大多数Java项目在调第三方HTTP接口时,会封装一个工具类,里面用懒加载或者静态变量持有一个全局的OkHttpClient实例。所有业务方调第三方接口,都走这一个实例。
平时这么用没什么问题。OkHttpClient本身是线程安全的,官方也推荐复用实例来减少连接开销。
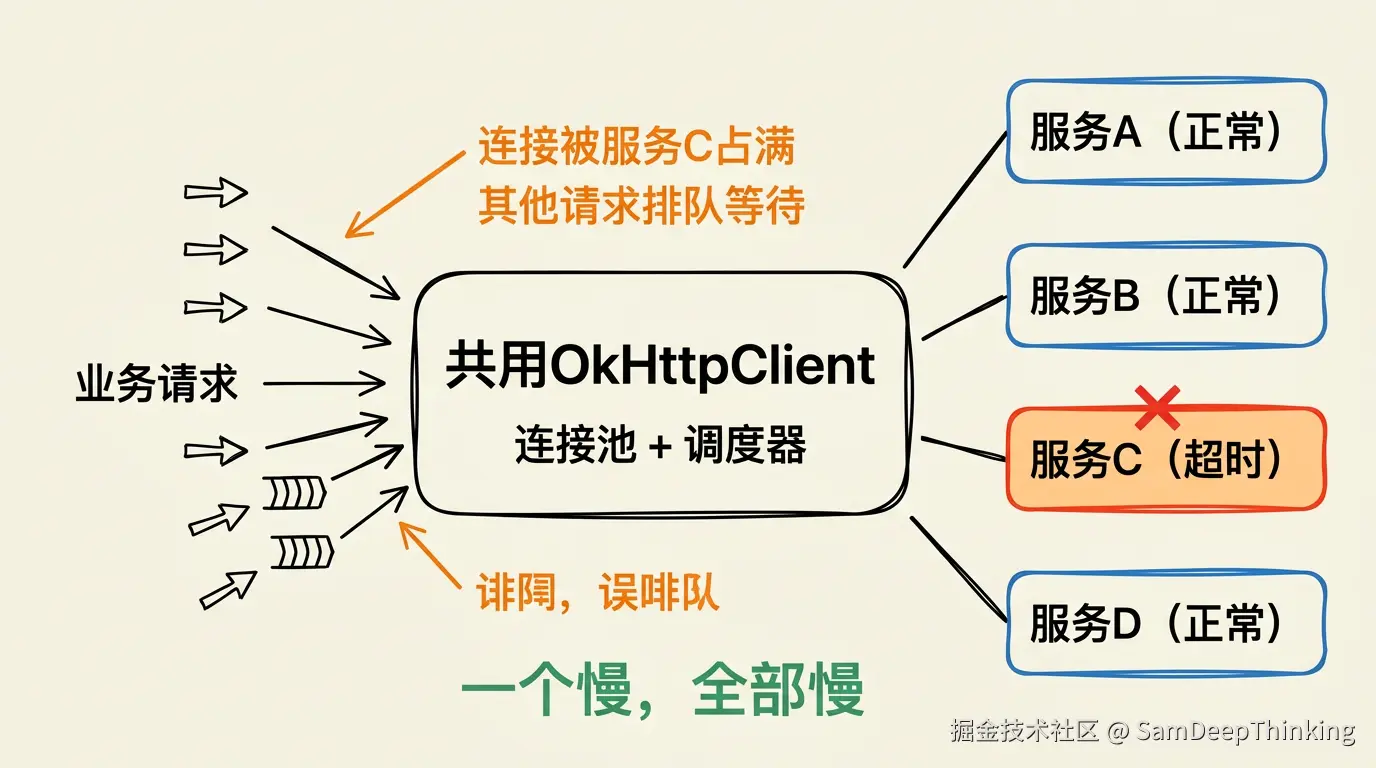
问题在于,第三方系统是不可控的。你对接的第三方可能有5个、10个,每个第三方的稳定性、响应速度、限流策略都不一样。某天其中一个第三方的接口响应变慢了,从正常的几百毫秒变成了十几秒甚至超时,这时候事情就不是「那一个接口变慢了」这么简单。因为所有第三方的HTTP调用共用同一个OkHttpClient,共享同一个连接池和调度器,一个慢接口会把连接资源占住,其他正常的第三方接口也跟着受影响。
下面先讲共用HTTPClient在底层为什么会互相影响,再讲生产环境里怎么按业务场景做隔离配置,最后附一张可以直接拿来用的配置速查表。
共用一个HTTPClient,问题出在哪
要理解为什么一个慢接口会拖垮其他接口,得看OkHttpClient内部的两个关键组件:Dispatcher和ConnectionPool。
Dispatcher的调度机制
OkHttp用Dispatcher来管理所有HTTP请求的并发调度。每个OkHttpClient实例有自己的Dispatcher,Dispatcher里有两个核心参数:
- maxRequests:最大并发请求数,默认64
- maxRequestsPerHost:单个主机的最大并发请求数,默认5
当你用enqueue()发起异步请求时,Dispatcher会检查当前正在执行的请求数是否超过maxRequests,以及目标主机的并发数是否超过maxRequestsPerHost。超过了就排队等着。
如果所有第三方调用共用同一个OkHttpClient,那它们也共用同一个Dispatcher。假设你对接了A、B、C三个第三方,maxRequests是64。正常情况下,三家的请求加起来可能也就占用十几个并发位,完全够用。一旦A的接口变慢了,本来几百毫秒就能完成的请求现在要等十几秒才释放,正在执行的请求数会迅速累积。当累积到64个时,B和C的新请求就算目标主机完全正常,也得排队。
用同步调用execute()的情况更直接。execute()会阻塞调用线程直到响应返回,如果A的接口超时时间设成60秒,调用线程就被占住60秒。你的业务线程池(比如Tomcat的工作线程)被A的慢请求一个一个吃掉,剩下给B、C的线程越来越少。
