目录
[1.1 文档加载](#1.1 文档加载)
[1.1.1 加载 PDF 文件](#1.1.1 加载 PDF 文件)
[1.1.2 加载 Markdown 与文本文件](#1.1.2 加载 Markdown 与文本文件)
[1.1.3 加载 Word 文档](#1.1.3 加载 Word 文档)
[1.2 文档分块](#1.2 文档分块)
[1.2.1 基础分块:按字符数分割](#1.2.1 基础分块:按字符数分割)
[1.2.2 高级分块:基于语义边界的分割](#1.2.2 高级分块:基于语义边界的分割)
[1.2.3 语义分块:基于嵌入相似度的高级分割](#1.2.3 语义分块:基于嵌入相似度的高级分割)
[1.2.4 分块策略总结](#1.2.4 分块策略总结)
[2.1 向量定义与向量化的意义](#2.1 向量定义与向量化的意义)
[2.2 向量相似算法](#2.2 向量相似算法)
[2.2.1 余弦相似度](#2.2.1 余弦相似度)
[2.2.2 欧氏距离](#2.2.2 欧氏距离)
[2.2.3 点积](#2.2.3 点积)
[2.3 向量化实践](#2.3 向量化实践)
[2.3.1 使用开源模型进行向量化](#2.3.1 使用开源模型进行向量化)
[2.3.2 批量处理分块后的文档](#2.3.2 批量处理分块后的文档)
[3.1 top-k 语义检索原理](#3.1 top-k 语义检索原理)
[3.1.1 暴力检索(Brute Force)](#3.1.1 暴力检索(Brute Force))
[3.1.2 使用 FAISS 建立高效索引](#3.1.2 使用 FAISS 建立高效索引)
[3.2 索引优化:从 Flat 到 IVF](#3.2 索引优化:从 Flat 到 IVF)
[4.1 向量数据库的介绍](#4.1 向量数据库的介绍)
[4.2 主流向量数据库与功能对比](#4.2 主流向量数据库与功能对比)
[4.3 使用 Chroma 作为向量存储](#4.3 使用 Chroma 作为向量存储)
[4.4 使用 FAISS 作为本地向量存储](#4.4 使用 FAISS 作为本地向量存储)
[第五部分:提示词增强 RAG 设计](#第五部分:提示词增强 RAG 设计)
[5.1 基础 RAG 提示词模板](#5.1 基础 RAG 提示词模板)
[5.2 高级提示词设计](#5.2 高级提示词设计)
[5.3 调用大模型生成答案](#5.3 调用大模型生成答案)
[5.4 完整 RAG 流程整合](#5.4 完整 RAG 流程整合)
[6.1 选择题](#6.1 选择题)
[6.2 填空题](#6.2 填空题)
[6.3 简答题](#6.3 简答题)
[6.4 实操题](#6.4 实操题)
前言
在人工智能与大语言模型飞速发展的今天,我们经常会遇到这样的场景:向 ChatGPT 询问一个关于公司内部产品文档的问题,模型要么回答"我不知道",要么给出一个过时甚至错误的答案。这是因为通用大语言模型(LLM)的训练数据存在截止日期,且不包含企业的私有数据。
检索增强生成(Retrieval-Augmented Generation, RAG)技术应运而生。它就像为模型配备了一个可以实时查阅的"外挂知识库"。当用户提问时,RAG 系统首先从知识库中检索出最相关的文档片段,然后将这些片段连同原始问题一起提交给 LLM,让模型基于这些"参考资料"生成准确、可靠的答案。
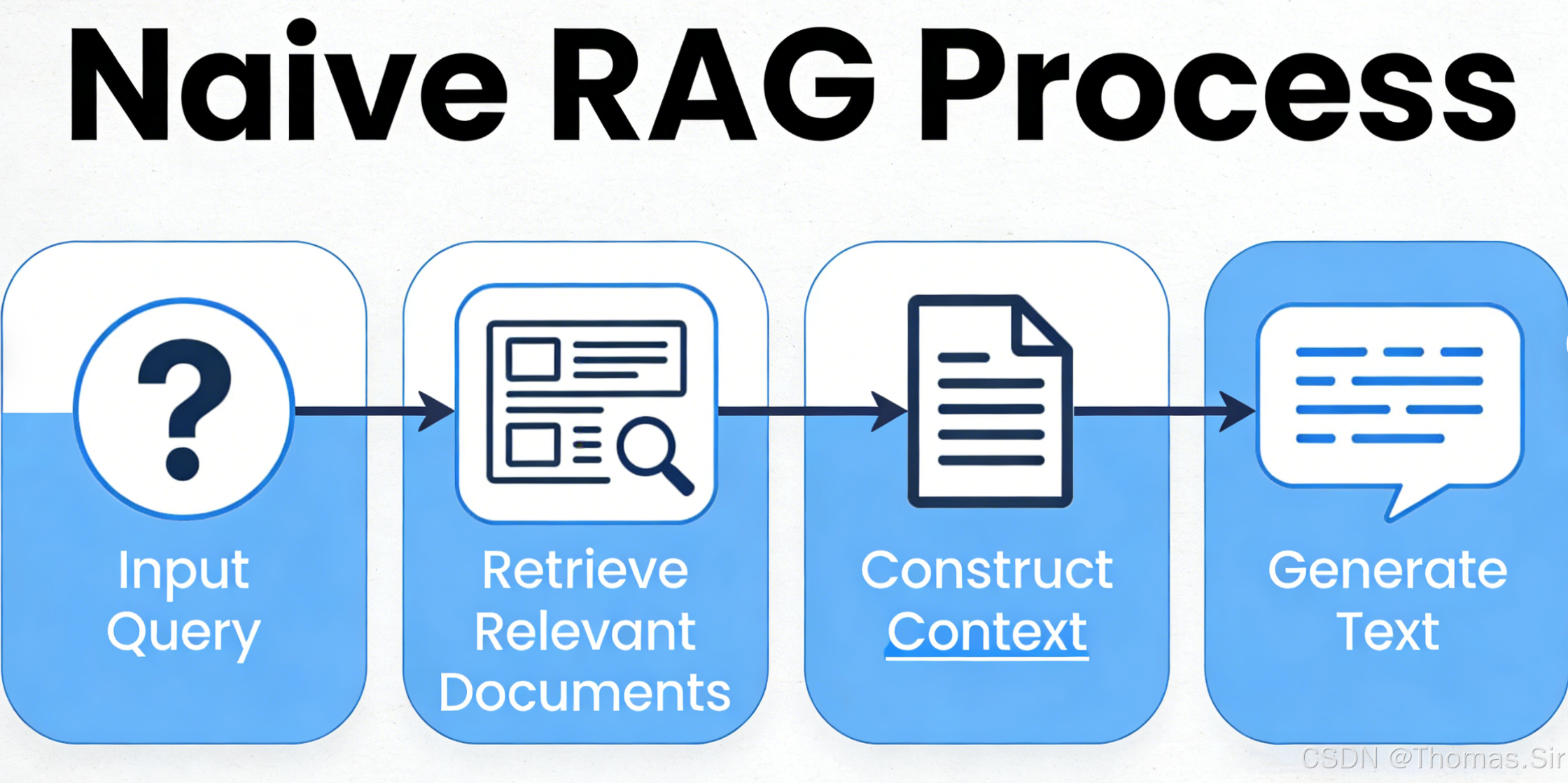
本文将带领读者从零开始,深入浅出地构建一个基础的 RAG 系统------通常被称为"Naive RAG"。之所以称之为"Naive",是因为它遵循最经典、最直接的流程:索引 → 检索 → 生成。虽然目前业界已有高级 RAG(如 Agentic RAG、Graph RAG 等),但掌握 Naive RAG 是理解一切复杂变体的基石。
本文面向初级到中级的技术爱好者、后端/前端/运维工程师以及在校学生。无论你是想在自己的项目中落地 RAG,还是希望深入理解其原理,本文都将提供一份详尽、可运行的实践指南。我们将涵盖从知识库搭建、文本向量化、向量存储到最终的提示词增强生成的全流程,并提供完整的代码示例与课后练习。
让我们开始这段充满挑战与收获的旅程,亲手打造一个能够回答你私有文档问题的智能问答系统!
