Harness Engineering:AI 从"聪明"到"可靠"的第三代工程范式
💡 TL;DR | 一分钟速读
AI 编码助手已经可以在数周内生成数十万行生产级代码。
但真正的挑战不是让 AI 写出代码,而是让它持续、可靠、可审计地工作。
解决这个问题的系统工程方法论,叫做 Harness Engineering(驾驭工程)。
如果你还停留在"怎么写好 Prompt"的阶段,这篇文章会让你意识到:你可能已经慢了整整一个时代。
目录
- [一、什么是 Harness Engineering?](#一、什么是 Harness Engineering? "#%E4%B8%80%E4%BB%80%E4%B9%88%E6%98%AF-harness-engineering")
- [二、AI 工程的三代进化史](#二、AI 工程的三代进化史 "#%E4%BA%8Cai-%E5%B7%A5%E7%A8%8B%E7%9A%84%E4%B8%89%E4%BB%A3%E8%BF%9B%E5%8C%96%E5%8F%B2")
- [三、Harness 的六大核心组件(三层架构)](#三、Harness 的六大核心组件(三层架构) "#%E4%B8%89harness-%E7%9A%84%E5%85%AD%E5%A4%A7%E6%A0%B8%E5%BF%83%E7%BB%84%E4%BB%B6%E4%B8%89%E5%B1%82%E6%9E%B6%E6%9E%84")
- 四、核心运营逻辑:用错误喂养规则库
- [五、Harness Engineering vs Fine-tuning:选哪个?](#五、Harness Engineering vs Fine-tuning:选哪个? "#%E4%BA%94harness-engineering-vs-fine-tuning%E9%80%89%E5%93%AA%E4%B8%AA")
- [六、失败场景推演:如果不做 Harness,会发生什么?](#六、失败场景推演:如果不做 Harness,会发生什么? "#%E5%85%AD%E5%A4%B1%E8%B4%A5%E5%9C%BA%E6%99%AF%E6%8E%A8%E6%BC%94%E5%A6%82%E6%9E%9C%E4%B8%8D%E5%81%9A-harness%E4%BC%9A%E5%8F%91%E7%94%9F%E4%BB%80%E4%B9%88")
- 七、七大反模式
- [八、我需要多完整的 Harness?------分级决策树](#八、我需要多完整的 Harness?——分级决策树 "#%E5%85%AB%E6%88%91%E9%9C%80%E8%A6%81%E5%A4%9A%E5%AE%8C%E6%95%B4%E7%9A%84-harness%E5%88%86%E7%BA%A7%E5%86%B3%E7%AD%96%E6%A0%91")
- [九、落地实践:从零构建第一个 Harness](#九、落地实践:从零构建第一个 Harness "#%E4%B9%9D%E8%90%BD%E5%9C%B0%E5%AE%9E%E8%B7%B5%E4%BB%8E%E9%9B%B6%E6%9E%84%E5%BB%BA%E7%AC%AC%E4%B8%80%E4%B8%AA-harness")
- [十、成本模型:Harness 的代价与收益](#十、成本模型:Harness 的代价与收益 "#%E5%8D%81%E6%88%90%E6%9C%AC%E6%A8%A1%E5%9E%8Bharness-%E7%9A%84%E4%BB%A3%E4%BB%B7%E4%B8%8E%E6%94%B6%E7%9B%8A")
- [十一、Harness Engineering 的行业影响](#十一、Harness Engineering 的行业影响 "#%E5%8D%81%E4%B8%80harness-engineering-%E7%9A%84%E8%A1%8C%E4%B8%9A%E5%BD%B1%E5%93%8D")
- 十二、FAQ
- 结语
一、什么是 Harness Engineering?
概念来源
"Harness"一词借用自软件工程中的 Test Harness(测试驾具) 概念------一套围绕被测对象的完整控制与验证基础设施。在 AI Agent 场景下,这一概念被延伸为:
Agent Harness(代理驾具) 是环绕 AI 模型的完整控制基础设施,包含记忆系统、工具接口、编排逻辑、安全护栏、可观测性管道与评估回路。
用一个公式表达:
ini
Agent = Model + HarnessModel 决定 AI 有多聪明,Harness 决定 AI 有多可靠。前者是模型公司的责任,后者是你的责任。
Harness Engineering 即围绕这套基础设施进行系统性设计、构建与运营的工程学科。
⚠️ 术语说明(请先读这一段)
截至本文写作时,"Harness Engineering"作为一个术语,尚未出现在 NeurIPS、ICML 等顶级学术会议论文中,也没有被 OpenAI、Google、Anthropic 等公司在官方文档中正式采用。
它目前是 AI 工程实践社区(LangChain、AI Engineer Summit 等)中正在形成共识的工程实践框架,而非已成熟的学术概念。
读者可以把它理解为:对 Agent 系统工程实践的一种系统性命名与归纳,而非某个权威机构颁布的标准。本文使用这一术语,是因为它精确描述了一类真实存在的工程需求。
为什么需要这个概念?
