前言
网络数据包从应用程序到物理网线的传输过程,是一个涉及多个内核子系统的复杂流水线。这个过程涵盖了从用户态系统调用,到传输层协议处理,再到网络层路由与封装,最终由网卡硬件完成数据发送的完整链路。
理解这一过程,不仅有助于编写高性能网络程序,更能在系统性能调优和故障诊断时,透过现象看本质。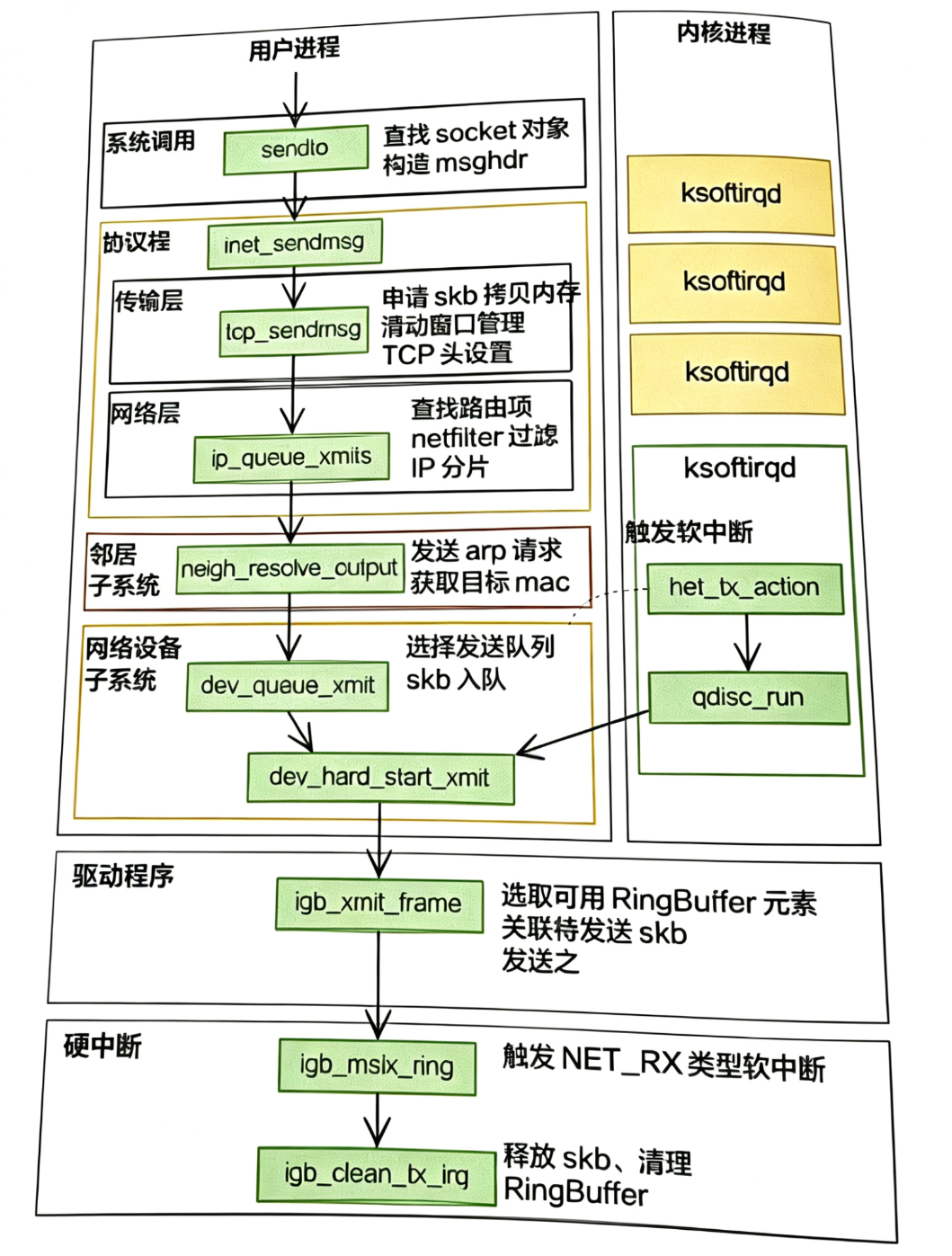
第一章 驱动初始化与硬件探测
1.1 PCI 总线枚举与设备发现
Linux 内核在启动阶段,PCI 子系统会对系统总线进行全面扫描。当扫描到网卡设备时,PCI 层会根据设备的 Vendor ID 和 Device ID 与已注册驱动的 ID 表进行匹配。
匹配成功的驱动会触发其 .probe() 回调函数。以 Intel 千兆网卡为例,对应的是 igb_probe() 函数。这一阶段是网卡被内核 "接管" 的起点。
1.2 驱动私有结构体分配
在 .probe() 函数执行期间,驱动首先分配私有数据结构体,该结构体包含网卡运作所需的所有关键信息:
┌─────────────────────────────────────────────────────────────┐
│ igb_adapter 结构体 │
├─────────────────────────────────────────────────────────────┤
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 硬件寄存器基地址(通过 ioremap 映射) │ │
│ │ 中断号(IRQ 或 MSI-X) │ │
│ │ 网卡型号与特性标志 │ │
│ │ 发送/接收队列数组指针 │ │
│ │ 注册的 net_device 指针 │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘1.3 net_device 结构体初始化
驱动随后分配核心网络设备结构体 struct net_device,这是内核网络子系统中网卡的抽象表示。关键初始化操作包括:
netdev_ops 注册:将驱动实现的操作函数集注册到 net_device 结构体:
┌─────────────────────────────────────────────────────────────┐
│ netdev_ops 函数指针注册 │
├─────────────────────────────────────────────────────────────┤
│ │
│ dev->netdev_ops = &igb_netdev_ops; │
│ │
│ 函数集内容: │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ .ndo_open = igb_open // 启动网卡 │ │
│ │ .ndo_stop = igb_close // 停止网卡 │ │
│ │ .ndo_start_xmit = igb_xmit_frame // 发送数据包 │ │
│ │ .ndo_set_mac_address = ... // 设置 MAC │ │
│ │ .ndo_change_mtu = ... // 修改 MTU │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ 作用:内核上层协议栈通过统一接口操作网卡,无需关心具体硬件 │
│ │
└─────────────────────────────────────────────────────────────┘ethtool_ops 注册:提供网卡配置和诊断接口,使用户可通过 ethtool 工具查询和修改网卡参数。
1.4 中断处理函数注册
驱动调用 request_irq() 向内核注册硬中断处理函数。该函数是中断处理的 "顶半部"(Top Half),负责在硬件中断发生时快速响应:
┌─────────────────────────────────────────────────────────────┐
│ request_irq 注册流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ request_irq(irq_num, igb_intr, flags, driver_name, dev); │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ igb_intr() - 硬中断处理函数 │ │
│ │ { │ │
│ │ // 职责:极短,仅通知内核"包来了" │ │
│ │ napi_schedule(&q_vector->napi); // 触发软中断 │ │