第一部分:知识库搭建
在 RAG 系统中,知识库是基石。如果知识库中的数据质量差、分块不合理,后续的检索和生成效果将大打折扣。本部分我们将重点解决两个核心问题:如何将各类文档加载进系统,以及如何将长文档切分为适合检索与生成的语义块。
1.1 文档加载
现实世界中的文档格式五花八门:PDF、Word、Markdown、纯文本、HTML 网页等。一个健壮的 RAG 系统需要支持多种格式的文档加载器。在 Python 生态中,LangChain 和 LlamaIndex 是两个最流行的框架,它们封装了各类文档加载器,极大简化了开发工作。
我们将以 LangChain 为例,演示如何加载常见的文档格式。首先,安装必要的依赖库:
bash
pip install langchain langchain-community pypdf python-docx unstructured[all] chromadb1.1.1 加载 PDF 文件
PDF 是文档存储的常见格式,但提取其中的文本可能充满挑战(如表格、多列布局)。pypdf 是一个轻量级的 PDF 文本提取库。
python
# pdf_loader.py
from langchain_community.document_loaders import PyPDFLoader
from langchain.schema import Document
import os
from typing import List
def load_pdf(file_path: str) -> List[Document]:
"""
加载单个 PDF 文件,返回 LangChain Document 对象列表
Args:
file_path (str): PDF 文件的路径
Returns:
List[Document]: 文档对象列表,每个元素代表 PDF 中的一页
"""
# 初始化 PyPDFLoader,它会自动按页解析 PDF
loader = PyPDFLoader(file_path)
# load() 方法返回一个 Document 列表,每个 Document 包含 page_content 和 metadata
documents = loader.load()
# 为每个文档添加元数据,便于后续追踪来源
for doc in documents:
doc.metadata.update({
"source": file_path,
"type": "pdf"
})
print(f"成功加载 PDF 文件: {file_path},共 {len(documents)} 页")
return documents
# 示例用法
if __name__ == "__main__":
# 假设我们有一个名为 "example.pdf" 的文件
# docs = load_pdf("example.pdf")
# print(f"第一页内容预览: {docs[0].page_content[:200]}")
pass1.1.2 加载 Markdown 与文本文件
Markdown 是技术文档的常用格式,而纯文本则是最简单的载体。LangChain 提供了 TextLoader 可以处理这类文件。
python
# text_md_loader.py
from langchain_community.document_loaders import TextLoader
from langchain.schema import Document
from typing import List
import os
def load_text_or_md(file_path: str) -> List[Document]:
"""
加载文本或 Markdown 文件
Args:
file_path (str): 文件路径,支持 .txt, .md 等
Returns:
List[Document]: 文档对象列表,通常包含一个元素(整个文件内容)
"""
# 使用 TextLoader,它会读取整个文件内容作为一个 Document
# 注意:TextLoader 默认使用 UTF-8 编码,若文件为其他编码需指定 encoding 参数
loader = TextLoader(file_path, encoding='utf-8')
documents = loader.load()
# 添加元数据
for doc in documents:
doc.metadata.update({
"source": file_path,
"type": "text"
})
print(f"成功加载文本文件: {file_path}")
return documents
# 如果需要加载目录下的所有 Markdown 文件,可以编写一个批量加载函数
def load_markdowns_from_directory(directory_path: str) -> List[Document]:
"""
批量加载目录下的所有 .md 文件
Args:
directory_path (str): 目录路径
Returns:
List[Document]: 所有文档的合并列表
"""
all_docs = []
for root, dirs, files in os.walk(directory_path):
for file in files:
if file.endswith('.md') or file.endswith('.txt'):
file_path = os.path.join(root, file)
docs = load_text_or_md(file_path)
all_docs.extend(docs)
print(f"批量加载完成,共加载 {len(all_docs)} 个文档片段")
return all_docs1.1.3 加载 Word 文档
Word 文档(.docx)在办公场景中非常常见。我们可以使用 python-docx 库来解析。
python
# word_loader.py
from langchain.schema import Document
from typing import List
import docx
def load_docx(file_path: str) -> List[Document]:
"""
加载 .docx 文件,提取所有段落文本
Args:
file_path (str): Word 文档路径
Returns:
List[Document]: 包含整个文档内容的 Document 列表
"""
try:
# 打开 Word 文档
doc = docx.Document(file_path)
# 提取所有段落的文本,用换行符连接
full_text = "\n".join([paragraph.text for paragraph in doc.paragraphs])
# 封装为 LangChain Document
document = Document(
page_content=full_text,
metadata={
"source": file_path,
"type": "docx"
}
)
print(f"成功加载 Word 文档: {file_path}")
return [document]
except Exception as e:
print(f"加载 Word 文档失败: {file_path}, 错误: {e}")
return []
# 如果需要提取表格内容,可以扩展上述函数
def load_docx_with_tables(file_path: str) -> List[Document]:
"""
加载 .docx 文件,包含段落和表格内容
"""
doc = docx.Document(file_path)
content_parts = []
# 提取段落
for para in doc.paragraphs:
if para.text.strip():
content_parts.append(para.text)
# 提取表格
for table in doc.tables:
for row in table.rows:
row_text = "\t".join([cell.text for cell in row.cells])
if row_text.strip():
content_parts.append(row_text)
full_text = "\n".join(content_parts)
return [Document(page_content=full_text, metadata={"source": file_path, "type": "docx"})]1.2 文档分块
文档加载完成后,我们得到了一系列较长的文本(可能是整本书、整份报告)。如果直接将这些长文本嵌入并检索,会带来几个问题:
检索精度低:一个包含太多主题的块,当用户查询某个具体细节时,由于语义相似度可能不够聚焦,导致检索结果不准确。
LLM 上下文限制:大模型都有输入 token 数限制(如 GPT-3.5 为 4K/16K tokens)。过长的块无法全部放入提示词中。
成本与性能:嵌入更长的文本意味着更高的计算成本,且向量维度不变的情况下,长文本的语义信息会被稀释。
因此,我们需要将文档切分成语义连贯的"块"(Chunks)。分块策略的选择直接影响 RAG 系统的最终效果。
1.2.1 基础分块:按字符数分割
最简单的分块方式是按固定长度切割。虽然粗暴,但在某些场景下足够用。
python
# simple_chunking.py
from langchain.text_splitter import CharacterTextSplitter
