2面试官最爱问的一个问题:"你们线程池参数是怎么配的?"如果你只会回答"核心线程数 = CPU 核数",那基本就凉了。线程池和连接池是 Java 开发中最基础的性能优化手段,但大多数人只是"会用",不知道怎么"用好"。本文从池化思想讲起,深入 ThreadPoolExecutor 七大参数的实战调优,再到 HikariCP 和 HTTP 连接池,帮你建立完整的池化调优能力。
一、池化思想的本质
先思考一个问题:为什么需要"池"?
没有线程池的世界:
请求来了 → 创建线程 → 处理请求 → 销毁线程
请求来了 → 创建线程 → 处理请求 → 销毁线程
...
QPS = 1000 → 每秒创建销毁 1000 个线程
创建一个线程的开销:
├── 分配线程栈内存(默认 1MB)
├── 系统调用(用户态 → 内核态切换)
├── OS 线程调度注册
└── 总耗时:约 0.1-1ms
当 QPS 很高时,"创建-销毁"本身就成了性能瓶颈。池化的核心思想:预先创建一批资源,重复利用,避免频繁创建销毁的开销。
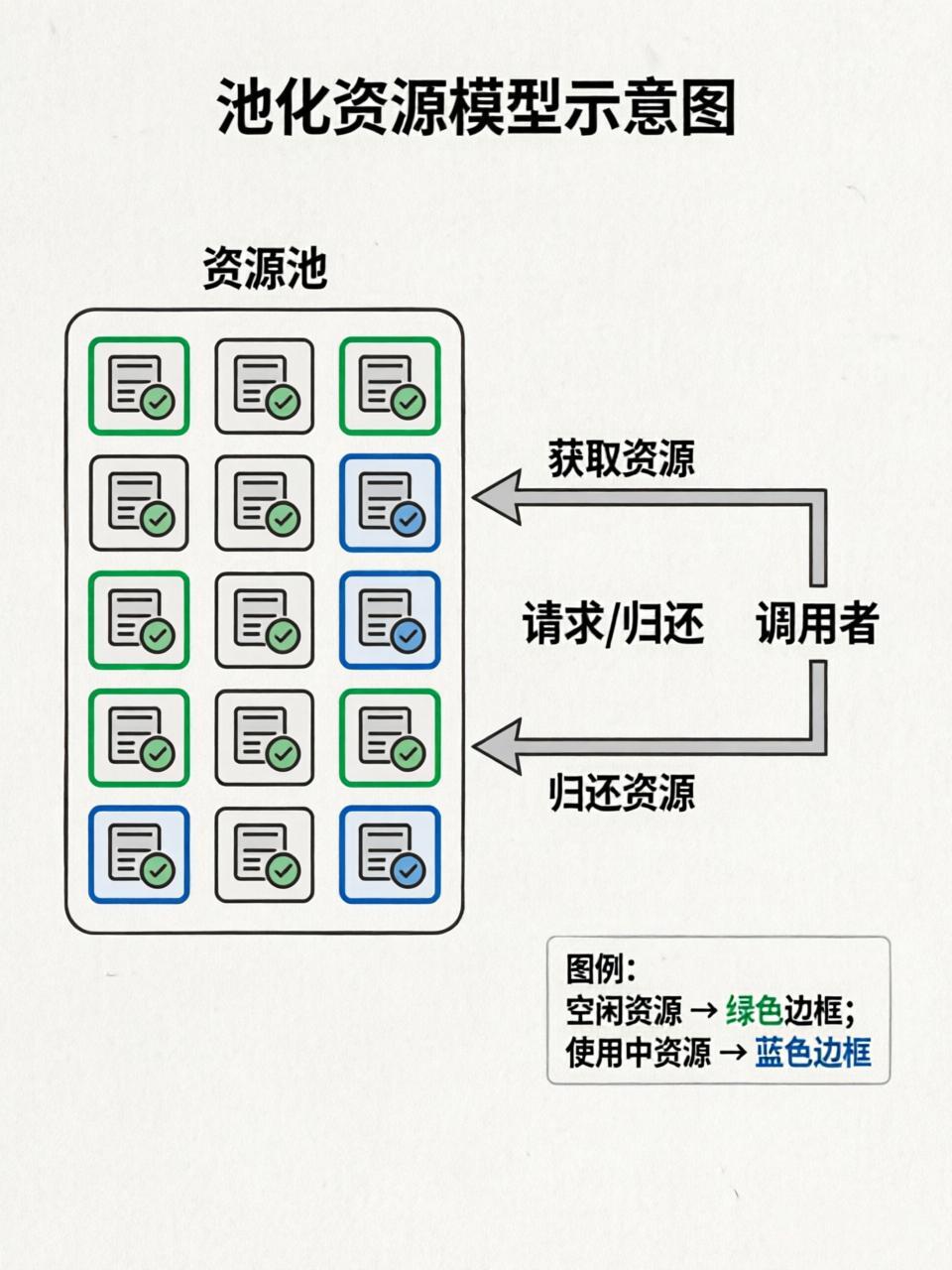
Java 里常见的池:
| 池类型 | 管理的资源 | 代表实现 |
|---|---|---|
| 线程池 | 线程 | ThreadPoolExecutor |
| 数据库连接池 | 数据库连接(TCP + 认证会话) | HikariCP, Druid |
| HTTP 连接池 | HTTP 连接(TCP + TLS) | OkHttp, Apache HttpClient |
| Redis 连接池 | Redis 连接 | Lettuce, Jedis |
| 对象池 | 重量级对象 | Apache Commons Pool |
二、ThreadPoolExecutor 七大参数
java
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 非核心线程空闲存活时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 任务队列
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略
)2.1 执行流程
这个流程必须烂熟于心:
新任务提交
│
├── 1. 当前线程数 < corePoolSize?
│ → YES:创建核心线程执行(即使有空闲核心线程!)
│ → NO:↓
│
├── 2. 任务队列未满?
│ → YES:放入队列等待
│ → NO:↓
│
├── 3. 当前线程数 < maximumPoolSize?
│ → YES:创建非核心线程执行
│ → NO:↓
│
