开篇介绍:
hello 大家,上一篇博客中,我给大家介绍了进程的状态,那么也说了,接下来的几篇博客中,我们将不断围绕着进程展开解析,所以,再本篇博客中,我们就要来了解进程优先级以及进程切换、进程调度,这些都是进程中较为重要的内容,希望大家能有所收获。
废话不多说,我们开始。
进程优先级:
进程优先级是 Linux 多任务调度的 "核心规则"------ 相当于给 CPU 分配资源时的 "排队号",决定了哪个进程先 "办事"、哪个后 "办事"。下面从 "日常场景切入→逐点拆透原理→手把手实操→补全基础概念"进行解析。
3-3-1 基本概念:CPU 资源的 "分配规则",解决 "谁先抢 CPU" 的问题
核心定义(一句话懂)
进程优先级(priority)就是 "CPU 给谁先干活的顺序"------ 优先级高的进程,CPU 会主动先找它;优先级低的进程,得等 CPU 空闲了才轮到它,就像银行办事 "VIP 先办,普通号排队"。
为什么必须有优先级?(没有优先级会乱套!)
Linux 是 "多任务系统",比如你打开浏览器、微信、终端,后台还在跑杀毒软件、日志备份,可能同时有几百个进程在 "抢 CPU"。但 CPU 核心就那么几个(比如 4 核、8 核),没有规则的话:
- 关键进程(比如系统服务、键盘响应)可能被后台下载、日志统计这类 "不紧急" 的进程抢占,导致电脑卡顿、键盘按了没反应;
- 不重要的进程和重要进程抢资源,CPU 来回切换,效率极低(比如一边玩游戏一边后台备份,游戏卡顿,备份也慢)。
优先级的核心作用就是 "分轻重缓急":
- 保证系统核心进程(比如硬件驱动、网络服务)优先执行,避免系统崩溃;
- 让前台交互进程(比如浏览器、办公软件、游戏)响应更快,提升用户体验;
- 让后台进程(比如文件备份、日志分析)在 CPU 空闲时执行,不拖慢前台操作。
额外优化:给进程 "绑定专属 CPU",进一步提升效率
除了调优先级,还能把进程 "固定" 到某个 CPU 核心上(比如把游戏绑定到 CPU 0 和 1,备份程序绑定到 CPU 3),相当于给进程分配 "专属窗口",好处特别实在:
- 减少 "切换开销":进程在不同 CPU 核心间切换时,需要保存 / 恢复它的运行状态(比如当前执行到哪条指令、寄存器里的数据),绑定 CPU 后不用切换,省出资源;
- 避免 "资源争抢":比如把服务器的数据库进程绑定到核心 CPU,其他不重要的进程绑定到次要 CPU,保证数据库响应速度不被干扰。
生活类比(超形象)
把 CPU 想象成 "银行的办事窗口",进程就是 "来办事的客户":
- 高优先级进程 = VIP 客户(比如银行 VIP、紧急业务办理者):不用排队,直接到窗口办事;
- 低优先级进程 = 普通客户(比如存钱、转账的普通用户):得等 VIP 办完,再按顺序排队;
- 绑定 CPU = 给客户分配 "专属窗口":比如给企业大客户分配专门的窗口,不用和普通客户挤,办事更快,也不影响其他人。
实操小补充:怎么绑定 CPU?(简单提一句,后面可展开)
用taskset命令就能绑定,比如把 PID 1234 的进程绑定到 CPU 0 和 1(核心编号从 0 开始):
taskset -cp 0,1 1234执行后,这个进程只会在 CPU 0 和 1 上运行,不会跑到其他核心。
补充:进程优先级和权限的区别:
OK大家,那么看完了进程优先级的概念之后,我们知道,它是控制进程的优先与否,那么这个时候大家可能会好奇,诶,那进程优先级和我们之前所学的权限有什么区别呢?两个好像都是优先前后呀。
那么其实它们的区别很简单,那就是:权限是能不能获得资源(即掌握着有没有资格获得资源),而进程优先级是获得资源的先后顺序,那么想要有所谓的获得资源的先后顺序,就肯定要先有资格获得资源吧,这就是它们之间的区别。
3-3-2 查看系统进程:用ps -l读懂优先级的 "5 个关键字段"
要调优先级,先得 "看懂进程的优先级信息"。最常用的命令是ps -l(l是 "长格式",会显示和优先级相关的核心字段),执行后输出类似这样:
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 R 1000 12345 9876 0 80 0 - 34567 - pts/0 00:00:01 bash
0 S 1000 12346 12345 0 85 5 - 23456 - pts/0 00:00:00 sleep 60
0 R 0 1237 1 0 70 -10 - 12345 - ? 00:05:30 nginx我们不用管所有字段,重点盯UID、PID、PPID、PRI、NI这 5 个 ------ 它们是操作优先级的 "关键钥匙",逐个拆透:
1. UID:进程的 "主人身份",决定你能不能调优先级
- 含义:进程执行者的用户 ID,相当于 "谁启动的这个进程";,前面我也有说过,系统是不认我们自己的username的,它只认UID,UID就是用户身份在系统中的身份证号。
- 常见值:
0是 root 用户(系统管理员,"超级用户"),1000左右是普通用户(你登录电脑的账号); - 关键影响:
- root 用户:能调整所有进程的优先级(包括别人的进程、系统进程),还能设置负的 NI 值(提高优先级);
- 普通用户:只能调整自己的进程,且不能设置负的 NI 值(只能降低或保持优先级)------ 防止普通用户滥用权限,抢占系统核心资源。
2. PID:进程的 "身份证号",操作进程的唯一标识
- 含义:每个进程启动后,系统会分配一个唯一的数字编号(比如 12345),就像人的身份证号,不会重复;
- 作用:后续调整优先级、终止进程(
kill命令),都要靠 PID 定位目标进程; - 小技巧:如果不知道进程 PID,用
ps -l | grep 进程名查找,比如找sleep进程的 PID:ps -l | grep sleep,输出里的数字就是 PID(比如 12346); - 范围:默认 0-32767(系统最多支持 32768 个进程同时运行,可通过内核参数调整)。
3. PPID:进程的 "爸爸 ID",知道谁启动了它
- 含义:PPID 是 "父进程 PID"------ 除了系统启动的第一个进程(1 号进程
init/systemd),所有进程都是被其他进程 "创建" 的,创建它的就是 "父进程"; - 例子:上面的
sleep进程(PID 12346)的 PPID 是 12345(bash进程),说明sleep是你在终端(bash)里输入sleep 60启动的; - 实用场景:如果某个进程占用资源过高,想调优先级,可通过 PPID 找到它的 "父进程",判断是不是重要进程(比如父进程是
nginx,可能是 web 服务,不能随便调低优先级)。
4. PRI:进程的 "实际排队号",值越小越先办
- 核心含义:PRI 是 "实际执行优先级",相当于银行窗口的 "排队号"------ 数字越小,排队越靠前,CPU 越先给它分配时间;
- 默认值:绝大多数进程的默认 PRI 是
80------ 这是 Linux 内核调度器(CFS调度器)的 "基准值",就像银行默认给普通客户发 "80 号"; - 关键特点:用户不能直接改 PRI!PRI 是内核根据 NI 值、进程状态(比如 R/S/D)、系统负载动态计算的结果,你能改的只有 "修正项 NI",间接影响 PRI。
5. NI:进程的 "排队号修正券",决定 PRI 往前移还是往后移
- 核心含义:NI 是 "nice 值",相当于给进程的 "排队号优惠券"------ 用来修正 PRI 的数值,和 PRI 是 "绑定关系";
- 取值范围:
-20(最大优惠,排队号往前移最多)到19(最大惩罚,排队号往后移最多),共 40 个级别,那么用到PRI身上就代表说,PRI的范围是60到99,至于0-59是什么,那就和我们下面要讲的进程调度有关,其实是实时调度。 - 默认值:
0(无优惠无惩罚,PRI=80+0=80,按默认排队); - 通俗理解:
- NI=-20:相当于 "VIP 优惠券",排队号直接减 20(PRI=60),比默认进程靠前很多;
- NI=19:相当于 "普通优惠券",排队号加 19(PRI=99),比默认进程靠后很多;
- NI=0:无券,按默认号排队。
其他字段快速解读(帮你看懂进程状态)
- S:进程状态(比如
R= 运行态、S= 可中断睡眠态,之前详细讲过); - C:进程当前占用 CPU 的百分比(比如
0表示暂时没占用 CPU,50表示占用一个核心的 50%); - CMD:启动进程的命令(比如
bash是终端、sleep 60是睡眠命令、nginx是 web 服务)。
3-3-3 PRI and NI:核心联动关系,用 "公式 + 例子" 秒懂
这是优先级的 "核心知识点"------PRI 是 "最终排队号",NI 是 "修正券",两者通过一个简单公式联动,用户只能通过调 NI 来改 PRI。
核心公式(记下来,永远不会错)
80调整后的实际优先级(PRI(new))= 原始优先级(PRI(old)80) + NI值- PRI (old):默认是 80(绝大多数情况);
- NI 值:你设置的修正值(-20~19);
- PRI (new):最终用来排队的优先级,值越小越优先。