from langchain.schema import Document
from typing import List
def simple_character_chunking(documents: List[Document], chunk_size: int = 500, chunk_overlap: int = 50) -> List[Document]:
"""
使用 CharacterTextSplitter 进行简单分块
Args:
documents: 原始文档列表
chunk_size: 每个块的最大字符数
chunk_overlap: 块之间的重叠字符数,用于保持上下文连贯
Returns:
分块后的 Document 列表
"""
# 初始化分割器
text_splitter = CharacterTextSplitter(
separator="\n", # 优先按换行符分割
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len, # 使用字符数计算长度
is_separator_regex=False
)
# 执行分块
chunks = text_splitter.split_documents(documents)
# 为每个块添加块索引元数据
for i, chunk in enumerate(chunks):
chunk.metadata['chunk_index'] = i
chunk.metadata['chunk_size'] = len(chunk.page_content)
print(f"简单分块完成:{len(documents)} 个文档 -> {len(chunks)} 个块")
return chunks1.2.2 高级分块:基于语义边界的分割
按字符分割可能会在句子中间切断,破坏语义完整性。更优的做法是使用递归分割器,它尝试优先按段落、句子、单词等层次进行分割,直到块的大小满足要求。
python
# recursive_chunking.py
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema import Document
from typing import List
def recursive_character_chunking(documents: List[Document], chunk_size: int = 500, chunk_overlap: int = 50) -> List[Document]:
"""
使用 RecursiveCharacterTextSplitter 进行递归分割
该分割器会尝试按照 ["\n\n", "\n", " ", ""] 的顺序逐步降级分割,
尽可能保持段落、句子完整
"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len,
separators=["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""] # 支持中英文分隔符
)
chunks = text_splitter.split_documents(documents)
for i, chunk in enumerate(chunks):
chunk.metadata['chunk_index'] = i
chunk.metadata['chunk_size'] = len(chunk.page_content)
print(f"递归分割完成:{len(documents)} 个文档 -> {len(chunks)} 个块")
return chunks1.2.3 语义分块:基于嵌入相似度的高级分割
在 Naive RAG 之上,还有更高级的语义分块方法:先按句子分割,然后计算相邻句子之间的嵌入相似度,当相似度发生显著变化时,在此处切分。这样可以保证每个块内部的语义高度相关。
python
# semantic_chunking.py
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import SentenceTransformersTokenTextSplitter
import numpy as np
from typing import List, Tuple
from langchain.schema import Document
def semantic_chunking(documents: List[Document], similarity_threshold: float = 0.7) -> List[Document]:
"""
基于语义相似度的分块
注意:此方法需要调用 Embedding 模型,开销较大,适合对质量要求极高的场景
Args:
documents: 原始文档列表
similarity_threshold: 相似度阈值,低于此值则切分
Returns:
语义分块后的 Document 列表
"""
# 这里假设我们已经有 OpenAI Embeddings,实际应用中可使用开源模型
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
all_chunks = []
for doc in documents:
# 1. 按句子分割
sentences = doc.page_content.split('。') # 简单中文分句,生产环境请使用更精确的分句器
sentences = [s.strip() for s in sentences if s.strip()]
if len(sentences) <= 1:
# 如果只有一个句子,直接作为一个块
all_chunks.append(Document(page_content=doc.page_content, metadata=doc.metadata))
continue
# 2. 获取所有句子的 Embedding
sentence_embeddings = embeddings.embed_documents(sentences)
# 3. 计算相邻句子相似度
similarities = []
for i in range(len(sentence_embeddings) - 1):
sim = np.dot(sentence_embeddings[i], sentence_embeddings[i+1]) / (
np.linalg.norm(sentence_embeddings[i]) * np.linalg.norm(sentence_embeddings[i+1])
)
similarities.append(sim)
# 4. 根据相似度决定切分点
current_chunk = []
current_chunk.append(sentences[0])
for i in range(1, len(sentences)):
# 如果当前句子与前一句的相似度低于阈值,则结束当前块
if similarities[i-1] < similarity_threshold:
# 完成当前块
chunk_text = '。'.join(current_chunk) + '。'
chunk_doc = Document(
page_content=chunk_text,
metadata={**doc.metadata, 'chunk_type': 'semantic'}
)
all_chunks.append(chunk_doc)
# 开始新块
current_chunk = [sentences[i]]
else:
current_chunk.append(sentences[i])
# 添加最后一个块
if current_chunk:
chunk_text = '。'.join(current_chunk) + '。'
all_chunks.append(Document(page_content=chunk_text, metadata={**doc.metadata, 'chunk_type': 'semantic'}))
print(f"语义分块完成:原始 {len(documents)} 个文档 -> {len(all_chunks)} 个块")
return all_chunks1.2.4 分块策略总结
| 分块方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 固定字符分割 | 简单、快速、可控 | 可能切断语义单元 | 日志、代码等结构化文本 |
| 递归分割 | 保留段落/句子完整性 | 仍可能切断语义边界 | 通用文档,平衡质量与效率 |
| 语义分块 | 块内语义高度内聚 | 计算开销大,依赖 Embedding | 高质量问答系统、学术论文 |
在实际项目中,通常需要根据文档类型和业务场景进行多次实验,找到最优的分块大小(通常 300-1000 tokens 之间)和重叠比例(一般 10%-20%)。
第二部分:Embedding(嵌入)
在 RAG 系统中,Embedding 是连接人类语言与机器计算的桥梁。它将文本片段转换为高维空间中的向量,使得我们可以通过数学运算(如余弦相似度)来度量文本之间的语义相似性。
2.1 向量定义与向量化的意义
什么是向量?
在数学上,向量是一组有序的数字。在自然语言处理中,一个词、一个句子甚至一篇文档都可以被表示为一个固定维度的向量。例如,OpenAI 的
text-embedding-ada-002模型将文本映射到 1536 维的向量空间。
为什么需要向量化?