AI 模型天然具有三个工程缺陷:
| 缺陷 | 表现 | 工程后果 |
|---|---|---|
| 概率性输出 | 同一输入,输出不确定 | 难以通过测试、无法保证 SLA |
| 短时记忆 | 上下文窗口之外的内容全部遗忘 | 跨任务状态丢失 |
| 幻觉倾向 | 可能伪造数据、捏造引用 | 不可直接接入生产系统 |
Harness Engineering 就是专门用来填补这三个坑的系统工程学。
二、AI 工程的三代进化史
以下是一个有助于理解 AI 工程演进脉络的框架:
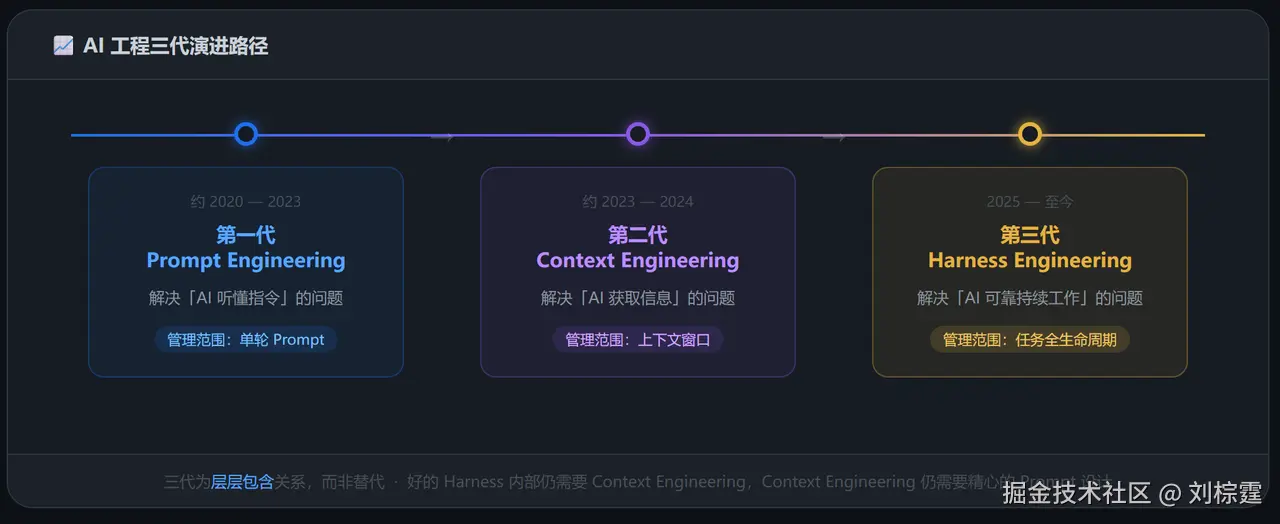
时间线说明 :Prompt Engineering 的实践可追溯至 2020 年 GPT-3 发布后,并非始于 2022 年------2022 年是 ChatGPT 发布后该概念大规模普及 的时间节点。三代之间并非严格替代关系,而是层层包含:好的 Harness 内部依然需要 Context Engineering,Context Engineering 依然需要精心的 Prompt 设计。
Context Engineering 这一术语由 Andrej Karpathy 于 2024--2025 年在 X(Twitter)上持续推广,他将其定义为"精心构建填入上下文窗口中所有内容的技艺"。Harness Engineering 可视为在此基础上的进一步延伸------从管理单次上下文,走向管理 Agent 的完整运行生命周期。
三代对比
| 维度 | Prompt Engineering | Context Engineering | Harness Engineering |
|---|---|---|---|
| 核心关注点 | 如何表达指令 | 如何管理信息 | 如何构建控制系统 |
| 管理范围 | 单轮 Prompt | 上下文窗口 | 任务全生命周期 |
| 主要技能 | 写作、表达 | 信息架构、RAG 设计 | 系统设计、反馈工程 |
| 瓶颈 | AI 理解能力不足 | 信息不全、过时 | AI 可靠性、可控性 |
| 典型工具 | ChatGPT 对话框 | LangChain、LlamaIndex | LangGraph、AutoGen、CrewAI |
| 工程师角色 | Prompt 撰写者 | 信息管道设计者 | 控制系统架构师 |
三、Harness 的六大核心组件(三层架构)
以下架构综合了 AWS Bedrock Agent、Azure AI Foundry、LangGraph 等主流生产框架中的设计模式。

第一层:信息层
① 记忆与状态管理
问题:LLM 的上下文窗口不是数据库,它会"忘记"。
工程解法:
python
# 错误做法:把所有历史塞进 context(导致"上下文腐烂")
messages = all_history # ❌
# 正确做法:外部状态管理 + 按需加载
class AgentState:
short_term: list # 当前会话(in-context)
long_term: VectorStore # 语义记忆(Pinecone/pgvector)
episodic: dict # 事件记录(Redis/DynamoDB)
def load_relevant(self, query: str) -> list:
return self.long_term.similarity_search(query, k=5) # ✅ 按需检索| 记忆类型 | 存储位置 | 典型技术 | 适用场景 |
|---|---|---|---|
| 短期(工作记忆) | Context Window | 直接注入 | 当前任务 |
| 长期(语义记忆) | 向量数据库 | Pinecone、Weaviate | 知识检索 |
| 情节记忆 | K-V 存储 | Redis、DynamoDB | 历史事件 |
| 过程记忆 | 结构化存储 | PostgreSQL | 工作流规则 |
关键原则:信息渐进式披露(Progressive Disclosure)------不要一次性把所有信息塞给模型,按任务阶段按需加载。
