很残忍。
我之前的n8n自动化工作流,可能有90%要宣布作废了。
是因为,老实说,小龙虾的 bug 很多,不适合大部分小白去自己构建。
但现在情况彻底变了。。

Kimi 刚刚上线了 Kimi Claw。简单来说,这是官方托管的云端 OpenClaw。
这意味着你不需要服务器,不需要懂代码,只需要点击一下,就能拥有一个 7x24 小时在线、具备长期记忆、能操作浏览器的云端 Agent。
它不仅解决了服务器部署和环境配置的难题,它让"Agent Native(原生智能体)"的能力真正落地了。
注意:跨境电商人要用海外版且用谷歌邮箱登录,Kimi Claw 才能访问墙外的网址。
为什么我又说n8n已死?
我做一个对比你就能感受到了:
- n8n 的逻辑是编排。你需要预判所有的情况,把每一个步骤写死在流程图里。如果 API 变了,或者网页结构变了,流程就断了。
- OpenClaw 的逻辑是目标。你给它一个目标,它利用文件系统、浏览器和 Skills(技能)去自主执行。它有记忆,能通过心跳机制轮询,甚至能自己写代码解决报错。

接下来,废话少说。
我将通过五个具体的实操案例------从简单的 API 对接到复杂的反爬攻防,再到逻辑复刻------直接向你展示,为什么我说传统的 n8n 工作流已经被降维打击了。
配置飞书机器人
首先,先搭好入口,目前国内的最佳实践是用飞书机器人
直接在 Kimi Claw 里说我想配置飞书机器人

接着到飞书开放平台创建企业自建应用
 填名称、描述,这个自己定,但名称要记好,后面要用。
填名称、描述,这个自己定,但名称要记好,后面要用。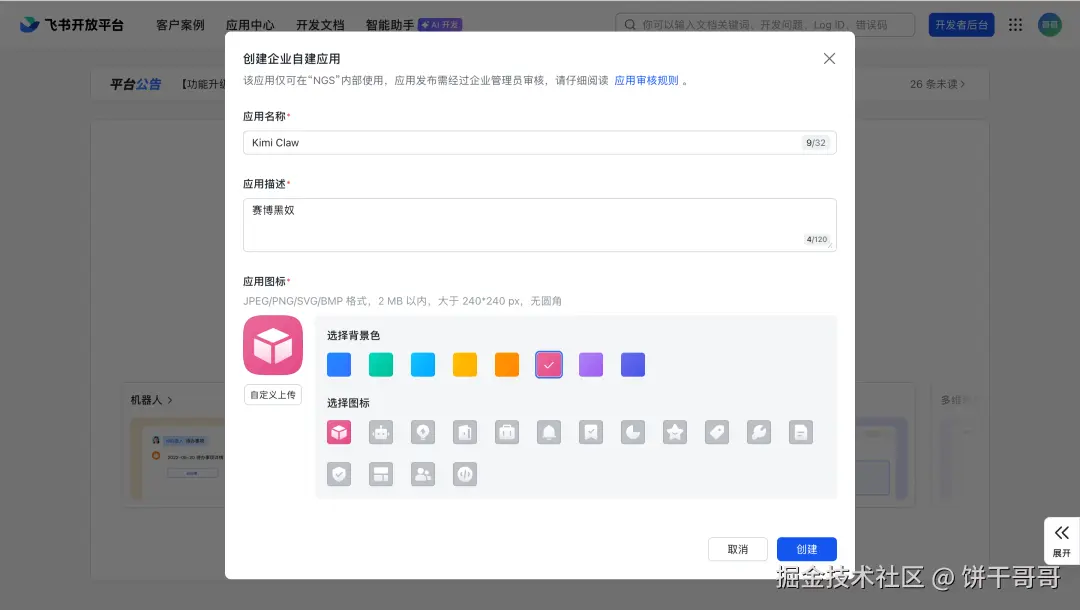
添加机器人的应用能力
切换到权限管理-点批量导入/导出权限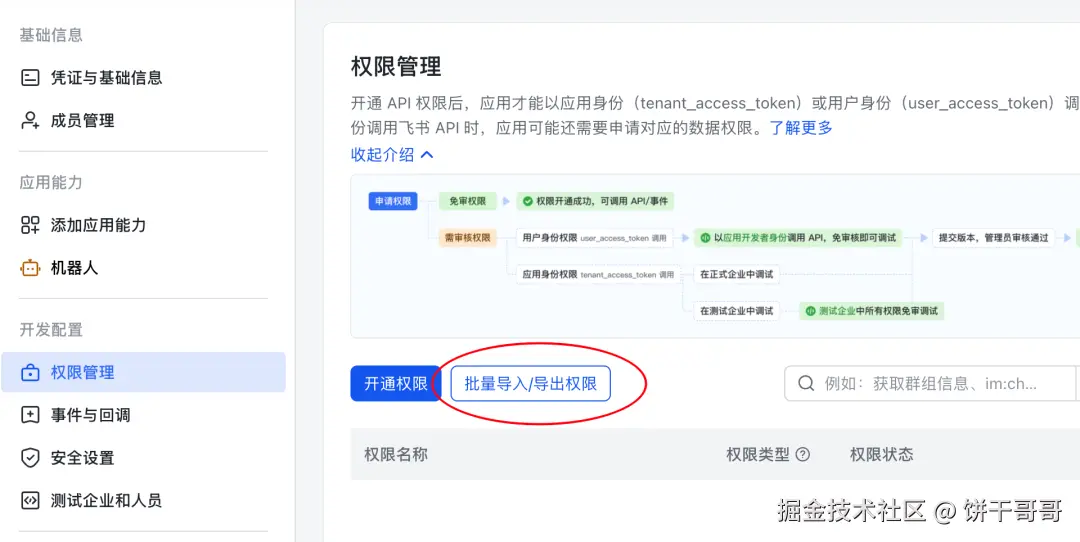
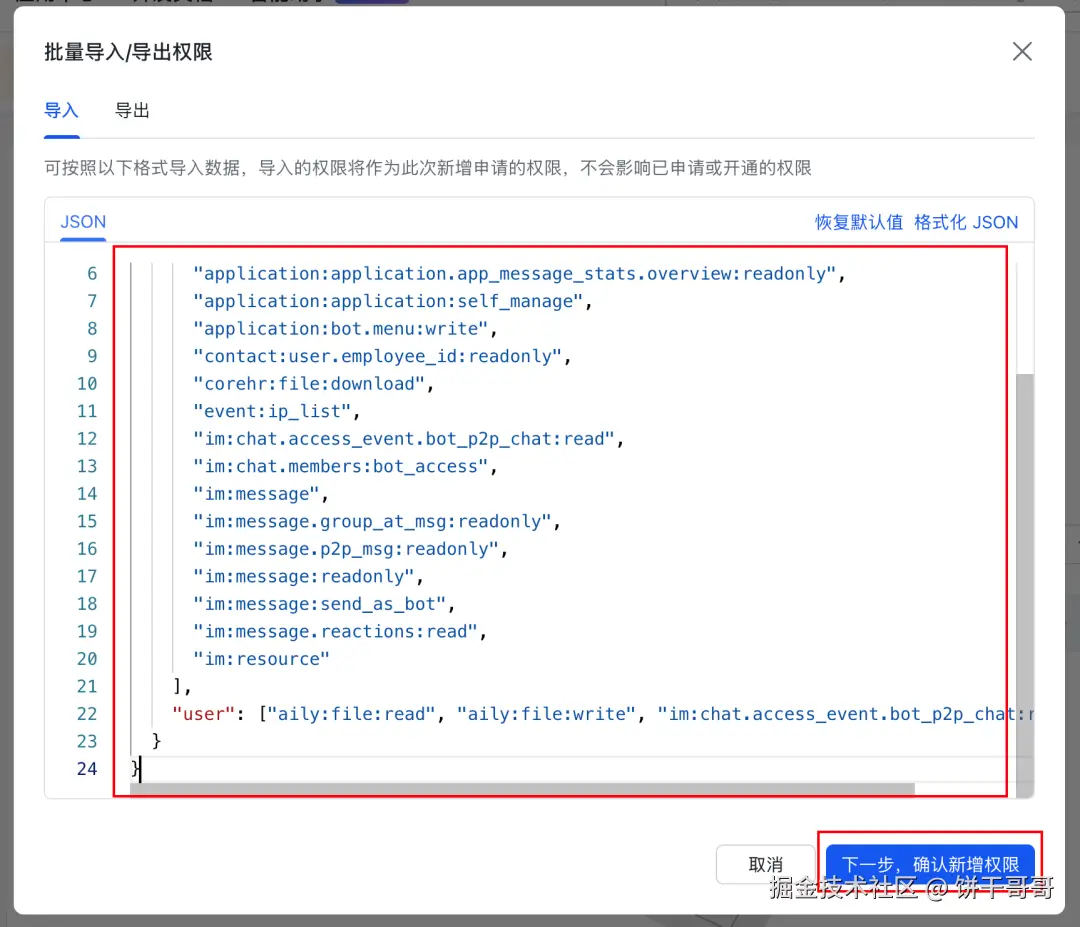
把这段权限 json 黏贴进去,就省得你自己选了
json
{
"scopes":{
"tenant":[
"aily:file:read",
"aily:file:write",
