 《从前端到 Agent》系列|01:LLM 核心原理与推理计算
《从前端到 Agent》系列|01:LLM 核心原理与推理计算
大家好~在上一篇文章中,我们已经对LLM(大语言模型)有了基础的认知,从这一篇开始,我们将逐步从概念转向具体应用,再到实践落地。需要说明的是,我的整个《从前端到 Agent》系列,都是按照我自己的学习路径逐步撰写的。
今天,我们正式进入提示词工程(Prompt Engineering)的学习------这是连接 LLM 与实际应用的核心桥梁,也是我们从"会用 AI"到"用好 AI"的关键一步。
我们正式开始提示词工程 (Prompt Engineering) 的了解
前言
很多人对提示词工程有个普遍误解,认为它只是"教你怎么和 AI 聊天"。但实际上,提示词工程的核心是用自然语言对大模型进行"编程" :LLM 的底层逻辑是"概率预测",它会根据你给出的上下文,预测最符合逻辑的下一个token(字符/词语),因此你提供的上下文越清晰、越具体,它预测出你想要结果的概率就越高。
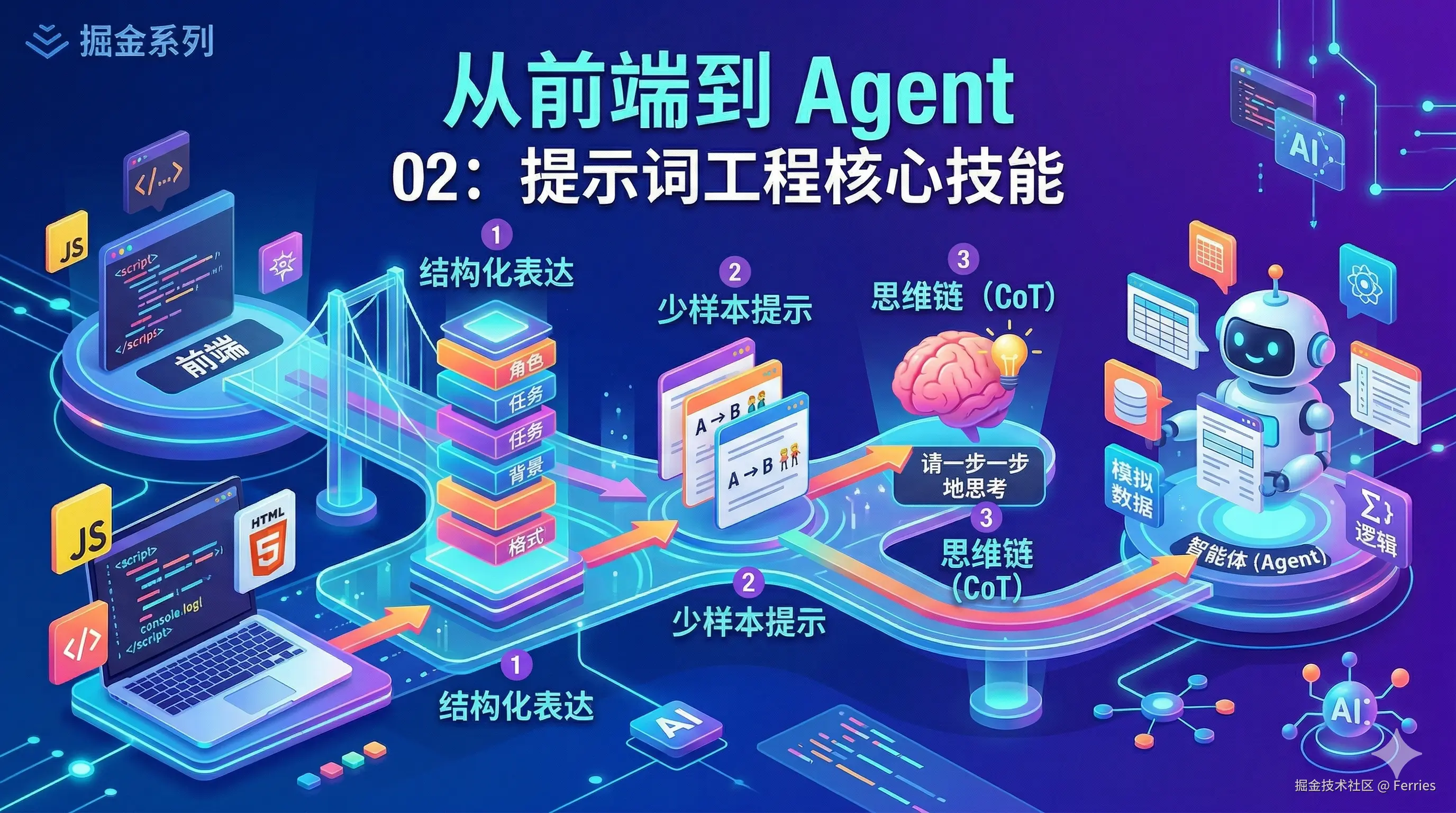
提示词工程并非杂乱无章的"话术技巧",而是有明确的进阶路径的。我们可以把它分为三个核心阶段,一步步把 AI 打造成贴合自己需求的专属专家。
第一阶段:结构化表达 (给 AI 设定清晰的框架) 🏗️
不要像和朋友聊天那样给 AI 发一句模糊的话,而是要把它当成一个极其聪明但完全不了解你背景的实习生。一个工业级的提示词通常包含四个核心要素:
- 角色 (Role) :让模型带入专家身份(这会激活它预训练数据中特定领域的词汇分布)。
- 背景 (Context) :交代你为什么要做这件事,目标受众是谁。
- 任务 (Task) :明确具体的动词和行动。
- 格式 (Format) :规定输出的排版、字数、语气或数据结构(如 Markdown、表格、JSON)。
| ❌ 糟糕的提示词 (无结构) | ✅ 优秀的提示词 (结构化) |
|---|---|
| 帮我写个关于时间管理的文章。 | 角色 你是一位拥有 10 年经验的世界 500 强企业高管教练。 背景 我的受众是刚入职场的大学毕业生,他们经常因为多任务处理而感到焦虑。 任务 请写一篇关于"时间管理"的短文,介绍番茄工作法和四象限法则。 格式 输出字数在 800 字左右,语言风格幽默幽默,使用 Markdown 格式,包含二级标题和加粗重点。 |
第二阶段:少样本提示 (Few-Shot Prompting) 👯♂️
当你想让 AI 模仿特定风格、遵循特定规则,却难以用文字清晰描述时,"举例"比"说教"更有效。LLM 擅长"模式识别",你给它几个典型示例,它就能快速领悟规则,进而模仿输出------这就是少样本提示的核心逻辑。