② 知识传递系统
核心任务:建立可维护的"AI 可读知识库",区分静态知识与动态知识。
markdown
静态知识(版本控制):架构文档、API 规范、代码风格指南
↓ 存入 Git + 向量库,随代码库版本更新
动态知识(实时更新):数据库状态、外部 API 返回值、用户最新输入
↓ 通过 MCP(Model Context Protocol)实时注入MCP(Model Context Protocol) 是 Anthropic 于 2024 年底推出、当前被 OpenAI 等广泛支持的开放协议,用于标准化 AI 模型与外部数据源(数据库、云盘、内部 API)的连接方式。详见:modelcontextprotocol.io
第二层:执行层
③ 工具与技能体系(Tool Sandbox)
生产级 Agent 的工具管理绝不是"给模型一堆函数调用"这么简单:
python
# 工具必须具备:Schema + 权限控制 + 执行边界
tool_registry = {
"read_file": {
"schema": {"path": "str", "encoding": "str"},
"permission": "read_only",
"sandbox": True,
"timeout": 5 # 秒
},
"execute_code": {
"schema": {"code": "str", "language": "str"},
"permission": "sandboxed_exec",
"sandbox": True,
"timeout": 30,
"memory_limit": "512MB"
}
}Skills 库(技能库):把领域内的标准流程封装成可复用操作单元:
code_review_skill:按照团队规范检查代码变更bug_fix_skill:定位→复现→修复→验证deploy_skill:预检→构建→灰度→监控
④ 编排与协调(Orchestration)
错误认知 :让 AI 自由发挥,"走一步看一步" 正确做法 :设计可验证的循环(Verifiable Loop)
css
任务输入 → 规划分解 → 执行子任务 → 机器验证
↑ |
└── 更新规则库 ← 错误分析 ┘[失败]
↓[通过]
保留交接信息 → 下一子任务核心原则 :每个子任务的完成标准必须机器可验证,而非人工判断。这是 Agent 系统从"演示级"迈向"生产级"的关键门槛。
多 Agent 协同时,交接状态(Handoff State)必须被序列化并持久化,防止"交接遗忘"导致任务断链。
第三层:反馈层
⑤ 约束与验证(Guardrails)
类比:操作系统不允许用户态进程直接操作硬件;浏览器不允许 JS 随意发起跨域请求。Harness 对 AI 的作用相同。
输入护栏 → 敏感词过滤 · PII 脱敏 · Prompt 注入检测
执行护栏 → 工具权限校验 · 文件系统范围限制 · API 频率控制
输出护栏 → 合规性检查(金融/医疗/法律)· 内容安全 · 格式验证强制 Chain-of-Thought:要求 AI 先展示推理过程再给出结论,方便人工追溯与审计------这在金融、医疗等监管行业是强制项。
⑥ 追踪与可观测性(Observability)
生产级 AI 系统必须像微服务一样可观测:
| 监控维度 | 监控内容 | 推荐工具 |
|---|---|---|
| Trace(链路追踪) | Agent 每一步的推理与行动 | LangSmith、Arize Phoenix |
| Metrics(指标) | Token 消耗、延迟、成功率 | Helicone、Prometheus |
| Logs(日志) | 错误日志、工具调用记录 | CloudWatch、ELK |
| Evals(评估) | 输出质量的自动化评分 | RAGAS、自定义 Eval |
熵控制(Entropy Control):Observability 的核心价值之一是在熵增失控之前发出预警,而不是等系统崩溃后复盘。
💬 读到这里,问你一个问题:
你们团队目前的 AI Agent,六大组件里做到了几个?
