在实际工程项目中,单台 Redis 服务器根本无法满足生产需求 ------ 不仅会面临单点故障,一旦宕机整个缓存服务直接瘫痪;同时单台机器内存容量有限、请求负载过高,也撑不住高并发场景。
就拿电商网站来说,商品数据大多是 "一次上传、无数次浏览",属于典型的 "多读少写" 场景。想要解决单机 Redis 的痛点,搭建 Redis 集群是必经之路。本篇博客全程干货,从基础的主从复制、哨兵模式,到分布式 Cluster 集群,再到 SpringBoot 整合实操,最后详解面试常考的缓存穿透、击穿、雪崩问题,兼顾理论与实操,适合 Redis 集群入门及巩固学习。
一、Redis 集群基础:为什么必须用集群?
单台 Redis 无法应用于生产,核心原因有两点:
- 结构层面:单点故障风险高,一台服务器需承担所有请求,负载压力巨大;
- 容量层面:单台 Redis 内存有限,即便机器内存有 256G,也不建议将 Redis 存储内存超过 20G,无法满足海量数据存储需求。
而 Redis 集群能完美解决以上问题,结合 "多读少写" 的业务场景,通过合理的架构设计,实现高可用、高并发、大容量的缓存服务。
二、Redis 主从复制(一主二从架构)
Redis 本身读写性能优异,但在超高并发场景下,单台服务器依旧会面临读写压力过大的问题。主从复制架构,核心是 "读写分离",分担主节点压力,是 Redis 高可用的基础。
1. 核心概念
主从复制,即把一台 Redis 服务器(主节点 Master)的数据,复制到其他 Redis 服务器(从节点 Slave),数据复制是单向的,只能从主到从。
- 主节点(Master):以写操作为主,同时负责同步数据到从节点;
- 从节点(Slave):以读操作为主,不允许写操作,数据完全同步主节点;
- 常用架构:一主二从(1 个主节点 + 2 个从节点),适配 80% 的读写分离场景,大幅减轻主节点读压力。
默认情况下,每台 Redis 服务器都是主节点,一个主节点可挂载多个从节点,但每个从节点只能归属一个主节点。
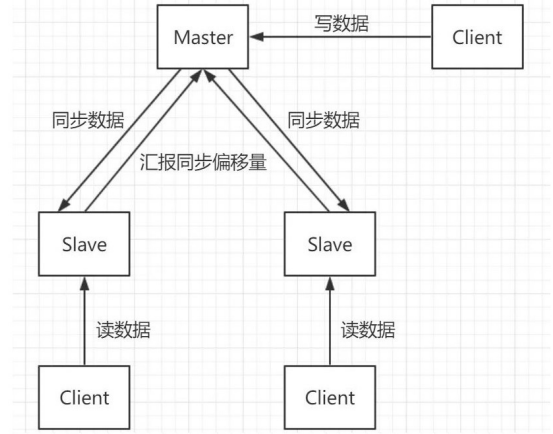
2. 主从复制原理(三步同步)
- 从节点连接主节点后,主动发送数据同步请求;
- 主节点接收请求后,对自身数据进行 RDB 持久化,生成 RDB 文件并发送给从节点,从节点读取 RDB 文件完成数据初始化;
- 后续主节点每执行一次写操作,都会实时同步给从节点,保证主从数据一致。
3. 主从复制的核心作用
- 数据冗余:实现数据热备份,是 Redis 持久化之外的另一重数据保障;
- 故障恢复:主节点宕机时,从节点可临时顶替主节点提供读服务,避免服务中断;
- 负载均衡:读写分离,主节点写、从节点读,多个从节点分摊读压力,提升并发量;
- 高可用基石:是哨兵模式、Cluster 集群的基础,没有主从复制,就无法实现后续的自动故障转移。
4. 一主二从环境搭建(Docker 版,实操可直接复用)
(1)前期准备(阿里云服务器)
创建配置文件和数据存储目录,规划 3 台 Redis 实例(1 主 2 从):
# 配置文件目录(3个配置文件,对应3台实例)
/tmp/redis/conf/redis1.conf
/tmp/redis/conf/redis2.conf
/tmp/redis/conf/redis3.conf
