一直有小伙伴在群里问我:Codex 好用是好用,但只能调 OpenAI 自家的 GPT-5.5 模型,有没有办法切到国内的大模型啊?
答案当然是可以。
看,这是我切到DeepSeek V4的。
原理其实很简单,我们只需要做一层协议适配,把 Codex 的 Responses API 请求转换为国内模型支持的 Chat Completions 或 Messages API 就行了。
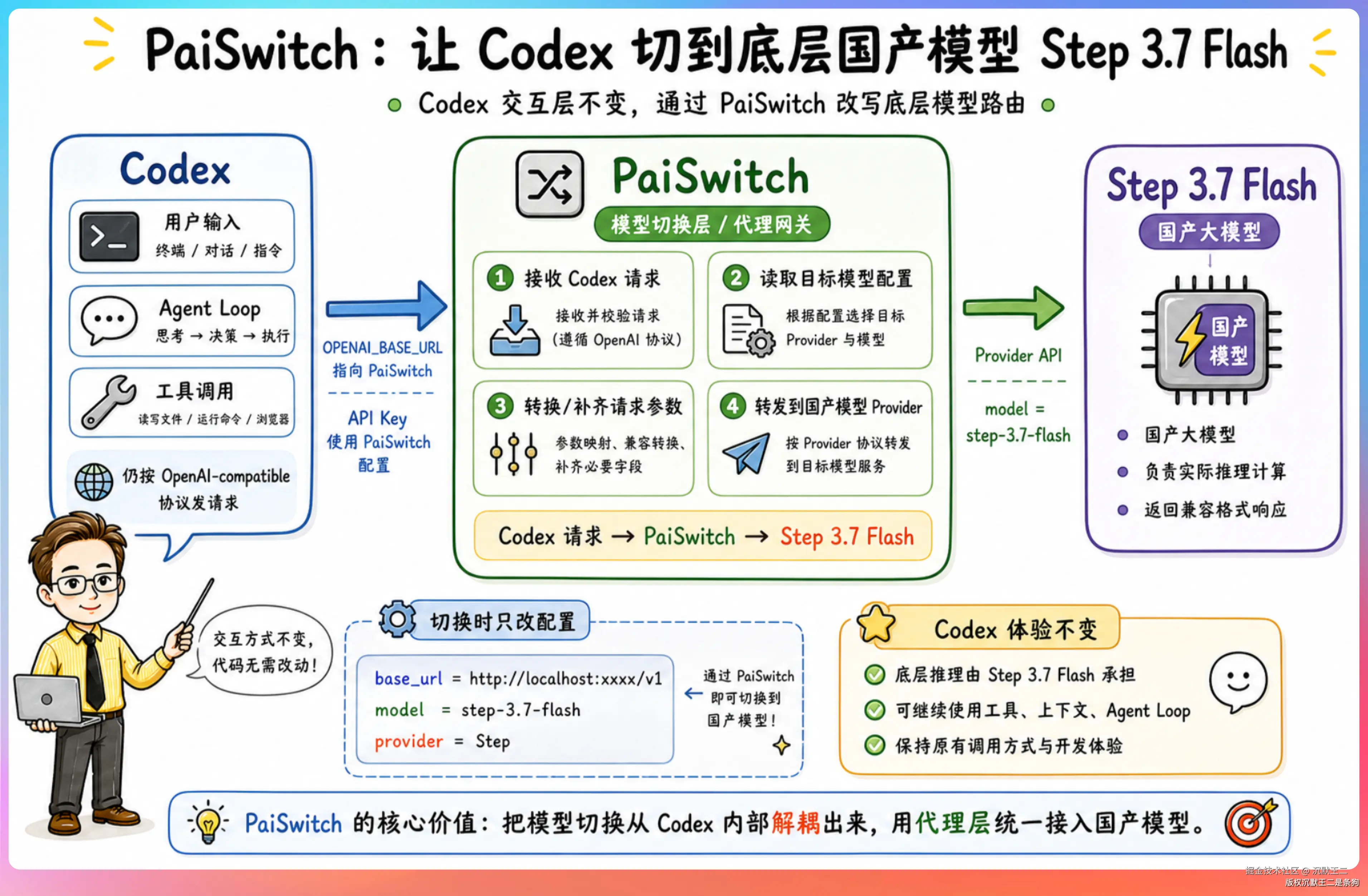
嗯,原理搞明白,做起来其实就很简单了。
我是用 Claude Code + Step 3.7 Flash 来完成的。
我需要给PaiSwitch增加一个底层可以给Codex切底层模型的功能
除了使用 Step 3.7 Flash 完成Codex底层模型的切换,我还顺手干了两件事。
1、用 Step 3.7 Flash 给 PaiAgent 加了生图工作流。
2、给 PaiCLI 增加了联网搜索和视觉理解能力。
这篇内容就把整个过程拆开来讲。
系好安全带,我们粗粗粗发~
01、Step 3.7 Flash 是什么?
阶跃星辰(StepFun)在 5 月 29 日发布了 Step 3.7 Flash,一个面向生产级 Agent 的高效率 Flash 模型。
注意,不是"更快更便宜的 Flash 替代品"。阶跃星辰想做的事情是让 Agent 在真实任务中更快、更稳、更省地完成完整工作流。
几个关键参数先摆出来:
- 架构:198B MoE(混合专家),每次推理激活约 11B 参数
- 上下文窗口:256K tokens
- 生成速度:最高 400 TPS
- 开源协议:Apache 2.0
- API 协议:同时兼容 OpenAI Chat Completions 和 Anthropic Messages
