CREval: An Automated Interpretable Evaluation for Creative Image Manipulation under Complex Instructions
论文链接![]() https://arxiv.org/abs/2603.26174
https://arxiv.org/abs/2603.26174
GitHub:![]() https://github.com/ChonghuinanWang/CREvalBenchmark数据集下载:
https://github.com/ChonghuinanWang/CREvalBenchmark数据集下载:![]() https://huggingface.co/datasets/ChonghuinanWang/CREval
https://huggingface.co/datasets/ChonghuinanWang/CREval
目录

一、引言
当前,用户对自由形式的图像生成或图像编辑的需求越来越多,编辑指令也逐渐复杂,但目前缺少一个系统的、人类对齐的框架去评估生成模型在创意图像生成任务的性能,所以本文专门针对这类任务设计了一个评估方案。
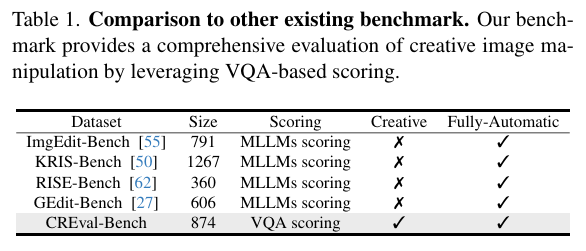
