大语言模型(LLM)基于无状态设计,每次推理独立进行,不具备跨会话记忆能力。通过 Mem0 框架管理记忆生命周期,结合 Elasticsearch 提供向量检索能力,可以构建支持记忆持久化存储、语义检索和智能更新的生产级 AI 记忆系统。
适用场景
-
长交互信息处理:在长对话场景中避免上下文遗忘。
-
跨会话上下文保持:Agent 需要了解用户的交互历史和个性化偏好。
-
记忆持久化管理:将对话中的关键信息结构化存储。
-
多 Agent 协同:多个 Agent 共享同一记忆存储。
以下两个场景进一步说明记忆系统的价值。
电商智能导购
当用户开启新会话咨询"洗碗机需要支持软水盐自动提醒"时,若系统不支持跨会话记忆,则无法激活首次咨询中提出的"家里有婴儿,水质安全优先"的约束。默认的上下文截断机制会将其降级为孤立问答,而记忆系统可以通过向量索引,将"婴儿家庭"标签持久化绑定至用户 ID,并在新会话中以结构化记忆片段注入上下文,实现跨会话意图继承。
智能 AI 客服
客户投诉"上个月购买的扫地机器人 APP 无法连接",在缺乏记忆系统时,系统需重复确认:"您购买的是哪款?序列号是多少?"------重复询问会严重影响客户体验,而且每轮交互都在消耗宝贵的上下文空间。而记忆系统可以将用户设备 ID、历史工单信息、已尝试解决方案等作为可版本化记忆单元进行存储。新会话启动时,系统仅用少量 token 的语义查询即可精准召回结构化状态,使客服响应从"重新诊断"跃迁至"续接处置"。
方案架构
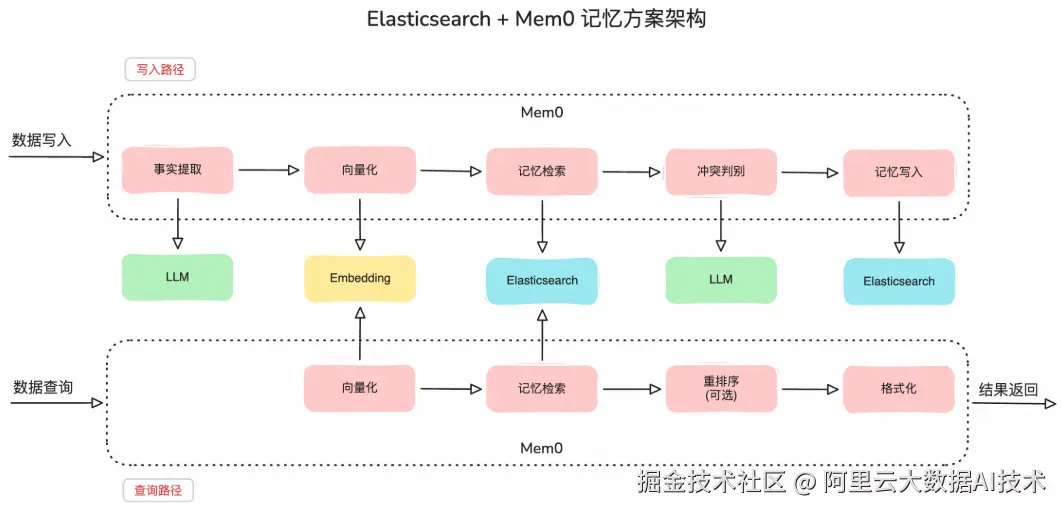
系统的核心工作流程如下:
-
事实提取:调用 LLM 对输入内容进行事实提取。
-
向量化:调用 Embedding 模型将文本转换为向量,确保语义相近的记忆在向量空间中距离相近。
-
记忆检索:调用 Elasticsearch 执行 Top-K 相似向量检索,返回最相关的记忆片段。
-
冲突判别:调用 LLM 判断对记忆执行 update、merge、ignore 或 create 操作。
-
写入执行:调用 Elasticsearch 将最新记忆持久化存储。
在检索路径中,还可以配置重排序模型(Reranker)对检索结果进行二次排序,提升召回精度。
集成案例:为 OpenClaw 接入记忆系统
OpenClaw是一个开源的个人 AI Agent 框架,它将 LLM 与操作系统、Web 访问、文件操作等能力相结合,使 AI 能够连贯执行复杂任务。OpenClaw 的原生记忆系统存在上下文长度受限、检索效率不高、不支持跨会话连续性等短板,接入 Mem0 + Elasticsearch 可以解决这些问题。
步骤一:准备 Elasticsearch
-
按照快速入门创建实例并设置登录密码。
-
配置 Kibana 公网访问白名单:
-
进入目标实例基本信息 页面,在左侧导航栏单击 配置与管理 > 可视化控制 ,在Kibana 区域单击修改配置。
-
配置Kibana公网访问白名单 :Kibana公网访问白名单默认为127.0.0.1,表示禁止所有IPv4地址访问,需要将您的实际设备IP添加到公网白名单才能访问Kibana。更多白名单配置信息,请参见通过Kibana连接集群。
-
-
返回Kibana 区域,单击公网入口 ,在Kibana登录页面,输入用户名和密码,成功登录后在 Kibana Dev Tools 中创建名为
mem0的索引:bashPUT /mem0 { "settings": { "number_of_shards": 1, "number_of_replicas": 1 } }