11B 激活参数是什么概念?
意味着推理时的计算量和一个 11B 级别的小模型差不多,但背后有 198B 参数的知识储备。
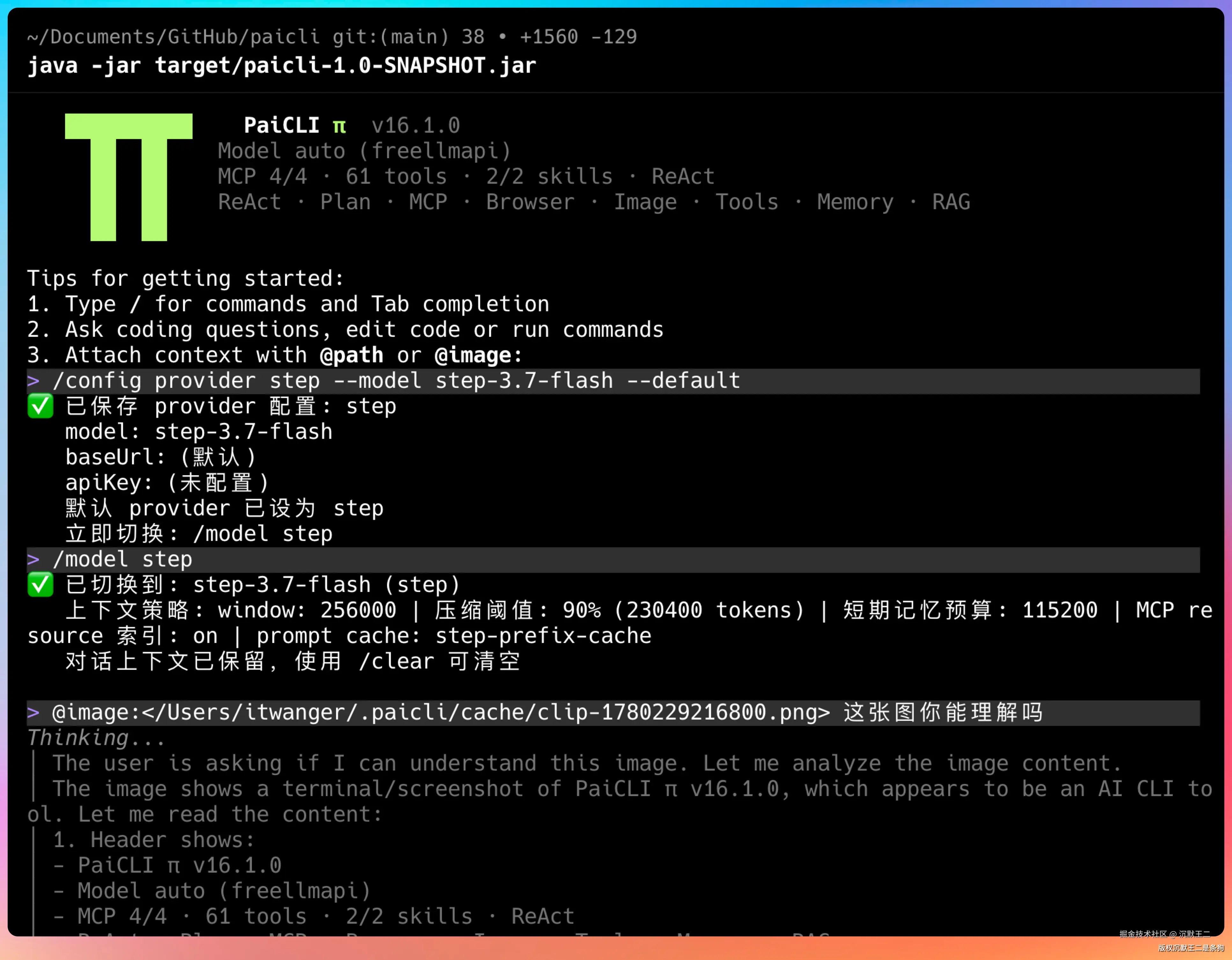
我录了个屏,接入 Step 3.7 Flash 的时候,PaiCLI的速度非常快,注意我没有加速哦。
【视频】
这token输出速度,刚刚的。
速度快、成本低,同时保持非常高的智能水平。
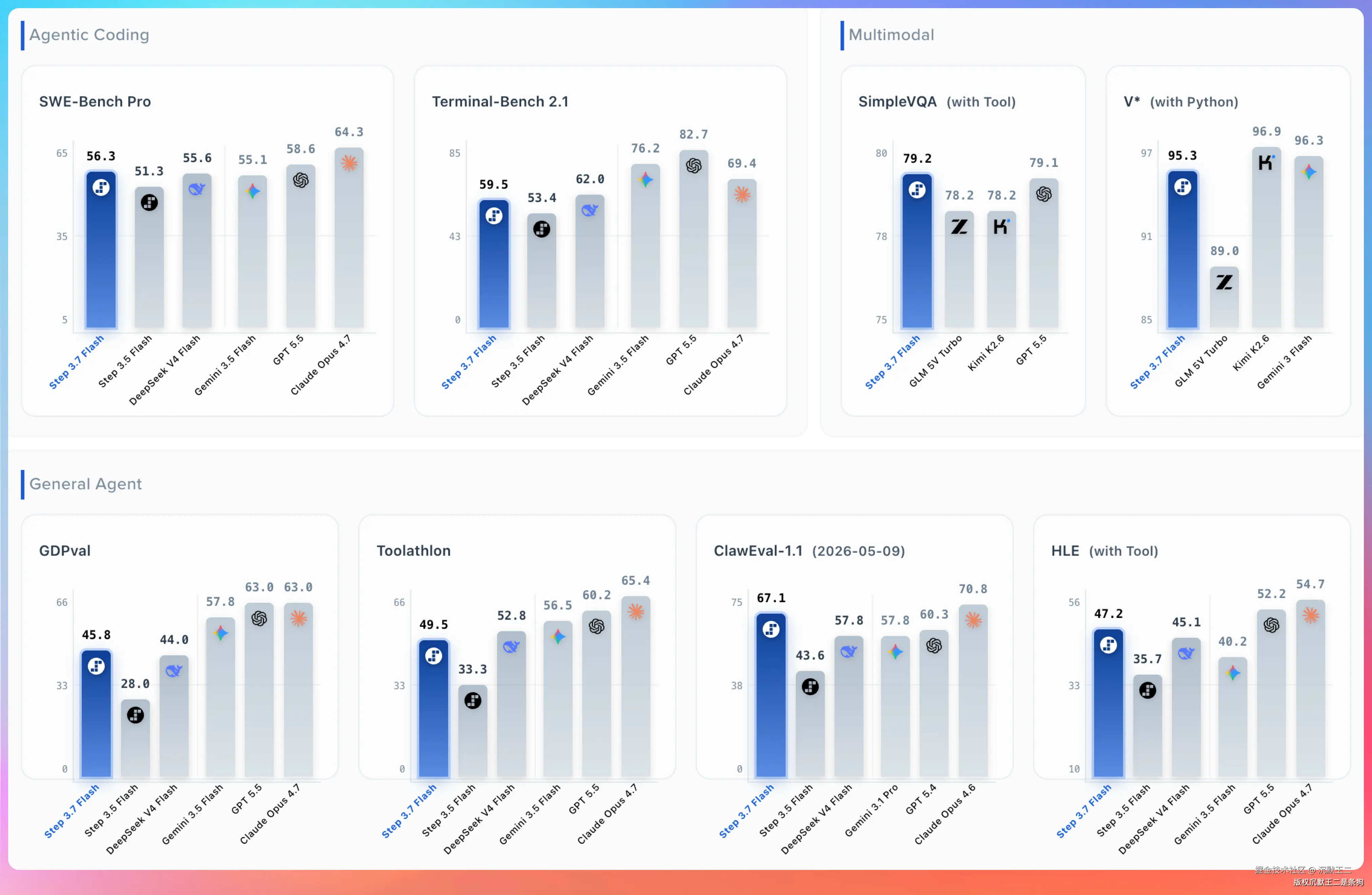
SWE-Bench Pro 拿到 56.3%,超过了 DeepSeek V4 Flash(55.6%)和 Gemini 3.5 Flash(55.1%)。ClawEval-1.1 得分 67.1%,在 Flash 级别的模型里排第一。
更有意思的是它的 Advisor Mode。
简单说就是 Step 3.7 Flash 作为 Agent 的执行引擎跑大部分任务,只在关键决策节点调用更强的 Advisor 模型。
这种模式下能达到 Claude Opus 4.6 编码性能的 97%,而每个任务的成本大约是 Opus 的九分之一($0.19 vs $1.76)。
性价比真的拉满了。
还有一点让我比较意外:Step 3.7 Flash 的多模态是原生的。
看,这是我在 PaiCLI中接入后的测试结果,Agent可以理解剪贴板中的图片是什么。
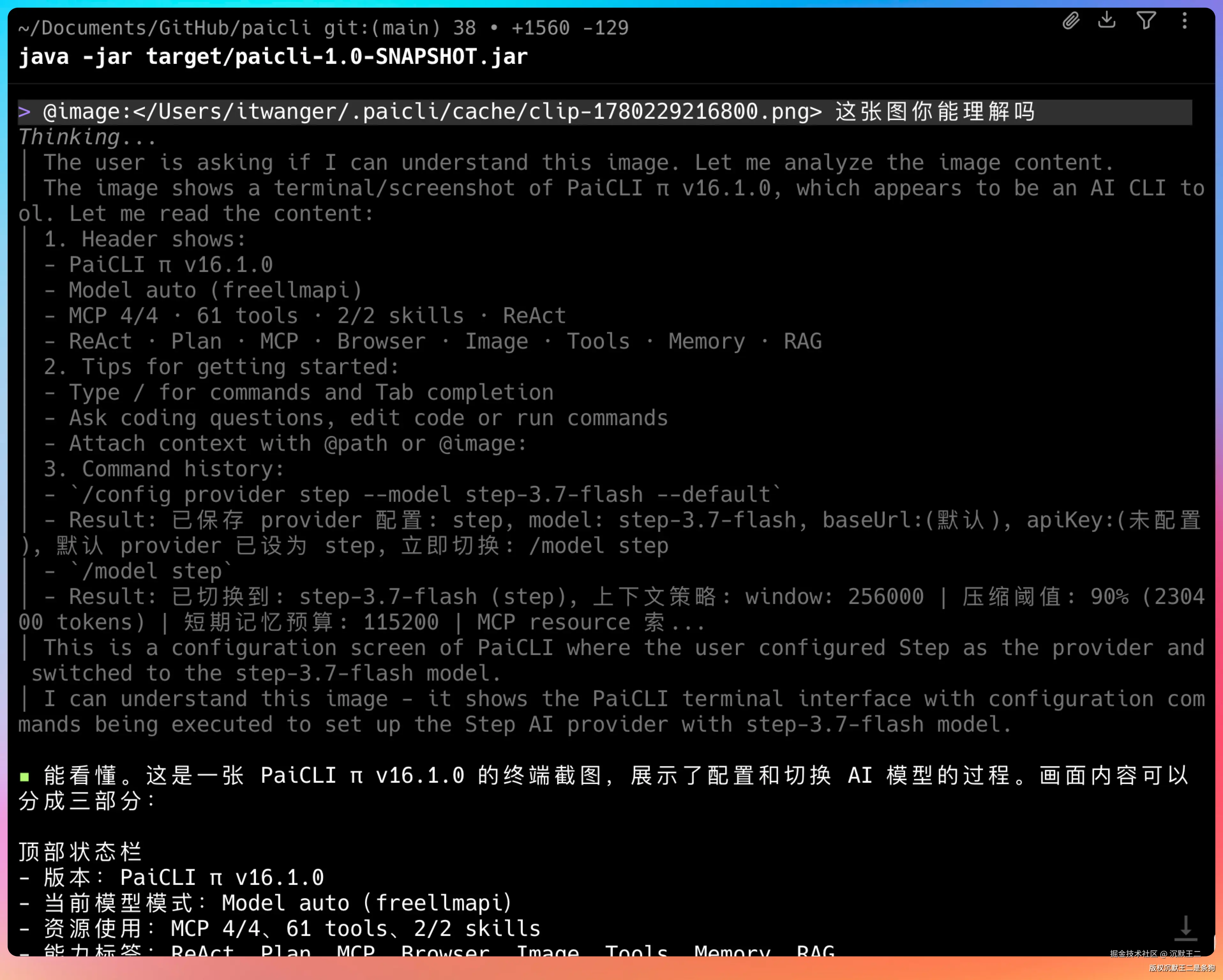
它可以直接理解 UI 界面、图表、文档截图、应用界面,然后把视觉信息转化成结构化的分析结果。
开发 Agent 的时候不需要另外接一个视觉模型或者配置什么视觉 MCP,一个模型就能搞定看图和推理。