│ │ } │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘1.5 注册到网络子系统
最后,驱动调用 register_netdev(dev) 将网卡注册到内核网络子系统。注册成功后,用户可通过 ifconfig -a 或 ip link 查看到网卡设备(如 eth0),但此时网卡处于 DOWN 状态,尚未激活。
第二章 网卡启动与 RingBuffer 初始化
2.1 多队列网卡架构
早期的网卡只有一个发送队列和一个接收队列,所有网络数据的发送和接收都要争抢这唯一的一个队列,这在高性能服务器上会成为瓶颈。
现代服务器网卡(如 Intel 的 ixgbe、igb 等驱动对应的网卡)支持多队列架构:
┌─────────────────────────────────────────────────────────────┐
│ 多队列网卡架构 │
├─────────────────────────────────────────────────────────────┤
│ │
│ CPU 核心 0 ──► 发送队列 0 ──► TX Ring 0 │
│ CPU 核心 1 ──► 发送队列 1 ──► TX Ring 1 │
│ CPU 核心 2 ──► 发送队列 2 ──► TX Ring 2 │
│ ... │
│ │
│ 优势:不同连接/不同 CPU 的数据分发到不同队列,并行处理 │
│ │
└─────────────────────────────────────────────────────────────┘2.2 初始化调用链
当网卡驱动加载并启动网卡时,必须为这些队列分配内存:
┌─────────────────────────────────────────────────────────────┐
│ 网卡启动初始化调用链 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ifconfig eth0 up │
│ │ │
│ ▼ │
│ __igb_open() // Intel igb 网卡打开入口 │
│ │ │
│ ├──► igb_setup_all_tx_resources() │
│ │ 遍历所有发送队列 │
│ │ 调用 igb_setup_tx_resources() │
│ │ │
│ └──► igb_setup_all_rx_resources() │
│ 遍历所有接收队列 │
│ 调用 igb_setup_rx_resources() │
│ │
└─────────────────────────────────────────────────────────────┘2.3 RingBuffer 的双重结构
RingBuffer 不仅仅是一个数组,而是由两块内存组成的双重结构:
┌─────────────────────────────────────────────────────────────┐
│ RingBuffer 双重结构 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ igb_tx_buffer[] (软件视角) │ │
│ │ 内核使用的软件结构 │ │
│ │ ┌────┬────┬────┬────┐ │ │
│ │ │skb*│skb*│skb*│skb*│ ... │ │
│ │ └────┴────┴────┴────┘ │ │
│ │ 记录已提交的 skb 指针,用于发送完成后释放内存 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ 通过 DMA 映射 │
│ │ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ e1000_adv_tx_desc[] (硬件视角) │ │
│ │ DMA 一致性内存,网卡可直接访问 │ │
│ │ ┌──────┬──────┬──────┬──────┐ │ │
│ │ │DMA │DMA │DMA │DMA │ │ │
│ │ │addr │addr │addr │addr │ │ │
│ │ └──────┴──────┴──────┴──────┘ │ │
│ │ 每个描述符包含:数据物理地址、长度、状态位 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ 对应关系: │
│ igb_tx_buffer[i].skb ←──对应──► e1000_adv_tx_desc[i] │
│ │
└─────────────────────────────────────────────────────────────┘为什么需要双重结构?