└── 4. 执行拒绝策略
注意一个反直觉的设计:任务队列满了才会创建非核心线程。不是"核心线程忙不过来就扩容",而是"队列都放不下了才扩容"。
2.2 四种拒绝策略
| 策略 | 行为 | 适用场景 |
|---|---|---|
| AbortPolicy(默认) | 抛 RejectedExecutionException | 关键任务,必须知道被拒绝了 |
| CallerRunsPolicy | 由提交任务的线程自己执行 | 不丢失任务,但会阻塞调用线程 |
| DiscardPolicy | 默默丢弃,不抛异常 | 可丢失的任务(日志、统计) |
| DiscardOldestPolicy | 丢弃队列中最早的任务 | 新任务优先级更高的场景 |
该表格清晰地展示了四种线程池拒绝策略的行为特征和适用场景,便于开发者根据实际需求选择合适的策略。
生产环境推荐:CallerRunsPolicy 或自定义策略(记日志 + 告警 + 降级)。
java
// 自定义拒绝策略:记录日志 + 降级处理
RejectedExecutionHandler customHandler = (r, executor) -> {
log.error("线程池已满!queue size={}, active threads={}",
executor.getQueue().size(),
executor.getActiveCount());
// 告警
alertService.send("线程池拒绝任务告警");
// 降级处理(可选:放入 MQ、持久化到 DB、CallerRuns 等)
if (r instanceof RunnableWithFallback) {
((RunnableWithFallback) r).fallback();
}
};2.3 如何选择任务队列
| 队列类型 | 特点 | 适用场景 |
|---|---|---|
| LinkedBlockingQueue(n) | 有界队列,指定容量 | 推荐!大多数场景 |
| ArrayBlockingQueue(n) | 有界队列,数组实现 | 对公平性有要求的场景 |
| SynchronousQueue | 不存储元素,直接交给线程 | 任务量大、处理快的场景 |
| LinkedBlockingQueue() | 无界队列(默认 Integer.MAX_VALUE) | 几乎不该用!会导致 OOM |
java
// ❌ 危险:无界队列 → 任务堆积 → OOM
ExecutorService pool = Executors.newFixedThreadPool(10);
// 内部用的是 new LinkedBlockingQueue<>(),无界!