# 数据目录(3个数据目录,隔离存储)
/tmp/redis/data/data1
/tmp/redis/data/data2
/tmp/redis/data/data3(2)创建 3 个 Redis 容器
# 主节点(redis11,映射端口6381)
docker run -itd -p 6381:6379 --name redis11 -v /tmp/redis/conf/redis1.conf:/etc/redis1.conf -v /tmp/redis/data/data1:/data redis redis-server /etc/redis1.conf
# 从节点1(redis12,映射端口6382)
docker run -itd -p 6382:6379 --name redis12 -v /tmp/redis/conf/redis2.conf:/etc/redis2.conf -v /tmp/redis/data/data2:/data redis redis-server /etc/redis2.conf
# 从节点2(redis13,映射端口6383)
docker run -itd -p 6383:6379 --name redis13 -v /tmp/redis/conf/redis3.conf:/etc/redis3.conf -v /tmp/redis/data/data3:/data redis redis-server /etc/redis3.conf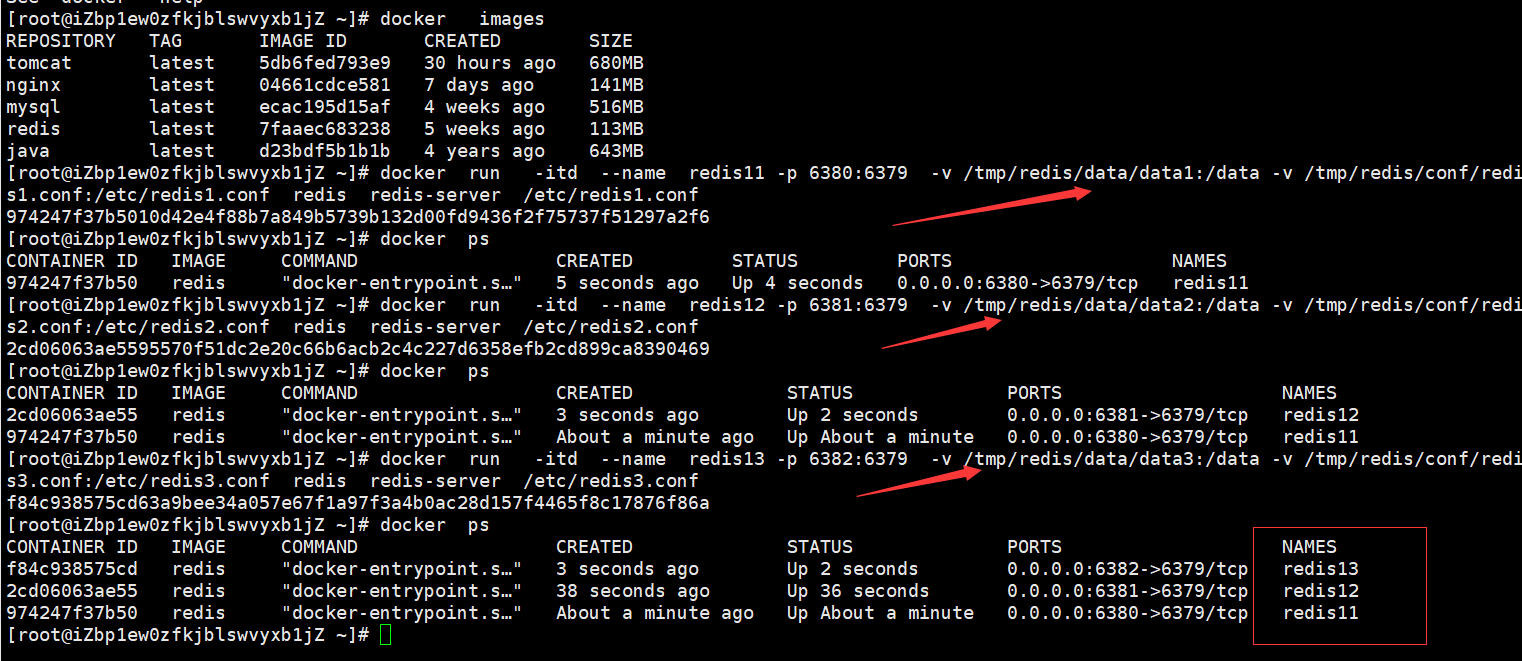
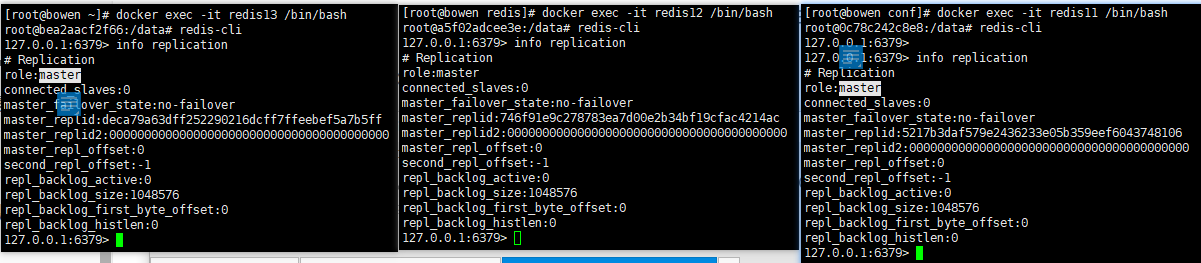
(3)查看容器信息
创建完成后,通过以下命令查看容器 IP(后续配置主从关系需用到):
docker inspect 容器名/容器ID记录 3 台容器的 IP 和端口(示例):
- redis11(主):172.18.0.2:6379
- redis12(从):172.18.0.3:6379
- redis13(从):172.18.0.4:6379
此时进入 3 台 Redis 实例,会发现默认都是主节点,未建立主从关系。
(4)配置主从关系(两种方式)
方式 1:临时配置(重启容器失效,适合测试)
进入从节点容器,执行命令 "认领主节点"(Redis 高版本用 replicaof,低版本用 slaveof):
# 进入redis12(从节点1),指定主节点为redis11
replicaof 172.18.0.2 6379
# 进入redis13(从节点2),指定主节点为redis11
replicaof 172.18.0.2 6379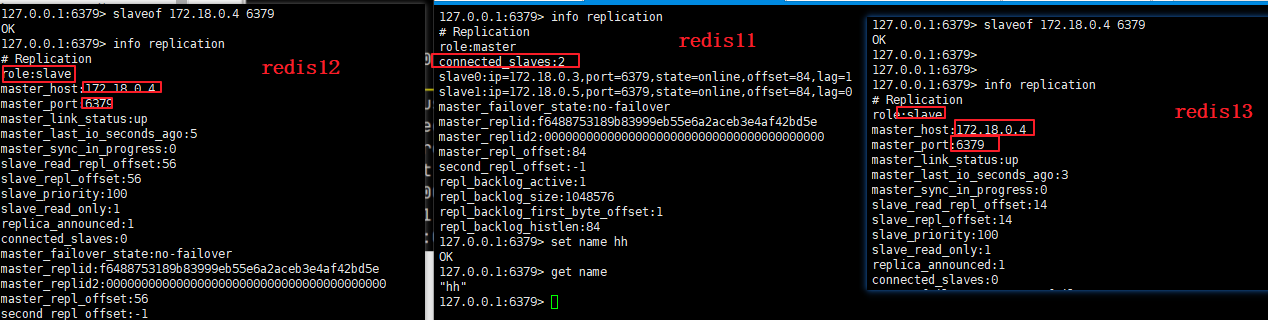
方式 2:永久配置(推荐,重启容器生效)
修改两个从节点的配置文件(redis2.conf、redis3.conf),添加以下配置:
################################# REPLICATION #################################
# 配置主节点IP和端口
replicaof 172.18.0.2 6379配置完成后,重启从节点容器,主从关系永久生效。
5. 主从复制使用规则(必记)
- 从节点只读不写:从节点执行写操作会直接报错,所有写操作必须在主节点执行;
