大家好,我是孟健。Claude Code 这次最值得看的,不是八卦,而是它把终端 Agent 的边界扒得更清楚了。
过去很多人还在问:Claude Code 强不强,值不值得买,会不会把 Cursor 干掉。
但今天更现实的问题其实是:什么活该交给它,什么活先别交。
如果这个边界没想清楚,Agent 不是帮你提效,而是帮你把返工提前做掉。
01 这次泄露,为什么值得普通开发者关心
3 月 31 日,Claude Code 因为 npm 包里带出了 source map,完整 CLI 源码被外界读到了。相关讨论在 Hacker News 直接冲到了 1800+ points、900+ comments,说明这已经不是小圈子八卦,而是开发者群体级别的关注。
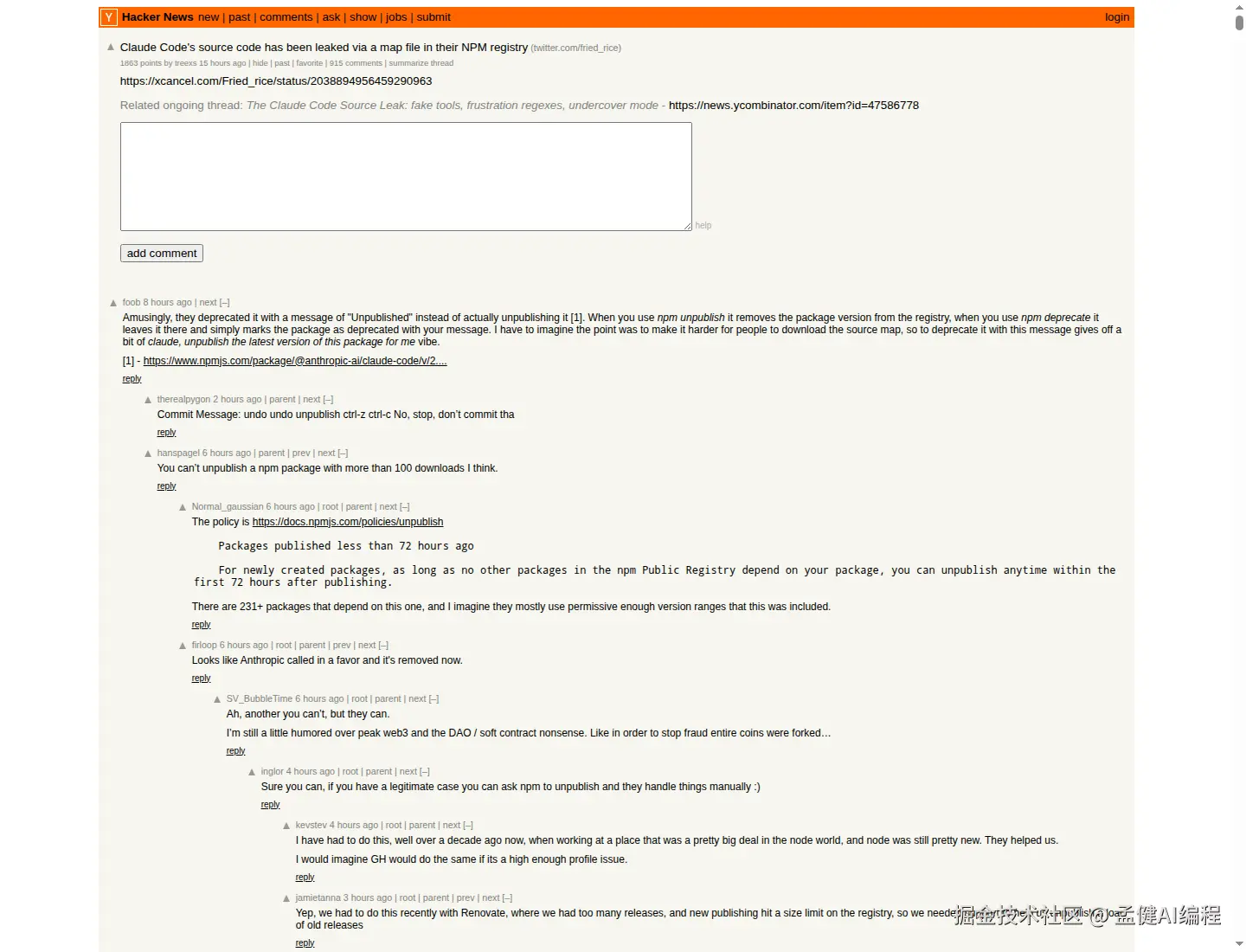
更关键的是,外界不是只看到了一堆实现细节,而是看到了几个非常有代表性的设计信号:
- 有 anti-distillation 相关机制,会注入 fake tools 之类的反蒸馏手段
- 有 undercover mode,会尽量避免在外部仓库里暴露 Anthropic 内部痕迹
- 还有一堆对真实工作流很敏感的判断:权限、上下文、会话压缩、客户端校验

这件事对我的启发很直接:终端 Agent 不是不能用,而是它本来就该被放在"边界清楚"的位置上。
争议一点说,很多人不是高估了 Claude Code 的能力,而是高估了自己下任务的清晰度。
AI 编程最贵的成本,不是 token,而是你把模糊需求交出去以后,再收回来重做的那一轮又一轮。
02 我现在只把终端 Agent 放在 3 个位置
1)边界清晰、验收明确的实现任务
