场景
一、Kafka 是什么?
Apache Kafka 是一个分布式、高吞吐、可持久化、高可用的消息队列 / 事件流平台。
主要用途:
异步解耦:系统之间不直接调用,通过消息通信
削峰填谷:流量突增时缓冲,防止下游被打崩
日志收集 / 数据同步:如用户行为日志、埋点、CDC 数据
实时流处理:配合 Flink、Spark Streaming 做实时计算
特点:
极高吞吐:单机几十万 TPS
消息持久化到磁盘,可重复消费
分布式可扩展,支持多副本高可用
消息顺序性保证
二、核心架构角色
1. Broker
Kafka 服务器节点
一个集群由多个 Broker 组成
负责存储消息、处理读写请求
2. Producer(生产者)
发送消息到 Kafka 的客户端
决定消息发往哪个分区(轮询、哈希、自定义)
3. Consumer(消费者)
从 Kafka 拉取消息的客户端
主动拉取(pull),不是 Kafka 推送
4. Consumer Group(消费者组)
最重要概念之一
一组消费者共同消费一个或多个 Topic
同一个组内,一条消息只会被一个消费者消费
不同组可以重复消费同一条消息
组内消费者数量 ≤ 分区数(多了闲置)
5. Topic(主题)
消息的分类,类似 "消息队列名称"
生产者发往 Topic,消费者订阅 Topic
6. Partition(分区)
核心中的核心
一个 Topic 可以分成多个 Partition
消息被分散存储在不同分区
同一分区内消息严格有序,不同分区不保证全局有序
分区越多,并发消费能力越强
7. Replica(副本)
每个分区可以有多个副本(备份)
分为:
Leader:负责读写
Follower:只同步数据,不对外提供服务
副本机制保证高可用,Leader 挂了 Follower 自动选举新 Leader
8. Offset(偏移量)
消息在分区内的唯一编号,从 0 递增
消费者通过 Offset 标记消费位置
Offset 由消费者自己维护(新版存在 Kafka 内部主题 __consumer_offsets)
三、消息存储机制
消息持久化到磁盘,不是内存
以分段文件存储:.log 数据文件 + .index 索引文件
可设置过期策略(按时间 / 大小删除)
顺序写磁盘,所以极快
四、消费模式
Pull 模式:消费者主动拉取
消费位点自主管理:
自动提交
手动提交(业务更可靠)
三种消费策略:
earliest:从头开始消费
latest:只消费最新消息
none:无位移时报错
五、核心特性
1. 顺序保证
分区内严格有序
想要全局有序:Topic 只设 1 个分区(但失去并发)
2. 高可用
多副本机制
自动故障转移
数据不丢(配置acks=all、min.insync.replicas=2)
3. 高吞吐
批量发送
页缓存 + 零拷贝
顺序写磁盘
4. 可扩展
集群可水平扩容
Topic 可增加分区
5. 消息可靠性
acks 机制:
acks=0:发完不管(最快)
acks=1:Leader 写入即确认
acks=all:所有 ISR 副本写入才确认(最安全)
六、重要进阶概念
1. ISR(In-Sync Replicas)
与 Leader 保持同步的副本集合
只有 ISR 内的副本才有资格被选为新 Leader
防止数据不一致
2. 重平衡(Rebalance)
组内消费者数量变化、分区变化时触发
重新分配分区给消费者
频繁 Rebalance 会影响性能,要避免
3. 事务消息
保证生产者发送多条消息原子性
消费者可设置读已提交模式,避免脏数据
4. 延迟队列 / 死信队列
Kafka 原生不支持延迟队列,但可通过:
多层 Topic + 定时转移
第三方插件实现
消费失败的消息可丢入死信队列(DLQ)
5. 消息回溯
可以重置 Offset,重新消费历史消息
七、和其他 MQ 的简单对比

注:
博客:
https://blog.csdn.net/badao_liumang_qizhi
实现
Windows 本地搭建 Kafka + Zookeeper
- 下载安装 JDK 8+
Kafka 需要 Java 环境,你本地必须装 JDK 并配置好环境变量。
- 下载 Kafka(自带 Zookeeper,不用单独下!)
去官网下载:https://archive.apache.org/dist/kafka/2.8.2/kafka_2.13-2.8.2.tgz
推荐 2.8.2 版本,最稳定、Windows 兼容最好。
下载后解压到一个无中文、无空格的目录
- 修改 Zookeeper 配置
进入上面解压后config目录
打开文件:zookeeper.properties
确认这一行(默认就是对的):
dataDir=/tmp/zookeeper
Windows 可以不改,也能跑。
- 修改 Kafka 配置(必须改!)
打开文件:server.properties
找到并修改两处:
① 日志路径(Windows 必须改)
log.dirs=D:\kafka_2.13-2.8.2\kafka-logs
② 允许外部访问(本地测试必须加)
在文件末尾加:
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://localhost:9092保存即可。
5、启动 Zookeeper(必须先启动!)
打开 CMD 命令行,进入 Kafka 目录
执行启动命令:
bin\windows\zookeeper-server-start.bat config\zookeeper.properties看到输出:
Started AdminServer on address 0.0.0.0 at port 8080
6、启动 Kafka(第二个 CMD 窗口)
重新开一个新的 CMD,不要关 zk!
进入 Kafka 目录
启动 Kafka:
bin\windows\kafka-server-start.bat config\server.properties看到:
KafkaServer id=0 started
7、创建测试主题(必须创建!)
再开一个新 CMD
进入目录
执行创建主题命令:
bin\windows\kafka-topics.bat --create --topic test-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1看到:
Created topic test-topic.