-
语义计算:两个文本的相似度可以通过计算它们向量之间的夹角(余弦相似度)来获得。向量越接近,文本语义越相似。
-
高效检索:向量数据库支持在高维空间中快速进行最近邻搜索(ANN),从而在海量文档中快速找到最相关的片段。
-
跨模态统一:理论上,图像、音频都可以映射到同一向量空间,实现多模态检索。
2.2 向量相似算法
在向量检索中,最常用的三种距离/相似度算法是:
2.2.1 余弦相似度
余弦相似度衡量两个向量方向上的相似性,忽略向量长度的影响。计算公式:
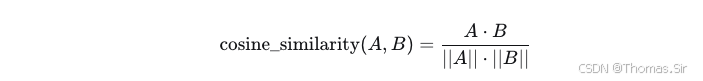
取值范围在 -1, 1 之间,1 表示方向完全相同,0 表示正交,-1 表示完全相反。在文本 Embedding 中,通常结果在 0~1 之间。
适用场景:文本 Embedding 通常被归一化,因此余弦相似度与点积等价,是语义检索最常用的指标。
2.2.2 欧氏距离
欧氏距离衡量向量在空间中的绝对距离。公式:
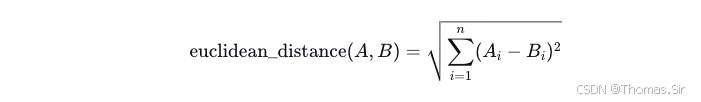
距离越小,表示向量越接近。如果 Embedding 经过了归一化,欧氏距离与余弦相似度存在转换关系。
适用场景:当向量长度本身具有意义时(如图像特征),欧氏距离更合适。
2.2.3 点积
点积直接计算两个向量的对应分量乘积之和。在向量归一化后,点积等价于余弦相似度。公式:
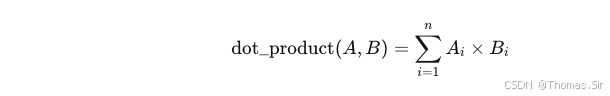
适用场景:许多向量数据库默认使用点积作为相似度度量,因为它计算速度快。
2.3 向量化实践
我们将使用开源 Embedding 模型 BAAI/bge-small-zh 进行向量化实践。该模型在中文任务上表现优秀,且对硬件要求较低。我们也可以使用 OpenAI 的 Embedding API,但需要 API Key。
首先安装必要的库:
python
pip install sentence-transformers torch2.3.1 使用开源模型进行向量化
python
# embedding_demo.py
from sentence_transformers import SentenceTransformer
import numpy as np
from typing import List, Union
import time
class LocalEmbedding:
"""
封装本地 Embedding 模型,用于将文本转换为向量
"""
def __init__(self, model_name: str = "BAAI/bge-small-zh"):
"""
初始化 Embedding 模型
Args:
model_name: HuggingFace 模型名称,可选:
- BAAI/bge-small-zh (384维,快速)
- BAAI/bge-base-zh (768维,平衡)
- BAAI/bge-large-zh (1024维,高精度)
"""
print(f"正在加载 Embedding 模型: {model_name}")
self.model = SentenceTransformer(model_name)
self.dimension = self.model.get_sentence_embedding_dimension()
print(f"模型加载完成,向量维度: {self.dimension}")
def embed_text(self, text: Union[str, List[str]]) -> np.ndarray:
"""
将单个文本或文本列表转换为向量
Args:
text: 单个字符串或字符串列表
Returns:
numpy 数组,shape = (n, dimension)
"""
if isinstance(text, str):
text = [text]
# 计算 Embedding
embeddings = self.model.encode(text, normalize_embeddings=True) # 归一化,便于余弦相似度计算
return embeddings
def compute_similarity(self, text1: str, text2: str) -> float:
"""
计算两个文本的余弦相似度
Returns:
相似度得分,范围 0~1
"""
vec1 = self.embed_text(text1)[0]
vec2 = self.embed_text(text2)[0]
# 因为已经归一化,点积即为余弦相似度
similarity = np.dot(vec1, vec2)
return float(similarity)
# 示例用法
if __name__ == "__main__":
# 初始化模型
embedder = LocalEmbedding("BAAI/bge-small-zh")
# 测试文本
texts = [
"我喜欢吃苹果,苹果是一种水果。",
"香蕉是黄色的,也是一种常见的水果。",
"今天天气真好,适合出去跑步。",
"深度学习是机器学习的一个分支。"
]
# 批量获取向量
start_time = time.time()
vectors = embedder.embed_text(texts)
elapsed = time.time() - start_time
print(f"向量化完成,耗时 {elapsed:.2f} 秒")
print(f"向量形状: {vectors.shape}")
print(f"第一个向量前10个维度: {vectors[0][:10]}")
# 计算相似度矩阵
print("\n相似度矩阵:")
for i in range(len(texts)):
for j in range(i+1, len(texts)):
sim = embedder.compute_similarity(texts[i], texts[j])
print(f"'{texts[i][:20]}...' vs '{texts[j][:20]}...': {sim:.4f}")2.3.2 批量处理分块后的文档
在实际 RAG 系统中,我们需要对知识库中的所有文档块进行向量化。
python
# batch_embedding.py
from typing import List
from langchain.schema import Document
import numpy as np
def embed_documents(
chunks: List[Document],
embedder: LocalEmbedding,
batch_size: int = 32
) -> List[np.ndarray]:
"""
批量对文档块进行向量化
Args:
chunks: 文档块列表
embedder: 已初始化的 Embedding 实例
batch_size: 批处理大小,避免内存溢出
Returns:
向量列表,每个元素对应一个块的向量
"""
texts = [chunk.page_content for chunk in chunks]
all_embeddings = []
# 分批处理
for i in range(0, len(texts), batch_size):
batch_texts = texts[i:i+batch_size]
batch_embeddings = embedder.embed_text(batch_texts)
all_embeddings.extend(batch_embeddings)
print(f"已处理 {min(i+batch_size, len(texts))}/{len(texts)} 个块")
# 为每个块添加向量到元数据(可选,通常向量会单独存储)
for chunk, embedding in zip(chunks, all_embeddings):
chunk.metadata['embedding_dim'] = len(embedding)
# 注意:通常不建议将向量存在 metadata 中,会占用大量内存
print(f"向量化完成,共 {len(all_embeddings)} 个向量")
return all_embeddings第三部分:Indexing(索引)
当我们拥有了所有文档块的向量后,如何快速找到与用户问题最相关的几个块?这就涉及到索引(Indexing)和检索(Retrieval)技术。索引的目的是构建一种数据结构,使得我们能够在对数时间复杂度内完成近似最近邻(Approximate Nearest Neighbor, ANN)搜索。
3.1 top-k 语义检索原理
语义检索的流程如下:
-
用户输入查询:例如"什么是向量数据库?"
