一、背景:企业数据管理面临的挑战

随着企业信息化程度的提升,业务系统数量不断增加。纷享CRM、金蝶ERP、旺店通WMS、飞书OA等系统在企业内部并行运行,形成了典型的多源异构数据环境。这种环境带来以下结构性问题:
数据分散与隔离
各业务系统的数据存储在独立的数据库中,采用不同的数据定义和编码规则。跨系统的数据查询需要人工导出、格式转换和表格合并,操作周期长且容易出错。
数据标准差异
不同系统对同一业务实体的定义存在差异。例如,"客户"在CRM系统中可能以商机线索形式存在,在ERP系统中以结算单位形式存在,在WMS系统中以收货方形式存在。这种定义差异导致数据关联困难。
数据获取效率
业务分析人员获取完整数据视图通常需要等待IT部门进行数据抽取和清洗,周期从天级到周级不等,难以满足实时分析需求。
二、数据仓库架构设计

2.1 总体架构
企业级数据仓库采用经典的三层架构模式:
数据源层
涵盖企业运营的各类业务系统:
- 客户关系管理系统(CRM):客户档案、回款记录、跟进历史
- 企业资源计划系统(ERP):采购订单、生产工单、销售数据、财务凭证
- 仓储管理系统(WMS):库存台账、出入库记录、库龄数据
- 办公自动化系统(OA):审批流程、任务协同数据
- 线下数据:Excel/CSV文件、第三方API接口
存储处理层
包含数据仓库的核心处理引擎,支持实时同步和批量抽取两种模式。实时同步适用于监控场景,延迟控制在秒级;批量抽取适用于报表分析,通过定时调度执行。
数据展示层
提供多种数据消费方式:可视化报表、数据API服务、协作平台推送、权限管控界面。
2.2 数据流转流程

数据从源系统到消费端的完整处理链路如下:
- 数据采集:通过预置连接器或自定义API接入源数据
- ODS层存储:原始数据以与源系统一致的格式存储,保留数据血缘关系
- 数据清洗:执行标准化转换,包括编码映射、格式统一、去重处理