Step 3.7 Flash 对搜索型 Agent 任务做了专门优化,配合 StepSearch / web_search 工具时,可以在 Agent Loop 中完成检索、阅读和综合。
也就是说。
在 Agent 推理过程中,如果需要外部信息,模型会自动触发搜索,拿到结果后继续推理。整个过程不需要再手动编排"搜索→解析→再输入"的流程。
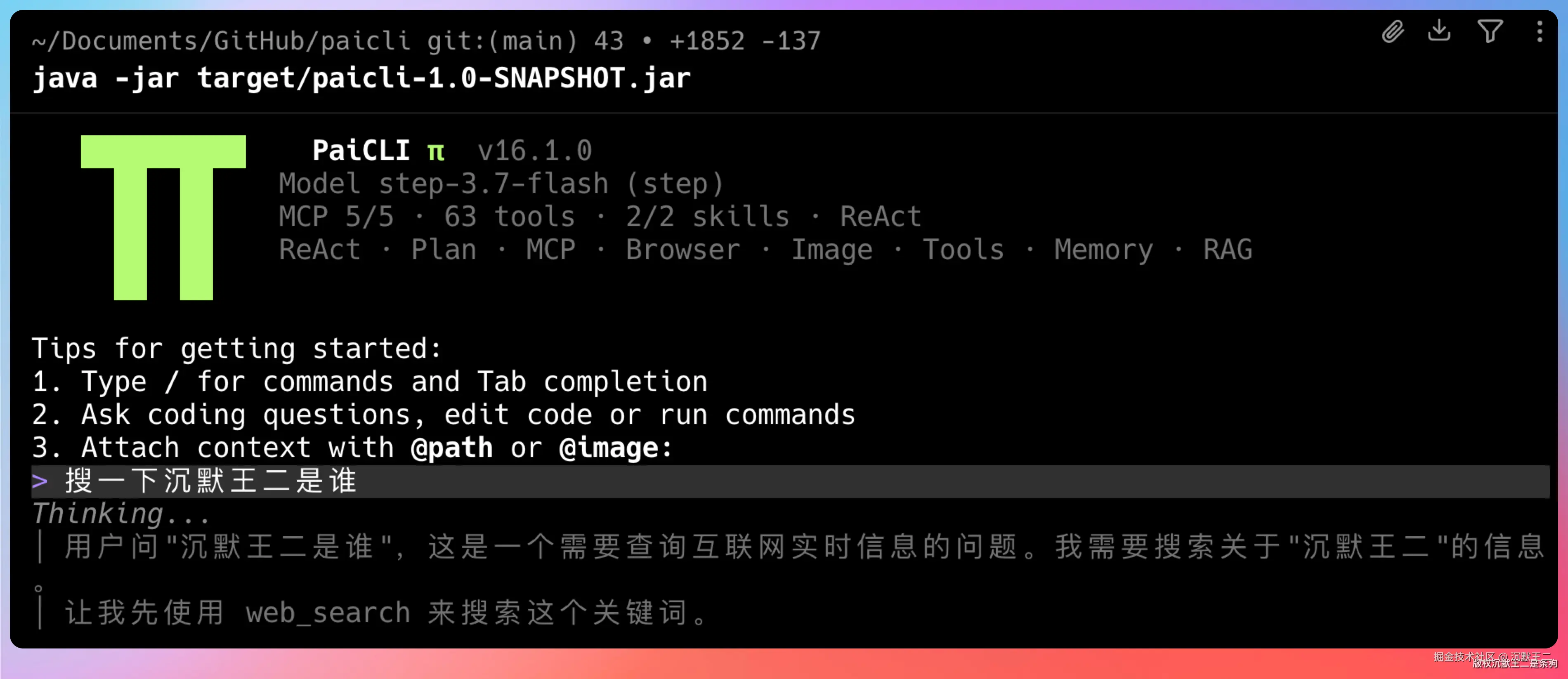
比如说我这里让PaiCLI直接搜沉默王二是谁,模型里是没有这个数据的,所以Agent会自动触发联网搜索,使用 StepSearch 进行搜索,然后给出答案。
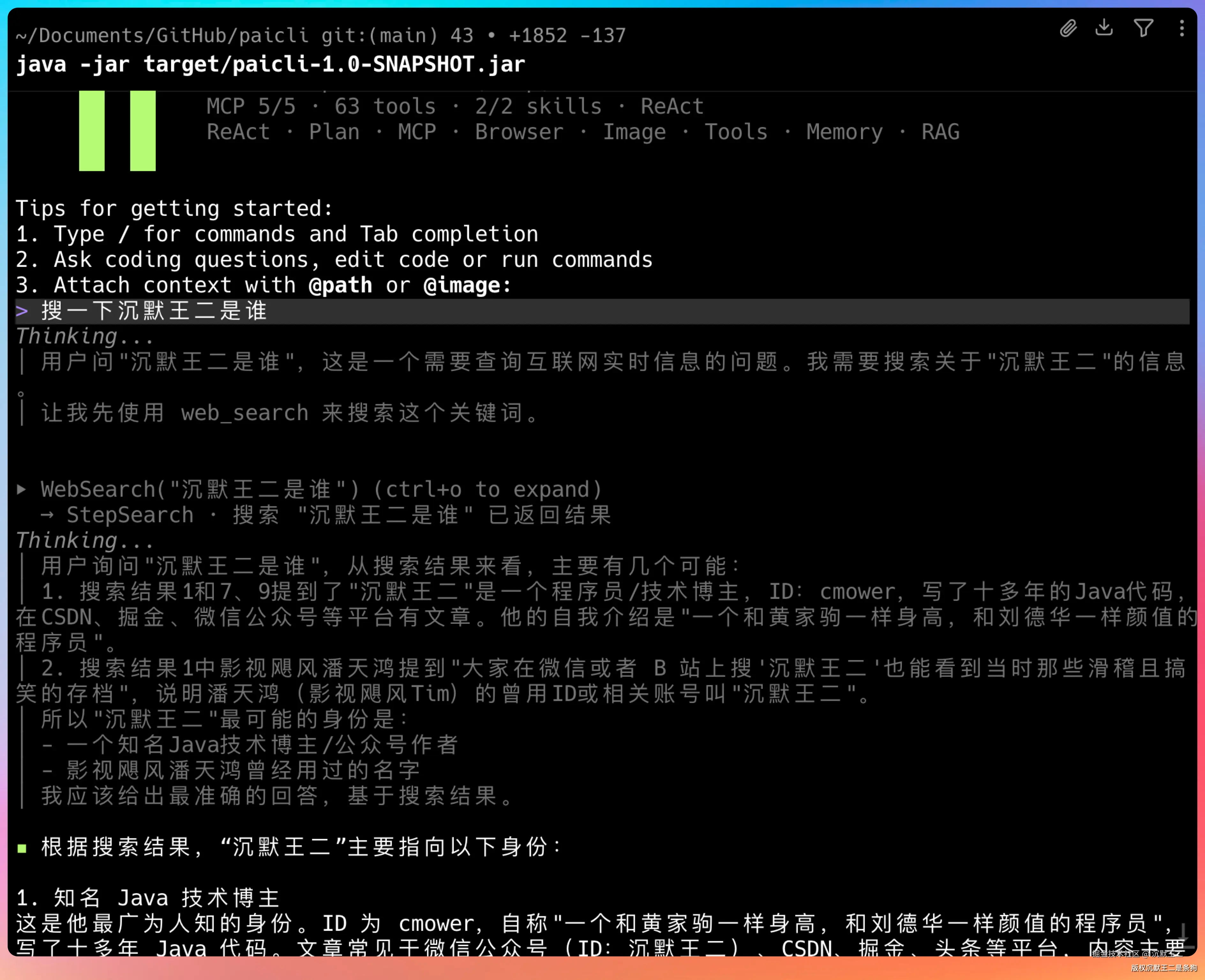
结果非常准确。😄
还有一个我觉得对国内开发者非常友好的地方。
Step 3.7 Flash 的 API 同时支持 OpenAI 和 Anthropic 两种协议。

这意味着不管你是用 Claude Code 还是 Codex,理论上都可以直接对接。在 Agent 生态兼容性上,Step 3.7 Flash 对 Claude Code、KiloCode、RooCode、OpenCode、Hermes Agent、OpenClaw 等主流框架也做了适配优化。
02、Codex 切 Step 3.7 Flash
Codex 用的是 OpenAI 的 Responses API,国内大模型普遍用的是 Chat Completions API。虽然 Step 3.7 Flash 兼容 OpenAI 协议,但 Codex 走的 Responses API 和标准的 Chat Completions API 还是有差异的。
PaiSwitch 就是为了解决这个问题而生的。
