1、下载DataX源码
地址为https://github.com/alibaba/DataX.git
2、通过maven打包:
在DataX根目录执行打包命令
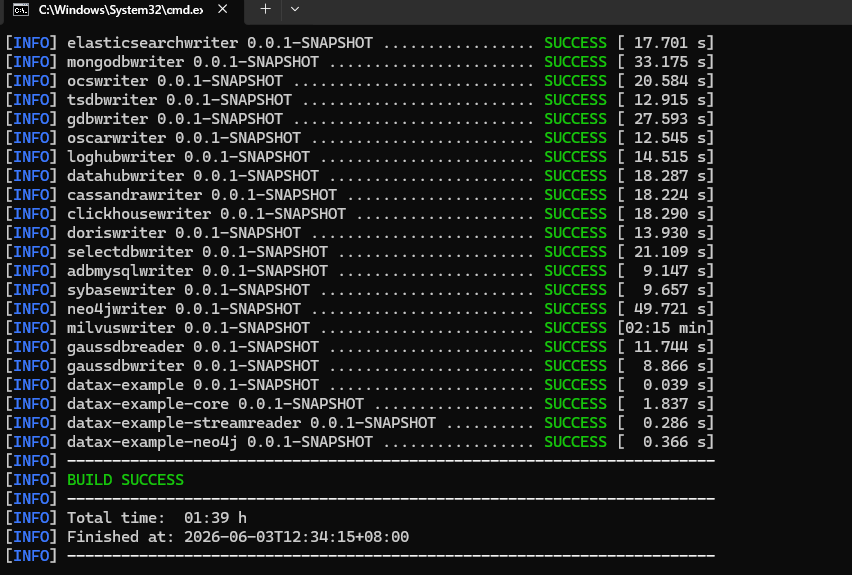
mvn -U clean package assembly:assembly -Dmaven.test.skip=true打包成功,日志显示如下:
INFO BUILD SUCCESS
INFO ------------------------------------------------------------------------
INFO Total time: 01:39 h
INFO Finished at: 2026-06-03T12:34:15+08:00
INFO ------------------------------------------------------------------------
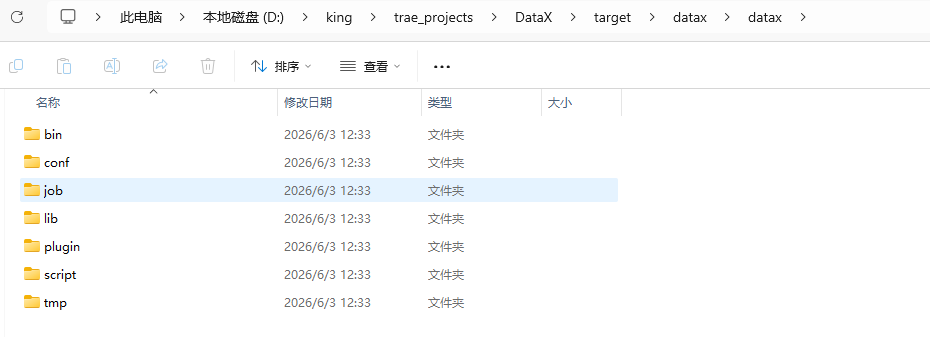
3、DataX目录
打包成功后的DataX包位于 {DataX_source_code_home}/target/datax/datax/ ,结构如下:
4、配置示例:从stream读取数据并打印到控制台