评论区告诉我,我会在下一篇汇总大家最常缺失的组件。
四、Harness 的核心运营逻辑:用错误喂养规则库
这是整个 Harness Engineering 方法论中最重要的一条运营原则:
sql
AI 犯错
↓ 不要只修正这一次的输出
↓ 把这次错误转化为一条规则/测试/约束
↓ 更新规则库(Constraint Library)
↓ AI 永远不再犯这个错
↓ 系统在使用中自我进化 ♻️在这种模式下,工程师的日常工作不再是亲手写功能代码,而是:
- 设计任务拆解规则与验证标准
- 维护知识系统与上下文架构
- 优化工具权限与沙箱边界
- 分析错误,并把每一次错误转化为系统改进
这种工作模式在主流 AI 编码产品的设计理念中均有体现------Devin、GitHub Copilot Workspace 等产品均强调验证循环与自动修复能力,越成熟的 AI 编码系统,越依赖这套"错误→规则"的飞轮机制。
五、Harness Engineering vs Fine-tuning:选哪个?
很多团队遇到 AI 表现不稳定,第一反应是"要不要微调模型"------这通常是一个代价高昂的误判。
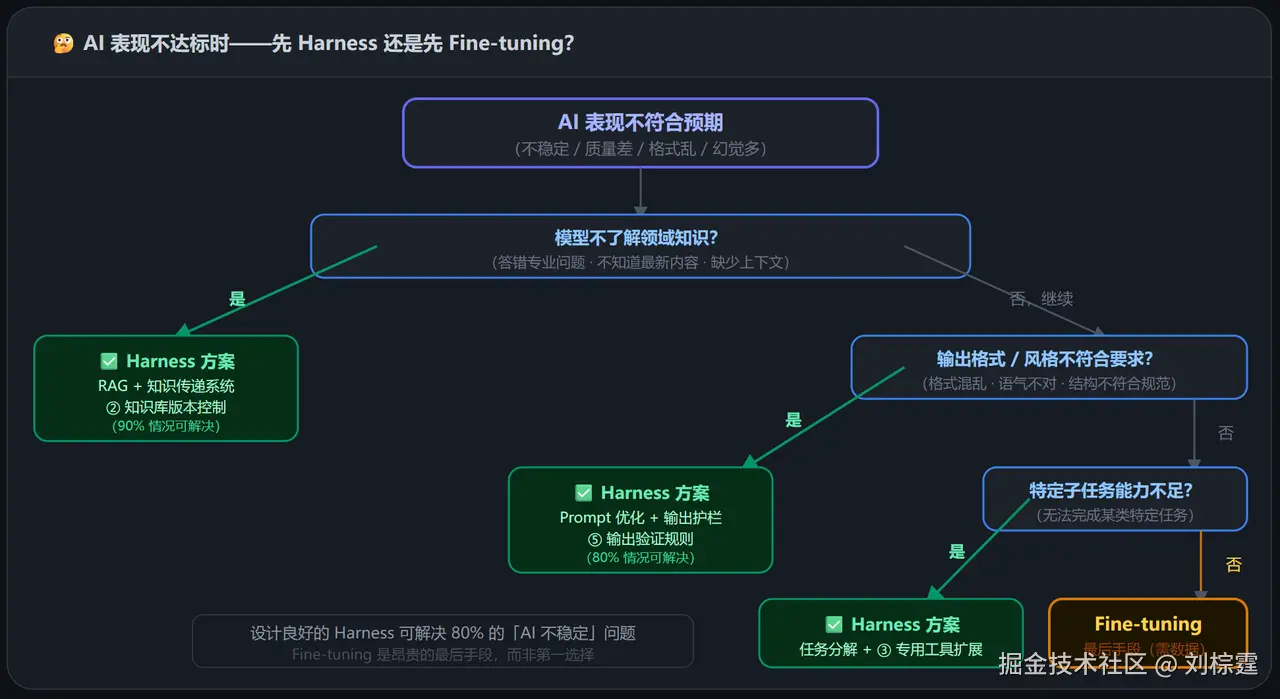
对比详解
| 维度 | Harness Engineering | Fine-tuning |
|---|---|---|
| 适用场景 | 知识注入、流程控制、安全约束 | 风格迁移、特定任务能力强化 |
| 数据需求 | 无需训练数据 | 需要高质量标注数据集(通常 1k+ 样本) |
| 迭代速度 | 快(改配置/规则即生效) | 慢(训练周期 + 评估周期) |
| 成本 | 低(推理时成本) | 高(GPU 训练 + 部署维护) |
| 可解释性 | 高(规则可读、护栏可审计) | 低(权重变化不可解释) |
| 推荐优先级 | 首选 | 作为 Harness 调优后的补充手段 |
实践原则 :在大多数生产场景中,一个设计良好的 Harness 可以解决大多数"AI 表现不稳定"问题。Fine-tuning 是昂贵的最后手段,而非第一选择。
六、失败场景推演:如果不做 Harness,会发生什么?