// ✅ 正确:显式指定有界队列
ThreadPoolExecutor pool = new ThreadPoolExecutor(
10, 20, 60, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000), // 队列容量 1000
new ThreadPoolExecutor.CallerRunsPolicy()
);所以永远不要用 Executors 的工厂方法,阿里巴巴 Java 开发手册明确禁止。
三、线程池参数调优实战
3.1 核心线程数怎么定?
教科书公式:
-
CPU 密集型:`corePoolSize = CPU 核心数 + 1`
-
IO 密集型:`corePoolSize = CPU 核心数 × 2`(或更多)
但这个公式实际很少直接用 ,因为:
(1). 大部分业务是混合型(既有计算又有 IO)
(2). 不同接口的 CPU/IO 比例不同
(3). 同一个线程池可能被多种任务共享
更实用的方法------基于 Little's Law:
期望吞吐量 = 并发线程数 / 平均响应时间
已知:
目标吞吐量 = 2000 QPS
平均响应时间 = 50ms = 0.05s
需要的线程数 = 2000 × 0.05 = 100 个
→ corePoolSize = 100
→ maximumPoolSize = 150(留 50% buffer 应对抖动)
最靠谱的方法------压测调优:
步骤:
先设一个保守值(比如 CPU 核数 × 2)
压测,观察以下指标:
线程池活跃线程数(activeCount)
队列积压数(queueSize)
任务等待时间
CPU 利用率
P99 延迟
- 根据结果调整:
队列经常有积压 → 增大 corePoolSize
CPU 利用率很低 → 可以增大线程数(说明大部分时间在等 IO)
CPU 利用率 > 80% → 减小线程数
频繁触发拒绝策略 → 增大队列容量或 maximumPoolSize
3.2 不同业务的推荐配置
java
@Configuration
public class ThreadPoolConfig {
// ========= 快速响应型(API 请求处理) =========
// 特点:响应时间要求高,不能排太长队
@Bean("apiExecutor")
public ThreadPoolExecutor apiExecutor() {
int cpuCores = Runtime.getRuntime().availableProcessors();
return new ThreadPoolExecutor(
cpuCores * 4, // 核心线程多一些,快速响应
cpuCores * 8,
60, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(500), // 队列不要太大,宁可拒绝也不要等太久
new ThreadFactoryBuilder().setNameFormat("api-pool-%d").build(),
new ThreadPoolExecutor.CallerRunsPolicy()
);
}
// ========= IO 密集型(数据库/外部服务调用) =========
// 特点:大部分时间在等 IO,需要更多线程
@Bean("ioExecutor")
public ThreadPoolExecutor ioExecutor() {
int cpuCores = Runtime.getRuntime().availableProcessors();
return new ThreadPoolExecutor(
cpuCores * 10, // IO 密集,线程可以多
cpuCores * 20,
120, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(2000),
new ThreadFactoryBuilder().setNameFormat("io-pool-%d").build(),
new ThreadPoolExecutor.CallerRunsPolicy()
);
}
// ========= CPU 密集型(计算/加密/压缩) =========
// 特点:CPU 是瓶颈,线程太多反而增加上下文切换开销
@Bean("cpuExecutor")
public ThreadPoolExecutor cpuExecutor() {
int cpuCores = Runtime.getRuntime().availableProcessors();
return new ThreadPoolExecutor(
cpuCores + 1, // CPU 密集,线程不要太多
cpuCores * 2,
60, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000),
new ThreadFactoryBuilder().setNameFormat("cpu-pool-%d").build(),
new ThreadPoolExecutor.AbortPolicy()
);
}
}3.3 线程池监控
配置好了不代表不用管。生产环境必须监控:
java
@Component
public class ThreadPoolMonitor {
@Autowired
@Qualifier("apiExecutor")
private ThreadPoolExecutor apiExecutor;
// 暴露到 Prometheus
@Scheduled(fixedRate = 10000)
public void reportMetrics() {
Metrics.gauge("threadpool.api.active", apiExecutor.getActiveCount());
