预训练模型
BERT架构
bert是transformer编码器架构创建的双向性预训练语言模型,并不适用于文本生成,工作范式可以分为预训练(Pre-training)和微调(Fine-tuning)两个主要阶段。
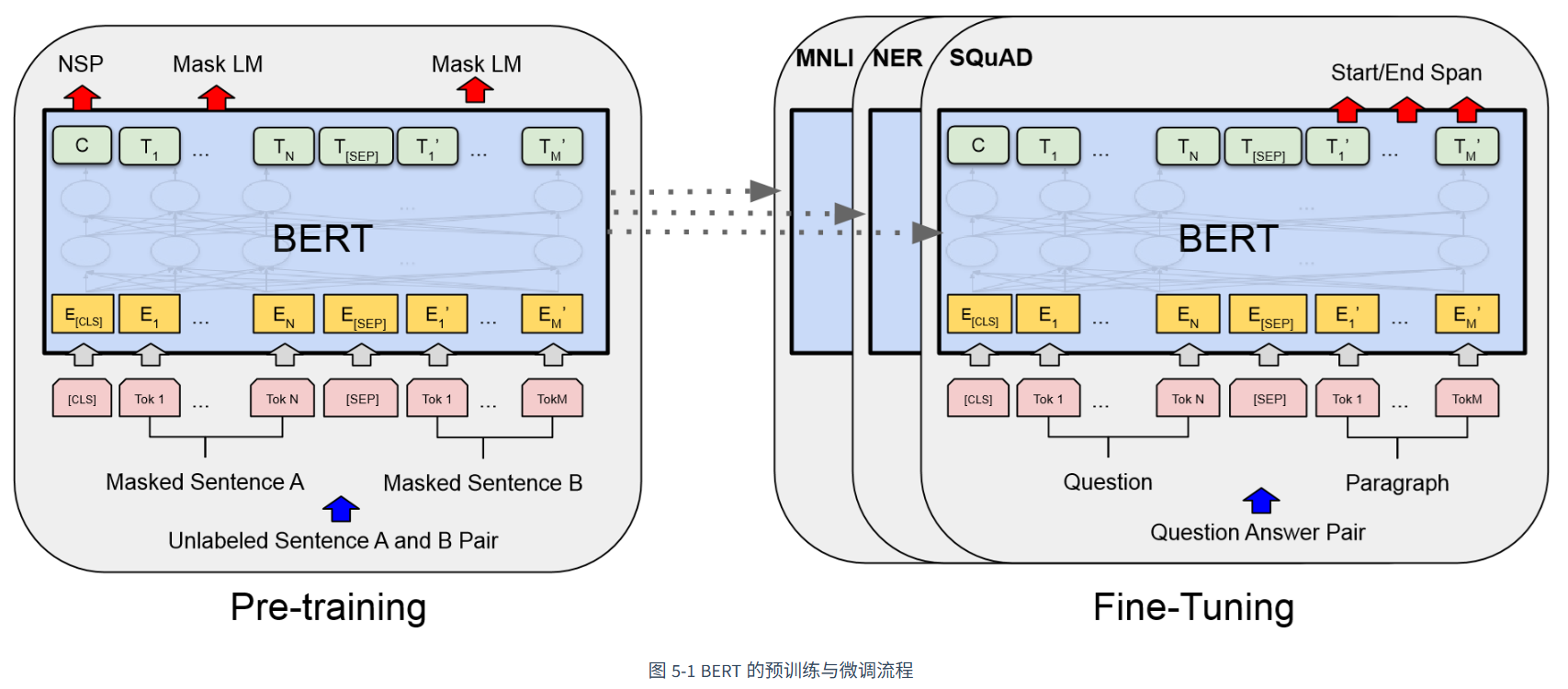
常见的bert模型规模:
|--------------|------------|---------------|---------------|----------|
| 模型 | 层数 (L) | 隐藏层大小 (H) | 注意力头数 (A) | 总参数量 |
| BERT-Base | 12 | 768 | 12 | ~1.1 亿 |
| BERT-Large | 24 | 1024 | 16 | ~3.4 亿 |
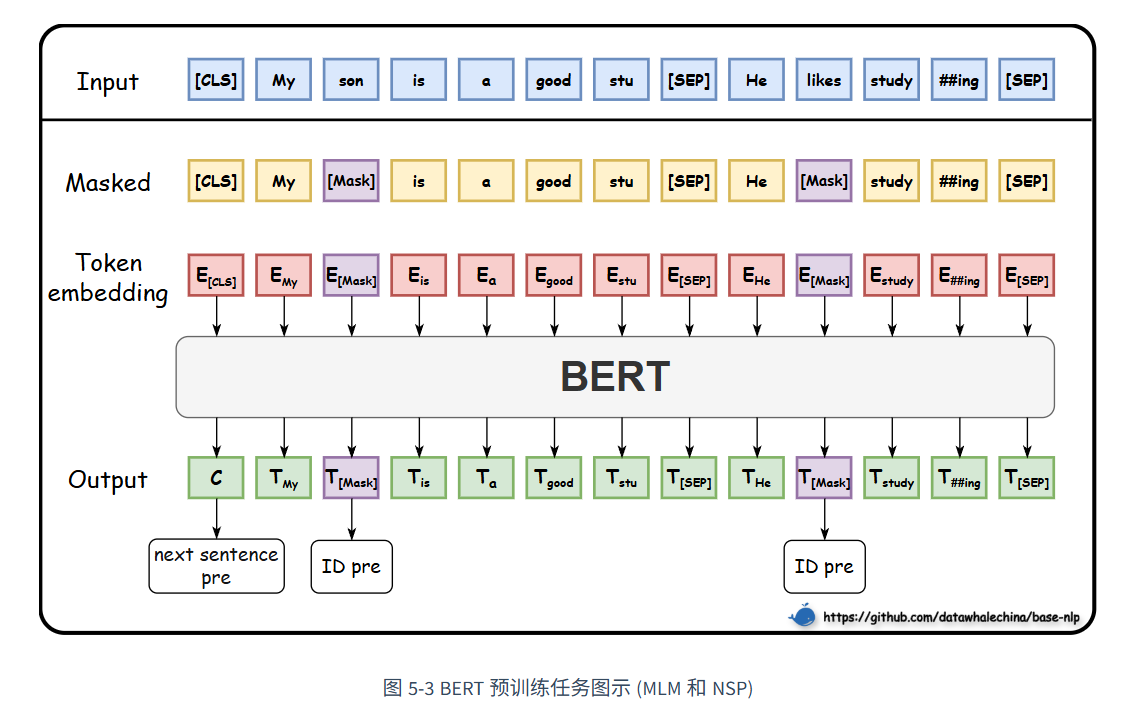
bert预训练任务:MLM掩码语言模型,随机mask部分词元;下一句预测NSP,后续研究RoBERTa,ALBERT 对NSP提出了质疑,但是在BERT原始论文的消融实验证明是有用的。
实践技巧与生态
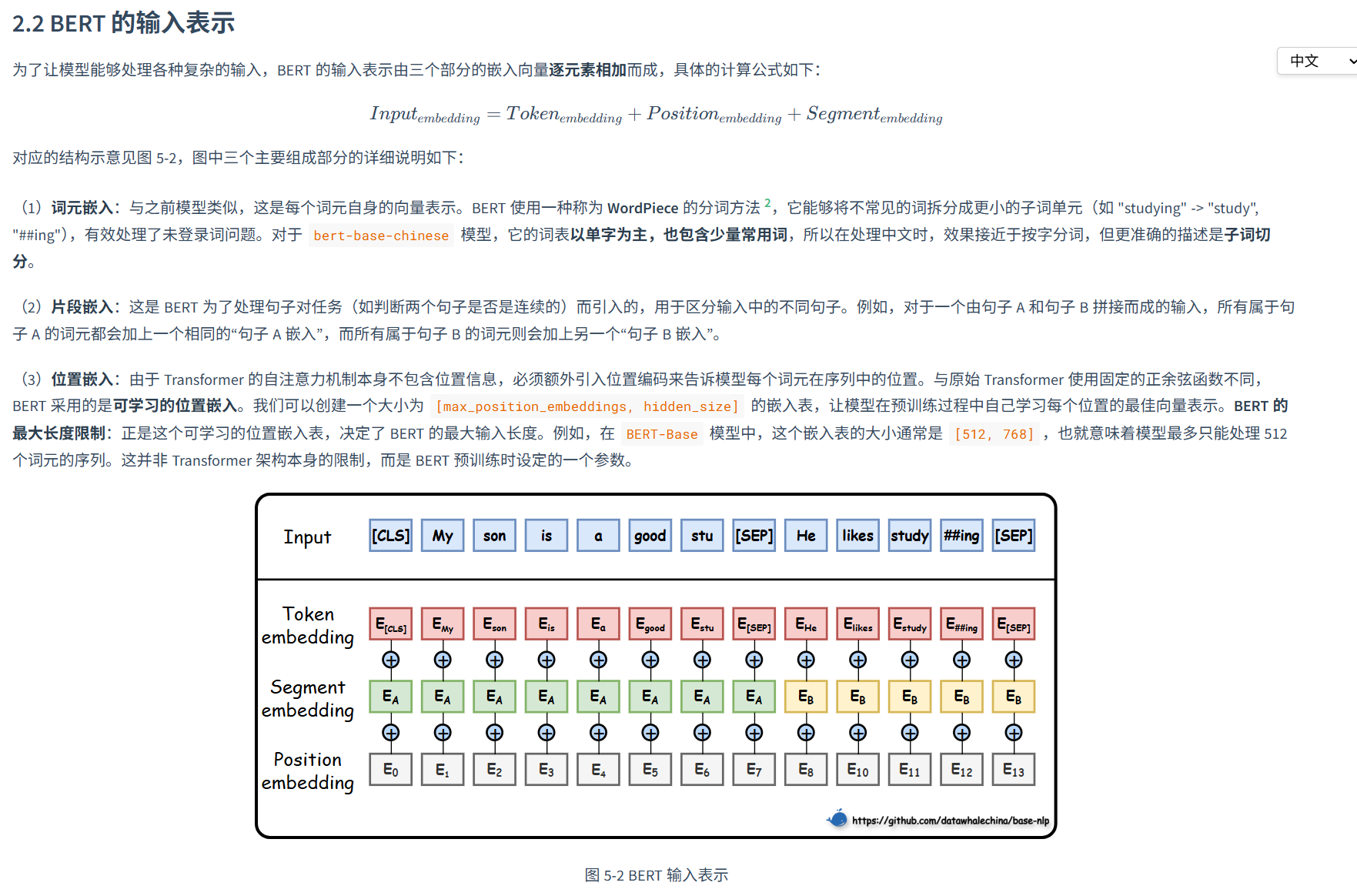
最大长度限制:最大输入长度为512个token(包含特殊token)。其次是特殊 Token 的添加 ,输入序列的开头必须添加 [CLS],结尾必须添加 [SEP]。******** 虽然现在的 Tokenizer 通常会自动处理这些特殊 Token 的添加,但在手动构建输入或分析数据时,务必牢记这一要求。在某些任务(如命名实体识别)中,将最后几层(例如,最后四层)的向量进行拼接或相加,有时能获得比单独使用最后一层更好的效果。
下载好预训练模型参数放在本地:
python
import torch
import os
from transformers import AutoTokenizer, AutoModel
#%%
# 1. 环境和模型配置
# os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' # 可选:设置镜像
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