内核与硬件的视角不同:
- 硬件视角:网卡只认简单的物理地址,它看不懂复杂的 skb 结构。描述符数组中只需存放数据的物理地址和长度。
- 软件视角:内核需要记录 "这个位置之前发的是什么包",以便发送完成后释放对应的 skb 内存。
2.4 关键指针初始化
┌─────────────────────────────────────────────────────────────┐
│ 环形缓冲区指针管理 │
├─────────────────────────────────────────────────────────────┤
│ │
│ next_to_use (生产者指针) │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 指向下一个可用的描述符槽位 │ │
│ │ 内核要发包时,把数据放在此位置,然后后移 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ next_to_clean (消费者指针) │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 指向下一个待清理的描述符槽位 │ │
│ │ 网卡发送完成后,内核从此位置开始检查并释放内存 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ 环形特性:指针到达末尾后自动回绕,形成无限循环的环形 │
│ │
└─────────────────────────────────────────────────────────────┘第三章 系统调用入口
3.1 send 系统调用的本质
当应用程序调用 send() 时,操作系统需要完成从用户态到内核态的转换:
┌─────────────────────────────────────────────────────────────┐
│ send 系统调用流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 用户态代码: │
│ send(sockfd, buf, len, flags); │
│ │ │
│ ▼ │
│ 内核态:SYSCALL_DEFINE4(send, ...) │
│ │ │
│ ▼ │
│ sys_send() // 直接复用 sendto 逻辑 │
│ │ │
│ ▼ │
│ sockfd_lookup_light(fd, &err, &fput_needed) │
│ │ │
│ ▼ │
│ 构造 msghdr 结构体(打包用户数据指针) │
│ │ │
│ ▼ │
│ sock_sendmsg() // 进入内核网络子系统 │
│ │
└─────────────────────────────────────────────────────────────┘3.2 三大核心任务
任务一:文件描述符到 Socket 对象的转换
sock = sockfd_lookup_light(fd, &err, &fput_needed);用户传递给内核的是一个整数 fd(文件描述符),内核需要将其转换为内部的结构体指针。这是后续所有操作的基础。
任务二:构造 msghdr 消息头
struct msghdr msg;
struct iovec iov;
iov.iov_base = buff; // 用户数据的虚拟地址
iov.iov_len = len; // 用户数据的长度
msg.msg_iov = &iov;
msg.msg_iovlen = 1;内核定义了一个标准的消息头结构来统一管理各种发送请求。这里只是记录了用户态数据缓冲区的地址和长度,此时尚未发生数据拷贝。
任务三:分发到协议层
return sock->ops->sendmsg(iocb, sock, msg, size);这是 Linux 网络架构中最精彩的多态设计:sock->ops 是一个函数指针结构体,不同的协议(TCP/UDP)这个指针指向不同的实现:
- TCP (SOCK_STREAM) :
sock->ops→inet_stream_ops→inet_sendmsg - UDP (SOCK_DGRAM) :
sock->ops→inet_dgram_ops→inet_sendmsg
第四章 Socket 层分发
4.1 协议族层的分发逻辑
inet_sendmsg 是 INET 协议族的入口函数,其实现极为简洁:
int inet_sendmsg(struct kiocb *iocb, struct socket *sock,
struct msghdr *msg, size_t size)
{
return sk->sk_prot->sendmsg(iocb, sk, msg, size);
}核心机制同样是函数指针分发:sk->sk_prot 是特定协议的函数集合:
- TCP :
sk->sk_prot→tcp_prot→tcp_sendmsg - UDP :
sk->sk_prot→udp_prot→udp_sendmsg
4.2 Socket 发送缓冲区
每个 TCP Socket 都有一个发送缓冲区(sk_write_queue),用于暂存待发送的数据:
┌─────────────────────────────────────────────────────────────┐
│ Socket 发送缓冲区结构 │
├─────────────────────────────────────────────────────────────┤
│ │
│ struct sock { │
│ struct {
│ struct sk_buff *head; // 队列头 │
│ struct sk_buff *tail; // 队列尾 │
│ } sk_write_queue; │
│ │
│ // 其他字段... │
│ }; │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ sk_write_queue 队列示意图: │ │
│ │ [skb1] → [skb2] → [skb3] → NULL │ │
│ │ head tail │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘第五章 TCP 传输层处理
5.1 tcp_sendmsg 函数分析
tcp_sendmsg 是 TCP 发送逻辑的核心,其主要职责是:
-
获取或创建 SKB(Socket Kernel Buffer)
-
将用户数据拷贝到内核空间
-
将 SKB 加入发送队列
┌─────────────────────────────────────────────────────────────┐
│ tcp_sendmsg 执行流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ tcp_sendmsg(sock, msg, len) │
│ │ │
│ ├──► 循环处理所有待发送数据 │
│ │ while (msg->msg_iovlen > 0) { │
│ │ │
│ │ // 步骤 1:获取当前 SKB │
│ │ skb = tcp_write_queue_tail(sk); │
│ │ 检查是否可以合并到现有 SKB │
│ │ │
│ │ // 步骤 2:申请新 SKB(如需要) │
│ │ if (skb == NULL || skb_full) { │
│ │ skb = sk_stream_alloc_skb(sk); │
│ │ skb_entail(sk, skb); // 加入发送队列 │
│ │ } │
│ │ │
│ │ // 步骤 3:数据拷贝(最关键) │
│ │ skb_add_data_nocache(sk, skb, from, copy); │
│ │ memcpy(to=skb->data, from=用户空间, copy); │
│ │ │
│ │ // 步骤 4:检查是否触发发送 │
│ │ if (forced_push(tp) || skb == send_head) │
│ │ tcp_push(sk, skb, ...); │
│ │ } │
│ │ │
│ └──► 返回发送的字节数 │
│ │
└─────────────────────────────────────────────────────────────┘
5.2 SKB 合并策略
TCP 协议栈倾向于将多个小数据块合并到一个 SKB 中,这是 Nagle 算法的应用:
- 合并条件:当前 SKB 未满(小于 MSS,最大分段大小)
- 优势:减少包的数量,提高网络利用率
- 代价:增加延迟
5.3 数据拷贝的本质
skb_add_data_nocache(sk, skb, from, copy);这一步调用 memcpy 将数据从用户空间拷贝到内核空间。这是网络发送过程中最消耗 CPU 的操作之一,也是零拷贝技术(如 sendfile、splice)试图规避的环节。
第六章 TCP 发送决策