Metrics.gauge("threadpool.api.pool_size", apiExecutor.getPoolSize());
Metrics.gauge("threadpool.api.queue_size", apiExecutor.getQueue().size());
Metrics.gauge("threadpool.api.completed", apiExecutor.getCompletedTaskCount());
Metrics.gauge("threadpool.api.rejected",
((CustomRejectedHandler) apiExecutor.getRejectedExecutionHandler())
.getRejectedCount());
}
// 关键告警规则:
// 1. 队列使用率 > 80% → 预警
// 2. 活跃线程数 = 最大线程数 → 告警
// 3. 拒绝次数 > 0 → 紧急告警
}3.4 动态线程池
参数不一定要写死。线程池支持运行时动态调整:
java
// ThreadPoolExecutor 提供了 setter 方法
executor.setCorePoolSize(newCoreSize);
executor.setMaximumPoolSize(newMaxSize);
// 结合配置中心(Nacos/Apollo)实现动态调参
@NacosValue(value = "${thread.pool.core-size:10}", autoRefreshed = true)
private int coreSize;
@NacosConfigListener(dataId = "thread-pool-config")
public void onConfigChange(String config) {
// 解析新配置
int newCoreSize = parseConfig(config, "coreSize");
int newMaxSize = parseConfig(config, "maxSize");
// 动态调整(注意:maxSize 必须 >= coreSize)
if (newMaxSize >= newCoreSize) {
executor.setMaximumPoolSize(newMaxSize);
executor.setCorePoolSize(newCoreSize);
log.info("线程池参数已更新: core={}, max={}", newCoreSize, newMaxSize);
}
}美团开源的 DynamicTp就是这个思路的完善实现,集成了配置中心、监控告警和动态调参。
四、数据库连接池调优(HikariCP)
4.1 为什么 HikariCP 最快?
Spring Boot 2.x 默认数据库连接池就是 HikariCP(光)。它的性能碾压 Druid、C3P0、DBCP:
对比表格:HikariCP vs Druid vs C3P0
| 特性 | HikariCP | Druid | C3P0 |
|---|---|---|---|
| 获取连接耗时 | 极低(纳秒级) | 微秒级 | 毫秒级 |
| 字节码精简 | 编译后仅 130KB | 数 MB | 数 MB |
| ConcurrentBag | 自研无锁并发容器 | 基于 Lock | 基于 Lock |
| 连接状态追踪 | CAS 操作 | synchronized | synchronized |
| 监控功能 | 基础 | 极强(SQL 监控/防注入) | 弱 |
特性分析
(1)HikariCP
- 高性能设计,连接获取耗时极低
- 轻量级,字节码精简
- 采用无锁并发机制提升效率
(2)Druid
- 提供强大的监控和防注入功能
- 连接管理基于传统锁机制
- 功能全面但体积较大
(3)C3P0
- 连接获取效率较低
- 功能相对简单
- 适用于基础场景
HikariCP 快的核心原因:
1)ConcurrentBag :借鉴了 .NET 的 ConcurrentBag,用 ThreadLocal + CAS 实现近乎无锁的连接获取
2)FastList :替代 ArrayList,省掉 range check 和 size 判断
3)字节码精简:做了大量无用代码删减,减少类加载和 JIT 编译开销
4.2 HikariCP 核心参数
java
spring:
datasource:
hikari:
# ======== 连接数配置 ========
minimum-idle: 10 # 最小空闲连接数
maximum-pool-size: 20 # 最大连接数(最重要的参数!)
# ======== 超时配置 ========
connection-timeout: 3000 # 获取连接超时(ms),默认 30s 太长了
idle-timeout: 600000 # 空闲连接超时(ms),10 分钟
max-lifetime: 1800000 # 连接最大存活时间(ms),30 分钟
validation-timeout: 3000 # 验证连接超时
# ======== 其他 ========
pool-name: HikariPool-Master # 连接池名字(监控用)
leak-detection-threshold: 60000 # 连接泄漏检测阈值,60s4.3 maximum-pool-size 怎么定?
HikariCP 官方的公式:
connections = ((core_count * 2) + effective_spindle_count)
core_count = CPU 核心数
effective_spindle_count = 磁盘数(SSD 算 1)
例如:4 核 CPU + SSD → connections = 4 * 2 + 1 = 9
大部分情况下 10-20 就够了。很多人设成 100、200,其实完全没必要,反而有害:
为什么连接数不是越大越好?