local_model_path = "d:\\桌面\\大模型\\大模型基础\\5BERT 代码实战\\bert-base-chinese" # 本地模型目录绝对路径
texts = ["我来自中国", "我喜欢自然语言处理"]
# 2. 加载模型和分词器(使用本地路径)
tokenizer = AutoTokenizer.from_pretrained(local_model_path)
model = AutoModel.from_pretrained(local_model_path, from_tf=False).to(device)
model.eval()
print("\n--- BERT 模型结构 ---")
print(model)
# 3. 文本预处理
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt").to(device)
# 打印 Tokenizer 的完整输出,以理解其内部结构
print("--- Tokenizer 输出 ---")
for key, value in inputs.items():
print(f"{key}: \n{value}\n")
# 4. 模型推理
with torch.no_grad():
outputs = model(**inputs)
# 5. 提取特征
last_hidden_state = outputs.last_hidden_state
sentence_features_pooler = getattr(outputs, "pooler_output", None)
# (1) 提取句子级别的特征向量 ([CLS] token)
sentence_features = last_hidden_state[:, 0, :]
# (2) 提取第一个句子的词元级别特征
first_sentence_tokens = last_hidden_state[0, 1:6, :]
print("\n--- 特征提取结果 ---")
print(f"句子特征 shape: {sentence_features.shape}")
if sentence_features_pooler is not None:
print(f"pooler_output shape: {sentence_features_pooler.shape}")GPT架构
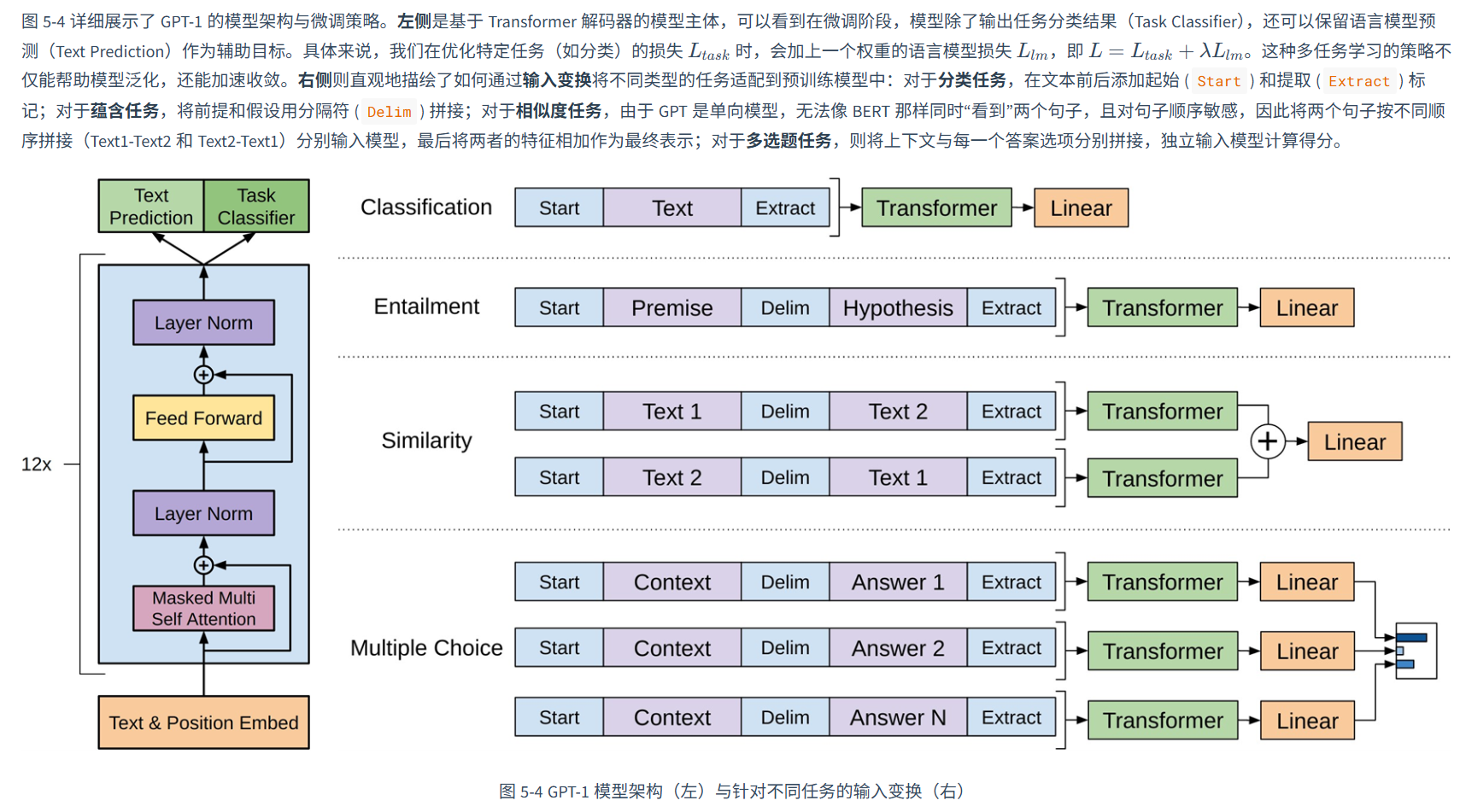
随着模型规模的增长:由预训练+微调->提示(Prompt) 和上下文学习(In-context Learning, ICL)

使用pipline实现代码
python
# pipeline 应用
from transformers import pipeline
print("\n\n--- Pipeline 快速演示 (英文) ---")
generator = pipeline("text-generation", model=model_name, device=device)
pipeline_outputs = generator("I like eating fried", max_new_tokens=5, num_return_sequences=1)
print(pipeline_outputs[0]['generated_text'])T5架构
提示词:

Span Corruption和哨兵符


Hugging face
AutoClass智能加载机制:AutoTokenizer, AutoModel, AutoConfig; 根据 Checkpoint 名称,自动推断并加载正确的模型架构**。其中,** from_pretrained** 是加载接口,既支持从 Hub 在线下载,也支持从本地目录加载.而 save_pretrained 则是保存接口,可将模型权重、配置和词表保存到本地。
python
from transformers import AutoTokenizer, AutoModel
# 自动加载:无需手动导入 BertTokenizer 或 BertModel
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
model = AutoModel.from_pretrained("bert-base-chinese")
# 保存:将模型权重与分词器配置保存到本地目录
model.save_pretrained("./my_local_bert")
tokenizer.save_pretrained("./my_local_bert")Trainer:微调与评估
python
from transformers import TrainingArguments, Trainer, AutoModelForSequenceClassification, AutoTokenizer
# 使用英文模型 distilbert-base-uncased
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 为了快速演示,我们只取一小部分数据
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(100))
small_eval_dataset = tokenized_datasets["validation"].shuffle(seed=42).select(range(100))
# 1. 准备模型
model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
# 2. 配置参数
training_args = TrainingArguments(
output_dir="test_trainer",
eval_strategy="epoch", # 每个 epoch 结束进行评估
num_train_epochs=1,
)
# 3. 实例化 Trainer 并启动训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
)
trainer.train()
python
import numpy as np
import evaluate
# 加载评估指标
metric = evaluate.load("accuracy")
# 定义计算函数:将 Logits 转换为 Predictions 并计算 Accuracy
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# 重新实例化 Trainer,注入 compute_metrics
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics, # 关键步骤
)
# 训练并评估
trainer.train()