6.1 tcp_push 与 tcp_write_xmit
当数据需要发送时,tcp_push() 被调用,进而触发 tcp_write_xmit():
┌─────────────────────────────────────────────────────────────┐
│ TCP 发送决策流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ tcp_push(sk, tp, flags) │
│ │ │
│ ▼ │
│ tcp_write_xmit(tp) // 发送指挥官 │
│ │ │
│ └──► while (skb = tcp_send_head(sk)) { │
│ │
│ // 检查 1:拥塞窗口 │
│ if (!tcp_cwnd_test(tp, skb)) │
│ break; // 网络拥堵,暂停发送 │
│ │
│ // 检查 2:滑动窗口 │
│ if (!tcp_snd_wnd_test(tp, skb, ...)) │
│ break; // 对方缓冲区满,暂停 │
│ │
│ // 通过检查,执行发送 │
│ tcp_transmit_skb(sk, skb); │
│ } │
│ │
└─────────────────────────────────────────────────────────────┘6.2 拥塞控制检测
tcp_cwnd_test() 检查拥塞窗口( Congestion Window):
- 目的:探测网络是否拥堵
- 机制:如果网络拥堵,即使接收方能接收,发送方也应减缓发送速率,避免网络瘫痪
6.3 滑动窗口检测
tcp_snd_wnd_test() 检查发送窗口:
- 目的:探测接收方是否还能接收数据
- 机制:如果对方接收缓冲区已满,发送方必须等待,直到收到对方的 ACK 确认接收了数据
第七章 TCP 发送与 SKB 克隆
7.1 tcp_transmit_skb 函数分析
一旦通过所有检查,数据包调用 tcp_transmit_skb() 进行正式发送前的最后处理:
┌─────────────────────────────────────────────────────────────┐
│ tcp_transmit_skb 执行流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ tcp_transmit_skb(sk, skb) │
│ │ │
│ ├──► 步骤 1:克隆 SKB(为重传做准备) │
│ │ skb = skb_clone(skb, gfp_mask); │
│ │ │
│ │ ┌─────────────────────────────────────────┐ │
│ │ │ 为什么需要克隆? │ │ │
│ │ │ │ │ │
│ │ │ TCP 是可靠协议,发出去的数据必须保留 │ │ │
│ │ │ 原始 SKB 留在发送队列中(防止重传) │ │ │
│ │ │ 克隆体发送给下层协议栈 │ │ │
│ │ │ │ │ │
│ │ │ 收到 ACK → 释放原始 SKB │ │ │
│ │ │ 未收到 ACK → 重新克隆发送 │ │ │
│ │ └─────────────────────────────────────────┘ │
│ │ │
│ ├──► 步骤 2:封装 TCP 头部 │
│ │ th = tcp_hdr(skb); │
│ │ th->source = sk->sk_sport; // 源端口 │
│ │ th->dest = sk->sk_dport; // 目的端口 │
│ │ th->seq = tcp_skb_sequence(skb); │
│ │ th->ack_seq = tp->rcw_nxt; │
│ │ // ... 其他 TCP 头字段 │
│ │ │
│ └──► 步骤 3:移交给网络层 │
│ icsk->icsk_af_ops->queue_xmit(skb, ...); │
│ // IPv4: ip_queue_xmit() │
│ // IPv6: ip6_xmit() │
│ │
└─────────────────────────────────────────────────────────────┘7.2 SKB 指针操作原理
SKB 是一块连续的内存,预留了各层协议头的空间。内核不需要移动数据,只需移动指针:
┌─────────────────────────────────────────────────────────────┐
│ SKB 内存布局与指针操作 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ SKB 内存结构 │ │
│ │ │ │
│ │ ┌────┬────┬────┬─────────────┬────────┐ │ │
│ │ │MAC │IP │TCP │ Payload │ Tail │ │ │
│ │ │Head│Head│Head│ Data │ Room │ │ │
│ │ └────┴────┴────┴─────────────┴────────┘ │ │
│ │ ↑ ↑ ↑ ↑ │ │
│ │ head network transport data │ │
│ │ │ │
│ │ 设置 TCP 头时:移动 transport 指针 │ │
│ │ 设置 IP 头时:移动 network 指针 │ │
│ │ 设置 MAC 头时:移动 mac 指针 │ │
│ │ │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘第八章 网络层处理
8.1 IP 层入口
ip_queue_xmit() 是 IPv4 网络层的总入口函数:
┌─────────────────────────────────────────────────────────────┐
│ ip_queue_xmit 执行流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ip_queue_xmit(skb, &fl) │
│ │ │
│ ├──► 路由查找与缓存 │
│ │ __sk_dst_check(sk, cookie) │
│ │ ip_route_output_ports(&fl, ...) │
│ │ │
│ │ ┌─────────────────────────────────────────┐ │
│ │ │ 路由查找过程: │ │
│ │ │ │ │ │
│ │ │ 1. 检查 Socket 缓存的路由项 │ │
│ │ │ 如果命中,直接使用 │ │
│ │ │ │ │
│ │ │ 2. 查询全局路由表 (route -n) │ │
│ │ │ 确定出口网卡和下一跳网关 │ │
│ │ │ │ │
│ │ │ 3. 缓存路由项到 Socket │ │
│ │ │ 供后续使用 │ │
│ │ └─────────────────────────────────────────┘ │
│ │ │
│ ├──► 封装 IP 头部 │
│ │ iph = ip_hdr(skb); │
│ │ iph->version = 4; │
│ │ iph->ihl = 5; │
│ │ iph->ttl = 64; │
│ │ iph->protocol = IPPROTO_TCP; │
│ │ iph->saddr = 源 IP; │
│ │ iph->daddr = 目的 IP; │
│ │ │
│ └──► 进入输出处理 │
│ ip_local_out(skb); │
│ │
└─────────────────────────────────────────────────────────────┘8.2 Netfilter 钩子
ip_local_out() 和 ip_output() 会触发 Netfilter 钩子:
┌─────────────────────────────────────────────────────────────┐
│ IP 层 Netfilter 钩子 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ip_local_out() │
│ │ │
│ ├──► NF_HOOK(PF_INET, NF_INET_LOCAL_OUT) │
│ │ └──► iptables LOCAL_OUT 链规则检查 │
│ │ │
│ ▼ │
│ ip_output() │
│ │ │
│ ├──► 增加发送统计 │
│ │ │
│ └──► NF_HOOK(PF_INET, NF_INET_POST_ROUTING) │
│ └──► iptables POSTROUTING 链规则检查 │
│ (常用于 NAT 地址转换) │
│ │
└─────────────────────────────────────────────────────────────┘8.3 分片决策