以下为虚构的典型场景,基于 AI 落地项目的常见失败模式构建,用于说明 Harness 各组件缺失后的实际后果,非特指某一真实事件。
假设场景:某 B2B SaaS 公司的 AI 客服 Agent

背景:一家中型 B2B SaaS 公司在 2025 年初上线了 AI 客服 Agent,用于自动处理用户工单。上线时 Demo 效果极好,工程团队很自信。
事故时间线:
| 时间 | 事件 | 严重程度 |
|---|---|---|
| 第 1 周 | 一切正常,客服满意度 92% | 🟢 正常 |
| 第 3 周 | Agent 开始推荐已下线的功能,用户投诉 | 🟡 告警 |
| 第 5 周 | 发现 Agent 偶发引用旧版退款政策 | 🔴 严重 |
| 第 6 周 | 用户截图发到社交媒体,引发舆情 | ⚫ 危机 |
根因分析:
| 根因 | 对应缺失的 Harness 组件 |
|---|---|
| 产品文档更新后未同步到 AI 知识库 | ② 知识传递系统(无版本控制机制) |
| 退款政策变更未触发 AI 知识库更新 | ② 动态知识注入缺失 |
| 没有对"账单/退款"话题设置特殊验证 | ⑤ 约束与验证护栏缺失 |
| 没有监控 Agent 回答质量随时间衰减 | ⑥ 追踪与可观测性缺失 |
修复方案(事后 Harness 补建):
- 建立产品文档变更→知识库自动同步管道(Git Hook → 向量库重索引)
- 对账单/退款/政策类话题增加强制人工审核节点
- 引入每日自动 Eval,用 200 个黄金测试用例检测回答质量漂移
- 建立"知识库版本"概念,每次变更记录变更时间和触发原因
教训:
这个项目不是"AI 能力不够"的问题------模型本身性能从未出问题。问题完全出在 Harness 缺失上。这是一个可以在上线前就被 Harness 评估发现并阻止的事故。
💬 你们团队有没有类似的翻车经历?
欢迎评论区分享(可匿名),我会整理成下期的"AI 落地翻车案例集"。
七、七大反模式(Harness 工程师必读)
以下错误在 AI 落地项目中极为常见,每一个都可能导致项目失败:
| # | 反模式名称 | 错误做法 | 正确做法 |
|---|---|---|---|
| 1 | 层级混淆 | 把 Harness 逻辑写进 Prompt | 分离模型层与控制层 |
| 2 | 工具堆砌 | 给模型 50+ 个工具"让它自己选" | 每个任务场景精选 ≤10 个工具 |
| 3 | 过早自治 | 跳过验证回路直接追求完全自动化 | 先建人工检查点,再逐步放权 |
| 4 | 忽视验证 | 只看模型输出是否"像对的" | 建立机器可验证的完成标准 |
| 5 | 静态规则库 | 规则写完就不更新 | 建立错误→规则的自动化管道 |
| 6 | 无状态设计 | 每次对话重新开始 | 用外部存储持久化任务状态 |
| 7 | 忽视熵管理 | 让 Agent 无限制地产生副作用 | 设计明确的边界与回滚机制 |
八、我需要多完整的 Harness?------分级决策树
最常见的问题:六大组件,我到底要全部做吗?
