文章目录
- 一、前言
- 二、思路
- 三、落实
- 四、完成类
-
- 4.1、TextSummarizer.cs
- [4.2、stopWords.cs 上面3.3有我就不复制了。](#4.2、stopWords.cs 上面3.3有我就不复制了。)
- 4.3、测试结果:
一、前言
想写个文件内容收索小工具。
Office、PDF、TXT等获取到纯文本后写入索引。
但考虑到这样生成的索引可能会很大。
所以,文本精简为摘要更好。
了解了官方自带Microsoft.ML ,一通模型配置后,找不到模型下载地址, 好气。
自己写一个。
二、思路
1、清洗 :去除特殊字符、多余空格\R \N什么的
2、提取关键词: 过滤掉无意,然后取出现最多的词汇
3、通过关键字对段落评分
4、筛选高分句子(按原文顺序),拼接,截取最大长度
百度文库随便下了个word 做测试

三、落实
3.1、清洗
csharp
private string CleanText(string text)
{
// 去除HTML标签
text = Regex.Replace(text, @"<[^>]+>", string.Empty);
// 去除特殊字符(保留中文、英文、数字、标点)
text = Regex.Replace(text, @"[^\u4e00-\u9fa5a-zA-Z0-9.,!?;:,。!?;:]", " ");
// 合并多个空格为单个
text = Regex.Replace(text, @"\s+", " ");
return text.Trim();
}3.2、分词
这里使用盘古分词
csharp
/// <summary>
/// 提取关键词(基于词频,排除停用词)
/// </summary>
private HashSet<string> ExtractKeyWords(string text, int topN)
{
// 1、盘古分词
Segment segment = new Segment();
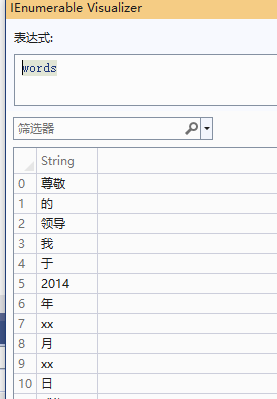
var wordsList = segment.DoSegment(text);
List<string> words = wordsList.Select(w => w.Word).ToList();
}
3.3、过滤停用字
过滤 '的' 这种无意义的关键字
csharp
public class stopWords
{
/// <summary>
/// 停用词库
/// </summary>
public static readonly HashSet<string> Words = new HashSet<string>(StringComparer.OrdinalIgnoreCase)
{
//无语义
"的", "了", "是", "我", "你", "他", "她", "它", "们", "在", "有", "就", "不", "和", "也", "都", "这", "那",
"此", "彼", "之", "于", "以", "而", "则", "因", "为", "所", "把", "被", "让", "使", "将", "给", "对", "对于",
"关于", "与", "及", "或", "即", "乃", "且", "若", "如", "像", "似", "比", "到", "往", "向", "从", "由", "自",
"并", "又", "还", "只", "才", "更", "很", "挺", "太", "极", "最", "凡", "诸", "各", "每", "全", "共", "均",
"曾", "已", "正", "将", "刚", "才", "常", "便", "可", "能", "会", "应", "该", "要", "得", "需", "须", "肯",
"敢", "需", "应", "须", "呗", "嘛", "呢", "吗", "吧", "啊", "哦", "哈", "呀", "哟", "唉", "呃",
"a", "an", "the", "and", "or", "but", "is", "are", "was", "were", "be", "been", "being",
"in", "on", "at", "to", "for", "of", "with", "by", "from", "into", "onto", "during", "through",
"about", "around", "between", "among", "within", "without", "above", "below", "over", "under",
"i", "you", "he", "she", "it", "we", "they", "me", "him", "her", "us", "them",
"my", "your", "his", "her", "its", "our", "their", "mine", "yours", "ours", "theirs",
"this", "that", "these", "those", "who", "whom", "whose", "which", "what", "when", "where", "why", "how",
"do", "does", "did", "have", "has", "had", "will", "would", "shall", "should", "may", "might", "can", "could", "must"," ",
//办公场景通用
"公司", "部门", "员工", "同事", "领导", "经理", "总监", "总", "先生", "女士", "各位", "大家", "本人", "本", "贵",
"现将", "现将有关", "如下", "情况", "内容", "事宜", "问题", "事项", "工作", "任务", "安排", "部署", "落实", "执行",
"要求", "规定", "通知", "公告", "通报", "报告", "申请", "审批", "审核", "同意", "不同意", "反馈", "沟通", "协调",