-
查询向量化 :使用与知识库相同的 Embedding 模型将查询转换为向量
q。 -
相似度计算 :计算
q与知识库中所有向量v_i的相似度(余弦、欧氏距离等)。 -
Top-k 选取:选出相似度最高的 k 个文档块(k 通常为 3-10)。
-
返回结果:将这些块的文本内容作为上下文返回。
对于海量数据(如百万级文档),逐一遍历所有向量计算相似度是不可行的(时间复杂度 O(N))。因此,我们需要建立索引来加速检索。
3.1.1 暴力检索(Brute Force)
暴力检索是最简单直接的方法:计算查询向量与所有文档向量的相似度,然后排序。虽然准确率最高,但效率低下,仅适用于小规模数据集(< 1万条)。
python
# brute_force_search.py
import numpy as np
from typing import List, Tuple
from langchain.schema import Document
def brute_force_search(
query_vector: np.ndarray,
embeddings: List[np.ndarray],
chunks: List[Document],
top_k: int = 5
) -> List[Tuple[Document, float]]:
"""
暴力检索:计算查询向量与所有向量的余弦相似度,返回 top-k 结果
Args:
query_vector: 查询向量
embeddings: 所有文档块向量列表
chunks: 对应的文档块列表
top_k: 返回结果数量
Returns:
List of (Document, similarity_score) 按相似度降序排列
"""
similarities = []
# 计算每个向量与查询向量的相似度(已归一化,直接点积)
for emb, chunk in zip(embeddings, chunks):
sim = np.dot(query_vector, emb)
similarities.append((chunk, sim))
# 按相似度降序排序
similarities.sort(key=lambda x: x[1], reverse=True)
return similarities[:top_k]3.1.2 使用 FAISS 建立高效索引
FAISS(Facebook AI Similarity Search)是 Meta 开源的高效相似度搜索库,支持 GPU 加速,是工业界最常用的向量索引工具之一。
python
# faiss_indexing.py
import faiss
import numpy as np
from typing import List, Tuple
from langchain.schema import Document
class FAISSIndex:
"""
封装 FAISS 向量索引,支持高效的 top-k 检索
"""
def __init__(self, dimension: int):
self.dimension = dimension
self.index = None
self.chunks = [] # 存储对应的文档块
self.embeddings = [] # 存储向量,便于重建索引
def build_index(self, embeddings: List[np.ndarray], chunks: List[Document], use_gpu: bool = False):
"""
构建 FAISS 索引
Args:
embeddings: 向量列表,每个元素为 numpy 数组
chunks: 对应的文档块列表
use_gpu: 是否使用 GPU(需要安装 faiss-gpu)
"""
self.chunks = chunks
self.embeddings = embeddings
# 将向量列表转换为 float32 类型的 numpy 数组,shape = (n, dimension)
vectors = np.array(embeddings).astype('float32')
# 创建索引:这里使用 IndexFlatIP(内积索引,适用于归一化向量的余弦相似度)
# 注意:由于我们的向量已经归一化,内积等价于余弦相似度
self.index = faiss.IndexFlatIP(self.dimension)
# 添加向量到索引
self.index.add(vectors)
# 可选:使用 GPU(需要 faiss-gpu)
if use_gpu:
try:
res = faiss.StandardGpuResources()
self.index = faiss.index_cpu_to_gpu(res, 0, self.index)
print("已启用 GPU 加速")
except Exception as e:
print(f"GPU 启用失败,继续使用 CPU: {e}")
print(f"索引构建完成,共 {self.index.ntotal} 个向量")
def search(self, query_vector: np.ndarray, top_k: int = 5) -> List[Tuple[Document, float]]:
"""
检索最相似的 top-k 个文档块
Args:
query_vector: 查询向量,shape = (dimension,)
top_k: 返回结果数量
Returns:
List of (Document, similarity_score)
"""
# 确保向量维度正确
query = np.array([query_vector]).astype('float32')
# 执行搜索
# similarities: 相似度得分数组,shape = (1, top_k)
# indices: 索引数组,shape = (1, top_k)
similarities, indices = self.index.search(query, top_k)
results = []
for i in range(top_k):
idx = indices[0][i]
if idx != -1: # -1 表示无效索引
results.append((self.chunks[idx], float(similarities[0][i])))
return results
def add_documents(self, embeddings: List[np.ndarray], chunks: List[Document]):
"""
动态添加新的文档块(适用于增量更新)
"""
vectors = np.array(embeddings).astype('float32')
self.index.add(vectors)
self.chunks.extend(chunks)
self.embeddings.extend(embeddings)
print(f"已添加 {len(embeddings)} 个新文档,当前总数: {self.index.ntotal}")
# 示例:完整检索流程
def semantic_search_pipeline(query: str, faiss_index: FAISSIndex, embedder: LocalEmbedding, top_k: int = 5):
"""
完整的语义检索流程
"""
# 1. 查询向量化
query_vector = embedder.embed_text(query)[0]
# 2. 检索
results = faiss_index.search(query_vector, top_k)
# 3. 格式化输出
print(f"查询: {query}\n")
for i, (doc, score) in enumerate(results):
print(f"结果 {i+1} (相似度: {score:.4f}):")
print(f"来源: {doc.metadata.get('source', 'unknown')}")
print(f"内容: {doc.page_content[:200]}...")
print("-" * 50)
return results3.2 索引优化:从 Flat 到 IVF
IndexFlatIP 是精确检索,即暴力搜索。对于大规模数据,我们需要使用近似索引,如 IndexIVFFlat(倒排文件索引),它通过聚类将向量空间划分为多个区域,检索时只搜索与查询向量最接近的几个区域,大幅提升速度。
python
# advanced_faiss_index.py
def build_ivf_index(embeddings: List[np.ndarray], dimension: int, nlist: int = 100) -> faiss.Index:
"""
构建 IVF 索引(倒排文件索引)
Args:
embeddings: 向量列表
dimension: 向量维度
nlist: 聚类中心数量,通常设置为 sqrt(N) 或 4*sqrt(N)
Returns:
FAISS IVF 索引
"""
vectors = np.array(embeddings).astype('float32')
n = len(vectors)
# 创建量化器(用于计算距离)
quantizer = faiss.IndexFlatIP(dimension)
# 创建 IVF 索引,nlist 为聚类数量,这里使用内积
index = faiss.IndexIVFFlat(quantizer, dimension, nlist, faiss.METRIC_INNER_PRODUCT)
# 训练索引(必须)
print("正在训练 IVF 索引...")
index.train(vectors)
# 添加向量
index.add(vectors)
# 设置检索时搜索的聚类数量(nprobe),值越大越精确,但速度越慢
index.nprobe = 10
print(f"IVF 索引构建完成,共 {index.ntotal} 个向量,聚类中心数: {nlist}")
return index第四部分:向量存储
向量存储(Vector Store)是专门用于存储和检索向量数据的数据库系统。与传统数据库不同,向量数据库针对高维向量的相似度搜索进行了优化,支持高效的 ANN 算法。
4.1 向量数据库的介绍
向量数据库的核心功能包括:
-
存储向量:支持高维向量的持久化存储。
-
相似度检索:提供高效的 top-k 相似度搜索。
-
元数据过滤:支持根据来源、时间等元数据过滤后再检索。
-
混合检索:结合关键词检索(BM25)与向量检索,提升召回率。
-
可扩展性:支持分布式部署,处理亿级向量。
4.2 主流向量数据库与功能对比
目前市面上主流的向量数据库有:
| 数据库名称 | 类型 | 优势 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Chroma | 嵌入式/客户端-服务器 | 轻量、易用、Python 原生、与 LangChain 集成好 | 不支持分布式 | 原型开发、小规模应用 |
| Pinecone | 云服务 | 全托管、高可用、功能强大 | 需要付费、数据隐私问题 | 企业级生产环境 |
| Weaviate | 开源/云 | 支持混合检索、GraphQL API、模块化 | 部署相对复杂 | 需要混合检索的场景 |
| Qdrant | 开源/云 | 高性能、支持过滤、Rust 编写 | 社区相对较小 | 高性能需求场景 |
| Milvus | 开源/云 | 分布式、功能最全、支持 GPU | 运维成本高 | 超大规模数据集 |