答案是:取决于你的 Agent 类型和风险等级。
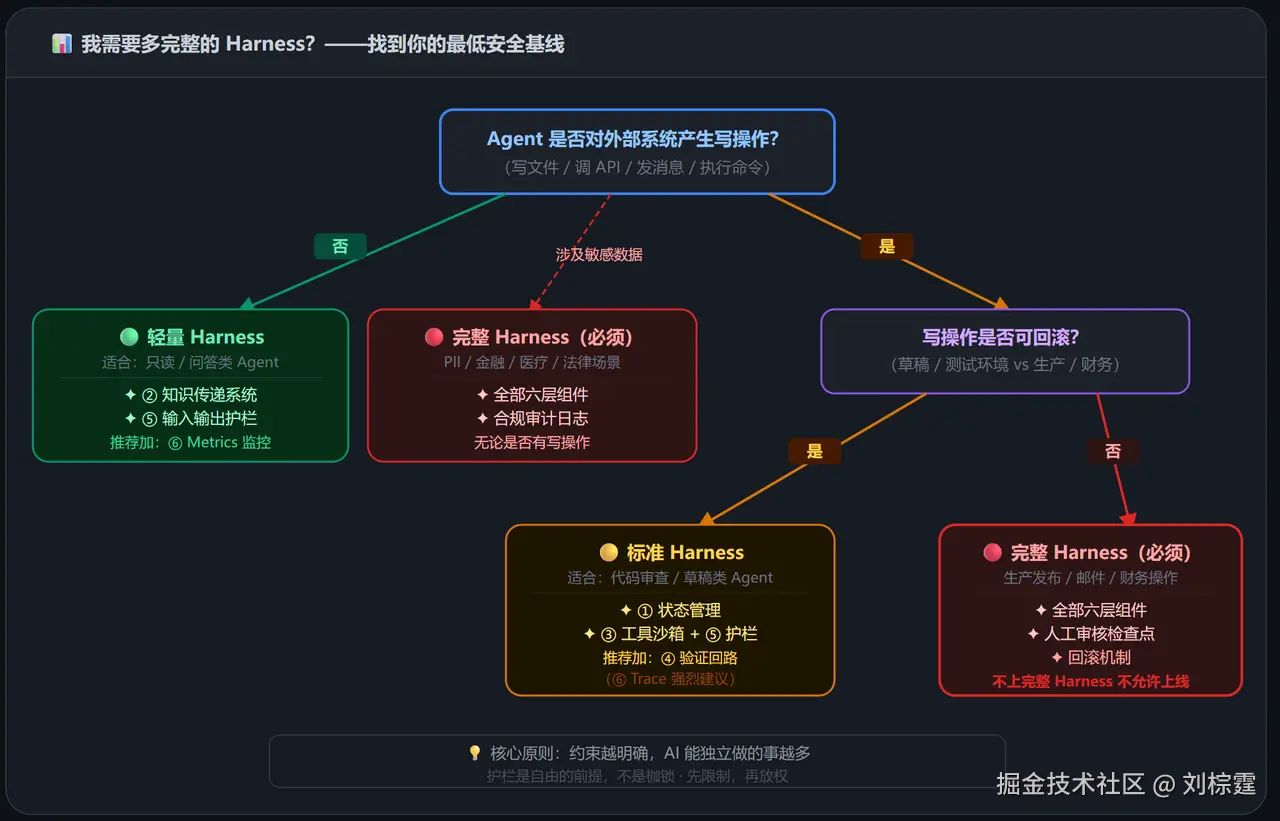
三个典型场景的配置建议
| 场景 | 必须做 | 建议做 | 可暂缓 |
|---|---|---|---|
| 内部知识问答 Bot | ② 知识传递、⑤ 输出护栏 | ⑥ Metrics、① 对话历史 | ③ 工具沙箱、④ 复杂编排 |
| 代码审查 Agent | ① 状态管理、③ 工具沙箱、⑤ 护栏、⑥ Trace | ④ 可验证循环、② 代码规范知识库 | 无 |
| 自动化运维 Agent | 全部六层 + 人工审核节点 | 回滚机制、变更审计日志 | 无(全部必须) |
💬 对号入座一下:
你们团队的 Agent 属于哪个场景?