"跟进", "处理", "解决", "完成", "提交", "发送", "接收", "查阅", "参考", "了解", "知悉", "知晓", "掌握", "熟悉",
"为了", "根据", "按照", "依据", "结合", "鉴于", "由于", "因此", "所以", "此外", "另外", "同时", "并且", "以及",
"特此", "特此说明", "特此报告", "特此申请", "综上所述", "总而言之", "总之", "综上", "以上", "以上所述", "请予批准",
"请予支持", "请予配合", "望周知", "请各部门", "请相关人员", "务必", "及时", "尽快", "按时", "按期", "定期", "临时",
// Word专属
"页眉", "页脚", "页码", "分节符", "分页符", "样式", "字体", "字号", "行距", "段落", "对齐方式", "缩进", "边框", "底纹",
"水印", "目录", "索引", "脚注", "尾注", "域", "邮件合并", "宏", "VBA", "模板", "修订", "插入", "删除", "批注者", "版本",
"版本号", "V1.0", "V2.0", "修订模式", "审阅模式", "接受修订", "拒绝修订", "批注", "批注内容", "批注时间", "批注人",
"修改人", "修改时间", "修订痕迹",
// Excel专属
"单元格", "行", "列", "行号", "列标", "工作表", "工作簿", "公式", "函数", "数据透视表", "图表", "筛选", "排序",
"条件格式", "数据验证", "宏", "VBA", "模板", "冻结窗格", "拆分窗格", "共享", "协作", "同步", "锁定单元格", "解锁",
"批注者", "批注时间", "共享链接", "工作簿共享", "保护工作表",
// PPT专属
"幻灯片", "母版", "版式", "动画", "切换效果", "文本框", "形状", "图片", "图表", "模板", "背景", "配色方案",
"字体", "字号", "对齐方式", "组合", "拆分", "超链接", "页码", "页眉页脚", "共享备注", "演示者视图", "批注",
"批注者", "共享链接", "幻灯片共享", "协作模式",
// Outlook专属
"主题", "抄送", "密送", "收件人", "发件人", "日期", "时间", "附件", "详见附件", "附件如下", "回复", "转发", "邮件",
"特此邮件", "特此告知", "特此通知", "请查阅", "请回复", "请确认", "请审批", "谢谢", "感谢", "顺颂商祺", "祝好",
"日历", "日程", "会议邀请", "响应", "接受", "拒绝", "暂定", "提醒", "邮件正文", "签名", "自动回复", "垃圾邮件",
"收件箱", "发件箱", "已发送", "草稿箱", "归档", "标记", "重要性", "优先级", "转发自", "回复自", "原邮件", "抄送链",
"回复链", "会议回执", "已读回执", "未读回执", "转发次数", "回复次数",
// 行政部
"办公用品", "采购", "考勤", "请假", "加班", "出差", "报销", "费用", "固定资产", "办公环境", "会议安排",
// 财务部
"报销", "发票", "凭证", "台账", "预算", "结算", "付款", "收款", "工资", "薪酬", "福利", "社保", "公积金", "税务",
//it
"需求", "bug", "版本", "迭代", "测试", "上线", "代码", "开发", "系统", "软件", "硬件", "服务器", "数据库",
//人力
"招聘", "面试", "入职", "离职", "转正", "绩效考核", "KPI", "OKR", "培训", "团建", "员工关系", "薪酬",
// 业务核心术语
"合同", "协议", "条款", "金额", "日期", "签字", "盖章", "预算", "营收", "成本", "利润", "数据", "报表", "台账",
"需求", "bug", "版本", "迭代", "测试", "上线", "招聘", "面试", "入职", "离职", "绩效考核",
// Office功能核心术语
"宏", "VBA", "数据透视表", "邮件合并", "共享链接", "会议邀请", "审批", "报销"
};
}3.4、词频(关键字权重)
csharp
/// <summary>
/// 提取关键词(基于词频,排除停用词)
/// </summary>
private HashSet<string> ExtractKeyWords(string text, int topN)
{
// 1、盘古分词
Segment segment = new Segment();
var wordsList = segment.DoSegment(text);
List<string> words = wordsList.Select(w => w.Word).ToList();
//2、过滤停用词
var filteredWords = words
.Where(w =>
!string.IsNullOrWhiteSpace(w)
&& !stopWords.Words.Contains(w) // 过滤停用词
)
.ToList();
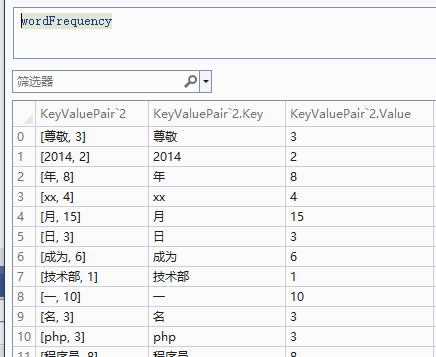
// 3、词频统计
var wordFrequency = filteredWords
.GroupBy(w => w, StringComparer.OrdinalIgnoreCase)
.ToDictionary(g => g.Key, g => g.Count(), StringComparer.OrdinalIgnoreCase);
// 4、取词频最高的N个作为关键词
return wordFrequency