Anthropic 官方 best practices 里写得很直白:给 Claude 一个可验证的成功标准,是最高杠杆动作;推荐流程不是直接开写,而是 explore first, then plan, then code。
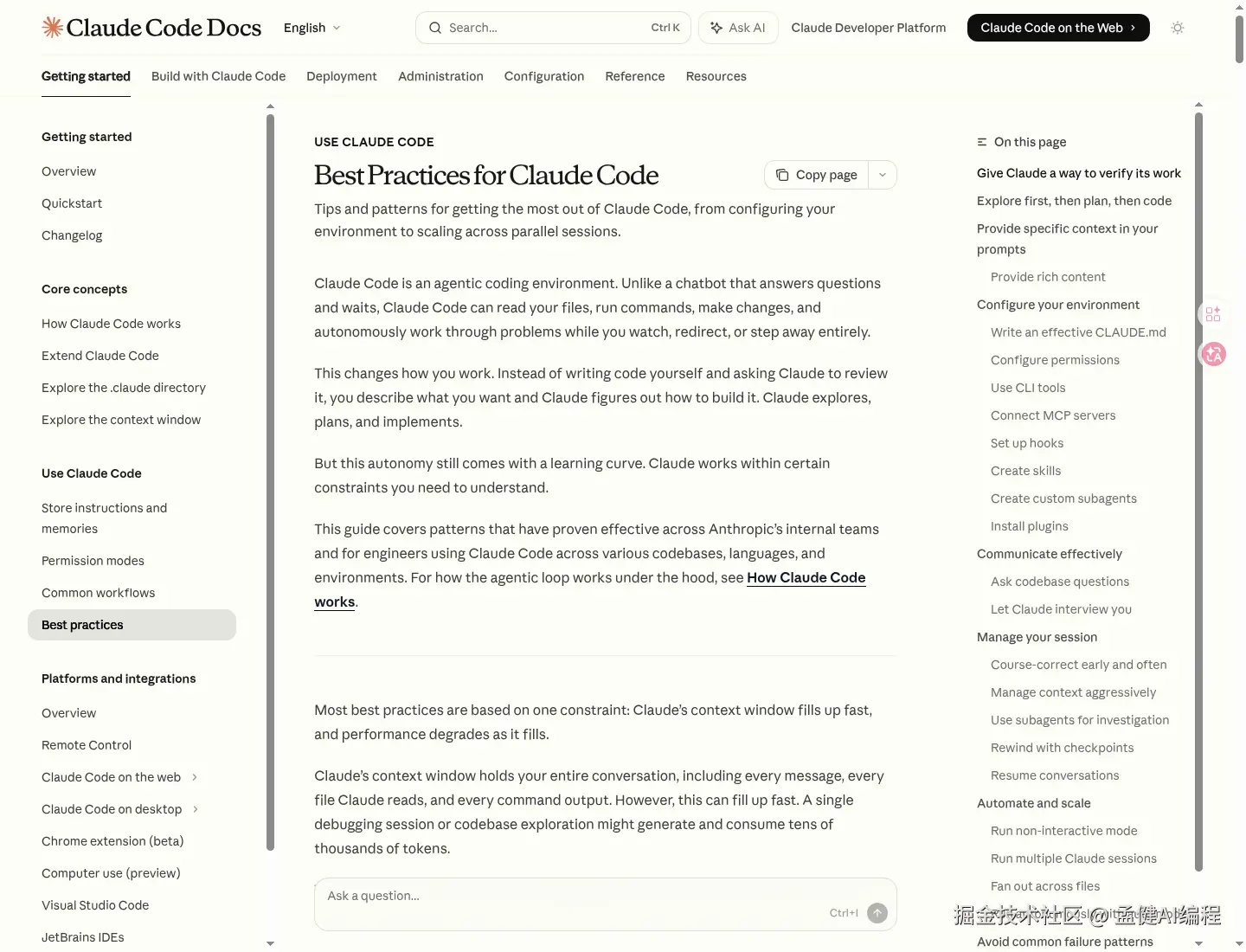
这就决定了第一类最适合交给它的活:
- issue 已经写清楚
- 改动边界明确
- 有测试、截图或输出可验
- 完成标准一句话能说清
这种任务交给 Agent,省下来的不是敲代码那几分钟,而是少掉中间那几次上下文切换。
2)重复出现、适合流程化的工作流任务
GitHub 在 2 月 4 日把 Claude 和 Codex coding agents 放进 public preview,也说明整个行业已经在把 Agent 往工作流里塞,而不是只当聊天玩具。
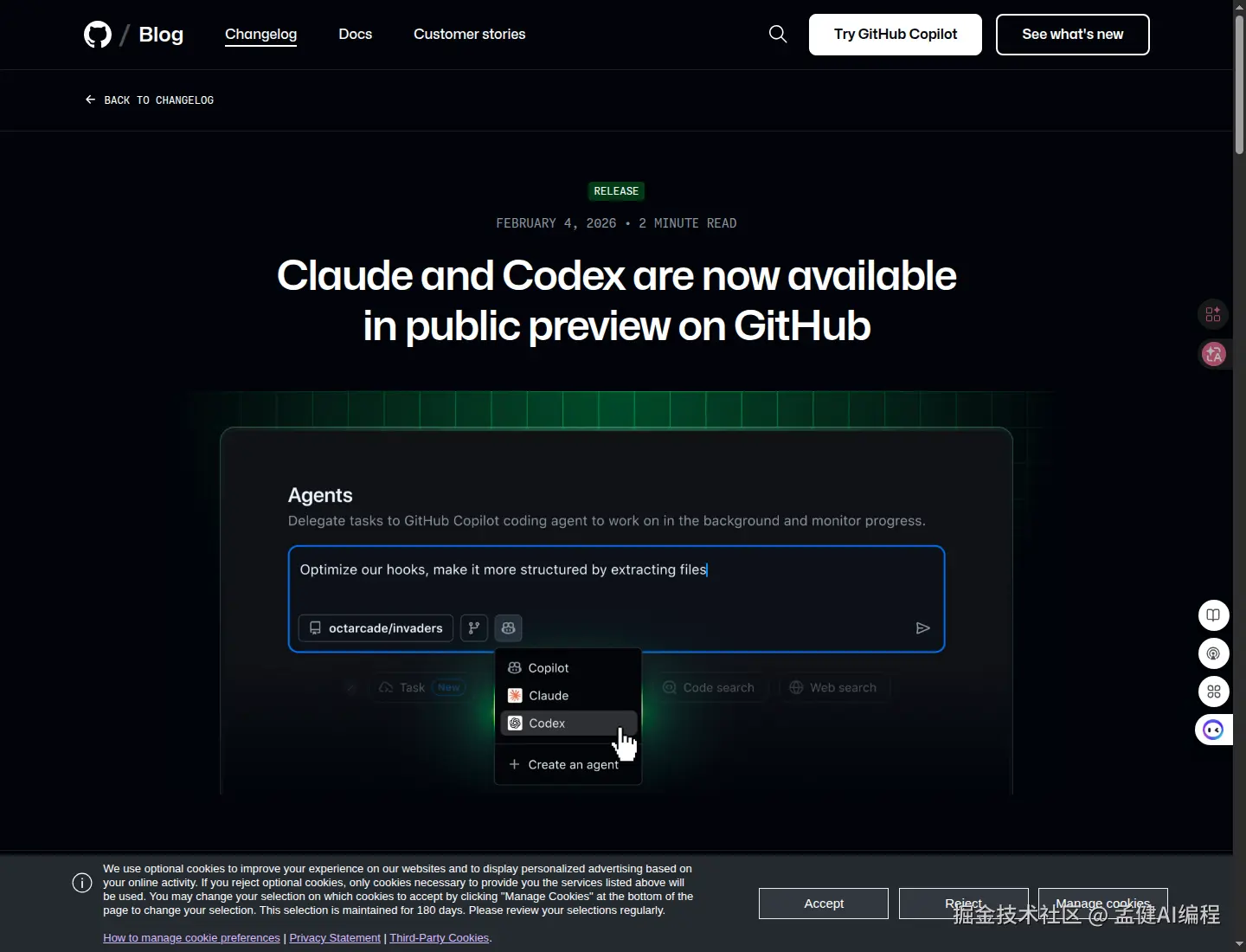
官方给的入口非常明确:可以从 GitHub、GitHub Mobile、VS Code、issue、PR、Agents tab 里直接启动和分派任务。
这类最适合 Agent 的活通常是:
- issue 起草初版修复
- PR review comment 跟进
- 文档、配置、测试一起补齐
- 脚手架和重复改造任务
人不是做不了,而是太碎。碎到最后,真正浪费你的不是技术,而是切来切去。
3)先跑第一轮、再由人拍板的探索任务
Claude Code 官方还单独把 subagents 拿出来讲,核心价值就是:把探索和实现放进不同上下文,减少主会话被污染。
这其实特别像真实团队协作。
你先让 Agent 去:
- 扫代码库
- 列改动点
- 写第一版计划
- 起最小可运行版本
- 把风险先翻出来
然后你再决定哪条路值得继续走。
很多人把 Agent 当最终执行者。我现在更愿意把它当第一轮推进者。
