目录
如果说:
线性回归
是机器学习的入门模型那么:
感知器(Perceptron)
就是神经网络的起点1957年,美国科学家:
Frank Rosenblatt提出了感知器模型。
它是人类历史上第一个能够:
自动学习参数
自动完成分类
具有"学习能力"的神经网络模型虽然今天我们已经拥有:
CNN
RNN
Transformer
GPT等复杂模型,但这些模型本质上都是由大量感知器组合而成。
因此:
理解感知器,就是理解神经网络的第一步。
本文将带你系统学习:
什么是感知器
感知器的数学原理
感知器如何分类
感知器如何学习
感知器训练过程
感知器与逻辑回归区别
Sklearn实现感知器二、什么是感知器
感知器是一种:
二分类线性模型例如:
是否是垃圾邮件
是否通过贷款审批
是否患病
是否点击广告都可以使用感知器解决。
感知器结构非常简单:
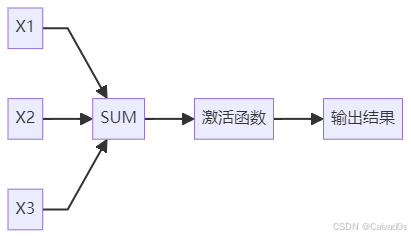
核心思想:
多个输入特征
↓
线性加权求和
↓
激活函数
↓
输出分类结果三、生物神经元与感知器
感知器最初来源于对生物神经元的模拟。
生物神经元工作过程:
树突接收信号
↓
细胞核处理信号
↓
轴突输出信号对应到感知器:
| 生物神经元 | 感知器 |
|---|---|
| 树突 | 输入特征 |
| 突触 | 权重 |
| 细胞体 | 加权求和 |
| 轴突 | 输出结果 |
因此:
感知器
=
人工神经元四、感知器的数学模型
假设有三个输入特征:
x1
x2
x3对应权重:
w1
w2
w3感知器首先计算:
z=w_1x_1+w_2x_2+w_3x_3+b
其中:
w
表示权重
b
表示偏置例如:
x1 = 2
x2 = 3
w1 = 0.5
w2 = 0.8
b = 1
z = w1*x1 + w2*x2 + b
print(z)输出:
4.4五、激活函数
仅仅求和还不能分类。
需要通过:
激活函数(Activation Function)进行判断。
感知器使用最简单的阶跃函数:
f(z)=\begin{cases}1,&z>0\0,&z\le0\end{cases}
意思是:
z > 0
输出1
z ≤ 0
输出0例如:
python
def step(z):
return 1 if z > 0 else 0
print(step(4.4))输出:
1表示:
属于正类六、感知器如何完成分类
假设有如下二维数据:
| 年龄 | 收入 | 是否购买 |
|---|---|---|
| 25 | 5000 | 0 |
| 30 | 10000 | 1 |
| 35 | 15000 | 1 |
感知器会寻找一条直线:
将两类数据分开如下图所示:
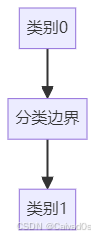
这条直线称为:
决策边界(Decision Boundary)七、感知器学习的目标
感知器训练的本质:
寻找最优权重w使分类错误最少。
目标:
错误分类样本数量最小训练流程:

八、感知器学习规则
假设:
真实标签
y = 1预测结果:
ŷ = 0说明预测错误。
此时需要更新权重。
更新公式:
w_i=w_i+\eta(y-\hat y)x_i
其中:
η
学习率(Learning Rate)决定每次更新幅度。
九、手动模拟一次训练
假设:
x = [2, 3]
y = 1初始参数:
w = [0, 0]
lr = 0.1预测:
z = 0
y_pred = 0发生错误:
真实值 = 1
预测值 = 0更新:
w1 = 0 + 0.1*(1-0)*2
w2 = 0 + 0.1*(1-0)*3结果:
w = [0.2, 0.3]模型变得更接近正确答案。
十、感知器训练完整流程
python
for epoch in range(100):
for x, y in dataset:
y_pred = predict(x)
error = y - y_pred
w += lr * error * x训练过程:
预测
↓
计算误差
↓
更新权重
↓
继续预测
↓
不断优化十一、Sklearn实现感知器
Scikit-Learn 已经提供现成实现。
导入:
from sklearn.linear_model import Perceptron创建模型:
python
model = Perceptron(
max_iter=1000,
eta0=0.1
)训练:
model.fit(X_train, y_train)预测:
pred = model.predict(X_test)十二、鸢尾花数据集实战
加载数据:
python
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target划分数据:
python
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42
)训练模型:
python
from sklearn.linear_model import Perceptron
model = Perceptron()
model.fit(
X_train,
y_train
)预测:
pred = model.predict(X_test)计算准确率:
python
from sklearn.metrics import accuracy_score
acc = accuracy_score(
y_test,
pred
)
print(acc)输出:
0.9以上通常可以达到较好的分类效果。
十三、感知器的优点
优点:
结构简单
实现容易
训练速度快
容易理解特别适合作为:
神经网络入门模型十四、感知器的缺点
最大的缺点:
只能解决线性可分问题例如:
AND问题
可以解决但:
XOR问题
无法解决原因:
无法用一条直线分开十五、为什么感知器推动了深度学习发展
1969年,
Marvin Minsky 和 Seymour Papert 证明:
单层感知器无法解决XOR问题这让人工智能研究陷入低谷。
后来研究人员提出:
多层感知器(MLP)结构:
输入层
↓
隐藏层
↓
输出层最终发展成:
神经网络
↓
深度学习
↓
Transformer
↓
GPT因此:
今天所有的大模型,本质上都可以追溯到最早的感知器思想。
十六、感知器与逻辑回归区别
| 对比项 | 感知器 | 逻辑回归 |
|---|---|---|
| 输出 | 0/1 | 概率 |
| 激活函数 | 阶跃函数 | Sigmoid |
| 损失函数 | 分类错误 | 交叉熵 |
| 可解释性 | 高 | 高 |
| 概率输出 | 不支持 | 支持 |
十七、面试高频问题
什么是感知器?
最简单的人工神经网络模型感知器解决什么问题?
线性二分类问题感知器为什么重要?
神经网络的基础感知器如何学习?
预测
↓
计算误差
↓
更新权重感知器为什么不能解决XOR问题?
XOR不是线性可分数据十八、总结
感知器是机器学习历史上具有里程碑意义的模型。
其核心思想非常简单:
输入特征
↓
加权求和
↓
激活函数
↓
分类结果
↓
误差反馈
↓
更新权重虽然今天的深度学习模型已经拥有数十亿参数,但其底层逻辑依然与感知器一脉相承。
对于学习机器学习和深度学习的人来说:
感知器不仅是一个算法,更是理解神经网络、反向传播和大模型训练机制的重要起点。掌握感知器,你就掌握了人工智能发展的第一块基石。