步骤二:部署 Mem0 Server
-
安装 Mem0 和 Flask:
pip install mem0ai flask更多安装方式请参见 Mem0 README。
-
创建 Mem0 Server 目录:
bashmkdir -p /opt/mem0-server cd /opt/mem0-server -
创建
server.py文件,内容如下,将其中的变量替换为实际值:-
$API_KEY:百炼 API Key
-
ELASTICSEARCH_HOST、ELASTICSEARCH_PORT:Elasticsearch 实例的访问地址和端口
-
ELASTICSEARCH_USER、ELASTICSEARCH_PASSWORD:Elasticsearch 的用户名和密码
kotlin# server.py - Run this as a standalone service from mem0 import Memory from flask import Flask, request, jsonify app = Flask(__name__) # Configure Mem0 here config = { "llm": { "provider": "openai", "config": { "model": "qwen-plus", "api_key": "$API_KEY", "openai_base_url": "https://dashscope.aliyuncs.com/compatible-mode/v1", } }, "embedder": { "provider": "openai", "config": { "model": "text-embedding-v4", "api_key": "$API_KEY", "openai_base_url": "https://dashscope.aliyuncs.com/compatible-mode/v1", } }, "vector_store": { "provider": "elasticsearch", "config": { "host": "$ELASTICSEARCH_HOST", # Elasticsearch 的 host "port": "$ELASTICSEARCH_PORT", # Elasticsearch 的 port "user": "$ELASTICSEARCH_USER", # Elasticsearch 的 user "password": "$ELASTICSEARCH_PASSWORD", # Elasticsearch 的 password "collection_name": "mem0", # 步骤一中创建的索引名称 } }, } memory = Memory.from_config(config) @app.route('/v1/memories', methods=['POST']) def add_memory(): data = request.json result = memory.add( messages=data['messages'], user_id=data['user_id'] ) return jsonify(result) @app.route('/v2/memories/search', methods=['POST']) def search_memories(): data = request.json