1. 算力单位
P= Peta
完整单词: Petaflops
- Peta: 10^15 千万亿
- flops: floating-point operations per second 每秒浮点运算次数
算力单位从小到大:
- K= Kilo 千
- M = Mega(百万)
- G = Giga(十亿)
- T = Tera (万亿)
- P = Peta(千万亿)
- E = Exa (百亿亿)
换算
1P = 1 Pflops = 1000Tflops = 1 千万亿次浮点运算/秒
2. 什么叫浮点数? 为什么算力要看浮点,不看整数?
浮点数就是计算机里面用来表示小数的一种数据类型。
FP = Float-Point 浮点数。
- 整数: 1,2,100,-5 没有小数点
- 浮点数: 3.14,0.5,-2.13 带小数点的数
之所以叫浮点,是因为小数点位置可以浮动。
- 123.45
- 1.2345 * 10^2
- 0.12345 * 10^3 数组一样,只是小数点在飘来飘去。
现代算力强的场景,全是小数运算。
- AI 神经网络,权重全是0.001 ,0.872,-0.345 这种小数
- 游戏引擎,光照,坐标都是小数
- 科学计算:流体、气象、核模拟、仿真都是小数, 整数用不上。
3. 为什么小数在计算机世界会更强调"精度"?
在九年义务教育的认知里:
场景① π,根号2等形成的无理数, 是无限不循环小数
场景② 1/3, 1/6,1/7等形成的小数是无限循环小数
场景③ 其余的 0.1,0.2,0.3,0.314等是有限小数, 口语一般不涉及精度,保持原数
在我们10个手指头的世界中,只要小数能拆成若干个1/10,1/100,1/1000,1/10000等相加,那么就是有限小数, 参考上面的场景③。 对于上面的场景①②从进制存储的角度实质无限,我们在实践中会有精度要求。
在计算机二进制世界,存储方式类似, 有限小数的定义发生了变化:
只要小数能拆成若干个1/2,1/4,1/8,1/16等相加,那么就是有限小数。
二进制中,除1/2=0.5,1/4=0.25,1/8=0.125,1/2+1/8=0.625等在计算机中能精确存储, 其他数字(eg:0.1,0.2,0.3)都不能精确存储.
计算机存储浮点数的方式:科学计数法
数值 = 符号 * 尾数 * 2^ 指数
不能精确存储,在实践中就会引入精度的概念,
精度 = 用多少进制空间去存这个小数
- 位数越多,数字越准,越慢,越占显存;
- 位数越少,数字越糙,越快,越省显存。
3.1 双精度/单精度/半精度
1> 双精度: FP64
- 64位存一个小数
- 超级准
- 科学计算、航天、金融、物理仿真
- 缺点: 慢、吃显存、AI基本不用
2> 单精度: FP32
- 用32为存储
- 精度中上,足够准
- 传统渲染、科学计算、早期AI训练
3> 半精度: FP16
- 只用16位存储小数
- 精度变低, 速度翻倍,显存减半
- 大规模训练、 AI画图、推理
4. 针对LLM做 显存估算
我现在部署的这款模型:Qwen/Qwen3.5-122B-A10B-GPTQ-Int4是中等旗舰模型的量化版本。
4.1 参数总量:122B,MOE专家架构,其中激活参数为 10B。
这里面B= billon(10亿),数量单位,意味着有10亿个权重值。
在神经网络中, 参数就是模型在不断学习过程中不断调整的权重(决定神经元之间的连接强度)和偏置(每个神经元偏移量)。
MoE专家架构,总参数是122B, 激活参数10B(每次推理用到的参数),但是总参数要都加载进显存。
4.2 KV Cache 是可变成本
当生成文本时,模型每生成一个token,都需要知道之前所有的token的Key和Value(注意力机制中的KV矩阵)。 如果不做缓存,每次生成都要重新计算之前所有token的K和V,计算量会随序列长度呈平方型增长 (1+(n-1) * (n-1))/2, 输出第n个token是O(n^2)的时间复杂度。
KV Cache用空间换时间,把之前计算好的所有token的K/V存下来,计算第n个token时时间复杂度是O(n)。
单个Token的KV Cache空间大小, 对于Qwen3.5-122B-A10B模型,大约是256KB。
| 参数 | 值 | 说明 |
|---|---|---|
| 层数 (num_layers) | 64 | Transformer 层总数 |
| 隐藏层维度 (hidden_size) | 8192 | 每层的特征维度 |
| 注意力头数 (num_attention_heads) | 64 | Query 头数 |
| KV 头数 (num_key_value_heads) | 8 | Key/Value 头数(GQA 架构) |
| 头维度 (head_dim) | 128 | 每个头的维度 |
ini
# 单个 token 的 KV Cache 大小(字节)
per_token_kv_cache = 2 * num_layers * num_key_value_heads * head_dim * bytes_per_element
# 代入 Qwen3.5-122B-A10B 参数:
per_token_kv_cache = 2 * 64 * 8 * 128 * 2 # FP16 = 2字节
= 2 * 64 * 8 * 128 * 2
= 262,144 字节
≈ 0.256 MB / token① 上下文长度
决定了大模型单次任务能处理的最大开销, 与KV Cache的占用大小是线性关系。
上下文限制的作用范围是单轮对话(每次请求的输入输出token总长度),Qwen3.5-122B-A10B原生支持 262,144 tokens(256k tokens)
不同上下文的显存占用:
| 上下文长度 | KV Cache 显存 | 说明 |
|---|---|---|
| 2K tokens | 512 MB | 短对话场景 |
| 8K tokens | 2.05 GB | 中等对话 |
| 32K tokens | 8.19 GB | 长文档处理 |
| 64K tokens | 16.38 GB | 超长上下文 |
| 128K tokens | 32.77 GB | 极长上下文 |
| 256K tokens | 65.54 GB | 最大支持上下文 |
② 并发度
决定同时有几个任务在跑,并发请求的KV cache 是独立且隔离的。
上面说了AI模型一般是半精度FP16, 也就是两字节,那么122B满血版 122B * 2byte=230GiB,
Q4量化模型,权重值大约占据122B* 0.5=60GB显存,加上可变的KV Cache(受到上下文长度、并发度影响)。
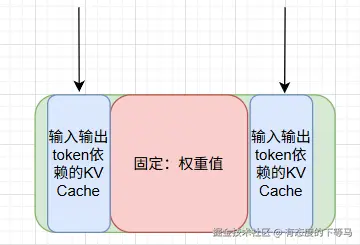
在寸土寸金的GPU机器上,vllm部署据此也有一些调参要求。
css
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3.5-122B-A10B-GPTQ-Int4 --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --reasoning-parser qwen3 --enable-auto-tool-choice --tool-call-parser qwen3_coder --quantization moe_wna16 --gpu_memory_utilization 0.85 --max_num_seqs 64