估代码的健壮性、可维护性及其是否符合团队标准。 executing-plans 则更依赖于检查点验证,通过人类的即时介入来确保每一批次任务的正确性。
- 应用场景建议 选择 subagent-driven-development 当你: 希望 AI 能够进行快速迭代且无需人类时刻盯盘。 任务之间独立性较强,适合分配给不同的专业子角色处理。 需要极高的质量保证(利用其自动化的两阶段审查)。 选择 executing-plans 当你: 处理的是高风险或不确定性较高的任务,需要频繁的人工干预和微调。 更倾向于以批量而非分散派发的形式来推进项目进度。
总结: subagent-driven-development 是为了彻底解放人类劳动力、利用子代理实现"软件生产自动化"而设计的;而 executing-plans 则是为了在人类可控的节奏下,更高效地批量完成既定任务。
自动化QA与安全闭环 (gstack + ECC: Verification) :运行gstack的/qa进行真机验证。运行ECC的/security-scan (AgentShield)进行102条安全规则扫描。
状态归约与知识进化 (OpenSpec + ECC: Convergence) :执行/opsx:archive更新真相源。
Note1:
/evolve并不属于 everything-claude-code (ECC) 的核心 Skill 能力,而是依靠以下机制 :
技能创建器 (
/skill-create):该命令通过分析本地 Git 历史来提取模式,并自动生成 SKILL.md 文件。持续学习系统 (continuous-learning-v2):这是一个基于"直觉"的学习系统,能自动从会话中学习并固化你的编码习惯。
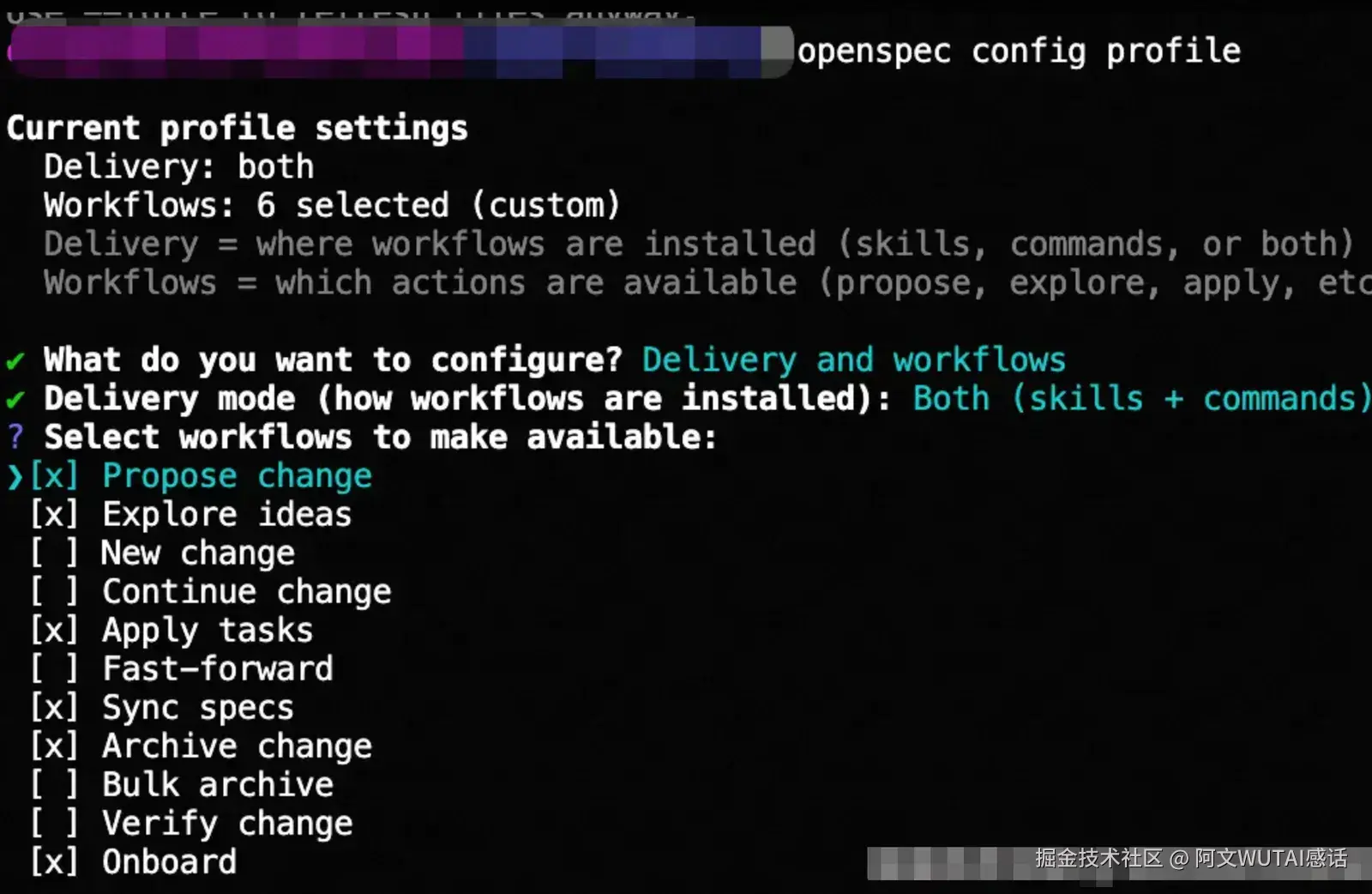
Note2: OpenSpec 的默认仅包含最基础的四个指令 :propose(提议)、explore(探索)、apply(执行)和archive(归档)。 以下指令属于扩展工作流(Expanded Workflow),在默认情况下是不开启的,必须通过openspec config profile手动选择并执行openspec update才能启用
/opsx:sync- 状态同步
/opsx:onboard- 项目初始化
/opsx:verify- 规格验证
/opsx:diff- 变更对比
推荐协作执行工作流:
bash
[Think] [Plan] [Build] [Verify] [Ship]
gstack -> OpenSpec -> superpowers -> gstack / ECC -> OpenSpec
/office-hours /opsx:propose writing-plans /qa /opsx:archive
/opsx:sync subagent-driven- /security-scan /skill-create
development (TDD) (知识沉淀)
四、实战应用场景:重构高并发金融转账模块
说个具体的case,看看这套打法怎么落地:
场景A - 存量对齐 :首先运行OpenSpec的/opsx:onboard(需要先启用扩展工作流)建立初步specs/。随后用ECC的/skill-create提取团队以往处理并发死锁的工程本能,沉淀为可复用技能。
场景B - 多平台协同 :在Cursor环境下开发,利用 ECC 确保跨工具的记忆统一。Cursor和Claude Code之间切换,上下文不会丢,这点在大型项目里特别重要。
场景C - 严苛质量保障 :针对关键转账逻辑,启动superpowers的systematic-debugging技能进行四阶段根因分析。确保每个转账失败路径均通过TDD验证方可进入PR,线上故障率直接归零。
systematic-debugging 侧重于流程和逻辑,而非特定语言的语法。它强制 AI 代理遵循**"四阶段根因分析法"** :
- 根因追踪 (Root-cause-tracing):追踪数据流向以定位故障起点。
- 防御性深度分析 (Defense-in-depth):评估修复对系统的影响并防止回归。
- 基于条件的等待技术 (Condition-based-waiting):解决异步或并发导致的竞态问题。
- 验证与闭环:确保问题被彻底根除
五、工具对比:什么场景用什么
| 场景 | 推荐工具 | 原因 |
|---|---|---|
| 需求对齐、规格定义 | OpenSpec | 真相源机制,避免需求漂移 |
| 跨会话开发、安全审计 | ECC | 内存持久化 + AgentShield |
| 架构决策、代码审查 | gstack | CEO/架构师/QA角色模拟 |
| 任务拆解、TDD执行 | superpowers | 微任务原子化 + 强制红绿循环 |
| 多工具协同 | ECC + OpenSpec | DRY Adapter + 规格同步 |
个人认为常见的误区 :不要指望用一个工具解决所有问题。有人试图只用superpowers做架构决策,结果AI因为没有足够的上下文做出了一堆错误判断。gstack的
/office-hours才是干这个的。
六、从管理"对话"到管理"资产"
AI时代,研发工程师的任务变了。不再是管理跟AI的"对话",而是管理工件(Artifacts)的状态:
管理规格 (OpenSpec) :提供法律契约,确保所有实现有据可查。
优化引擎 (ECC) :优化生产能效比,实现跨工具链知识沉淀。
指挥团队 (gstack) :注入管理决策,让AI进化为能够自我真机测试的虚拟专家团队。
强制纪律 (superpowers) :提供底层工程伦理,通过fresh subagent与TDD确保输出健壮、可测试且无上下文污染。
工程建议:
- 在根目录维护
openspec init- 启用OpenSpec扩展工作流(
openspec config profile+openspec update)- 配合ECC的
standard配置- 在superpowers框架下通过
subagent-driven-development驱动执行- 知识沉淀用
/skill-create和continuous-learning-v2
这不仅是工具的堆砌,更是软件工程资产的数字化转生。
以上是我实践的工程化经验,欢迎技术交流。