摘要:
TokenSeg是针对3D 医学图像分割计算复杂度高、同质区域计算冗余问题提出。做法就是从编码器的四层中提取400个候选标记,捕捉全局解剖背景和精细边界细节;引入了一个边界感知标记器,它结合VQ-VAE量化和重要性评分来选择100个显著的标记,其中超过60%位于肿瘤边界附近;之后解码器根据这些确定好的标记来生成掩码。
介绍:
3D医学图像分割存在两大核心痛点:1.计算复杂度随体素数量立方级增长,高分辨率 volume 处理效率极低;2. 对空气、脂肪等同质区域做冗余计算,浪费算力且限制模型扩展性 。为了解决这些问题,最近的研究探索了高效或稀疏的建模策略。稀疏卷积网络和条件计算/动态路由选择性地激活显著区域中的计算,而注意力和解剖引导网络强调器官或病变的特定特征,这些方法 要么在体素层面、要么在稠密特征层面做计算 ,并且缺少对 3D 体数据一套清晰、可直接使用的紧凑压缩表征。尽管VIT引入了基于patch的计算并建立了长距离依赖,但仍然需要大量的计算,并且忽略了边界感知的优先顺序,这对于描绘病变边缘至关重要。
DeepSeek-OCR11通过矢量量化和重要性评分将4K文档图像压缩为数百个token,以相当于一小部分的计算实现了相当的识别精度。在这一范例的启发下,本文探索了类似的压缩原理是否可以扩展到体积医学数据。