- 主节点宕机:默认从节点不会自动切换为主节点,集群仅失去写能力,主节点重启后恢复正常;
- 从节点宕机:若为临时配置的从节点,重启后会变回主节点,且丢失之前同步的数据;若为永久配置,重启后会自动重新同步主节点数据;
- 主节点故障手动切换:在任意从节点执行
replicaof no one,使其成为新主节点,其他从节点再执行replicaof 新主节点IP 端口,手动切换主从关系。
三、哨兵模式(Sentinel):主从自动故障转移
普通主从复制有一个致命缺陷:主节点宕机后,需要人工手动切换从节点为主节点,不仅费时费力,还会导致服务短暂不可用。Redis 从 2.8 版本开始,推出哨兵模式,完美解决这个问题。
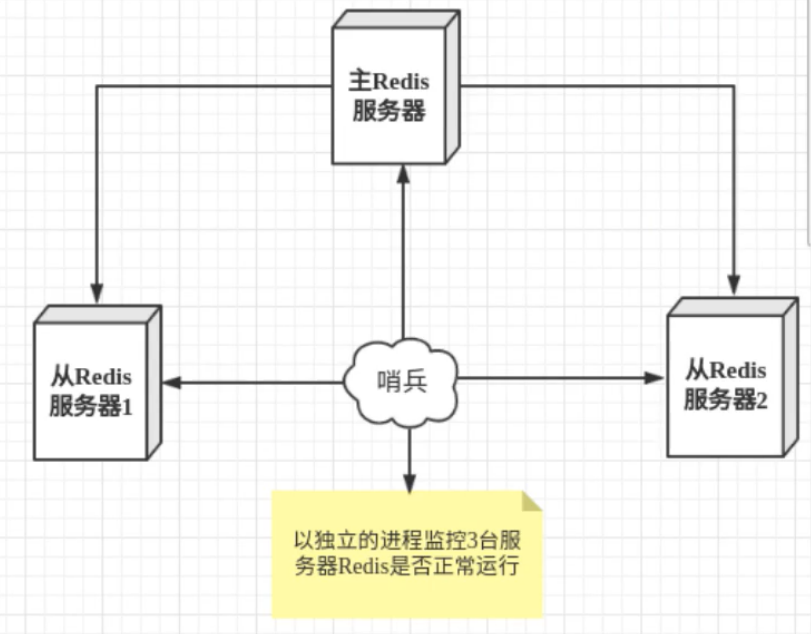
1. 哨兵模式核心概述
哨兵(Sentinel)是一个独立运行的进程,核心作用是 "监控 + 自动故障转移",基于主从复制架构,实现 Redis 集群的高可用。
- 监控:实时监测主节点、从节点的运行状态,通过发送命令,判断节点是否正常;
- 自动故障转移:当监测到主节点宕机,自动投票选举一个从节点,将其切换为新主节点,并通知其他从节点更新主节点配置,全程无需人工干预。
为了避免单哨兵故障,生产环境通常采用 "多哨兵模式",哨兵之间互相监控,提升集群稳定性。
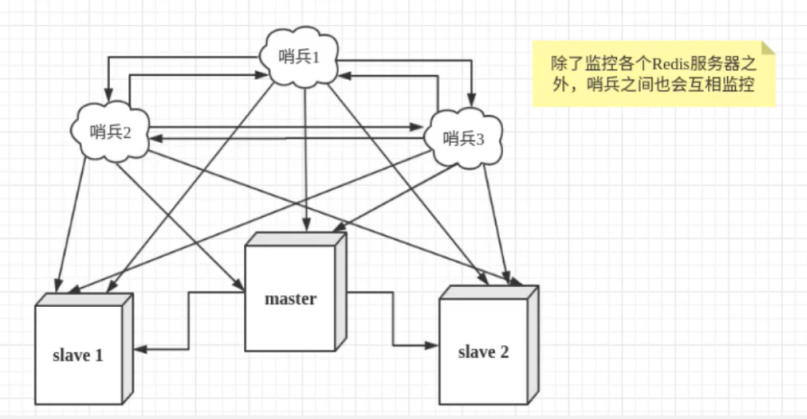
2. 关键术语(面试常考)
- 主观下线:单个哨兵检测到主节点无响应,单方面判定主节点不可用;
- 客观下线:多个哨兵检测到主节点故障,且达到指定数量(配置中设置),统一判定主节点下线,开启故障转移流程。
3. 哨兵模式搭建(基于一主二从架构)
(1)配置哨兵配置文件(sentinel.conf)
创建哨兵配置文件,放入/tmp/redis/conf/目录,核心配置如下:
# 哨兵运行端口(默认26379)
port 26379
# 关闭保护模式,允许外部访问
protected-mode no
# 监控主节点:mymaster(集群名,可自定义)、主节点IP、端口、判定下线的哨兵数量(1代表1个及以上哨兵判定即可)
sentinel monitor mymaster 172.18.0.2 6379 1(2)重新创建容器(挂载哨兵配置)
# 主节点(redis11)
docker run -itd -p 6381:6379 --name redis11 -v /tmp/redis/conf/redis1.conf:/etc/redis1.conf -v /tmp/redis/data/data1:/data -v /tmp/redis/conf/sentinel.conf:/etc/sentinel.conf redis redis-server /etc/redis1.conf
# 从节点1(redis12)
docker run -itd -p 6382:6379 --name redis12 -v /tmp/redis/conf/redis2.conf:/etc/redis2.conf -v /tmp/redis/data/data2:/data -v /tmp/redis/conf/sentinel.conf:/etc/sentinel.conf redis redis-server /etc/redis2.conf
