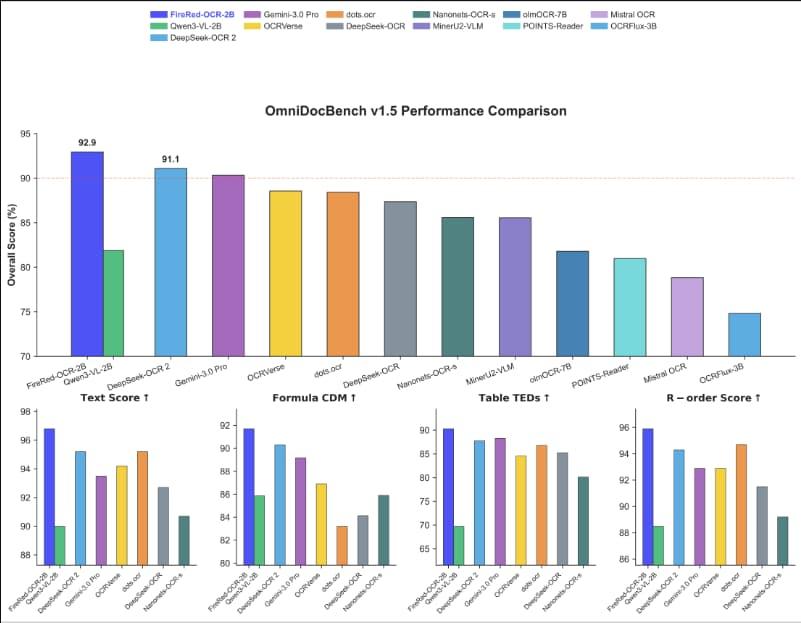
FireRed-OCR
github地址:https://github.com/FireRedTeam/FireRed-OCR
FireRed-OCR是一个系统化的框架,旨在将通用的大型视觉语言模型 (LVLM) 专门化为高性能、像素级精确的结构化文档解析专家。
通用虚拟语言模型在处理复杂文档时经常会遇到"结构幻觉"(例如,行排列紊乱、出现虚构公式)。FireRed-OCR 通过将文本生成范式从"印象式"转变为"结构工程"来解决这个问题
主要特点
- 结构完整性:该模型利用格式约束 GRPO(组相对策略优化),强制执行严格的语法有效性,消除未闭合的表格或无效的 LaTeX 公式等常见错误。
- "几何 + 语义"数据工厂:一种新型数据引擎,利用几何特征聚类和多维标记来合成平衡数据集,有效处理长尾布局。
渐进式培训流程:
- 多任务预对齐:建立空间基础。
专业 SFT:标准化全图像 Markdown 输出。
格式约束的GRPO:通过强化学习进行自我纠正
使用方式
网盘下载并解压后,双击start.bat
等待终端启动
浏览器打开localhost:7860
选择图片,点击底部的开始OCR
然后查看实时进度,等待md结果
解析完成,可以点击下载md,使用自己的编辑器查看效果
也可以直接复制识别结果中的文本内容
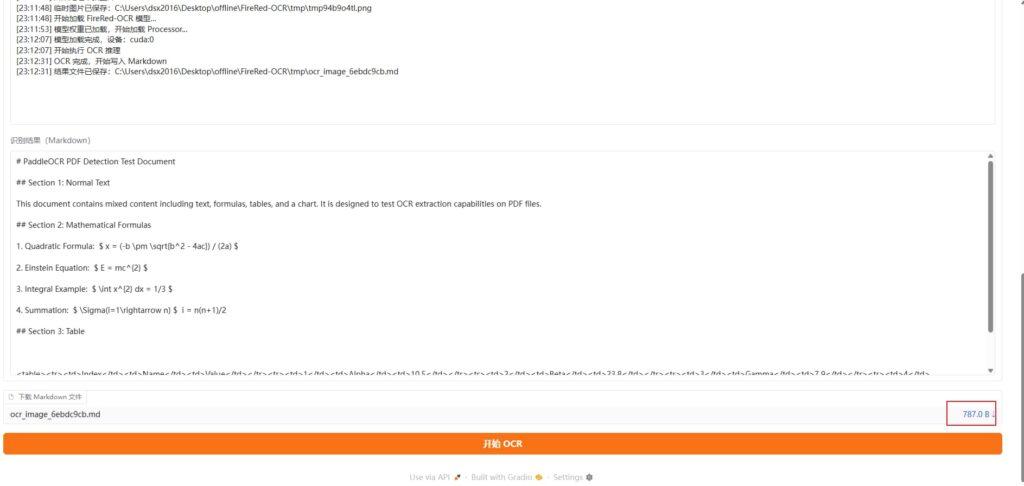
点击红框区域可以下载文件
Tips
点击此处 网盘下载
注意,FireRed-OCR默认不支持pdf转md,只支持图片转md
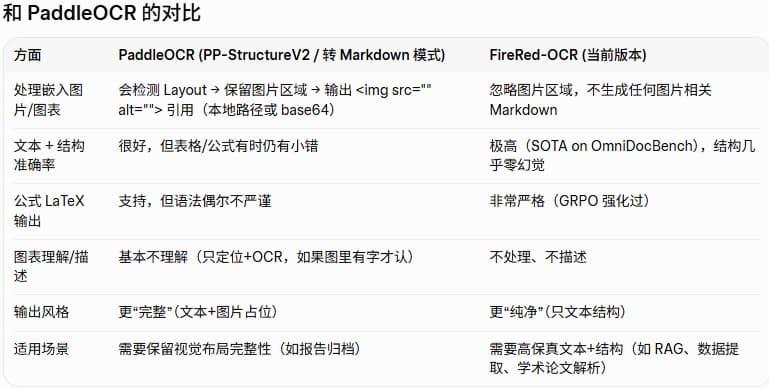
同样的FireRed-OCR只处理文本等内容,如果遇到图表等元素,不会像paddleocr一样进行处理和md引用
实际测试,图片转md需要显存4GB左右,但是PDF转md显存需要至少8GB起,并且时间会比价久
目前多图片处理还没有进行测试,只是占位
另外FireRed-OCR是端到端的ocr类别,建议有显卡优先尝试,只有cpu不太适合
其他补充说明
1.懒人包地址如果打不开,可以试试关闭wifi,使用手机流量尝试,如果还是打不开,那就是能谷歌才能打开(已测试部分地区无法打开)
2.如果遇到多个zip文件下载,那是压缩分卷,需要下载全部的zip,然后全部一起解压缩,才会得到一个最终文件(不了解的可以查询关键词 压缩分卷)
3.打开项目优先localhost:端口,其次尝试127.0.0.1:端口,如果还是打不开,建议使用chrome等主流浏览器其他待定