| Faiss | 库(非数据库) | 极致性能、灵活 | 需要自己管理持久化 | 需要嵌入到现有系统 |
4.3 使用 Chroma 作为向量存储
Chroma 是最适合入门学习的向量数据库,它提供简洁的 API,并完美集成 LangChain。
python
# chroma_demo.py
from langchain_community.vectorstores import Chroma
from langchain.schema import Document
from typing import List
import numpy as np
class ChromaVectorStore:
"""
封装 Chroma 向量数据库,实现持久化存储与检索
"""
def __init__(self, embedding_model: LocalEmbedding, persist_directory: str = "./chroma_db"):
"""
初始化 Chroma 向量存储
Args:
embedding_model: 自定义的 Embedding 模型(需要实现 embed_documents 和 embed_query 方法)
persist_directory: 数据持久化目录
"""
self.embedding_model = embedding_model
self.persist_directory = persist_directory
self.vectorstore = None
# 将自定义 Embedding 模型适配为 LangChain 的 Embeddings 接口
class EmbeddingAdapter:
def __init__(self, model):
self.model = model
def embed_documents(self, texts: List[str]) -> List[List[float]]:
embeddings = self.model.embed_text(texts)
return embeddings.tolist()
def embed_query(self, text: str) -> List[float]:
embedding = self.model.embed_text(text)
return embedding[0].tolist()
self.adapter = EmbeddingAdapter(embedding_model)
def create_from_documents(self, documents: List[Document]):
"""
从文档列表创建向量数据库
"""
self.vectorstore = Chroma.from_documents(
documents=documents,
embedding=self.adapter,
persist_directory=self.persist_directory
)
# 持久化到磁盘
self.vectorstore.persist()
print(f"向量数据库创建成功,存储路径: {self.persist_directory}")
print(f"共存储 {self.vectorstore._collection.count()} 个向量")
def load_existing(self):
"""
加载已有的向量数据库
"""
self.vectorstore = Chroma(
embedding_function=self.adapter,
persist_directory=self.persist_directory
)
print(f"加载已有向量数据库,共 {self.vectorstore._collection.count()} 个向量")
def similarity_search(self, query: str, k: int = 5) -> List[Document]:
"""
相似度检索
"""
results = self.vectorstore.similarity_search(query, k=k)
return results
def similarity_search_with_score(self, query: str, k: int = 5) -> List[tuple]:
"""
带相似度得分的检索
"""
results = self.vectorstore.similarity_search_with_score(query, k=k)
return results
def add_documents(self, documents: List[Document]):
"""
增量添加文档
"""
self.vectorstore.add_documents(documents)
self.vectorstore.persist()
print(f"已添加 {len(documents)} 个文档,当前总数: {self.vectorstore._collection.count()}")4.4 使用 FAISS 作为本地向量存储
如果希望完全控制索引,且不需要持久化到数据库系统,FAISS + 文件存储是一个很好的选择。
python
# faiss_store.py
import pickle
import os
import numpy as np
from typing import List, Tuple
from langchain.schema import Document
class FAISSVectorStore:
"""
基于 FAISS 的本地向量存储,支持持久化
"""
def __init__(self, dimension: int, use_gpu: bool = False):
self.dimension = dimension
self.use_gpu = use_gpu
self.index = None
self.chunks = []
self.embeddings = []
def add(self, embeddings: List[np.ndarray], chunks: List[Document]):
"""
添加向量和文档块
"""
if self.index is None:
# 首次添加,创建索引
self.index = faiss.IndexFlatIP(self.dimension)
if self.use_gpu:
res = faiss.StandardGpuResources()
self.index = faiss.index_cpu_to_gpu(res, 0, self.index)
vectors = np.array(embeddings).astype('float32')
self.index.add(vectors)
self.chunks.extend(chunks)
self.embeddings.extend(embeddings)
def search(self, query_vector: np.ndarray, k: int = 5) -> List[Tuple[Document, float]]:
"""
检索
"""
query = np.array([query_vector]).astype('float32')
similarities, indices = self.index.search(query, k)
results = []
for i in range(k):
idx = indices[0][i]
if idx != -1:
results.append((self.chunks[idx], float(similarities[0][i])))
return results
def save(self, path: str):
"""
保存索引和元数据到磁盘
"""
os.makedirs(path, exist_ok=True)
# 保存 FAISS 索引
faiss.write_index(self.index, os.path.join(path, "index.faiss"))
# 保存文档块和向量(用于重建)
with open(os.path.join(path, "chunks.pkl"), "wb") as f:
pickle.dump(self.chunks, f)
with open(os.path.join(path, "embeddings.pkl"), "wb") as f:
pickle.dump(self.embeddings, f)
print(f"FAISS 存储已保存到: {path}")
def load(self, path: str):
"""
从磁盘加载
"""
# 加载 FAISS 索引
self.index = faiss.read_index(os.path.join(path, "index.faiss"))
# 加载文档块和向量
with open(os.path.join(path, "chunks.pkl"), "rb") as f:
self.chunks = pickle.load(f)
with open(os.path.join(path, "embeddings.pkl"), "rb") as f:
self.embeddings = pickle.load(f)
print(f"FAISS 存储已加载,共 {self.index.ntotal} 个向量")第五部分:提示词增强 RAG 设计
检索到相关文档块后,最后一步是构造提示词(Prompt)并调用大语言模型生成答案。提示词的设计直接决定了生成答案的质量。
5.1 基础 RAG 提示词模板
最简单的 RAG 提示词包含三个部分:系统指令、上下文、用户问题。
python
# basic_prompt.py
def build_basic_rag_prompt(query: str, contexts: List[str]) -> str:
"""
构建基础的 RAG 提示词
Args:
query: 用户问题
contexts: 检索到的上下文列表
Returns:
构造好的提示词字符串
"""
# 将多个上下文合并
context_str = "\n\n".join([f"[片段{i+1}]: {ctx}" for i, ctx in enumerate(contexts)])
prompt = f"""请基于以下提供的上下文信息回答用户的问题。如果上下文中没有相关信息,请直接说"根据现有资料无法回答该问题",不要编造信息。
### 上下文信息 ###
{context_str}
### 用户问题 ###
{query}
### 回答 ###
"""
return prompt5.2 高级提示词设计
为了提升回答质量,我们可以加入更多指令,如角色扮演、格式要求、引用来源等。
python
# advanced_prompt.py
def build_advanced_rag_prompt(
query: str,
contexts: List[tuple], # (document, score)
conversation_history: List[dict] = None,
output_format: str = "markdown"
) -> str:
"""
构建高级 RAG 提示词,包含角色设定、来源引用、历史对话等
Args:
query: 用户问题
contexts: 上下文列表,每个元素为 (document, similarity_score)
conversation_history: 历史对话,格式如 [{"role": "user", "content": "..."}, ...]
