自然语言处理常见任务
- 文本分类
- 序列标注
- 文本生成
- 信息抽取
- 文本转换
自然语言处理发展历史
- 规则系统阶段
- 1954年,乔治城大学和IBM联合开发俄英翻译
- 1966年,约瑟夫·魏岑鲍姆开发ELIZA心理医生聊天机器人,模仿"倾听式对话",是世界上最早的"聊天机器人"
- 统计方法阶段
- N-gram模型(一个词出现的概率,只取决于它前面 N-1 个词)
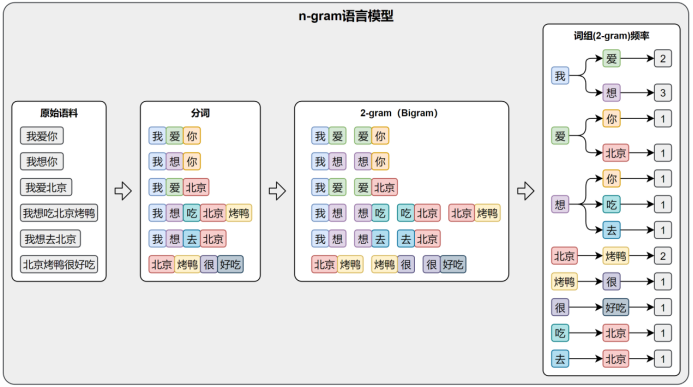
- N-gram模型(一个词出现的概率,只取决于它前面 N-1 个词)
- 机器学习阶段(见招拆招)
-
词袋模型 (词袋+特征向量)+逻辑回归 实现文本分类
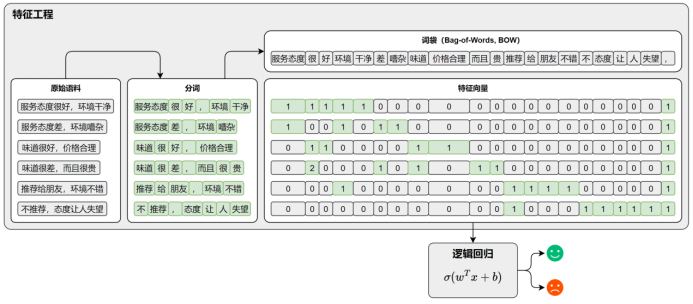
-
n-gram(将相邻的 n 个词作为一个整体,这样就能保留一部分的词序信息。)
"服务很好但味道差劲"分词后 "服务","很","好","但","味道","差劲"
"味道很好但服务差劲"分词后 "味道","很","好","但","服务","差劲"
这两条评论在词袋模型 中的特证向量是完全相同的
使用n-gram 后"服务很好","很好但","好但味道","但味道差劲"
"味道很好","很好但","好但服务","但服务差劲"
在词袋模型中的特征向量也就区分了
-
- 深度学习阶段
- 传统序列模型(静态输出):RNN、LSTM、GRU
- 序列到序列(动态输出):Seq2Seq、Attention机制、Transformer(提升训练效率,增强模型对长距离依赖的建模能力)
- "预训练 + 微调"的时代:BERT、GPT、Qwen
N-gram模型、**词袋模型、**n-gram的区别
- N-gram模型是统计学习方法:单个词的出现概率,仅依赖前文N-1个词
- 词袋模型 是机器学习方法,词袋 指无序去重的词汇集合;该模型拆分文本单词,仅统计词频、忽略语序与语法,生成文本特征向量 ,结合逻辑回归 可实现文本分类
- n-gram通过将相邻n个词作为整体,解决了词袋模型因忽略语序导致不同语义文本特征向量相同的问题。
token
在原始文本中,被切分为若干具有独立语义的最小单元,即token
分词
将原始文本切分为若干具有独立语义的最小单元(即token)的过程
词表
由语料库构建出的、包含模型可识别 token 的集合。词表中每个token都分配有唯一的 ID,并支持 token 与 ID 之间的双向映射。
英文与中文中常见的分词方式、区别
字符级分词、词级分词、子词级分词
英文
- 词级分词
- 子词级分词
- 字符级分词
中文
- 词级分词
- 子词级分词
- 字符级分词
词表示分类
稀疏的词表示:one-hot编码
稠密的词表示:语义化词向量
上下文相关的词表示
Word2Vec原理
Word2Vec(一个词的含义由它周围的词决定)
- CBOW(Continuous Bag-of-Words)模型(输入一个词的前后若干个词,预测中间的目标词)
- Skip-gram 模型(输入是一个中心词,预测前后若干个词)
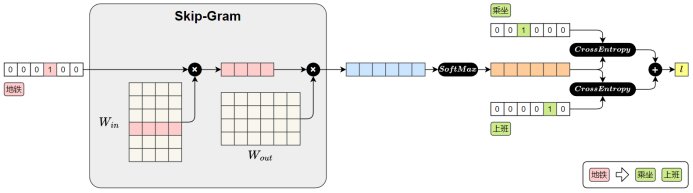
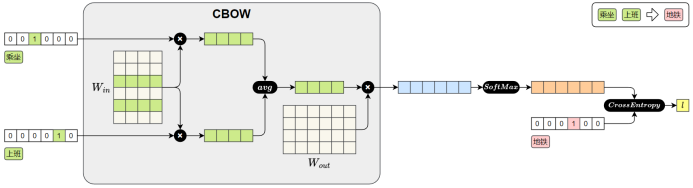
获取Word2Vec词向量方式
- 直接使用他人公开发布的词向量
- 在特定语料上自行训练
pip install gensim
from gensim.models import KeyedVectors
上下文相关词表示
上下文相关词表示(Contextual Word Representations)
词语的向量表示会根据它所在的句子上下文动态变化,从而更好地捕捉其语义。
为什么RNN论文公式和实际代码书写形式不一样?