ConnectionPool的连接争用
OkHttpClient的ConnectionPool管理着底层的TCP连接复用。默认配置是最多保持5个空闲连接,空闲超过5分钟回收。
ConnectionPool也是跟OkHttpClient实例绑定的。多个第三方共用一个OkHttpClient,就是共用一个连接池。连接池里的连接按目标主机区分,A的连接不能给B用。当A的接口变慢,A的连接长时间被占用不释放,连接池里有效的空闲连接数下降。如果这时候B和C的请求量上来了,可能需要频繁创建新连接,增加了额外的TCP握手开销和延迟。
这件事可以用一个简单的比喻来理解:一家公司只有一个共用的快递收发室,所有部门的快递都在这里处理。某天有个部门寄了一批需要特殊包装的大件,每件都要处理很久,把收发室的工位全占了。其他部门正常的快递送到了,也只能在门口排队等着。问题不在大件本身,在于所有部门共用了同一个收发室。
舱壁隔离模式
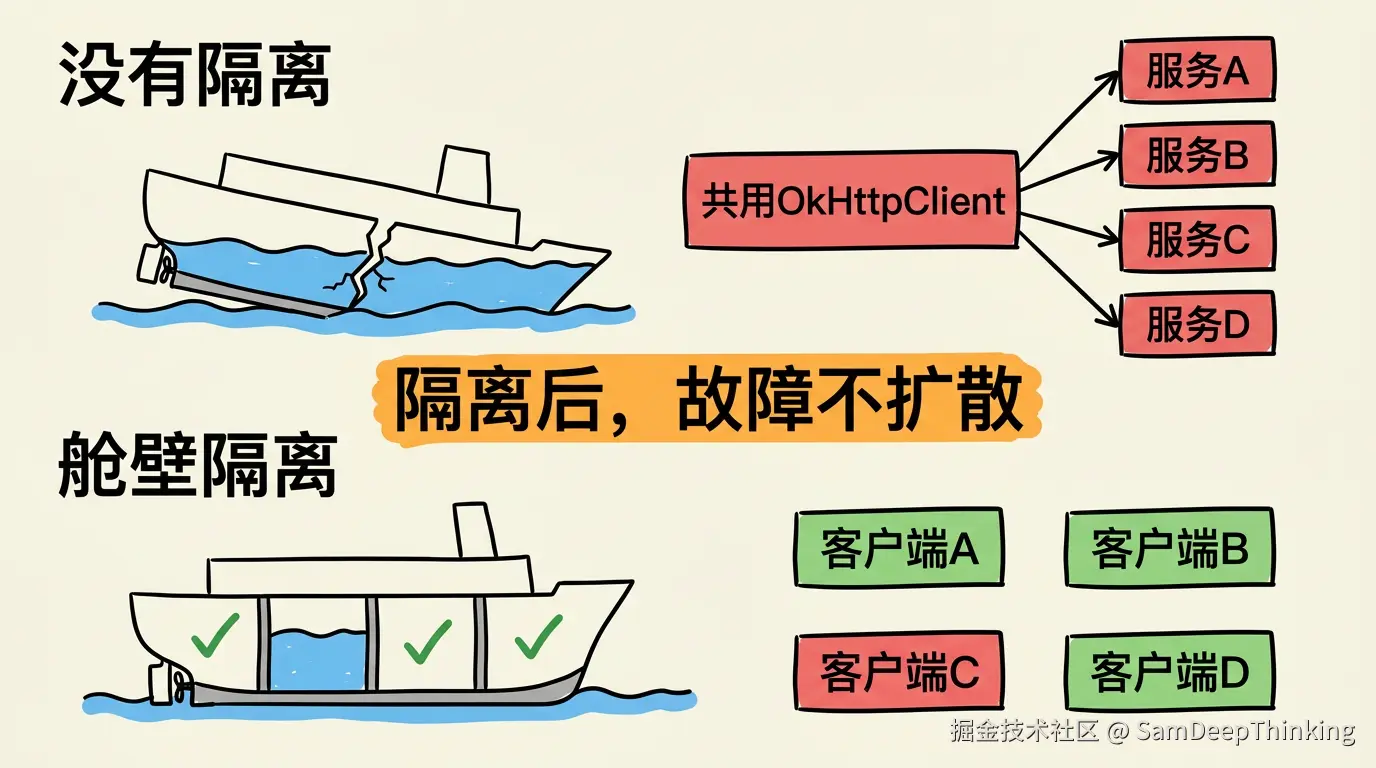
这个问题在分布式系统领域有一个对应的解决思路,叫Bulkhead模式,中文一般翻译成舱壁隔离。
这个概念来自造船工程。远洋船舶的船体内部被多道水密隔壁分成若干个独立的隔舱。某个隔舱被撞破进水后,关闭水密门,水只会灌满这一个隔舱,其他隔舱不受影响,船还能继续航行。如果没有这些隔壁,一个破口就可能导致整船进水。
Netflix在构建微服务架构时,把这个思路搬到了软件工程里。他们在2012年开源的Hystrix框架,核心设计目标之一就是隔离。具体做法是:为每一个外部依赖分配独立的线程池,每个线程池有自己的并发上限。某个依赖变慢了,最多把自己那个线程池耗尽,不会影响其他依赖的线程池。Hystrix的GitHub Wiki里写得很清楚:
隔离是防止单个依赖故障扩散到整个系统的关键机制。
Hystrix做的是调用层的线程池隔离,而OkHttpClient的独立配置是在连接层做隔离。两者解决的是同一个问题:防止一个慢依赖把其他依赖拖下水。连接层隔离的好处是粒度更细,可以针对不同第三方的特点(响应时间、并发量、稳定性、限流策略)分别配置超时时间和并发上限。
共用HTTPClient的风险属于典型的隐性风险。平时系统运行正常,所有接口响应都很快,你根本看不出哪里有问题。只有当某个第三方出故障时,隐藏的耦合关系才暴露出来,影响面远超预期。项目管理里有个说法叫冰山下的风险,指的就是这类东西:最危险的不是你已经识别出来的风险,而是那些你觉得不会出事的隐性依赖。
生产环境的HTTPClient隔离方案