output_format: 输出格式,支持 "markdown", "json", "plain"
Returns:
构造好的提示词
"""
# 角色设定
system_message = """你是一个专业的知识助手,名叫"智答"。你的职责是基于提供的参考资料,准确、清晰地回答用户的问题。
请遵循以下原则:
1. 只根据提供的上下文回答问题,不要使用外部知识。
2. 如果上下文不足以回答问题,明确告知用户信息不足。
3. 回答时尽量引用具体的上下文来源,让用户知道信息的出处。
4. 回答要简洁、有条理,使用清晰的段落。
"""
# 构建上下文部分,包含相似度得分
context_section = "### 参考资料 ###\n"
for i, (doc, score) in enumerate(contexts):
source = doc.metadata.get('source', '未知来源')
# 相似度阈值过滤:低于 0.7 的标注为低置信度
confidence = "高置信度" if score > 0.7 else "中等置信度"
context_section += f"\n[来源{i+1}] 文件: {source} | 相关度: {score:.3f} ({confidence})\n"
context_section += f"{doc.page_content}\n"
context_section += "-" * 50 + "\n"
# 历史对话部分(可选)
history_section = ""
if conversation_history:
history_section = "### 对话历史 ###\n"
for turn in conversation_history[-3:]: # 只取最近3轮
role = "用户" if turn["role"] == "user" else "助手"
history_section += f"{role}: {turn['content']}\n"
history_section += "\n"
# 输出格式指令
format_instruction = ""
if output_format == "markdown":
format_instruction = "请使用 Markdown 格式组织回答,适当使用标题、列表、加粗等元素增强可读性。"
elif output_format == "json":
format_instruction = "请以 JSON 格式返回答案,包含 'answer' 和 'sources' 两个字段。"
# 最终提示词
prompt = f"""{system_message}
{context_section}
{history_section}
### 用户当前问题 ###
{query}
{format_instruction}
### 回答 ###
"""
return prompt5.3 调用大模型生成答案
我们可以使用 OpenAI API 或本地模型(如 ChatGLM、Llama)来生成答案。这里以 OpenAI 为例。
python
# llm_generation.py
from openai import OpenAI
from typing import List, Dict, Any
import os
class RAGGenerator:
"""
RAG 生成器,负责调用 LLM 生成最终答案
"""
def __init__(self, api_key: str = None, model: str = "gpt-3.5-turbo", base_url: str = None):
"""
初始化生成器
Args:
api_key: OpenAI API Key,如果不提供则从环境变量 OPENAI_API_KEY 读取
model: 模型名称
base_url: API 基础 URL,可用于代理或本地模型
"""
self.api_key = api_key or os.getenv("OPENAI_API_KEY")
if not self.api_key:
raise ValueError("请提供 OpenAI API Key")
self.client = OpenAI(api_key=self.api_key, base_url=base_url)
self.model = model
def generate(self, prompt: str, temperature: float = 0.3, max_tokens: int = 1000) -> str:
"""
生成回答
Args:
prompt: 提示词
temperature: 温度参数,0-1之间,越低越确定
max_tokens: 最大生成 token 数
Returns:
生成的回答文本
"""
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "你是一个专业的智能助手。"},
{"role": "user", "content": prompt}
],
temperature=temperature,
max_tokens=max_tokens
)
return response.choices[0].message.content
except Exception as e:
print(f"生成失败: {e}")
return "抱歉,生成回答时遇到错误,请稍后重试。"
def generate_with_history(self, messages: List[Dict[str, str]], temperature: float = 0.3) -> str:
"""
支持对话历史的生成
"""
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=temperature
)
return response.choices[0].message.content5.4 完整 RAG 流程整合
现在,我们将所有组件整合起来,形成一个完整的 Naive RAG 系统。
python
# complete_rag.py
import os
from typing import List, Optional
from langchain.schema import Document
class NaiveRAG:
"""
完整的 Naive RAG 系统,整合文档加载、分块、向量化、检索、生成
"""
def __init__(self,
embedding_model_name: str = "BAAI/bge-small-zh",
llm_model: str = "gpt-3.5-turbo",
chunk_size: int = 500,
chunk_overlap: int = 50,
top_k: int = 5):
"""
初始化 RAG 系统
"""
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
self.top_k = top_k
# 初始化 Embedding 模型
self.embedder = LocalEmbedding(embedding_model_name)
# 初始化向量存储(使用 Chroma)
self.vectorstore = ChromaVectorStore(self.embedder)
# 初始化生成器
self.generator = RAGGenerator(model=llm_model)
# 文档存储(原始文档块)
self.chunks = []
def ingest_documents(self, file_paths: List[str]):
"""
摄入文档:加载、分块、向量化、存储
"""
all_docs = []
# 1. 加载文档
for file_path in file_paths:
if file_path.endswith('.pdf'):
docs = load_pdf(file_path)
elif file_path.endswith('.docx'):
docs = load_docx(file_path)
elif file_path.endswith('.txt') or file_path.endswith('.md'):
docs = load_text_or_md(file_path)
else:
print(f"不支持的文件类型: {file_path}")
continue
all_docs.extend(docs)
print(f"文档加载完成,共 {len(all_docs)} 个原始文档片段")
# 2. 分块
self.chunks = recursive_character_chunking(
all_docs,
chunk_size=self.chunk_size,
chunk_overlap=self.chunk_overlap
)
# 3. 创建向量数据库
self.vectorstore.create_from_documents(self.chunks)
print("文档摄入完成!")
def query(self, question: str, return_context: bool = False) -> dict:
"""
查询问答
Args:
question: 用户问题
return_context: 是否返回检索到的上下文
Returns:
包含答案和可选上下文的字典
"""
# 1. 检索相关上下文
retrieved_docs = self.vectorstore.similarity_search_with_score(question, k=self.top_k)
# 提取文本内容
contexts = [(doc, score) for doc, score in retrieved_docs]
context_texts = [doc.page_content for doc, _ in contexts]
# 2. 构建提示词
prompt = build_advanced_rag_prompt(question, contexts)
# 3. 生成答案
answer = self.generator.generate(prompt)
result = {
"answer": answer,
"question": question
}
if return_context:
result["contexts"] = [
{
"content": doc.page_content,
"score": score,
"source": doc.metadata.get("source", "unknown")
}
for doc, score in contexts
]
return result
def chat_loop(self):
"""
交互式命令行对话
"""
print("RAG 问答系统已启动,输入 'exit' 退出")
print("-" * 50)
while True:
question = input("\n请输入问题: ").strip()
if question.lower() == 'exit':
break
if not question:
continue
print("正在思考...")
result = self.query(question)
print("\n回答:")
print(result["answer"])
print("\n" + "-" * 50)
# 示例用法
if __name__ == "__main__":
# 初始化系统
rag = NaiveRAG(
embedding_model_name="BAAI/bge-small-zh",
llm_model="gpt-3.5-turbo",
chunk_size=500,
top_k=5
)
# 摄入文档(假设有一批文档)
# rag.ingest_documents(["docs/产品手册.pdf", "docs/FAQ.md"])
# 启动对话
# rag.chat_loop()
# 单次查询
# result = rag.query("如何配置环境变量?")
# print(result["answer"])第六部分:本章练习题与解答
为了帮助读者巩固所学知识,我们设计了以下练习题,涵盖选择题、填空题、简答题和实操题。
6.1 选择题
1. 在 RAG 系统中,对文档进行分块的主要目的是什么?
A. 减少存储空间
B. 提高检索精度和满足 LLM 上下文限制
C. 加快文档加载速度
D. 增加答案长度
答案:B
解析:分块的主要目的是让每个块包含语义完整的信息,便于检索时精准匹配,同时确保每个块的大小不超过 LLM 的上下文限制。
2. 以下哪种相似度计算方法在向量归一化后与点积等价?
A. 欧氏距离
B. 曼哈顿距离
C. 余弦相似度
D. 杰卡德相似度
答案:C
解析:当向量经过归一化(模长为1)后,点积结果等于余弦相似度。
3. 下列哪个向量数据库是嵌入式、轻量级且与 LangChain 集成最友好的?