3 个实际例子,彻底懂联动
例子 1:默认情况(NI=0)------ 按原号排队
- 场景:普通用户启动
bash终端(默认进程); - 计算:PRI (old)=80,NI=0 → PRI (new)=80+0=80;
- 结果:和其他默认进程一起排队,按 "时间片轮转" 方式共享 CPU(比如每个进程分 10 毫秒 CPU 时间,轮流执行)。
例子 2:提高优先级(NI 为负值)------ 排队号往前移
- 场景:root 用户启动游戏进程,想让游戏更流畅,设置 NI=-5;
- 计算:PRI (old)=80,NI=-5 → PRI (new)=80-5=75;
- 结果:PRI=75 比默认的 80 小,排队更靠前,CPU 会优先给游戏分配时间,游戏响应更快;
- 适用场景:关键进程(游戏、实时数据处理、服务器核心服务如
mysql),需要快速响应。
例子 3:降低优先级(NI 为正值)------ 排队号往后移
- 场景:普通用户启动后台备份程序(
rsync同步文件),不想让它影响前台浏览器操作,设置 NI=10; - 计算:PRI (old)=80,NI=10 → PRI (new)=80+10=90;
- 结果:PRI=90 比默认的 80 大,排队靠后,只有当 CPU 空闲时(比如你不操作浏览器、不玩游戏),备份程序才会占用 CPU,不会拖慢前台。
为什么 NI 的范围是 - 20~19?(内核的 "安全限制")
不是内核随便定的,而是为了 "保护系统稳定":
- 下限 - 20:防止用户把进程优先级调得太高(比如 NI=-20,PRI=60),抢占系统核心进程(比如内核驱动、硬件响应进程,默认 PRI 可能在 60 以下),导致系统卡顿、崩溃;
- 上限 19:防止用户把进程优先级调得太低(比如 NI=19,PRI=99),导致进程长期得不到 CPU 资源(比如备份程序跑了一天还没完成);
- 40 个级别:既能满足 "精细调整"(比如轻微提高 1 级、降低 3 级),又不会因为级别太多导致管理复杂(比如 100 个级别,用户不知道该设多少)。
关键注意点(避坑指南)
- NI 是 "修正值",不是优先级本身 ------ 优先级最终看 PRI,但你不能直接改 PRI,只能改 NI;
- 不同系统默认 PRI 可能不同(比如有些嵌入式 Linux 默认 PRI=120),但联动公式不变(PRI (new)=PRI (old)+NI);
- 普通用户不能设负 NI------ 比如你是普通用户,想给
sleep进程设 NI=-3,会报错 "Operation not permitted",必须用sudo切换到 root 用户; - NI 值一旦设置,会一直生效 ------ 除非你重新调整,或者进程退出,比如设置
nice -n 5 sleep 60,整个 60 秒内,这个sleep进程的 NI 都是 5。
3-3-4 PRI vs NI:一张表分清,再也不混淆
| 对比维度 | PRI(实际执行优先级) | NI(nice 值 / 优先级修正值) |
|---|---|---|
| 核心含义 | 最终用来排队的 "号码",谁先执行看它 | 给排队号 "加减分" 的修正券 |
| 取值范围 | 内核动态计算(默认 80 左右) | 固定 - 20~19(共 40 个级别) |
| 用户可操作性 | 不能直接改,内核说了算 | 可以通过命令 / 函数改(root 权限更自由) |
| 联动关系 | 被 NI 影响,PRI (new)=PRI (old)+NI | 主动影响 PRI,是 "因" |
| 优先级影响 | 值越小,越先执行 | 负值→PRI 变小(往前排);正值→PRI 变大(往后排) |
| 默认值 | 80(大多数系统) | 0(无修正) |
| 实际用途 | 内核调度时判断顺序 | 用户调整进程优先级的 "工具" |
3-3-5 查看与调整进程优先级:3 种方式 + 编程实现(手把手实操)
方式 1:用top命令 ------ 实时监控 + 调整已运行的进程
top是 Linux "进程监控神器",既能实时看进程状态,又能直接调整优先级,适合 "临时调整正在运行的进程"(比如游戏卡了,临时提高优先级)。
实操步骤(以调整sleep进程为例,全程可视化)
- 先启动一个要调整的进程:在终端执行
sleep 100(让进程睡眠 100 秒,方便我们调整); - 执行
top命令,进入实时监控界面 ------ 会看到所有进程的 PID、PRI、NI、CPU 占用等信息(按M可按内存排序,按P可按 CPU 排序,方便找进程); - 快速找到目标进程:在
top界面按/,输入sleep,回车 ------ 会高亮显示所有sleep进程,记下它的 PID(比如 12346); - 开始调整优先级:按
r键("renice" 的缩写,意思是 "重新设置 nice 值"); - 输入进程 PID:终端提示 "PID to renice:",输入 12346,回车;
- 输入要设置的 NI 值:提示 "Renice PID 12346 to value:",比如输入
-5(注意:普通用户输负数会报错,这里用sudo top启动top,获得 root 权限); - 确认调整:按回车,界面会显示 "Renice successful",表示调整成功;
- 查看结果:在
top界面找到该进程,会发现 NI 值变成-5,PRI 值变成75(80-5); - 退出
top:按q键即可。
示例效果(前后对比)
- 调整前:
PID 12346 | PRI 80 | NI 0 | CMD sleep 100 - 调整后:
PID 12346 | PRI 75 | NI -5 | CMD sleep 100
避坑指南
- 普通用户调负 NI 报错:解决办法是用
sudo top启动(需要输入 root 密码),或者切换到 root 用户(su - root); - 找不到进程:在
top界面按/搜索进程名,比手动找快很多; - 调整后 PRI 没变化:可能进程处于睡眠态(S/D),等进程被唤醒(比如
sleep结束),PRI 会按公式重新计算。
方式 2:用nice命令 ------ 启动新进程时,直接设置优先级
**nice命令的作用是 "给新进程发一张修正券"------ 进程一启动,NI 值就生效,适合 "提前规划进程优先级"(比如启动备份程序时,直接设低优先级),**我们需要知道,nice命令的使用是在进程还没开始的时候,而不是进程开始了才使用nice,还有就是在nice之后,nice -n后面的命令(进程)也同时开始进行,就是说在我们使用nice指令的时候,不仅是设置某个进程的NI值,也是同时开始那一个进程。
基本语法
nice -n [NI值] 要启动的命令-n:指定 NI 值(可选,不写的话默认 NI=0);- 命令:要启动的进程(比如
sleep 60、./a.out、rsync 源目录 目标目录)。
实操示例(分普通用户和 root 用户)
示例 1:普通用户启动低优先级进程(只能设非负 NI)
# 普通用户启动sleep 60,设置NI=5(优先级比默认低)
nice -n 5 sleep 60-
含义:这个
sleep进程一启动,NI 就是 5,PRI=80+5=85,会等默认进程执行完再占用 CPU; -
验证:另开终端执行
ps -l | grep sleep,输出如下(NI=5,PRI=85):0 S 1000 12347 9876 0 85 5 - 23456 - pts/0 00:00:00 sleep 60
示例 2:root 用户启动高优先级进程(可以设负 NI)
# root用户启动自己写的程序a.out,设置NI=-10(优先级比默认高)
sudo nice -n -10 ./a.out-
含义:
a.out程序一启动,NI 就是 - 10,PRI=80-10=70,会优先抢占 CPU; -
验证:执行
ps -l | grep a.out,输出如下(NI=-10,PRI=70):plaintext
0 R 0 12348 9876 0 70 -10 - 45678 - pts/0 00:00:01 ./a.out
简化写法(少写一个-n)
nice命令的-n可以省略,直接用 "nice [NI值] 命令",注意 NI 值前面要加-或+:
nice -5 ./a.out # 等价于 nice -n -5 ./a.out(root可用,提高优先级)
nice +5 sleep 60 # 等价于 nice -n 5 sleep 60(普通用户可用,降低优先级)
nice 0 sleep 60 # 等价于 nice -n 0 sleep 60(默认优先级)避坑指南
- 普通用户设负 NI 报错:比如
nice -n -3 sleep 60,会提示 "Operation not permitted",解决方案是加sudo; - 命令输错导致 NI 失效:比如
nice -n 5 sleep 60写成nice -n5 sleep 60(-n和 5 之间没空格),会报错 "invalid option",必须加空格。
方式 3:用renice命令 ------ 调整已运行的进程,适合批量操作