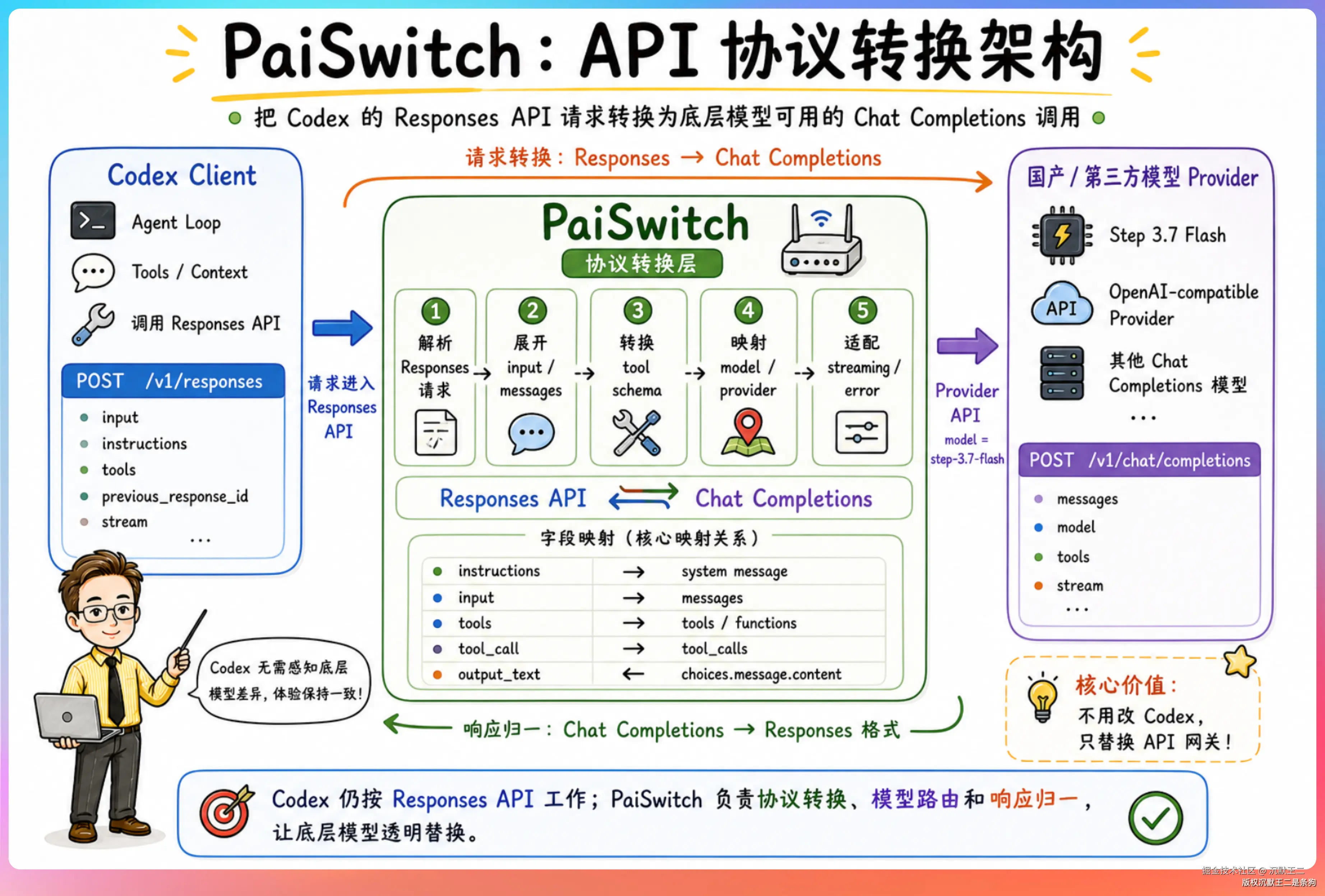
核心原理我们前面也提到了。
在本地起一个代理服务,接收 Codex 发来的 Responses API 请求,转换成 Chat Completions 格式,转发给目标模型,再把响应转换回 Responses 格式返回给 Codex。
就可以了。
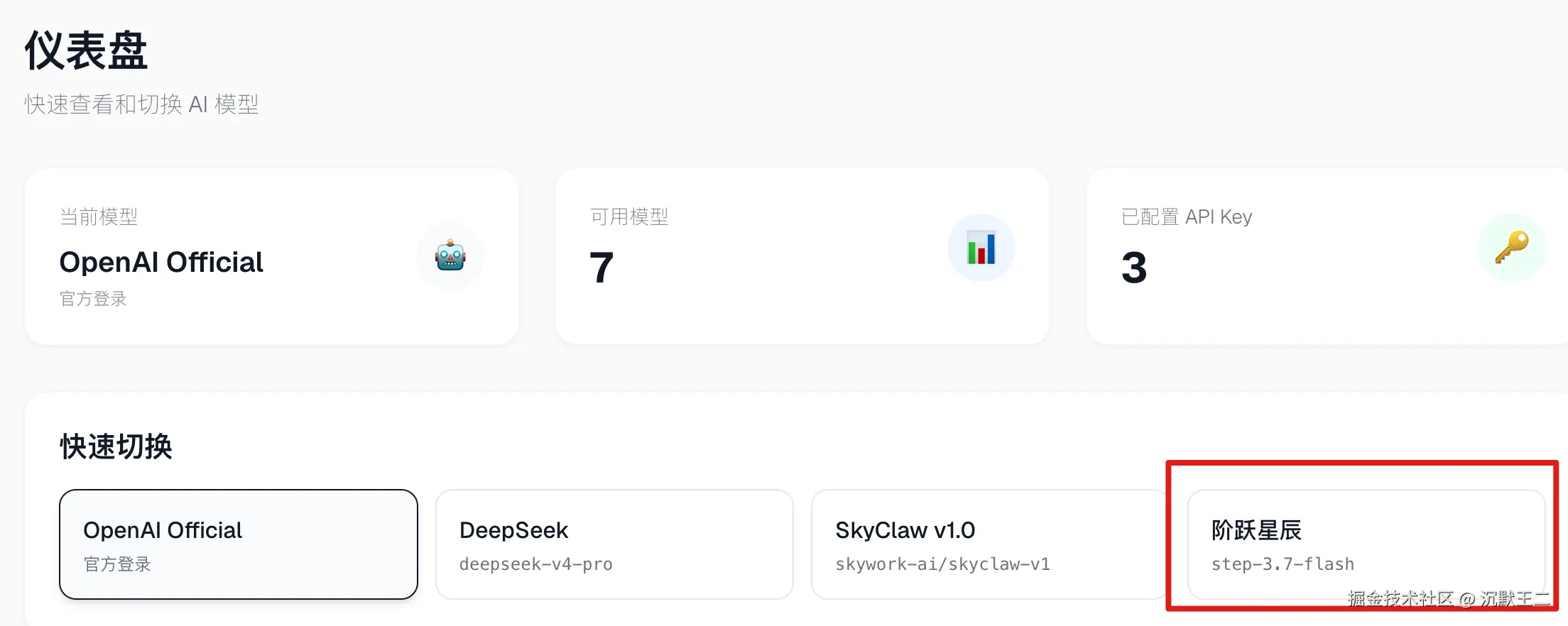
PaiSwitch是开源的哦。
切换流程
以 Codex 切换到 Step 3.7 Flash 为例,整个流程是这样的:
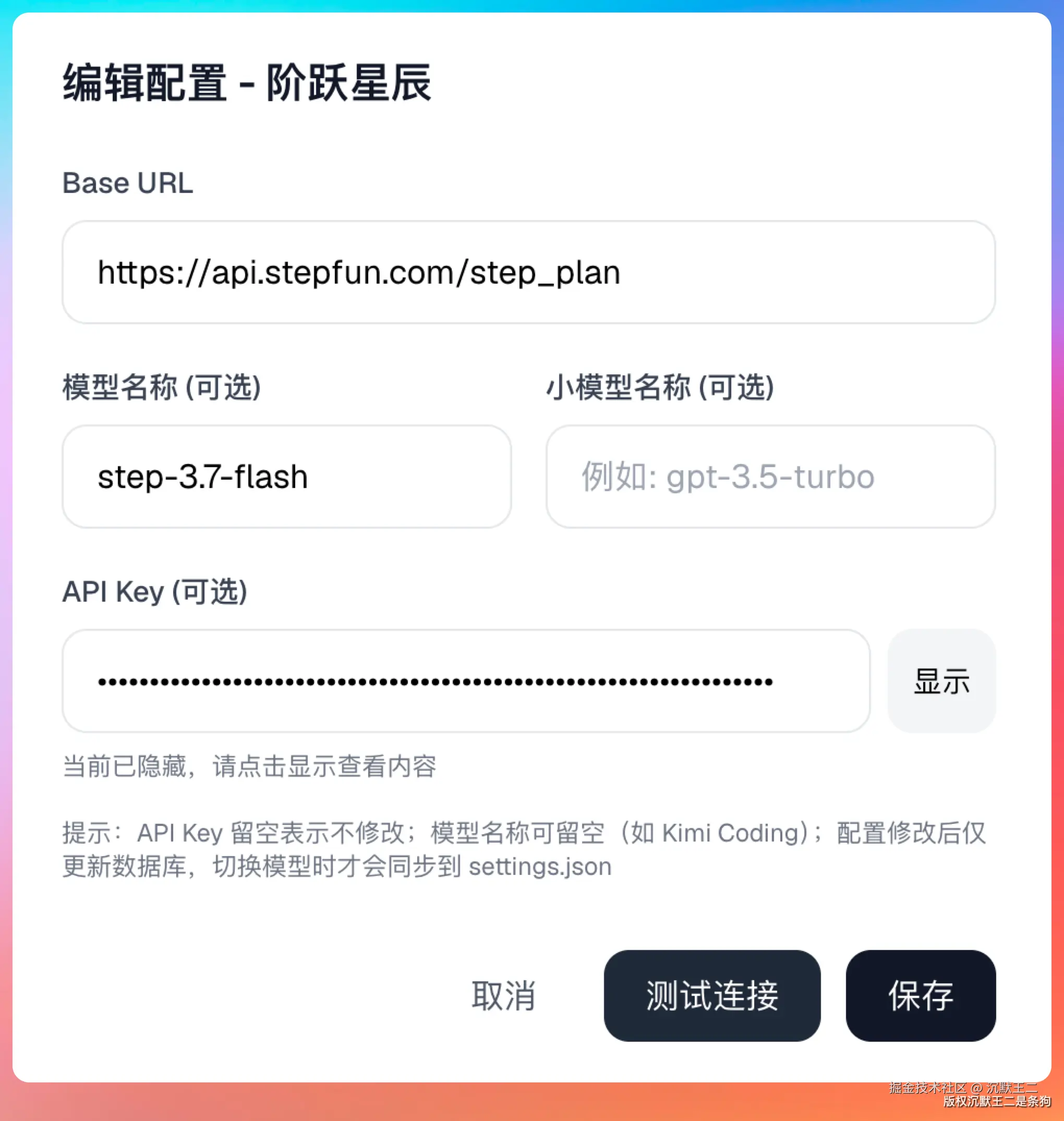
第一步,在 PaiSwitch 添加 Step 3.7 Flash,填入你的 API Key。
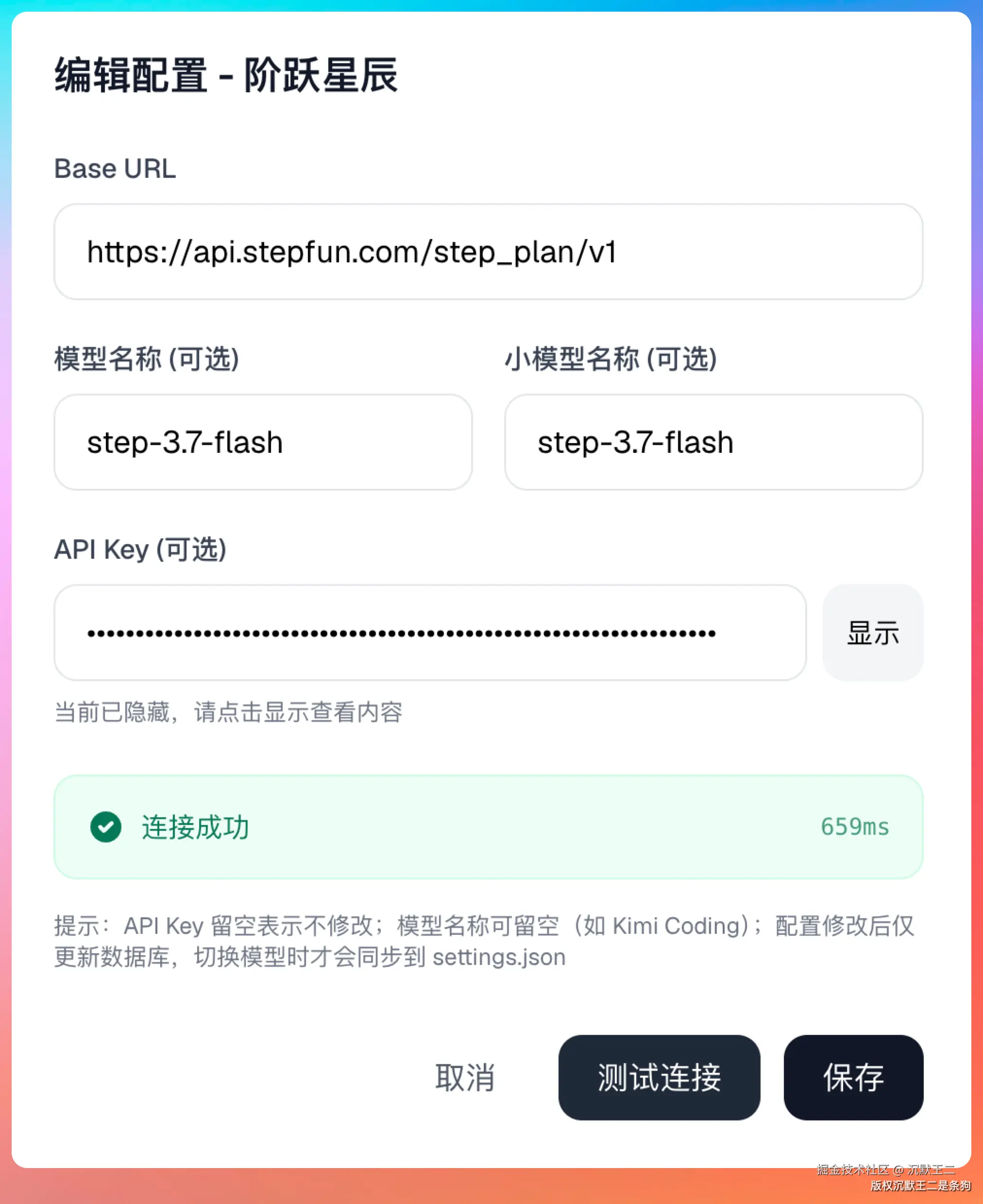
- base url 填:
https://api.stepfun.com/step_plan/v1 - 模型名填:
step-3.7-flash
可以点【测试链接】测一下通不通。
第二步,在 PaiSwitch的仪表盘页面选择 Codex,然后切到阶跃星辰。
PaiSwitch 会自动修改 ~/.codex/config.toml,把模型配置指向本地代理:
toml
model_provider = "step"
model = "step-3.7-flash"
model_reasoning_effort = "high"
[model_providers.step]
name = "Step 3.7 Flash"
base_url = "http://127.0.0.1:8080/codex-proxy/step/v1"