# 从节点2(redis13)
docker run -itd -p 6383:6379 --name redis13 -v /tmp/redis/conf/redis3.conf:/etc/redis3.conf -v /tmp/redis/data/data3:/data -v /tmp/redis/conf/sentinel.conf:/etc/sentinel.conf redis redis-server /etc/redis3.conf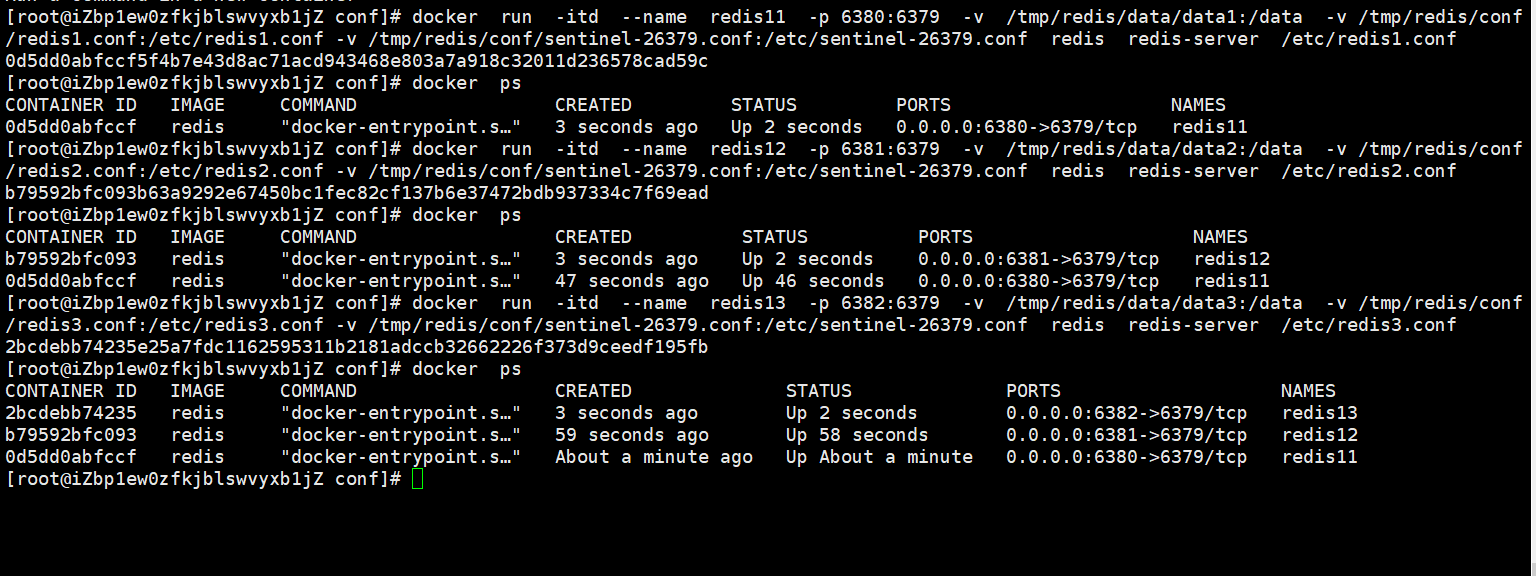
(3)启动哨兵
进入任意从节点容器,启动哨兵进程:
redis-sentinel /etc/sentinel.conf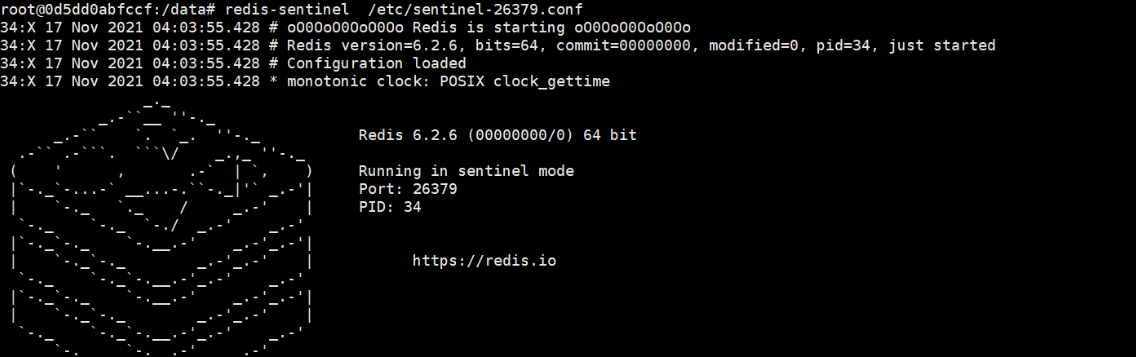
启动后,哨兵会自动监控主节点,当主节点宕机,会自动执行故障转移,切换新主节点。
4. 哨兵模式优缺点
优点
- 继承主从复制所有优势,实现自动故障转移,服务可用性大幅提升;
- 多哨兵监控,稳定性强,避免单哨兵故障导致集群失控;
- 无需人工干预,减少运维成本,比普通主从架构更健壮。
缺点
- 在线扩容困难:集群容量达到上限后,扩容流程复杂,无法快速扩展;
- 配置复杂:哨兵配置项繁多,搭建和调优门槛较高;
- 单主节点瓶颈:集群只有一个主节点,所有写压力集中在主节点,负载依旧较大。
5. 哨兵模式完整配置(备用)
完整的 sentinel.conf 配置文件,包含密码、超时时间、脚本配置等,可直接复用:
# 哨兵运行端口
port 26379
# 哨兵工作目录
dir /tmp
# 监控主节点(mymaster为集群名,可自定义)
sentinel monitor mymaster 127.0.0.1 6379 1
# 主节点密码(若主从设置了密码,必须配置)
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# 主观下线超时时间(默认30000毫秒,30秒)
sentinel down-after-milliseconds mymaster 30000
# 故障转移时,同时同步数据的从节点数量(设为1,避免多个从节点同时不可用)
sentinel parallel-syncs mymaster 1
# 故障转移超时时间(默认180000毫秒,3分钟)
sentinel failover-timeout mymaster 180000
# 通知脚本(故障时发送通知,可选)
sentinel notification-script mymaster /var/redis/notify.sh
# 客户端重配置脚本(主节点切换后,通知客户端,可选)
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh四、Redis Cluster 集群:多主多从,分布式存储
哨兵模式解决了主从自动故障转移问题,但依旧是单主节点架构,写压力无法分散。Redis Cluster 集群采用 "三主三从" 架构,实现数据分片存储,彻底解决单机容量和并发瓶颈,是生产环境中最常用的 Redis 集群方案。
1. Cluster 集群核心概述
Cluster 集群由多个节点(Node)组成,采用 "多主多从" 架构,核心特点是 "去中心化 + 数据分片":
