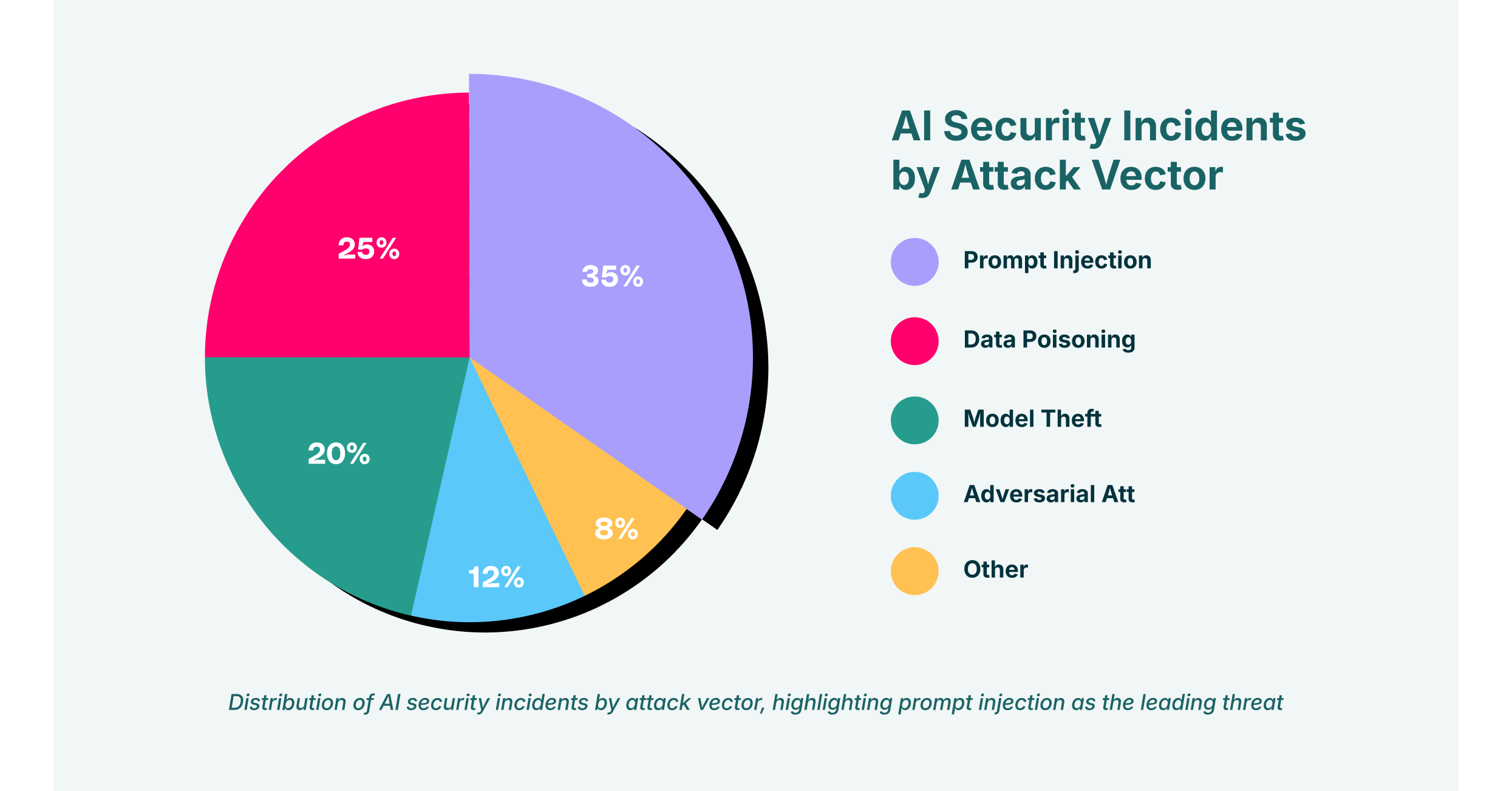
OpenAI正式启动公共Safety Bug Bounty (安全漏洞赏金计划),旨在鼓励全球研究人员识别其产品中存在的AI滥用行为 和安全风险。该计划托管于Bugcrowd 平台,是对现有Security Bug Bounty的重要补充,专门处理那些虽不符合传统安全漏洞定义、但具有现实危害潜力的报告。
此举标志着OpenAI在应对AI特有威胁方面迈出关键一步------传统安全框架已难以覆盖新兴的AI攻击面。
计划核心机制
Safety Bug Bounty与Security Bug Bounty并行运行,所有提交报告将由OpenAI的安全与赏金团队共同评估,并根据范围和归属在两个计划间灵活流转。研究人员可通过Bugcrowd上的OpenAI Safety Bug Bounty页面直接提交。
该计划重点奖励那些可能导致实质性滥用或安全风险的设计或实现问题,而非一般性内容策略绕过。
重点关注的AI特有风险类别
OpenAI明确列出以下高优先级场景:
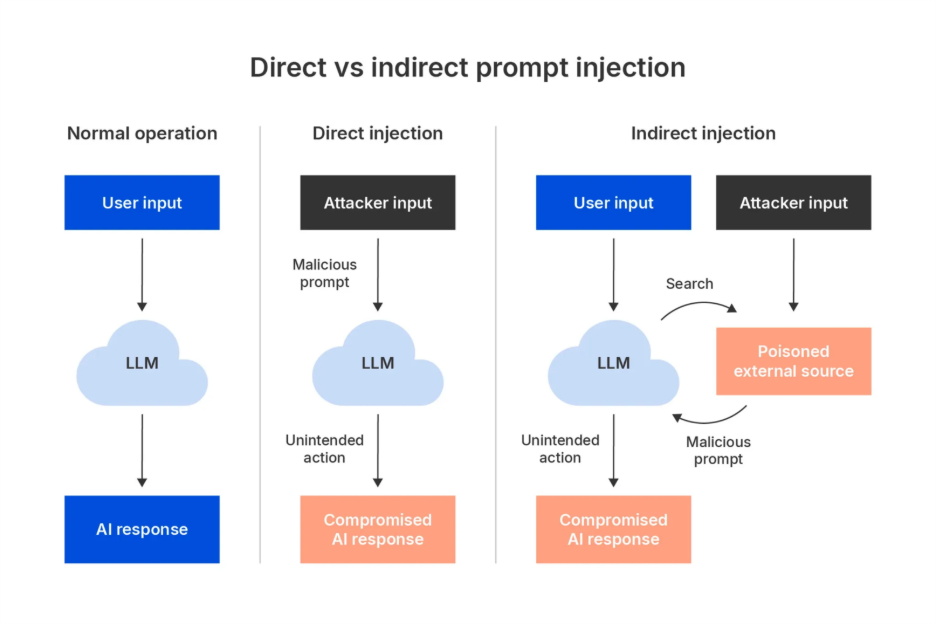
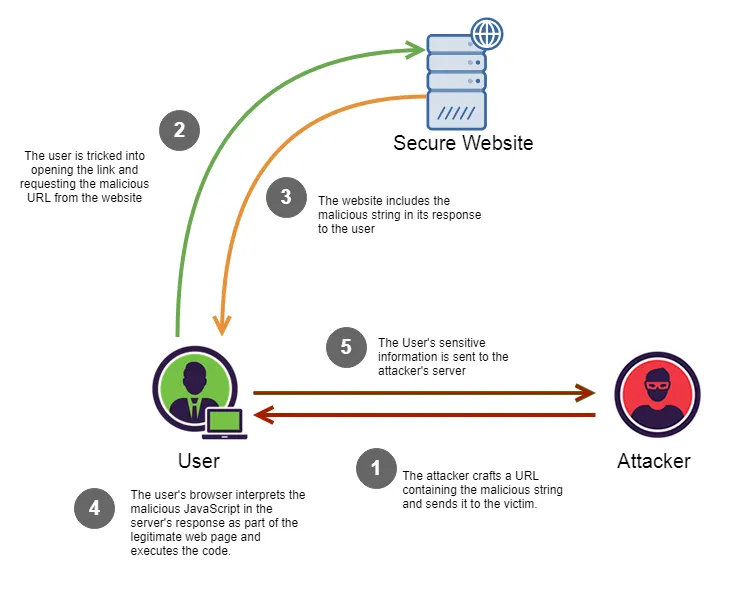