做法是在Spring的配置类里为每个第三方定义独立的OkHttpClient Bean,每个Bean有自己的超时时间、并发上限和连接池配置。
下面是一个实际配置示例:
Java
@Configuration
public class MyHttpConfig {
// 数据同步服务:批量调用,对延迟不太敏感
@Bean("syncServiceClient")
public OkHttpClient syncServiceClient() {
Dispatcher dispatcher = new Dispatcher();
dispatcher.setMaxRequests(25);
dispatcher.setMaxRequestsPerHost(25);
return new OkHttpClient.Builder()
.dispatcher(dispatcher)
.connectTimeout(60, TimeUnit.SECONDS)
.readTimeout(60, TimeUnit.SECONDS)
.writeTimeout(60, TimeUnit.SECONDS)
.connectionPool(new ConnectionPool(5, 5, TimeUnit.SECONDS))
.build();
}
// 核心业务接口:高频调用,对吞吐量要求高
@Bean("bizServiceClient")
public OkHttpClient bizServiceClient() {
Dispatcher dispatcher = new Dispatcher();
dispatcher.setMaxRequests(50);
dispatcher.setMaxRequestsPerHost(50);
return new OkHttpClient.Builder()
.dispatcher(dispatcher)
.connectTimeout(60, TimeUnit.SECONDS)
.readTimeout(60, TimeUnit.SECONDS)
.writeTimeout(60, TimeUnit.SECONDS)
.build();
}
// 第三方签名服务:调用频率低,对方服务器性能有限
@Bean("signServiceClient")
public OkHttpClient signServiceClient() {
Dispatcher dispatcher = new Dispatcher();