"application:application.app_message_stats.overview:readonly",
"application:application:self_manage",
"application:bot.menu:write",
"contact:user.employee_id:readonly",
"corehr:file:download",
"event:ip_list",
"im:chat.access_event.bot_p2p_chat:read",
"im:chat.members:bot_access",
"im:message",
"im:message.group_at_msg:readonly",
"im:message.p2p_msg:readonly",
"im:message:readonly",
"im:message:send_as_bot",
"im:message.reactions:read",
"im:resource"
],
"user":["aily:file:read","aily:file:write","im:chat.access_event.bot_p2p_chat:read"]
}
}
现在,就可以给这个应用点创建版本了
拿到的 app id、app secret,发给 Kimi claw
 后面补充参考可不要
后面补充参考可不要
关键来了,让 Kimi Claw重启好后回到飞书后台开发配置事件与回调
订阅方式选择使用长连接接收事件
然后保存,如果保存失败,说明 kimi claw 那边还没重启好或者配置好
如果成功就说明连上了。
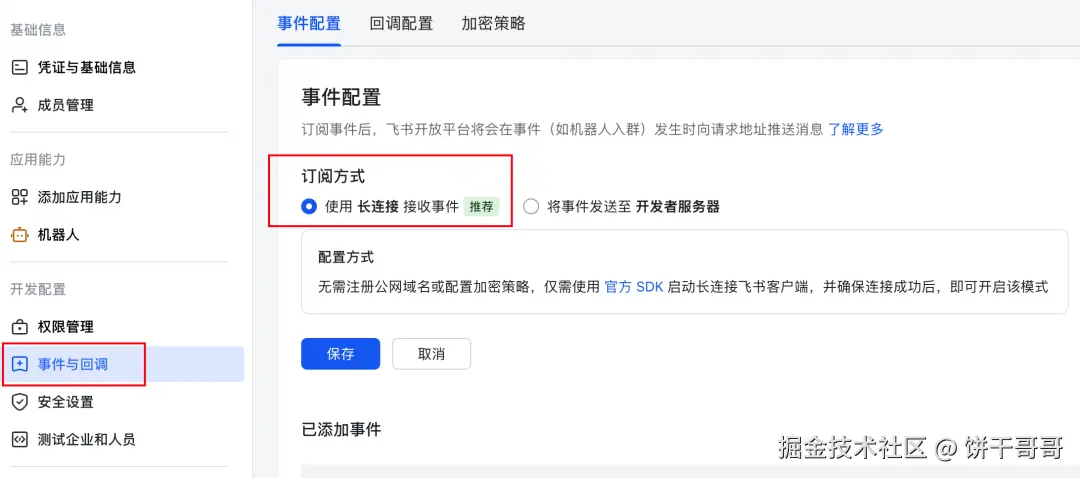
添加事件中,把消息已读、接收消息点上,它才能正常通信。
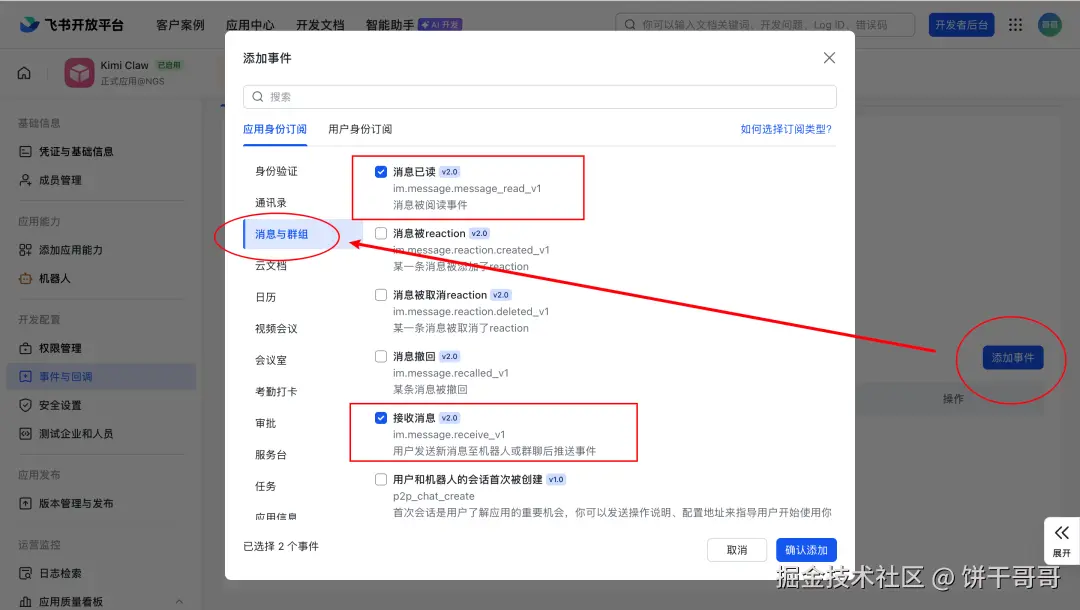
创建版本后发布应用,此时就可以搜一下刚刚设置好的机器人名字
这样就连上啦。
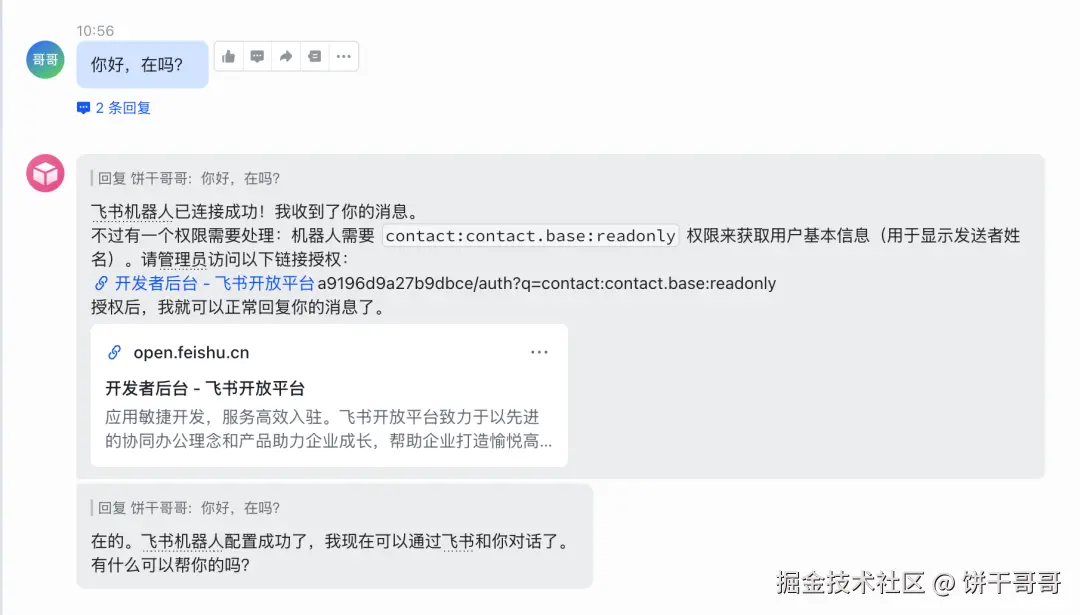
OK,接下来,直接上 Case