ip_finish_output() 判断数据包是否需要分片:
┌─────────────────────────────────────────────────────────────┐
│ 分片决策逻辑 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ip_finish_output(skb) │
│ │ │
│ ▼ │
│ if (skb->len > mtu && !skb_is_gso(skb)) │
│ return ip_fragment(skb, ip_finish_output2); │
│ else │
│ return ip_finish_output2(skb); │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ GSO (Generic Segmentation Offload) │ │
│ │ │ │
│ │ 现代网卡支持 GSO 时,内核故意不分片 │ │
│ │ 而是将大包直接交给网卡,让网卡硬件进行分片 │ │
│ │ 这样可以减轻 CPU 负担 │ │
│ │ │ │
│ │ 以太网 MTU 通常为 1500 字节 │ │
│ │ IP 头 + TCP 头 + 数据 超过 1500 就要分片 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘第九章 邻居子系统
9.1 邻居子系统的定位
邻居子系统是网络层(IP)和数据链路层(MAC)之间的 "翻译官":
┌─────────────────────────────────────────────────────────────┐
│ 邻居子系统位置 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 网络层 (IP) │ │
│ │ IP 层只知道目标 IP 地址 │ │
│ └──────────────────────────┬──────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 邻居子系统 (ARP) │ │
│ │ 负责 IP → MAC 地址解析 │ │
│ │ 维护 ARP 缓存表 │ │
│ └──────────────────────────┬──────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 数据链路层 (MAC) │ │
│ │ 需要 MAC 地址才能发送 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘9.2 地址解析流程
ip_finish_output2() 执行邻居查找和 MAC 头封装:
┌─────────────────────────────────────────────────────────────┐
│ 邻居查找与 MAC 头封装流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ip_finish_output2(skb) │
│ │ │
│ ├──► __ipv4_neigh_lookup_noref(neigh) │
│ │ 在 ARP 缓存表中查找目标 IP 对应的 MAC 地址 │
│ │ │
│ ├──► 分支判断: │
│ │ ┌──────────────────┬──────────────────┐ │
│ │ │ Cache Hit │ Cache Miss │ │
│ │ │ (命中) │ (未命中) │ │
│ │ │ ↓ │ ↓ │ │
│ │ │ 直接发送 │ 创建邻居项 │ │
│ │ │ (有 MAC) │ (无 MAC) │ │
│ │ └──────────────────┴──────────────────┘ │
│ │ │
│ └──► 封装 MAC 头并发送 │
│ dev_hard_header(skb, dev, ETH_P_IP, ...) │
│ dst_neigh_output(skb); │
│ dev_queue_xmit(skb); │
│ │
└─────────────────────────────────────────────────────────────┘9.3 ARP 请求处理
当 ARP 缓存未命中时:
┌─────────────────────────────────────────────────────────────┐
│ ARP 请求流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 邻居项创建 → neigh_resolve_output() │
│ │ │
│ ├──► 触发 ARP 广播请求 │
│ │ "谁是 192.168.1.1?请告诉我你的 MAC 地址" │
│ │ │
│ ├──► 挂起数据包 │
│ │ 数据包暂时存放在邻居项队列中等待 │
│ │ │
│ ├──► 收到 ARP 响应 │
│ │ 更新邻居项,填入 MAC 地址 │
│ │ │
│ └──► 取出挂起的数据包继续发送 │
│ 封装 MAC 头 → dev_queue_xmit() │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 重要现象: │ │
│ │ 第一次 Ping 某个 IP 延迟较高(ARP 请求耗时) │ │
│ │ 后续 Ping 延迟很低(缓存命中) │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘9.4 struct neighbour 结构体
┌─────────────────────────────────────────────────────────────┐
│ neighbour 结构体关键字段 │
├─────────────────────────────────────────────────────────────┤
│ │
│ struct neighbour { │
│ __be32 primary_key; // 目标 IP 地址 │
│ struct net_device *dev; // 出口网卡 │
│ unsigned char ha[ALIGN(MAX_ADDR_LEN, sizeof(long))];// MAC │
│ │
│ // output 函数指针------巧妙的状态机设计 │
│ int (*output)(struct neighbour *, struct sk_buff *); │
│ │
│ // 状态转换: │
│ // NUD_NONE → NUD_INCOMPLETE: 正在 ARP 请求 │
│ // NUD_INCOMPLETE → NUD_REACHABLE: ARP 响应到达 │
│ // 解析完成前: output = neigh_resolve_output │
│ // 解析完成后: output = dev_queue_xmit │
│ }; │
│ │
└─────────────────────────────────────────────────────────────┘第十章 网络设备子系统
10.1 dev_queue_xmit 入口
dev_queue_xmit() 是网络设备子系统的总入口:
┌─────────────────────────────────────────────────────────────┐
│ dev_queue_xmit 入口流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ dev_queue_xmit(skb) │
│ │ │
│ ├──► netdev_pick_tx(dev, skb) │
│ │ 选择发送队列(多队列网卡) │
│ │ │
│ │ ┌─────────────────────────────────────────┐ │
│ │ │ 多队列选择策略: │ │
│ │ │ │ │
│ │ │ 1. 基于 XPS (Transmit Packet Steering) │ │
│ │ │ 根据 CPU 核心选择对应队列 │ │
│ │ │ │ │
│ │ │ 2. 基于流哈希 (Flow Hash) │ │
│ │ │ 同一连接的包走同一队列 │ │
│ │ │ │ │
│ │ │ 目的:避免多核争抢同一队列锁 │ │
│ │ └─────────────────────────────────────────┘ │
│ │ │
│ └──► 获取 QDisc (排队规则) │
│ q = rcu_dereference_bh(txq->qdisc); │
│ __dev_xmit_skb(skb, q, txq); │
│ │
└─────────────────────────────────────────────────────────────┘10.2 QDisc 排队规则
