从今天开始,雷欧将和大家一起学习大模型应用开发。我们不搞基础,不搞虚的,只搞最重要的知识来学习。
今天,我们要学习的是Transformer架构!!当然,底层机理,包括代码实现,并不需要我们知道,那么,我们需要学会什么呢?咱接着往下看......
首先,简单介绍一下什么是Transformer,Transformer是一种基于纯注意力机制的神经网络架构,由谷歌在2017年提出,最初用于机器翻译任务,现在已成为NLP和CV领域的基础架构。
1.Transformer整体架构
Transformer采用Encoder-Decoder结构,但与传统的RNN序列到序列模型不同,它完全依赖注意力机制来捕获序列中的全局依赖关系。
这话读完,OK,傻眼了,不急雷欧来慢慢和大家拆解:
首先就是这个Encoder-Decoder结构,这玩意是啥呢,从字面上看,翻译成中文那不就是编码器和解码器嘛,大家可以想象成翻译员的工作,Encoder就负责听和理解句子,Decoder就负责翻译车工目标语言,例如:
你好(中文)->Encoder理解句子含义->Decoder->Hello(英文)
好,现在知道了Encoder和Decoder,继续往后看,这RNN又是个啥?RNN学名叫循环神经网络,有的小伙伴就要问了,哎,雷欧,这啥东西啊。其实,你不需要知道他是啥东西,你只需要知道它是干啥的,它是顺序的处理一句话的,比如他喜欢学习,这句话使用RNN就需要先处理他,处理完才能处理喜欢,最后处理学习,必须按照顺序一个一个的处理。
咱都是搞开发的,顺序执行往往就和效率挂钩,而且,针对大模型来说,我要是有1万个他喜欢学习,你能保证当他处理到第500个他喜欢学习的时候,前面的信息它还记得吗,使用RNN可无法保证。
简单来说,就一句话,Encoder-Decoder结构能解决传统RNN顺序处理文字,当文字过长而导致的信息丢失问题。
下一个问题又来了,注意力又是个什么玩意啊?注意力其实就像一个全局审视。
Encoder-> 他在学习
注意力-> 让学习能同时看到他和在
Decoder-> 根据他和在来翻译学习
总结成三个词就是看全文,抓重点,记得牢。
通俗解释完成,下来仔细拆解拆解。
2.Encoder编码器
Encoder由 N个相同的层(默认N=6) 堆叠而成,每层包含两个子层:
- 多头自注意力机制(Multi-Head Self-Attention)
- 前馈神经网络(Feed-Forward Neural Network)
每个子层都采用残差连接(Residual Connection) 和 层归一化(Layer Normalization),即:
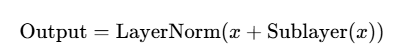
Encoder工作流程:
- 输入序列(如原始句子)首先转换为词嵌入(Word Embedding),并加上位置编码。
- 通过多头自注意力机制,每个词可以关注序列中的所有其他词,捕获词与词之间的依赖关系。
- 前馈神经网络对每个词的表示进行非线性变换。
- 数据流:词嵌入(Embedding) → 位置编码(Positional Encoding)→ 多头注意力(Multi-Head Attention) → 残差连接与层归一化(Add & Norm)→ 前馈神经网络(FFN) → 残差连接与层归一化(Add & Norm)→ 输出
我敢保证,上面这一段读完,很多欧迷都是懵逼状态,根本不懂这是啥,咱们慢慢学习
首先我们先来整体理解一下Encoder是干什么的,之前我们说过,它是倾听者,转换到计算机上来说就是它的作用就是将输入的句子进行理解,消化成计算机能处理的知识
就像我们读书时理解一段文字的过程:
- 第一遍读:大概了解
- 第二遍读:深入理解
- ...
- 第六遍读:完全吃透
Transformer 的 Encoder 就是这样层层叠加理解,默认 6 层,可以更多或更少。
接下来是每一层的的两个工具:
|------------|--------|---------------------|
| 多头自注意力 | "全局审视" | 让每个词看看句子中其他所有词,找出关联 |
| 前馈神经网络 | "深度思考" | 对每个词进行独立的消化、提炼 |
多头自注意力(Multi-Head Self-Attention)
作用:让每个词"看到"句子中的所有其他词
"多头"的意思:从不同角度同时看问题
| 角度(头) | 关注重点 |
|---|---|
| 头1 | 语法结构(主语、谓语) |
| 头2 | 语义关联(谁做什么) |
| 头3 | 位置关系(在哪、什么时候) |
| ... | ... |
8个"头"同时工作,综合起来理解更全面!