- 去中心化:无中心节点,连接任意一个主节点,都能操作整个集群;
- 数据分片:将数据分散存储在不同主节点,每个主节点只存储一部分数据,分担存储和读写压力;
- 高可用:每个主节点对应一个从节点,主节点宕机后,从节点自动选举为新主节点。
2. Cluster 集群环境搭建(Docker host 模式,三主三从)
(1)集群配置规划
- 容器名称:redis-node1~redis-node6(6 个容器,3 主 3 从);
- 端口号:6379、6380、6381(主节点),6382、6383、6384(从节点);
- 挂载目录:数据目录
/tmp/redis/data/node1~node6,配置文件自动生成; - 注意:阿里云服务器需开放端口(6379~6384)和集群总线端口(16379~16384,端口号 + 10000)。
(2)创建 6 个 Redis 容器(开启集群模式)
# 节点1(主,端口6379)
docker create --name redis-node1 --net host -v /tmp/redis/data/node1:/data redis --cluster-enabled yes --cluster-config-file nodes-node-1.conf --port 6379
# 节点2(主,端口6380)
docker create --name redis-node2 --net host -v /tmp/redis/data/node2:/data redis --cluster-enabled yes --cluster-config-file nodes-node-2.conf --port 6380
# 节点3(主,端口6381)
docker create --name redis-node3 --net host -v /tmp/redis/data/node3:/data redis --cluster-enabled yes --cluster-config-file nodes-node-3.conf --port 6381
# 节点4(从,端口6382)
docker create --name redis-node4 --net host -v /tmp/redis/data/node4:/data redis --cluster-enabled yes --cluster-config-file nodes-node-4.conf --port 6382
# 节点5(从,端口6383)
docker create --name redis-node5 --net host -v /tmp/redis/data/node5:/data redis --cluster-enabled yes --cluster-config-file nodes-node-5.conf --port 6383
# 节点6(从,端口6384)
docker create --name redis-node6 --net host -v /tmp/redis/data/node6:/data redis --cluster-enabled yes --cluster-config-file nodes-node-6.conf --port 6384(3)启动所有容器