QDisc (Queueing Discipline) 决定数据包的排队和调度方式:
┌─────────────────────────────────────────────────────────────┐
│ QDisc 排队规则 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 常见 QDisc 类型: │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ pfifo_fast │ 简单 FIFO,优先级队列 │ │
│ ├─────────────────────────────────────────────────────┤ │
│ │ sch_fq │ 公平队列,降低延迟 │ │
│ ├─────────────────────────────────────────────────────┤ │
│ │ sch_htb │ 层级令牌桶,流量整形 │ │
│ ├─────────────────────────────────────────────────────┤ │
│ │ sch_tbf │ 令牌桶,限速 │ │
│ ├─────────────────────────────────────────────────────┤ │
│ │ sch_sfq │ 随机公平队列 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ 简单场景下(pfifo_fast): │
│ 数据包直接进入驱动队列,等待发送 │
│ │
└─────────────────────────────────────────────────────────────┘10.3 __dev_xmit_skb 发送逻辑
┌─────────────────────────────────────────────────────────────┐
│ __dev_xmit_skb 执行流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ __dev_xmit_skb(skb, q, txq) │
│ │ │
│ ├──► 分支判断: │
│ │ ┌──────────────────┬──────────────────┐ │
│ │ │ 直通模式 (Bypass)│ 正常排队 (Enqueue)│ │
│ │ │ 队列为空时 │ 队列非空或不支持 │ │
│ │ │ ↓ │ ↓ │ │
│ │ │ 直接发送 │ 入队等待 │ │
│ │ │ 延迟低 │ 复杂调度 │ │
│ │ └──────────────────┴──────────────────┘ │
│ │ │
│ └──► __qdisc_run(q) │
│ 开始发送循环 │
│ │
└─────────────────────────────────────────────────────────────┘10.4 发送循环与配额机制
__qdisc_run() 实现了发送循环,采用配额机制防止单队列霸占 CPU:
┌─────────────────────────────────────────────────────────────┐
│ 发送循环配额机制 │
├─────────────────────────────────────────────────────────────┤
│ │
│ __qdisc_run(q) │
│ │ │
│ ├──► 循环发送 │
│ │ while (qdisc_restart(q)) { │
│ │ │
│ │ quota--; │
│ │ if (quota <= 0) { │
│ │ __netif_reschedule(q); │
│ │ break; // 触发软中断 │
│ │ } │
│ │ │
│ │ if (need_resched()) { │
│ │ __netif_reschedule(q); │
│ │ break; │
│ │ } │
│ │ } │
│ │ │
│ ├──► qdisc_restart() │
│ │ skb = dequeue_skb(q); // 取出一个包 │
│ │ sch_direct_xmit(skb, ...); // 发送给驱动 │
│ │ │
│ └──► 返回是否有更多待发送包 │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 配额机制的目的: │ │
│ │ 防止某个队列长时间霸占 CPU,导致系统其他任务无法执行 │ │
│ │ 配额耗尽后触发软中断,让出 CPU │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘10.5 NET_TX_SOFTIRQ 软中断
当发送配额耗尽时,内核触发 NET_TX_SOFTIRQ:
┌─────────────────────────────────────────────────────────────┐
│ NET_TX_SOFTIRQ 触发与处理 │
├─────────────────────────────────────────────────────────────┤
│ │
│ __netif_reschedule(q) │
│ │ │
│ ├──► 将 QDisc 加入 CPU 的 output_queue 链表 │
│ │ softnet_data.output_queue │
│ │ │
│ └──► raise_softirq_irqoff(NET_TX_SOFTIRQ) │
│ 触发发送软中断 │
│ │
│ net_tx_action() // 软中断处理函数 │
│ │ │
│ └──► 遍历 output_queue,继续发送 │
│ qdisc_run() │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 为什么需要软中断? │ │
│ │ │ │
│ │ 1. 防止用户进程长时间占用 CPU(算在 sy 时间) │ │
│ │ 2. 软中断消耗的 CPU 算在 si 时间,便于区分 │ │
│ │ - sy 高:业务逻辑忙 │ │
│ │ - si 高:网络处理忙 │ │
│ │ 3. 实现"削峰填谷",保护系统响应性 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘第十一章 驱动程序与 DMA
11.1 dev_hard_start_xmit 入口
这是内核网络子系统和网卡驱动的交界点:
┌─────────────────────────────────────────────────────────────┐
│ 驱动层入口 │
├─────────────────────────────────────────────────────────────┤
│ │
│ dev_hard_start_xmit(skb, dev, txq) │
│ │ │
│ ├──► 调用驱动的发送函数 │
│ │ ops = dev->netdev_ops; │
│ │ skb = ops->ndo_start_xmit(skb, dev); │
│ │ │
│ │ // Intel igb 网卡对应 igb_xmit_frame() │
│ │ │
│ └──► 返回发送状态 │
│ NETDEV_TX_OK: 发送成功 │
│ NETDEV_TX_BUSY: 队列满,稍后重试 │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 多态设计: │ │
│ │ 内核调用统一的 ndo_start_xmit 接口 │ │
│ │ 具体实现由各厂商驱动完成,互不依赖 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘11.2 DMA 映射与描述符填充
igb_tx_map() 完成 DMA 映射和描述符填充:
┌─────────────────────────────────────────────────────────────┐
│ DMA 映射与描述符填充流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ igb_tx_map(txq, skb) │
│ │ │
│ ├──► 获取空闲描述符 │
│ │ tx_desc = TX_DESC(txq, txq->next_to_use); │
│ │ │
│ ├──► DMA 映射(核心步骤) │
│ │ dma_addr = dma_map_single(dev, │
│ │ skb->data, │
│ │ skb->len, │
│ │ DMA_TO_DEVICE); │
│ │ │
│ │ ┌─────────────────────────────────────────┐ │
│ │ │ DMA 映射的本质: │ │
│ │ │ │ │
│ │ │ 网卡是独立硬件,无法直接访问 CPU 虚拟内存│ │