- DW层建模:按主题域进行维度建模,采用星型模型或雪花模型组织数据
- 宽表构建:将关联数据预聚合成业务宽表,减少查询时的表关联操作
- 指标计算:基于统一口径计算业务指标,如销售额、库存周转率等
- 数据服务:通过API或推送机制将数据交付给消费端
三、数据源集成方案
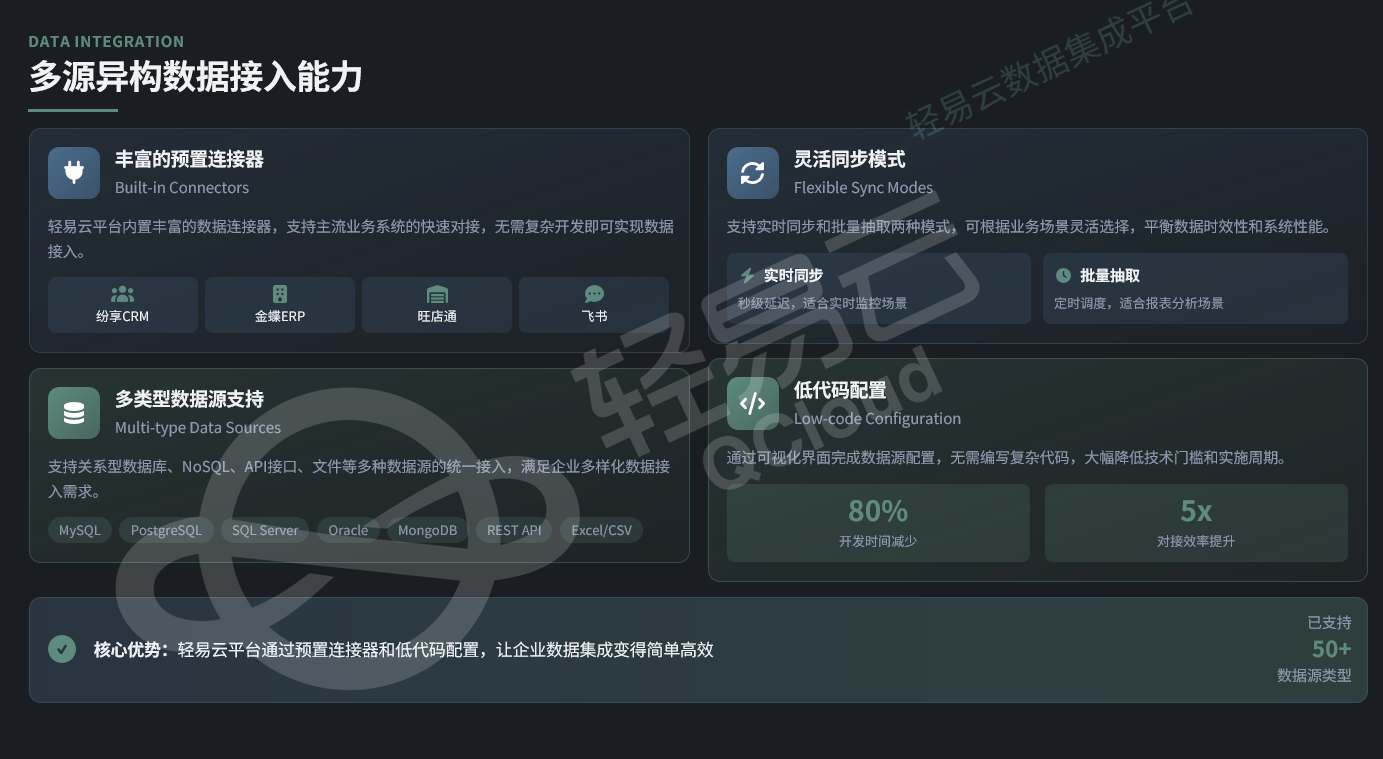
3.1 多源异构数据接入
数据仓库需要支持以下数据源类型:
关系型数据库
MySQL、PostgreSQL、SQL Server、Oracle等传统事务型数据库,承载ERP、CRM等系统的业务数据。
NoSQL数据库
MongoDB等文档型数据库,用于存储非结构化或半结构化数据。
API接口
RESTful API、WebService等接口协议,对接SaaS化业务系统或第三方数据服务。
文件数据
Excel、CSV等离线文件,用于补录线下业务数据或历史数据迁移。
3.2 业务数据全景
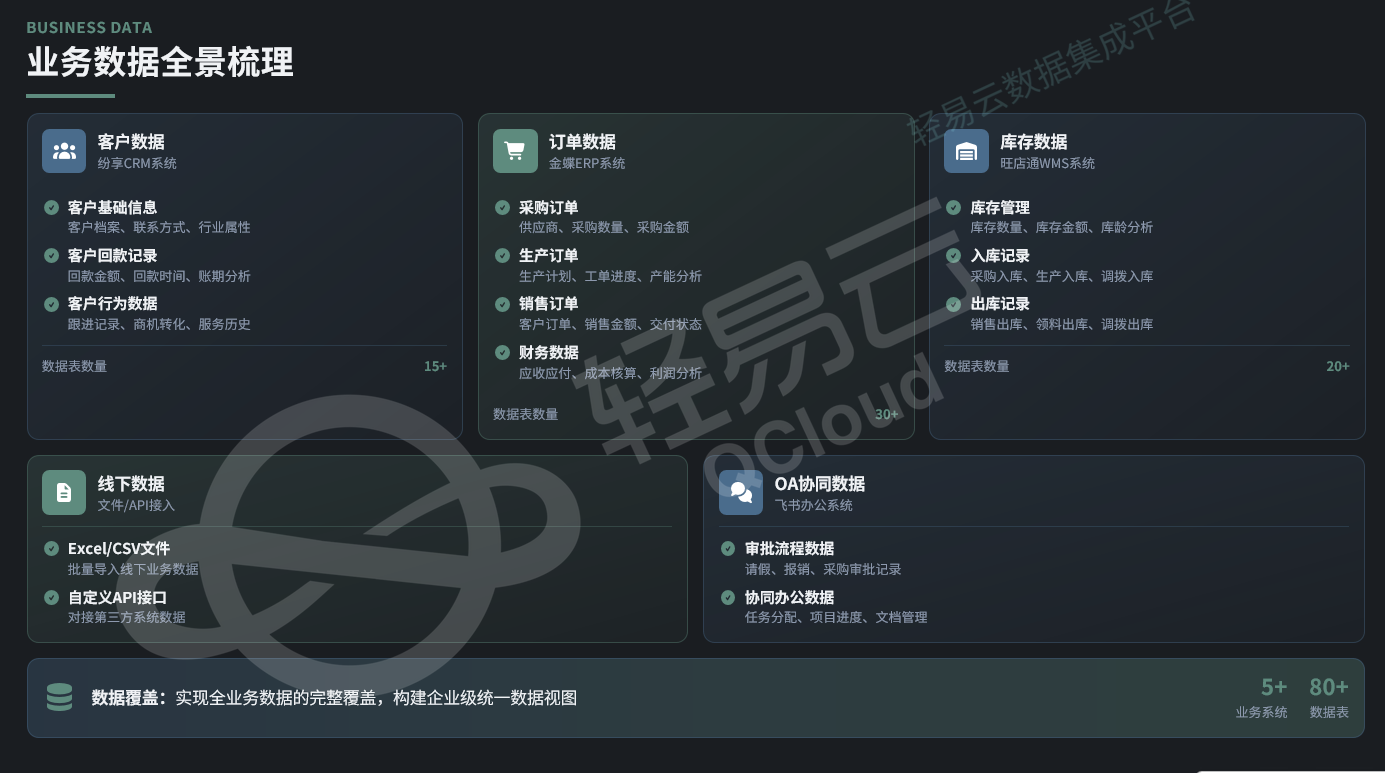
典型制造型企业的数据仓库通常涵盖以下数据域:
| 数据域 | 源系统 | 主要数据表 | 数据规模 |
|---|---|---|---|
| 客户域 | CRM | 客户档案、回款记录、跟进历史 | 15+张表 |
| 订单域 | ERP | 采购订单、生产工单、销售订单 | 30+张表 |
| 库存域 | WMS | 库存台账、出入库记录 | 20+张表 |
| 财务域 | ERP | 应收应付、成本核算 | 10+张表 |
| 协同域 | OA | 审批流程、任务数据 | 5+张表 |
四、数据存储与处理
4.1 分层数据架构
ODS层(操作数据存储层)
- 职责:原始数据接入与保留
- 设计原则:保持与源系统数据结构一致,不做业务逻辑转换
- 技术特点:支持批量加载和增量同步,保留数据变更历史
DW层(数据仓库层)