dispatcher.setMaxRequests(10);
dispatcher.setMaxRequestsPerHost(5);
return new OkHttpClient.Builder()
.dispatcher(dispatcher)
.connectTimeout(60, TimeUnit.SECONDS)
.readTimeout(60, TimeUnit.SECONDS)
.writeTimeout(60, TimeUnit.SECONDS)
.build();
}
// 通用客户端:偶尔调用的低频接口
@Bean("commonClient")
public OkHttpClient commonClient() {
return new OkHttpClient.Builder()
.connectTimeout(60, TimeUnit.SECONDS)
.readTimeout(60, TimeUnit.SECONDS)
.writeTimeout(60, TimeUnit.SECONDS)
.build();
}
}每个策略类通过@Resource指定Bean名称注入对应的客户端:
Java
@Component
public class SignServiceStrategy {
@Resource(name = "signServiceClient")
private OkHttpClient okHttpClient;
// 业务逻辑...
}这里用@Resource(name="xxx")而不是@Autowired,是因为同一个类型有多个Bean,@Autowired按类型注入会报歧义错误,@Resource按名称注入更明确。
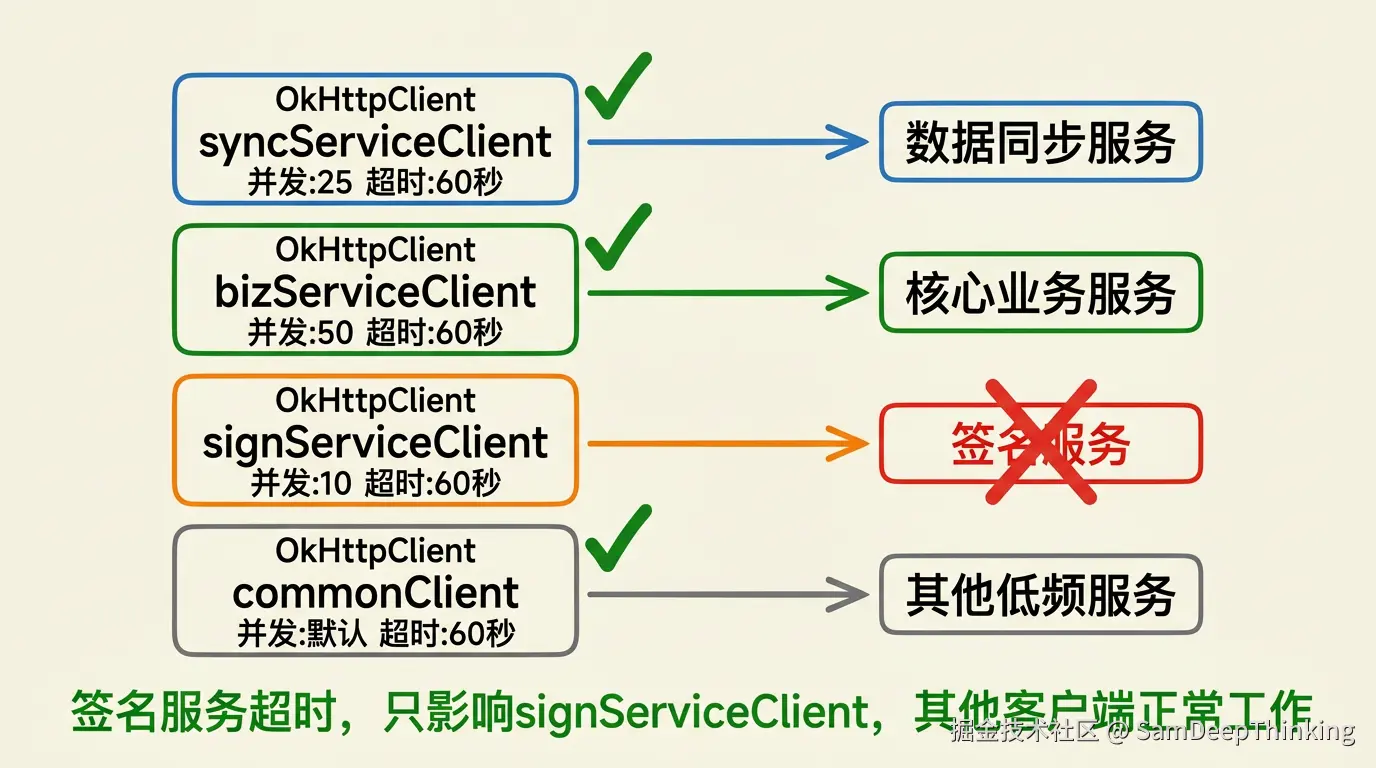
四个客户端的配置差异和背后的考虑:
| 客户端 | 最大并发 | 单主机并发 | 超时时间 | 配置依据 |
|---|---|---|---|---|
| syncServiceClient | 25 | 25 | 60秒 | 批量数据同步,并发适中,超时放宽 |
| bizServiceClient | 50 | 50 | 60秒 | 高频业务接口,需要较大吞吐量 |
| signServiceClient | 10 | 5 | 60秒 | 对方有限流(10次/秒),2台机器各分5 |
| commonClient | 默认64 | 默认5 | 60秒 | 低频偶尔调用,用默认值即可 |