wire_api = "responses"第三步,Codex 重启后,所有请求都会经过 PaiSwitch 的代理。
Claude Code 中 切 Step 3.7 Flash 也是类似。
- base URL 填:
https://api.stepfun.com/step_plan - 模型名填:
step-3.7-flash
然后重启Claude Code。
03、Step 3.7 Flash + PaiAgent
PaiAgent 是我做的一个 AI 工作流编排平台,之前已经支持了 LLM 对话、联网搜索、知识库检索等节点。
但生图一直没加,原因很简单------之前没有一个又快又便宜的多模态模型能顶住 Agent 工作流里的高频调用。
Step 3.7 Flash 发布后,我觉得时机到了。
开发过程
Codex 切到 Step 3.7 Flash,然后给这样一个 Prompt:
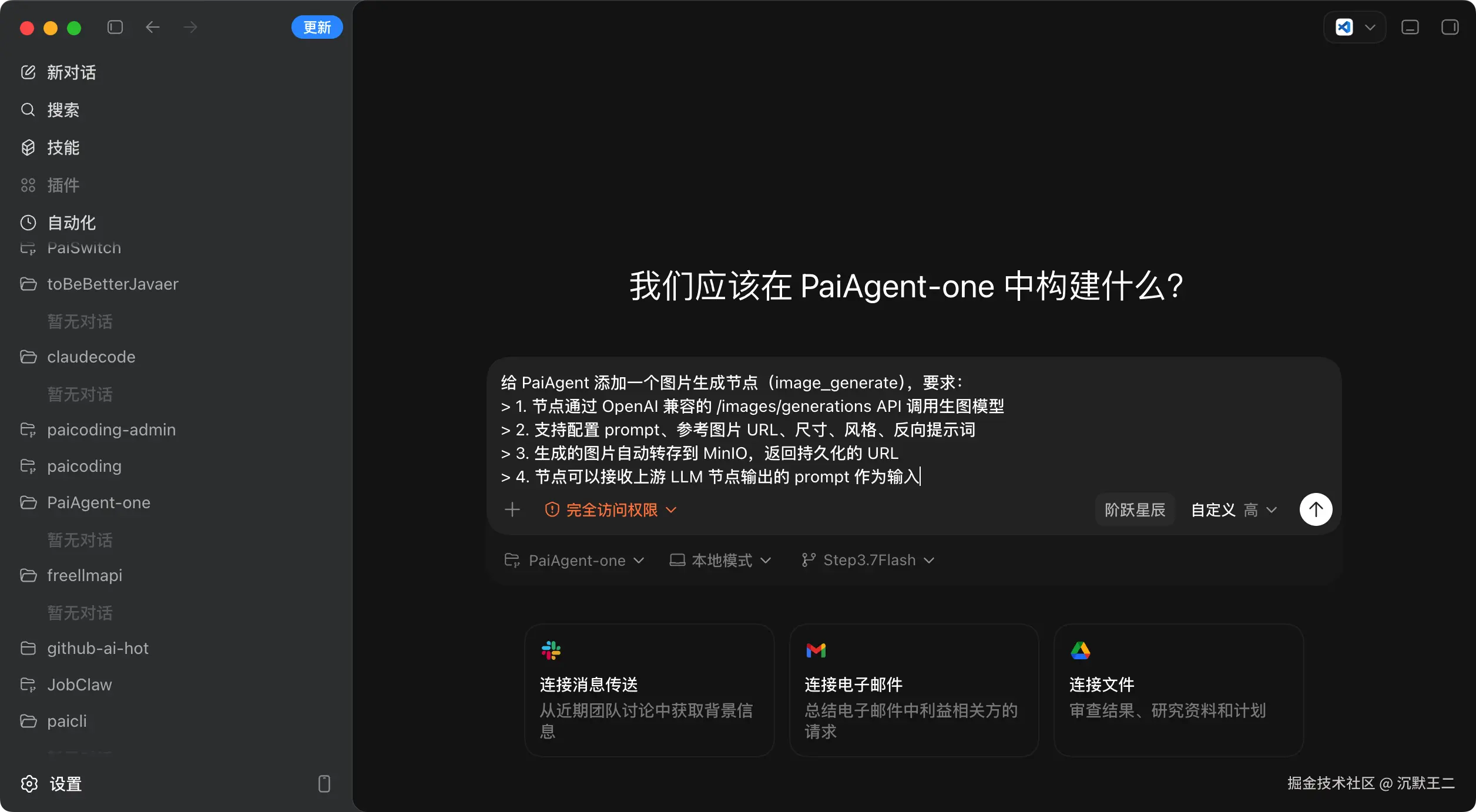
给 PaiAgent 添加一个图片生成节点(image_generate),要求:
- 节点通过 OpenAI 兼容的 /images/generations API 调用生图模型
- 支持配置 prompt、参考图片 URL、尺寸、风格、反向提示词
- 生成的图片自动转存到 MinIO,返回持久化的 URL
- 节点可以接收上游 LLM 节点输出的 prompt 作为输入
Step 3.7 Flash 的 Tool Use 稳定性在这个任务里体现得比较明显。整个开发过程中,它需要反复读取 PaiAgent 的现有代码、理解节点执行器的抽象基类、生成新的执行器代码、修改节点定义服务,中间涉及大量的上下文切换和工具调用。