.OrderByDescending(kv => kv.Value)
.Take(topN)
.Select(kv => kv.Key)
.ToHashSet(StringComparer.OrdinalIgnoreCase);
}
3.5、句子权重(根据关键字评分)

四、完成类
nuget PanGu.Core1.0.0
4.1、TextSummarizer.cs
csharp
using PanGu;
using System.Text.RegularExpressions;
/// <summary>
/// .NET 8 无模型文本摘要生成器
/// 基于规则化的关键句提取实现
/// </summary>
public class TextSummarizer
{
/// <summary>
/// 生成文本摘要
/// </summary>
/// <param name="text">原始文本</param>
/// <param name="summaryLength">摘要最大长度(字符数)</param>
/// <param name="topSentenceCount">最多选取的句子数</param>
/// <returns>生成的文本摘要</returns>
public string GenerateSummary(string text, int summaryLength = 200, int topSentenceCount = 3)
{
if (string.IsNullOrWhiteSpace(text))
return string.Empty;
// 步骤1:文本预处理
var cleanText = CleanText(text);
var sentences = SplitTextToSentences(cleanText);
// 如果句子数少于等于要选的数量,直接返回拼接结果(控制长度)
if (sentences.Count <= topSentenceCount)
{
var fullSummary = string.Join(" ", sentences);
return TruncateText(fullSummary, summaryLength);
}
// 步骤2:提取关键词(词频统计)
var keyWords = ExtractKeyWords(cleanText, topN: 10);
// 步骤3:对每个句子评分
var scoredSentences = ScoreSentences(sentences, keyWords);
// 步骤4:筛选高分句子(按原文顺序)
var topSentences = scoredSentences
.OrderByDescending(s => s.Score)
.Take(topSentenceCount)
.OrderBy(s => s.Index) // 保持原文顺序
.Select(s => s.Sentence)
.ToList();
// 步骤5:拼接并截断到指定长度
var summary = string.Join(" ", topSentences);
return TruncateText(summary, summaryLength);
}
/// <summary>
/// 文本清洗:去除特殊字符、多余空格
/// </summary>
private string CleanText(string text)
{
// 去除HTML标签(如果有)
text = Regex.Replace(text, @"<[^>]+>", string.Empty);
// 去除特殊字符(保留中文、英文、数字、标点)
text = Regex.Replace(text, @"[^\u4e00-\u9fa5a-zA-Z0-9.,!?;:,。!?;:]", " ");
// 合并多个空格为单个
text = Regex.Replace(text, @"\s+", " ");
return text.Trim();
}
/// <summary>
/// 将文本分割为句子
/// </summary>
/// <summary>
/// 将文本分割为句子
/// </summary>
private List<string> SplitTextToSentences(string text)
{
// 定义句子分割符
var sentenceSeparators = new[] { '。', '!', '?', '.', '!', '?' };
// 先按分割符分割,保留分割符(关键:避免丢失分割符)
var parts = new List<string>();
int lastIndex = 0;
// 遍历文本,手动分割并保留分割符(替代Regex.Split的丢失分割符问题)
for (int i = 0; i < text.Length; i++)
{
if (sentenceSeparators.Contains(text[i]))
{
// 提取句子(从上次位置到当前分割符)
string sentence = text.Substring(lastIndex, i - lastIndex + 1).Trim();
if (!string.IsNullOrWhiteSpace(sentence) && sentence.Length > 2)
{
parts.Add(sentence);
}
lastIndex = i + 1;
}
}
// 处理最后一段(无分割符的剩余文本)
if (lastIndex < text.Length)
{
string lastSentence = text.Substring(lastIndex).Trim();
if (!string.IsNullOrWhiteSpace(lastSentence) && lastSentence.Length > 2)
{
// 给最后一段补充默认分割符(保证语义完整)
parts.Add(lastSentence + "。");
}
}
return parts;
}
/// <summary>
/// 提取关键词(基于词频,排除停用词)