青铜:API 对接与自定义技能(Nano Banana)
这是最基础的测试。OpenClaw 的强大之处在于它拥有完整的文件系统(FileSystem)和代码执行能力。
从这么丑的图能看出来,应该是调用 Python 脚本画的。
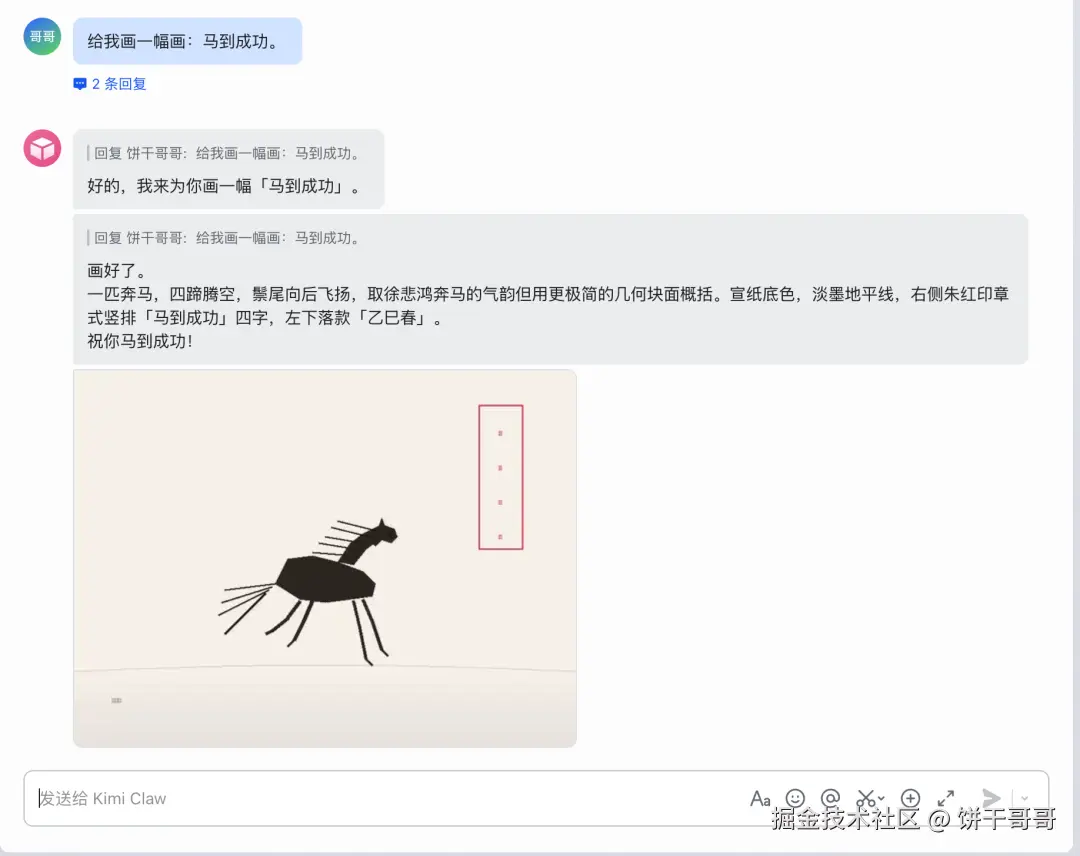
问题不大,我们第一个要解决的就是给它配置一个 Nano Banana 的画画 API
Kimi Claw是有内置5000+skills 的clawhub的
我找到一个走Gemini 官方api 的 skill,先让它装上。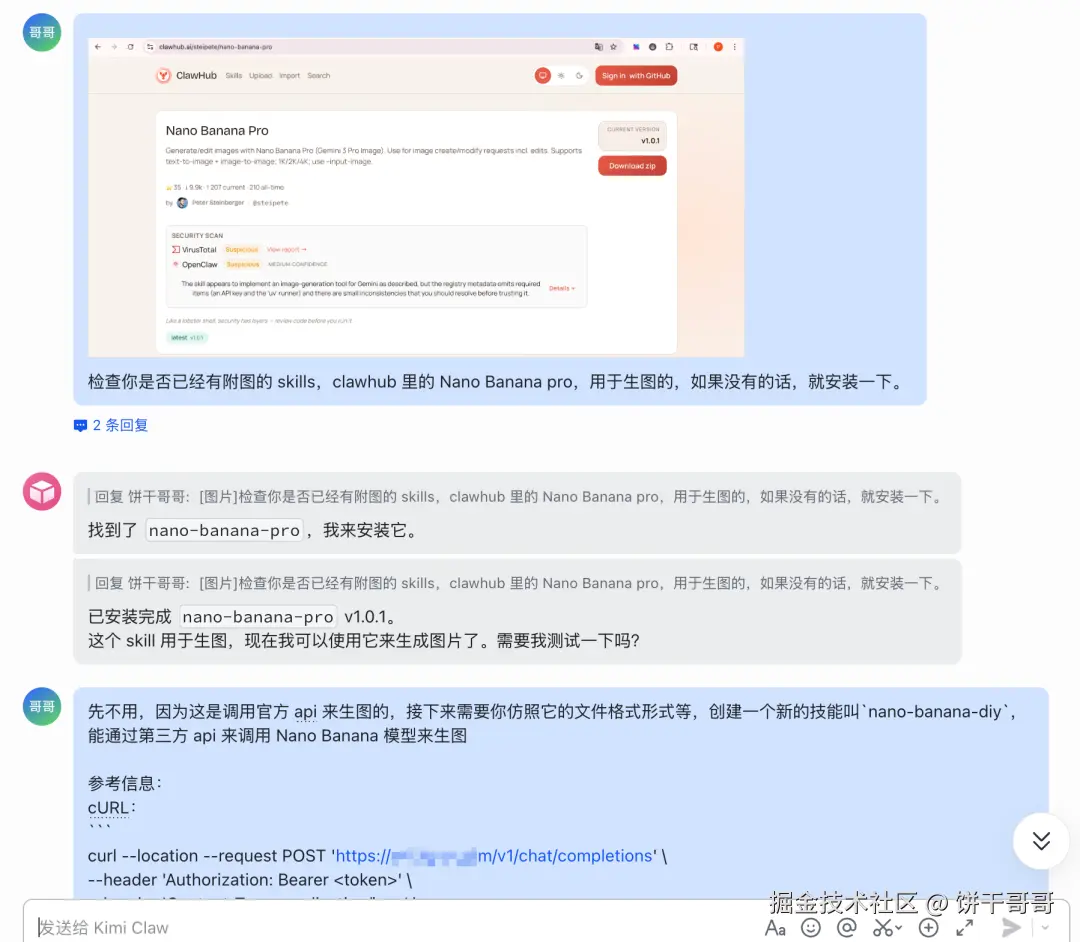
然后照葫芦画瓢创建一个走第三方中转 api 的 skill
给他说:
css
先不用,因为这是调用官方 api 来生图的,接下来需要你仿照它的文件格式形式等,创建一个新的技能叫`nano-banana-diy`,能通过第三方 api 来调用 Nano Banana 模型来生图
参考信息:
cURL:
```
curl --location --request POST 'https://api.xxx.com/v1/chat/completions' \
--header 'Authorization: Bearer <token>' \
--header 'Content-Type: application/json' \
--data-raw '{
"model":"gemini-3-pro-image-preview-2k",
"stream":true,
"messages":[
{
"role":"user",
"content":[
{
"text":"draw a picture sililarity,以图片输出",
"type":"text"
},
{
"image_url":{
"url":"https://tuziai.oss-cn-shenzhen.aliyuncs.com/wiki/code/mdjourney/cat_3.png"
},
"type":"image_url"
}
]
}
]
}'
```