先让它把路踩出来,再由人决定是不是值得往前冲。
03 哪 3 类任务,我反而更不会交给它
1)需求自己都没定清的活
如果你自己都讲不清楚目标、边界和不做什么,Agent 只会把模糊放大。它会很努力,但努力错方向,比不努力更贵。
2)高风险的真实动作
涉及生产环境、账号权限、资金、外部执行动作的任务,我现在都不会让终端 Agent 单独闭环。能力越强,越要知道哪里必须人工接管。
3)强依赖视觉判断和业务感觉的任务
复杂 UI 微调、产品取舍、老板一句话背后的真实意图,这些不是代码问题,是判断问题。判断没定清前,把活交出去就是预支返工。
最近 GitHub 上各种 Claude Code how-to、best practice、workflow 仓库开始一起冒头,也说明用户关注点已经从"哪个模型更强",切到"怎么把 Agent 接进主流程"。
04 如果你今天就要上手,我建议用这张判断表
我自己现在给任务之前,会先过 4 个问题。
第一问:目标能不能一句话说清
如果一句话说不清,先别丢给 Agent。
比如:
- ✅「把这个登录报错修掉,跑通现有测试」
- ❌「你顺手把整个登录体验优化一下」
前者是任务,后者是愿望。
第二问:验收标准是不是客观的
最好的验收标准,不是"看起来差不多",而是:
- 测试通过
- 页面截图对齐
- lint/build 成功
- 某个接口返回正确结果
Anthropic 官方 best practices 为什么一直强调 verification?因为没有验证,Agent 很容易生成"看起来像对的东西"。这类错最烦。你第一眼觉得差不多,第二天才发现根本没真正解决问题。
第三问:出错成本高不高
如果这一步一旦出错,代价是线上事故、账号权限、资金风险、客户数据风险,那就别追求帅,直接把人工接管点前置。