/// </summary>
private HashSet<string> ExtractKeyWords(string text, int topN)
{
// 1、盘古分词
Segment segment = new Segment();
var wordsList = segment.DoSegment(text);
List<string> words = wordsList.Select(w => w.Word).ToList();
//2、过滤停用词
var filteredWords = words
.Where(w =>
!string.IsNullOrWhiteSpace(w)
&& !stopWords.Words.Contains(w) // 过滤停用词
)
.ToList();
// 3、词频统计
var wordFrequency = filteredWords
.GroupBy(w => w, StringComparer.OrdinalIgnoreCase)
.ToDictionary(g => g.Key, g => g.Count(), StringComparer.OrdinalIgnoreCase);
// 4、取词频最高的N个作为关键词
return wordFrequency
.OrderByDescending(kv => kv.Value)
.Take(topN)
.Select(kv => kv.Key)
.ToHashSet(StringComparer.OrdinalIgnoreCase);
}
/// <summary>
/// 对句子进行评分
/// 评分维度:关键词数量(主要) + 位置权重(首句/尾句加分) + 句子长度(适中加分)
/// </summary>
private List<ScoredSentence> ScoreSentences(List<string> sentences, HashSet<string> keyWords)
{
var scoredSentences = new List<ScoredSentence>();
for (int i = 0; i < sentences.Count; i++)
{
var sentence = sentences[i];
var score = 0.0;
// 维度1:关键词匹配数(核心权重)
var sentenceWords = Regex.Split(sentence, @"\W+")
.Concat(sentence.Where(c => char.IsLetterOrDigit(c)).Select(c => c.ToString()))
.Select(w => w.Trim())
.Where(w => !string.IsNullOrWhiteSpace(w))
.ToList();
var keywordMatchCount = sentenceWords.Count(w => keyWords.Contains(w));
score += keywordMatchCount * 5; // 关键词匹配权重最高
// 维度2:位置权重(首句、尾句加分)
if (i == 0) // 第一句通常是主旨句
score += 4;
else if (i == sentences.Count - 1) // 最后一句可能是总结句
score += 3;
else if (i < sentences.Count / 3) // 前1/3的句子加分
score += 2;
// 维度3:句子长度(排除过短/过长的句子,适中长度加分)
var sentenceLength = sentence.Length;
if (sentenceLength >= 15 && sentenceLength <= 100)
score += 2;
scoredSentences.Add(new ScoredSentence
{
Sentence = sentence,
Score = score,
Index = i
});
}
return scoredSentences;
}
/// <summary>
/// 截断文本到指定长度(保留完整语义,避免截断到单词中间)
/// </summary>
private string TruncateText(string text, int maxLength)
{
if (text.Length <= maxLength)
return text;
// 找到最后一个标点符号的位置,避免截断到句子中间
var lastPunctuationIndex = text.LastIndexOfAny(new[] { '。', '!', '?', '.', '!', '?' }, maxLength);
if (lastPunctuationIndex > maxLength - 20) // 确保至少保留大部分内容
return text.Substring(0, lastPunctuationIndex + 1);
// 如果没有合适的标点,直接截断并加省略号
return text.Substring(0, maxLength - 3) + "...";
}
/// <summary>
/// 带评分的句子模型
/// </summary>
private class ScoredSentence
{
public string Sentence { get; set; } = string.Empty;
public double Score { get; set; }
public int Index { get; set; }
}
}4.2、stopWords.cs 上面3.3有我就不复制了。
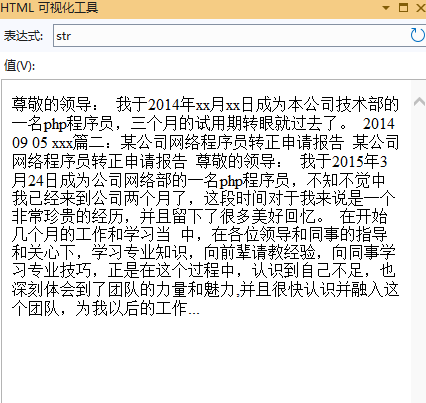
4.3、测试结果:
取评分最高的三段,并按文章原始顺序排序,生成最长300字符的摘要:
csharp
//调用
TextSummarizer ft = new TextSummarizer();
string str= ft.GenerateSummary(fileText,300,3);