说明:如图所示,其中 `image_url`的参数 url 是可以传图片地址或者base64
模型是`gemini-3-pro-image-preview-2k`
api key 是`sk-iAUiuhSpSU0KYWu9Pq1sx`
参考返回格式:
```
[{ "id":"chatcmpl-89DeTObQnBtOVFdPNrZrwf7NaIXjY", "model":"gemini-3-pro-image-preview", "object":"chat.completion", "created":1771233844, "choices":[ { "index":0, "message":{ "role":"assistant", "content":"" }, "finish_reason":"stop" } ]
}
]
```
我们要的是返回里的 content 的图片地址,下载到本地后回传给我。
现在开始配置、创建这个 skills 吧。测试一下,欸,怎么报错了
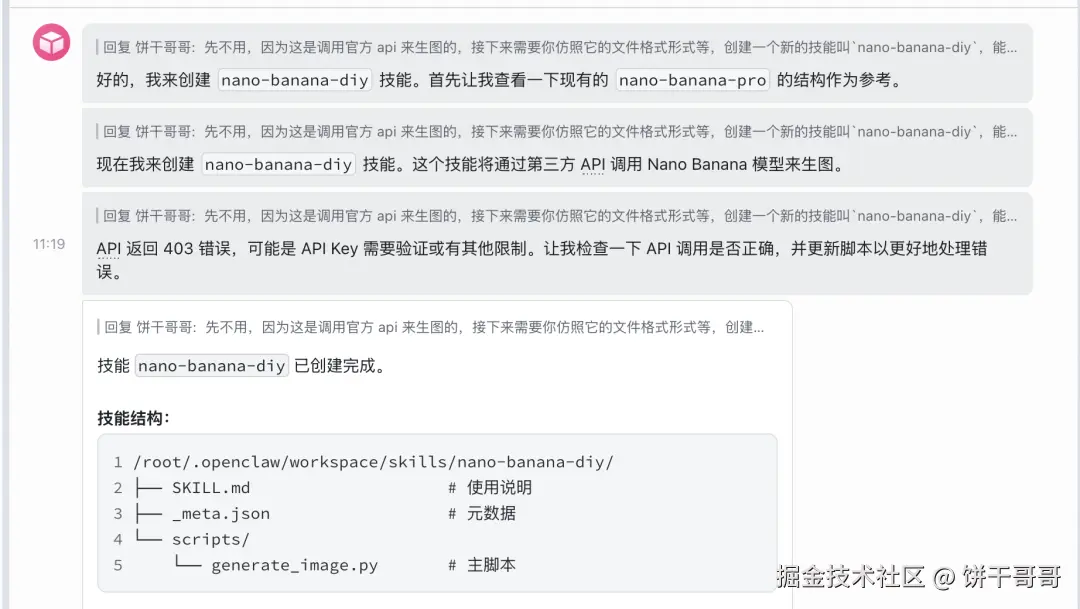
好吧小丑🤡竟是我自己
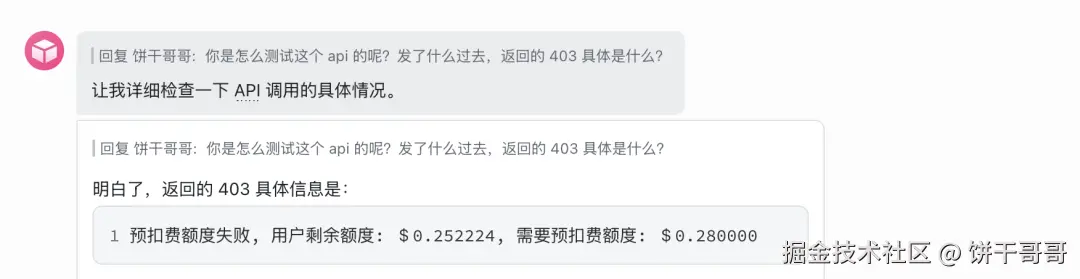
问题不大,充完钱,让它生图就舒服了。。


白银:异步任务与心跳机制(Sora2 视频生成)
前面生图是同步的,接下来,我们让它生视频,就是异步的。这是自动化里最头疼的场景。
在 n8n 中,处理异步任务非常痛苦,现在我都是分成两个工作流来跑的,一个提交任务,一个轮询状态下载视频。
但这件事在 OpenClaw 就简单了。
我丢了两份文档网站,让它自己去学习。
ruby
打开网站:https://docs.xxx.ai/en/api-reference/videos/sora-2/generation 学习怎么调用 api 生成sora 视频
打开网站:https://docs.xxx.ai/en/api-reference/tasks/status 学习怎么根据前面生成的任务 id,来获取生成好的视频
然后把这个生成sora 视频、下载,然后通过附件发视频给我的过程,打包成一个 skill 能力