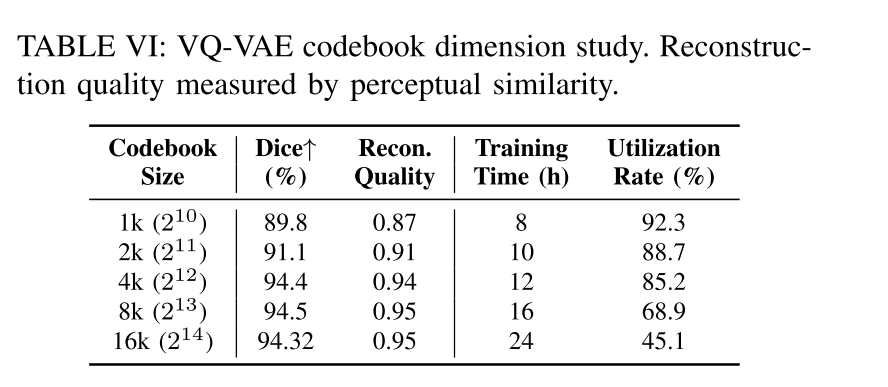
TokenSeg介绍了三个关键设计:(1)多尺度分层编码器,它在四个分辨率级别提取候选标记,以捕获全局解剖上下文和细粒度边界细节;(2)边界感知标记器,将矢量量化表示与基于重要性的选择相结合,仅保留集中在解剖边界周围的信息最丰富的标记;(3)稀疏到密集解码器,通过标记重新投影、渐进上采样和跳过连接来重建高分辨率分段掩码。
方法:
数据流程:
在编码器部分做了4 层不同清晰度的特征金字塔,然后不一个个像素算,而是把每层切成一个个小格子,每个格子只提取1 个代表点(token)。最后把 4 层拼起来,一共就400 个代表点。这样做保留了关键信息(特别是边界)并丢掉了没用的同质区域。
3D 核磁共振图像里,大部分都是背景和大片均匀区域,这些地方没什么有用信息。但分割准不准,关键就看边界位置,如果给所有点都分配一样的算力,就会把计算浪费在空白、没对比的地方,边界反而画不准,于是使用一个"优先看边界" 的令牌选择器,把算力全集中在边缘附近,同时让不同扫描图像的特征保持稳定。也就是说从编码器中得到的400个token,对其进行筛选,留下约100个token,其中大部分是肿瘤边界的特征。筛选标准为离肿瘤边界近不近;特征信息强不强;不重复用同一个模板。
