一、JVM概述
1.1 什么是JVM?
JVM(Java Virtual Machine,Java虚拟机)---java程序的运行环境(java二进制字节码的运行环境);
好处:
- 一次编写,到处运行;
- 自动内存管理,垃圾回收功能;
- 数组下标越界检查;
- 多态;
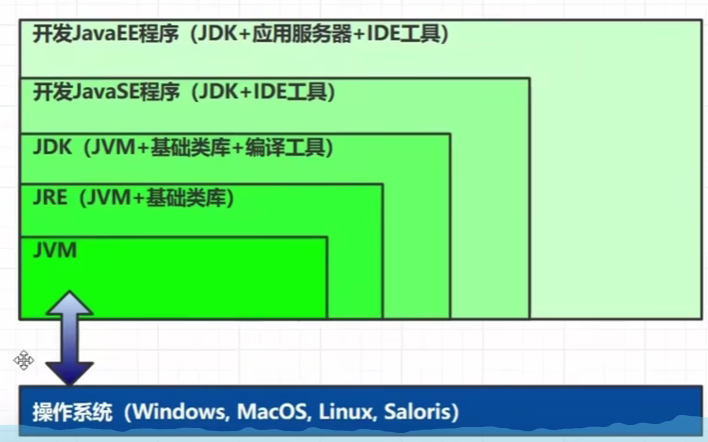
比较jvm、jre、jdk?
1.2 学习JVM有什么用?
- 面试;
- 理解底层的实现原理;
- 中高级程序员的必备技能;
1.3 常见的JVM
| JVM名称 | 开发商 | 核心特点 | 主要技术特性 | 适用场景 |
|---|---|---|---|---|
| HotSpot VM | Oracle (原Sun) | 最主流的JVM,JDK默认搭载 | JIT编译(C1/C2编译器)、分代垃圾回收、混合执行模式 | 通用Java应用(服务器、桌面、嵌入式) |
| OpenJ9 | Eclipse基金会 (原IBM) | 轻量级、启动快、内存占用低 | AOT编译、共享类缓存、低停顿GC(Balanced GC、Gencon) | 微服务、容器、云原生、资源受限环境 |
| GraalVM | Oracle | 高性能、多语言支持、原生镜像 | AOT编译(native-image)、Graal JIT编译器、Truffle多语言框架 | Serverless、微服务、多语言混合开发 |
| Zing VM | Azul Systems | 商业JVM,极低延迟、无停顿 | C4垃圾回收器(无GC停顿)、ReadyNow!预热优化、支持超大堆内存 | 金融交易系统、实时系统、延迟敏感场景 |
| J9 VM | IBM | IBM JDK默认JVM,OpenJ9前身 | 低内存占用、快速启动、与IBM产品深度集成 | IBM WebSphere、企业级Java应用 |
| BEA JRockit | BEA (现Oracle) | 曾是高性能服务器JVM | JRockit JIT编译器、确定性垃圾回收 | 服务器端应用(技术已并入HotSpot) |
| Microsoft JVM | Microsoft | 微软早期为IE提供的JVM | 与IE浏览器深度集成 | 客户端Applet应用(已停止维护) |
| Apache Harmony | Apache基金会 | 开源JVM实现 | 模块化架构、完整Java SE实现 | 开源项目基础(演变为Android Dalvik/ART) |
1.4 学习路线
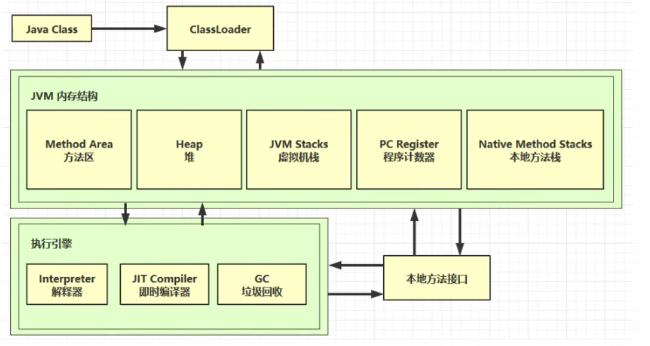
二、JVM内存模型
2.1 程序计数器(PC Register)
Program Counter Register程序计数器(寄存器)记住下一条jvm指令的执行地址;
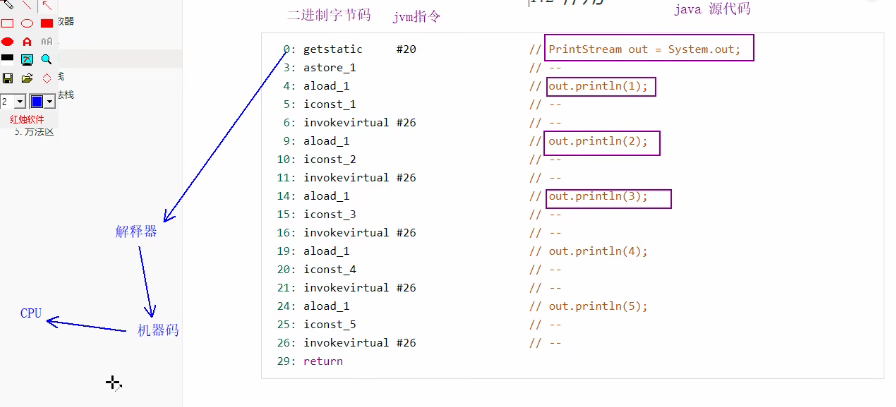
特点:
1.是线程私有的;
2.不会存在内存溢出;
2.2 虚拟机栈
2.2.1 定义
Java Virtual Machine Statcks(Java虚拟机栈)
- 是线程私有的;
- 每个线程运行时所需要的内存;
- 每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存;
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法;
问题辨析:
- 垃圾回收是否涉及栈内存?
答:不需要,栈内存自动回收; - 栈内存分配越大越好吗?
答:不是,栈内存越大,线程数会越少; - 方法内的局部变量是否线程安全?
- 如果方法内局部变量没有逃离方法的作用访问,它是线程安全的;
- 如果是局部变量引用了对象,并逃离方法的作用方法,需要考虑线程安全;
2.2.2 栈内存溢出(StackOverFlowError)
- 栈帧过多导致栈内存溢出;
- 栈帧过大导致栈内存溢出(不易出现);
2.2.3 线程运行诊断
案例1:CPU占用过多
定位:
- 用top定位哪个进程对cpu的占用过高;
- ps H -eo pid,tid,%cpu |grep 进程id:用ps命令进一步定位是哪个线程引起的cpu占用过高;
- jstack进程id:可以根据线程id找到有问题的线程,进一步定位到问题代码的源码行号;
案例2:程序运行很长时间没有结果
2.3 本地方法栈(Native Method Stacks)
本地方法栈是为虚拟机执行 Native 方法(本地方法) 服务的,其中的Native方法是指用其他语言(如C、C++、汇编)编写,并通过JNI(Java Native Interface)供Java调用的方法;
java虚拟机栈与本地方法栈的比较:
| 对比维度 | Java 虚拟机栈 (JVM Stack) | 本地方法栈 (Native Method Stack) |
|---|---|---|
| 服务对象 | 执行 Java 方法(字节码) | 执行 Native 方法(如 C/C++ 编写的 JNI 方法) |
| 栈帧内容 | 存储局部变量表、操作数栈、动态链接、方法出口等 Java 方法执行信息 | 存储本地方法调用所需的参数、局部变量、状态等,具体结构依赖 JVM 实现和底层操作系统 |
| 异常类型 | StackOverflowError(栈深度超限)、OutOfMemoryError(扩展栈内存不足) |
同样会抛出 StackOverflowError 和 OutOfMemoryError |
| 线程私有 | 是,每个线程拥有独立的 Java 虚拟机栈 | 是,每个线程拥有独立的本地方法栈 |
| JVM 规范 | 规范严格定义了数据结构、栈帧格式等 | 规范未强制定义,允许 JVM 实现自由设计 |
| 主流实现 (HotSpot) | 与本地方法栈合并为一个栈空间,但逻辑上仍通过栈帧类型区分 | 与 Java 虚拟机栈合并实现,不单独分配内存区域 |
| 内存分配 | 可通过 -Xss 参数设置栈容量(影响 Java 栈帧深度) |
在 HotSpot 中由同一 -Xss 参数控制;其他 JVM 可能有独立参数 |
| 执行环境 | 在 JVM 内部执行,不直接依赖操作系统 API | 通常涉及 JNI 调用,可能切换到 C/C++ 执行环境,甚至直接调用操作系统接口 |
2.4 堆
2.4.1 定义
通过new关键字,创建对象都会使用堆内存
特点:
- 是线程共享的,堆中对象都需要考虑线程安全的问题;
- 有垃圾回收机制;
2.4.2 堆内存溢出
出现报错:OutOfMemoryError:Java heap space
-Xmx:调整堆内存的大小;
2.4.3 堆内存诊断
- jps工具:查看当前系统中有哪些Java程序,进程号;
- jmp工具:查看进程对应某时刻堆内存占用情况;
- jconsole工具:图形界面的,多功能的检测工具,可以连续检测;
java
/**
* 演示堆内存
*/
public class Demo1 {
public static void main(String[] args) throws InterruptedException {
System.out.println("1....");
Thread.sleep(30000);
byte[] array = new byte[1024 * 1024 * 10]; //10MB
System.out.println("2...");
Thread.sleep(30000);
array=null;
System.gc();
System.out.println("3...");
Thread.sleep(1000000L);
}
}jps:找到进程号
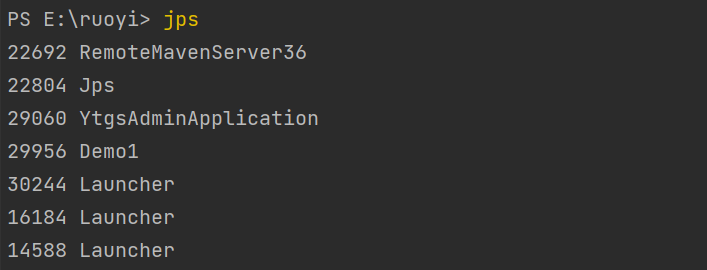
jmap -heap 29060:查看进程对应"某时刻"堆内存占用情况;
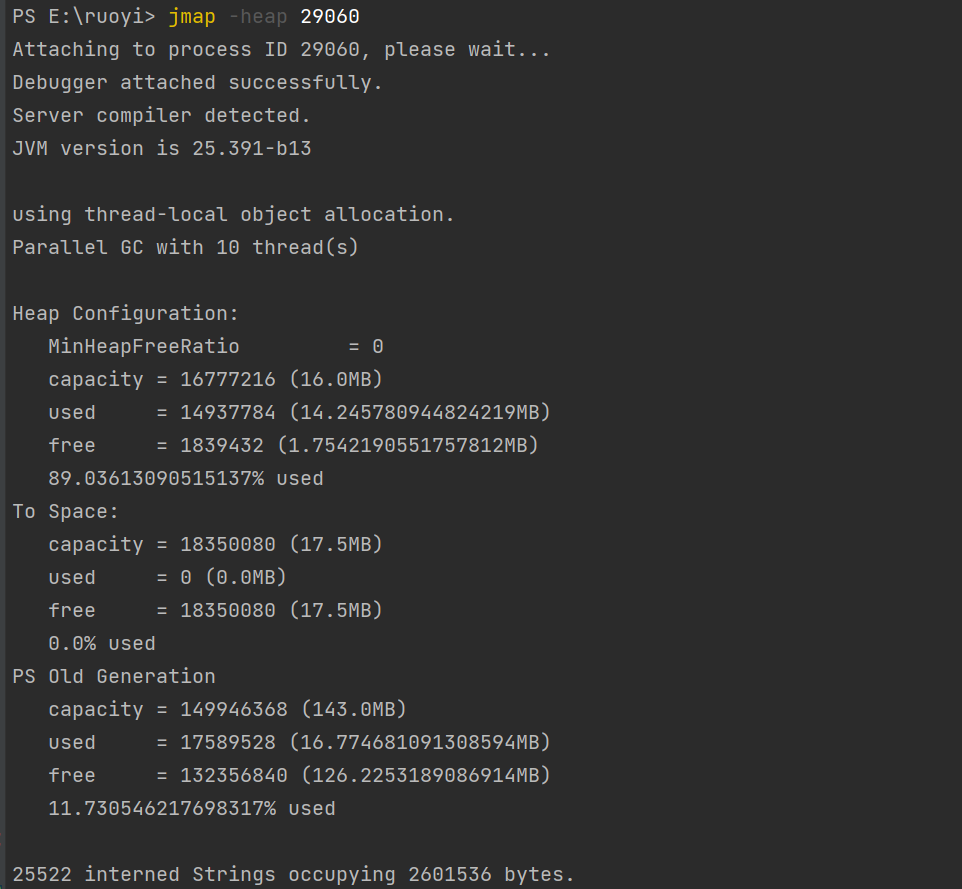
命令行执行jconsole命令,打开图形界面如下:
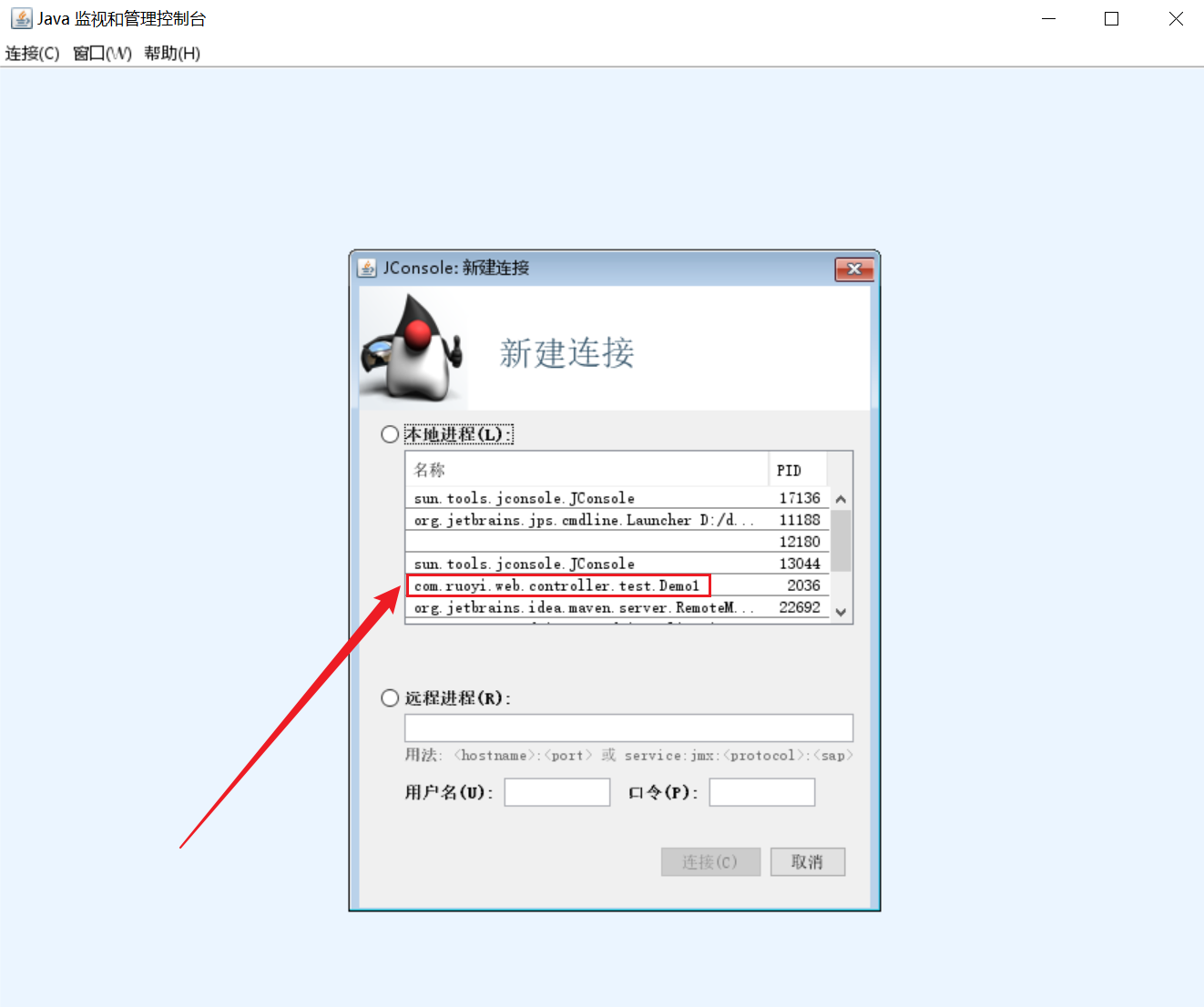
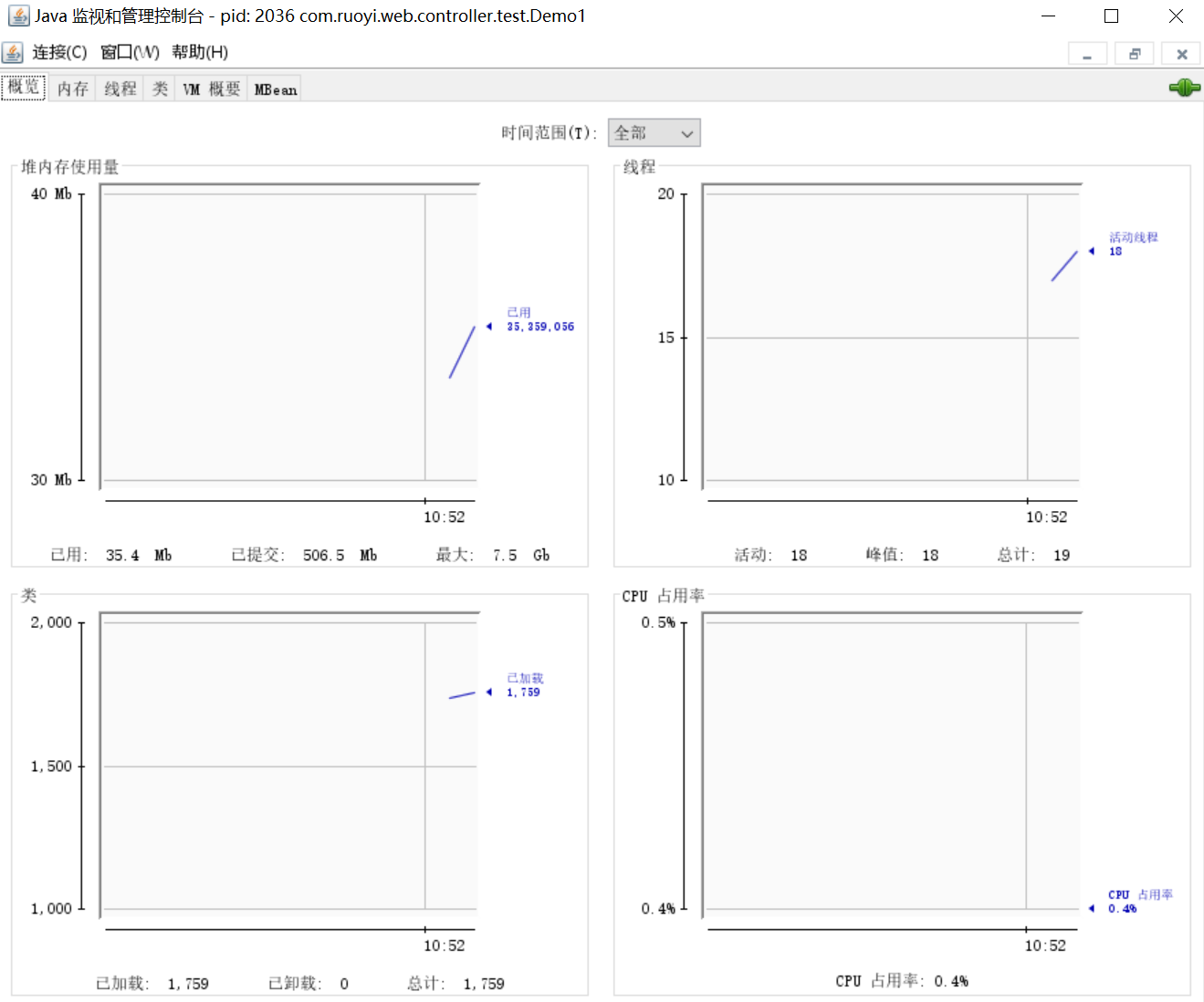
案例:垃圾回收后,内存占用仍然很高
命令行:
jps:查看进程id;
jmap:使用内存情况;
jconsole:
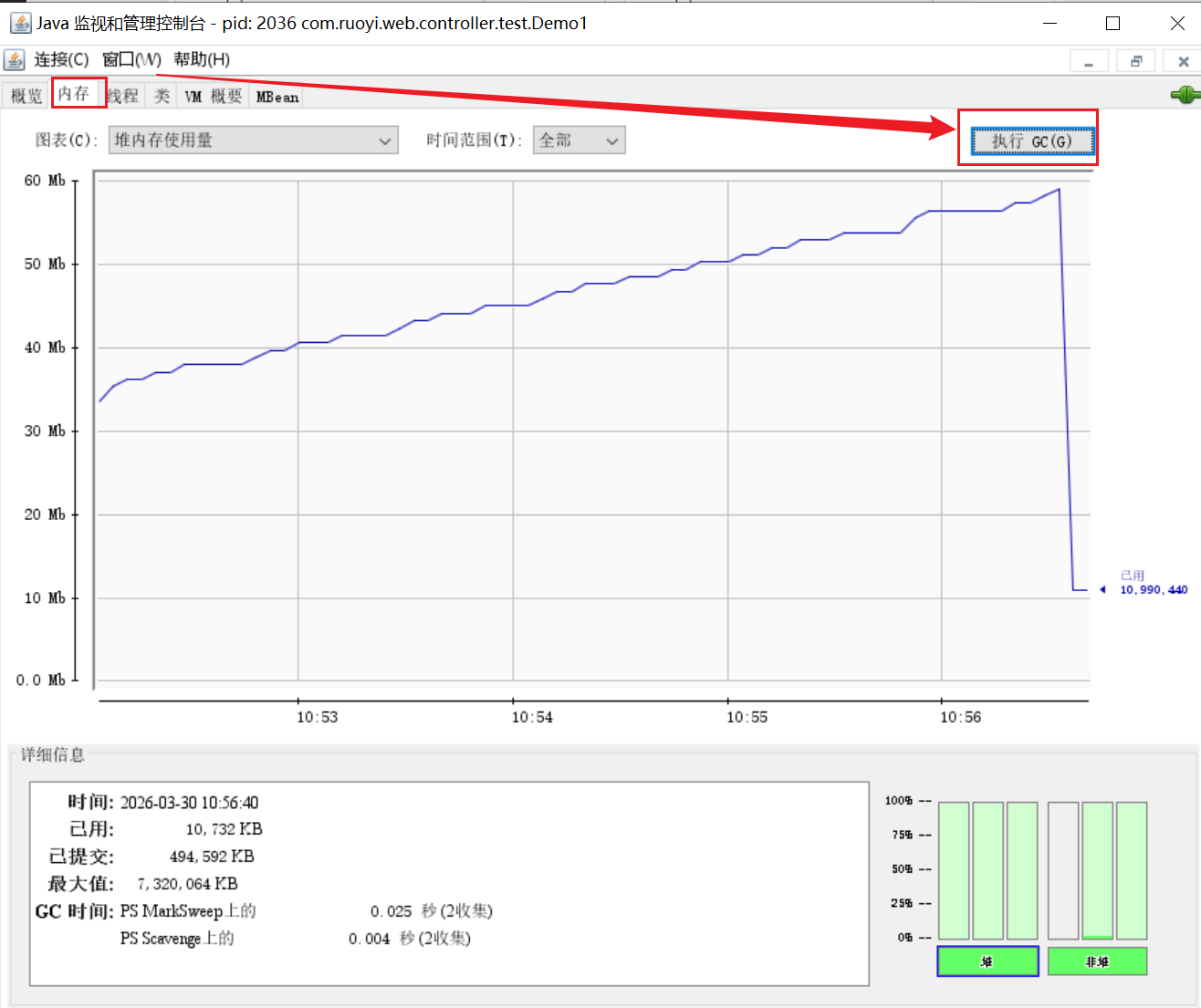
jvisualvm:可视化方式展示虚拟机内存;
2.5 方法区
2.5.1 定义
方法区是JVM规范定义的线程共享内存区域,用于存储类元数据、常量池、静态变量和JIT编译代码;其物理实现在JDK 8后改为元空间,使用本地内存以规避永久代的内存上限问题。
2.5.2 组成
方法区逻辑组成(规范层面)
| 组成部分 | 存储内容 | 说明 |
|---|---|---|
| 类元数据 | 类名、父类、接口列表、访问修饰符、字段信息、方法信息(含字节码)、注解等 | 每个类加载后存储的"模板"信息 |
| 运行时常量池 | 编译期生成的字面量、符号引用,运行期可动态添加的常量 | 每个类或接口都有一个运行时常量池 |
| JIT代码缓存 | JIT编译后的热点方法本地机器码、JNI相关代码 | 独立于方法区主存储,用于提升执行效率 |
物理组成对比(不同JDK版本)
| 数据项 | JDK 6(永久代) | JDK 7(永久代) | JDK 8+(元空间) |
|---|---|---|---|
| 类元数据 | 永久代(JVM堆内) | 永久代(JVM堆内) | 元空间(本地内存) |
| 运行时常量池 | 永久代(JVM堆内) | 永久代(JVM堆内) | 元空间(本地内存) |
| 静态变量 | 永久代 | 堆 | 堆 |
| 字符串常量池 | 永久代 | 堆 | 堆 |
| JIT代码缓存 | 代码缓存区(独立内存) | 代码缓存区(独立内存) | 代码缓存区(独立内存) |
JDK 8+ 方法区组成明细
| 组成部分 | 实际存储位置 | 内存类型 | 关键JVM参数 | 回收机制 |
|---|---|---|---|---|
| 类元数据 | 元空间 | 本地内存(直接内存) | -XX:MetaspaceSize -XX:MaxMetaspaceSize | 类卸载时回收 |
| 运行时常量池 | 元空间 | 本地内存(直接内存) | 同元空间参数 | 类卸载时回收 |
| 静态变量 | 堆 | JVM堆内存 | -Xms -Xmx | GC时回收(跟随Class对象) |
| 字符串常量池 | 堆 | JVM堆内存 | -Xms -Xmx | GC时回收(跟随对象生命周期) |
| JIT代码缓存 | 代码缓存区 | 本地内存(独立) | -XX:ReservedCodeCacheSize -XX:InitialCodeCacheSize | 满时停止编译,一般不回收 |
类元数据详细组成
| 类别 | 具体内容 |
|---|---|
| 类层级信息 | 类的全限定名、父类的全限定名、实现的接口列表 |
| 访问修饰符 | public、protected、private、abstract、final、static 等 |
| 字段表 | 字段名、字段类型(如 I、Ljava/lang/String;)、修饰符、字段顺序 |
| 方法表 | 方法名、返回类型、参数列表、修饰符、方法字节码、异常表 |
| 属性表 | 类/字段/方法上的注解、内部类列表、SourceFile 等调试信息 |
运行时常量池组成
| 类型 | 示例 | 存储内容 |
|---|---|---|
| 字面量 | "hello"、100、final int MAX = 10 | 文本字符串、final常量值、基本类型常量 |
| 符号引用 | com/example/User getName ()Ljava/lang/String; | 类和接口的全限定名、字段的名称和描述符、方法的名称和描述符 |
| 动态常量 | String.intern() 返回的字符串 | 运行时可动态添加的常量(JDK 7+ 字符串在堆中) |
方法区相关内存溢出
| JDK版本 | 异常类型 | 常见原因 | 解决方案 |
|---|---|---|---|
| JDK 6-7 | OutOfMemoryError: PermGen space | 动态代理类过多、大量JSP、频繁热部署 | 增大 -XX:MaxPermSize 或升级到 JDK 8 |
| JDK 8+ | OutOfMemoryError: Metaspace | 动态代理类过多、大量JSP、频繁热部署 | 增大 -XX:MaxMetaspaceSize 或排查类加载泄漏 |
| 所有版本 | OutOfMemoryError: CodeCache | JIT编译的代码过多、方法过大 | 增大 -XX:ReservedCodeCacheSize |
方法区 vs 堆 vs 栈 对比
| 维度 | 方法区 | 堆 | 虚拟机栈 |
|---|---|---|---|
| 存储内容 | 类元数据、常量池、JIT代码 | 对象实例、数组、静态变量(JDK 7+) | 局部变量、操作数栈、方法出口 |
| 线程共享 | 是 | 是 | 否(每个线程私有) |
| 生命周期 | JVM启动到结束 | JVM启动到结束 | 线程启动到结束 |
| 内存位置(JDK 8+) | 元空间(本地内存)+ 代码缓存 | JVM堆内存 | 线程栈内存(本地内存) |
| GC回收 | 有条件回收(类卸载) | 主要回收区域 | 方法结束即回收 |
2.5.3 方法区内存溢出
- 1.8以前会导致永久代 内存溢出
java.lang.OutOfMemoryError: PermGen space
-XX:MaxPermSize=8m - 1.8之后会导致元空间 内存溢出
java.lang.OutOfMemoryError: Metaspace
-XX:MaxMetaspaceSize=8m
2.5.4 运行时常量池
常量池: 就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息
运行时常量池: 常量池是*.class文件中的,当该类被加载,他的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址;
2.5.5 StringTable
StringTable定义
| 项目 | 说明 |
|---|---|
| 定义 | StringTable(字符串常量池/串池)是 JVM 中存储字符串对象引用的哈希表 |
| 本质 | 全局哈希表(HashTable),存储指向堆中 String 对象的引用 |
| 作用 | 字符串复用,节省内存,提高性能 |
| 设计模式 | 享元模式(Flyweight Pattern) |
StringTable 只存储被"驻留"的字符串(字面量和 intern 调用),绝大多数运行时动态创建的字符串对象都不在 StringTable 中
java
public class StringTableTest {
public static void main(String[] args) {
// 情况1:字面量-进入StringTable
String s1 = "hello";
// 情况2:new 对象-不进入StringTable
String s2 = new String("hello");
// 情况3:运行时拼接 -不进入StringTable
String s3 = "hello" + System.currentTimeMillis();
// 情况4:字符串操作-不进入StringTable
String s4 = s1.toUpperCase();
// 情况5:手动intern-可能进入StringTable
String s5 = s2.intern();
String s6 = s2 + System.currentTimeMillis();
String s7 = s1 + System.currentTimeMillis();
String s8 = new String(s1);
String s9 = "HELLO";
// 对应值
System.out.println("s1:" + s1);
System.out.println("s2:" + s2);
System.out.println("s3:" + s3);
System.out.println("s4:" + s4);
System.out.println("s5:" + s5);
System.out.println("s6:" + s6);
System.out.println("s7:" + s7);
System.out.println("s8:" + s8);
System.out.println("s9:" + s9);
// 验证
System.out.println(s1 == s2); //false
System.out.println(s1 == s5); //true
System.out.println(s2 == s3); //false
System.out.println(s2 == s8); //false
System.out.println(s3 == s6); //false
System.out.println(s3 == s7); //false
System.out.println(s6 == s7); //false
System.out.println(s4 == s9); //false
// 查看对象地址(System.identityHashCode())
System.out.println(System.identityHashCode(s1)); //表内对象
System.out.println(System.identityHashCode(s2)); //堆中新对象
System.out.println(System.identityHashCode(s5)); //同s1
}
}StringTable位置
| JDK 版本 | StringTable 位置 | 运行时常量池位置 | 说明 |
|---|---|---|---|
| JDK 6 | 永久代(PermGen) | 永久代 | 大小固定,容易 OOM |
| JDK 7 | 堆(Heap) | 堆 | 避免永久代限制 |
| JDK 8+ | 堆(Heap) | 元空间(Metaspace) | StringTable 在堆,常量池在元空间 |
什么数据存储在 StringTable 中
- 会进入 StringTable 的字符串
| 类型 | 示例代码 | 进入时机 |
|---|---|---|
| 字符串字面量 | String s = "hello"; |
类加载时 |
| 编译期常量表达式 | String s = "hello" + "world"; |
类加载时 |
| final 常量拼接 | final String a = "hello"; String b = a + "world"; |
类加载时 |
| 显式 intern() | new String("hello").intern(); |
调用时 |
| 基本类型转字符串常量 | String s = "" + 123; |
类加载时 |
| 枚举的 name() | Color.RED.name() |
首次调用时 |
- 不会进入 StringTable 的字符串
| 类型 | 示例代码 | 存储位置 |
|---|---|---|
| new 创建 | new String("hello") |
堆(普通对象) |
| 运行时拼接 | "hello" + System.currentTimeMillis() |
堆(普通对象) |
| 字符串方法 | s.toUpperCase() s.substring(1) |
堆(普通对象) |
| StringBuilder | new StringBuilder().append("a").toString() |
堆(普通对象) |
| I/O 读取 | bufferedReader.readLine() |
堆(普通对象) |
| JSON/XML 解析 | jsonParser.readValue(...) |
堆(普通对象) |
| UUID 生成 | UUID.randomUUID().toString() |
堆(普通对象) |
| 数据库查询 | resultSet.getString("name") |
堆(普通对象) |
StringTable 存储内容结构
| 存储内容 | 类型 | 说明 |
|---|---|---|
| String 对象引用 | 指针/引用 | 指向堆中的 String 对象 |
| 哈希桶数组 | 数组 | 用于快速查找 |
| 链表/红黑树节点 | 节点 | 解决哈希冲突(JDK 8+) |
| 锁信息 | 同步机制 | 保证线程安全 |
注意:StringTable 不直接存储字符串的 char\[\]/byte\[\] 数组和 String 对象的实例数据。
StringTable垃圾回收
GC 特性对比
| JDK 版本 | 是否可回收 | 回收条件 | 说明 |
|---|---|---|---|
| JDK 6 | 否 | 无 | 永久代中的字符串常量不会被回收 |
| JDK 7 | 是 | 无引用时 | 移到堆后,可以被 GC 回收 |
| JDK 8+ | 是 | 无引用时 | 延续 JDK 7 的机制 |
哪些字符串可被回收
| 字符串类型 | 是否可回收 | 回收条件 |
|---|---|---|
| 字面量(有引用) | 否 | 类还在,常量池引用存在 |
| 字面量(无引用) | 是 | 类卸载后 |
| 手动 intern(有引用) | 否 | 强引用存在 |
| 手动 intern(无引用) | 是 | 只有 StringTable 引用 |
| 动态 intern | 是 | 只有 StringTable 引用 |
StringTable性能调优
| 参数 | 作用 | 适用场景 | 默认值(JDK 8) |
|---|---|---|---|
-XX:StringTableSize |
设置 StringTable 桶数量 | 有大量 intern 字符串时 | 60013 |
-XX:+PrintStringTableStatistics |
打印 StringTable 统计 | 诊断分析 | false |
-XX:+UseStringDeduplication |
G1 字符串去重 | 有大量重复字符串时 | false |
-XX:StringDeduplicationAgeThreshold |
去重年龄阈值 | 配合去重使用 | 3 |
最佳实践对照
| 场景 | 是否应该放入 StringTable | 原因 |
|---|---|---|
| HTTP 方法名(GET, POST) | ✅ 应该 | 数量少,重复高 |
| HTTP 状态码(200, 404, 500) | ✅ 应该 | 数量少,重复高 |
| 数据库列名(id, name, created_at) | ✅ 应该 | 固定字段名 |
| 枚举值字符串(SUCCESS, FAIL) | ✅ 应该 | 有限状态值 |
| 配置项名称 | ✅ 应该 | 固定配置键 |
| 用户输入数据 | ❌ 不应该 | 不可控,数量大 |
| 动态 SQL | ❌ 不应该 | 变化多端 |
| UUID/Token | ❌ 不应该 | 唯一性,无复用 |
| 大文本内容 | ❌ 不应该 | 占用内存大 |
| 日志消息 | ❌ 不应该 | 频繁创建,及时回收 |
| JSON 字段值 | ❌ 不应该 | 通常唯一或变化 |
常见误区
| 误区 | 真相 |
|---|---|
| 所有字符串都在 StringTable 中 | ❌ 只有字面量和 intern() 的字符串在 |
| new String() 会在常量池创建 | ❌ 不会自动创建,除非内容首次出现 |
| StringTable 中的字符串永不回收 | ❌ JDK 7+ 可以被回收 |
| 字符串拼接结果在常量池 | ❌ 除非是编译期常量 |
| StringTable 包含所有字符串 | ❌ 只包含被驻留的字符串引用 |
| intern() 后字符串永久存在 | ❌ 无外部引用时会被回收 |
| 核心知识点速记 | |
| 知识点 | 要点 |
| ------- | ------ |
| StringTable 本质 | 全局哈希表,存储 String 对象引用 |
| 存储位置 | JDK 6:永久代;JDK 7+:堆 |
| 存储内容 | 字面量、编译期常量、手动 intern 字符串 |
| 不存储内容 | 大多数运行时动态创建的字符串 |
| 垃圾回收 | JDK 7+ 可回收,条件是无外部引用 |
| 调优参数 | StringTableSize、PrintStringTableStatistics |
| 性能影响 | 减少内存占用,但过度使用会增加 GC 压力 |
2.6 直接内存(Direct Memory)
直接内存并不是JVM运行时数据区的一部分,而是操作系统本地内存 (Native Memory)中的一块区域,Java通过NIO(New I/O)的ByteBuffer类提供了操作直接内存的能力。
什么是直接内存?
传统I/O(BIO): Java堆--->直接内存(临时缓冲区)--->操作系统--->磁盘/网卡
- 数据需要从Java堆复制到直接内存(或反过来);
- 涉及两次内存拷贝;
直接内存(NIO): Java堆(仅持有引用)--->直接内存--->操作系统--->磁盘/网卡
- ByteBuffer.allocateDirect() 分配的内存就在直接内存中;
- Java堆中只保存一个指向直接内存的引用(地址);
- 避免了Java堆和本地内存之间的数据拷贝;
如何使用直接内存
java
// 分配 1MB 直接内存
ByteBuffer directBuffer = ByteBuffer.allocateDirect(1024 * 1024);
// 写入数据
directBuffer.put("hello".getBytes());
// 切换为读模式
directBuffer.flip();
// 读取数据
byte[] dst = new byte[5];
directBuffer.get(dst);
// 手动释放(重要!)
sun.misc.Cleaner cleaner = ((DirectBuffer) directBuffer).cleaner();
if (cleaner != null) {
cleaner.clean();
}分配方式
-
ByteBuffer.allocateDirect(int capacity) - 分配直接内存
-
ByteBuffer.allocate(int capacity) - 分配堆内存(普通方式)
| 对比维度 | 堆内存(Heap Memory) | 直接内存(Direct Memory) |
|---|---|---|
| 分配位置 | JVM 堆内存(Java 堆) | 操作系统本地内存(Native Memory) |
| 分配方式 | new Object()、ByteBuffer.allocate() |
ByteBuffer.allocateDirect() |
| 分配速度 | 快(只需移动指针) | 慢(需要系统调用) |
| 读写速度 | 慢(有额外内存拷贝) | 快(零拷贝) |
| GC 管理 | 自动 GC 管理 | 不受 GC 直接管理(依赖 Cleaner 释放) |
| 内存限制 | -Xms / -Xmx 控制 |
-XX:MaxDirectMemorySize 控制(默认等于堆大小) |
| 回收时机 | GC 发生时自动回收 | 当 DirectByteBuffer 被 GC 时,通过 Cleaner 回收 |
| 适用场景 | 常规 Java 对象、业务逻辑 | 频繁 I/O 操作(网络、文件)、大块数据传输 |
| 典型应用 | 大多数 Java 对象 | Netty、FileChannel、NIO |
| 内存溢出风险 | 堆内存不足 OOM | 直接内存不足 OOM(堆可能还有空间) |
| 排查难度 | 较容易(有成熟工具如 MAT、JProfiler) | 较难(需要 NMT、JFR 等工具) |
| 释放方式 | 自动(GC 回收) | 手动(Cleaner.clean())或自动(GC 时清理) |
三、垃圾回收机制
3.1 如何判断对象可以回收
3.1.1 引用计数法
为每个对象维护一个整数计数器,记录有多少个"指针"或"引用"指向该对象。当这个计数变为 0 时,意味着该对象不再被任何地方使用,可以立即被回收;
优点:
- 实时性高:对象一旦失去最后引用,内存立即被回收,无需等待特定GC时机;
- 停顿时间短:内存回收操作分散在引用修改过程中,不会出现长时间的Stop-The-World暂停;
- 实现简单:逻辑只管,只需要维护一个整型计数器,易于实现和调试;
- 可预测性:对象生命周期与引用绑定,资源释放时机确定,适合需要确定性析构的场景;
- 局部性好:回收操作仅涉及当前修改引用的对象,不扫描整个堆;
缺点:
- 循环引用问题(致命缺陷):互相引用的对象即使从程序跟不可达,引用计数也不为0,导致内存泄漏;
- 计数器更新开销大:每次引用复制都需要修改两个对象的计数器,频繁操作下性能损耗明显;
- 多线程同步开销:多线程环境下,计数器操作需要原子操作或枷锁,进一步增加开销;
- 无法处理环状数据结构:双向链表、图等结构中的循环引用无法自动回收;
- 空间开销:每个对象需要额外的内存空间存储引用计数器(通常为4或8字节);
- 递归回收问题:回收一个对象可能触发其引用对象的级联回收,递归深度过大时可能导致栈溢出;
3.1.2 可达性分析算法(又称可达性算法或根搜索算法)
从一组称为"GC Roots"的根对象出发,通过引用链 向下搜索,所有能被搜索到的对象标记为"存活",未被搜索到的对象则判定为"可回收"
- java虚拟机中的垃圾回收器采用可达性分析来探索所有存活的对象;
- 扫描堆中的对象,看是否能够沿着GC Root对象为起点的引用链找到该对象,找不到,表示可以回收;
- 哪些对象可以作为GC Root?
GC Roots(根对象)
GC Roots是可达性分析的起点,通常包括以下几类对象:
- 虚拟机栈(栈帧中的局部变量表)中引用的对象:当前正在执行的方法中引用的对象;
- 静态属性引用的对象:类的静态变量引用的对象(方法区中);
- 常量引用的对象:如字符串常量池中的引用;
- JNI(Native方法)引用的对象:本地方法栈中引用的对象;
- 活跃线程对象:所有正在运行的线程;
- 同步锁(synchronized)持有的对象;
- JVM内部的系统类加载器等;
引用链(Reference Chain)
从GC Root出发,通过一系列引用关系最终到达某个对象的路径,称为该对象的引用链,如果一个对象没有任何GC Root指向它,且不存在任何引用链可以到达它,则该对象被判定为不可达,即"垃圾";
工作流程:
- 标记阶段:
- 从所有GC Roots出发,进行深度优先搜索 或广度优先搜索;
- 遍历所有可达的对象,并将它们标记为"存活";
- 清理阶段:
- 遍历堆内存,所有未被标记的对象被认为是不可达的,可以被回收;
- 具体的回收方式取决于垃圾回收器的实现(标记-清除、标记-复制、标记-整理等);
优点:
- 解决循环引用:从 GC Roots 出发遍历,即使对象间存在循环引用,只要整组对象不可达,都会被整体回收。
- 准确性高:能够精确识别所有存活对象,不会误判正在使用的对象为垃圾;
- 适合管理大规模堆:相比引用计数法,减少了每次引用修改时的维护开销,更适合海量对象场景;
- 算法拓展性强:可作为多种回收策略的基础(标记-清除、标记-复制、标记-整理、分代回收等);
- 支持并发和增量优化:现代 GC 可在可达性分析的基础上实现并发标记、增量回收,降低停顿时间。
缺点:
- 需要Stop-The-World:在根节点枚举和某些标记阶段,必须暂停所有用户线程,影响应用响应性;
- 遍历开销较大:需要扫描整个堆或至少大部分存活对象,堆内存越大,遍历耗时越长;
- 根节点枚举复杂:GC Roots 来源多样(栈帧、静态变量、JNI 等),收集所有根节点存在一定开销;
- 非实时性:对象不会在失去引用时立即回收,需要等待下一次 GC 触发,内存释放有延迟;
- 对应用线程敏感:GC 执行期间,如果应用线程持续修改引用关系,需要额外的机制(如写屏障)来保证正确性;
- 实现复杂度高:涉及三色标记、读写屏障、并发控制等高级技术,实现难度较大;
3.1.3 四种引用
- 强引用
特点: 最常见的引用(如Object obj=new Object()),只要强引用存在,垃圾回收器(GC)就绝不会回收被引用的对象;
内存泄漏: 强引用是导致内存泄漏的主要原因(例如集合中无用的对象未被清除); - 软引用
实现: SoftReference
特点: 只有当内存不足 (即将发生OutOfMemoryError)时,GC才会回收被引用的对象;
用途: 内存敏感的告诉缓存 (例如加载图片时,可以使用软引用缓存图片,这样既能快速展示,又能在内存紧张时自动释放);
3.** 弱引用**
实现: WeakReference
特点: 只要发生GC,无轮内存是否充足,都会被回收 ;
用途: 容器类(如WeakHashMap)、存储监听者列表,防止因为隐式的强引用导致对象无法被回收,ThreadLocal中的Entry也继承了弱引用,以防止内存泄漏; - 虚引用
实现: PhantomReference
特点: 最弱的引用,无法通过它获取对象实例 (get()永远返回null),对象被回收时,系统会将其虚引用放入一个关联的引用队列 ;
用途: 对象回收跟踪。主要用于在对象被GC后收到一个通知,用于管理堆外内存(如NIO中的DirectByteBuffer,确保直接内存被正确释放). - 终结器引用
终结器引用(Finalizer Reference)是JVM内部为实现finalize()方法而使用哦个的一种特殊引用类型,它不属于java.lang.ref包中面向开发者的那四种引用(强/软/弱/虚),但在HotSpot JVM的引用体系中确实存在。
终结器引用工作机制
当一个类重写了finalize()方法,且该类的对象没有被任何强引用持有时,JVM的处理流程如下:
GC 发现对象不可达(无强引用)
↓
检查对象类是否重写了 finalize()
↓
若是 → JVM 创建终结器引用(Finalizer Reference)
↓
终结器引用被放入一个专门的引用队列
↓
Finalizer 线程(低优先级守护线程)从队列取出对象
↓
调用该对象的 finalize() 方法
↓
finalize() 执行完毕后,对象变为"真正可回收"
↓
下一次 GC 时回收对象内存
| 引用类型 | 回收时机 | 实现/表现方式 | 典型用途 | 备注 |
|---|---|---|---|---|
| 强引用 | 永不回收(只要引用存在) | 默认方式:Object obj = new Object() |
普通对象引用 | 最常见,可能导致内存泄漏 |
| 软引用 | 内存不足时(OOM 前) | SoftReference<T> |
内存敏感缓存 | 适合实现缓存机制 |
| 弱引用 | 下一次 GC 发生时(无论内存是否充足) | WeakReference<T> |
WeakHashMap、ThreadLocal |
防止内存泄漏的重要工具 |
| 虚引用 | 任何时候(无法通过引用获取对象实例) | PhantomReference<T> |
堆外内存回收追踪 | get() 永远返回 null,必须配合引用队列使用 |
| 终结器引用 | finalize() 方法执行后(JVM 内部机制) |
重写 finalize() 方法 |
支持 finalize() 机制 |
Java 9 起已废弃,不推荐使用;延迟回收、性能差 |
3.2 垃圾回收算法
垃圾回收(Garbage Collection,GC)主要解决三个问题:哪些内存需要回收、什么时候回收、如何回收。
3.2.1 标记-清除
原理:
- 标记阶段: 遍历所有根对象(GC Roots),标记所有可达对象;
- 清除阶段: 遍历堆内存,回收未被标记的对象;
优点:
- 实现简单;
- 处理速度快(不需要移动对象)
缺点:
- 内存碎片: 回收后产生大量不连续内存碎片,可能导致无法分配大对象;
- 效率问题: 随着对象增多,标记和清除都需要遍历整个堆;
回收前: 存活可回收存活可回收存活
回收后: 存活空闲存活空闲存活 ← 碎片化
3.2.2 标记-整理
原理:
- 标记阶段: 与标记-清除相同,标记存活对象;
- 整理阶段: 将所有存活对象向一端移动,然后清理边界以外的内存;
优点:
- 无内存碎片;
- 内存利用率高(不需要预留空闲空间);
缺点:
- 效率较低: 需要移动对象并更新引用,比标记-清除多一次移动开销;
回收前: 存活可回收存活可回收存活
整理后: 存活存活存活空闲空闲 ← 连续排列
3.2.3 复制
原理:
- 将内存分为两块(如Eden和Survivor的From 和 To);
- 每次只使用其中一块;
- 垃圾回收时,将存活对象复制到另一块,然后清空原区域;
优点:
- 无内存碎片: 所有存活对象连续排列;
- 效率高: 只需遍历存活对象,适合存活率低的场景;
缺点:
- 内存浪费: 始终有一半内存空闲;
- 存活对象较多时,复制成本高
回收前: 存活可回收存活可回收存活
整理后: 存活存活存活空闲空闲 ← 连续排列
3.3 分代垃圾回收
分代垃圾回收(Generational Garbage Collection)是JVM 最核心的内存管理策略 。它基于一个经过大量实践验证的观察:大部分对象"朝生夕灭",存活时间很短;而越老的对象,越难被回收。
核心思想:
既然对象有"年龄"差异,那就不应该用同一种方式对待它们。分代回收将堆内存划分为不同的"代"(Generation),对不同代采用最合适的回收算法,从而达到整体最优;
堆内存结构
新生代(Young Generation)
- Eden区: 新对象出生地,占新生代80%;
- Survivor区: 两个(From和To),各占10%,用于存放Minor GC 后存活的对象;
- 特点: 对象存活率极低(5%-10%);
- 回收算法:复制算法;
老年代(Old Generation)
- 特点: 存放长期存活或大对象;
- 回收算法:标记-整理 或标记-清除;
对象的一生(从出生到死亡(或晋升)的全过程)
1️⃣ 对象出生
new Object() → 分配到 Eden 区
2️⃣ 第一次 Minor GC
Eden 区满了 → 触发 Minor GC
├─ 存活对象 → 复制到 Survivor From (S0)
├─ 对象年龄 = 1
└─ 清空 Eden 区
3️⃣ 第二次 Minor GC
Eden 区又满了 → 再次 Minor GC
├─ Eden + S0 存活对象 → 复制到 Survivor To (S1)
├─ 对象年龄 +1(年龄变为 2)
└─ 清空 Eden 和 S0,交换 S0 和 S1 的角色
4️⃣ 重复步骤 3
每经历一次 Minor GC,存活对象的年龄 +1
5️⃣ 晋升到老年代(满足任一条件)
条件 A:年龄达到阈值(默认 15)→ 晋升
条件 B:动态年龄判定(相同年龄对象总和超过 S 区 50%)→ 提前晋升
6️⃣ 老年代也满了 → 触发 Full GC
回收整个堆(新生代 + 老年代)
为什么分代能提升效率?
- 新生代:复制算法
- 存活率低: 只需要复制少量存活对象;
- 速度快: 复制成本低,且不会产生内存碎片;
- 分配快: 使用"指针碰撞"技术,分配内存像移动指针一样快;
- 老年代:标记-整理/清除
- 存活率高: 复制大量对象成本太高;
- 空间利用率高: 不需要预留空闲空间;
- 适合长时间存活对象: 移动次数少;
- 整体收益
- 减少Full GC频率: 大部分对象在新生代就被回收了;
- 停顿时间可控: Minor GC快,Full GC少;
- 内存利用率高: 没有浪费一半内存(复制算法只在新生代使用);
两种GC类型
| GC 类型 | 触发时机 | 回收范围 | 核心算法 | 频率 | 停顿时间 | 影响 |
|---|---|---|---|---|---|---|
| Minor GC | Eden 区满 | 新生代(Eden + Survivor) | 复制算法 | 频繁 | 短(毫秒级) | 对应用影响较小 |
| Full GC | 老年代满 / 手动调用 System.gc() |
整个堆(新生代 + 老年代)+ 元空间 | 标记-整理 或 标记-清除 | 极少 | 长(可能秒级) | 可能导致应用卡顿,需尽量避免 |
3.4 垃圾回收器
垃圾回收器(Garbage Collector ,GC) 是JVM中负责自动内存管理 的组件,它的核心职责是:自动识别并回收程序中不再使用的对象,释放内存空间。
- 为什么需要垃圾回收器?
没有GC的时代(C/C++) 出现的问题:
- 忘记释放--->内存泄漏;
- 重复释放--->程序崩溃;
- 释放后继续使用--->野指针;
有GC的Java的优势:
- 程序员无需关心内存释放;
- 避免内存泄漏和野指针;
- 提高开发效率;
- 垃圾回收器的工作流程
- 步骤1:判断对象是否存活: 可达性分析算法;
- 步骤2:选择回收时机: 自动触发(Minor GC、Full GC)、手动触发(调用System.gc()不推荐)、被动触发(分配大对象失败时);
- 步骤3:执行回收算法: 标记-清除、标记整理、复制等算法;
- 垃圾回收器分类
| 回收器名称 | 所属年代 | 核心算法 | 并行/并发 | 线程模式 | 主要特点 | 适用场景 | JVM 参数 |
|---|---|---|---|---|---|---|---|
| Serial | 新生代 | 复制算法 | 串行 | 单线程 | 简单高效,单核 CPU 友好,GC 时全程 STW | 客户端模式、单核服务器、内存较小(< 2GB) | -XX:+UseSerialGC |
| ParNew | 新生代 | 复制算法 | 并行 | 多线程 | Serial 的多线程版,常与 CMS 配合 | 多核 CPU、服务端模式、与 CMS 搭配使用 | -XX:+UseParNewGC |
| Parallel Scavenge | 新生代 | 复制算法 | 并行 | 多线程 | 注重吞吐量,支持自适应调节(可自动调整 Eden/Survivor 比例) | 后台批处理、科学计算、高吞吐量场景 | -XX:+UseParallelGC |
| Serial Old | 老年代 | 标记-整理算法 | 串行 | 单线程 | Serial 的老年代版本,简单可靠 | 单核 CPU、客户端模式、CMS 的后备预案 | -XX:+UseSerialOldGC (已过时) |
| Parallel Old | 老年代 | 标记-整理算法 | 并行 | 多线程 | Parallel Scavenge 的老年代版,高吞吐量 | 与 Parallel Scavenge 配合,高吞吐量应用 | -XX:+UseParallelOldGC |
| CMS | 老年代 | 标记-清除算法 | 并发 | 多线程 | 低停顿,并发收集,但产生内存碎片,对 CPU 敏感 | Web 服务、实时交互、低延迟要求应用 | -XX:+UseConcMarkSweepGC |
| G1 | 全堆(逻辑分代) | 分区 + 标记-复制/整理 | 并行 + 并发 | 多线程 | 可预测停顿模型,将堆分为多个 Region,优先回收垃圾最多区域 | 多核大内存(≥ 4GB)、期望可控低停顿 | -XX:+UseG1GC |
| ZGC | 全堆(早期不分代,JDK21+ 支持分代) | 染色指针 + 读屏障 | 并发 | 多线程 | 极低停顿(< 1ms),支持 TB 级堆内存 | 超大堆内存、对延迟要求极高的场景(如金融、实时系统) | -XX:+UseZGC |
| Shenandoah | 全堆(早期不分代) | 布鲁克斯指针 + 并发压缩 | 并发 | 多线程 | 低停顿(与堆大小无关),OpenJDK 贡献 | 中大型堆内存、低延迟需求的 OpenJDK 环境 | -XX:+UseShenandoahGC |
补充:
- STW: Stop-The-World,即暂停所有应用线程;
- 吞吐量 = 运行用户代码时间 / (运行用户代码时间 + GC 时间);
- 并发: GC 线程与应用线程交替执行(不挂起应用);
- 并行: 多个 GC 线程同时执行,但应用线程需暂停;
- JDK 版本建议:
JDK 8: 默认 Parallel GC,可切换 G1/CMS。
JDK 9+: G1 为默认回收器。
JDK 11+: ZGC / Shenandoah 可用(需开启实验性参数)。
JDK 15+: ZGC / Shenandoah 正式可用。
JDK 21: ZGC 支持分代模式(默认开启)。
3.5 垃圾回收调优
垃圾回收调优 是指通过调整JVM参数、代码逻辑或内存分配策略,使垃圾回收器在吞吐量、延迟 和内存占用三者之间达到最佳平衡的过程(让GC更高效,让应用不卡顿、不崩溃、不浪费资源)。
为什么需要GC调优?
常见问题场景:
- 频繁的Full GC: 应用长时间停顿;
- GC时间过长: 请求超时、RT飙升;
- 内存泄漏: OOM(OutOfMemoryError);
- CPU占用过高: GC线程争抢资源;
调优目标(三个维度):
| 维度 | 说明 | 典型指标 |
|---|---|---|
| 低延迟 | 单次GC停顿时间短,对应用响应影响小 | STW(Stop-The-World)< 10ms |
| 高吞吐量 | 应用线程运行时间占比高,GC消耗少 | GC时间占总时间 < 1% |
| 小内存占用 | 堆内存使用合理,无浪费 | 无OOM异常,无频繁Full GC |
三者不可兼得,需根据业务场景进行取舍
GC调优的核心概念
- STW: GC发生时,所有应用线程暂停,只让GC线程工作,STW时间越短越好;
- 年轻代 vs 老年代: 年轻代(存放生命周期短的对象,GC频繁但速度快Minor GC)、老年代(存放长期存活的对象,GC较少但耗时较长Major GC/Full GC);
- 对象晋升: 对象在年轻代熬过多次GC后(默认15次),晋升到老年代;
GC调优步骤
- 明确目标: 设定RT指标,设定GC频率指标;
- 收集GC日志
- 分析GC日志: GCeasy在线分析、GCViewer开源工具、JVisualVM/JMC(JDK自带);
- 定位问题类型
- 调整参数并验证
四、类字节码结构
类文件是Java编译器的输出产物,它包含了Java字节码,是Java虚拟机(JVM)能够理解和执行的二进制格式。
整体结构概述
ClassFile {
magic; // 魔数
minor_version; // 次版本号
major_version; // 主版本号
constant_pool_count; // 常量池计数器
constant_pool[]; // 常量池
access_flags; // 访问标志
this_class; // 类索引
super_class; // 父类索引
interfaces_count; // 接口计数器
interfaces[]; // 接口表
fields_count; // 字段计数器
fields[]; // 字段表
methods_count; // 方法计数器
methods[]; // 方法表
attributes_count; // 属性计数器
attributes[]; // 属性表
}各组成部分详解
- 魔数(Magic Number)
- 固定值:0xCAFEBABE
- 作用:标识文件是否为合法的Class文件
- 长度:4字节
- 版本号
- minor_version(2字节): 次版本号
- major_version(2字节): 主版本号(JDK 8=52,JDK 11=55,JDK 17=61)
- 作用:确保JVM版本兼容性
-
常量池(Constant Pool)
Class文件中最重要的部分,存储了类中所有的常量信息:常量池结构:
- constant_pool_count(2字节):常量数量+1
- cp_info[]:每个常量是一个表结构
常量类型包括:
-
CONSTANT_Utf8 = 1; // 字符串常量
-
CONSTANT_Integer = 3; // int常量
-
CONSTANT_Float = 4; // float常量
-
CONSTANT_Long = 5; // long常量(占2个槽位)
-
CONSTANT_Double = 6; // double常量(占2个槽位)
-
CONSTANT_Class = 7; // 类或接口引用
-
CONSTANT_String = 8; // String常量
-
CONSTANT_Fieldref = 9; // 字段引用
-
CONSTANT_Methodref = 10; // 方法引用
-
CONSTANT_InterfaceMethodref = 11; // 接口方法引用
-
CONSTANT_NameAndType = 12; // 名称和类型描述符
-
CONSTANT_MethodHandle = 15; // 方法句柄(Java 7+)
-
CONSTANT_MethodType = 16; // 方法类型(Java 7+)
-
CONSTANT_InvokeDynamic = 18; // 动态调用点(Java 7+)
记住tag值的口诀(按长度记忆)// 3字节固定长度(tag + 2字节索引)
tag=7 (Class)
tag=8 (String)// 5字节固定长度(tag + 4字节数据)
tag=3 (Integer)
tag=4 (Float)
tag=9 (Fieldref)
tag=10 (Methodref)
tag=11 (InterfaceMethodref)
tag=12 (NameAndType)// 9字节固定长度(tag + 8字节数据)
tag=5 (Long)
tag=6 (Double)// 变长
tag=1 (Utf8) → 3 + length
- 访问标志(Access Flags)
- 长度:2字节
- 标识类的访问属性:
0x0001:public
0x0010:final
0x0020:super
0x0200:interface
0x0400:abstract
0x4000:enum
0x8000:annotation
- 类索引、父类索引、接口索引集合
- this_class(2字节): 指向常量池中类的全限定名
- super_class(2字节): 指向父类的全限定名
- interfaces: 实现的所有接口
-
字段表(Fields)
field_info {
access_flags; // 字段访问标志
name_index; // 字段名索引
descriptor_index; // 字段描述符索引
attributes_count; // 属性数量
attributes[]; // 属性表
}
字段访问标志:
0x0001:public
0x0002:private
0x0004:protected
0x0008:static
0x0010:final
0x0040:volatile
0x0080:transient
-
方法表(Methods)
结构同字段表,包含方法的字节码指令:method_info {
access_flags; // 方法访问标志
name_index; // 方法名索引
descriptor_index; // 方法描述符索引
attributes_count; // 属性数量
attributes[]; // 属性表(包含Code属性)
}
Code属性 包含:
max_stack:最大操作数栈深度
max_locals:局部变量表大小
code\[\]:字节码指令序列
exception_table:异常处理表
- 属性表(Attributes)
常见的属性类型:
Code:方法的字节码
LineNumberTable:源码行号映射
LocalVariableTable:局部变量信息
SourceFile:源文件名
ConstantValue:final常量值
Exceptions:方法抛出的异常
InnerClasses:内部类信息
举例
java
package com.ruoyi.web.controller.test;
public class SimpleTest {
private int count;
public void increment(){
count++;
}
}javac SimpleTest .java
javap -v SimpleTest .class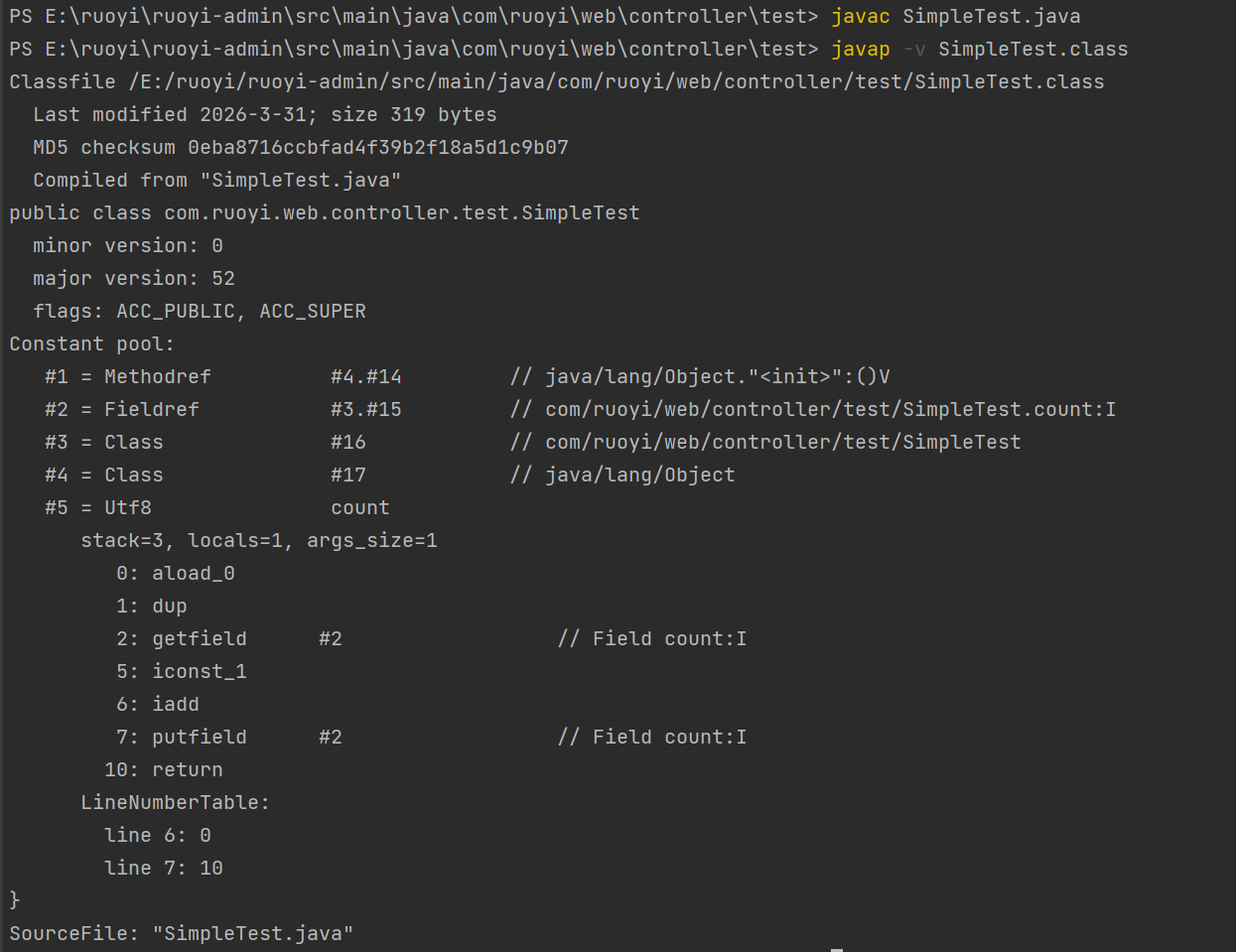
十六进制查看对应的字节码文件
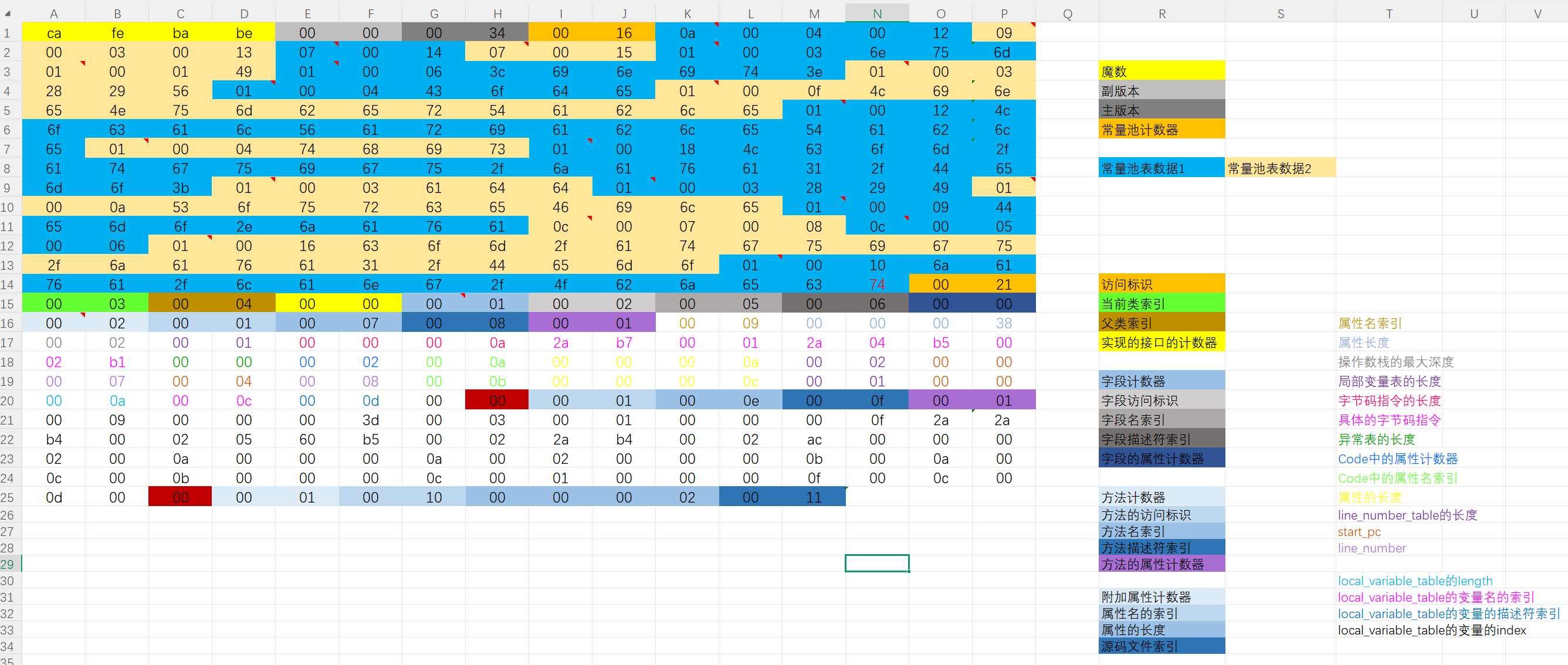
五、类加载
类加载是Java虚拟机(JVM)把类的字节码文件(.class文件)加载到内存中,经过验证、准备、解析等步骤,最终形成可以被JVM直接使用的Java类型的过程。
5.1 类加载过程
类加载分为:加载--->链接--->初始化
- 加载
- 通过类的全限定名获取二进制字节流(从class文件、JAR、网络等);
- 将字节流中的静态存储结构转化为方法区的运行时数据结构;
- 在堆中生成一个java.lang.Class对象,作为方法区数据的访问入口;
- 链接
链接包含三个子阶段:验证、准备、解析
验证: 确保Class文件的字节流复合JVM规范,不会危害虚拟机安全
- 文件格式验证: 魔数、版本号等;
- 元数据验证: 语义分析(是否有父类、是否覆盖final方法等);
- 字节码验证: 数据流和控制流分析,确保方法体合体;
- 符号引用验证: 符号引用能否被正确解析(类是否存在、权限是否够等);
准备
- 为静态变量(类变量)分配内存并设置默认初始值(零值);
- static int a=10------>准备阶段后a=0;
- 注意:static final 常量在准备阶段直接复制(因为不可变);
解析
- 将常量池中的符号引用 替换成直接引用(内存地址);
- 解析类型:类/接口、字段、类方法、接口方法;
- 初始化
- 执行类构造器()方法(编译器自动收集类变量的赋值动作和静态代码块);
- 类变量的赋值 和静态代码块 按代码顺序执行;
- 子类初始化前回初始化父类;
- 接口初始化不会触发父接口的初始化(除非使用父接口的常量);
触发初始化的六种情况:
- new对象;
- 访问静态变量/静态方法;
- 反射(Class.forName());
- 子类初始化时父类先初始化;
- 启动类(main方法所在类);
- MethodHandle解析结果对应的类未初始化时;
5.2 类加载器
- 双亲委派模型
-
类加载器收到加载请求后,先委派给父类加载器;
-
父类无法加载时,子类才自己尝试加载;
-
好处: 安全(防止核心类被篡改)、避免重复加载;
启动类加载器 (Bootstrap) ← 扩展类加载器 (Ext) ← 应用类加载器 (App)
- 线程上下文类加载器
作用: 打破双亲委派模型,让父类加载器区加载子类加载器才能找到的类;
典型应用: JDBC、JNDI、JAXB等SPI机制(服务提供者接口);
为什么需要:
- JDK核心类(如DriverManager)由Bootstrap加载;
- 但数据库驱动(如MySQL Driver)在classpath中,需要AppClassLoader加载;
- 双亲委派模型下,父加载器无法"看到"子加载器的类;
- 线程上下文类加载器允许父加载器通过Thread.currentThread().getContextClassLoader()获取子加载器来加载类;
- 自定义类加载器
为什么需要自定义?
- 从非标准来源加载类(网络、数据库、加密文件)
- 实现热部署/热替换
- 类隔离(同一类不同版本共存)
- 字节码加密/解密
实现步骤:
- 继承ClassLoader
- 重写findClass(String name)方法
- 读取.class文件字节码
- 调用defineClass()转换为Class对象
java
代码模板:
public class MyClassLoader extends ClassLoader {
private String classPath; // 自定义加载路径
public MyClassLoader(String classPath) {
this.classPath = classPath;
}
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
byte[] data = loadClassData(name);
if (data == null) {
throw new ClassNotFoundException(name);
}
return defineClass(name, data, 0, data.length);
}
private byte[] loadClassData(String className) {
String path = classPath + "/" + className.replace('.', '/') + ".class";
// 读取文件字节码并返回byte数组
return byteData;
}
}
java
使用示例
MyClassLoader loader = new MyClassLoader("/my/classes");
Class<?> clazz = loader.loadClass("com.example.Hello");
Object obj = clazz.newInstance();5.3 核心面试题速记
| 问题 | 答案要点 |
|---|---|
| 类加载的三个阶段 | 加载 → 链接 → 初始化 |
| 链接的三个子阶段 | 验证 → 准备 → 解析 |
| 准备阶段做什么 | 静态变量分配内存 + 零值 |
| 何时真正赋初始值 | 初始化阶段 |
| final static的区别 | final变量准备阶段直接赋值 |
| 双亲委派是什么 | 先委派父类加载,父类失败再自己加载 |
| 为什么需要破坏双亲委派 | SPI场景下父加载器需要调用子加载器的类 |
| 如何自定义类加载器 | 继承ClassLoader,重写findClass |
5.4 知识结构图
类加载机制
│
├── 加载过程
│ ├── 加载
│ ├── 链接
│ │ ├── 验证
│ │ ├── 准备
│ │ └── 解析
│ └── 初始化
│
└── 类加载器
├── 双亲委派模型
├── 线程上下文类加载器(破坏双亲委派)
└── 自定义类加载器六、即时编译(JIT)
即时编译是一种在程序运行时将代码动态编译成机器码的技术,介于解释执行和静态编译之间。
源代码 → [解释器逐行执行] 传统解释型(如早期Python)
源代码 → [编译器提前编译] 传统编译型(如C/C++)
源代码 → [运行时编译为机器码] 即时编译(JIT)为什么需要JIT?
| 问题 | 解决方案 |
|---|---|
| 解释执行太慢 | 热点代码编译成机器码,直接运行 |
| 静态编译缺乏灵活性 | 保留运行时信息,做针对性优化 |
| 跨平台需要重新编译 | 中间代码一次编写,到处运行 |
工作流程
1. 程序启动 → 以解释模式快速运行
↓
2. 收集运行时数据(哪些代码执行频繁)
↓
3. 识别"热点代码"(Hot Spot)
↓
4. 编译为本地机器码并缓存
↓
5. 后续直接执行机器码,速度大幅提升七、JVM 面试核心题库
7.1 基础题库
| 章节 | 面试问题 | 参考回答思路/核心考点 |
|---|---|---|
| 一、JVM 概述 | 1. 请解释 JVM、JRE 和 JDK 的区别? | JVM 是运行 Java 字节码的虚拟机;JRE 包含 JVM 和运行时类库,是运行环境;JDK 包含 JRE 和开发工具(如 javac),是开发环境。 |
| 2. 为什么说 Java "一次编写,到处运行"? | 依靠 JVM 屏蔽了不同操作系统的差异。Java 源代码编译成字节码(.class),只要目标系统有对应的 JVM,就能运行。 | |
| 3. 说一下常见的 JVM 有哪些?HotSpot 有什么特点? | 常见的有 HotSpot (Oracle/Sun,最主流,默认C1/C2编译器)、OpenJ9 (Eclipse,内存占用低)、GraalVM (高性能,支持多语言)。 | |
| 二、JVM 内存模型 | 1. Java 内存区域中哪些是线程私有的,哪些是共享的? | 私有:程序计数器、虚拟机栈、本地方法栈(无需 GC,线程结束自动回收)。 共享:堆(对象实例)、方法区(类元数据、常量池)。 |
| 2. 栈帧(Stack Frame)里面包含什么? | 包含局部变量表、操作数栈、动态链接、方法出口等信息。每个方法调用到执行完毕,对应一个栈帧在虚拟机栈中入栈出栈的过程。 | |
| 3. 堆内存溢出(OOM)和栈内存溢出(SOF)的原因是什么? | OOM (Java heap space):对象太多,堆内存不足(如内存泄漏、加载大文件)。 SOF (StackOverflowError):递归太深或方法嵌套调用太多,导致栈深度超限。 | |
| 4. JDK 1.8 中,字符串常量池去哪了? | 在 JDK 1.7 之前在永久代,JDK 1.8 及以后,字符串常量池被移到了堆(Heap)中,而类的元数据则放在元空间(Metaspace,本地内存)。 | |
| 5. 直接内存(Direct Memory)是什么?有什么问题? | 不是 JVM 运行时数据区,是操作系统内存。通过 ByteBuffer.allocateDirect 分配,避免了 Java 堆和 Native 堆之间的数据拷贝。问题:受 -XX:MaxDirectMemorySize 限制,分配不当也会导致 OOM。 |
|
| 三、垃圾回收机制 | 1. 怎么判断对象是否可以被回收?(可达性分析 vs 引用计数) | 引用计数:简单但无法解决循环引用问题(Java 不用)。 可达性分析:从 GC Roots 出发,不可达的对象即为垃圾。 |
| 2. 什么是强、软、弱、虚引用? | 强引用:永不回收。 软引用:内存不足时回收(适合缓存)。 弱引用:每次 GC 都回收(适合 ThreadLocal)。 虚引用:无法获取对象,仅用于跟踪回收通知(管理堆外内存)。 | |
| 3. 说一下常见的垃圾回收算法(标记-清除/复制/整理)? | 标记-清除:速度快,但有内存碎片。 标记-整理:无碎片,但移动对象成本高。 复制:无碎片,效率高,但内存浪费(存活对象少时用)。 | |
| 4. 为什么要分代回收?新生代和老年代分别用什么算法? | 基于"大多数对象朝生夕灭"的经验法则。 新生代:存活率低,用复制算法(Eden + 2 Survivor)。 老年代:存活率高,用标记-整理或标记-清除。 | |
| 5. 说一下 CMS 和 G1 的区别? | CMS:老年代,并发收集,低停顿,但有内存碎片,会产生浮动垃圾。 G1:面向服务端,分区(Region)管理,可预测停顿,整体基于"标记-整理",局部基于"复制"。 | |
| 四、类字节码结构 | 1. Class 文件的魔数是什么?有什么作用? | 魔数是 0xCAFEBABE。作用是确定这个文件是否为一个能被虚拟机接受的 Class 文件。 |
| 2. 常量池主要存储了什么内容? | 存储了类中的字面量(如文本字符串、final常量)和符号引用(类和接口的全限定名、字段名、方法名等)。 | |
| 3. 访问标志(Access Flags)的作用是什么? | 标识类或接口的访问属性,如 public、final、abstract、interface 等。 |
|
| 五、类加载 | 1. 请简述类加载的过程? | 加载 -> 链接(验证、准备、解析) -> 初始化。 注意:准备阶段给静态变量赋零值,初始化阶段才赋代码指定的值。 |
| 2. 什么是双亲委派模型?为什么要打破它? | 模型:类加载器收到请求先委派给父类加载,父类无法完成才自己尝试。 好处:防止核心 API 被篡改,避免重复加载。 打破:如 JDBC/SPI 机制,父类加载器(Bootstrap)需要加载位于 Classpath 下的第三方驱动实现,此时需通过线程上下文类加载器来打破双亲委派。 | |
| 3. 如何自定义类加载器? | 继承 ClassLoader 类,重写 findClass 方法,读取字节码文件,调用 defineClass 转换为 Class 对象。 |
|
| 六、即时编译 (JIT) | 1. 为什么需要 JIT 编译器? | 解释执行逐行运行效率低。JIT 将热点代码(频繁执行的方法)编译成本地机器码缓存起来,直接运行机器码,大幅提升执行效率。 |
| 2. HotSpot VM 中有哪些 JIT 编译器? | C1 (Client):轻量级,编译速度快,优化程度一般。 C2 (Server):重量级,编译慢但优化激进(如内联函数、逃逸分析)。 分层编译:混合使用两者。 |
7.2 实战题库
7.2.1 内存模型与调优:从理论到实战诊断
- 堆内存溢出(OOM)的排查话术与工具链
场景: 面试官问:"线上服务器 CPU 飙升或内存溢出怎么办?"
加分回答策略: 采用*定位 -> 分析 -> 解决 的结构化回答,并提及具体的命令;
| 步骤 | 关键动作 | 涉及文档工具/命令 | 话术示例 |
|---|---|---|---|
| 1. 定位进程 | 找到资源占用最高的 Java 进程 | top、ps |
"首先使用 top 命令查看系统资源占用,找到 CPU 或内存异常的 Java 进程 ID(PID)。" |
| 2. 定位线程 | 找到是哪个线程导致的异常 | ps H -eo pid,tid,%cpu |
"如果是 CPU 高,我会用 ps H -eo pid,tid,%cpu 查看该进程中哪个线程占用最高,并将线程 ID 转换为 16 进制。" |
| 3. 导出堆栈 | 获取代码层面的线索 | jstack |
"使用 jstack <PID> 导出线程栈,搜索刚才的 16 进制线程 ID,直接定位到问题代码的行号。" |
| 4. 内存分析 | 分析对象过多的原因 | jmap、jconsole |
"如果是内存溢出,使用 jmap -dump 导出堆转储文件,或者用 jmap -histo 查看对象统计,分析是哪个对象在疯狂增长。" |
- 字符串常量池(StringTable)的版本变迁
场景: 面试官问:"JDK 1.8 对字符串常量池做了什么优化?"
加分回答策略:画图对比 + 解释痛点。
JDK 1.6 及以前:
- 位置:永久代(PermGen)。
- 痛点:永久代大小有限,且 Full GC 对字符串常量池的回收效率低,容易导致 PermGen Space OOM。
JDK 1.7:
- 变化: 字符串常量池被移到了堆(Heap)中。
- 好处: 减少了永久代的内存压力,且字符串可以被正常的 GC 回收。
JDK 1.8:
- 变化: 永久代被移除,取而代之的是元空间(Metaspace)(使用本地内存)。
- 现状: 字符串常量池仍在堆中,而类的元数据(运行时常量池)在元空间。
话术总结:"JDK 1.8 将字符串常量池移到堆中,主要是为了解决永久代容易 OOM 的问题,并让字符串对象能像普通对象一样被高效的 GC 管理。"
7.2.2 垃圾回收器(GC):画图与选型
- 核心算法的"三色标记"与"指针碰撞"
场景: 面试官问:"复制算法为什么没有内存碎片?"
加分回答策略:手绘内存移动图。
复制算法(新生代):
- 图示:画两个区域(From 和 To)。存活对象被复制到 To 区,然后一次性清理 From 区。
- 结论:对象在 To 区是连续排列的,所以无碎片,且分配内存只需移动指针(指针碰撞),效率极高。
标记-整理(老年代):
- 图示:画一堆杂乱的对象。标记后,存活对象向一端移动,清理边界外内存。
- 结论:解决了标记-清除算法的碎片问题,但移动对象成本高。
- 回收器的演进与选型(重点:G1 vs CMS)
场景: 面试官问:"G1 和 CMS 有什么区别?你们线上用哪个?"
加分回答策略:对比表格 + 业务场景匹配。
| 维度 | CMS (Concurrent Mark Sweep) | G1 (Garbage First) | 你的选型理由 |
|---|---|---|---|
| 内存布局 | 传统分代(新生/老年代) | Region 分区 | "G1 的内存布局更灵活,可以预测停顿时间。" |
| 算法 | 标记-清除(有碎片) | 标记-整理 + 复制 | "CMS 会产生碎片,导致 Full GC;G1 没有碎片问题。" |
| 停顿时间 | 不可预测 | 可预测(设定时间目标) | "我们系统对延迟敏感,G1 可以设置比如 200ms 内完成 GC。" |
| 适用场景 | 4G-6G 内存以下 | 大内存(4G+) | "目前服务器内存普遍较大,G1 是更主流的选择。" |
话术建议: "如果是中小型应用,Parallel GC(吞吐量优先)也是不错的选择;如果是大型互联网应用,G1 或 ZGC 是首选。"
7.2.3 类加载与字节码:深度与破坏原则
展示你对双亲委派模型的深刻理解,特别是为什么要"破坏"它。
- 双亲委派模型的"破坏"与 SPI
场景: 面试官问:"什么是双亲委派?为什么要破坏它?"
加分回答策略:图解类加载委托链 + SPI 实际案例。
什么是双亲委派:
- 流程:AppClassLoader -> ExtClassLoader -> BootstrapClassLoader。
- 原则:先找父亲加载,不行再自己来。
- 好处:安全,防止核心类库被篡改(比如你自己写一个 java.lang.String,不会被加载)。
为什么要破坏它:
痛点(JDBC 问题):
- Bootstrap 加载了 DriverManager(在 rt.jar 中)。
- 但是数据库驱动(如 com.mysql.cj.jdbc.Driver)在 Classpath 中,Bootstrap 根本"看不见"它。
解决方案(线程上下文类加载器):
- DriverManager 在初始化时,会通过 Thread.currentThread().getContextClassLoader() 获取到 AppClassLoader。
- 强行用 AppClassLoader 去加载具体的驱动实现。
话术总结:"双亲委派是为了安全,但在 Java SPI(服务提供接口)场景下,父类加载器需要回调子类加载器的代码,这时候必须通过线程上下文类加载器来打破双亲委派。"
- 字节码与魔数
场景: 面试官问:"Class 文件的结构是怎样的?"
加分回答策略:背诵魔数 + 常量池作用。
- 魔数(Magic Number):0xCAFEBABE(咖啡宝贝)。这是 Class 文件的身份证,如果不是这个值,JVM 会直接拒绝加载。
- 常量池(Constant Pool):这是 Class 文件的资源仓库,存放了字面量(如字符串、final常量)和符号引用(类名、方法名)。
- 版本号:JDK 8 对应 52,JDK 11 对应 55。高版本 JDK 不能运行低版本字节码(向下兼容,不向上兼容)。
7.2.4 总结:面试官眼中的"高分候选人"
在面试 JVM 时,请务必遵循以下原则:
- 拒绝"死记硬背":不要一上来就背定义。例如,不要说"堆是线程共享的内存区域",而要说"在排查内存泄漏时,我们通常关注堆内存,因为它是所有线程共享的,也是对象分配的主要场所。"
- 善用工具:提到 jstack、jmap、jconsole 等工具,证明你有线上问题排查的经验。
- 版本意识:时刻区分 JDK 1.6/7/8 的差异(特别是永久代 vs 元空间、字符串常量池位置),这能证明你对技术演进的关注。
- 理解设计哲学:理解为什么要有 GC(解放程序员)、为什么要有双亲委派(安全)、为什么要分代(基于对象生命周期的统计学规律)。