result = memory.search( query=data['query'], user_id=data['user_id'] ) return jsonify(result) @app.route('/v1/memories', methods=['DELETE']) def delete_memories(): user_id = request.args.get('user_id') memory.delete_all(user_id=user_id) return jsonify({"status": "success"}) if __name__ == '__main__': app.run(host='0.0.0.0', port=8420)
-
-
启动 Mem0 Server:
vbscriptpython server.py
步骤三:配置 OpenClaw
-
在 ECS 上部署 OpenClaw。可以选择以下两种方式:
-
方式一(计算巢一键部署) :在 ECS 上部署 OpenClaw
-
方式二(Workbench 一键安装):
-
登录 ECS 控制台,选择目标实例。
-
单击远程连接 > 立即登录。
-
在 Workbench 终端工具栏点击一键管理 OpenClaw。
-
选择安装 Openclaw并确认执行。
-
-
-
登录 ECS,创建 Skill 目录:
bashmkdir -p ~/.openclaw/workspace/skills/agentic-memory-es cd ~/.openclaw/workspace/skills/agentic-memory-es -
在该目录下创建以下三个文件:
bashagentic-memory-es/ ├── manifest.json # Metadata 与 API 定义 ├── handler.py # 核心处理逻辑 └── SKILL.md # 指令文档manifest.json:
json{ "name": "agentic memory", "id": "agentic-memory-es", "version": "1.0.0", "description_for_model": "基于 Mem0 + Elasticsearch 的记忆平台。支持记忆存储 (add)、检索 (search) 、按 run id 删除 (delete_by_run_id)以及按 user id 删除(delete_by_user_id)。", "description_for_human": "基于阿里云 Elasticsearch 驱动的 Agent 记忆平台。", "auth": { "type": "token", "token_header": "Authorization", "token_prefix": "Token" }, "api": { "type": "python", "main_file": "handler.py", "functions": [ { "name": "add", "description": "从会话中提取事实,用户偏好或习惯并进行持久化。", "parameters": { "type": "object", "properties": { "user_id": { "type": "string", "description": "user