我们先明确两个相关概念,方便后续理解:
- 零样本(Zero-Shot) :无需任何示例,直接向模型下达指令,适合简单、通用的需求,比如"把'苹果'翻译成法文""总结这段文字的核心观点"。
- 少样本(Few-Shot) :提供3-5个典型示例,让模型模仿规则输出,适合复杂、有特定要求的需求,比如模仿特定文风、提取特定格式的数据。
举个简单例子:无需解释"请将文字转换为对应 emoji",只需给出示例,模型就能领悟规则:
狗 -> 🐶 猫 -> 🐱 鸟 -> 🐦 狮子 -> 🦁
拓展知识点:少样本提示的关键技巧------示例要"典型且统一",避免示例混乱(比如既给文字转emoji,又给文字转拼音);示例数量控制在3-5个(太少领悟不透彻,太多增加模型负担)。适用场景:模仿写作口吻、数据提取、格式转换、简单翻译等。
第三阶段:思维链 (Chain of Thought, CoT) 🧠
这是提示词工程中最具革命性的发现之一。当你问 AI 一个复杂的逻辑题时,如果直接让它给答案,它大概率会出错(因为它是一次性预测出来的)。
核心技巧 :在提示词中加上一句神奇的咒语: "请一步一步地思考" (Let's think step by step) 。
背后的底层逻辑 : 结合我们之前聊过的"纯解码器"架构,模型是看不到未来的。当你让它"一步一步思考"时,它会先把中间的推理过程写出来。这些被写出来的中间过程,就成了它预测最终答案的全新上下文。这相当于强行给它的大脑扩充了工作记忆,让它把复杂问题拆解成了多个简单问题。
掌握了这三个阶段,你就能搞定 90% 的日常 AI 交互了。
实践案例:用提示词工程解决实际需求
比如我现在想让AI给我做一个表格
在这种情况下,最好的提示词不是直接让它"画个表",而是让它帮你梳理维度(列名) ,并**生成贴近真实的模拟数据(Mock Data)**来启发你。
基于我们刚才讲的"结构化表达"(角色、背景、任务、格式),你可以直接复制并填空使用下面这个**"万能表格生成提示词"**:
📋 万能表格模板生成提示词 (直接复制使用)
【角色设定】 你现在是一位资深的行业分析师和数据产品经理,非常擅长将模糊的想法结构化为清晰的数据表格。
【背景信息】 我目前需要制作一个关于 在这里填入你的大致方向,比如:个人每月开销追踪 / 竞品分析 / 台湾环岛游计划 / 新员工入职流程 的表格。但我目前还没有具体的数据,甚至不太确定应该包含哪些维度。
【核心任务】
- 设计表头:帮我头脑风暴,这个表格应该包含哪些最核心、最实用的列(建议 5-8 列),要求既全面又符合实际逻辑。