│ │ │ DMA 映射将 skb 数据缓冲区映射到物理总线地址│ │
│ │ │ 网卡通过这个物理地址直接读写数据 │ │
│ │ │ │ │
│ │ │ 优势:无需 CPU 拷贝数据 │ │
│ │ └─────────────────────────────────────────┘ │
│ │ │
│ ├──► 填写描述符 │
│ │ tx_desc->read.buffer_addr = dma_addr; │
│ │ tx_desc->read.cmd_type_len = cmd_type | len; │
│ │ tx_desc->read.olinfo_status = 0; │
│ │ │
│ ├──► 记录 skb 指针(用于后续释放) │
│ │ tx_buffer[txq->next_to_use].skb = skb; │
│ │ │
│ └──► 更新指针并通知网卡 │
│ txq->next_to_use++; │
│ writel(txq->next_to_use, hw->addr + E1000_TDT); │
│ // 写寄存器"踢门铃",通知网卡有新数据 │
│ │
└─────────────────────────────────────────────────────────────┘11.3 DMA 传输示意图
┌─────────────────────────────────────────────────────────────┐
│ DMA 传输机制 │
├─────────────────────────────────────────────────────────────┤
│ │
│ CPU 视角(虚拟地址): │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ skb->data ──────────────────► 用户缓冲区 │ │
│ │ │ │ │
│ │ dma_map_single() │ │
│ │ │ │ │
│ │ ▼ │ │
│ │ 返回物理地址 0x12345678 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ 物理视角: │
│ ┌─────────────────────┐ ┌─────────────────────┐ │
│ │ 系统内存 │ │ 网卡 │ │
│ │ ┌───────────────┐ │ │ │ │
│ │ │ DMA 地址: │ │◄──DMA──│ 读取数据并发送 │ │
│ │ │ 0x12345678 │ │ 总线 │ │ │
│ │ │ skb->data │ │ │ │ │
│ │ └───────────────┘ │ └─────────────────────┘ │
│ └─────────────────────┘ │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 关键特性: │ │
│ │ CPU 只需提交数据地址,网卡自己取走数据 │ │
│ │ 整个 DMA 传输过程无需 CPU 介入数据搬运 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘第十二章 发送完成与内存回收
12.1 中断触发机制
网卡发送完数据后,会触发硬件中断:
┌─────────────────────────────────────────────────────────────┐
│ 发送完成中断流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 网卡发送完成 │
│ │ │
│ ├──► 硬件中断信号 │
│ │ IRQ 触发 │
│ │ │
│ └──► 硬中断处理函数 (igb_msix_ring) │
│ // 注意:必须极短 │
│ napi_schedule(&q_vector->napi); │
│ // 触发软中断,返回 │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 重要设计:为什么用 NET_RX 而非 NET_TX? │ │
│ │ │ │
│ │ 历史原因与优化: │ │
│ │ 早期内核有 NET_TX_SOFTIRQ │ │
│ │ NAPI 引入后,为了减少上下文切换,发送完成清理 │ │
│ │ 被合并到 NET_RX 软中断中 │ │
│ │ │ │
│ │ 原因: │ │
│ │ NAPI 触发时已关闭网卡中断,进入轮询模式 │ │
│ │ 既然已经进入轮询,顺手清理 TX 更高效 │ │
│ │ 避免再开一个独立的软中断处理 │ │
│ │ │ │
│ │ 这就是为什么 top 中 NET_RX 计数远大于 NET_TX │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘12.2 软中断清理流程
igb_clean_tx_irq() 完成内存释放:
┌─────────────────────────────────────────────────────────────┐
│ 发送清理流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ksoftirqd (NET_RX_SOFTIRQ) │
│ │ │
│ └──► net_rx_action() │
│ napi_poll() │
│ │ │
│ └──► igb_poll() │
│ // 清理 TX │
│ igb_clean_tx_irq(txq) │
│ │ │
│ ├──► 循环检查描述符状态 │
│ │ 检查 next_to_clean 位置 │
│ │ 判断是否已发送完成 │
│ │ │
│ ├──► 解除 DMA 映射 │
│ │ dma_unmap_single(...) │
│ │ │
│ ├──► 释放 SKB │
│ │ dev_kfree_skb_any(skb) │
│ │ │
│ │ ┌─────────────────────────┐│ │
│ │ │ 注意:驱动层释放后, ││ │
│ │ │ TCP 层可能仍保留 SKB ││ │
│ │ │ 用于重传 ││ │
│ │ │ 收到 ACK 后才彻底释放 ││ │
│ │ └─────────────────────────┘│ │
│ │ │
│ └──► 重置描述符 │
│ 准备供下次使用 │
│ │
└─────────────────────────────────────────────────────────────┘12.3 SKB 生命周期管理
┌─────────────────────────────────────────────────────────────┐
│ SKB 发送生命周期 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 阶段 1:创建 │ │
│ │ sk_stream_alloc_skb() ──► 分配 SKB + 数据缓冲区 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 阶段 2:克隆 │ │
│ │ tcp_transmit_skb() ──► skb_clone() │ │
│ │ 原版留在发送队列,克隆体发往下层 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 阶段 3:DMA 映射 │ │
│ │ igb_tx_map() ──► dma_map_single() │ │
│ │ 描述符记录物理地址,网卡取走数据 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 阶段 4:驱动层释放 │ │
│ │ igb_clean_tx_irq() ──► dev_kfree_skb_any() │ │
│ │ 解除 DMA 映射,释放驱动层引用 │ │
│ │ 驱动层引用计数 -1 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 阶段 5:协议层释放(收到 ACK) │ │
│ │ tcp_ack() ──► tcp_clean_rtx_queue() │ │
│ │ 移除发送队列,释放原版 SKB │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘第十三章 完整流程总览
13.1 端到端调用链
┌─────────────────────────────────────────────────────────────┐
│ Linux 网络发送完整路径 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ 用户态 │ │
│ │ send(sockfd, buf, len, flags) │ │