MySQL 处理连接也要消耗资源:
每个连接占用一个线程(或线程池中的一个工作线程)
每个连接消耗内存(sort_buffer, join_buffer 等)
连接越多,锁争用越严重
上下文切换开销越大
实测数据(来自 HikariCP 官方 wiki):
线程池 50 → TPS 约 10000
线程池 100 → TPS 约 10000(没变!)
线程池 200 → TPS 约 8000(反而降了!上下文切换开销增加)
结论:宁少勿多,10-20 足以支撑大多数业务
4.4 连接泄漏排查
连接泄漏 = 借了连接不还。表现:连接池耗尽,新请求获取不到连接。
java
// 常见泄漏场景
// ❌ 场景一:手动获取连接但没关
Connection conn = dataSource.getConnection();
Statement stmt = conn.createStatement();
stmt.execute("SELECT 1");
// 忘了 conn.close()!
// ✅ 修复:try-with-resources
try (Connection conn = dataSource.getConnection();
Statement stmt = conn.createStatement()) {
stmt.execute("SELECT 1");
} // 自动关闭
// ❌ 场景二:事务异常后连接没释放
@Transactional
public void transfer() {
// 方法内部抛出了非 RuntimeException
// @Transactional 默认只回滚 RuntimeException
// 如果抛 checked exception 且没被正确处理,连接可能不会释放
throw new IOException("文件错误");
}
// ✅ 修复:@Transactional(rollbackFor = Exception.class)HikariCP 的连接泄漏检测:
java
spring:
datasource:
hikari:
leak-detection-threshold: 60000 # 连接被借出 60 秒还没归还,打印堆栈开启后泄漏时会打印完整堆栈,直接定位到是哪行代码借的连接:
java
WARN com.zaxxer.hikari.pool.ProxyLeakTask -
Connection leak detection triggered for com.mysql.cj.jdbc.ConnectionImpl@xxxx,
stack trace follows
java.lang.Exception: Apparent connection leak detected
at com.example.UserService.queryUser(UserService.java:42)五、HTTP 连接池调优
5.1 为什么 HTTP 也需要连接池?
不用连接池(短连接):
每次请求 → TCP 三次握手 → TLS 握手(HTTPS 额外 1-2 RTT)→ 发送请求 → 接收响应 → TCP 四次挥手
每次请求额外开销:5-50ms(取决于网络延迟和是否 HTTPS)
用连接池(长连接/Keep-Alive):
首次 → TCP 握手 + TLS 握手 → 发送请求 → 接收响应
后续 → 发送请求 → 接收响应(直接复用连接,省掉握手开销)
5.2 OkHttp 连接池配置
java
@Configuration
public class OkHttpConfig {
@Bean
public OkHttpClient okHttpClient() {
// 连接池:最大空闲连接 50,空闲 5 分钟后关闭
ConnectionPool pool = new ConnectionPool(50, 5, TimeUnit.MINUTES);
return new OkHttpClient.Builder()
.connectionPool(pool)
.connectTimeout(3, TimeUnit.SECONDS) // 连接超时
.readTimeout(10, TimeUnit.SECONDS) // 读超时
.writeTimeout(10, TimeUnit.SECONDS) // 写超时
.retryOnConnectionFailure(true) // 连接失败自动重试
.build();
}
}5.3 Apache HttpClient 连接池配置
java
@Configuration
public class HttpClientConfig {
@Bean
public CloseableHttpClient httpClient() {
// 连接池管理器
PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager();
cm.setMaxTotal(200); // 最大总连接数
cm.setDefaultMaxPerRoute(50); // 每个路由(host)最大连接数
// 对特定服务设置更大的连接数
cm.setMaxPerRoute(
new HttpRoute(new HttpHost("core-service", 8080)),
100 // 核心服务允许更多连接
);
// 请求配置
RequestConfig requestConfig = RequestConfig.custom()
.setConnectTimeout(3000) // 建立连接超时