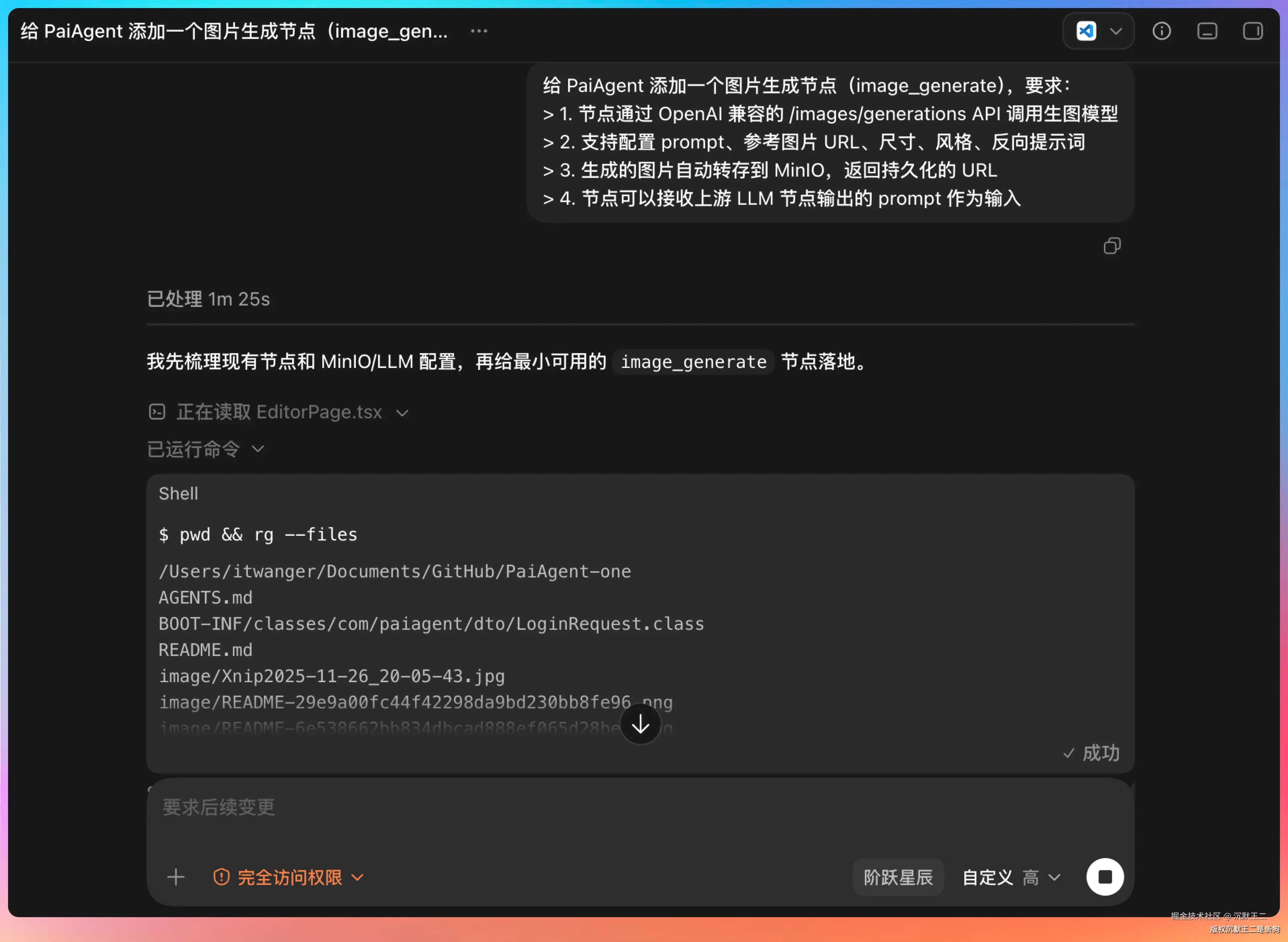
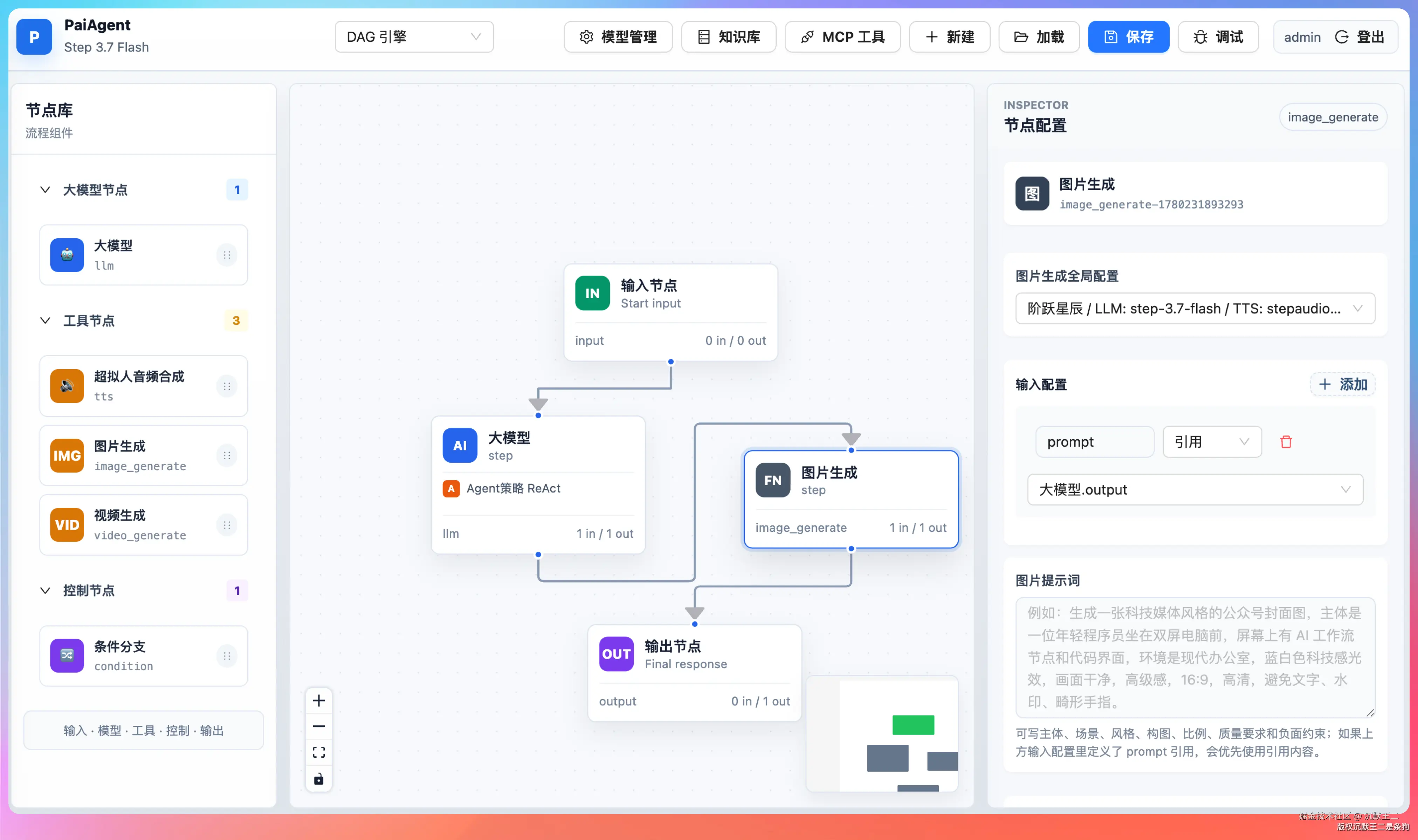
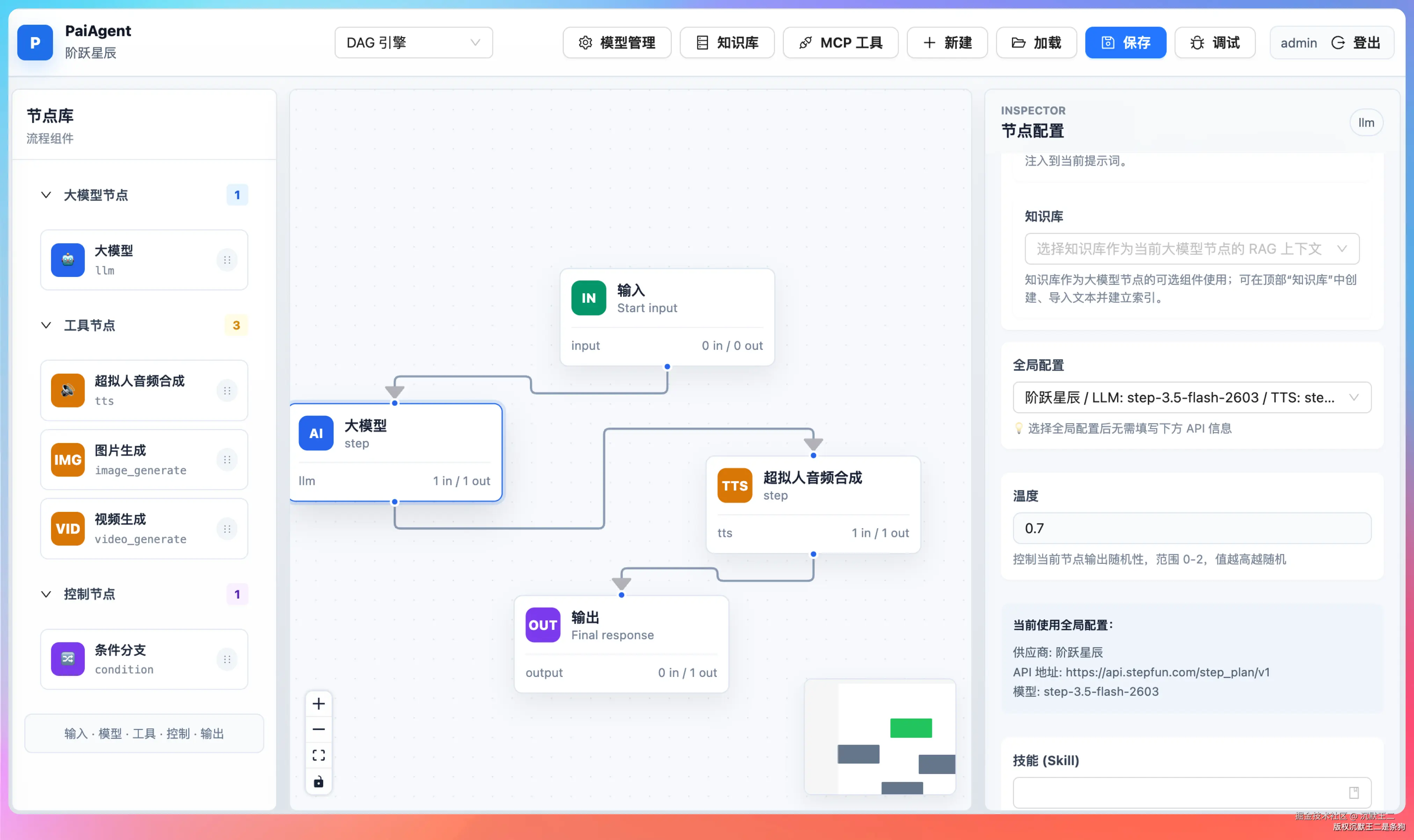
最终生成的核心代码是 ImageGenerateNodeExecutor,执行流程分四步:
- 从上游节点或配置中提取 prompt
- 通过配置解析器获取 API 地址、Key 和生图模型名称
- 调用
/images/generationsAPI 生成图片 - 把生成的图片从临时 URL 转存到 MinIO,返回持久化地址
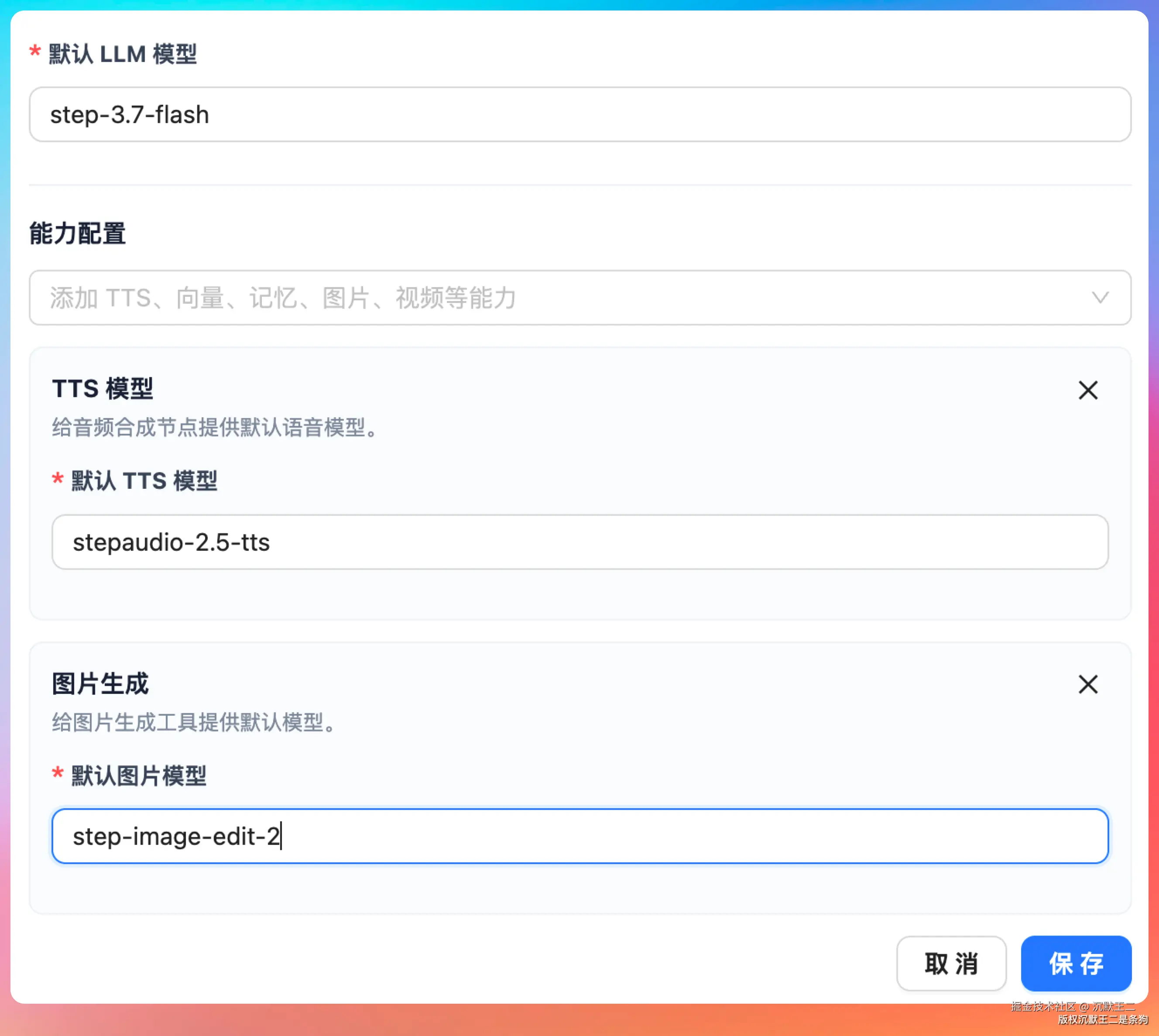
生图效果
在 PaiAgent 的全局配置里,语言模型设置为 Step 3.7 Flash,生图模型设置为 step-image-edit-2。
然后我们新建这样一个工作流:输入→LLM 节点→image_generate 节点→输出。
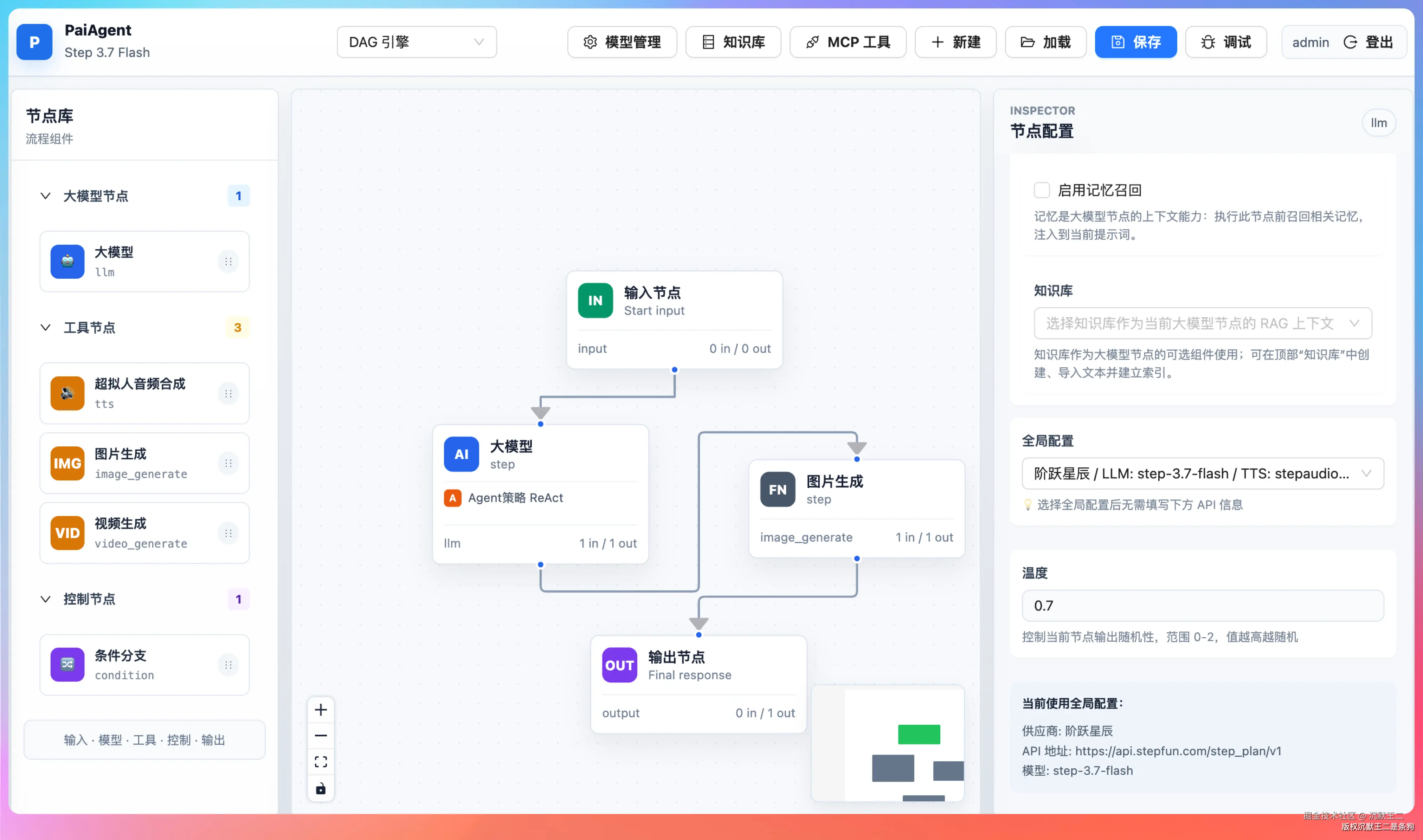
LLM 节点选择我们刚刚配置的 Step 3.7 Flash,LLM 节点的提示词如下所示:
markdown
你是专业的 AI 生图提示词设计师。请根据用户输入,生成适合阶跃星辰图片生成模型的提示词。
硬性要求:
1. 只输出最终生图提示词,不要解释,不要标题,不要 Markdown。
2. 输出必须控制在 512 个字符以内,越接近 300-450 字符越好。
3. 保留用户输入中的核心主体、场景、用途、风格和比例要求。
4. 如果信息不足,请适度补充画面细节,包括主体、环境、构图、光线、色彩、镜头、质感。
5. 不要堆砌过多形容词,不要写长段落。