A. Milvus
B. Pinecone
C. Chroma
D. Weaviate
答案:C
解析:Chroma 是轻量级的嵌入式向量数据库,API 简洁,适合原型开发和教学。
6.2 填空题
1. 在 FAISS 中,_________ 索引是精确检索,而 _________ 索引通过聚类实现近似检索,以提升速度。
答案:IndexFlatIP;IndexIVFFlat
解析:IndexFlatIP 暴力计算所有向量的相似度,结果精确但慢;IndexIVFFlat 使用倒排索引,牺牲少量精度换取速度。
2. 在 RAG 提示词设计中,通常包含三个核心部分:系统指令、_________ 和用户问题。
答案:上下文/参考资料
解析:RAG 的核心就是将检索到的上下文作为生成依据。
3. 常用的中文 Embedding 模型 BAAI/bge-small-zh 输出的向量维度是 _________。
答案:384
解析:bge-small-zh 输出 384 维向量,bge-base-zh 为 768 维,bge-large-zh 为 1024 维。
6.3 简答题
1. 请简述 Naive RAG 的基本工作流程,并说明每个步骤的作用。
参考答案:
Naive RAG 的工作流程分为三个主要阶段:
-
索引阶段:
-
文档加载:从 PDF、Word 等格式中提取文本。
-
文档分块:将长文档切分为语义完整的块,便于检索。
-
向量化:使用 Embedding 模型将文本块转换为向量。
-
存储:将向量存入向量数据库,建立索引。
-
-
检索阶段:
-
用户输入查询后,同样使用 Embedding 模型将查询向量化。
-
在向量数据库中执行相似度搜索,找到最相关的 top-k 个文档块。
-
-
生成阶段:
-
将检索到的文档块作为上下文,结合用户问题构造提示词。
-
调用大语言模型生成基于上下文的答案。
-
2. 什么是语义分块?相比固定长度分块,它有什么优势?
参考答案:
语义分块是一种基于文本语义相似度进行切分的方法。首先将文本按句子分割,然后计算相邻句子之间的向量相似度,当相似度低于阈值时在此处切分,使得每个块内部的语义高度内聚。
优势:
-
每个块内的信息主题一致,不会在不同主题间跳跃。
-
检索时更容易命中完整的主题单元,提高答案连贯性。
-
减少因切断关键信息导致的检索遗漏。
3. 在使用向量检索时,为什么通常要对向量进行归一化?
参考答案:
归一化是将向量的模长变为1的过程。主要好处有:
-
归一化后,向量点积等于余弦相似度,简化计算。
-
避免向量长度对相似度度量的影响,只关注方向(语义)。
-
许多近似最近邻算法(如 FAISS 的 IndexFlatIP)要求输入向量已归一化。
-
提高数值稳定性。
6.4 实操题
题目:请基于本文提供的代码,搭建一个简单的 RAG 系统,回答以下问题:
-
使用
BAAI/bge-small-zh作为 Embedding 模型,对一段你感兴趣的文本(不少于500字)进行分块和向量化。 -
构建 FAISS 索引,并实现一个查询函数,返回 top-3 最相似的块。
-
如果使用 OpenAI API(或本地模型),生成最终答案。
-
记录并分析:不同分块大小(如 200、500、1000)对检索结果的影响。
参考答案框架:
python
# 实操题答案示例
import numpy as np
from sentence_transformers import SentenceTransformer
import faiss
# 1. 准备文本
text = """
(请替换为你的文本)
"""
# 2. 分块函数
def chunk_text(text, chunk_size=500, overlap=50):
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunk = ' '.join(words[i:i+chunk_size])
chunks.append(chunk)
return chunks
# 3. 向量化
model = SentenceTransformer('BAAI/bge-small-zh')
chunks = chunk_text(text, chunk_size=500)
embeddings = model.encode(chunks, normalize_embeddings=True)
# 4. 构建 FAISS 索引
dimension = embeddings.shape[1]
index = faiss.IndexFlatIP(dimension)
index.add(embeddings.astype('float32'))
# 5. 查询函数
def search(query, k=3):
query_vec = model.encode([query], normalize_embeddings=True)
scores, indices = index.search(query_vec.astype('float32'), k)
results = [(chunks[idx], score) for idx, score in zip(indices[0], scores[0])]
return results
# 6. 测试不同分块大小
query = "你的测试问题"
for size in [200, 500, 1000]:
chunks_test = chunk_text(text, chunk_size=size)
print(f"分块大小 {size}: 共 {len(chunks_test)} 个块")
results = search(query)
print(f"Top 相似度: {results[0][1]:.4f}")分析要点:
分块过小(200):可能丢失上下文,但检索更精细。
分块适中(500):平衡检索精度和上下文完整性。
分块过大(1000):可能包含多个主题,降低检索精度,且可能超出 LLM 上下文限制。
总结
本文系统性地介绍了 Naive RAG 的核心技术栈与实现细节,从知识库搭建、Embedding、索引、向量存储到提示词增强生成,为读者呈现了一个完整可运行的 RAG 系统。我们不仅讲解了理论原理,更提供了大量带详细注释的代码示例,涵盖文档加载、分块策略、Embedding 模型使用、FAISS/Chroma 向量数据库集成以及提示词工程等关键环节。
回顾全文,有几个核心要点值得强调:
-
分块是艺术:没有万能的"最佳分块大小",需要根据文档类型、检索任务和 LLM 上下文长度进行实验调优。递归分割是平衡效率与效果的良好起点。
-
Embedding 模型的选择至关重要:对于中文场景,BAAI 系列模型(bge-small/base/large)在准确性和资源消耗之间提供了灵活选择。向量归一化与相似度度量的配合需要仔细考量。
-
向量数据库的演进:从简单的 FAISS 库到功能完备的 Chroma/Pinecone/Milvus,选择合适的存储方案取决于数据规模、部署环境和团队维护能力。对于原型开发,Chroma 提供了最低的入门门槛。
-
提示词工程决定生成质量:优秀的提示词应该包含角色设定、明确的指令、上下文来源引用以及输出格式要求。合理的温度参数设置(0.1-0.3)有助于平衡确定性与创造性。
-
评测与迭代:Naive RAG 仅仅是起点。在实践中,我们需要通过构建评测数据集、计算 Hit Rate、MRR 等指标来持续优化系统。后续可探索高级 RAG 技术,如查询重写、上下文压缩、多路召回、自省机制等。
通过本文的学习,读者应该能够独立搭建一个基础的 RAG 问答系统,并具备进一步探索更复杂 RAG 架构的能力。RAG 技术仍在快速发展,结合 Agent 的自主决策能力、知识图谱的结构化知识、多模态数据的融合,未来将解锁更多激动人心的应用场景。
希望本文能成为你踏入 RAG 世界的坚实一步。现在,拿起代码,去构建属于你自己的智能问答系统吧!
🌟 感谢您耐心阅读到这里!
🚀 技术成长没有捷径,但每一次的阅读、思考和实践,都在默默缩短您与成功的距离。
💡 如果本文对您有所启发,欢迎点赞👍、收藏📌、分享📤给更多需要的伙伴!
🗣️ 期待在评论区看到您的想法、疑问或建议,我会认真回复,让我们共同探讨、一起进步~
🔔 关注我,持续获取更多干货内容!
🤗 我们下篇文章见!