这时已经完成Stage1和Stage2的全部工作,现在解码器只有 K 个稀疏关键点,解码器第一步就是:把这些点严丝合缝放回原来的位置,其他地方全设置为0。先钉死位置,再慢慢放大补全,最后画出完整、连续、精准的分割图。
之后就是将来自编码器的skip特征与当前稀疏特征图,上一层解码器的特征图concat在一起进行卷积等操作。
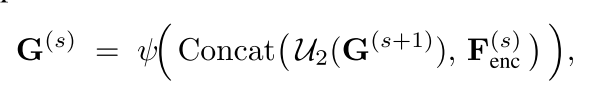
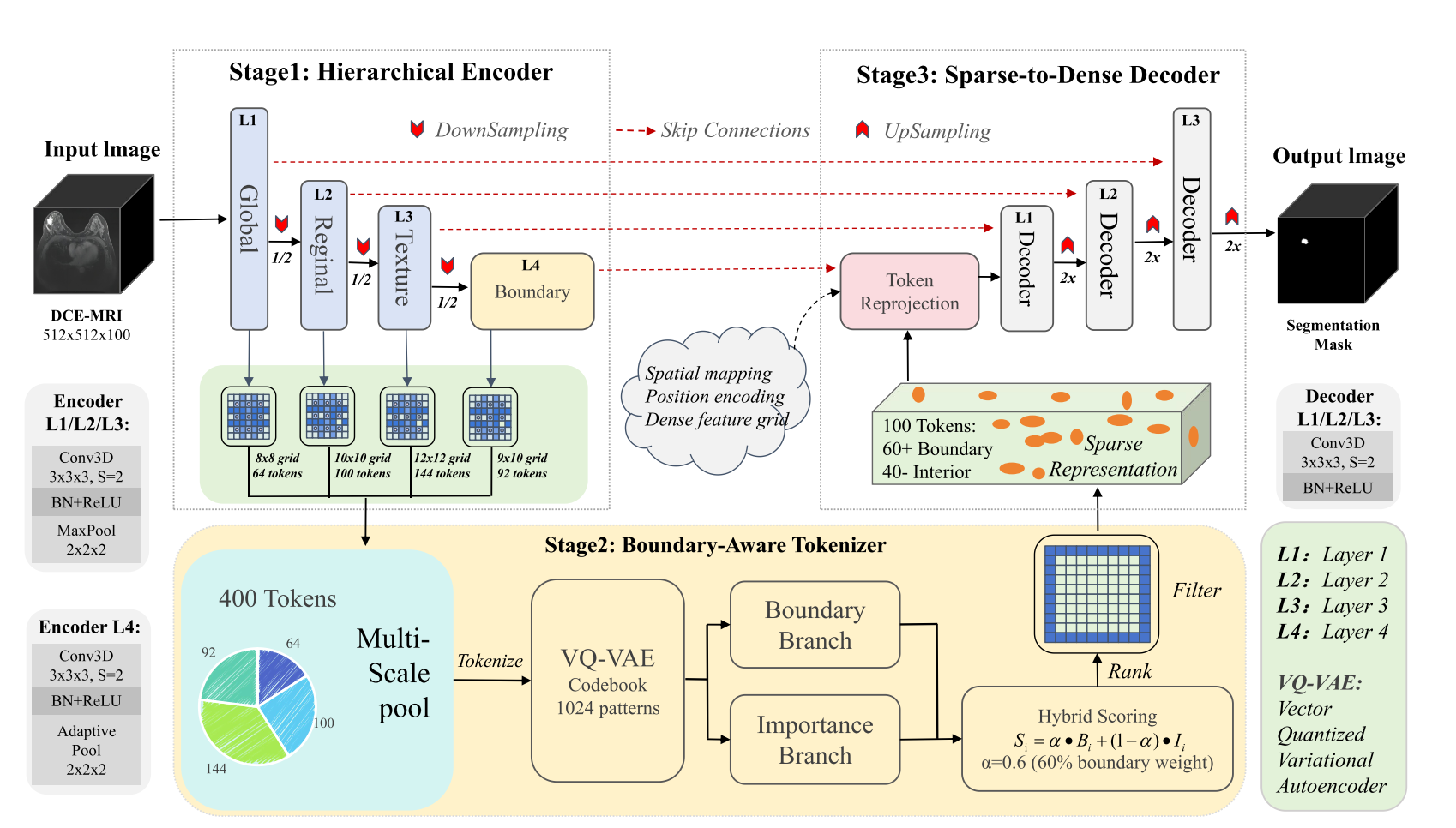
损失函数:




实验:
在验证集上的实验结果:
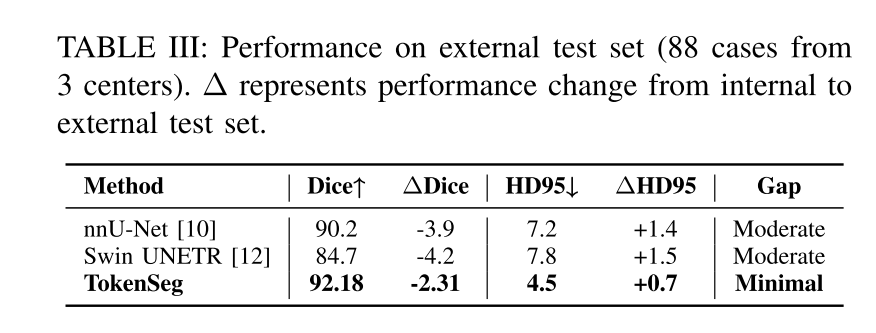
额外测试集上的实验结果:
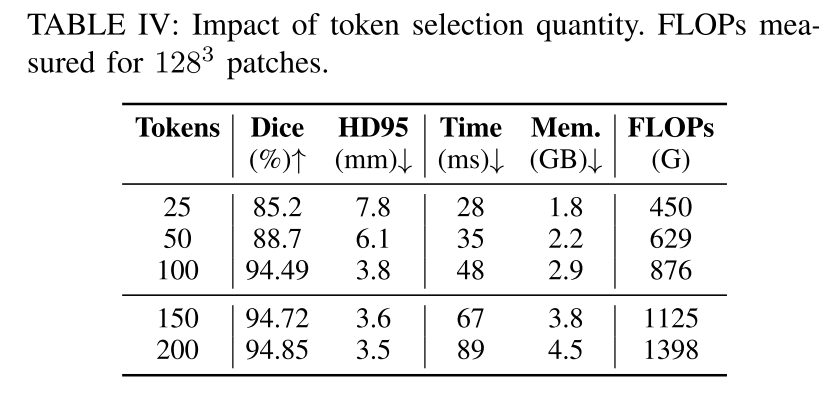
token数量选择对于模型性能的影响:
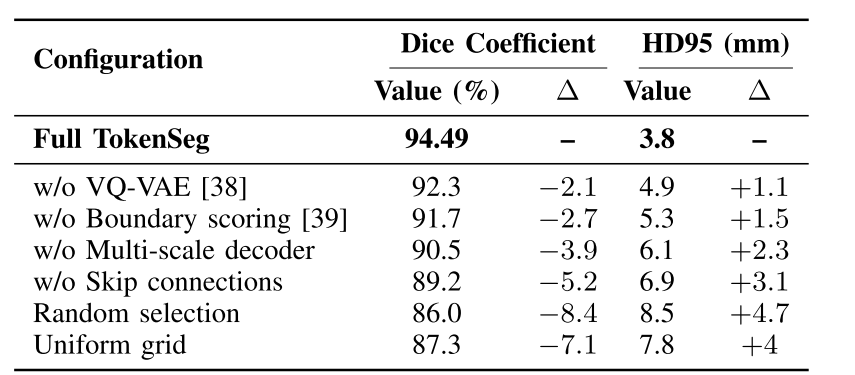
各组件消融实验:
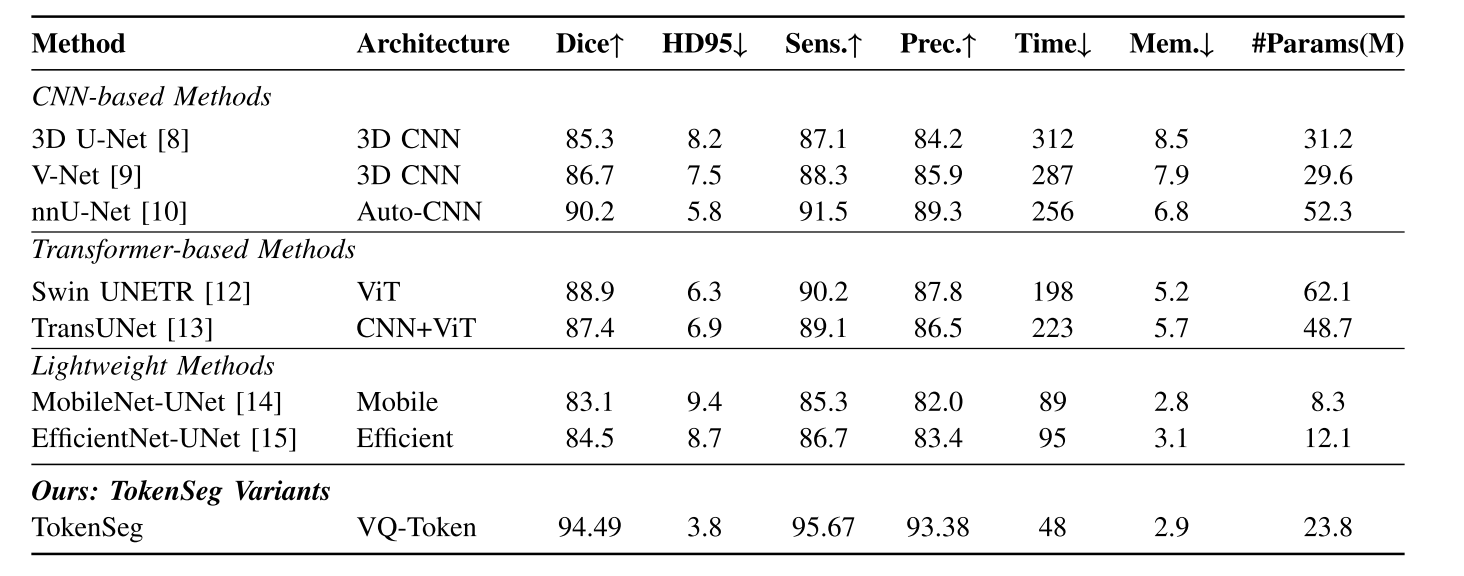
VQ-VAE 码本大小的消融实验