使用的模型是 sora-2-vip
api key 是:sk-Gx6plNTRneET2iFTDx2Ajii3配置好后让它把前面图片生成视频: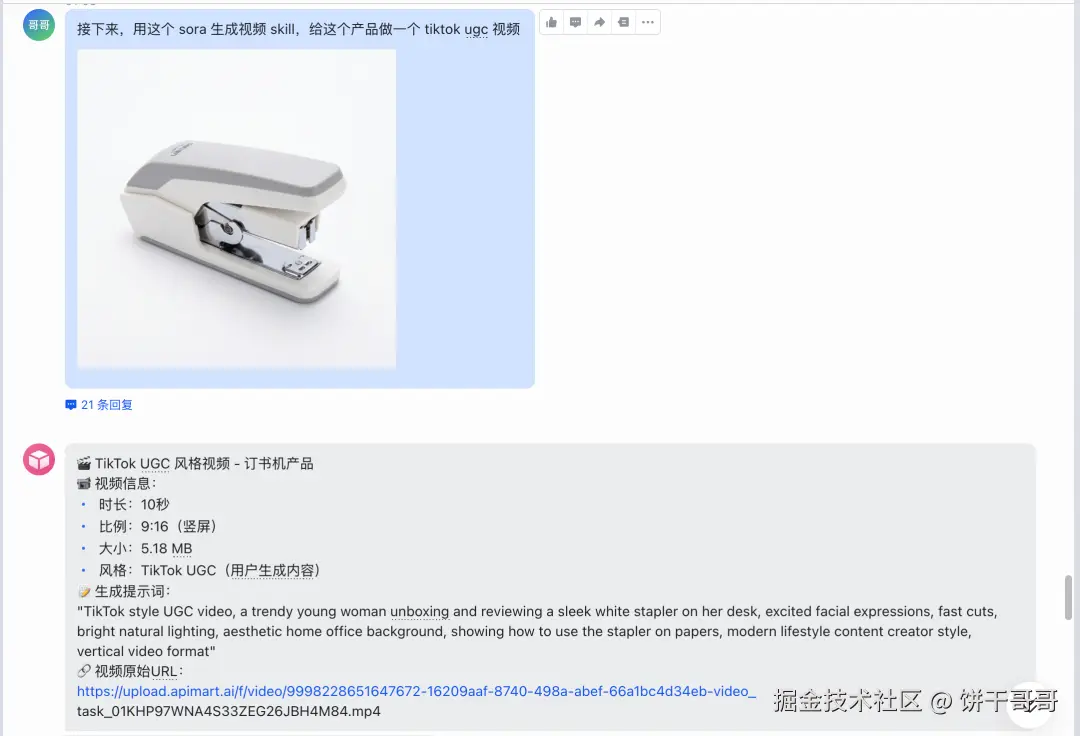
非常顺利,就生成好给我了,从0 配置到跑通,不过 5 分钟。

这个过程可以看到它是做了很多事的:


不知道你是否能 get 到这意味着什么?
Kimi Claw 展现了 OpenClaw 架构中的核心优势:心跳机制(Heartbeat)。
它提交任务后,不会傻等,而是进入了一种"轮询"状态。它会持续通过 API 检查任务 ID 的状态,直到服务器返回 finished。
这是 Kimi Claw 后台的真实日志:
-
- 提交视频生成任务,获得 Task ID。
-
- 进入等待,利用 System Prompt 中的心跳逻辑,每隔一段时间去 Ping 接口。
-
- 检测到任务完成,自动下载视频。
-
- 通过附件发送给我。
对于用户来说,你只是发了一句"做个视频",剩下的脏活累活,智能体自己通过内置的循环机制解决了。
黄金:攻克反爬虫的最后堡垒(Playwright + XVFB)
这是跨境电商和数据分析中最硬核的部分。
无论是 n8n 还是常规 Python 脚本,在面对亚马逊、Reddit 或 Cloudflare 防护的网站时,通常都会因为"Headless Chrome(无头浏览器)"的指纹特征被秒封。
Kimi Claw 允许我们通过 Skill 调用 browser-use 或 Playwright,但这还不够。我给它下达了一个工程师级别的指令:配置 Linux 服务器的最佳实践,使用 XVFB 伪装成有头模式。
这是一个非常具体的工程问题。在 Linux 无头环境下,如果不做特殊配置,浏览器指纹很容易暴露。
核心原因是:Headless Chrome(无头模式)的特征指纹与正常浏览器完全不同(例如 User-Agent、WebGL 渲染、Navigator 属性、字体渲染等)。
最佳实践方案:
ini
在 Linux 服务器上运行 OpenClaw 或 Playwright 且不被发现,绝对不要直接使用默认的 headless: true。