docker start redis-node1 redis-node2 redis-node3 redis-node4 redis-node5 redis-node6(4)组建 Cluster 集群
进入任意一个容器(如 redis-node1),执行集群组建命令:
# 进入容器
docker exec -it redis-node1 /bin/bash
# 组建集群(--cluster-replicas 1 表示每个主节点对应1个从节点)
redis-cli --cluster create 宿主机IP:6379 宿主机IP:6380 宿主机IP:6381 宿主机IP:6382 宿主机IP:6383 宿主机IP:6384 --cluster-replicas 1执行后,输入yes确认集群配置,等待初始化完成即可。
(5)集群验证
连接集群节点(必须加-c参数,代表集群模式):
shell
redis-cli -c -h 宿主机IP -p 6379执行cluster nodes命令,可查看所有节点的主从关系和运行状态。
3. 分片哈希槽(Cluster 核心原理)
Redis Cluster 集群共有16384 个分片哈希槽,这是数据分片的核心:
- 16384 个哈希槽会平均分配给所有主节点(3 主节点时,每个主节点分配 5461 个槽位);
- 节点 1(主):0~5460
- 节点 2(主):5461~10922
- 节点 3(主):10923~16383
- 读写数据时,Redis 会根据 key 通过 CRC16 算法,计算出一个 0~16383 的哈希值;
- 根据哈希值定位到对应的哈希槽,再找到该槽位归属的主节点,执行读写操作。
4. 集群搭建常见坑(避坑指南)
-
坑 1:报错
[ERR] Node xxx:6379 is not empty- 原因:搭建集群前,节点中存在残留数据或集群配置;
- 解决:清空节点数据目录(
/tmp/redis/data/node1~node6),重新创建容器。
-
坑 2:集群无法连接,节点之间无法通信
- 原因:未开放集群总线端口(服务端口 + 10000);
- 解决:阿里云服务器开放 6379~6384 和 16379~16384 端口。
5. Cluster 集群核心特点
- 去中心化:无中心节点,任意主节点均可接入集群,操作全集群数据;
- 数据分片:数据分散存储在不同主节点,解决单机容量瓶颈;
- 自动故障转移:主节点宕机后,对应从节点通过过半选举机制,自动成为新主节点;
- 水平扩容:可按需增减节点,扩展集群容量和并发能力;
- 读写分离:主节点负责读写,从节点负责同步备份和读操作,分担压力。
五、SpringBoot 整合 Redis Cluster 集群(实操)
SpringBoot 整合 Redis Cluster 非常简单,只需引入依赖、配置集群节点,即可实现对集群的读写操作。
1. 导入依赖
SpringBoot 默认使用 Lettuce 连接 Redis(替代 Jedis),需引入核心依赖和连接池依赖:
<!-- Redis核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- Lettuce连接池依赖 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>2. 配置 application.properties