id" }, "context": { "type": "string", "description": "会话内容" } }, "required": ["user_id", "context"] } }, { "name": "search", "description": "检索用户级别的历史记忆(跨会话)。", "parameters": { "type": "object", "properties": { "user_id": { "type": "string", "description": "user id" }, "query": { "type": "string", "description": "检索条件" } }, "required": ["user_id", "query"] } }, { "name": "delete_by_run_id", "description": "清空 run id 对应的历史记忆。", "parameters": { "type": "object", "properties": { "run_id": { "type": "string", "description": "run id" } }, "required": ["run_id"] } }, { "name": "delete_by_user_id", "description": "清空 user id 对应的历史记忆。", "parameters": { "type": "object", "properties": { "user_id": { "type": "string", "description": "user id" } }, "required": ["user_id"] } } ] } }将
$Mem0_HOST替换为步骤二中 Mem0 Server 的实际地址:-
如果 Mem0 Server 和 OpenClaw 在同一台 ECS,使用
http://127.0.0.1:8420 -
如果在不同机器,使用 Mem0 Server 的内网或公网 IP 地址
pythonimport json import subprocess HOST = "$Mem0_HOST" def _run_safe_curl(url, payload, method='POST'): if payload is not None: input_data = json.dumps(payload, ensure_ascii=False) else: input_data = "" cmd = [ "curl", "-s", "-X", method, url, "-H", "Content-Type: application/json", "--data-binary", "@-", "--max-time", "15", "--no-buffer" ] try: input_data = json.dumps(payload) result = subprocess.run( cmd, input=input_data, capture_output=True, text=True, check=True, encoding='utf-8' ) output = result.stdout.strip() if not output: return {"status": "success"} return json.loads(output) except subprocess.CalledProcessError as e: return {"error": f"Curl command failed: {e.stderr}"} except Exception as e: return {"error": str(e)} def add(user_id, context): url = f"{HOST}/v1/memories" payload = { "messages": [ {"role": "user", "content": context} ], "user_id": str(user_id) } return _run_safe_curl(url, payload, method='POST') def search(user_id, query): url = f"{HOST}/v2/memories/search" payload = { "query": query, "user_id": str(user_id) } return _run_safe_curl(url, payload, method='POST') def delete_by_run_id(run_id): url = f"{HOST}/v1/memories?run_id={run_id}" return _run_safe_curl(url, payload=None, method='DELETE') def delete_by_user_id(user_id): url = f"{HOST}/v1/memories?user_id={user_id}" return _run_safe_curl(url, payload=None, method='DELETE')markdown--- name: agentic memory description: 基于 Mem0 + Elasticsearch 的记忆平台。 allowed-tools: - add - search - delete_by_run_id - delete_by_user_id metadata: category: memory provider: elasticsearch --- # Instructions 你现在已拥有由 Elasticsearch 驱动的记忆存储。该 skill 集成了 Mem0 + Elasticsearch 服务,为 OpenClaw 提供长期记忆能力,取代原生.md文件存储,它能够实现对用户偏好、事实记忆和事件关系的精确提取及毫秒级检索,支持跨会话的知识持久化。请遵循以下原则: 1. 主动记忆:捕捉核心事实(身份、技能)或明确偏好(习惯、禁忌)。 - 用户提到"我正在开发 Agent 助手"时,调用 add。 - 用户表示偏好"我喜欢先计划好再开始执行"、"我在工作的时候不喜欢被打扰",调用 add。 2. 上下文检索:启动新任务或追溯历史时,调用 search 获取记忆,确保对话连贯。 3. 记忆遗忘:用户放弃了某项决策(例如"我不想再纠结这个问题了"),调用 delete_by_run_id。删除 run id 对应记忆。 4. 记忆清除:用户决定清除所有记忆,调用 delete_by_user_id。删除 user id 对应记忆。 # Tools ## Memory Management (Mem0 + Elasticsearch) 该工具集提供基于 Mem0 + Elasticsearch 的记忆能力,使智能体能够跨不同会话持久化存储、检索记忆。 ### 1. add - **描述**: 从会话中提取事实,用户偏好或习惯并进行持久化。 - **所需参数**: - `user_id` (string): 用户唯一标识。 - `context` (string): 会话内容。 - **返回**: 包含操作状态或新存储记录 ID 的对象。 ### 2. search - **描述**: 检索用户级别的历史记忆(跨会话)。 - **所需参数**: - `user_id` (string): 用户唯一标识。 - `query` (string): 检索条件。 - **返回**: 包含按相关性排序的结果。 ### 3. delete_by_run_id - **描述**: 清空 run id 对应的历史记忆。 - **所需参数**: - `run_id` (string): 用于隔离短期会话或临时流程的实体标识符。适用于支持工单、聊天会话、实验等需要独立重置或过期的场景。 - **返回**: 操作确认信息。 ### 4. delete_by_user_id - **描述**: 清空 user id 对应的历史记忆。 - **所需参数**: - `user_id` (string): 用户唯一标识。 - **返回**: 操作确认信息。 # Output Format 1. **自然融合**: 禁止提及"搜索记忆"等术语。将事实作为已知背景直接嵌入回复(如:"基于你正在学习 Rust,建议...")。 2. **上下文感知**: 优先使用检索到的事实进行个性化决策,提供定制化的技术指导。 3. **优雅处理**: 若未检索到相关记忆,直接生成高质量回应,严禁提及"未找到记忆"或"搜索失败"。 4. **动作反馈**: 调用 add 成功后,在回复结尾以简洁自然的方式确认(如:"已记下你的偏好"),避免机械化的系统提示。 # 示例 ### 场景 1: 记忆添加(Add) **用户输入**: "我计划下个月扩容 Elasticsearch 服务。" **动作**: add(user_id="user_01", context="计划下个月扩容 Elasticsearch") ### 场景 2: 记忆检索 (Search) **用户输入**:"帮我查看我之前的扩容计划" **动作**: search(user_id="user_01", query="扩容计划") ### 场景 3:记忆遗忘(Delete by run id) **用户输入**: "忘掉之前的扩容计划吧,我们不打算扩容了。" **动作**: delete_by_run_id(run_id="run_01") ### 场景 4:用户记忆清除(Delete by user id) **用户输入**: "清除本用户所有记忆。" **动作**: delete_by_user_id(user_id="user_01") # Tags `Memory-as-a-Service` `Elasticsearch` `Mem0` # Limitations - **复杂度限制**: 避免将极长的段落作为单一事实保存;请将其拆分为较短的、具有语义定义的陈述,以获得更好的检索准确性。 -
-
刷新 Skills 或重启 OpenClaw Gateway。
步骤四:验证效果
完成 Mem0 Server 部署后,您可以通过以下方式验证记忆系统功能:
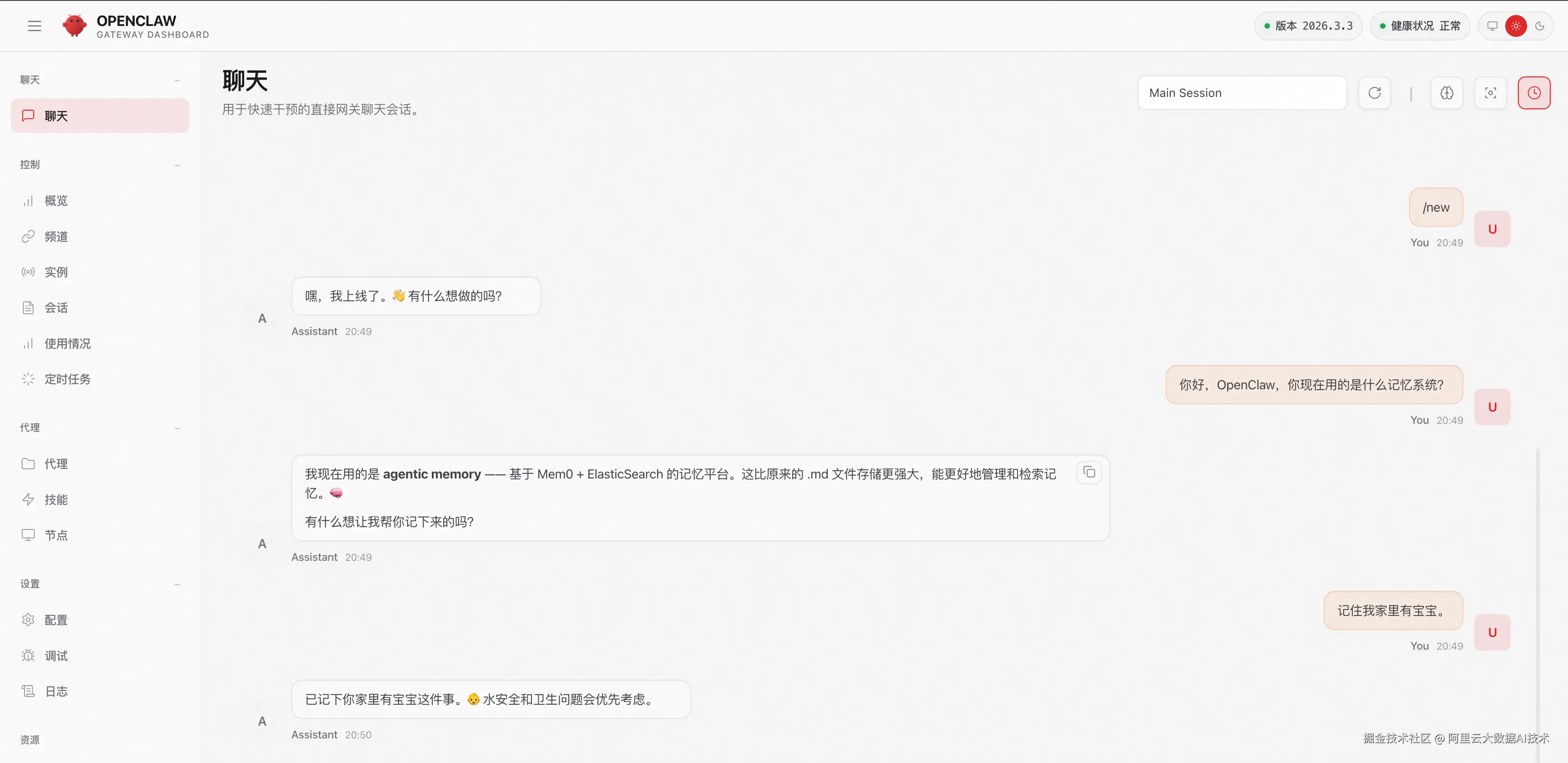
- 记忆写入:
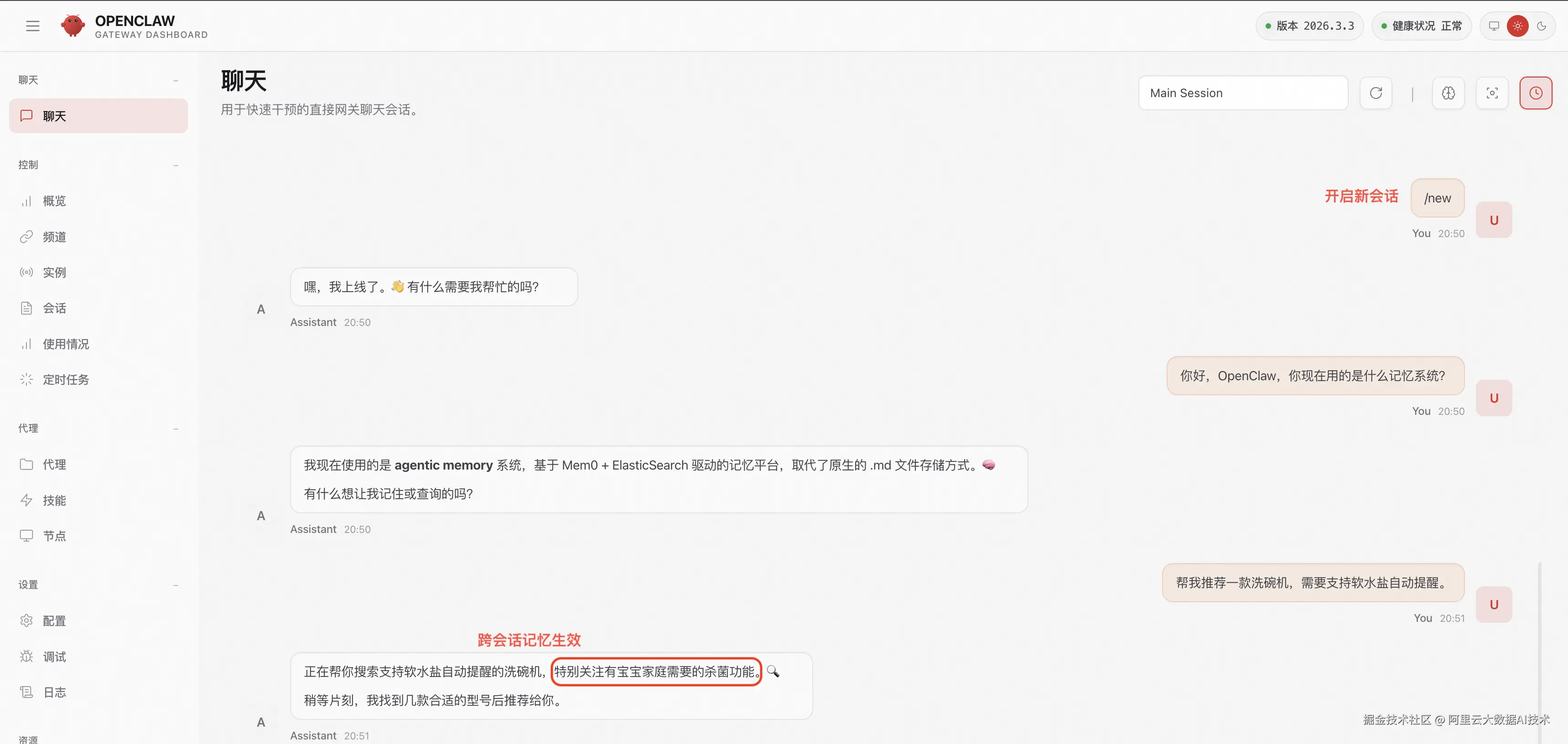
- 记忆检索:
上述示例基于阿里云托管的 OpenClaw 搭建,支持快速一键部署。如需本地部署,参见 OpenClaw GitHub 仓库。