评论告诉我,顺便说说你觉得最难落地的是哪一层。
九、落地实践:从零构建第一个 Harness
最小可行 Harness(MVH)三步法
第一步:定义边界
yaml
# harness_config.yaml
agent:
name: "code_review_agent"
allowed_tools: ["read_file", "search_code", "post_comment"]
forbidden_actions: ["delete_file", "push_to_main", "modify_ci"]
max_iterations: 50
timeout: 300s第二步:建立验证回路
python
def verify_agent_output(output: AgentOutput) -> VerificationResult:
checks = [
run_linter(output.code_changes),
run_unit_tests(output.code_changes),
check_security_scan(output.code_changes),
validate_against_spec(output.code_changes, spec)
]
return VerificationResult(passed=all(checks), details=checks)第三步:设计错误捕获管道
python
def handle_agent_error(error: AgentError, rule_library: RuleLibrary):
root_cause = analyze_root_cause(error)
new_rule = generate_rule_from_error(root_cause)
rule_library.add_rule(new_rule)
return retry_with_new_rules(rule_library)完整可运行 Demo
以下是一个真实可运行 的最小 Harness 实现,基于 openai Python SDK,无需额外框架依赖:
python
"""
minimal_harness.py ------ 最小可行 Harness 示例,可直接运行
依赖: pip install openai
运行: OPENAI_API_KEY=sk-xxx python minimal_harness.py
"""
import json
from dataclasses import dataclass, field
from typing import Any
from openai import OpenAI
client = OpenAI()
# ── ① 外部状态管理 ────────────────────────────────────────────────
@dataclass
class AgentState:
task: str
iteration: int = 0
max_iterations: int = 10 # 护栏:防无限循环
errors: list[str] = field(default_factory=list)
constraint_library: list[str] = field(default_factory=list)
completed: bool = False
# ── ③ 工具沙箱:所有工具必须注册,有明确权限和边界 ─────────────────
TOOL_REGISTRY = {
"read_file": {"permission": "read_only", "timeout": 5},
"write_note": {"permission": "append_only", "timeout": 3},
}
def sandboxed_tool_call(tool_name: str, args: dict) -> str:
if tool_name not in TOOL_REGISTRY:
return f"[BLOCKED] 工具 '{tool_name}' 未注册,禁止调用"
return f"[OK] 模拟执行 {tool_name}({args})"
# ── ⑤ 护栏:输入检测 + 输出验证 ──────────────────────────────────
BLOCKED = ["删除生产数据库", "rm -rf", "DROP TABLE"]
def input_guardrail(text: str) -> tuple[bool, str]:
for kw in BLOCKED:
if kw in text:
return False, f"输入包含危险指令 '{kw}',已拦截"
return True, ""
def output_guardrail(text: str) -> tuple[bool, str]:
if "password" in text.lower() and "=" in text:
return False, "输出疑似包含密码信息,已拦截"
return True, ""
# ── ④ 可验证的循环(Verifiable Loop)─────────────────────────────
def run_agent(task: str) -> dict[str, Any]:
state = AgentState(task=task)
ok, reason = input_guardrail(task)
if not ok:
return {"success": False, "blocked": reason}
constraints = "\n".join(f"- {c}" for c in state.constraint_library) or "暂无"
messages = [
{"role": "system", "content": (
f"你是严格遵守规则的 AI 助手。\n历史约束:\n{constraints}\n"
f"完成后输出 JSON:{{\"done\": true, \"result\": \"...\"}}"
)},
{"role": "user", "content": task},
]
while not state.completed and state.iteration < state.max_iterations:
state.iteration += 1
content = client.chat.completions.create(
model="gpt-4o-mini", messages=messages, temperature=0
).choices[0].message.content
ok, reason = output_guardrail(content)
if not ok:
state.errors.append(reason)
messages += [{"role": "assistant", "content": content},
{"role": "user", "content": f"输出违规:{reason},请重新生成。"}]
continue
messages.append({"role": "assistant", "content": content})
try:
parsed = json.loads(content)
if parsed.get("done"):
state.completed = True
return {"success": True, "result": parsed["result"],
"iterations": state.iteration, "errors": state.errors}