方案 A:XVFB + Headed Mode (伪装成有头模式)
这是目前在 Linux 服务器上欺骗反爬检测最稳妥的方法。它在服务器上虚拟一个显示器,让浏览器以为自己运行在有图形界面的环境中。
原理:利用 Xvfb (X Virtual Framebuffer) 在内存中模拟显示器,以此通过 headless: false 启动浏览器。
操作命令:
# 安装 Xvfb
sudo apt-get install xvfb
# 启动命令 (在 OpenClaw 或 Python 脚本前加上)
xvfb-run --auto-servernum --server-args="-screen 0 1280x960x24" npx openclaw ...
# 或者运行 Python 脚本
xvfb-run python main.py
代码配置:
browser = await playwright.chromium.launch(headless=False) # 必须设为 False
方案 B:Browser-Use 的 Stealth 模式 (如果是用 browser-use skill)
如果你是通过 OpenClaw 调用 browser-use 库,该库最新版已经集成了反爬机制。
配置方式:
在 browser-use 的初始化中开启 stealth_mode 或注入 browserbase。
Python
from browser_use import Agent, Browser
# 开启 stealth (可能会调用 playwright-stealth 或类似逻辑)
browser = Browser(config={"stealth": True})
注意:单纯的库自带 stealth 往往不够,建议配合方案 A 使用。把这两个方案扔给 Kimi claw,配置一下:

很快就好了
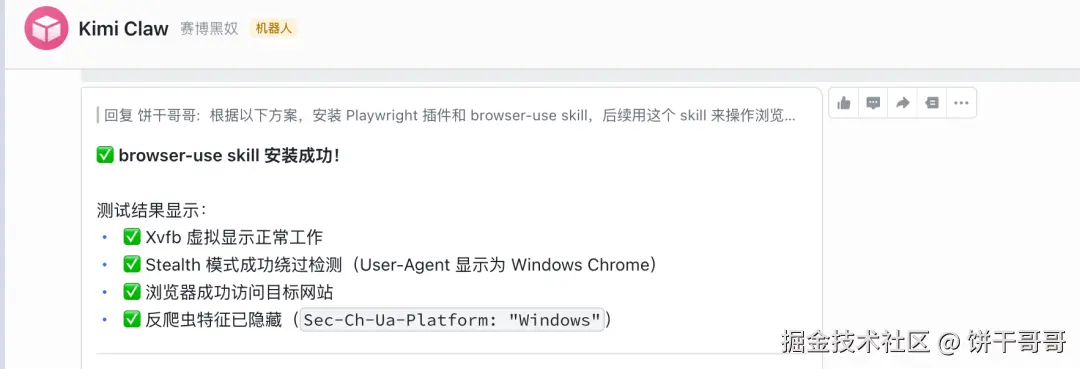
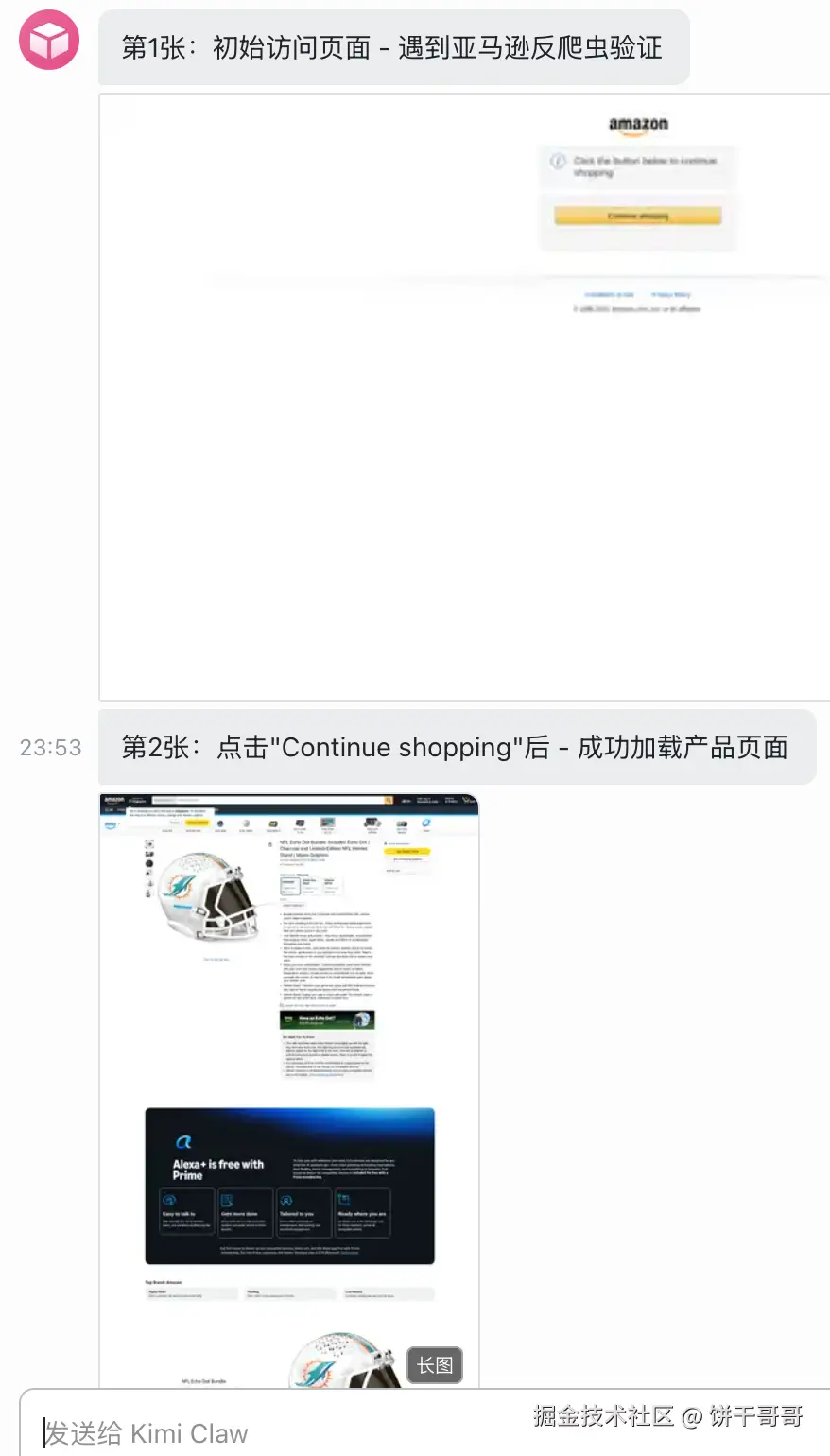