6. 除非用户明确要求文字,否则提示词中加入:避免文字、Logo、水印、二维码、乱码。
7. 优先输出中文提示词。
用户输入:
{{input}}
请输出一段不超过 512 字符的生图提示词。一个典型的工作流是这样的:
用户输入"一个帅气的二次元美女" → Step 3.7 Flash 作为 LLM 节点润色和扩展 prompt → image_generate 节点调用 step-image-edit-2 生成图片 → 图片转存到 MinIO → 输出持久化 URL
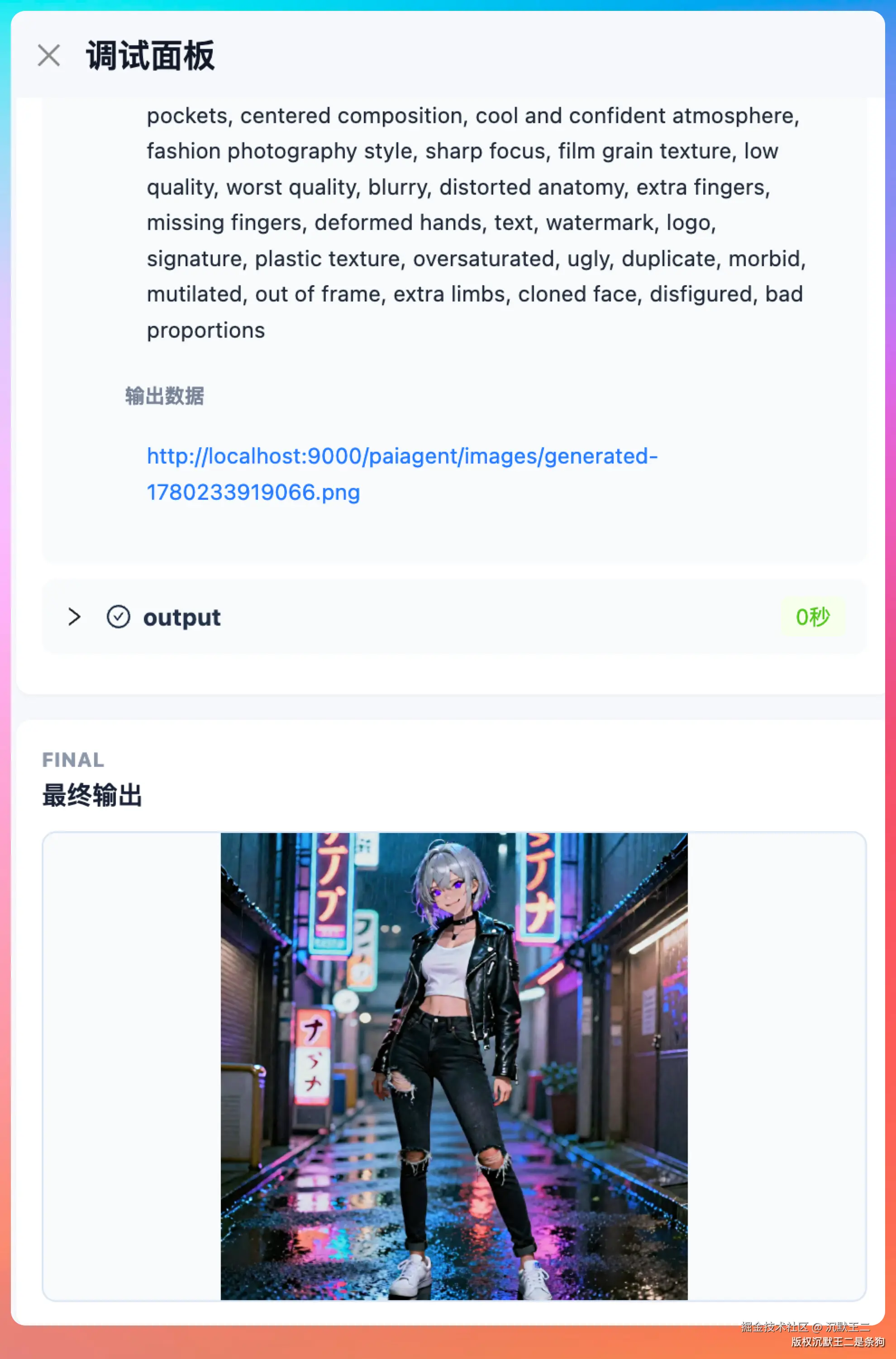
完全 one-shot。
我测试了几组 prompt,生图速度大概在 10 秒出一张,效果不错。
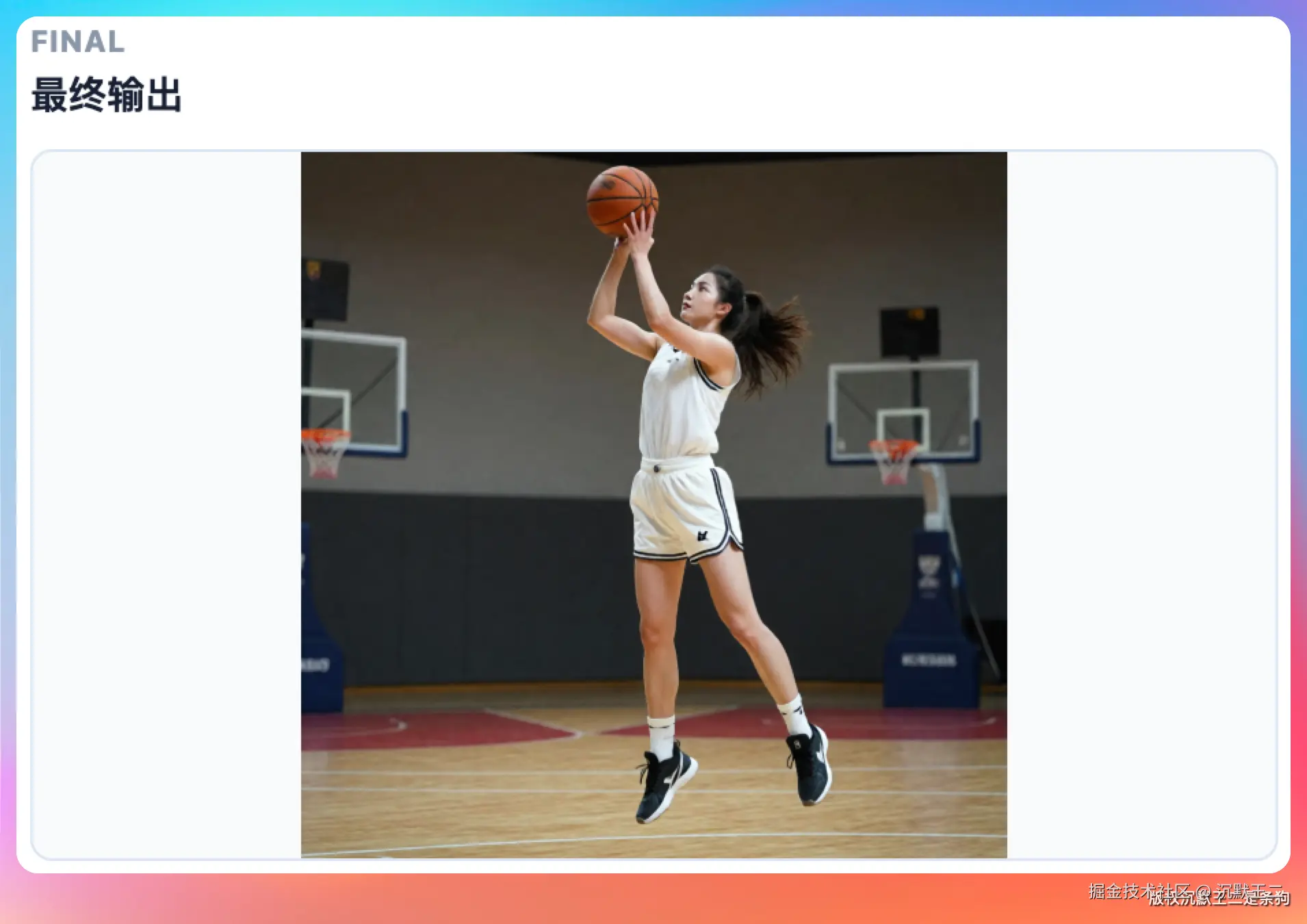
关键是整个工作流全程自动化,LLM 负责想创意、写 prompt,生图模型负责出图,不需要人在中间手动复制粘贴。
还有一个细节值得一提:阶跃星辰的生图 API 返回的图片 URL 有效期是 30 天。
如果不做持久化,30 天后图片就丢了。所以 PaiAgent 的 image_generate 节点在拿到生图结果后,会自动把图片上传到 MinIO 对象存储,返回一个永久可用的内部 URL。
04、Step 3.7 Flash + PaiCLI
PaiCLI 是我做的另一个项目,一个终端里的 AI 助手。之前它已经有了基础的联网搜索能力(智谱、SerpAPI、SearXNG 三个搜索提供商),底层模型用的是 Step 3.5 Flash。
Step 3.7 Flash 发布后,我做了两件事:升级底层模型,同时把 Step 3.7 Flash 的视觉理解和联网搜索能力组合起来,让 PaiCLI 能"看图 + 搜索"一条龙完成任务。