我现在的原则很简单:
- 低风险动作,让 Agent 多跑
- 中风险动作,让 Agent 提方案,人确认
- 高风险动作,只让 Agent 做准备,不让它最终执行
第四问:返工时谁来收尾
很多人低估了这一问。
如果这件事做歪了,最后一定还是你自己回来兜底,那你就应该提前判断:这次交给 Agent,到底是在减少工作,还是只是在推迟工作。
以前常见的流程是:
- 我自己读代码
- 我自己试改
- 我自己跑测试
- 我自己回滚
- 我自己补文档
现在更合理的流程应该是:
- 我先把边界写清
- Agent 先读、先试、先列方案
- Agent 跑第一轮实现和验证
- 我只接 review、决策和最后的 merge
这个变化表面看是"让 AI 多做一点"。
本质上不是。
本质上是:把你最贵的脑力,用在方向判断,而不是用在反复起步。
这也是为什么我现在越来越少问"这个 Agent 能不能做",而是先问"这件事值不值得让 Agent 先跑"。
问题一换,返工会立刻少很多。
05 写在最后
所以我今天的结论很明确。
Claude Code 这次泄露,真正让人看清的,不是哪段源码更刺激,而是:终端 Agent 天生适合边界清楚、可验证、可回收的任务,不适合替你接住所有判断。
如果你今天就想开始用,最稳的分工只有三步:
- 人定边界
- Agent 跑第一轮
- 人做最后判断
这才是我心里 2026 年 AI 编程最靠谱的姿势。
不是把人拿掉。
而是把人从低价值推进动作里拿出来。
工具就摆在那里。用不用,是你的事。
👋 我是孟健,前腾讯 T11 / 前字节技术 Leader,现在全职做 AI 编程。
🔥 更多 AI 编程实战:
- GitHub:@mengjian-github
- 专栏:AI编程实战
觉得有用?点赞+收藏 就是最大支持 🙏