📌 系列简介 :「JS全栈AI Agent学习」系列第二篇 ⏱️ 预计阅读时间:15 分钟 🛠️ 技术栈 :LangChain.js + TypeScript + NestJS 📖 原书地址 :adp.xindoo.xyz
上一篇学了提示链、路由、并行化------解决了"怎么执行"的问题。 这一篇的三个模式,解决的是更高阶的问题:怎么做得更好、怎么突破边界、怎么面对复杂任务。
🗺️ 系列导航
| 篇 | 主题 | 状态 |
|---|---|---|
| 第1篇 | 提示链 · 路由 · 并行化 | ✅ |
| 第2篇(本篇) | 反思 · 工具使用 · 规划 | ✅ |
📖 读这篇,你可以带走什么
| # | 你会学到 | 对应章节 |
|---|---|---|
| 1 | 反思不是"泛泛自评",而是有具体内容的结构化闭环 | 第四章 |
| 2 | 自我反思 vs 外部评审,怎么选、什么时候混用 | 第四章 |
| 3 | 反思上限为什么定 3 次------「一鼓作气,再而衰,三而竭」 | 第四章 |
| 4 | LLM 不执行代码,它只输出"意图"------这个认知很重要 | 第五章 |
| 5 | 工具的 description 比实现更重要,写好描述比写好代码更关键 | 第五章 |
| 6 | 安全防护三层结构:输入校验 → 权限分级 → 人工确认 | 第五章 |
| 7 | 判断要不要用规划模式,比"任务复不复杂"更精准的标准 | 第六章 |
| 8 | [REPLAN] 标记:不可逆操作不能让 AI 自己决定 |
第六章 |
前言:执行能力有了,然后呢?
学完第一篇,你的 Agent 已经能拆解任务、分发请求、并行提速了。 但你可能还会遇到这些问题:
- AI 输出了结果,但质量不稳定,有时好有时差------怎么让它自己发现问题并改进?
- 任务需要读文件、查数据库、调接口,纯文本 LLM 根本做不到------怎么让它真正能做事?
- 任务很复杂,直接丢给 AI 结果天马行空------怎么让它先想清楚再动手?
这三个问题,对应本篇的三个模式:反思、工具使用、规划。
如果说第一篇解决的是"怎么跑起来",这一篇解决的是------怎么跑得稳、跑得远、跑得对。
📖 第四章:反思(Reflection)
读这章之前,我就已经这么做了
说实话,读到「反思」这章之前,我就已经在开发里这么做了。
写完一段代码,我习惯问自己三个问题:
- 这段代码有没有完成功能?
- 边界有没有考虑完善?
- 还能不能复用、优化?
这和《论语》里那句话是一个道理:
吾日三省吾身------为人谋而不忠乎?与朋友交而不信乎?传不习乎?
反省不是走形式,是要有具体内容的。曾子每天反省三件具体的事,不是泛泛地说"我今天表现怎么样"。
读到反思模式,我的第一反应就是:这不就是把这个习惯自动化了吗?
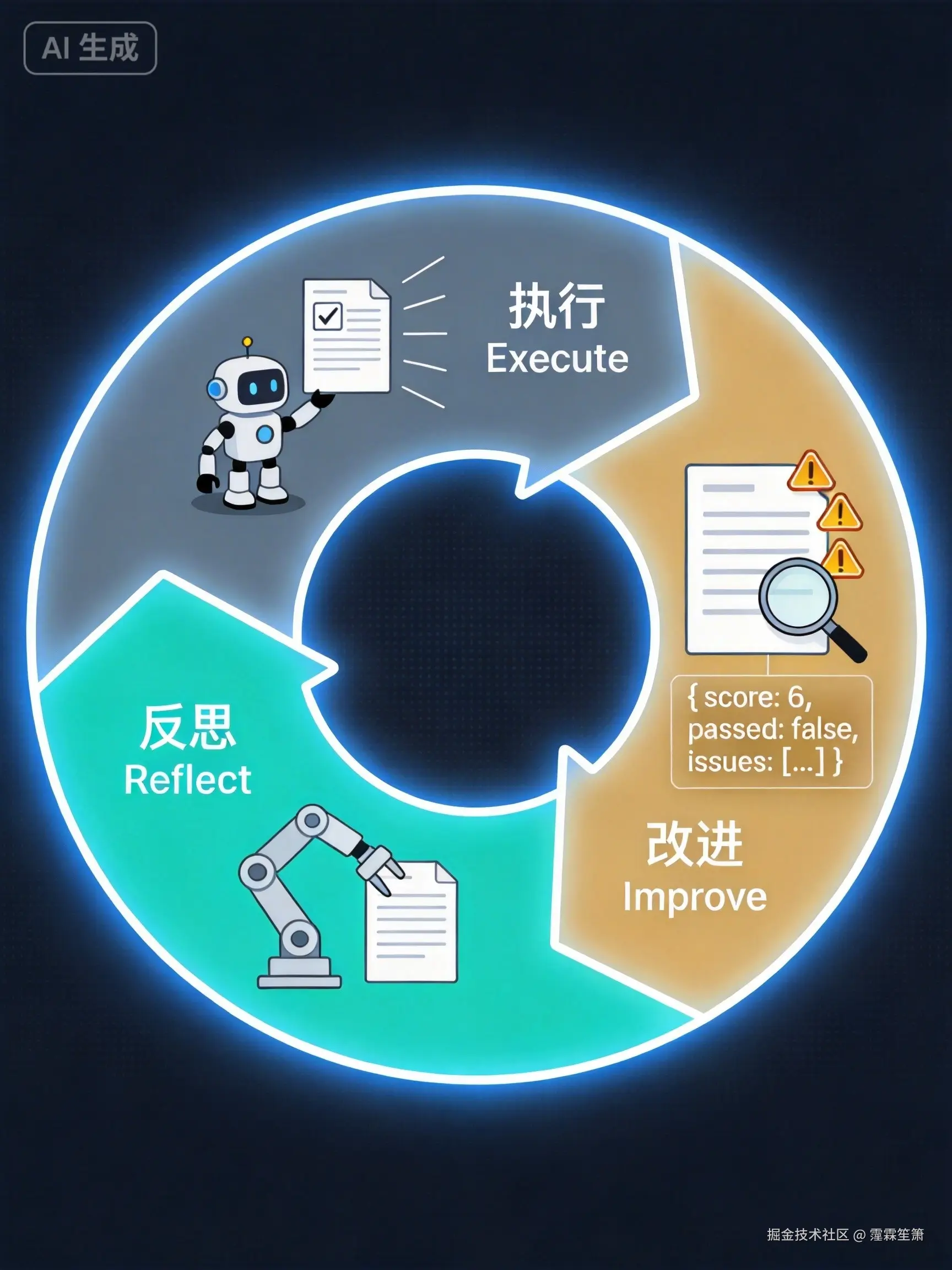
Agent 执行完任务,不直接输出结果,而是先问自己:
- 这个结果完成了目标吗?
- 有没有遗漏的边界?
- 有没有可以改进的地方?
css
执行 → 输出结果 → [反思:完成目标了吗?边界全了吗?还能更好吗?]
↓ 有问题
改进后重新执行
↑_____________|
(循环,直到满意)两种反思模式
书里把反思分为两种角色结构,用开发类比来理解:
自我反思(Self-Reflection)
同一个 LLM,先执行,再切换角色评审自己的输出。
就像写完代码自己 Review------能发现明显问题,但容易"自我感觉良好",对自己的盲区视而不见。
arduino
优点:简单、低成本
缺点:容易陷入"认知偏差",发现不了深层问题
适合:对质量要求适中的场景外部评审(Critic Agent)
另起一个专门负责批评的 Agent,独立评审执行结果。
就像找另一个同事来 Code Review------他不知道你当时怎么想的,所以能发现你自己看不到的问题。
优点:更客观,能发现执行 Agent 的盲区
缺点:多一次 LLM 调用,成本更高
适合:对质量要求高的场景,如代码生成、方案设计两者不是非此即彼的------先用自我反思快速迭代,质量卡关了再引入外部评审,是比较务实的做法。
反思结果必须结构化
反思不能只是一段文字感想,必须输出结构化数据,方便程序判断是否需要继续迭代:
typescript
interface ReflectionResult {
score: number; // 0-10 质量评分
passed: boolean; // 是否达到标准(比如 score >= 7)
issues: string[]; // 发现的具体问题列表
suggestions: string[]; // 改进建议
iteration: number; // 当前第几次反思
}反思上限定为 3 次------「一鼓作气,再而衰,三而竭」
反思循环必须有终止条件,这个上限不是随意拍的数字,是有逻辑的:
一鼓作气,再而衰,三而竭。------《左传·曹刿论战》
第一次反思:效果最好,能发现最明显的问题,改进幅度最大。 第二次反思:精益求精,发现细节问题,改进幅度变小。 第三次反思:边际收益已经很低,再反思下去基本是形式主义。
typescript
const MAX_ITERATIONS = 3; // 一鼓作气,三而竭
async function reflectiveExecute(task: string): Promise<string> {
let result = await execute(task);
for (let i = 0; i < MAX_ITERATIONS; i++) {
const reflection = await reflect(task, result);
if (reflection.passed) {
console.log(`✅ 第 ${i + 1} 次反思通过,评分:${reflection.score}`);
break;
}
console.log(`🔄 第 ${i + 1} 次反思,发现问题:`, reflection.issues);
result = await executeWithFeedback(task, result, reflection);
}
return result;
}💡 超过上限还没通过,应该升级为人工介入------而不是继续让 AI 自己转圈。 无限循环不是"更努力",是"没有终止条件的 bug"。
📖 第五章:工具使用(Tool Use)
先聊聊我踩过的坑
用过 Codex CLI、Claude 这类工具的人应该都有体会:在 CLI 环境里,AI 默认是读不了你本地文件的 。.vue、.md、.pdf,你以为它能理解,其实它只是在"猜"。
这就是纯 LLM 的边界------它只能处理你直接输入的文本,做不到:
❌ 读取本地文件(.vue .md .pdf .xlsx...)
❌ 访问实时网络
❌ 执行代码
❌ 操作数据库
❌ 调用第三方 API
❌ 感知当前时间Tool Use 就是为了解决这个问题------给 LLM 装上"手"。
前端视角的类比:先用原生,再找第三方
读到这章,我想到了一个前端开发的日常习惯:
实现一个功能,不会先去 npm 找包,而是先看浏览器原生支持什么。
- 需要定位?先看
navigator.geolocation - 需要存储?先看
localStorage/sessionStorage - 需要网络请求?先用
fetch - 原生做不到,再找第三方库;库也不够,再自己造
这就是 KISS(Keep It Simple) 和 DRY(Don't Repeat Yourself) 原则------少造轮子,优先复用已有能力。
Agent 的工具使用,逻辑完全一样:
markdown
LLM 原生能力(文本推理)
↓ 不够用
调用已有工具(读文件、查数据库、调 API)
↓ 还不够
扩展新工具(自己开发 / 接入第三方服务)核心机制:LLM 不执行代码
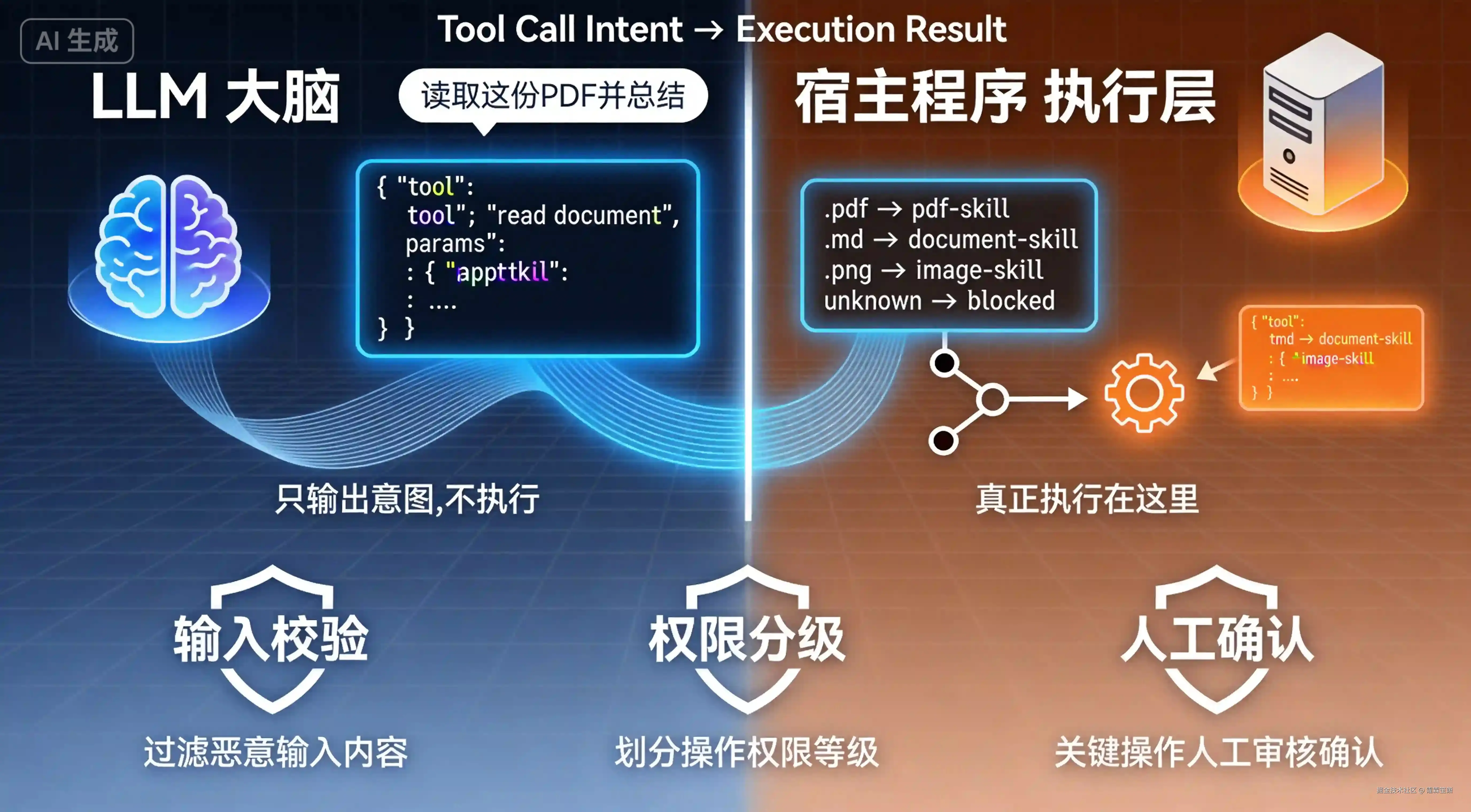
这个类比让我想清楚了一件事:工具的边界在哪里------LLM 负责"知道用什么",宿主程序负责"真正去做"。
很多人以为 AI 调用工具是"AI 直接执行代码",其实完全不是:
javascript
用户输入
↓
LLM 分析:我需要什么工具?参数是什么?
↓
输出结构化的"工具调用意图"(JSON) ← LLM 只做这一步
↓
宿主程序(你写的代码)实际执行工具 ← 真正执行在这里
↓
把执行结果返回给 LLM
↓
LLM 基于结果生成最终回答🎯 这个认知很重要:LLM 只是"描述想做什么",真正执行的是你写的宿主程序。 所以安全控制要在宿主程序里做------靠 LLM 自己约束自己,是不可靠的。
白名单 + 分发 + 统一处理------实际项目里用过的设计
这套设计不是读完书推导出来的,是我在实际项目里做过的:
根据文件后缀区分格式,再根据不同格式分发到对应的处理逻辑。
映射到 Agent 工具系统,就是三步:
第一步:确定支持的文件类型白名单
不能什么都支持,要根据实际需求定优先级:
- 文档类:先支持
.md和.pdf,.xlsx、.pptx后面再加 - 图片类:先支持
.jpg、.png、.webp,SVG 单独处理 - 视频类:先不做,太消耗 token,等有明确需求再说
第二步:后缀识别 + 分发到对应 Skill
有了白名单,就能写识别逻辑:识别到 .png 用 image-skill,识别到 .md 用 document-skill,不支持的直接阻断,避免 token 浪费。
第三步:封装公共结果处理器
不同工具的输出格式不同,需要一个统一的结果处理层,把各种格式归一化后再返回给用户。
这个思路,和 LangChain 的 Tool 设计几乎一致:
typescript
// Tool 三要素:实现、名称、描述
const readDocumentTool = tool(
async ({ filePath }) => {
const ext = path.extname(filePath).slice(1).toLowerCase();
if (!["md", "txt"].includes(ext)) return "错误:不支持的文件类型";
return fs.readFileSync(filePath, "utf-8");
},
{
name: "read_document",
// description 是最重要的:LLM 靠这个决定要不要用这个工具
description: "读取 .md 或 .txt 文档的文本内容",
schema: z.object({
filePath: z.string().describe("文档的绝对路径"),
}),
}
);💡 description 比实现更重要:LLM 选工具完全靠 description。 写得越清晰,选择越准确------这和写函数注释是一个道理,只不过读注释的换成了 AI。
安全设计:三层防护------来自安全公司的经验
书里只提到"安全控制要在宿主程序里做",但没有给出具体结构。
这三层是我自己想到的,来自之前在安全公司做产品的经验------防御要分层,每一层只负责自己那一段:
第一层:输入校验(宿主程序)
├── 文件类型白名单过滤
├── 路径合法性检查(防路径穿越攻击)
└── 文件大小限制(防 token 爆炸)
第二层:权限分级(工具内部)
├── 只读操作 → 直接执行
├── 写操作 → 需要用户权限验证
└── 危险操作 → 直接拒绝 + 记录日志
第三层:人工确认(不可逆操作)
└── 涉及不可逆操作 → 暂停执行,等待用户确认三层各自防一类风险:
- 危险脚本伪造后缀名 :比如把恶意脚本命名成
.md------要在工具内部先做内容校验,不能只看后缀 - 权限过大的操作:比如删库、清空文件------直接在工具层拒绝,不给 LLM 任何执行机会
- 有副作用的操作:比如写入数据库、发送邮件------先上报给用户,让用户决定是否执行
ReAct:工具调用的思维框架
工具调用背后有一个经典模式叫 ReAct(Reasoning + Acting):
yaml
Thought(思考):我需要先检测文件类型
Action(行动):调用 detect_file_type 工具
Observation(观察):返回 { supported: true, category: "document" }
Thought(思考):是 md 文件,用 read_document 工具
Action(行动):调用 read_document 工具
Observation(观察):返回文件内容
Thought(思考):我已经有了文件内容,可以总结了
Action(行动):生成最终回答(不再调用工具)LLM 不断地思考 → 行动 → 观察,直到认为任务完成。这个循环,就是工具调用的完整链路。
💡 关键洞察
| 洞察 | 说明 |
|---|---|
| 先用原生,再找第三方 | KISS + DRY,能不造轮子就不造 |
| LLM 不执行代码 | 它只输出"意图",宿主程序才真正执行 |
| description 决定工具选择 | 写好描述比写好实现更重要 |
| temperature=0 | 工具调用场景必须稳定,不能随机 |
| 安全分三层 | 输入校验 → 权限分级 → 人工确认 |
📖 第六章:规划(Planning)
先有需求,后发现对应模式
工具使用解决了"能做到"的问题,但如果任务足够复杂,直接丢给 AI 执行,结果往往天马行空。
我在实际项目里遇到过这个问题。当前在做的报价系统,如果直接跟 AI 说:
"根据当前项目的设计风格,在 projectList 添加一个入口,实现一个报价页面,并能生成 PDF"
AI 可能会给你一个完全不符合现有架构的方案,或者直接开始写代码,跳过了架构设计和影响范围分析。
说实话,"先规划再执行"这个习惯,我在做这个需求之前就已经这么做了------不是先学了规划模式才这么想,而是工程经验告诉我应该这么做。读到这章,才发现原来这就是规划模式。
我接到复杂需求的拆解方式大概是这样:
- 架构设计:先看影响范围,在不影响主流程的情况下设计完整链路
- 交互阶段拆分:梳理完整的用户交互流程(报价系统:项目入口 → 报价页 → 生成报价单,3个页面)
- 功能模块拆分:每个页面拆分功能模块,明确职责,不用太细,编码时再优化
- 组合验证:把所有模块组合起来,验证整体交互是否完整
这个过程映射到 Agent 上,就是规划模式要做的事。
原书的核心判断标准
书里有一句话说得非常准,是判断要不要用规划模式的关键:
「方法」需要被发现,还是已经已知?
- 方法已知、流程固定 → 用提示链就够了
- 方法未知、需要动态生成 → 用规划模式
这个标准比"任务复不复杂"更精准。有些任务看起来复杂,但流程是固定的(比如生成报价单),用提示链反而更稳;有些任务看起来简单,但解法不确定(比如调试一个未知 bug),就需要规划模式动态应对。
两种规划策略
这两个名字(静态规划/动态规划)是 AI 伙伴帮我提炼的,但背后的意思是我自己的理解:
静态规划(Plan-then-Execute)
先出完整计划,确认后再执行,执行中不修改计划。
适合:任务边界清晰、步骤可预见
例子:生成报价单(步骤固定:收集信息 → 计算 → 排版 → 导出PDF)
优点:可预测、可审查、token 消耗稳定
缺点:遇到意外情况不够灵活动态规划(ReAct + Replan)
每步执行后重新评估,必要时修改后续计划。
适合:任务边界模糊、中途可能发现新信息
例子:代码重构(重构过程中可能发现新的依赖问题)
优点:灵活应对变化
缺点:token 消耗大,执行路径不可预测计划必须结构化
计划不能是一段文字,必须是结构化数据,方便程序处理依赖关系和并行调度:
typescript
interface PlanTask {
id: string;
name: string;
description: string;
dependencies: string[]; // 依赖哪些任务完成后才能执行
estimatedTokens: number;
status: "pending" | "running" | "done" | "failed" | "skipped";
result?: string;
retryCount: number;
}有了依赖关系,就能做两件事:
- 拓扑排序:确定执行顺序
- 并行调度:没有依赖关系的任务同时执行(结合第一篇的并行化模式)
偏差检测与 [REPLAN] 标记------来自另一个项目的 Task 状态管理
执行到一半发现计划不对,怎么办?
[REPLAN] 这个标记是我自己设计的,来自另一个项目里做 Task 状态管理和流转的经验------任务执行过程中,状态不只有"成功/失败",还有"需要重新规划"这种中间态。
typescript
// 执行器检测到异常时,输出 [REPLAN] 标记
// 宿主程序捕获后,触发人工干预回调
const needReplan = result.startsWith("[REPLAN]");
if (needReplan && onReplanNeeded) {
const decision = await onReplanNeeded(result); // 上报给用户
// 根据用户决策:continue / replan / abort
}当 Agent 识别到偏差,有三种处理路径:
- 继续执行:当前偏差在可接受范围内
- 调整后继续:修改当前阶段的参数或方向,继续后续步骤
- 推翻重来:整个计划有问题,重新规划
实际项目里,大多数情况 AI 都会继续执行下去,这是现阶段的局限。但在设计系统时,应该主动埋入这个检测点------不可逆操作不能让 AI 自己决定。
规划 vs 提示链
| 提示链 | 规划模式 | |
|---|---|---|
| 步骤来源 | 开发者硬编码 | LLM 动态生成 |
| 流程是否固定 | 固定,不能变 | 可根据任务调整 |
| 适合场景 | 方法已知的任务 | 方法需要被发现的任务 |
| 成本 | 简单、可控、低 token | 灵活、强大、高 token |
🎯 选择原则:
- 方法已知 → 提示链
- 方法未知 → 规划模式
- 两者结合 → 规划模式生成计划,每个子任务内部用提示链执行
🔗 三章串联:自我进化闭环
这三章合在一起,构成了一个完整的自主执行闭环:
markdown
规划(Planning)
↓ 决定做什么、怎么做、分几步
工具使用(Tool Use)
↓ 执行时调用外部能力,突破纯文本边界
反思(Reflection)
↓ 做完后评估质量,驱动下次更好
↑_________________________________|
(循环迭代)| 模式 | 解决什么问题 | 核心结构 |
|---|---|---|
| 反思 | 输出质量不稳定,怎么自我改进? | 执行 → 评审 → 改进(循环) |
| 工具使用 | 纯文本做不到的事,怎么突破? | LLM 意图 → 宿主执行 → 结果反馈 |
| 规划 | 复杂任务怎么不跑偏? | 先出计划 → 确认 → 执行 → 监控 |
三者的关系,不是并列的三个工具,而是一个闭环:
规划决定方向,工具使用突破边界,反思保证质量------缺任何一环,Agent 都跑不远。
🛠️ 在 my-resume 项目中的应用
| 项目场景 | 对应模式 | 说明 |
|---|---|---|
| AI 生成简历后自动评分优化 | 反思 | 生成 → 评审 → 改进,最多3轮 |
| 读取用户上传的 PDF/图片简历 | 工具使用 | 文件类型白名单 + 对应 Skill 处理 |
| 报价系统完整链路实现 | 规划 | 先拆解阶段和步骤,再按计划执行 |
边学边做,是我觉得最快的方式。理论看懂了,不等于会用------只有落到真实项目里,才知道哪里还没想清楚。
📝 总结
两篇学完,手里已经有了六个核心模式:
| 第一篇(基础执行) | 第二篇(自我进化) | |
|---|---|---|
| 拆解 | 提示链:怎么串行拆解 | 规划:怎么面对复杂任务 |
| 分发 | 路由:怎么分发请求 | 工具使用:怎么突破边界 |
| 提速/质量 | 并行化:怎么提速 | 反思:怎么自我改进 |
这六个模式已经能覆盖大多数 Agent 开发场景。
学到这里,我越来越觉得:Agent 设计和软件系统设计,底层是同一套思维。 拆任务、管流程、做容错、保质量------工程师早就在做了,只不过现在执行者从代码变成了模型。
后续几篇会进入更高阶的领域:多智能体协作、记忆管理、安全防护......
下一篇预告: 当一个 Agent 不够用,需要多个 Agent 协作时,怎么设计? 第三篇将覆盖多智能体、记忆管理、学习适应三个模式。
💬 系列地址:持续更新中
📖 原书地址 :adp.xindoo.xyz
🛠️ 实战项目:my-resume(NestJS + Drizzle ORM + SQLite)
如果这篇对你有帮助,欢迎点赞收藏,我们下篇见 👋