.setSocketTimeout(10000) // 数据传输超时
.setConnectionRequestTimeout(2000) // 从连接池获取连接超时
.build();
return HttpClients.custom()
.setConnectionManager(cm)
.setDefaultRequestConfig(requestConfig)
.setKeepAliveStrategy((response, context) -> 30_000) // Keep-Alive 30s
.evictIdleConnections(60, TimeUnit.SECONDS) // 清理空闲超过 60s 的连接
.build();
}
}关键参数------DefaultMaxPerRoute:
假设你的服务要调用 3 个下游:
用户服务(高频)
订单服务(高频)
通知服务(低频)
MaxTotal = 200, DefaultMaxPerRoute = 50
含义:
到用户服务最多 50 个连接
到订单服务最多 50 个连接
到通知服务最多 50 个连接
总共不超过 200 个连接
如果用户服务流量大,可以单独设置 MaxPerRoute = 100
六、生产环境踩坑与调优
6.1 线程池的坑
| 坑 | 原因 | 解决方案 |
|---|---|---|
用 Executors.newFixedThreadPool 导致 OOM |
内部用无界队列 LinkedBlockingQueue() |
手动创建 ThreadPoolExecutor,指定有界队列 |
用 Executors.newCachedThreadPool 导致 CPU 飙升 |
maximumPoolSize = Integer.MAX_VALUE,疯狂创线程 |
手动创建,设合理的 maximumPoolSize |
| 线程池里的异常被吞了 | Future 没调 get(),异常就丢了 |
用 submit + get(),或在 Runnable 内部 try-catch |
| 优雅关闭丢任务 | 直接 shutdownNow() |
先 shutdown(),等待超时后再 shutdownNow() |
| 不同业务共用线程池 | 慢任务占满线程,快任务也被阻塞 | 不同业务用不同线程池隔离 |
java
// 优雅关闭线程池
@PreDestroy
public void shutdown() {
executor.shutdown(); // 不再接受新任务
try {
// 等待已提交的任务完成
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
log.warn("线程池未能在 60s 内关闭,强制关闭");
executor.shutdownNow();
}
} catch (InterruptedException e) {
executor.shutdownNow();
Thread.currentThread().interrupt();
}
}6.2 连接池的坑
| 坑 | 原因 | 解决方案 |
|---|---|---|
| 获取连接超时 | 连接池太小或连接泄漏 | 增大 pool size + 开启泄漏检测 |
| 连接被 MySQL 断开 | MySQL 默认 wait_timeout=8h,连接空闲超时被踢 | 设 max-lifetime < MySQL wait_timeout |
| 连接池没回收空闲连接 | idle-timeout 没生效 | 确保 idle-timeout < max-lifetime |
| Druid 监控 SQL 拖慢性能 | Druid 的 Filter 链有开销 | 生产环境关闭不必要的 Filter |
java
# 重要:max-lifetime 必须小于 MySQL 的 wait_timeout
# MySQL 默认 wait_timeout = 28800(8小时)
# HikariCP 建议 max-lifetime = 1800000(30分钟)
spring:
datasource:
hikari:
max-lifetime: 1800000 # 30 分钟,远小于 MySQL 的 8 小时
idle-timeout: 600000 # 10 分钟6.3 Spring Boot 内置 Tomcat 线程池调优
别忘了 Tomcat 也有自己的线程池:
java
server:
tomcat:
threads:
min-spare: 20 # 最小空闲线程(= corePoolSize)
max: 200 # 最大线程数(= maximumPoolSize)
max-connections: 10000 # 最大连接数(NIO 模式下连接数可以远大于线程数)
accept-count: 100 # 等待队列长度(全满后拒绝新连接)
connection-timeout: 5000 # 连接超时Tomcat 线程池 vs 业务线程池:
用户请求 → Tomcat 线程池(处理 HTTP 协议)
│
├── 同步调用:Tomcat 线程直接执行业务逻辑
│ 一个请求占一个 Tomcat 线程直到结束
│
└── 异步调用:Tomcat 线程只负责接收请求
业务逻辑交给自定义线程池
Tomcat 线程立即释放去接新请求
结论:如果所有接口都是同步的,Tomcat max-threads 就是你的并发上限
如果用了 @Async 或 WebFlux,Tomcat 线程可以更少
七、面试高频问题
Q1:线程池的核心参数有哪些?执行流程是什么?