# Redis Cluster集群节点配置(替换为自己的宿主机IP)
spring.redis.cluster.nodes=118.31.189.130:6379,118.31.189.130:6380,118.31.189.130:6381,118.31.189.130:6382,118.31.189.130:6383,118.31.189.130:6384
# Redis密码(若未设置密码,注释即可)
# spring.redis.password=123456
# Lettuce连接池配置
spring.redis.lettuce.pool.max-active=8 # 最大活跃连接数
spring.redis.lettuce.pool.max-wait=-1 # 最大等待时间(-1表示无限制)
spring.redis.lettuce.pool.max-idle=8 # 最大空闲连接数
spring.redis.lettuce.pool.min-idle=0 # 最小空闲连接数
spring.redis.lettuce.shutdown-timeout=100 # 关闭超时时间3. 代码测试
使用StringRedisTemplate操作 Redis 集群,测试读写功能:
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.StringRedisTemplate;
@SpringBootTest
class SpringBootRedisClusterApplicationTests {
@Autowired
private StringRedisTemplate redisTemplate;
@Test
void contextLoads() {
// 向集群中存入数据
redisTemplate.opsForValue().set("testKey", "testValue");
// 从集群中获取数据
Object result = redisTemplate.opsForValue().get("testKey");
System.out.println("从Redis集群获取的数据:" + result);
}
}运行测试用例,若能正常输出数据,说明 SpringBoot 与 Redis Cluster 整合成功。
六、Redis 缓存三大问题(穿透、击穿、雪崩)
Redis 作为缓存层,核心作用是挡住大部分请求,减轻数据库压力。但在高并发场景下,容易出现缓存穿透、击穿、雪崩三大问题,严重时会压垮数据库,这也是面试高频考点。
1. 缓存处理常规流程
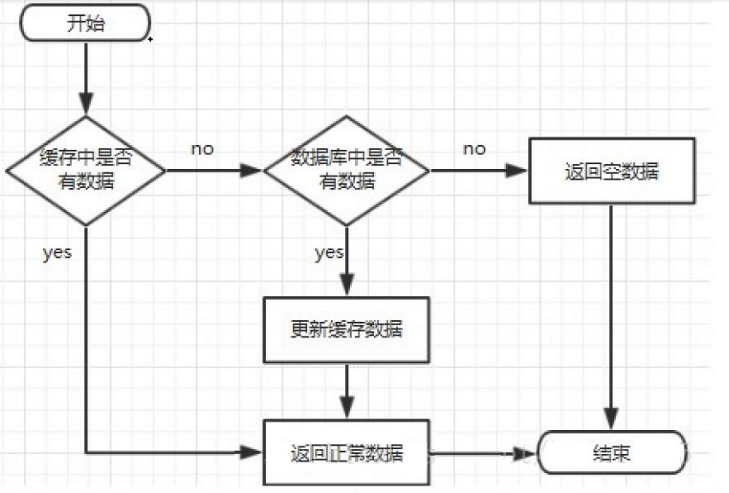
请求到来 → 查 Redis 缓存 → 缓存命中(直接返回结果) → 缓存未命中(查数据库) → 数据库命中(写入缓存 + 返回结果) → 数据库未命中(返回空结果)。
2. 缓存穿透(查询不到数据)
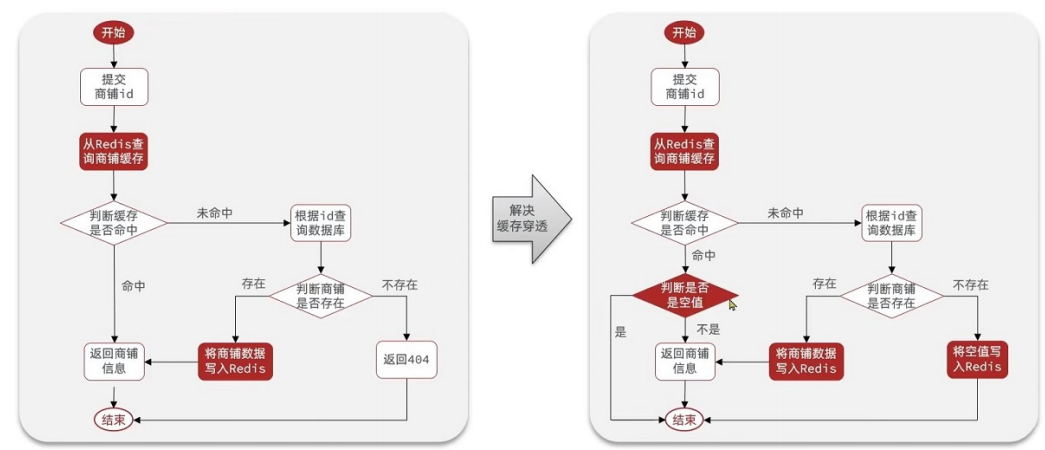
概念
查询一个缓存和数据库都不存在的数据,因为数据库无数据,无法写入缓存,导致每次请求都直接打到数据库。黑客常利用此漏洞发起攻击,大量请求访问不存在的数据,压垮数据库。
解决方案
-