现有的Benchmark主要针对添加、删除、替换物体或者一些简单的逻辑推理任务,而我们希望能够对主流生成模型在指令更复杂,形式更自由,内容更有创意时的生成和编辑效果进行一个评估,因此制作了CREval-Bench。

CREval-Bench主要依赖多模态大模型进行直接打分,所以是全自动化的,不需要手工参与。当前也有很多评估方法是使用大模型进行自动化打分,但与其他用大模型直接评分的方案不同的是,一方面现有大多数自动评估方法是大模型直接打分,是黑盒的,不具有可解释性,因此潜在的大模型bias问题会比较严重,但CREval是基于问答对来进行打分 ,因此可以直观地看见生成的图像在哪里得分、哪里扣分,具有很强的可解释性,而且问答对本身相对客观,所以bias问题相对较小。
二、CREval-Bench
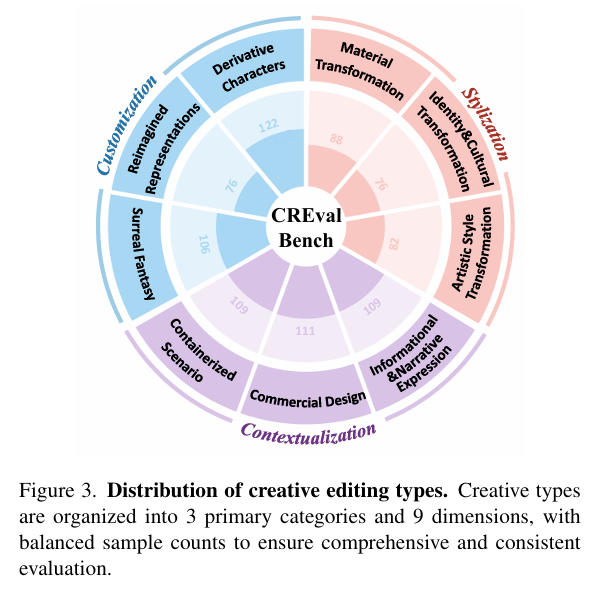
CREval对每一张图从**指令遵循(IF)、视觉一致性(VC)、视觉质量(VQ)**三个评估指标方面进行考量,每个评估指标至少包含5个问题,问题数量会随着图像或者指令的难度进行适当增加,所以说每张生成图都对应包含至少15个问答对,通过和人工提出的问题进行过比较,问题覆盖率达到80%,最终构建了一个Benchmark------CREval-Bench。总体来看,CREval-Bench共包含三个创意类型和9个创意维度,每个维度的样本数量是均衡的,一共包含874张图像和13k个问答对。