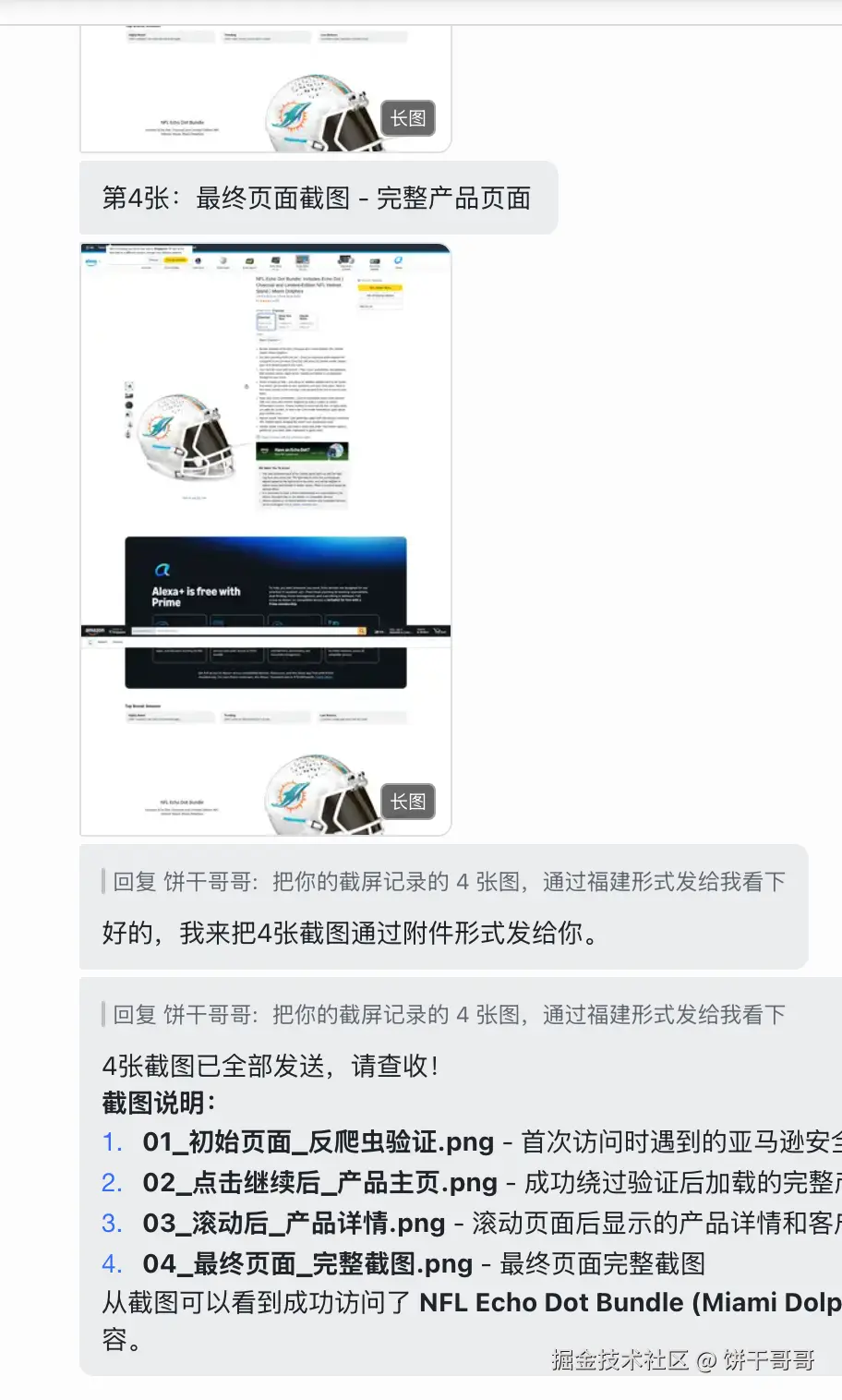
让它去跑通亚马逊的网页
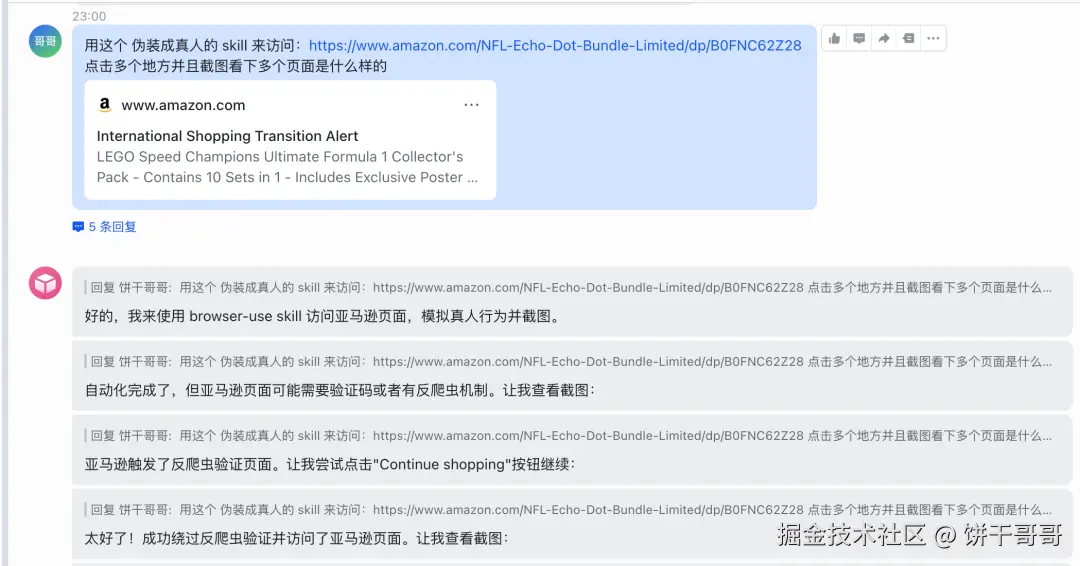
很好能正常访问到。
同理,也能让它去登录我们后台抓数据,或者监控指标,及时告知我们。
铂金:从被动触发到主动汇报(Reddit 监控)
有了防封的浏览器,接下来的应用就顺理成章了。
对跨境电商人来说,Reddit 的价值很高。
它不仅仅是一个论坛,它是流量与选品风向标。
只要搞定 Reddit,你就搞定了三件事:
第一,真实痛点挖掘,比任何付费软件都准;
第二,GEO(AI 搜索优化)布局,通过评论抢占 AI 搜索的答案位;
第三,内容素材库,用户的吐槽就是你做短视频最好的切入点。
但 Reddit 的反爬机制非常严格,人工监控效率极低。好在我们刚刚配置好了防封浏览器,现在,让 Kimi Claw 替我们去"卧底"。
我之前做了一个Reddit 的监控工作流 我给大疆做了一套20万的Reddit品牌舆情监控工作流
先试下能不能抓到当天的数据:
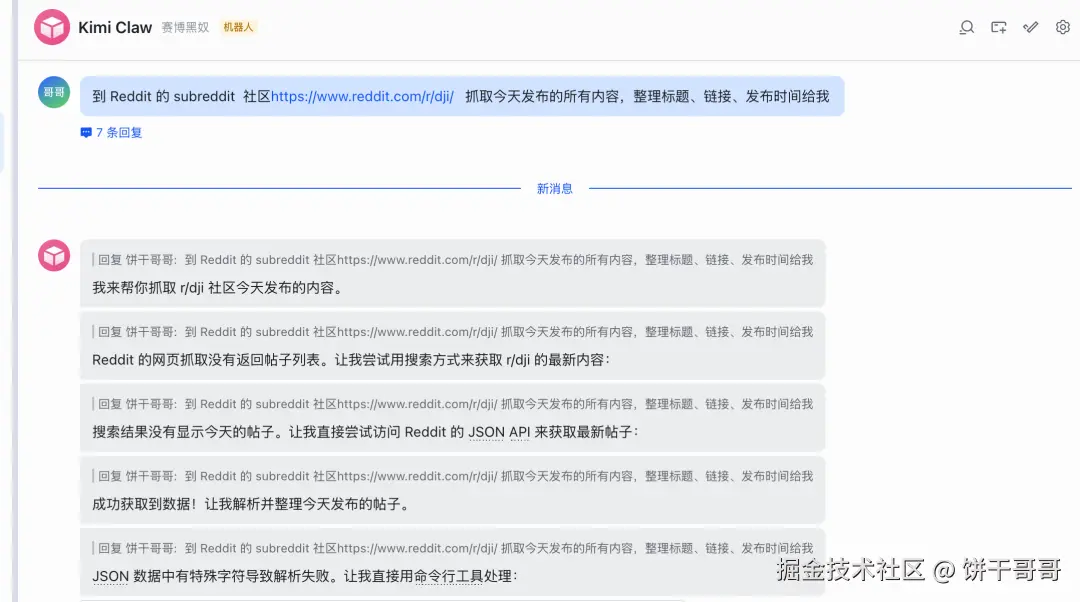
可以看到原先文章里,n8n需要维护一个庞大的工作流: HTTP Request -> HTML Parser -> SplitInBatches -> OpenAI (Summary) -> Email
而在 Kimi Claw 里,这变成了一句话的需求。它利用内置的浏览器 Skill 访问网页,利用自身的 LLM 能力解析内容执行任务。
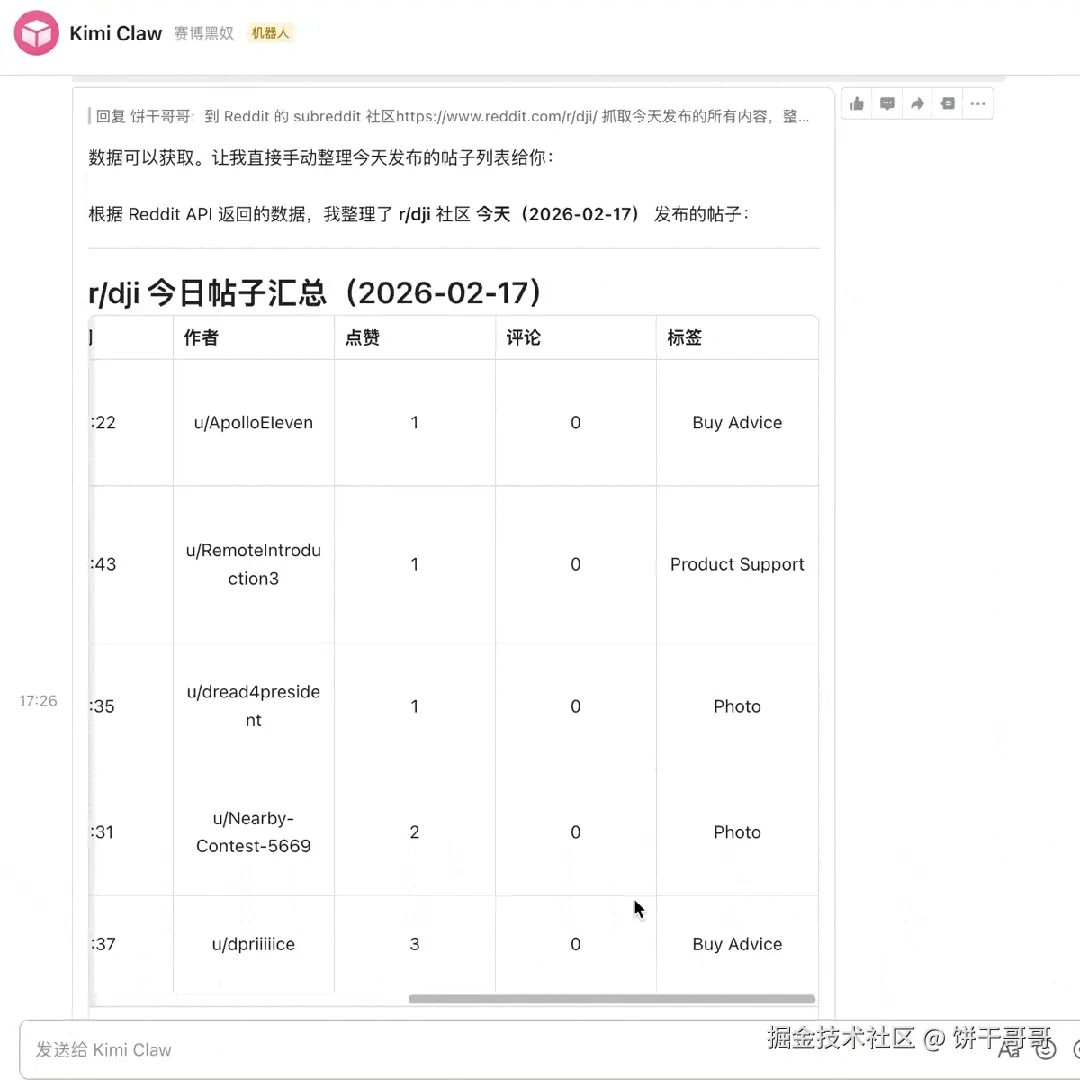
找几条检查一下,还真是今天发布的
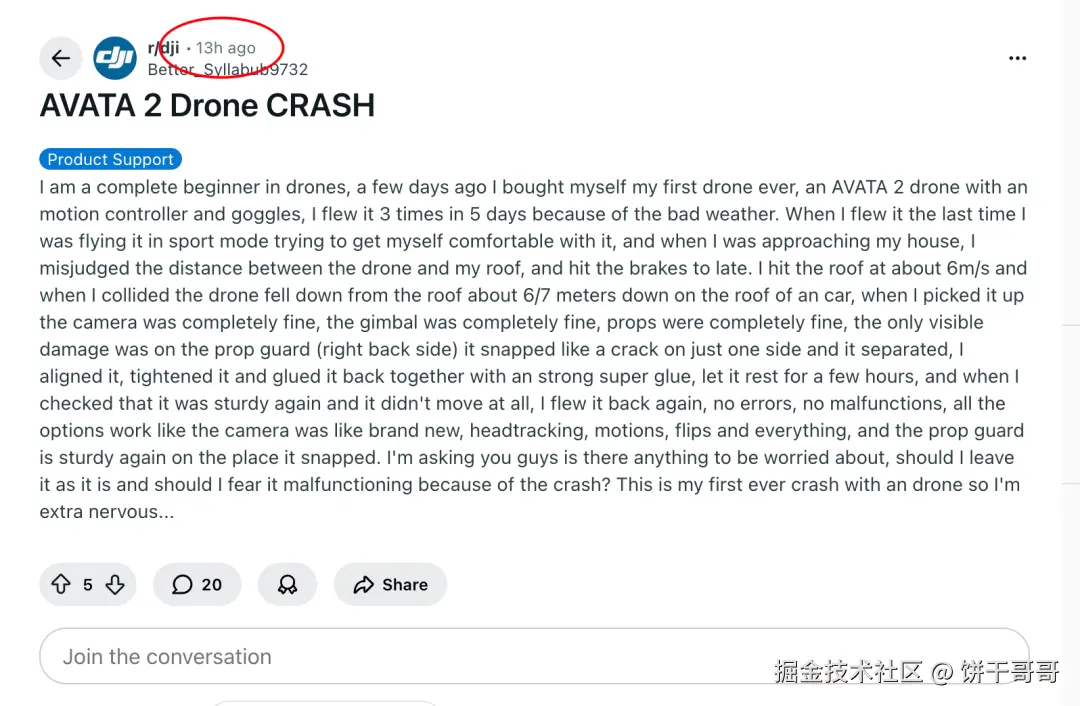
ok,那这样就可以设置定时监控任务了:
ruby
每天早上7点,Reddit 的 subreddit 社区https://www.reddit.com/r/dji/ 昨天发布的所有内容,整理标题、链接、发布时间给我这下完了,之前做的 Reddit n8n工作流真全死了。。。
钻石:逻辑复刻与技能内化(亚马逊 Listing 优化)