这里要特别说一下signServiceClient的配置。它的maxRequestsPerHost设成5,不是因为我们这边处理不过来,而是对方的签名服务有限流策略,每秒最多接受10个请求。我们部署了2台机器,平摊下来每台限制5个并发,正好卡在对方的限流阈值以内。如果不做这个限制,高峰期我们的请求超过对方限流阈值,会被直接拒绝,反而要多一轮重试。
很多项目里同时存在另一种写法:一个静态工具类,里面用懒加载持有一个全局OkHttpClient,所有业务方通过静态方法调用。这种工具类在调内部服务时问题不大,因为内部服务的稳定性是可控的。拿它去调第三方接口,就存在上面说的连带风险。如果你的项目里有这种工具类,建议把第三方调用逐步迁移到独立配置的客户端上,内部服务的调用可以继续用工具类。
在系统设计阶段就把HTTPClient按业务场景拆开,改个配置类的事,成本很低。等线上出了问题再来拆,要改代码、要回归测试、要紧急发版,成本是设计阶段的十倍不止。项目管理里讲「源头治理,一次把事情做对」,说的就是这类情况。很多技术方案的返工,不是方案本身不好,是初始设计时没考虑隔离性。
配置参数怎么定
独立配置HTTPClient不难,难的是每个参数应该设成多少。上面的示例里所有客户端的超时时间都设成了60秒,这在实际生产环境中并不合理,只是一个偏保守的起步值。下面讲讲每个参数的调优思路。
超时时间
超时时间不能一刀切。每个第三方接口的正常响应时间差异很大,有的几十毫秒就返回,有的要跑几秒。
connectTimeout(连接超时)控制的是TCP握手的等待时间。如果对方服务器在同一个内网或者延迟很低的云环境,3到5秒足够了。跨公网调海外服务的可以适当放宽。
readTimeout(读超时)是重点。它控制的是连接建立后,等待对方返回数据的时间。这个值应该根据对方接口的实际响应时间来定。一个比较靠谱的做法是:看对方接口的P99延迟,在这个基础上乘以2到3倍作为readTimeout。比如对方接口P99是2秒,readTimeout设成5到6秒比较合理。
如果统一设成60秒,意味着某个接口真出问题时,你的调用线程要被阻塞60秒才能释放。60秒内这个连接一直被占用,Dispatcher的并发位也一直被占着。超时时间越长,故障时的影响持续时间越长。
writeTimeout(写超时)一般跟请求体大小有关。普通的JSON请求5到10秒够用,上传文件的接口可以设大一些。
并发上限
maxRequests和maxRequestsPerHost的设置取决于两个因素:你这边的业务量,以及对方能承受多少。