三、方法
接下来介绍制作CREval-Bench的过程和使用CREval方法进行评估的pipeline,首先第一步 是先收集高质量的原始图像,图像来源包括几个现有的公开数据集、和互联网上直接收集的图像,然后使用gpt-4o去生成编辑指令,期间会人为输入一些指令示例,规定要生成的创意指令类型。第二步 是要生成评估问题,从IF、VC、VQ三个指标出发,每个指标对应不同的问题生成prompt,生成过程采用cot的方式,先拆解编辑指令,然后分析需要改变的或者不能改变的元素,最后生成问答对。刚才提过,每个指标对应的问题不少于5个,每张图像会对应至少15个问答对供之后进行评估。对于VC,有些元素很重要,有些没那么重要,但是也很重要,所以设置了一个权重。最后就是使用视觉语言大模型对输入的原始图像和编辑后的图像,以及问题进行回答,回答的结果和参考答案进行比较,来计入一个得分。
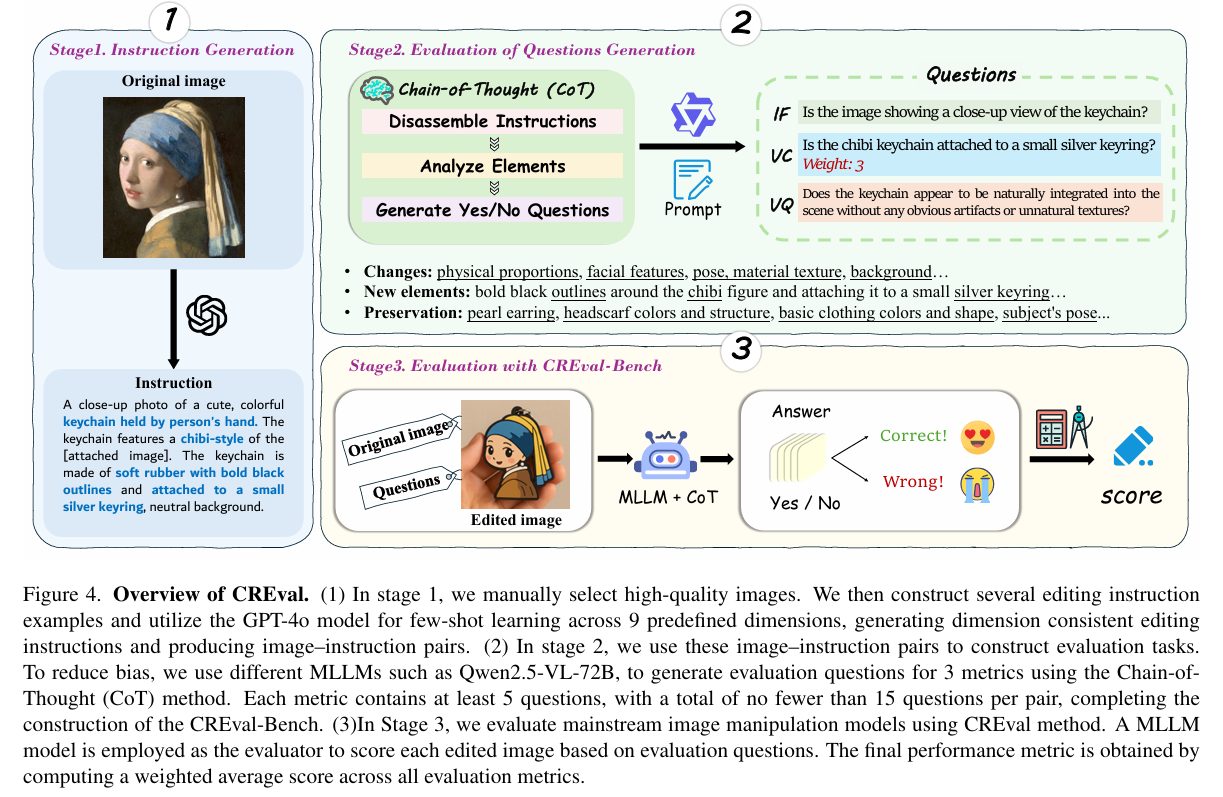
在打分时,采用了加权平均,文中给出解释是因为大模型对视觉质量不敏感,察觉不出图像中的质量问题(如肢体扭曲等),且指令遵循和视觉一致性在编辑过程中同等重要。另外额外做了权重对比分析。