1)第一步、创建作业的配置文件(json格式)
可以通过命令查看配置模板: python datax.py -r {YOUR_READER} -w {YOUR_WRITER},这里执行命令
python datax.py -r streamreader -w streamwriter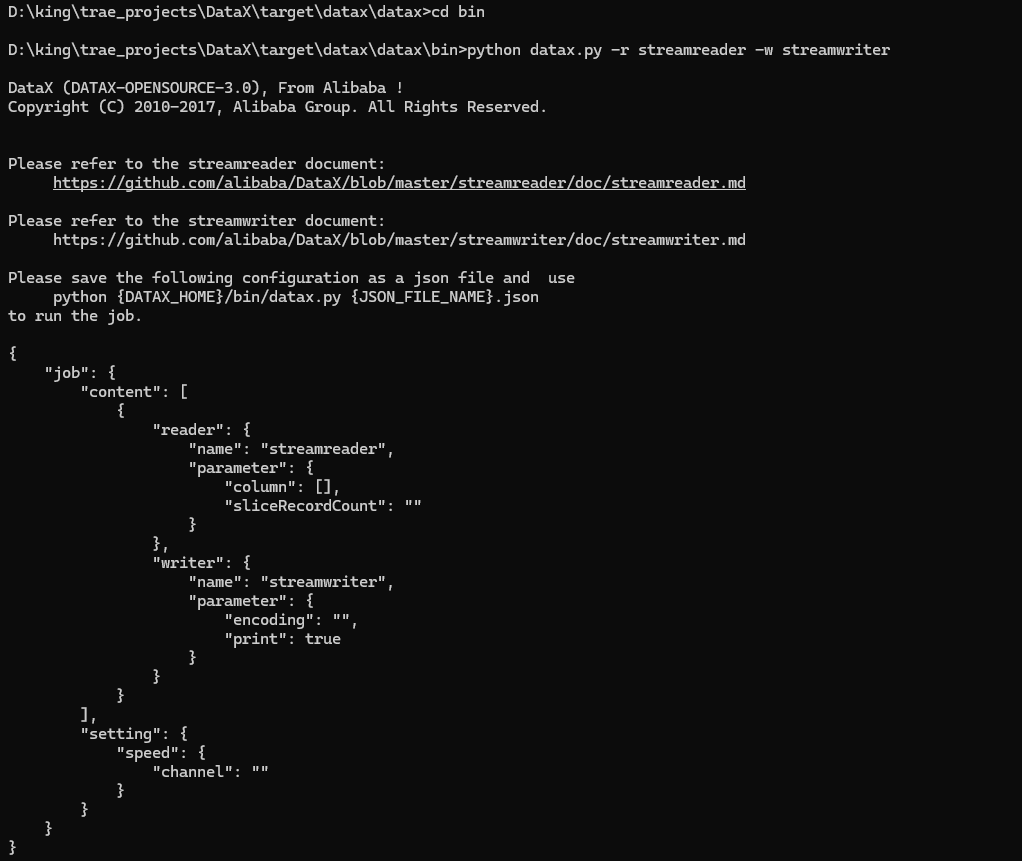
2)根据模板配置json如下:
将stream2stream.json文件放到job目录下,内容如下:
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}3)运行job
执行命令
chcp 65001
python bin/datax.py ./job/stream2stream.json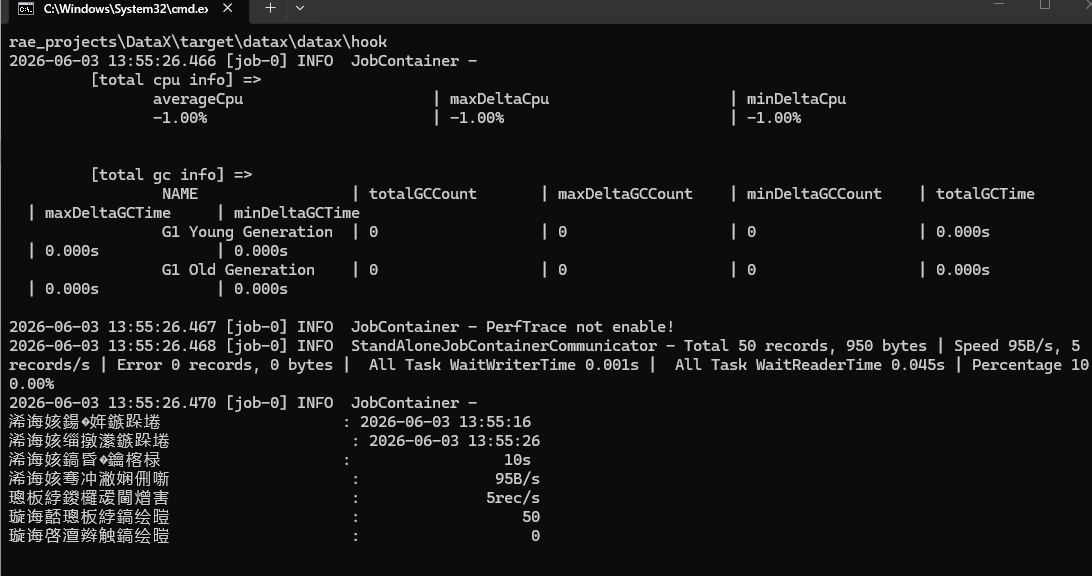
出现乱码。
4)解决乱码
执行命令 chcp 65001后显示正常,如果不想每次都输 chcp 65001,可以写个批处理。
chcp 65001
python bin/datax.py ./job/stream2stream.json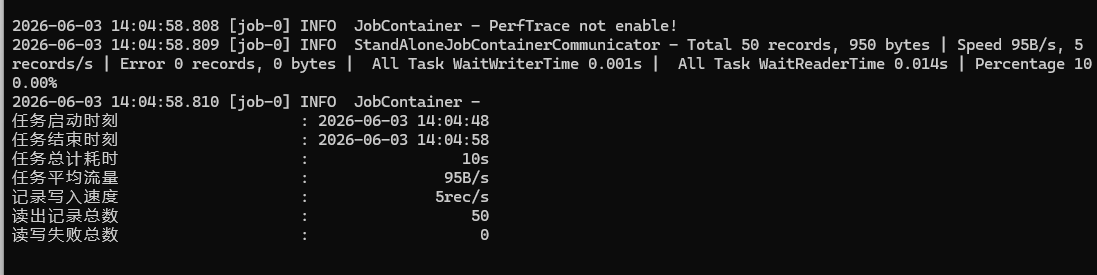
done!!!
下一篇文章将讲解DataX-Web安装部署。