多模态记忆:让 AI Agent 记忆各种类型的信息
前言
多模态记忆是指让 AI Agent 能够记忆和理解多种类型的信息,包括文本、图像、音频等。这能显著提升 Agent 的能力。
我在多个项目中实现过多模态记忆,今天分享一些设计和实现。
记忆项设计
python
from dataclasses import dataclass, field
from typing import Dict, Any, Optional, List
from enum import Enum
import hashlib
import time
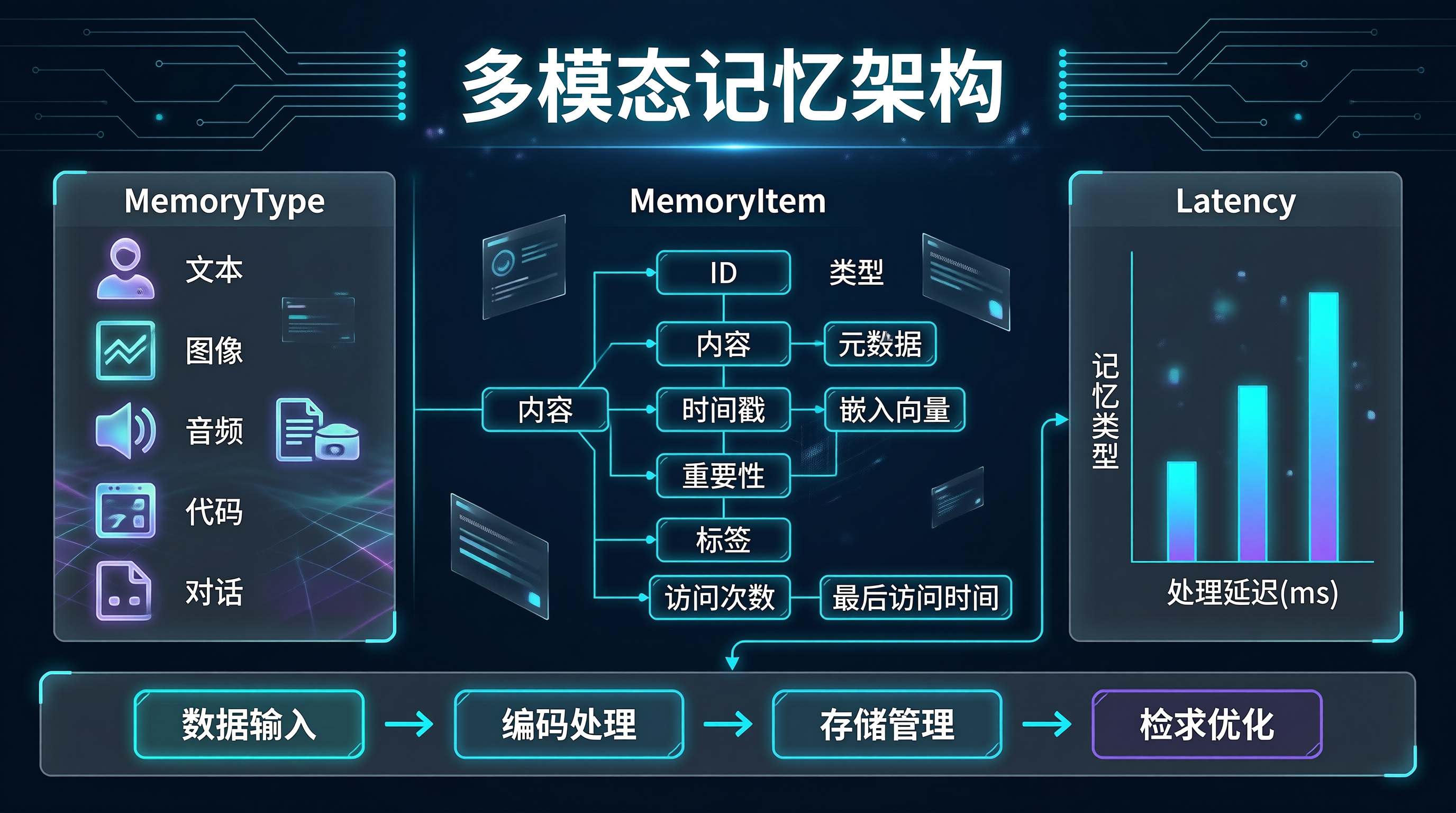
class MemoryType(Enum):
"""记忆类型"""
TEXT = "text"
IMAGE = "image"
AUDIO = "audio"
DOCUMENT = "document"
CODE = "code"
DIALOGUE = "dialogue"
@dataclass
class MemoryItem:
"""记忆项"""
id: str
type: MemoryType
content: Any
metadata: Dict[str, Any] = field(default_factory=dict)
embedding: Optional[List[float]] = None
timestamp: float = field(default_factory=time.time)
importance: float = 1.0
tags: List[str] = field(default_factory=list)
access_count: int = 0
last_access: Optional[float] = None
def generate_id(self):
"""生成唯一 ID"""
content_str = str(self.content)
return hashlib.md5((content_str + str(self.timestamp)).encode()).hexdigest()
def to_dict(self) -> Dict[str, Any]:
"""转换为字典"""
return {
"id": self.id,
"type": self.type.value,
"content": self.content,
"metadata": self.metadata,
"embedding": self.embedding,
"timestamp": self.timestamp,
"importance": self.importance,
"tags": self.tags,
"access_count": self.access_count,
"last_access": self.last_access
}多模态 Embedding
python
from typing import List, Any
class MultimodalEmbedder:
"""多模态 Embedding 生成器"""
def __init__(self):
# 这里应该加载实际的模型
self.text_model = None # 文本模型
self.image_model = None # 图像模型
def embed_text(self, text: str) -> List[float]:
"""文本 Embedding"""
# 实际实现应该调用真实模型
return [0.0] * 768 # 示例
def embed_image(self, image_data: bytes) -> List[float]:
"""图像 Embedding"""
# 实际实现应该调用真实模型
return [0.0] * 768 # 示例
def embed(self, memory: MemoryItem) -> List[float]:
"""通用 Embedding"""
if memory.type == MemoryType.TEXT:
return self.embed_text(str(memory.content))
elif memory.type == MemoryType.IMAGE:
return self.embed_image(memory.content)
else:
# 其他类型转为文本处理
return self.embed_text(str(memory.content))记忆存储
python
from typing import List, Dict, Any, Optional
import faiss
import numpy as np
class MemoryStore:
"""记忆存储"""
def __init__(self, dimension: int = 768):
self.dimension = dimension
self.memories: Dict[str, MemoryItem] = {}
self.index: Optional[faiss.Index] = None
self.embeddings: List[List[float]] = []
self.id_map: List[str] = []
self.embedder = MultimodalEmbedder()
def add(self, memory: MemoryItem):
"""添加记忆"""
if not memory.id:
memory.id = memory.generate_id()
# 生成 Embedding
if not memory.embedding:
memory.embedding = self.embedder.embed(memory)
# 存储
self.memories[memory.id] = memory
self.embeddings.append(memory.embedding)
self.id_map.append(memory.id)