自己这边的业务量可以通过监控看高峰期每秒发多少请求到这个第三方。maxRequests设成高峰QPS乘以平均耗时(秒),再留一定的余量。
对方的承受能力要看对方的限流策略。很多第三方API有明确的限流文档,比如每秒10次、每分钟100次。maxRequestsPerHost不能超过对方的限流阈值,否则请求会被拒绝。如果你有多台机器,要把限流阈值平摊到每台机器上。
连接池大小
ConnectionPool的maxIdleConnections(最大空闲连接数)建议和maxRequestsPerHost对齐或略大一些。空闲连接太少,高并发时频繁创建新TCP连接,增加延迟。空闲连接太多,白占资源。keepAliveDuration保持默认的5分钟一般够用,除非对方的服务器不支持长连接或者主动断开连接很快。
HTTPClient隔离配置速查表
| 配置项 | 含义 | 推荐值 | 调优依据 |
|---|---|---|---|
| connectTimeout | TCP建连超时 | 3~5秒 | 对方服务器的网络距离 |
| readTimeout | 等待响应超时 | 对方P99延迟 x 2~3 | 正常响应时间加上缓冲 |
| writeTimeout | 发送请求体超时 | 5~10秒 | 请求体大小,上传文件适当放宽 |
| maxRequests | 客户端最大并发 | 高峰QPS x 平均耗时 + 余量 | 自身业务量 |
| maxRequestsPerHost | 单主机最大并发 | 不超过对方限流阈值 / 机器数 | 对方的限流策略 |
| maxIdleConnections | 最大空闲连接数 | 大于等于maxRequestsPerHost | 避免高并发时频繁建连 |
| keepAliveDuration | 空闲连接保活时长 | 5分钟(默认值) | 对方是否支持HTTP长连接 |
什么时候需要独立配置
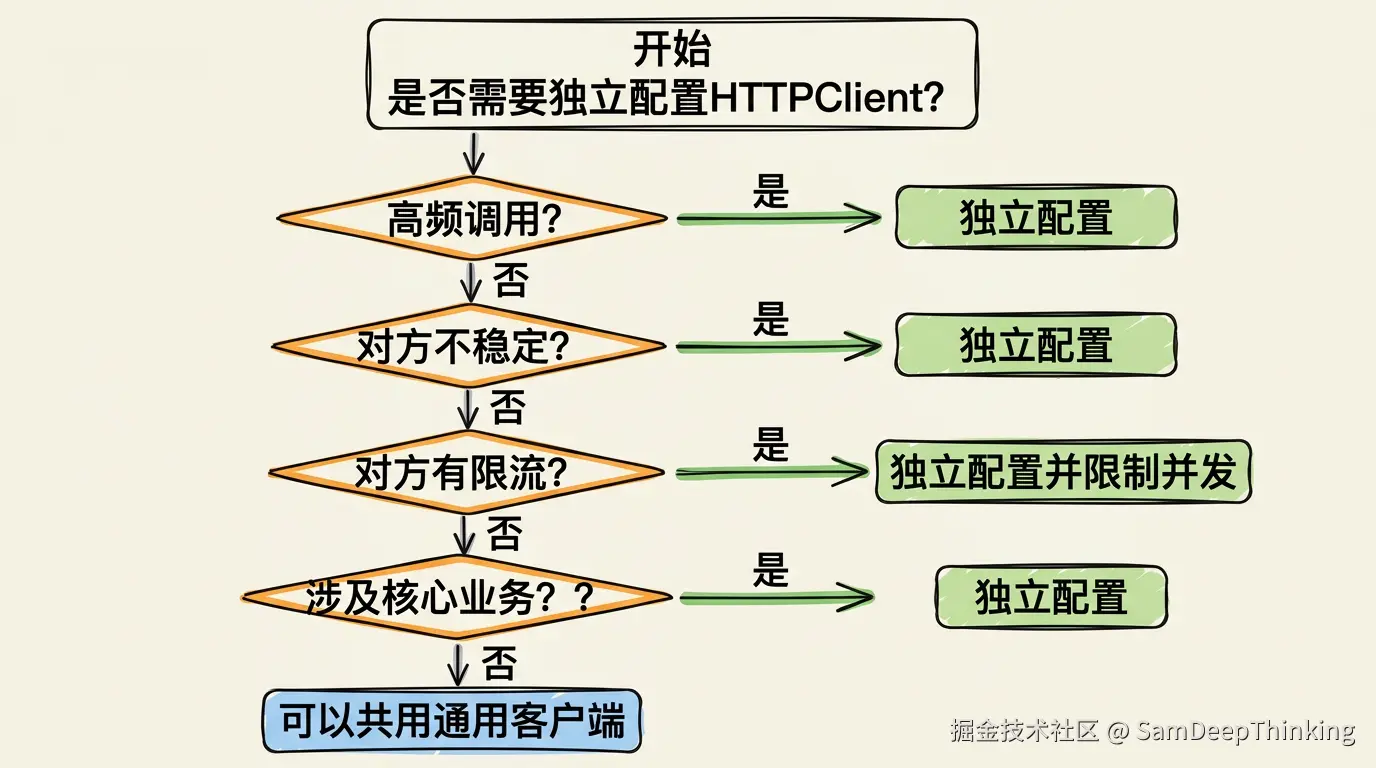
不是所有第三方调用都需要独立配置一个OkHttpClient。判断标准:
- 调用频率高,高峰期每秒有几十甚至上百个请求 → 独立配置
- 对方接口不稳定,历史上出现过超时或波动 → 独立配置
- 对方有明确的限流策略 → 独立配置,并用maxRequestsPerHost控制并发
- 接口涉及核心业务(支付、签名、数据同步),不能被其他接口影响 → 独立配置
- 偶尔调用一次的低频接口 → 可以共用一个通用客户端
配合熔断和降级
HTTPClient隔离解决的是连接层的故障传导问题。业务层面还可以再加一层保护:熔断和降级。