视觉理解 + 联网搜索
Step 3.7 Flash 的两个原生能力放在一起,会产生很有意思的化学反应。
视觉理解让模型能直接看懂图片内容------UI 界面、代码截图、架构图、报错信息,都能识别。
联网搜索让模型在推理过程中自动触发检索,获取实时信息。这两个能力组合起来,Agent 就能做到"看到一张图,理解图片内容,然后根据内容去搜索相关信息"。
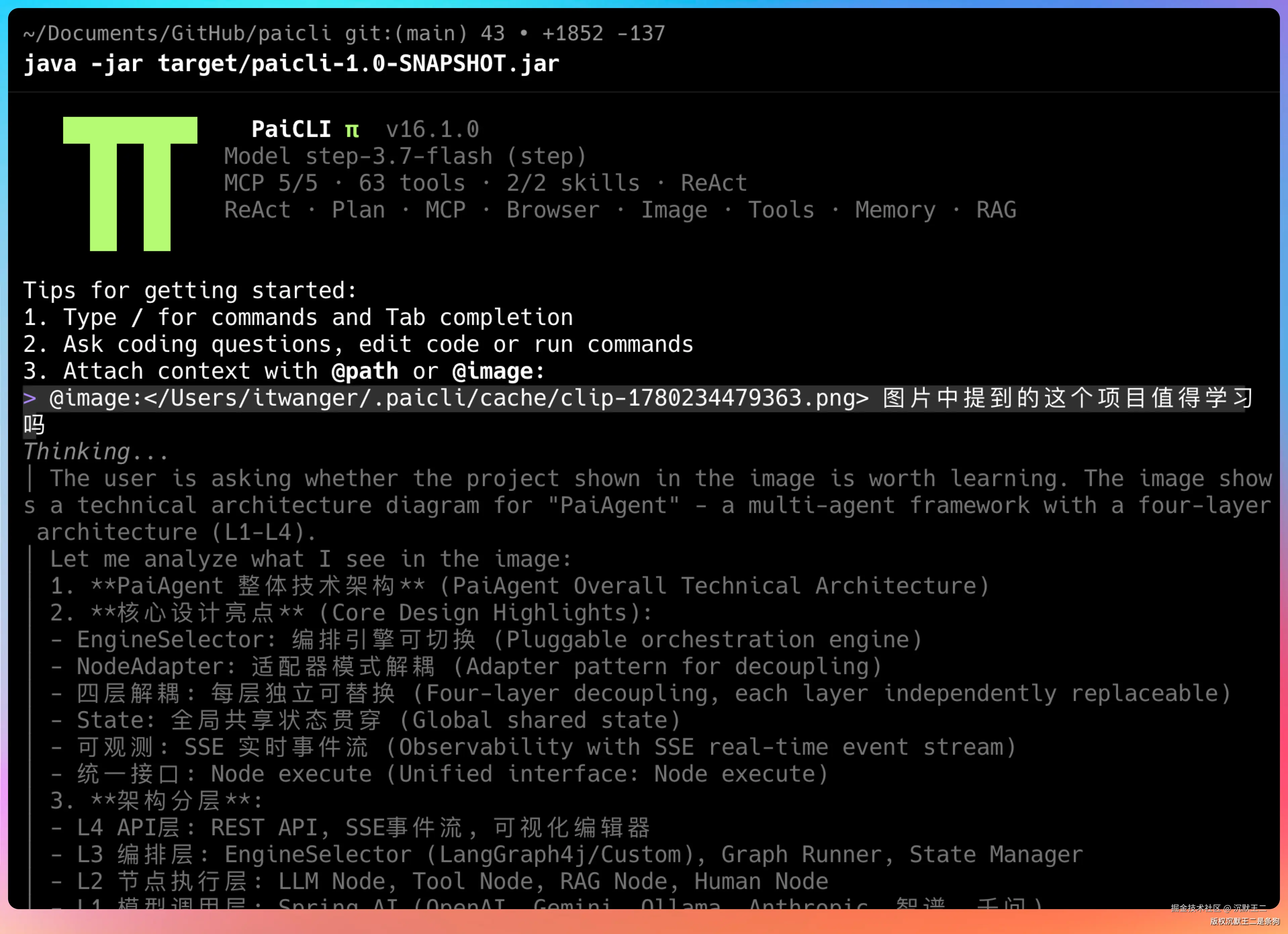
LLM 先理解图片里的内容是什么,然后再联网搜索最新的 AI Agent 技术栈,用的也是我们之前添加的 StepSearch 搜索工具。
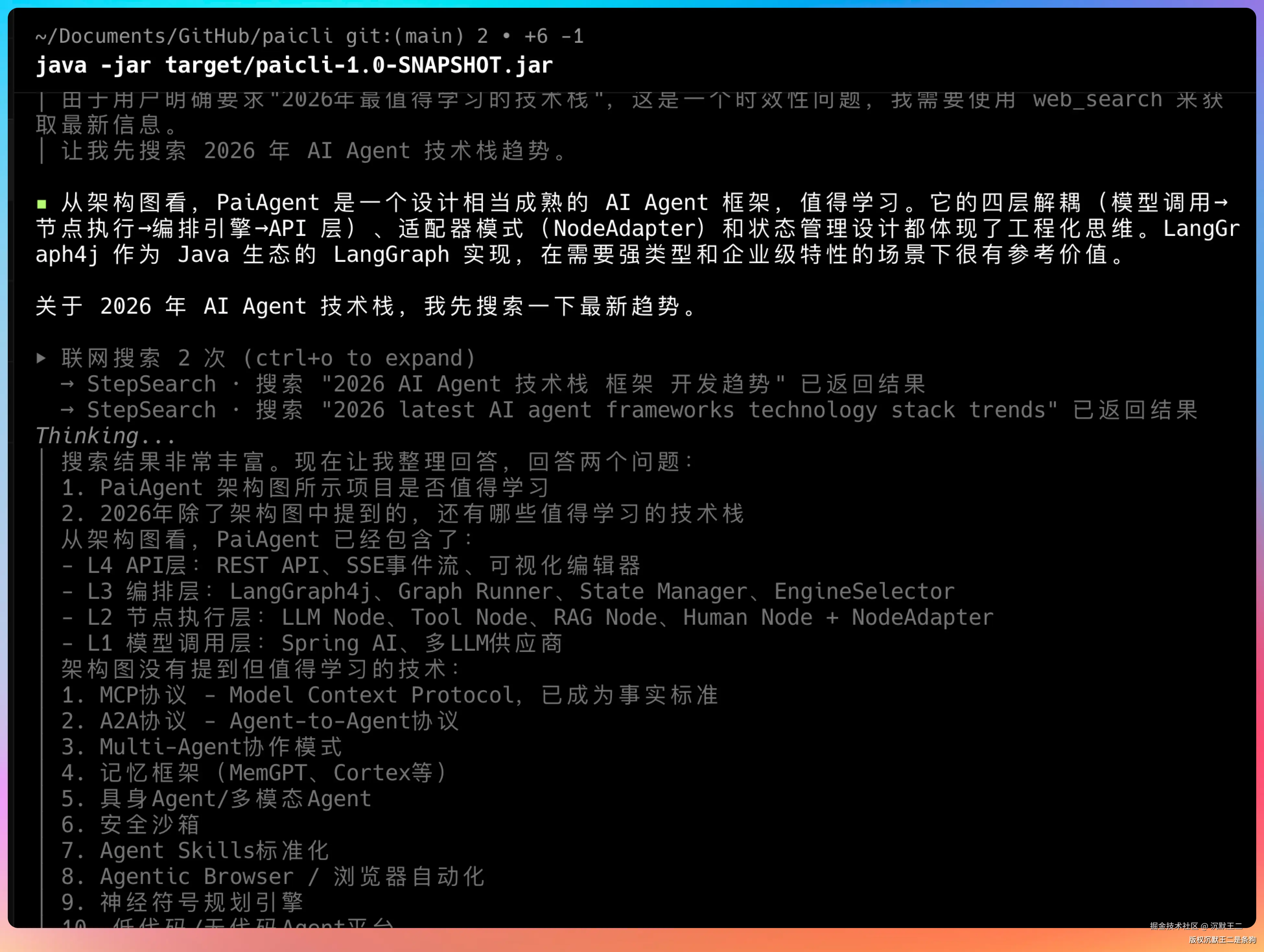
整体给的建议也非常合理。
ending
测了一天 Step 3.7 Flash,有几个感受。
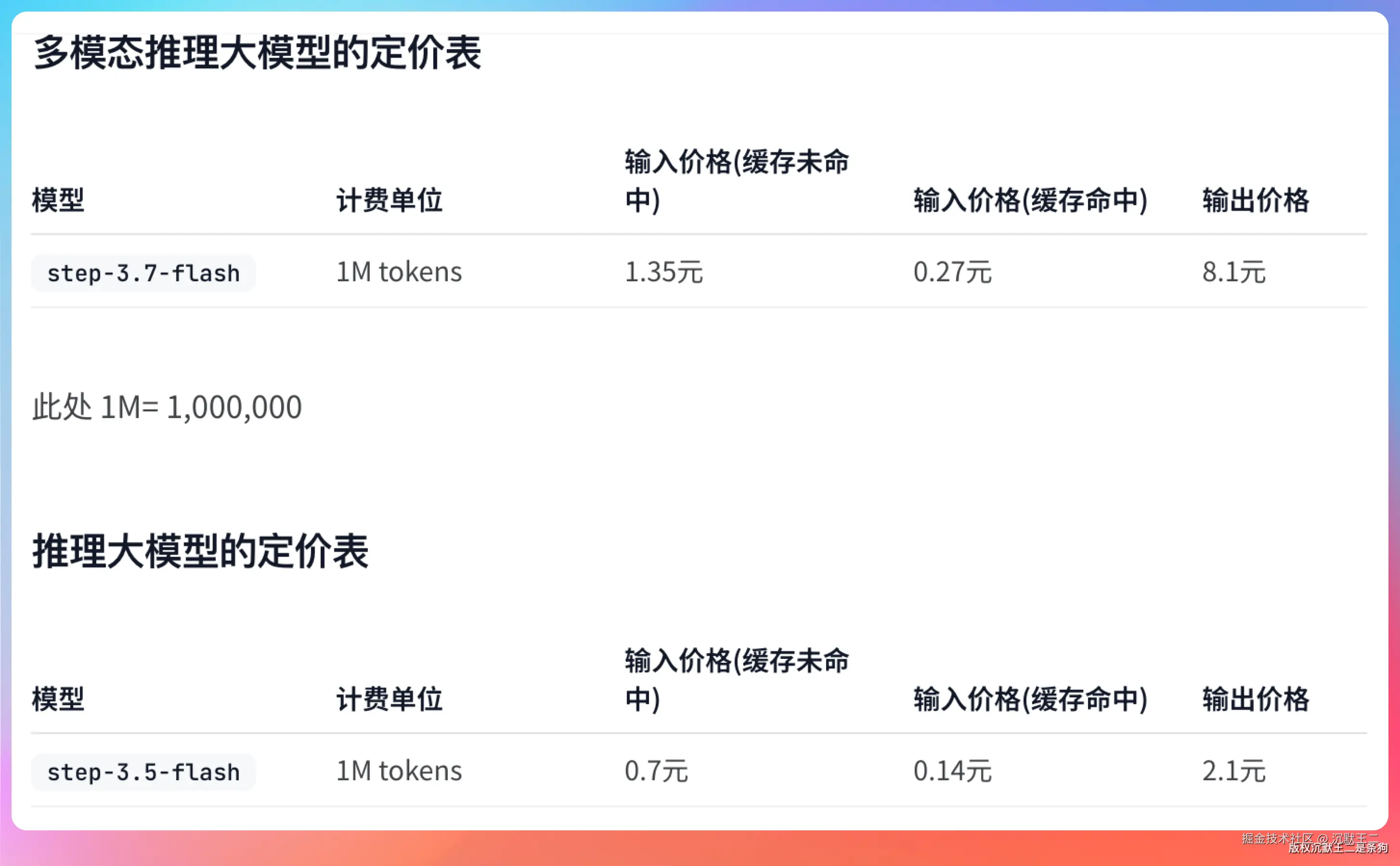
198B MoE 只激活 11B,速度够快。400 TPS 的生成速度,让 Agent Loop 里每一步都不会卡。价格够低,缓存命中只要 ¥0.27/M tokens,高频调用也不心疼。
ClawEval 67.1 的分数不是吹出来的,Tool Use 的稳定性在实际开发中确实能感受到。用 Codex + Step 3.7 Flash 写了一天代码,我认为效果是很不错的。
PaiSwitch 的意义不只是能用 Step 3.7 Flash。
它解决了 Codex 和国内大模型之间的协议差异,以后不管阶跃星辰出什么新模型,还是 DeepSeek 出 V5,都可以一键切过去。不用再等 Codex 官方适配,自己动手就行。
【好的工具除了给我们多一个选择,还能让每个选择都能提高我们的生产力。】
我们下期见。