方案 1:缓存空数据
- 原理:查询无结果时,将空值(如 {key: null})存入 Redis,设置较短的过期时间(如 5 分钟);
- 优点:实现简单,无需额外组件;
- 缺点:会占用部分 Redis 内存,若大量不存在的 key 被缓存,会造成内存浪费;且可能出现数据不一致(数据库后续新增该数据,缓存仍为空)。
-
方案 2:布隆过滤器
- 原理:提前将所有合法的 key 存入布隆过滤器(一个大型 bitmap),请求先经过过滤器,不存在的 key 直接被拒绝,不进入缓存和数据库;
- 优点:内存占用少,无多余空 key;
- 缺点:实现复杂,存在一定误判率(可能将不存在的 key 判定为存在)。

3. 缓存击穿(热点 key 过期)
概念
一个高并发访问的热点 key,缓存过期失效,此时大量请求同时涌入,缓存无法命中,全部请求直接访问数据库,造成数据库瞬时压力暴增,也叫 "热点 key 问题"。

解决方案
-
方案 1:热点数据永不过期
- 原理:对核心热点数据(如首页热门商品)不设置过期时间,避免过期失效;
- 优点:彻底杜绝击穿问题;
- 缺点:会占用 Redis 内存,且需手动更新缓存数据,保证与数据库一致。
-
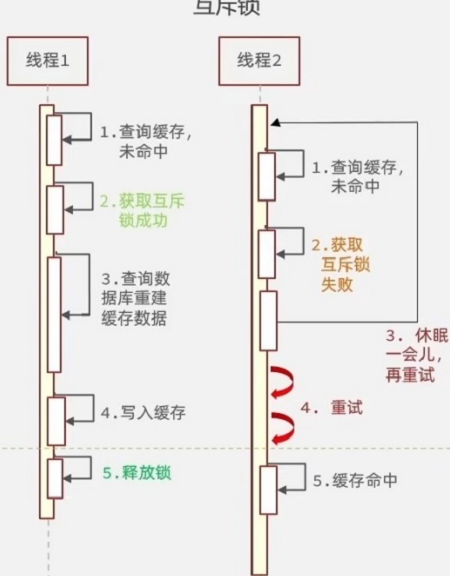
方案 2:互斥锁
- 原理:同一时间只允许一个线程查询数据库并重建缓存,其他线程等待(如使用 Redis 的 setnx 命令实现锁);
- 优点:保证数据强一致性;
- 缺点:会降低系统吞吐量,存在锁竞争开销。
4. 缓存雪崩(大量 key 同时过期)
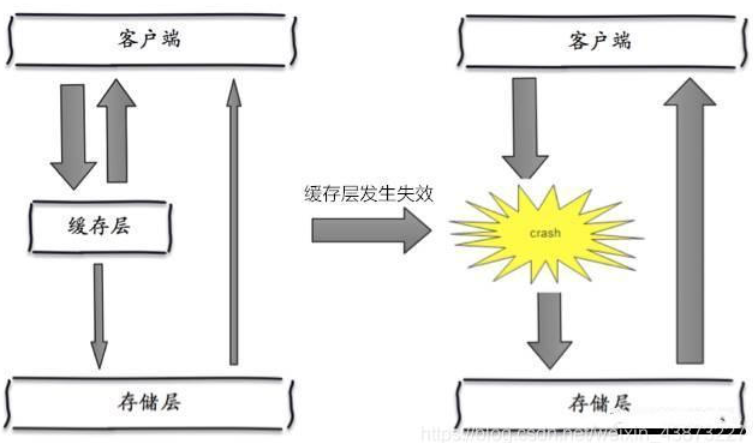
概念
大量缓存 key 在同一时间段集中过期,或者 Redis 服务宕机,导致所有请求都直接访问数据库,数据库承受不住海量请求而崩溃。
解决方案
- 过期时间随机化:给每个缓存 key 加上随机过期时间(如 10~20 分钟),避免大量 key 同时过期;
- 集群高可用:搭建 Redis Cluster 集群,避免单节点宕机导致整个缓存服务瘫痪;
- 热点数据永不过期:核心热点数据不设过期时间,保证缓存始终可用;
- 双缓存架构:设置缓存 A(设过期时间)和缓存 B(永不过期),请求先查 A,A 未命中查 B,同时异步重建缓存 A;
- 限流降级:缓存失效时,通过限流组件控制访问数据库的请求数量,避免数据库被压垮。
5. 补充概念(面试拓展)
- Redis 高可用:通过搭建集群(主从、哨兵、Cluster),实现多节点冗余,避免单节点故障导致服务中断;
- 限流降级:缓存失效后,通过加锁、队列或限流组件,控制访问数据库的线程数量,保护数据库;
- 数据预热:正式部署前,手动触发加载热点数据到缓存,避免大并发场景下,缓存未命中导致数据库压力骤增。
七、总结
Redis 集群的演进,本质是从 "解决单点故障" 到 "分担负载",再到 "分布式存储" 的过程:
- 主从复制:实现读写分离,解决单节点负载问题,是高可用基础;
- 哨兵模式:在主从复制基础上,实现自动故障转移,减少人工干预;
- Cluster 集群:多主多从 + 数据分片,彻底解决单机容量和并发瓶颈,是生产环境首选;
同时,缓存三大问题(穿透、击穿、雪崩)是 Redis 使用的核心隐患,需结合业务场景选择合适的解决方案,才能保证缓存服务稳定运行。