隔离之后有一个好处:可以精准地针对单个第三方做熔断。如果所有第三方调用共用一个HTTPClient,你很难判断是哪个第三方在拖后腿。隔离之后,每个第三方的错误率、超时率是独立统计的,某个第三方的失败率超过阈值就熔断这一个,其他第三方不受影响。这跟灰度发布的思路是一样的:控制影响范围,把风险锁定在最小的单元里。
Resilience4j提供了Bulkhead组件,可以在HTTPClient隔离之上再加一层调用层的隔离。它有两种模式:线程池隔离(为每个依赖分配独立线程池)和信号量隔离(用信号量控制并发数,不额外创建线程)。对于大多数场景,OkHttpClient的独立配置已经够用了。如果你的系统对隔离性要求非常高,或者除了HTTP之外还有其他类型的外部依赖(比如RPC、数据库),可以考虑引入Resilience4j做更细粒度的控制。
降级策略也值得提前想好。当某个第三方被熔断后,业务层应该有兜底方案。比如签名服务不可用时,队列里的签名请求可以暂存稍后重试;数据同步服务超时时,先写本地缓冲区等恢复后补推。降级方案没有通用模板,得根据具体业务场景来设计,这里只是提供一个思考方向。
小结
HTTPClient隔离就是改个配置类的事。这件事真正值得聊的,是背后的设计思路。
做了这么多年项目,我越来越觉得,很多线上故障的根源不是某个组件出了问题,而是多个组件之间存在不该有的耦合。HTTPClient是一个典型的例子。数据库连接池也是,如果一个应用里所有业务模块共用同一个连接池,某个慢SQL把连接占满了,其他模块的正常查询也会受影响。线程池同理,消息队列的Topic隔离同理。判断的标准是一样的:如果两个业务模块共享同一个资源,其中一个模块的异常行为会影响到另一个模块,就应该考虑隔离。
这和项目管理中的思路也是相通的。遇到紧急需求时,有经验的管理者会组建一个独立的小分队,给它独立的资源和排期,不让紧急需求打乱主团队的正常迭代节奏。技术架构上的资源隔离,和管理上的团队隔离,解决的是同一类问题:防止一个局部的异常扩散成全局的混乱。
在设计阶段多花10分钟做隔离配置,比出了线上事故后花10个小时排查改造,要值得得多。
希望这篇内容可以帮到你。
参考的内容
最近在知乎出了秒杀专栏,感兴趣的可以订阅一下。至于知识星球的,可以搜:
- 老码头的技术浮生录
它是一个能实际帮你解决难题的星球。有问题的,找知心的Sam哥,支持无限次语音一对一解决你遇到的难题。另外后续我新写的所有对外的付费专栏,在星球内都是免费的,且可以拿到所有源代码。
我的知乎账号:
- SamDeepThinking