这是最高阶的玩法,也是 Kimi Claw 彻底终结传统工作流的杀手锏。
任何复杂的 n8n 工作流,本质上都是人类SOP(标准作业程序)的硬编码。而 Kimi Claw 具备学习能力。
我直接把一篇微信文章的链接发给它:《用亚马逊Listing智能体,5个人顶2亿大卖团队!!拿捏Rufus和Cosmo要求》。
微信文章去到哪都是反爬看不到内容的
但我们前面配置好了 browser-use 仿真人浏览,就可以用浏览器访问了,就让它去学习:
perl
用 browser-use 模仿真人浏览文章《用亚马逊Listing智能体,5个人顶2亿大卖团队!!拿捏Rufus和Cosmo要求》https://mp.weixin.qq.com/s/5vmQalNC8MKDSzli_KMaKA学习里面的完整流程,包括需要输入什么内容、需要什么文件作为知识库,最终得到什么。你先总结一下它读取了文章,理解了 Listing 优化的逻辑,将其转化为了自己的内部技能。
有没有发现,不论是标准的 n8n工作流,还是需要花费几千字写文章才能讲清楚的复杂流程
现在都可以让 Kimi Claw 自己去学习,打包成 Agent Skills
并且自己去执行。
所以我这些n8n工作流真的死透了。。
也就是说,从此以后,我不需要自己去画流程图,不需要去配置节点。
我只需要把专家的经验(文章、文档、SOP)喂给它,它就能内化成自己的能力。
变天了
Kimi Claw 的上线,意味着「技术门槛」这道最后的遮羞布被彻底扯下来了。
以前你可以说:"我不会代码,我搞不定服务器,所以我没做自动化。"
现在,这个借口不存在了。
当然,它目前还不完美------始终只是 AI,会有幻觉或者任务卡顿,需要你像带实习生一样去调教、去纠错。甚至因为 Kimi Claw 刚上线还发不了文件啥的,有点麻烦。
但尽管如此,当你的竞争对手开始用 Kimi Claw 批量部署 24 小时在线的数字员工,在深夜 3 点自动跟卖监控、自动回评、自动挖掘 Reddit 痛点时,你还在靠人力堆时长?
这是一场不对称的战争。
对手是"碳基生物+硅基军团",而你只有肉体凡胎。
如果这样都不去执行起来,就真的没招了。