> ThreadPoolExecutor 有七个核心参数。执行流程是:新任务提交时,先看核心线程数是否已满,没满就创建核心线程执行;核心线程满了就放入任务队列;队列也满了才创建非核心线程;非核心线程也满了就执行拒绝策略。注意一个关键点:是队列满了才扩容线程,而不是核心线程忙了就扩容。
Q2:线程池大小怎么设置?
> 分三个层次回答。理论上,CPU 密集型设 N+1,IO 密集型设 2N。实际上用 Little's Law 计算:线程数 = 目标吞吐量 × 平均响应时间。最靠谱的是压测------先设保守值,压测观察 CPU 利用率、队列积压、P99 延迟,迭代调优。我们生产环境还用了动态线程池(基于 Nacos),可以不重启调整参数。
Q3:为什么不推荐 Executors 创建线程池?
> Executors.newFixedThreadPool 用的是无界队列 LinkedBlockingQueue,任务堆积会导致 OOM。Executors.newCachedThreadPool 的 maximumPoolSize 是 Integer.MAX_VALUE,可能创建大量线程耗尽系统资源。应该用 ThreadPoolExecutor 手动创建,显式指定有界队列和合理的最大线程数,同时设置有意义的线程名方便排查问题。
Q4:HikariCP 为什么比 Druid 快?
> 三个核心原因。一是 ConcurrentBag 无锁并发容器,用 ThreadLocal + CAS 实现连接获取,避免了 synchronized。二是 FastList 替代 ArrayList,省掉了无用的 range check。三是字节码极度精简,编译后才 130KB,减少类加载和 JIT 编译开销。不过 Druid 在 SQL 监控、防注入方面更强,选型时要看侧重点。
Q5:数据库连接池大小怎么设?为什么不是越大越好?
> HikariCP 官方公式是 connections = core_count × 2 + spindle_count,通常 10-20 就够了。连接数不是越大越好,因为 MySQL 每个连接都要消耗线程和内存,连接多了锁争用和上下文切换开销反而会降低吞吐量。实测数据显示连接池从 50 增加到 200,TPS 不升反降。核心原则是"宁少勿多",让每个连接尽量保持忙碌。
总结
池化调优核心要点
-
核心思想
- 预创建 + 复用:核心在于避免频繁创建和销毁对象带来的性能开销。
-
线程池配置
- 创建方式:推荐手动创建,避免使用Executors工具类。
- 队列选择:必须使用有界队列,防止内存溢出。
- 拒绝策略:建议使用CallerRunsPolicy,让调用线程自己执行任务,起到背压作用。
-
参数设定
- 设定流程:优先通过压测确定参数,其次参考利特尔法则(Little's Law),最后可参考CPU核数公式进行估算。
-
隔离策略
- 业务隔离:不同业务场景应使用独立的线程池,避免相互影响。
-
连接池配置
- HikariCP:通常配置10-20个连接数已足够。
- 生命周期 :
max-lifetime应设置得比MySQL的wait_timeout更短。
-
HTTP连接池
- 选型:推荐使用OkHttp或Apache HttpClient。
- 配置 :特别注意
MaxPerRoute(单路由最大连接数)的设置。
-
监控告警
- 核心指标:监控活跃线程数、队列积压情况和任务拒绝次数。
- 工具:通过Prometheus收集指标并配置告警。
-
动态调整
- 配置中心:结合配置中心,实现参数的运行时动态调整。
池化看似简单,但参数调优的功力决定了你是"会用"还是"用好"。记住三个原则:**有界队列防 OOM、压测定参别拍脑袋、监控告警早发现**。
光看不练假把式。线程池参数、HikariCP 调优、连接池排查这些话题,面试官一定会追着问细节。推荐用 面霸(AI 模拟面试平台)实战模拟几轮,AI 面试官会根据你的回答深度追问"你们线程池参数是怎么定的""连接泄漏怎么排查"这类问题,练到能自然表达出来才算真会。
体验地址:**http://106.12.14.47:8090/\*\*
> 懒得注册?直接用测试账号体验:
> - 手机号:`18088889999`
> - 密码:`test123#$qaz`
*觉得有帮助的话,点赞收藏不迷路。有问题评论区见。*