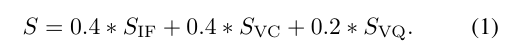

四、实验
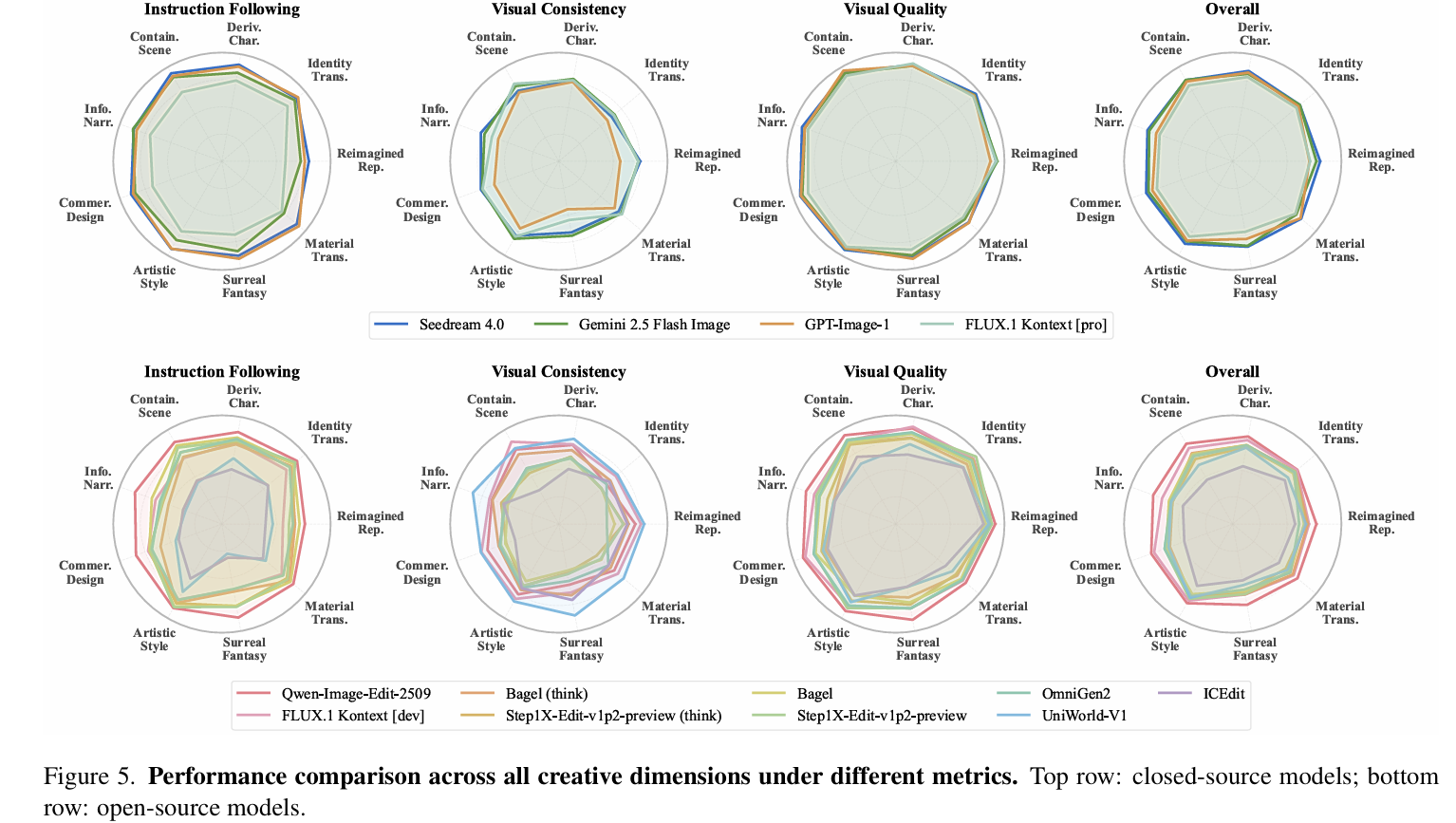
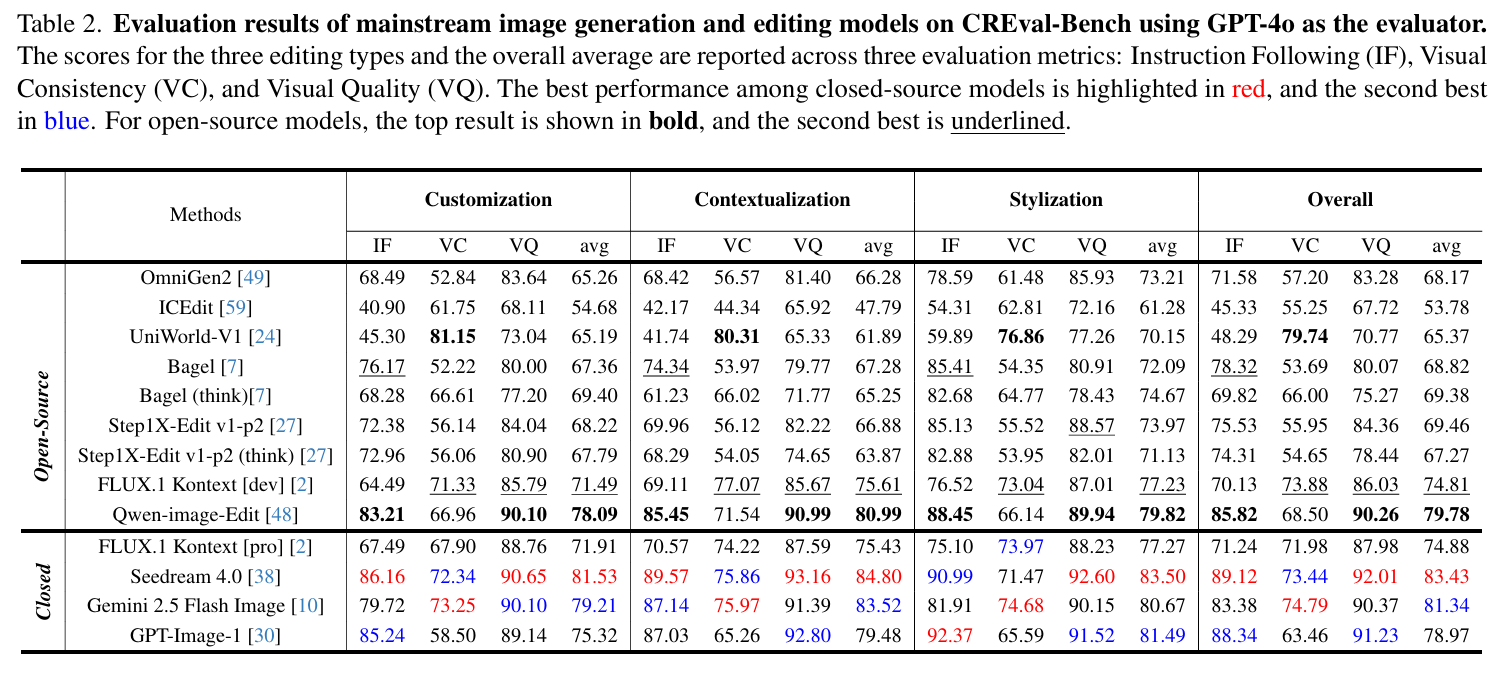
实验分别在开源和闭源的主流生成模型上进行测试,实验结果显示各模型各有所长。在闭源模型中Seedream4.0表现最佳,Gemini-2.5-flash-image在视觉一致性维度最佳,GPT-image-1由于在视觉一致性表现不佳导致总分被拉低;在开源模型中Qwen-image-Edit和FLUX.1 Kontext dev表现较好,其中FLUX的视觉一致性表现要优于Qwen-image-Edit,而表中的UniWorld-V1的VC指标最高是因为该模型在复杂指令的创意生成任务上的能力不足,导致生成图与原图的差异不明显,因此不具有参考价值。
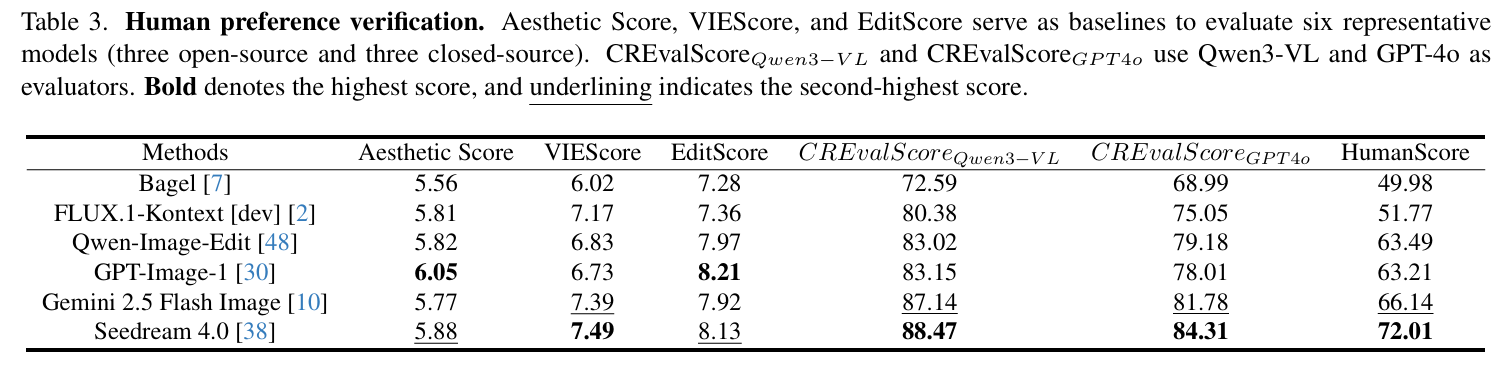
另外,本文进行了人类偏好验证。为了验证方法有效,除了GPT4o外,还选择了Qwen3-VL作为评估器,实验表明CREval方法与人类偏好一致。Qwen-Image-Edit和GPT-Image-1两个模型表现相近。