- 职责:主题建模与维度设计
- 建模方法:采用维度建模方法论,构建客户、订单、库存、财务等主题域
- 数据整合:通过主数据管理(MDM)实现跨系统数据关联,建立统一的企业级数据视图
APP层(数据应用层)
- 职责:面向具体应用场景的数据准备
- 输出形式:数据宽表、指标汇总表、定制化需求视图
4.2 数据治理机制

数据质量管理
建立数据校验规则,包括完整性检查(必填字段非空)、一致性检查(跨系统数据匹配)、准确性检查(数值范围合理性)。
权限管理
实施精细化权限控制:
- 行级权限:基于数据属性控制可见记录范围(如仅查看特定区域的销售数据)
- 列级权限:基于字段敏感度控制可见字段范围(如隐藏成本相关字段)
- 角色权限:按职能角色分配数据访问权限
五、数据展示与应用
5.1 数据服务方式
可视化分析
提供自助式报表设计工具,支持拖拽式界面创建数据仪表盘,实现多维度数据下钻分析。
数据API
封装标准化RESTful API接口,支持第三方系统的数据调用。提供接口文档、权限管理和调用日志监控。
消息推送
通过企业微信、钉钉、飞书等协作平台,将关键指标和异常预警实时推送给业务人员。
5.2 典型应用场景
经营分析报表
整合销售、库存、财务数据,生成多维度经营分析视图,包括销售趋势分析、库存周转监控、财务指标追踪。
客户360度视图
整合CRM的客户信息、ERP的交易记录、WMS的物流数据,构建完整的客户画像,支持客户价值分层和购买行为分析。
供应链分析
基于采购、生产、库存数据,分析供应商交付周期、产能利用率、安全库存水平,优化采购计划和库存策略。
财务分析
支持多维度成本核算(按产品、按部门、按项目),实现利润中心核算和预算执行监控。
六、实施路径
6.1 项目实施阶段
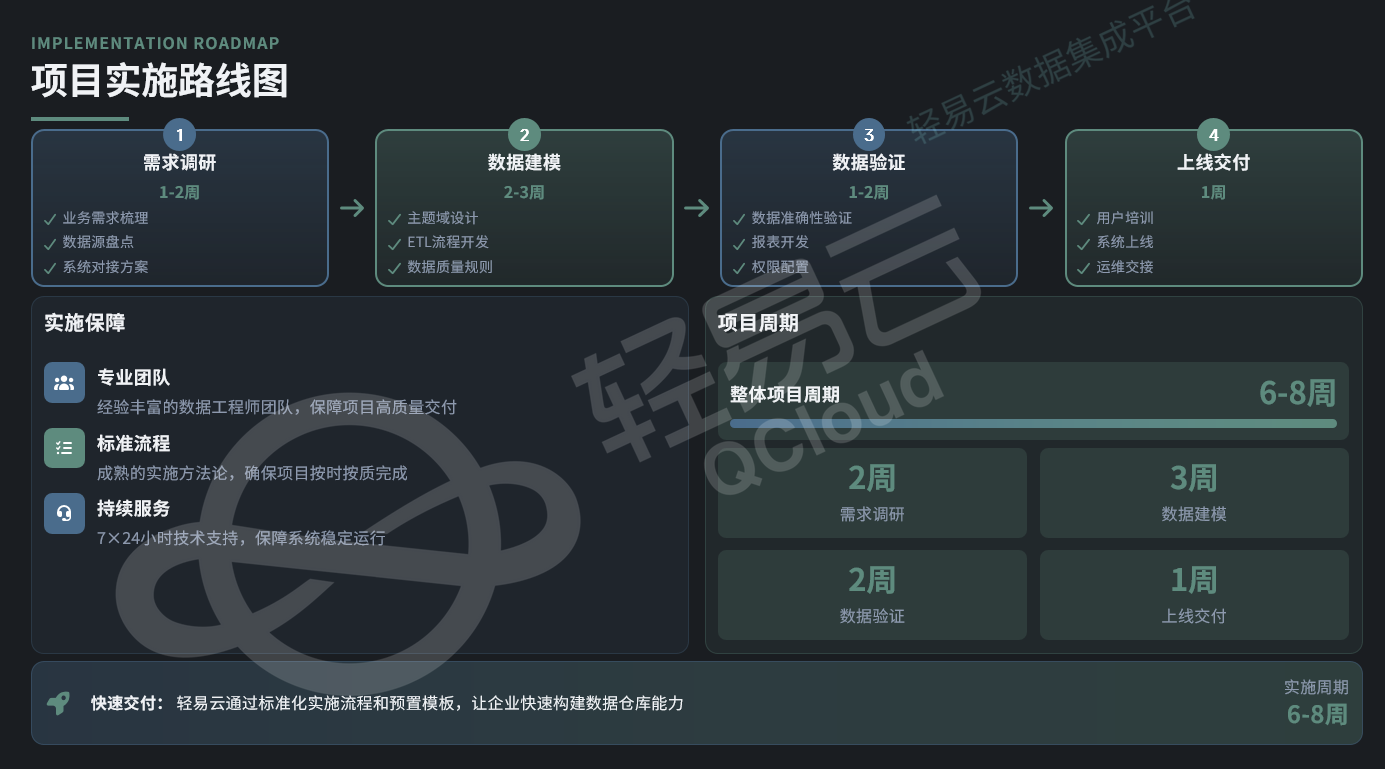
数据仓库项目通常按以下阶段实施:
第一阶段:需求调研(1-2周)