# 重建索引
self._rebuild_index()
def add_batch(self, memories: List[MemoryItem]):
"""批量添加"""
for memory in memories:
self.add(memory)
def _rebuild_index(self):
"""重建索引"""
if not self.embeddings:
self.index = None
return
vectors = np.array(self.embeddings).astype(np.float32)
self.index = faiss.IndexFlatL2(self.dimension)
self.index.add(vectors)
def retrieve(self, query: Any, top_k: int = 5) -> List[MemoryItem]:
"""检索相关记忆"""
# 将查询转为 embedding
if isinstance(query, str):
query_emb = self.embedder.embed_text(query)
else:
# 处理其他类型
query_emb = [0.0] * self.dimension
# 搜索
query_vec = np.array([query_emb]).astype(np.float32)
if self.index is None:
return []
scores, indices = self.index.search(query_vec, min(top_k, len(self.id_map)))
# 获取结果
results = []
for idx in indices[0]:
if idx >= 0 and idx < len(self.id_map):
memory_id = self.id_map[idx]
memory = self.memories[memory_id]
memory.access_count += 1
memory.last_access = time.time()
results.append(memory)
return results记忆组织
python
from typing import List
from collections import defaultdict
class MemoryOrganizer:
"""记忆组织者"""
def __init__(self, store: MemoryStore):
self.store = store
def get_by_type(self, mem_type: MemoryType) -> List[MemoryItem]:
"""按类型获取"""
return [
mem for mem in self.store.memories.values()
if mem.type == mem_type
]
def get_by_tag(self, tag: str) -> List[MemoryItem]:
"""按标签获取"""
return [
mem for mem in self.store.memories.values()
if tag in mem.tags
]
def get_recent(self, limit: int = 10) -> List[MemoryItem]:
"""获取最近的记忆"""
sorted_memories = sorted(
self.store.memories.values(),
key=lambda m: m.timestamp,
reverse=True
)
return sorted_memories[:limit]
def get_important(self, limit: int = 10) -> List[MemoryItem]:
"""获取重要的记忆"""
sorted_memories = sorted(
self.store.memories.values(),
key=lambda m: m.importance,
reverse=True
)
return sorted_memories[:limit]完整记忆系统
python
class MultimodalMemorySystem:
"""多模态记忆系统"""
def __init__(self):
self.store = MemoryStore()
self.organizer = MemoryOrganizer(self.store)
def add_memory(self, content: Any, mem_type: MemoryType,
metadata: Dict = None, tags: List[str] = None):
"""添加记忆"""
memory = MemoryItem(
id="",
type=mem_type,
content=content,
metadata=metadata or {},
tags=tags or []
)
self.store.add(memory)
return memory
def recall(self, query: str, top_k: int = 5) -> List[MemoryItem]:
"""回忆相关记忆"""
return self.store.retrieve(query, top_k)
def get_recent_history(self, limit: int = 20) -> List[MemoryItem]:
"""获取最近的历史"""
return self.organizer.get_recent(limit)总结
多模态记忆要点:
- 记忆表示:多类型统一表示
- 嵌入生成:多模态 Embedding
- 存储检索:高效存储和检索
- 组织管理:按类型、标签等组织
- 生命周期:重要性评估和老化
实践建议:
- 从文本记忆开始
- 逐步支持更多模态
- 设计合理的重要性评估
- 考虑记忆清理策略