- 生成模拟数据:基于你设计的表头,帮我填充 5 行贴近真实的模拟数据(Mock Data),让我能直观地看到这个表格填满后的样子。
- 留白预留:如果有需要我后续自己填写的个性化字段,请在模拟数据中用"待补充"或合理的预估值代替。
【输出格式】
- 请直接输出 Markdown 格式的表格。
- 在表格下方,用简短的 2-3 句话解释一下:你为什么建议我设置这几个特定的列(你的设计逻辑是什么)。
💡 为什么这个提示词会非常有效?
- 激发了"涌现能力" :你赋予了它"资深分析师"的角色,它就会去它的训练数据里调用那些专业的商业分析模型和常用模板,而不是给你一个极其业余的流水账。
- 用"模拟数据"具象化:LLM 本质上是在玩"概率接龙"。当你让它生成模拟数据时,它其实是在帮你把抽象的概念具象化,这往往能瞬间激发你的灵感,让你大呼:"对对对,我就是想要这个字段!"
- 解释设计逻辑(轻量级思维链) :让它解释"为什么这么设计",其实就是逼迫它在生成表格后进行一次简单的逻辑自洽,这能大幅降低它胡乱拼凑表头的概率。
让 AI 生成健身计划表(提示词优化思路)💪
很多人让 AI 生成健身计划表时,提示词过于简单(如"帮我写个健身计划"),导致输出的计划不贴合自身情况(比如忽略健身基础、目标)。结合我们前面讲的结构化表达,优质提示词应包含以下核心要素: 当我给一个简单提示词的结果如下
 优质提示词核心结构:
优质提示词核心结构:
- 角色:资深健身教练,擅长根据新手基础制定科学计划;
- 背景:我是健身新手,无运动基础,目标是减脂塑形,每周可运动3-4次,每次40分钟左右,无专业健身器材;
- 任务:制定一份4周健身计划,包含每次运动的热身、核心训练、拉伸步骤,标注每个动作的时长、组数、次数,兼顾易操作性;
- 格式:Markdown 格式,分每周计划,每个动作标注注意事项,语言通俗易懂,避免专业术语过多。
对比提醒:简单提示词(如"帮我写个健身计划")输出的内容会泛泛而谈,缺少针对性;而结构化提示词能让 AI 结合你的具体情况,生成可直接落地的计划------这就是提示词工程的价值。

总结与后续预告
本文我们重点学习了提示词工程的三个核心阶段(结构化表达、少样本提示、思维链),并通过两个实践案例,展示了优质提示词的设计思路。核心记住:提示词工程的本质是"用自然语言给 LLM 明确指令",上下文越清晰、逻辑越连贯,AI 输出的结果就越精准。
下一篇文章,我们将基于本文的提示词工程基础,进一步学习 LLM 的推理计算细节,以及如何将提示词工程与前端开发结合,实现简单的 AI 交互功能。跟着学习路径走,我们逐步从"会用 AI"走向"会用 AI 解决实际开发问题"。