renice命令专门用来 "修改已经在运行的进程的 NI 值",语法比top更简洁,还能批量调整多个进程,适合 "脚本自动化调整" 或 "一次性改多个进程",这个指令就是对已经开始的进程进行它的进程优先级的调整,即对已经开始的进程的NI值进行调整。
基本语法
renice [要设置的NI值] -p [进程PID1] [进程PID2] ...[要设置的NI值]:范围 - 20~19;-p:指定进程 PID(必须加,否则会报错);- 多个 PID:用空格分隔,比如同时调整 PID 12346 和 12347。
实操示例
示例 1:root 用户调整单个进程(提高优先级)
# 把PID 12346的进程NI设为-8,PRI=80-8=72
sudo renice -8 -p 12346- 执行后输出:
12346 (process ID) old priority 0, new priority -8(旧 NI=0,新 NI=-8); - 验证:
ps -l | grep 12346,会看到 NI=-8,PRI=72。
示例 2:普通用户批量调整多个进程(降低优先级)
# 把PID 12346和12347的进程NI都设为10,PRI=80+10=90
renice 10 -p 12346 12347-
执行后输出:
12346 (process ID) old priority 0, new priority 10 12347 (process ID) old priority 0, new priority 10 -
验证:
ps -l | grep -E "12346|12347",两个进程的 NI 都是 10,PRI 都是 90。
避坑指南
- 批量调整时 PID 不能错:如果输了一个不存在的 PID(比如 12349),会报错 "12349: no process found",但不影响其他 PID 的调整;
- 普通用户不能给进程 "提优先级":比如普通用户把 PID 12346 的 NI 从 5 改成 3(提高优先级),会报错 "Operation not permitted",只能改成比当前 NI 大的值(比如 5 改成 10),这个要注意和nice的普通用户不能设置NI为负值区分开来。
方式 4:编程实现 ------ 用getpriority和setpriority函数(C 语言)
如果需要在自己写的程序中 "动态获取 / 设置优先级"(比如游戏程序启动时自动提高自己的优先级),可以用 Linux 的系统函数,简单介绍如下(不用深入代码,知道怎么用就行):
-
getpriority:获取进程的 NI 值#include <sys/resource.h> // 必须包含这个头文件
// 参数说明:
// which:要获取的对象类型,填PRIO_PROCESS(表示按PID获取)
// who:进程PID,填0表示"当前进程"
int getpriority(int which, int who);
-
返回值:成功返回进程的 NI 值(-20~19),失败返回 - 1(并设置
errno表示错误原因); -
示例:获取当前程序的 NI 值:
#include <sys/resource.h> #include <stdio.h> int main() { // 获取当前进程的NI值 int ni = getpriority(PRIO_PROCESS, 0); printf("当前进程的NI值:%d\n", ni); // 默认输出0 return 0; }
-
setpriority:设置进程的 NI 值#include <sys/resource.h> // 必须包含这个头文件
// 参数说明:
// which:对象类型,填PRIO_PROCESS(按PID设置)
// who:进程PID,填0表示"当前进程"
// prio:要设置的NI值(-20~19)
int setpriority(int which, int who, int prio);
-
返回值:成功返回 0,失败返回 - 1(并设置
errno); -
示例:把当前程序的 NI 值设为 5:
#include <sys/resource.h> #include <stdio.h> int main() { // 设置当前进程的NI值为5 int ret = setpriority(PRIO_PROCESS, 0, 5); if (ret == 0) { printf("NI值设置成功!\n"); } else { printf("设置失败,可能是权限不够(普通用户不能设负NI)\n"); } return 0; } -
编译运行:
gcc test.c -o test && ./test(普通用户运行,设 NI=5 成功;设 NI=-3 失败)。
3-3-6 补充概念:竞争、独立、并行、并发(懂了这些,才懂为什么需要优先级)
这 4 个概念是多任务操作系统的 "基础逻辑",搞懂它们,你才能真正理解 "优先级存在的意义"------ 不是为了复杂,而是为了解决多进程运行时的实际问题。
1. 竞争性:进程抢资源的 "本质原因"
- 核心含义:系统里的进程数量,远大于 CPU、内存等资源的数量,进程之间必须 "竞争" 才能拿到资源;
- 生活例子:银行只有 2 个窗口(CPU 核心),但有 10 个客户(进程)要办事,客户之间必然要竞争窗口资源;
- 实际表现:你打开浏览器、微信、备份程序,4 核 CPU 要处理这 3 个进程 + 系统后台进程,必然有 "抢 CPU" 的情况;
- 优先级的作用:在竞争中 "定规则",让重要的进程先抢到资源,避免混乱。
2. 独立性:进程之间 "互不干扰" 的保障
- 核心含义:每个进程都有自己独立的 "运行环境"------ 比如独立的内存空间、独立的文件句柄、独立的 CPU 状态(寄存器、程序计数器),运行时互不影响;
- 生活例子:银行的每个客户办事都是独立的,A 客户的业务失败(比如密码输错),不会影响 B 客户办理转账;
- 实际表现:浏览器进程崩溃(闪退),微信进程依然能正常聊天;备份程序占用 1GB 内存,不会导致终端命令无法执行;
- 为什么重要:独立性让多任务运行 "更稳定",而优先级在稳定的基础上 "优化效率"------ 如果进程之间互相干扰,再高的优先级也没用(比如一个进程崩溃导致整个系统卡死)。
3. 并行:多个 CPU "同时干活",效率最高
- 核心含义:当系统有多个 CPU 核心时,多个进程可以在 "同一时刻",分别在不同核心上执行 ------ 真正的 "同时进行";
- 生活例子:2 个厨师(2 核 CPU)同时做 2 道菜(2 个进程),一道炒青菜,一道红烧肉,同时开工,同时完成;
- 实际表现:4 核 CPU 同时运行浏览器(CPU 0)、微信(CPU 1)、备份程序(CPU 2)、音乐播放器(CPU 3),4 个进程同时执行,互不等待;
- 优先级的作用:即使并行,高优先级进程也会 "占用更好的资源"------ 比如把游戏进程分配到性能更好的 CPU 核心(比如 Intel 的大核),普通进程分配到小核。
4. 并发:单 CPU "假装同时干活",靠快速切换
- 核心含义:当系统只有 1 个 CPU 核心时,多个进程通过 "快速切换" 的方式,在一段时间内都能推进 ------ 看起来像 "同时进行",但实际上是 "轮流干活",不用怀疑CPU怎么这么牛波一,科技是无极限的,而我的朋友,你也是。
- 生活例子:1 个厨师(1 核 CPU)要做 2 道菜(2 个进程),先炒 3 分钟青菜,再炖 5 分钟红烧肉,再回头炒 2 分钟青菜,循环往复,最终两道菜都做好;
- 实际表现:1 核 CPU 运行浏览器、微信、备份程序,CPU 会给每个进程分配 "时间片"(比如 10 毫秒):先执行浏览器 10 毫秒,再切换到微信 10 毫秒,再切换到备份程序 10 毫秒,循环往复;
- 优先级的作用:让高优先级进程获得 "更长的时间片" 或 "更频繁的切换机会"------ 比如浏览器的时间片是 20 毫秒,备份程序是 5 毫秒,这样浏览器响应更快,备份程序也能慢慢推进。
并行 vs 并发:一张表分清(再也不混淆)
| 对比维度 | 并行 | 并发 |
|---|---|---|
| 核心逻辑 | 多个 CPU 同时执行多个进程 | 单 CPU 快速切换,轮流执行多个进程 |
| 本质 | 真正的 "同时进行" | 看起来 "同时",实际是 "轮流" |
| 资源消耗 | 几乎无切换开销(不用保存进程状态) | 有切换开销(保存 / 恢复进程状态) |
| 生活例子 | 两个厨师同时做两道菜 | 一个厨师轮流做两道菜 |
| 实际表现 | 4 核 CPU 同时跑 4 个进程,每个进程占一个核 | 1 核 CPU 跑 4 个进程,每个进程轮流占 CPU |
进程切换:
**进程切换的核心是CPU 上下文切换------ 简单说就是 "CPU 从一个进程切换到另一个进程时,保存旧进程的运行状态、加载新进程的运行状态,让新进程接着跑" 的过程。**结合 Linux 内核 0.11 的实现逻辑和时间片机制,我们从 "为什么切→触发条件→怎么切" 逐步拆解,用生活类比 + 内核逻辑 + 代码核心,让你彻底懂透。
一、先搞懂:为什么需要进程切换?