- Agentic风险(包含MCP) :第三方提示注入(prompt injection)和数据外泄场景。攻击者控制的文本需在至少50%复现率下可靠劫持受害者AI Agent(包括浏览器代理、ChatGPT Agent等),执行有害操作或泄露敏感用户数据。还包括Agentic产品大规模执行禁止或潜在有害行为的情况。
- OpenAI专有信息泄露:模型无意中暴露推理相关专有信息,或泄露其他机密数据。
- 账户与平台完整性:绕过反自动化控制、操纵信任信号、规避账户限制/暂停/封禁等弱点。
不在范围内的内容:
- 仅导致粗俗语言或公开可用信息的一般越狱(jailbreak);
- 没有明显安全或滥用影响的通用内容策略绕过。
OpenAI会不定期开展针对特定危害(如生物风险内容)的私密赏金活动,并在开放时邀请研究人员参与。对于可实现未经授权访问功能、数据或超出权限的传统漏洞,仍应提交至现有Security Bug Bounty计划。
行业意义与参与方式
OpenAI Safety Bug Bounty的推出,体现了业界对AI全新攻击面的重视:Agentic AI 、提示注入 和数据外泄等风险正成为主流威胁。该计划通过激励安全研究社区,建立起针对AI特有威胁的结构化响应框架,与传统漏洞披露形成互补。
有意参与的研究人员可直接访问Bugcrowd上的OpenAI Safety Bug Bounty页面提交申请。OpenAI鼓励伦理黑客和AI安全研究者积极贡献,共同构建更安全的AI生态。