前馈神经网络(FFN)
作用:对每个词进行"深度加工"
比喻:
- 多头注意力像"广泛收集信息"
- 前馈神经网络像"深入思考提炼"
- 残差连接 + 层归一化(Add & Norm)
比喻:每层加了"保险"
| 机制 | 作用 | 比喻 |
|---|---|---|
| 残差连接 | 保留原始信息,防止梯度消失 | 做题时保留草稿,方便检查 |
| 层归一化 | 稳定训练,加速收敛 | 考试前调整心态,保持平稳 |
一句话总结:
Encoder 就像一个阅读理解高手 ,读6遍书,每遍用8个角度同时理解,最后把句子消化成高质量的知识向量
3.Decoder解码器
Decoder同样由 N个相同的层 堆叠而成,但每层包含三个子层:
- 多头自注意力(Masked Multi-Head Self-Attention)
- 编码器-解码器注意力(Encoder-Decoder Attention)
- 前馈神经网络
关键机制:
- 掩码多头注意力(Masked Multi-Head Attention):在训练时,遮挡未来位置的 token,防止信息泄露。
- Encoder-Decoder Attention:Query 来自前一个 Decoder 层,Key 和 Value 来自 Encoder 的输出,使 Decoder 能关注输入序列的相关部分。
Decoder工作流程:
- 输入已生成的词(训练时为目标序列,推理时逐步生成)。
- 通过 Masked Multi-Head Attention 防止看到未来信息。
- 与 Encoder 的输出进行交互(Encoder-Decoder Attention)。
- 最后通过线性层和 Softmax 生成下一个词的预测概率。
简单解释一下:
Decoder 就像一个翻译员,边写边猜下一个词。每次猜的时候:
- 只看自己已经写好的部分(掩码注意力)
- 随时参考原文意思(Encoder-Decoder Attention)
- 选一个概率最高的词写下来
4.注意力机制
注意力机制的核心是 缩放点积注意力(Scaled Dot-Product Attention):
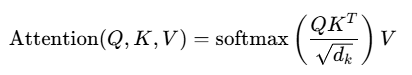
- Q(Query):查询向量,表示当前 token 想关注什么。
- K(Key):键向量,表示每个 token 能提供的信息。
- V(Value):值向量,表示实际要传递的信息。
- 缩放因子:防止点积结果过大导致梯度消失。
总结:
注意力机制就像一个检索系统:
- Q = 你想问的问题
- K = 信息的标签/索引
- V = 信息的详细内容
通过比较 Q 和 K 的相似度,找出最相关的信息(V),然后"关注"它。
5.多头注意力
多头注意力通过并行运行多个注意力头,让模型关注不同位置的不同表示子空间:
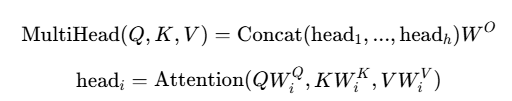
- 多头数量:默认 8 个。
- 线性投影:每个头有独立的 投影矩阵,最后进行合并。
在Transformer中的应用:
- Encoder自注意力:Q、K、V 都来自同一个序列(输入)。
- Decoder自注意力:Q、K、V 来自同一个序列(已生成部分),需Mask未来位置。
- Encoder-Decoder注意力:Q 来自 Decoder,K 和 V 来自 Encoder。
这个就不需要多说了,意思就是从不同的角度去理解问题,因此叫多头。
6.位置编码
由于注意力机制本身无法区分词的顺序,Transformer通过正弦位置编码注入位置信息:
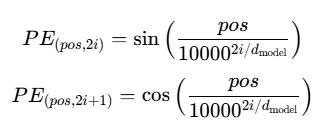
- 每个位置对应一个唯一的向量,加到词嵌入上。
- 正弦/余弦函数使模型能学习相对位置关系。
位置编码就像给每个词发一张"座位号":
- 正弦/余弦函数生成独特的座位号
- 座位号相加到词嵌入上
- 模型因此知道词的顺序
- 而且还能推算出词与词之间的相对距离!
好,接下来,我们用自己的话,完整的解释一下,什么是transform:
Transformer = 超级"理解+生成"机器
- 编码器:理解输入,像认真读书的学生划重点
- 注意力机制:找到相关的信息,像考试时定位关键词
- 解码器:根据理解生成输出,像根据笔记回答问题
- 位置编码:记住词语顺序,像标注页码
核心能力:理解上下文 → 生成正确内容
相信大家读完这篇文章,一定会对transform有自己的理解,会说流程就好。
我是程序员雷欧,我们下次见......