之前我们说过,Linux 是多任务操作系统,进程数量远大于 CPU 核心数(比如 1 个 CPU 要跑 10 个进程)。但 CPU 同一时刻只能执行一个进程的指令,要实现 "看起来所有进程都在同时运行",就必须让 CPU "轮流服务" 每个进程 ------ 这个 "轮流" 的动作,就是进程切换。
举个生活类比:
- CPU 是 "厨师",进程是 "要做的菜",1 个厨师要做 10 道菜;
- 厨师不能做完一道再做下一道(否则有些菜要等很久),而是 "炒 3 分钟青菜→盛起来→炒 5 分钟红烧肉→盛起来→回头炒青菜";
- 这个 "盛起来(保存状态)→换另一道菜(加载状态)→继续炒" 的过程,就是 "进程切换",目的是让所有菜(进程)都能稳步推进,看起来像 "同时在做"。
核心目的:
- 实现多任务并发:让多个进程在有限 CPU 上 "同时推进",提升系统利用率;
- 保证公平性:通过时间片机制,让每个进程都能分到 CPU 时间,不会被某个进程长期独占;
- 响应优先级:高优先级进程可以打断低优先级进程(比如键盘输入进程打断后台下载),保证用户体验。
二、触发进程切换的关键:时间片(内核 0.11 的 "闹钟")
进程不会随便切换,必须有 "触发条件",其中最常见的就是时间片耗尽------ 这和你提到的 "时间片是计数器" 完全一致。
1. 时间片是什么?
- 本质:内核给每个进程分配的 "CPU 使用时长"(比如 10 毫秒),用一个计数器记录;
- 内核 0.11 的实现:每个进程的
task_struct(PCB)里有个counter字段,就是时间片计数器。进程被调度时,counter会被设为初始值(比如 10),每过 1 个时钟滴答(约 10 毫秒),counter减 1; - 触发切换:当
counter减到 0 时,时间片耗尽,内核会触发 "时钟中断",进而调用调度函数schedule(),开始进程切换。
2. 其他触发条件(除了时间片耗尽)
- 进程主动放弃 CPU:比如进程调用
sleep()(进入 S 状态)、等待 IO(进入 D/S 状态),会主动让内核切换到其他进程; - 高优先级进程唤醒:低优先级进程正在运行时,高优先级进程被唤醒(比如网络包到达),内核会打断低优先级进程,触发切换;
- 进程退出:进程执行完(进入 X 状态),内核需要切换到其他就绪进程。
生活类比:
- 时间片就是 "厨师给每道菜分配的炒制时间"(比如每道菜先炒 3 分钟);
- 3 分钟到了(时间片耗尽),厨师就停手,换另一道菜;
- 如果某道菜需要等调料(进程等待 IO),厨师也会先换别的菜炒,不浪费时间。
三、进程切换的核心:CPU 上下文切换(内核 0.11 的实现步骤)
"CPU 上下文" 就是 CPU 运行一个进程时需要的 "全部状态信息"------ 主要是CPU 寄存器的值 (比如程序计数器 PC:记录下一条要执行的指令地址;栈指针 SP:记录当前栈的位置;通用寄存器:保存临时数据),以及进程的内核栈信息。
稍微了解一下寄存器:
OK大家,说实话,进程切换其实是和CPU中的寄存器有关的,所以,我们就需要了解一下寄存器,那么其实在我们目前这个阶段,我们不需要了解太多,我们仅需知道,寄存器其实是CPU中存储数据的一个空间,那么它里面的数据是可以随时被更换的,知道这个就够了。
对了,最后得补充一个很重要的注意点:寄存器!=寄存器内的内容,我们一般说的都是寄存器内的内容更换。
进程切换的本质就是 "保存旧进程的上下文→加载新进程的上下文→让新进程继续运行",Linux 内核 0.11 通过schedule()(调度函数)和switch_to()(切换函数)实现,步骤拆解如下(结合类比 + 代码逻辑):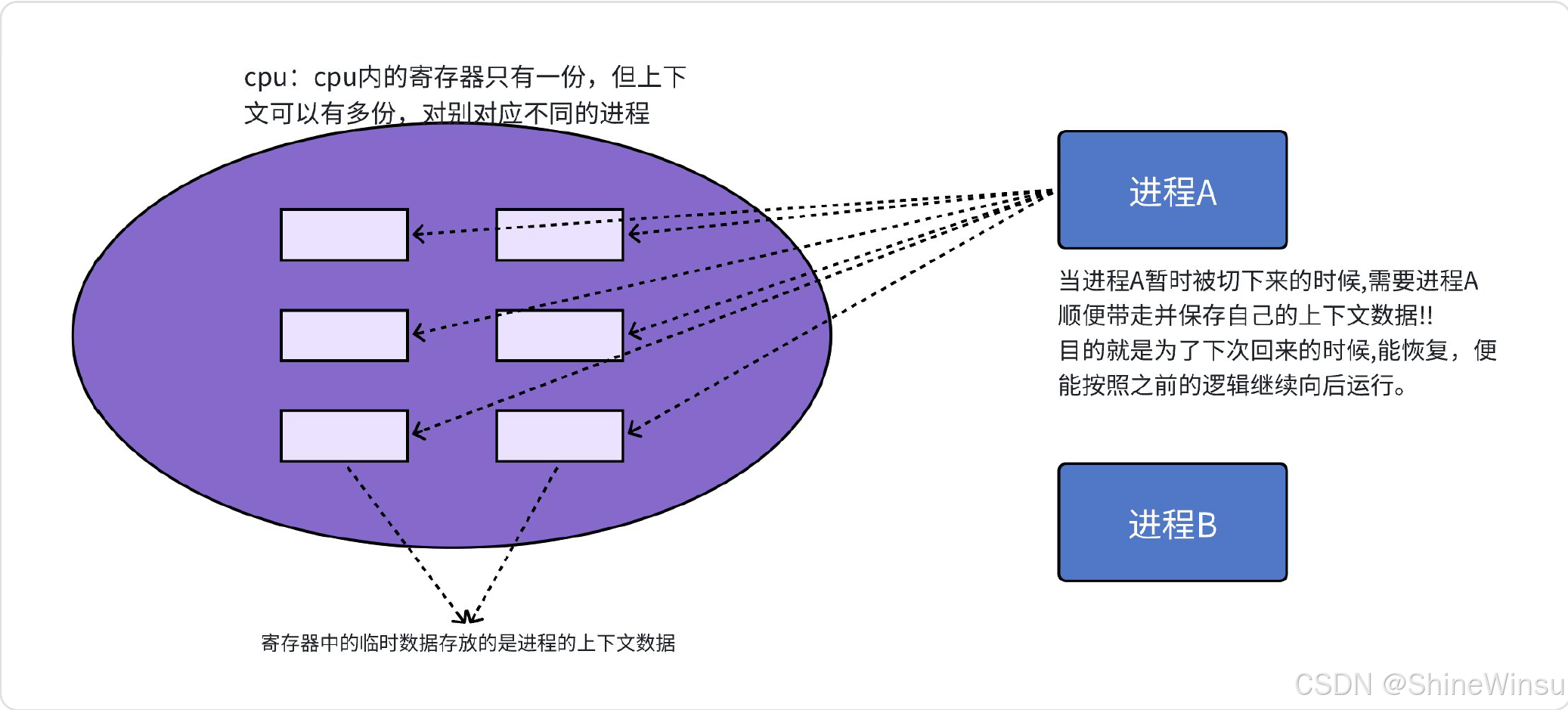
前提:所有进程的上下文都存在 PCB(task_struct)中
Linux 内核 0.11 的task_struct(PCB)里,有两个关键字段:
counter:时间片计数器(上面说过);kernel_stack:进程的内核栈指针(上下文信息会保存在这里);state:进程状态(R/S/D/T/Z 等)。
所有进程的task_struct通过链表串联(之前讲的list_head逻辑),schedule()函数会遍历这个链表,找到 "最该运行" 的进程(比如 R 状态、counter最大的进程)。
切换步骤(6 步走,超详细)
我们用 "厨师换菜" 类比,每一步对应内核操作:
步骤 1:触发切换(比如时间片耗尽)
- 场景:进程 A 正在 CPU 上运行,它的
counter减到 0(时间片耗尽),时钟中断触发; - 内核动作:中断处理程序会调用
schedule()函数,告诉内核 "该换进程了"; - 内核 0.11 代码逻辑:时钟中断处理函数
timer_interrupt()中,会调用do_timer(),do_timer()里让当前进程counter--,如果counter为 0,就设置need_resched标志(需要调度),中断返回后调用schedule()。
步骤 2:保存当前进程(A)的 CPU 寄存器状态
- 类比:厨师炒完菜 A 的 3 分钟,把 "当前炒到哪一步(比如青菜刚断生)、用了多少调料(临时数据)" 记在 "交接本" 上;