│ └──────────────────────────┬───────────────────────────┘ │
│ │ │
│ ┌──────────────────────────┼───────────────────────────┐ │
│ │ 系统调用层 (SYSCALL) │ │
│ │ SYSCALL_DEFINE4(send) │ │
│ │ │ │ │
│ │ ├──► sockfd_lookup_light() // 查找 Socket │ │
│ │ ├──► 构造 msghdr │ │
│ │ └──► sock_sendmsg() │ │
│ └──────────────────────────┬───────────────────────────┘ │
│ │ │
│ ┌──────────────────────────┼───────────────────────────┐ │
│ │ Socket 层 (INET) │ │
│ │ sock->ops->sendmsg() → inet_sendmsg() │ │
│ │ │ │ │
│ │ └──► sk->sk_prot->sendmsg() │ │
│ │ sk_prot.sendmsg → tcp_sendmsg() │ │
│ └──────────────────────────┬───────────────────────────┘ │
│ │ │
│ ┌──────────────────────────┼───────────────────────────┐ │
│ │ TCP 传输层 │ │
│ │ tcp_sendmsg() │ │
│ │ │ │ │
│ │ ├──► 数据拷贝到 SKB │ │
│ │ ├──► skb_entail() // 加入发送队列 │ │
│ │ └──► tcp_push_pending_frames() │ │
│ │ │ │ │
│ │ └──► tcp_write_xmit() │ │
│ │ │ │ │
│ │ ├──► tcp_cwnd_test() │ │
│ │ ├──► tcp_snd_wnd_test() │ │
│ │ └──► tcp_transmit_skb() │ │
│ │ │ │ │
│ │ ├──► skb_clone() │ │
│ │ ├──► 封装 TCP 头 │ │
│ │ └──► ip_queue_xmit() │ │
│ └──────────────────────────┬───────────────────────────┘ │
│ │ │
│ ┌──────────────────────────┼───────────────────────────┐ │
│ │ IP 网络层 │ │
│ │ ip_queue_xmit() │ │
│ │ │ │ │
│ │ ├──► 路由查找与缓存 │ │
│ │ ├──► 封装 IP 头 │ │
│ │ ├──► NF_HOOK (PRE_ROUTING) │ │
│ │ ├──► ip_output() │ │
│ │ ├──► NF_HOOK (POST_ROUTING) │ │
│ │ ├──► 分片检查 (ip_finish_output) │ │
│ │ └──► ip_finish_output2() │ │
│ │ │ │ │
│ │ ├──► 邻居查找 (neigh_lookup) │ │
│ │ ├──► ARP 解析 (如有需要) │ │
│ │ ├──► 封装 MAC 头 │ │
│ │ └──► dev_queue_xmit() │ │
│ └──────────────────────────┬───────────────────────────┘ │
│ │ │
│ ┌──────────────────────────┼───────────────────────────┐ │
│ │ QDisc 层 │ │
│ │ dev_queue_xmit() │ │
│ │ │ │ │
│ │ ├──► netdev_pick_tx() // 选择发送队列 │ │
│ │ ├──► __dev_xmit_skb() │ │
│ │ ├──► qdisc_run() │ │
│ │ │ │ │ │
│ │ │ └──► sch_direct_xmit() │ │
│ │ └──► 软中断触发 (NET_TX_SOFTIRQ) │ │
│ └──────────────────────────┬───────────────────────────┘ │
│ │ │
│ ┌──────────────────────────┼───────────────────────────┐ │
│ │ 驱动层 │ │
│ │ dev_hard_start_xmit() │ │
│ │ │ │ │
│ │ └──► ndo_start_xmit() │ │
│ │ │ │ │
│ │ ├──► igb_xmit_frame() │ │
│ │ │ │ │ │
│ │ │ ├──► 获取 TX 描述符 │ │
│ │ │ ├──► DMA 映射 │ │
│ │ │ ├──► 填写描述符 │ │
│ │ │ └──► 通知网卡 (写寄存器) │ │
│ │ │ │ │
│ │ └──► 返回 NETDEV_TX_OK │ │
│ └──────────────────────────┬───────────────────────────┘ │
│ │ │
│ ┌──────────────────────────┼───────────────────────────┐ │
│ │ 硬件层 │ │
│ │ 网卡 DMA 读取内存数据 │ │
│ │ │ │ │
│ │ ├──► 串行化数据 │ │
│ │ └──► 发送到物理网线 │ │
│ └──────────────────────────┬───────────────────────────┘ │
│ │ │
│ ┌──────────────────────────┼───────────────────────────┐ │
│ │ 中断清理 │ │
│ │ 网卡发送完成 → 触发硬中断 → 软中断清理 │ │
│ │ │ │ │
│ │ └──► igb_clean_tx_irq() │ │
│ │ │ │ │
│ │ ├──► 解除 DMA 映射 │ │
│ │ ├──► 释放 SKB │ │
│ │ └──► 重置描述符 │ │
│ └──────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘13.2 核心设计原则
┌─────────────────────────────────────────────────────────────┐
│ 核心设计原则总结 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 原则 1:CPU 尽早脱身 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ CPU 把数据交给 RingBuffer 后立即返回 │ │
│ │ 剩余工作由网卡异步完成 │ │
│ │ 硬中断通知后,驱动清理内存 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ 原则 2:延迟分配与按需分配 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ SKB 在需要时才分配 │ │
│ │ 物理页在有数据时才划拨 │ │
│ │ 合并小数据块减少包数量 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ 原则 3:克隆与重传保障 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ TCP 层克隆 SKB 保留原件用于重传 │ │
│ │ 驱动层释放后,TCP 层仍可能保留引用 │ │
│ │ 收到 ACK 后才彻底释放 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ 原则 4:多态与接口解耦 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ sock->ops、sk->sk_prot、netdev_ops │ │
│ │ 统一的函数指针接口,隔离协议差异 │ │
│ │ 内核无需关心底层具体实现 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ 原则 5:配额与软中断削峰 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 发送循环有配额限制 │ │
│ │ 配额耗尽触发软中断,让出 CPU │ │
│ │ 区分 sy(系统调用)和 si(软中断)CPU 消耗 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