except json.JSONDecodeError:
err = "输出必须是合法 JSON 格式"
state.errors.append(err)
if err not in state.constraint_library:
state.constraint_library.append(err) # 错误→规则飞轮 ♻️
messages.append({"role": "user", "content": "请严格按 JSON 格式输出。"})
return {"success": False, "reason": "超过最大迭代次数",
"iterations": state.iteration, "errors": state.errors}
if __name__ == "__main__":
result = run_agent("请用一句话总结什么是 Harness Engineering。")
print(json.dumps(result, ensure_ascii=False, indent=2))这段代码演示了五个核心组件的协作:状态管理①、工具注册③、可验证循环④、输入/输出护栏⑤、错误→规则飞轮(核心运营逻辑)。
工具生态参考选型
| 场景 | 推荐工具 | 说明 |
|---|---|---|
| Agent 编排 | LangGraph、AutoGen | 支持多 Agent、可验证循环 |
| 向量记忆 | Pinecone、pgvector | 语义检索、按需加载 |
| 护栏 | NeMo Guardrails、Llama Guard | 开源可定制 |
| 可观测性 | LangSmith、Arize Phoenix | 全链路 Trace |
| 沙箱执行 | E2B、Modal | 安全代码执行环境 |
| 知识协议 | MCP(Model Context Protocol) | 标准化外部数据接入 |
十、成本模型:Harness 的代价与收益
Harness 不是免费的------它会增加延迟和 Token 消耗。工程师需要做出明智的权衡。
Token 消耗分析
| Harness 组件 | Token 消耗来源 | 典型增量 |
|---|---|---|
| 系统提示(约束库) | 每次调用注入规则 | +500~2000 tokens/次 |
| RAG 检索(知识注入) | 检索结果塞入 context | +1000~5000 tokens/次 |
| Chain-of-Thought | 中间推理步骤 | +30%~100% 输出 tokens |
| 多轮验证循环 | 失败重试带来的额外调用 | +1~3 次额外调用 |
| 可观测性(Trace) | 额外日志写入 | 无 Token 消耗,有存储成本 |
延迟 Trade-off
| 方案 | 平均延迟 | 可靠性 |
|---|---|---|
| 无 Harness(裸调用) | ~1-2s | 低,不可预期 |
| 最小 Harness(护栏 + 状态) | ~2-4s | 显著提升 |
| 完整 Harness(六层 + 验证) | ~5-15s | 高,适合生产 |
以上为经验估算值,实际数值因模型、网络环境、任务复杂度而异,仅供量级参考。
三条成本控制策略
策略一:按风险分级调用 低风险任务(读/查询/建议)→ 轻量 Harness,减少 RAG 和 CoT; 高风险任务(写/执行/发布)→ 完整 Harness,不省略任何环节。
策略二:约束库缓存 约束库内容变化不频繁,可缓存为系统提示前缀,节省约 10-20% Token。
策略三:验证回路短路 若任务类型历史成功率 > 95%,可先执行、异步验证,失败时触发回滚(适用于低风险写操作)。
ROI 视角:
一次生产事故的修复成本(工程师时间 + 用户流失 + 声誉损失),通常远超完整 Harness 六个月的 Token 增量成本。Harness 不是"烧钱",而是保险。
十一、Harness Engineering 的行业影响
随着 AI Agent 从演示走向生产,行业内正在逐渐形成以下共识------AI 应用上线前的最低安全评估基线:
- 是否有完整的状态管理机制
- 工具调用是否经过沙箱隔离
- 是否存在可机器验证的完成标准
- 是否有错误→规则的更新管道
- 可观测性覆盖率是否达标
- 安全护栏是否覆盖输入/执行/输出三个环节
这一评估框架在 LangChain、AWS Bedrock、Anthropic 等团队的生产最佳实践文档中均有不同程度的体现,代表了当前工程实践的最低安全基线,而非某家公司的专有标准。
十二、FAQ:常见问题解答
Q:Harness Engineering 和 MLOps 有什么区别? A:MLOps 关注模型的训练、部署与监控生命周期;Harness Engineering 关注 Agent 在运行时的行为控制与可靠性保障。两者互补,但层级不同。
Q:小团队有必要做 Harness 吗? A:一旦接入生产数据或对外服务,最小可行 Harness(MVH)是底线要求。只做内部演示,可以暂缓。
Q:LangChain 框架算 Harness 吗? A:LangChain 提供了 Harness 的部分组件,但一个完整的 Harness 还需要你自己设计护栏逻辑、验证回路和错误→规则的运营管道。框架是地基,不是房子。
Q:Harness Engineering 会取代提示词工程吗? A:不是取代,是包含。提示词工程是 Harness 的一个组件,而不是全部。
Q:如何评估我的 Harness 质量? A:三个核心指标:① 任务成功率 (目标 > 85%);② 错误重犯率 (应趋向 0,用滚动 7 日窗口统计);③ 系统熵增速度(通过 Trace 中状态大小变化趋势监测)。
Q:Harness 和 Fine-tuning 能同时用吗? A:可以,且在高要求场景下推荐同时使用。先用 Fine-tuning 强化基础能力,再用 Harness 保障运行时可靠性与安全性。
💬 最后问你一个问题:
如果今天要给你现有的 AI Agent 补 Harness,你会从哪个组件开始?
评论区见------我逐条回复。
结语
AI 不缺能力,缺的是一套让它不翻车的系统。
Harness Engineering 的本质,是把工程师的角色从"写代码的人"升级为"设计控制系统的人"。
烈马天生强悍,但没有马具,它不知道该往哪里跑。你的价值,不在于跑得多快,而在于设计那套驾具。
延伸阅读
- Chip Huyen, AI Engineering: Building Applications with Foundation Models (O'Reilly, 2025) --- huyenchip.com
- LangChain Blog: Building Production-Ready Agents --- blog.langchain.dev
- OpenAI Cookbook: Orchestrating Agents --- cookbook.openai.com
- AWS Bedrock: Agent Architecture Best Practices --- docs.aws.amazon.com/bedrock
- Andrej Karpathy on Context Engineering --- X/Twitter @karpathy, 2024--2025
- NVIDIA NeMo Guardrails --- github.com/NVIDIA/NeMo...
- Model Context Protocol 官方文档 --- modelcontextprotocol.io
- LangGraph 多 Agent 编排指南 --- langchain-ai.github.io/langgraph