- 内核动作:
switch_to()函数会把 CPU 所有寄存器的值(程序计数器 PC、栈指针 SP、通用寄存器 AX/BX/CX 等),逐一保存到进程 A 的kernel_stack(内核栈)中; - 内核 0.11 代码逻辑:
switch_to()是汇编函数,通过pushl指令把寄存器值入栈,栈地址就是进程 A 的kernel_stack。
步骤 3:保存进程 A 的其他状态(PCB 更新)
- 类比:厨师在交接本上补充 "菜 A 的状态(比如正在炒)、下次该放什么调料(下一步指令地址)";
- 内核动作:更新进程 A 的
task_struct:- 把进程状态从 "R(运行态)" 改为 "R(就绪态)"(如果是时间片耗尽),或对应状态(比如等待 IO 就改为 S/D);
- 记录进程 A 的 "程序计数器 PC"(下次要执行的指令地址),方便后续恢复;
- 内核 0.11 代码逻辑:
schedule()函数会更新当前进程的state字段,然后把进程 A 放回 "就绪队列"(链表)。
步骤 4:选择下一个要运行的进程(B)
- 类比:厨师看 "待炒菜单",选一道 "最该炒的菜"(比如优先级最高、等待最久的菜 B);
- 内核动作:
schedule()函数遍历所有进程的task_struct链表,筛选出 "R 状态(就绪态)" 的进程,根据counter(剩余时间片)和优先级,选出 "下一个要运行的进程 B"; - 内核 0.11 代码逻辑:
schedule()会循环遍历task数组(内核 0.11 用数组管理进程),找到state为 TASK_RUNNING(R 状态)且counter最大的进程,作为下一个运行进程。
步骤 5:加载进程 B 的上下文(从 PCB 中恢复)
- 类比:厨师拿出菜 B 的 "交接本",照着上面的记录 "恢复状态"(比如菜 B 上次炒到半熟,现在继续炒;按记录放调料);
- 内核动作:从进程 B 的
kernel_stack中,逐一读出之前保存的寄存器值,加载到 CPU 的对应寄存器中:- 恢复程序计数器 PC:让 CPU 知道 "接下来要执行进程 B 的哪条指令";
- 恢复栈指针 SP:让进程 B 能继续使用自己的栈空间;
- 恢复通用寄存器:让进程 B 能继续处理之前的临时数据;
- 内核 0.11 代码逻辑:
switch_to()通过popl指令,从进程 B 的kernel_stack中弹出寄存器值,写入 CPU 寄存器。
步骤 6:切换页表(内存地址空间切换)
- 类比:厨师换菜时,要拿出菜 B 对应的 "食材和工具"(菜 A 的食材暂时收起来);
- 内核动作:每个进程有自己独立的内存地址空间(比如进程 A 的 0x1000 地址和进程 B 的 0x1000 地址指向不同物理内存),内核会切换页表寄存器(CR3),让 CPU 访问的是进程 B 的内存空间;
- 内核 0.11 代码逻辑:进程的
task_struct中有pgdir字段(页目录基地址),switch_to()会把pgdir的值写入 CR3 寄存器,完成地址空间切换。
最终结果:
CPU 开始执行进程 B 的指令,进程 B 从上次暂停的地方继续运行;进程 A 则留在就绪队列中,等待下次被调度(拿到时间片)。
四、内核 0.11 关键代码解析(不用懂汇编,看逻辑就行)

Linux 内核 0.11 的进程切换核心是两个函数:schedule()(C 语言,选进程)和switch_to()(汇编语言,切上下文),我们提炼核心逻辑,不用纠结语法:
1. schedule ():"选谁来运行"
void schedule(void) {
int i, next, c;
struct task_struct **p;
// 1. 遍历所有进程,找R状态且counter最大的进程
while (1) {
c = -1;
next = 0;
i = NR_TASKS; // NR_TASKS=64,内核0.11最多支持64个进程
p = &task[NR_TASKS];
while (--i) {
if (!task[i]) continue;
// 只考虑R状态的进程
if (task[i]->state == TASK_RUNNING && task[i]->counter > c) {
c = task[i]->counter;
next = i; // 记录选中的进程编号
}
}
if (c) break; // 找到有剩余时间片的进程,退出循环
// 所有进程时间片都为0,重新分配时间片(按优先级)
for (i=1; i<NR_TASKS; i++)
if (task[i])
task[i]->counter = (task[i]->counter >> 1) + task[i]->priority;
}
// 2. 调用switch_to(),切换到next进程
switch_to(next);
}核心逻辑:
- 先找 "R 状态 + 剩余时间片最大" 的进程(保证公平性,时间片多的先运行);
- 如果所有进程时间片都用完,就重新分配(
counter = 旧值/2 + 优先级),避免进程饿死; - 调用
switch_to()切换到选中的进程。
2. switch_to ():"怎么切过去"
switch_to:
; 1. 保存当前进程(prev)的寄存器到内核栈
pushl %ebp
pushl %ebx
pushl %esi
pushl %edi
; 2. 把当前进程的栈指针(esp)保存到task_struct的tss字段
movl %esp, task[%eax+4] ; task[eax]是当前进程,+4是tss字段偏移
; 3. 加载下一个进程(next)的栈指针到esp
movl task[%ecx+4], %esp
; 4. 恢复next进程的寄存器
popl %edi
popl %esi
popl %ebx
popl %ebp
ret核心逻辑:
- 用
pushl保存当前进程的寄存器(ebp/ebx/esi/edi 是关键寄存器); - 保存当前进程的栈指针(esp)到它的
task_struct,方便后续恢复; - 加载下一个进程的栈指针(esp),让 CPU 使用新进程的栈;
- 用
popl恢复新进程的寄存器,最后ret跳转到新进程的程序计数器(PC),开始运行。
五、总结:进程切换的核心逻辑
进程切换 ="保存旧进程上下文→选新进程→加载新进程上下文",本质是 "CPU 寄存器和内存地址空间的切换",说白了,进程切换的最核心的部分就是,CPU要保存和恢复被切换的进程的上下文数据,而时间片是触发切换的核心机制(内核 0.11 用counter计数,耗尽就切换)。
简单说:
- 上下文是 "进程的运行状态快照"(寄存器 + 栈 + 内存地址);
- 切换就是 "快照保存→快照恢复";
- 内核 0.11 通过
schedule()选进程、switch_to()切上下文,实现了多任务并发。
进程调度:
Linux 2.6 的 O (1) 调度算法是操作系统调度的 "效率革命"------ 不管系统里有 10 个还是 10000 个进程,调度器总能瞬间找到最该运行的那个(时间复杂度固定为 O (1))。下面用 "医院分诊" 的生活场景类比,结合数据结构细节,一步步讲透这套机制的每一个零件和运作流程。
一、核心框架:每个 CPU 一个 "调度分诊台"(runqueue)
首先明确一个大前提:每个 CPU 核心都有自己专属的 "调度分诊台"(runqueue)。就像医院里每个诊室有自己的分诊台,负责管理本诊室的病人(进程)调度,互不干扰。
如果是多核 CPU(比如 4 核),就有 4 个这样的分诊台。系统会尽量让进程在一个分诊台(CPU)上处理,避免频繁跨 CPU 切换(类似病人固定在一个诊室看病,不用来回跑);如果某分诊台太忙,会把部分病人转移到空闲分诊台(负载均衡),但核心调度逻辑由每个分诊台独立完成。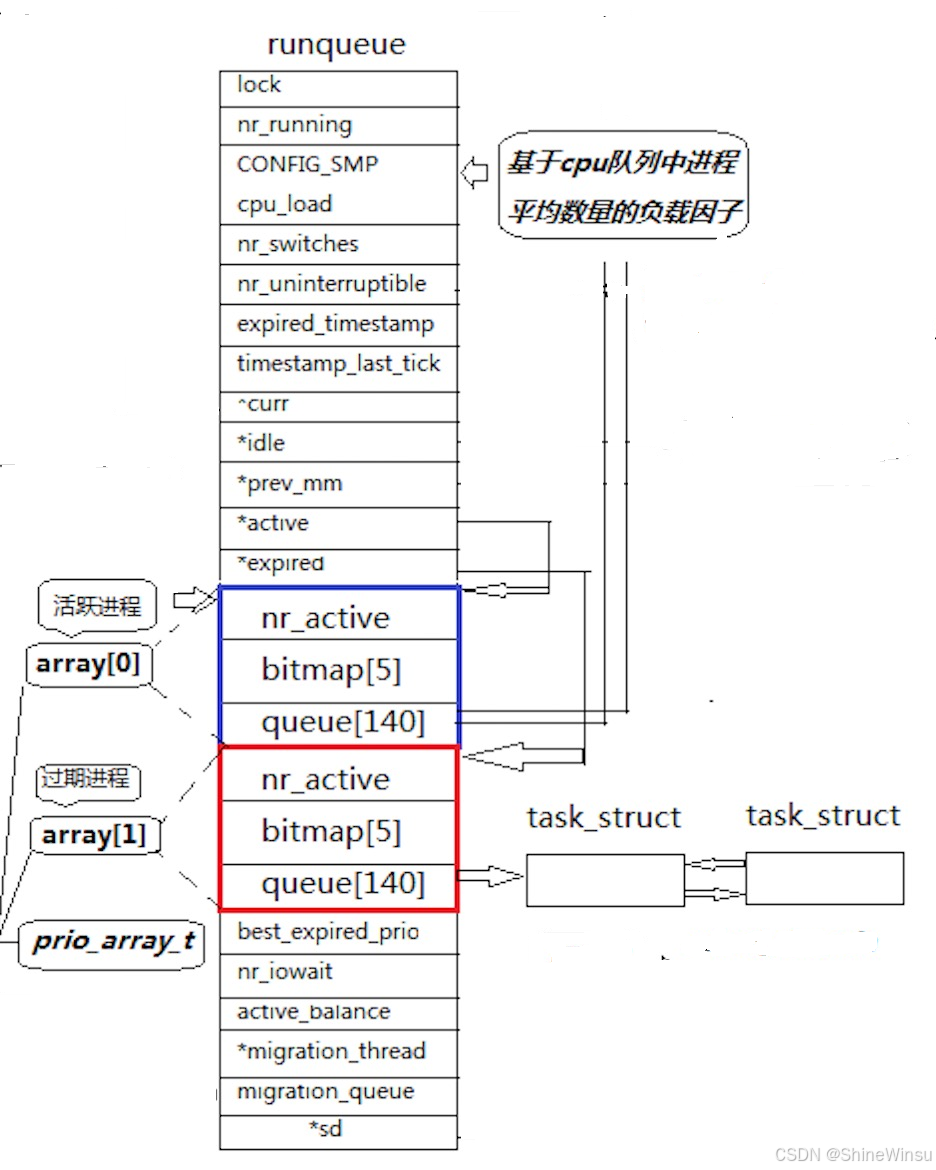
二、优先级:"病情紧急程度" 的分级(两类 140 级)
进程的 "优先级" 就像病人的 "病情紧急程度",决定了谁先被处理。Linux 2.6 把优先级分为两类,共 140 级:
| 优先级类型 | 数值范围 | 对应场景 | 和 nice 值的关系(普通优先级) |
|---|---|---|---|
| 实时优先级 | 0~99 | 系统核心任务(如硬件响应、工业控制),优先级最高 | 不涉及 nice 值 |
| 普通优先级 | 100~139 | 日常程序(浏览器、终端、后台脚本等) | nice 值 = 优先级 - 120(比如 nice=-20→100,nice=19→139) |
关键对应:我们平时调的 nice 值(-20~19),刚好对应普通优先级的 100~139。nice 值越小(越 "友好" 给高优先级),对应的优先级数值越小,越先被调度。
三、活动队列:"还没看完病的病人"(时间片未耗尽)
活动队列里的进程,都是时间片还没用完 的(类似病人还有 "就诊时间")。它的结构是prio_array(优先级数组),可以想象成 "候诊区",由三个核心部分组成:
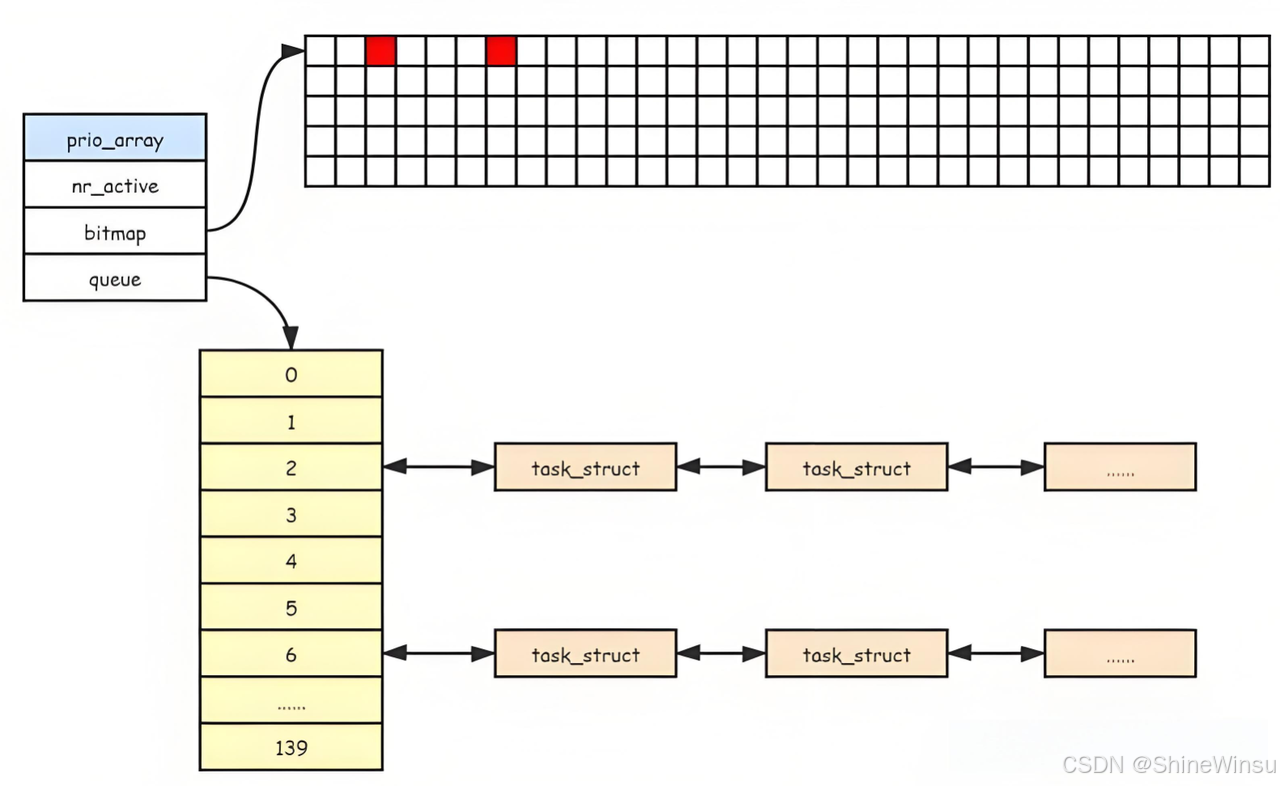
1. nr_active:候诊总人数
记录活动队列里所有优先级的进程总数(比如nr_active=20,表示当前有 20 个进程还没耗尽时间片,在候诊)。
2. queue[140]:按 "紧急程度" 分的候诊区
这是一个长度为 140 的数组,每个下标对应一个优先级(0~139),每个下标位置是一个 "双向链表"(排队的队伍),其实这个数组内存储的就是PCB,而且不只是一个PCB,而是多个进程优先级相同的PCB。
- 规则:相同优先级的进程在同一个链表中,按 "先进先出(FIFO)" 排队(先到的先看病);
- 优先级越高(数值越小),下标越小,对应的候诊区越靠前(比如优先级 100 的队列在
queue[100],比queue[120]的进程先被处理)。
类比:医院候诊区分成 140 个小区域,编号 0~139。0 号区是 "濒危病人"(实时最高优先级),100 号区是 "急诊病人"(nice=-20),139 号区是 "普通体检"(nice=19)。每个区域里的病人按先来后到排队。
3. bitmap[5]:"候诊区指示灯"(O (1) 的核心!)
这是整个调度算法的 "点睛之笔"------ 用 5 个 32 位整数(共 5×32=160 个比特位)组成的 "位图",标记 140 个候诊区(queue[0]~queue[139])是否有病人(进程),数组下标为0的数字的32个比特为就代表着deque的0-31,而下标为1的数组的32个比特为就代表着deque的32-63,后面的以此类推,还是很好理解的,其实本质和哈希表挂钩。
- 每个比特位对应一个候诊区:如果某候诊区有进程(非空),对应比特位设为 1(灯亮);否则为 0(灯灭);
- 作用:调度器不用逐个检查 140 个候诊区,只需扫一眼位图,找到第一个亮着的灯(最小的非零比特位),就能立即定位 "优先级最高的非空队列"。
- 那么执行过程也是很简单,一共有5个数字,然后系统扫一眼,看一下那个位置不为0,直接锁定那一个数字,再看一下那个数字里的哪个比特位不为0(即为1),那么此时就代表queue里面的这一个位置进程需要进行了。
类比:候诊区门口有一排指示灯(共 140 个),每个灯对应一个区域。0 号区灯亮表示有濒危病人,100 号区灯亮表示有急诊病人。调度器(医生)不用挨个区看,扫一眼指示灯,哪个灯亮且编号最小(最紧急),就直接去那个区叫第一个病人。
四、过期队列:"就诊时间用完的病人"(时间片耗尽)
过期队列和活动队列结构完全一样(也是prio_array),但里面放的是时间片已经用完的进程(类似病人的就诊时间到了,暂时不能继续看,需要重新排期)。
- 当一个进程的时间片耗尽(比如分配了 10ms,用完了),调度器会把它从活动队列移到过期队列的对应优先级队列中;
- 当活动队列里的进程全被处理完(候诊区空了),调度器会交换活动队列和过期队列的指针(相当于把 "过期队列" 改名为 "活动队列"),同时给过期队列里的所有进程重新计算时间片(比如按优先级分配新的时间),让它们变成 "新的活动进程" 继续候诊,这一个是非常关键的步骤,我们知道,上图的active指针是指向活动队列,而expired指针是指向过期队列,那么当活动队列的进程都被搞定了,是不是就要去处理过期队列的进程了,那么active指针和expired指针的指向是不能变的,但是又要怎么活动队列去有过期队列的进程呢?其实就是交换两个指针指向的内容就行了,非常的简单,大家之前C语言里面肯定不陌生这一块,因为我们要知道,CPU只会去处理活动队列里的进程的,而过期队列的进程,它是不管的,这一点大家一定要深深的知道。
类比:活动队列是 "当天上午的候诊病人",过期队列是 "当天上午没看完、需要下午再看的病人"。上午的病人全看完后,下午直接用过期队列里的病人(重新计算就诊时间),不用重新挂号。
五、调度流程:"医生叫号" 的 4 步高效流程
调度器选择下一个进程的过程,就像医生在分诊台叫号,全程不超过 4 步,且和病人数量无关:
步骤 1:锁定分诊台(避免混乱)
调度器先加锁(spinlock_t lock),防止多线程同时操作队列(类似医生叫号时,分诊台暂时不接受新病人挂号,避免混乱)。
步骤 2:用 "指示灯" 找最紧急的候诊区
调度器扫描活动队列的bitmap,找到第一个为 1 的比特位(最亮且最靠前的灯),确定最高优先级的非空队列(比如queue[100])。
- 这一步是 O (1) 的关键:不管有多少候诊区,扫位图的时间固定(最多检查 5 个 32 位整数)。
步骤 3:叫队头的病人(取进程)
从找到的队列(queue[100])中,取出链表的第一个进程(队头进程,先到先得)。
步骤 4:运行进程,处理时间片
- 把 CPU 分配给这个进程,开始执行;
- 进程运行时,时间片计数器不断递减;
- 时间片耗尽时,把进程移到过期队列的对应优先级队列,更新活动队列和过期队列的
nr_active和bitmap(比如活动队列的queue[100]灯灭,过期队列的queue[100]灯亮)。
特殊情况:活动队列空了怎么办?
如果活动队列的nr_active变成 0(上午的病人全看完了),调度器会:
- 交换
active和expired指针(让过期队列变成新的活动队列); - 给新活动队列(原过期队列)里的所有进程重新计算时间片(比如按优先级分配新的时间);
- 重复步骤 2~4,继续调度。
六、数据结构对应:代码里的 "分诊台零件"
结合内核代码,看看这些结构在代码里是如何定义的(不用懂语法,看字段对应关系):
1. struct rq(调度分诊台)
struct rq {
spinlock_t lock; // 分诊台的锁(防止混乱)
unsigned long nr_running; // 正在运行的进程总数
struct task_struct *curr; // 当前正在CPU上运行的进程(正在看病的病人)
struct task_struct *idle; // 空闲进程(没人看病时,CPU运行idle)
// 活动队列和过期队列的指针(指向arrays里的两个prio_array)
struct prio_array *active, *expired;
struct prio_array arrays[2]; // 实际存储两个队列(活动和过期各一个)
};active和expired是 "指针",平时分别指向arrays[0](活动队列)和arrays[1](过期队列);- 交换队列时,只需交换
active和expired的指向(比如active = &arrays[1]; expired = &arrays[0];),不用移动数据,效率极高。
2. struct prio_array(候诊区)
struct prio_array {
unsigned int nr_active; // 候诊的进程总数(当前区域有多少病人)
DECLARE_BITMAP(bitmap, MAX_PRIO+1); // 140个指示灯(MAX_PRIO=140)
struct list_head queue[MAX_PRIO]; // 140个候诊队列(每个优先级一个队伍)
};DECLARE_BITMAP(bitmap, 141):定义 141 个比特位(覆盖 0~140,留一个备用),实际用前 140 位;struct list_head queue[140]:140 个双向链表,每个链表存对应优先级的进程(病人排队的队伍)。
七、为什么叫 O (1) 调度?
"O (1)" 是算法时间复杂度的表示,意思是 "调度时间不随进程数量增加而变化"。
- 以前的调度算法(比如 Linux 2.4)需要遍历所有进程找最高优先级,进程越多,遍历越慢(时间复杂度 O (n));
- 而 Linux 2.6 通过 "位图定位 + 队列 FIFO",不管有 10 个还是 10000 个进程,找下一个进程的步骤都是固定的(扫位图→取队头),时间固定,所以叫 O (1) 调度。
总结:O (1) 调度的核心优势
这套机制就像给调度器装了 "精准导航":
- 用位图当 "指示灯",瞬间定位最高优先级队列;
- 用队列按优先级分组,保证同优先级进程公平排队;
- 用两个队列(活动 + 过期)交替,避免频繁重建队列;
最终实现了 "无论多少进程,调度都一样快",让 Linux 在多任务场景下(比如服务器、桌面系统)的响应速度大幅提升。
结语:在进程的世界里,读懂系统的 "生存法则"
敲下最后一个字符时,窗外的天已经暗了。回头看这篇关于进程优先级、切换与调度的文字,忽然想起第一次用top命令时的茫然 ------ 满屏滚动的数字里,PRI和NI像两个陌生的密码,进程状态的字母在眼前跳来跳去,完全不懂它们为什么时而R时而S,更不明白 CPU 到底在 "偏爱" 哪个进程。
现在再看,那些曾经晦涩的概念,其实都是系统在千万次实践中总结出的 "生存法则"。就像人类社会需要规则维持秩序,操作系统里的进程们,也靠着优先级、切换机制和调度算法,在有限的 CPU 资源里找到属于自己的位置。
那些藏在技术细节里的 "设计哲学"
写这篇博客时,最想和大家分享的,不是nice -n -5这样的命令语法,也不是switch_to函数的汇编代码,而是藏在这些细节背后的 "为什么"。
为什么优先级要分实时和普通?因为系统里既有 "一秒都不能等" 的硬件响应进程(比如键盘输入),也有 "慢慢来不着急" 的后台备份程序,它们的 "紧急程度" 本就不同。就像医院的急诊室永远为濒危病人敞开,而普通体检可以按号排队 ------ 这种分层,本质是对 "重要性" 的尊重。
为什么进程切换要保存上下文?因为 CPU 是个 "健忘的天才",它能瞬间完成复杂计算,却记不住上一个进程运行到了哪一行代码。所以需要像厨师炒完一道菜要记下火候那样,把寄存器里的状态好好存起来,下次才能接着炒。这种 "保存 - 恢复" 的逻辑,藏着多任务并发的核心秘密:不是真的 "同时",而是 "无缝衔接"。
为什么 O (1) 调度要用位图?因为当系统里有上万个进程时,"逐个找优先级最高的" 就像在字典里挨个翻页查字,效率低得可怕。而位图就像给字典加了个索引,一眼就能定位到目标 ------ 这种 "用空间换时间" 的思路,是计算机科学里最朴素也最精妙的智慧。
这些设计,从来都不是为了 "难倒学习者",而是为了让系统更高效、更稳定地服务于用户。就像我们学这些知识时,拆解task_struct的字段、分析schedule函数的逻辑,本质上也是在理解 "系统如何权衡公平与效率","如何在混乱中建立秩序"。
从 "会用" 到 "懂原理",隔着一次 "刨根问底"
刚开始学 Linux 时,我总满足于 "会用命令就行":知道renice能调优先级,top能看进程状态,就觉得够了。直到有一次,线上服务器的数据库突然卡顿,用ps看进程优先级都是默认的 80,top里 CPU 使用率也不高,却迟迟找不到原因。
后来跟着前辈排查,才发现是数据库进程被绑定到了性能较差的 CPU 小核上,而后台备份进程虽然优先级低,却占满了大核的缓存 ------ 这时候才明白,光知道taskset命令不够,得懂 "绑定 CPU 能减少切换开销" 的原理;光看PRI数值不够,得理解 "优先级背后是 CPU 时间片的分配策略"。
那次经历让我明白:技术的 "天花板",往往不在 "会用" 的层面,而在 "懂原理" 的深度。就像这篇博客里讲的:
- 你可以死记 "
PRI = 80 + NI",但理解 "NI 是用户给进程的'优惠券'",才能明白为什么普通用户不能设负 NI; - 你可以背下
switch_to的步骤,但想通 "上下文切换是为了让 CPU'假装同时做很多事'",才能理解为什么切换太频繁会让系统变慢; - 你可以记住 O (1) 调度 "用位图找队列",但想透 "这是为了在进程数量爆炸时保持效率",才能明白为什么服务器系统离不开这套机制。
从命令到原理,就像从 "知道车能开" 到 "知道发动机如何工作"。前者能让你应付日常驾驶,后者却能让你在车出故障时,知道该检查油路还是电路 ------ 这大概就是 "刨根问底" 的意义:它给你看透问题本质的能力。
写给正在和 "内核知识" 死磕的你
写这篇博客的过程中,我反复翻了 Linux 0.11 的源码,对着schedule函数的循环逻辑画了无数次流程图,甚至为了理解 "位图如何定位最高优先级",自己用 Python 写了个简化版的模拟程序。中间有好几次,盯着task_struct里的counter字段发呆:"为什么时间片耗尽要移到过期队列?""重新计算时间片时,为什么是counter = 旧值/2 + priority?"
后来突然想通:这些设计里藏着 "不让任何进程饿死" 的温柔。就像现实中,即使是优先级最低的后台进程,只要一直等,总会轮到它的时间片;就像排队时,即使排在最后,只要队伍在动,就总有轮到自己的时刻。
如果你现在也卡在某个概念里 ------ 可能是搞不懂CR3寄存器为什么要切换,可能是绕不明白活动队列和过期队列的交换逻辑,甚至只是记不住PRI和NI的区别 ------ 请一定别着急。
这些知识本就不是 "看一遍就懂" 的。内核开发者们用了几十年迭代出这些机制,我们花几周、几个月去拆解、去理解,太正常了。你可以像我一样,把ps -l的输出打印出来,对着字段一个个标含义;可以用top命令实时调整一个sleep进程的优先级,看着PRI数值变化;甚至可以找个旧版本的内核源码,对着schedule函数的注释一行行啃。
重要的是,别因为暂时看不懂就放弃。就像进程在就绪队列里等待调度,你的努力也在 "知识队列" 里排队 ------ 只要不停下,总会轮到它被 "CPU"(你的大脑)执行的时刻。
最后:进程的故事,也是系统的故事
进程优先级、切换与调度,看似是三个独立的知识点,实则是操作系统 "多任务能力" 的三大支柱:
- 优先级是 "规则",告诉系统 "谁更重要";
- 切换是 "手段",让系统能 "轮流服务" 不同进程;
- 调度是 "策略",保证系统在遵守规则的同时,效率最大化。
它们共同支撑起我们每天使用的 Linux 系统:让你在玩游戏时,键盘输入不会卡顿;让服务器在处理 thousands of 并发请求时,核心业务依然响应迅速;让后台备份程序默默跑完,却不打扰你刷网页。
而我们学习这些知识的过程,也是在和 "系统设计者" 对话。他们为什么这么设计?如果是我,会怎么优化?这种 "对话" 会慢慢培养一种思维:不满足于 "是什么",而是追问 "为什么",甚至思考 "如何更好"。
或许有一天,当你排查一个棘手的系统问题时,脑海里会闪过 "是不是优先级设反了?""会不会是进程切换太频繁?"------ 这时候,今天学的这些知识,就真正变成了你的 "武器"。
进程的世界永远在动态调度中向前,我们的学习之路也是。愿你在拆解每一个内核机制时,都能感受到技术背后的逻辑之美;愿你在和复杂概念死磕时,都能想起:每一个进程都在等待属于自己的时间片,每一份努力也终将被 "调度" 到收获的时刻。
下一篇,我们继续聊进程的更多故事。不见不散。