很多同学第一次遇到"内存泄漏排查"时,都会卡在同一个地方:系统监控告诉你内存在涨,但它不会告诉你到底是哪一行代码分配了这块内存,也不会告诉你为什么它没有被释放。top、ps、容器监控曲线都只能证明"有问题",却很难直接回答"问题在哪里"。这正是一个小型内存泄漏检测器存在的价值。它不是为了替代重量级分析工具,而是为了在工程现场里,用尽可能低的接入成本,把"正在泄漏的内存块"与"对应的调用路径"直接呈现出来,让排查从猜测变成定位。
这套检测器的核心思路可以概括成一句话:在内存分配发生的那一刻记录证据,在内存释放发生的那一刻更新账本,在需要的时候把"账本里还活着的分配"导出来。这里的"证据"最关键的一项就是调用栈。因为泄漏的本质是"某次分配没有走到对应释放",所以只要能稳定拿到分配时的调用链,通常就已经抓住了根因入口。项目里的 Allocation 结构承担的就是这件事,它不仅保存分配大小,还保存一段有限深度的栈帧地址;后续报告阶段再把地址还原成可读函数名,最终让读者看到"这块泄漏是从哪条业务路径来的"。
为了让整件事可维护、可扩展,这个项目把能力拆成了相互协作的几层。最前面是拦截层,它的职责不是分析内存,而是把目标进程里原本要调用 malloc/free/calloc/realloc/posix_memalign 的流量导向我们自己的 hook 函数。项目里既有 LD_PRELOAD 方式,也有注入改写方式,两条路虽然技术细节不同,但都会汇聚到统一的跟踪接口,例如 leak_detector_track_malloc、leak_detector_track_free、leak_detector_track_realloc。这一步非常关键,因为它决定了后面所有统计和报告是否有稳定数据源。
数据进入跟踪层之后,就会落到一个"正在存活分配"的全局状态里。最直观的实现就是 unordered_map<void*, Allocation>:地址作为 key,分配记录作为 value。每次分配就插入或更新,每次释放就删除对应项。到任意时刻,这个 map 里剩下的内容就是"尚未释放"的候选集合。这个集合本身并不保证 100% 都是 bug,因为有些进程会在生命周期末尾故意保留缓存,但它已经把问题空间从"全进程所有代码"缩小到了"几条明确调用链",这就是工程排查里最有价值的降维。为了保证并发场景正确性,这层通常会配互斥锁;为了避免 hook 过程中再次触发分配导致递归,项目还会有递归保护标记,这些都属于稳定性必需品,而不是可选优化。
当跟踪层写入一条新分配记录时,回溯层会同步抓取栈帧。实现上调用 backtrace() 获取返回地址数组,然后跳过内部框架帧,只保留业务更相关的部分,再在报告阶段用 backtrace_symbols() 和 __cxa_demangle() 做可读化。这里"最多 16 层"之类的配置,本质是性能与信息量之间的折中:层数太少可能丢上下文,层数太多会增加开销并拉长报告。对大多数业务来说,十几层已经足够把问题定位到模块甚至函数级别。换句话说,检测器不是在追求"完美还原每一层执行细节",而是在追求"以可接受成本给出足够可行动的定位信息"。
最后一层是控制与报告层,它决定这个工具是"能跑"还是"好用"。仅在进程退出时打印报告虽然简单,但真实排障中经常不够,因为很多服务要长期运行,不能为了看一次泄漏就重启。于是项目提供了运行中触发能力,例如通过信号快速生成报告,或者通过本地 Unix Socket 接收 report/pause/resume/stats/reset 等控制命令。这样一来,排查流程就从"事后复盘"变成"在线观察",可以在业务高峰、灰度期间、特定压测窗口实时抓快照,观察泄漏增长趋势,再决定是否继续深挖。
如果把上面这些放到一张架构图里,大致就是下面这样。读者可以先把它当作"导航图",后续每一篇再分别下钻到具体实现和坑点处理。
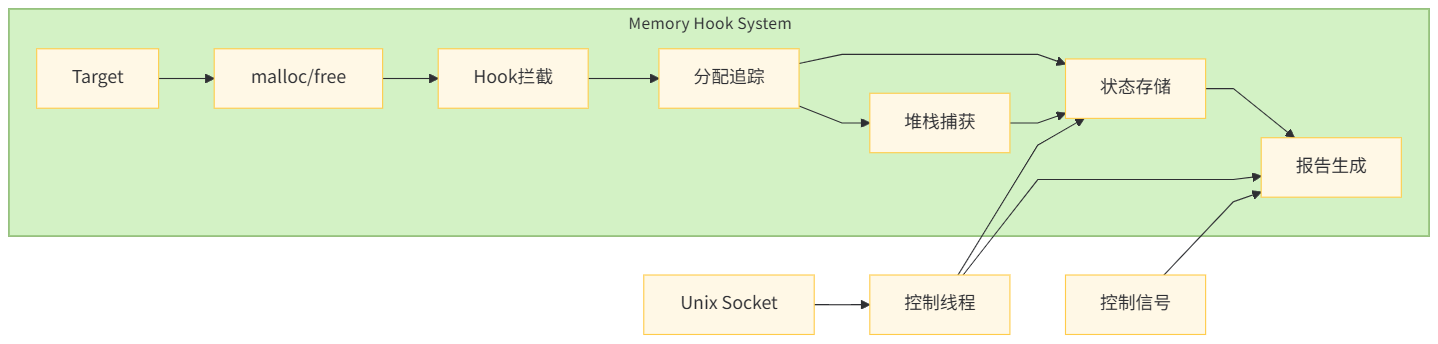
从工程实践角度看,这种设计最有价值的地方在于它天然支持"先跑通、再增强"。可以先做最小闭环:拦截 malloc/free、记录存活分配、进程退出输出报告;随后逐步补上 realloc/posix_memalign、符号反修饰、交互控制、统计维度、性能优化。每一步都有明确边界,不需要一开始就追求大而全。对于想自己动手实现工具链的读者来说,这正是一个理想的起点:复杂度可控,反馈周期短,收益直接可见。