- 梳理业务部门的数据分析需求
- 盘点现有数据源,评估数据质量
- 确定系统对接方案和数据同步策略
第二阶段:数据建模(2-3周)
- 设计主题域模型和维度表结构
- 开发ETL流程,实现从ODS到DW的数据转换
- 制定数据质量校验规则
第三阶段:数据验证(1-2周)
- 验证数据准确性,比对源系统和数仓数据的一致性
- 开发报表和仪表盘
- 配置权限管控策略
第四阶段:上线交付(1周)
- 培训业务用户和IT运维人员
- 系统正式上线运行
- 建立运维监控机制
总体周期:6-8周
6.2 与传统方案的对比
| 对比维度 | 传统定制开发方案 | 现代数据平台方案 |
|---|---|---|
| 实施周期 | 3-6个月 | 2-4周 |
| 开发方式 | 大量编码开发 | 配置化、低代码 |
| 系统对接 | 每系统单独开发接口 | 预置标准化连接器 |
| 运维复杂度 | 需要专业技术团队 | 可视化运维界面 |
| 需求响应 | 周级变更周期 | 天级配置调整 |
| 技术门槛 | 高(需专业开发人员) | 中(业务人员可操作) |
| 扩展能力 | 架构固化,扩展困难 | 支持弹性资源扩展 |
七、总结

企业数据仓库建设是数据管理的基础设施工程,其核心目标是解决数据分散、标准不一、获取困难等问题。通过采用分层架构设计(ODS-DW-APP),企业可以实现:
- 数据整合:建立统一的企业级数据视图,消除信息孤岛
- 数据治理:通过标准化流程提升数据质量和可信度
- 数据服务:通过API和可视化工具,让数据更易获取和使用
- 分析支持:为业务分析和决策提供完整、准确的数据基础
在实施过程中,采用配置化、低代码的数据平台可以显著缩短实施周期(从数月缩短到数周),降低技术门槛,使企业能够更快地构建数据能力。数据仓库的价值最终体现在数据获取效率的提升、数据质量的改善,以及对业务分析需求的响应速度上。