SpringBoot 集成 Kafka
SpringBoot 官方提供 Kafka 集成 starter,直接引入即可
<dependencies>
<!-- SpringBoot Web(用于测试接口发送消息) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- SpringBoot Kafka 核心依赖 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
</dependencies>application.yml 配置
spring:
kafka:
# Kafka 服务地址
bootstrap-servers: 127.0.0.1:9092
# ==================== 生产者配置 ====================
producer:
# 消息key序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 消息value序列化
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 应答级别(all保证消息不丢失)
acks: 1
# ==================== 消费者配置 ====================
consumer:
# 消费者组ID
group-id: test-group
# 消息key反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 消息value反序列化
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 从头开始消费
auto-offset-reset: earliest
# 自动提交偏移量
enable-auto-commit: true核心代码实现
- 生产者(发送消息)
创建一个 Controller 接口,用于测试发送消息到 Kafka:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
/**
* Kafka 生产者:发送消息
*/
@RestController
public class KafkaProducerController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
// 接口:发送消息到 test-topic
@GetMapping("/send/{message}")
public String sendMessage(@PathVariable String message) {
// 参数:topic名称 | 消息内容
kafkaTemplate.send("test-topic", message);
return "消息发送成功:" + message;
}
}- 消费者(监听并消费消息)
使用 @KafkaListener 注解监听主题,自动消费消息:
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
/**
* Kafka 消费者:监听主题消费消息
*/
@Component
public class KafkaConsumerService {
// 监听 test-topic 主题
@KafkaListener(topics = "test-topic", groupId = "test-group")
public void consumeMessage(String message) {
System.out.println("【消费者收到消息】:" + message);
}
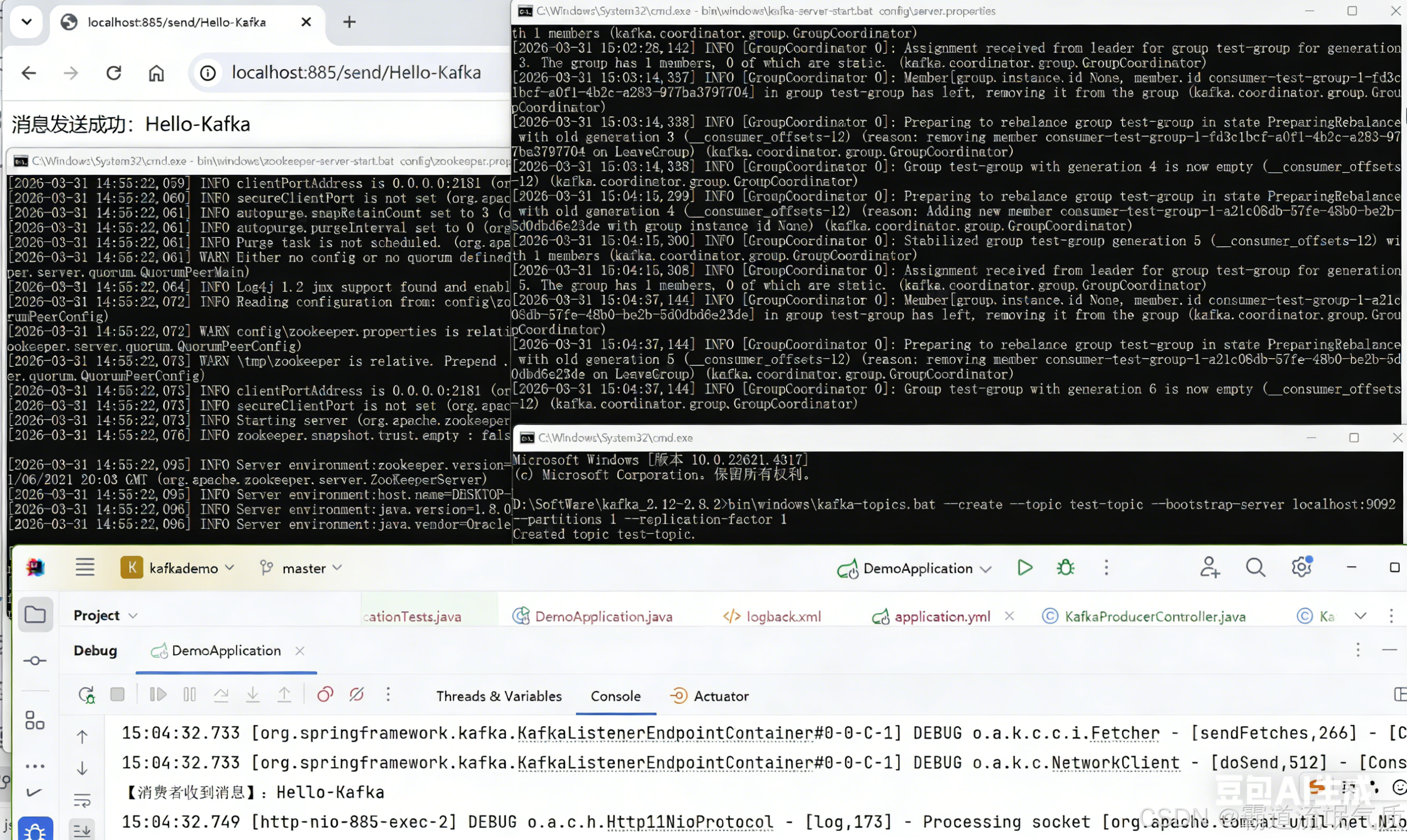
}启动 SpringBoot 项目
浏览器访问:
http://localhost:885/send/Hello-Kafka
验证结果: