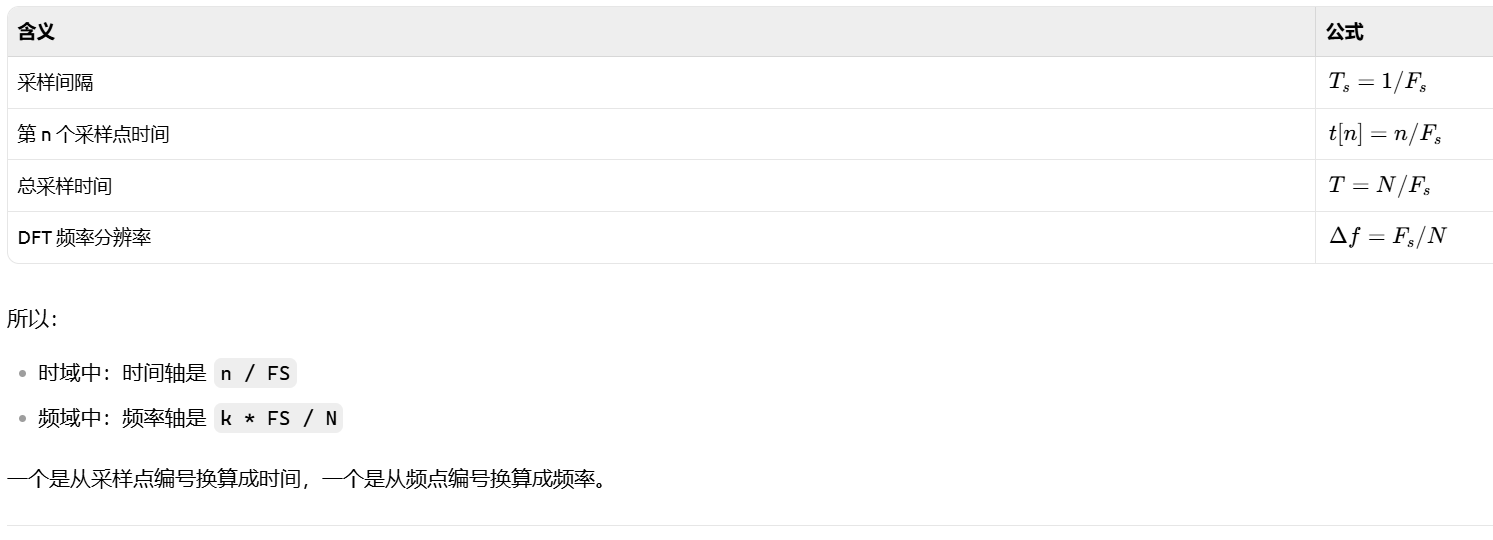
一、实验目的
掌握 DTMF(双音多频)信号的基本原理,利用 Python 实现信号的生成与识别,理解 Goertzel 算法相比 FFT 在特定频点检测上的优势。
二、实验原理
1. DTMF 编码规则
双音多频信号 (英语:Dual-Tone Multi-Frequency,简称:DTMF),电话系统中电话机与交换机之间的一种信令,最常用于拨号时发送被叫号码。不过双音多频的发明,除了缩短拨号时间,也扩展了拨号之外的功能,例如自动总机、交互式语音应答。
在双音多频信号普及之前,电话系统中使用一连串的断续脉冲来传送被叫号码,称为脉冲拨号。脉冲拨号需要电信局中的操作员手工完成长途接续。
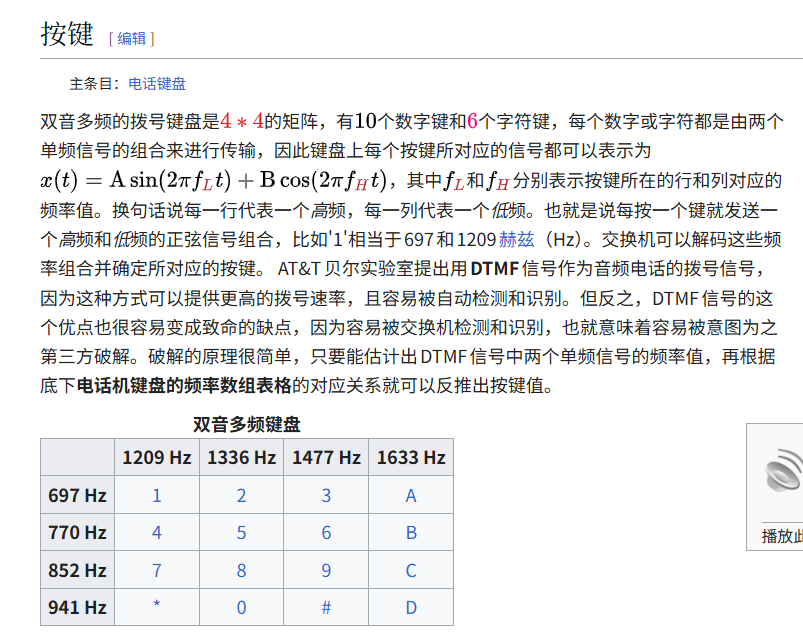
参考网页:https://zh.wikipedia.org/wiki/%E5%8F%8C%E9%9F%B3%E5%A4%9A%E9%A2%91
2. 识别方法
本实验分别使用 FFT 全频谱分析法 和 Goertzel 指定频点检测法 对 DTMF 信号进行识别,并比较两种方法的特点。
2.1 方法一:FFT 全频谱识别法
FFT 法的思路是:
对信号做 FFT,得到整个频谱;
在低频范围 650Hz 到 1000Hz 内找最大峰;
在高频范围 1100Hz 到 1700Hz 内找最大峰;
把检测到的频率贴近到标准 DTMF 频率;
查表得到按键。
它的特点是:
先算完整频谱,再从频谱中找目标频率。
2.2 方法二:Goertzel 指定频点识别法
FFT 会算出所有频点,但 DTMF 只关心 8 个固定频率:697, 770, 852, 941,1209, 1336, 1477, 1633,所以我们其实没必要算完整频谱。
Goertzel 算法可以理解成:
给某一个指定频率做一个检测器,只判断这个频率强不强。
对 8 个标准频率分别计算能量:然后:低频组取最大;高频组取最大;查表得到按键。
它的特点是:
不算完整频谱,只算关心的几个频率。这就比 FFT 更适合 DTMF 这种"目标频率固定"的任务。
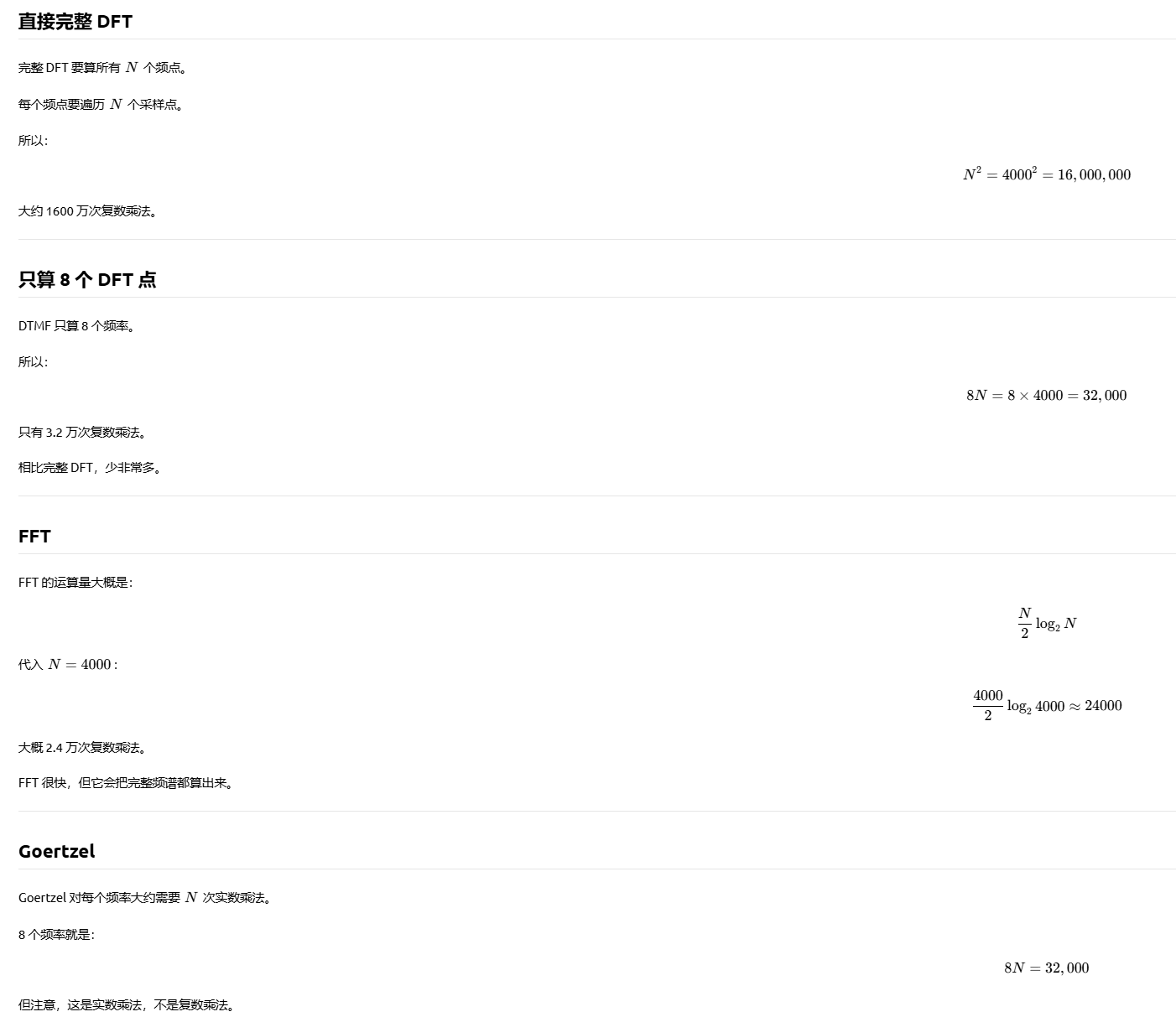
2.3 方法三: 直接算 8 个 DFT 点
DFT 公式,"可以只计算 8 个点",:DFT 的每一个频点 𝑋(𝑘) 是可以单独算的,不是非要一次性全算完。
(1).计算八个点:

DFT 公式一眼看出来:

频率和K:

FFT 频谱里大概就在 k=385 和 k=668 附近有峰。
(2) Goertzel 和"只算 8 个 DFT 点"是什么关系?

(3)运算量
(4)嵌入式系统
嵌入式系统,比如单片机、电话机芯片、小型语音设备,通常有几个限制:RAM 很小;CPU 不强;要实时处理信号;
从 DFT 公式可以看出,DTMF 信号的频率是固定的,只需要检测 697、770、852、941、1209、1336、1477、1633 这 8 个频率。因此没有必要计算完整频谱,只需要计算这 8 个目标频率上的能量即可。
Goertzel 算法可以看作是对单个 DFT 频点的高效递推计算。它不需要保存完整频谱,只需要为每个目标频率保存两个状态变量和一个系数,因此特别适合内存和算力有限的嵌入式系统。
(5)方法比较
有些 DTMF 频率不一定刚好落在整数 k

3.加窗
实际 DTMF 信号是有限长度的。比如只截取 0.5 秒,这相当于把原始连续信号"硬切"了一段下来。硬切会带来频谱泄漏。
本实验在识别前加入汉宁窗。由于实际信号是有限长度截取的,截断会带来频谱泄漏。汉宁窗可以减小信号两端的突变,从而降低旁瓣泄漏,使频率检测更加稳定。
加窗后信号幅度会有所下降,但本实验主要比较不同频率能量的相对大小,因此不影响按键识别结果。
三.任务拆分:
观察按键的频率,从而解出按键的内容
任务 1:合成一个 DTMF 信号

任务 2:对它做 FFT,画频谱
目标:把任务 1 的信号送进 FFT,画出频谱图。
需要回答的问题:频率轴怎么算?要不要加窗?要不要只画正频率?
1.频率轴
freq = np.fft.fftfreq(N, 1/f_s)
或者手写:
freq = np.arange(N) * f_s / N
2.要不要加窗?
DTMF 频率都是固定的,但你的信号长度大概率不是这些频率的整数周期,会有泄漏,建议加汉宁窗。
任务 3:自动找出两个峰值频率
目标:写代码自动找出频谱上最高的两个尖峰。
思路
在低频段(500~1000Hz)找最大的峰 → 这是"行频率"
在高频段(1100~1700Hz)找最大的峰 → 这是"列频率"
为什么要分两段找?因为 DTMF 的设计就是"一个低频 + 一个高频",分段找不会找错。
任务 4:把找到的频率匹配到最近的标准频率
目标:因为 FFT 有误差,找出来可能是 769.5Hz,要"贴近"到 770Hz。
思路
标准低频: 697, 770, 852, 941
标准高频: 1209, 1336, 1477, 1633
low_match = 距离 low_freq 最近的标准低频
high_match = 距离 high_freq 最近的标准高频
任务 5:查表反推按键
目标:从 (770, 1336) 反推出 "5"。
思路
用一个二维字典:
DTMF_TABLE = {
(697, 1209): '1', (697, 1336): '2', (697, 1477): '3', (697, 1633): 'A',
(770, 1209): '4', (770, 1336): '5', (770, 1477): '6', (770, 1633): 'B',
(852, 1209): '7', (852, 1336): '8', (852, 1477): '9', (852, 1633): 'C',
(941, 1209): '*', (941, 1336): '0', (941, 1477): '#', (941, 1633): 'D',
}
按键 = DTMF_TABLE(low_match, high_match)
任务6:Goertzel 指定频点识别法
观察DFT定义,老师提示"只需要检测 8 个标准频率",意思是:不用看完整频谱,只要问:这 8 个频率里,哪两个最明显?
Goertzel 算法是用来检测某个指定频率成分强不强的。DTMF 只需要检测 8 个标准频率,所以不用算完整 FFT。
公式:
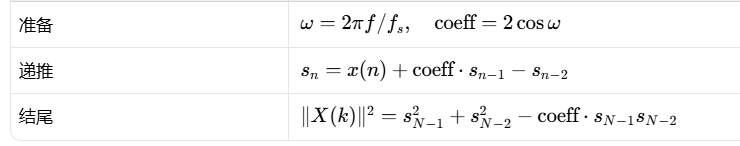
准备公式是根据目标频率生成检测器参数;递推公式是递推处理信号;结尾公式是把最后两个状态换算成该频率上的能量。
1.准备公式:
coeff 是后面递推公式里用的系数。它的作用可以理解成:coeff 决定这个检测器主要对哪个频率敏感。检测 697Hz,有一个 coeff。检测 770Hz,又是另一个 coeff。
2.递推公式:
它每次读一个新样本 𝑥(𝑛),然后更新一个中间变量 𝑠𝑛。
这个递推公式里有三个东西:𝑥(𝑛),当前新来的信号点,𝑠𝑛−1,上一次的状态,𝑠𝑛−2,上上次的状态,所以它有"记忆"。它不是只看当前一个点,而是一边读信号,一边把前面的影响累计起来。
如果输入信号里真的有目标频率,比如 770Hz,而你现在的检测器也是 770Hz,那么这个递推过程会越来越"对上节奏",最后数值会变大。如果输入信号里没有 770Hz,那它就不太能积累起来,最后数值较小。
3.结尾公式
这一步是把递推过程中留下的两个状态:𝑠𝑁−1,𝑠𝑁−2,转换成这个频率上的"强度分数"。这个值越大,说明这个频率越明显。
注意,它不是整段信号的能量,而是:目标频率 𝑓上的能量/强度。
说明:
为什么最后算能量,不直接算 X(k)?
因为识别 DTMF 只关心频率强弱,不关心相位。X(k) 是复数,包含幅度和相位;我们只需要幅度平方,所以直接算 |X(k)|^2,还省掉开根号和复数计算。

四.加窗实验:
用一个两端平滑归零的窗函数替代矩形窗,使信号两端自然过渡到零,消除截断处的突变,从而压低旁瓣、减少泄漏。
1.概念梳理
理想情况------录一段永远不停的 20kHz 正弦波:
频谱,一根直立的"针",正好立在 20kHz 处,其它地方全是 0。
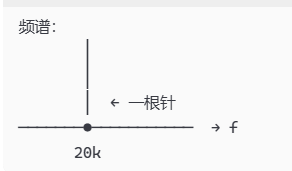
现实------只能录有限段,
真实情况是:你只录了 0.1ms 这一段:等价的数学操作是:原信号 × 一个矩形
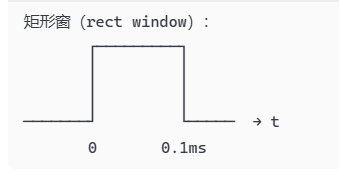
时域相乘⟺频域卷积,而矩形窗的频谱:
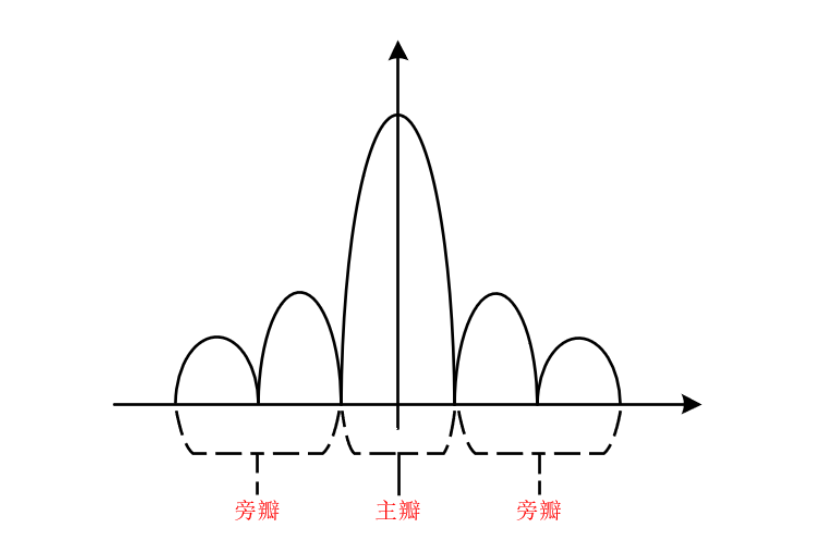
特征:主瓣:中间那个高大的尖峰,旁瓣:两边像波浪一样的小山丘,永远不会衰减到 0,会一直延伸出去
综上,

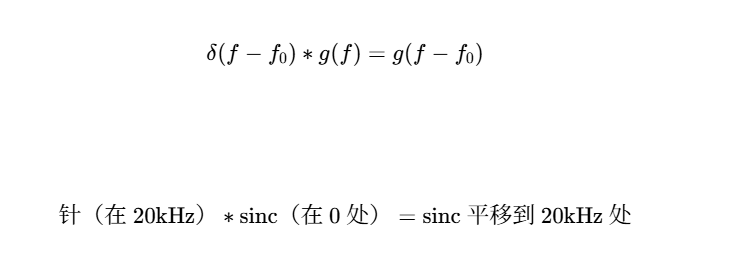
频谱泄漏:原本只该出现在 20kHz 的能量,"漏"到了周围的频率上。
2.实验代码
import numpy as np
from matplotlib import pyplot as plt
# ========== 参数 ==========
F_SMP = 1e6 # 采样率 1MHz
F_SIG = 20e3 # 信号 20kHz
T_SIM = 2.25 / F_SIG # 非整周期:2.25个周期
T_SMP = 1 / F_SMP
x = np.arange(0, T_SIM, T_SMP)
y = np.sin(2 * np.pi * F_SIG * x)
N = len(x)
# ========== 图1:时域四种窗对比 ==========
fig1, ax1 = plt.subplots(2, 2, figsize=(10, 6))
ax1[0][0].plot(x*1000, y)
ax1[0][1].plot(x*1000, y * np.hamming(N))
ax1[1][0].plot(x*1000, y * np.blackman(N))
ax1[1][1].plot(x*1000, y * np.hanning(N))
ax1[0][0].set_title("Original (Rectangular)")
ax1[0][1].set_title("Hamming")
ax1[1][0].set_title("Blackman")
ax1[1][1].set_title("Hanning")
for a in ax1.flat:
a.set_xlabel("Time (ms)")
a.set_ylabel("Amplitude")
fig1.tight_layout()
# ========== 图2:频域四种窗对比 ==========
NFFT = 8192 # 零填充到 8192 点,让频谱更细腻
fig2, ax2 = plt.subplots(2, 2, figsize=(10, 6))
windows = [
("Rectangular", np.ones(N)),
("Hamming", np.hamming(N)),
("Blackman", np.blackman(N)),
("Hanning", np.hanning(N)),
]
for i, (name, w) in enumerate(windows):
y_win = y * w
Y = np.abs(np.fft.fft(y_win, n=NFFT)) # 零填充到 NFFT 点
freq = np.arange(NFFT) * F_SMP / NFFT
half = NFFT // 2
# 转 dB(以最大值为参考)
Y_db = 20 * np.log10(Y[:half] / np.max(Y[:half]) + 1e-12)
row, col = divmod(i, 2)
ax2[row][col].plot(freq[:half] / 1e3, Y_db)
ax2[row][col].set_title(f"{name}")
ax2[row][col].set_xlabel("Freq (kHz)")
ax2[row][col].set_ylabel("Magnitude (dB)")
ax2[row][col].set_xlim(0, 60)
ax2[row][col].set_ylim(-80, 5)
ax2[row][col].axvline(x=20, color='r', linestyle='--', alpha=0.5, label='20kHz')
ax2[row][col].legend()
ax2[row][col].grid(True)
fig2.tight_layout()
plt.show()3.实验结果分析
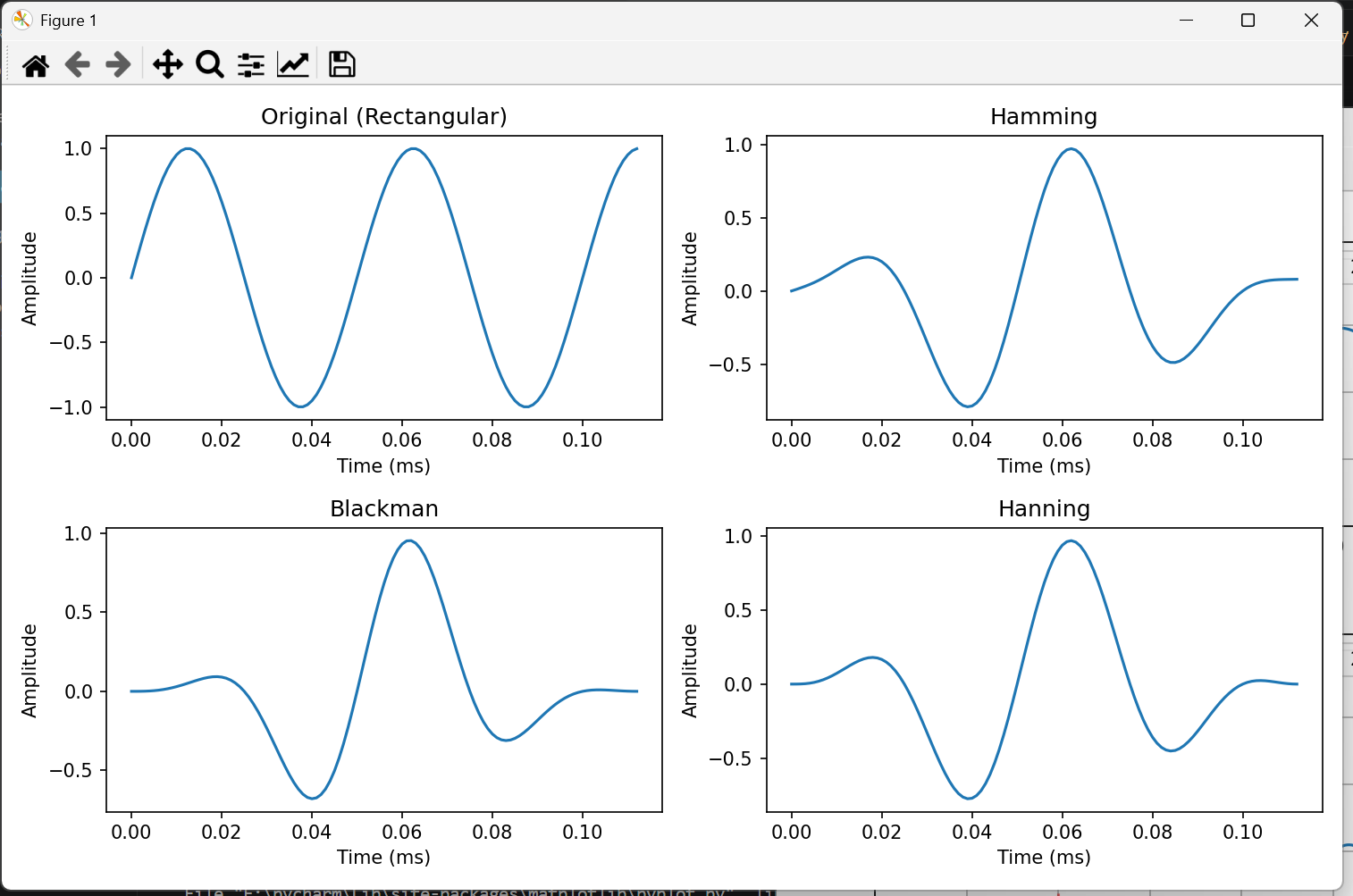
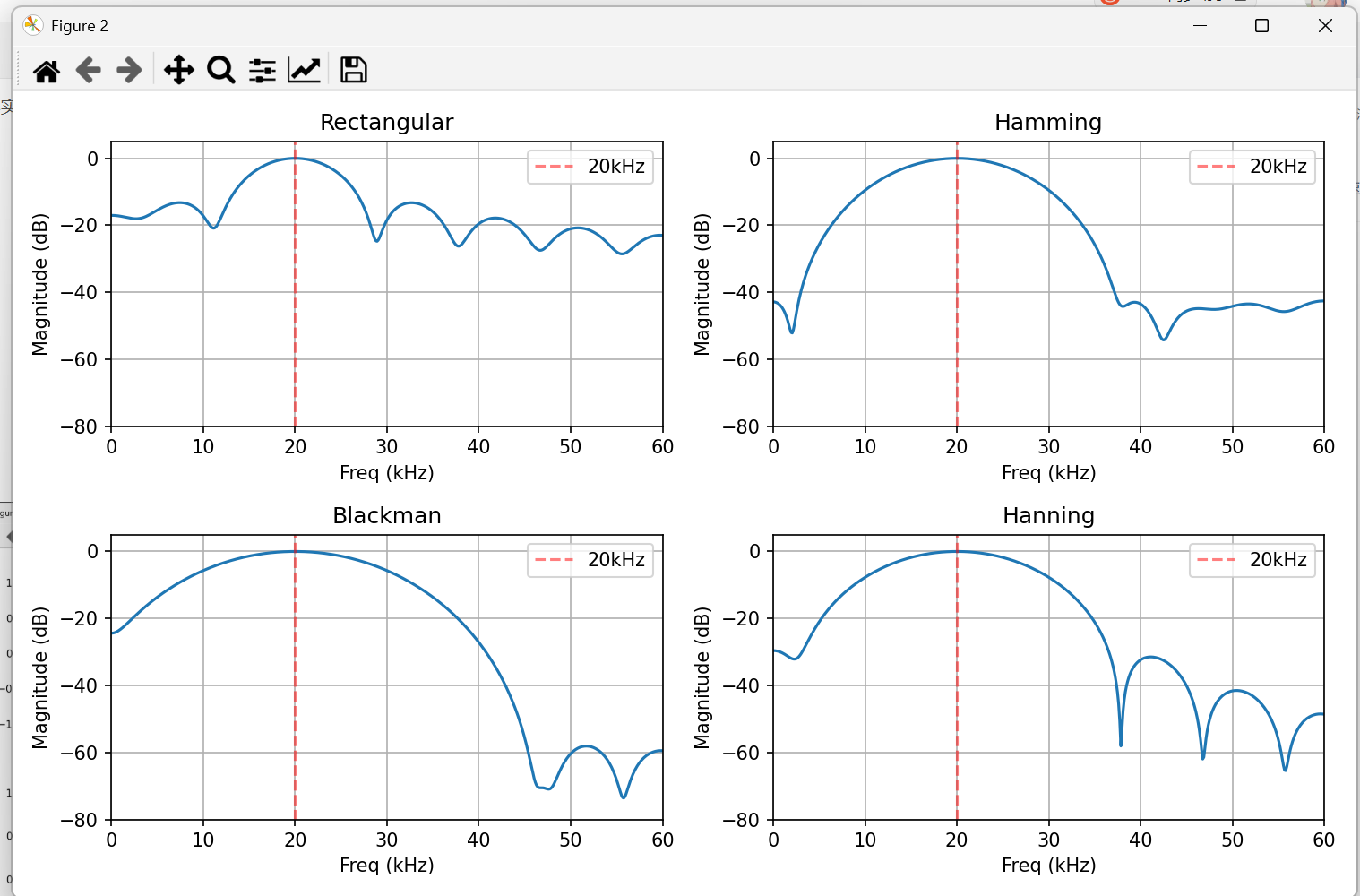
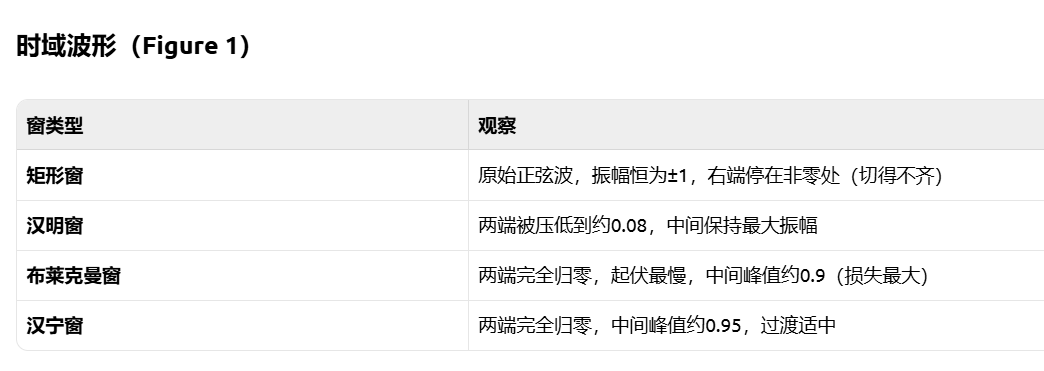
左上:矩形窗(Rectangular)
① 主瓣峰在红色虚线(20kHz)处
频谱的最高点确实在 20kHz 附近。这说明"信号确实是 20kHz"。
② 主瓣很宽(大约从 10kHz 到 30kHz)
这是因为你只有 2.25 个周期!信号太短 → 主瓣就胖。
信号越短 → 主瓣越胖 → 频率越"看不准"
③ 主瓣两边有波浪------旁瓣
看 0~10kHz 和 30~60kHz 区域,有很多小波浪,大约在 -20dB 左右。
-20dB 的旁瓣 = 主瓣的 1/10 能量。这就是泄漏------本不该有的频率成分。
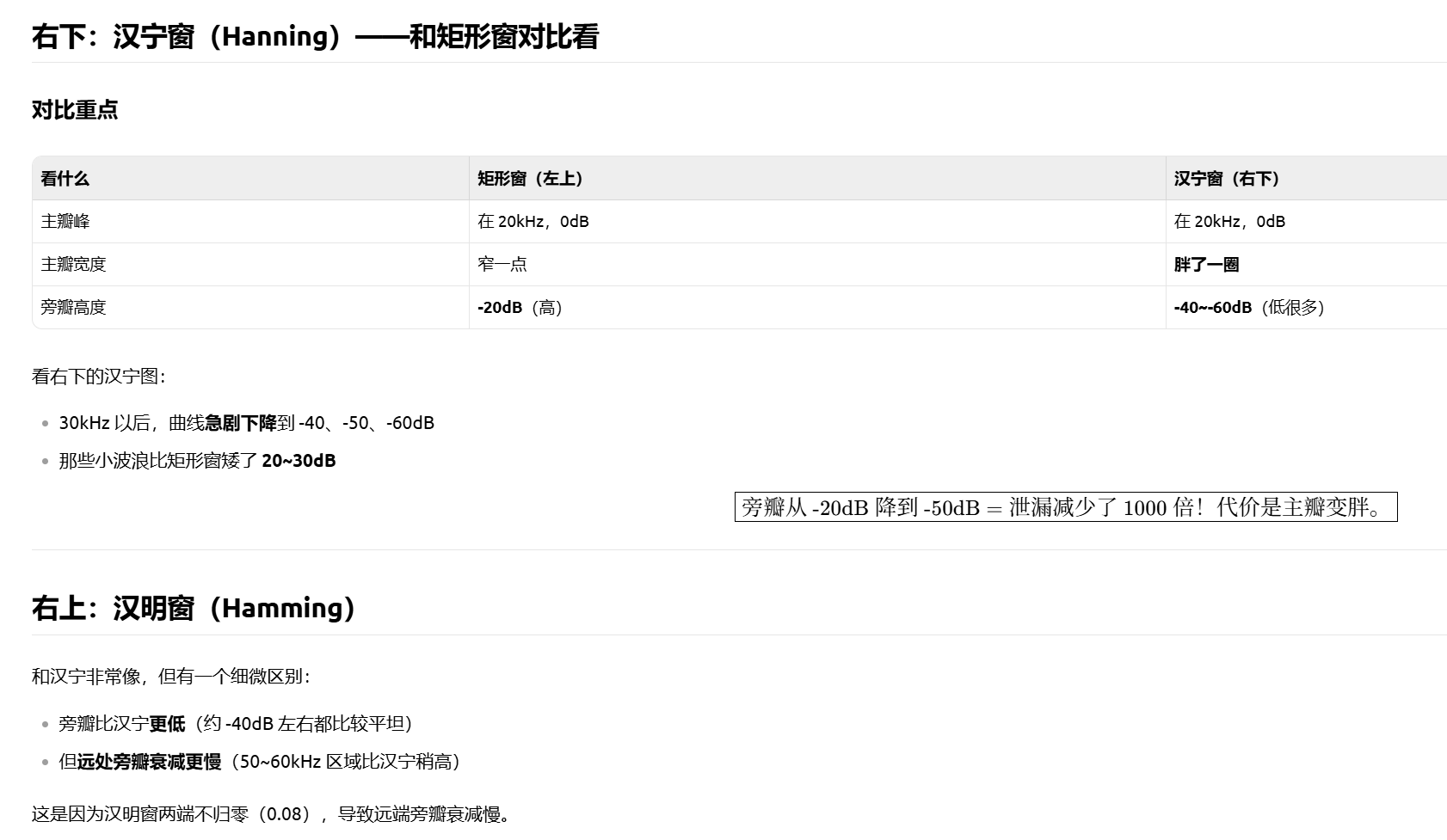

核心结论
压低旁瓣(减少泄漏)⟷主瓣变宽(分辨率降低),这是一个不可兼得的取舍。
需要分辨两个接近的频率 → 选矩形窗(主瓣窄)
需要检测微弱信号(不被强信号的旁瓣淹没) → 选布莱克曼窗(旁瓣低)
通用场景 → 选汉宁窗(折中)
4.问题记录

五.DTMF 双音多频信号生成与识别实验
本实验完成了 DTMF 信号的生成与识别。生成时根据按键表查出对应的低频和高频,将两个正弦波叠加得到按键信号。识别时没有使用完整 FFT,而是采用 Goertzel 算法,只检测 8 个 DTMF 标准频率上的能量。
相比 FFT,Goertzel 更适合这种只关心少数固定频率的场景。检测前加入汉宁窗可以减小有限长截取带来的频谱泄漏,使识别更加稳定。
1.代码
#!/usr/bin/env python3
import numpy as np
# ============================================================
# 1. DTMF 频率表
# ============================================================
FS = 8000
#每秒采 8000 个点。这是电话系统标准
LOW_FREQS = [697, 770, 852, 941]
HIGH_FREQS = [1209, 1336, 1477, 1633]
#行 = 低频,列 = 高频
DTMF_TABLE = {
(697, 1209): '1', (697, 1336): '2', (697, 1477): '3', (697, 1633): 'A',
(770, 1209): '4', (770, 1336): '5', (770, 1477): '6', (770, 1633): 'B',
(852, 1209): '7', (852, 1336): '8', (852, 1477): '9', (852, 1633): 'C',
(941, 1209): '*', (941, 1336): '0', (941, 1477): '#', (941, 1633): 'D',
}
# 反向表:由按键查频率
KEY_TO_FREQ = {}
# 遍历原始字典
for freq_pair, key in DTMF_TABLE.items():
# 键值互换,存入新字典
KEY_TO_FREQ[key] = freq_pair
# ============================================================
# 2. 生成 DTMF 信号
# ============================================================
def generate_dtmf(key, duration=0.5, fs=FS):
"""
生成指定按键的 DTMF 信号。
key: 按键,例如 '5'
duration: 信号时长,单位秒
fs: 采样率
"""
if key not in KEY_TO_FREQ:
raise ValueError(f"无效按键:{key}")
#raise:主动抛出错误,ValueError:值错误(Python 标准错误类型,表示传入的值不合法),
#Python出错直接 raise 抛异常,上层 try-except 接住。
f_low, f_high = KEY_TO_FREQ[key]
# 采样点数
N = int(fs * duration)
# 每个采样点对应的时间:t[n] = n / fs
t = np.arange(N) / fs
# 两个正弦波叠加
signal = np.sin(2 * np.pi * f_low * t) + np.sin(2 * np.pi * f_high * t)
return t, signal
# ============================================================
# 3. 方法一:FFT 全频谱识别法
# ============================================================
def decode_dtmf_fft(signal, fs=FS, use_window=True):
"""
使用 FFT 识别 DTMF 信号。
思路:先算完整频谱,再在低频区和高频区找峰值。
"""
signal = np.asarray(signal, dtype=float)
#把输入的信号强制变成 NumPy 数组(防止传入的不是数组),
#后面要做:FFT 快速傅里叶变换,乘法运算,频谱计算,这些只能用 NumPy 数组,普通 Python 列表做不了。
#把数据类型强制变成 浮点数 float,防止整数运算出错
N = len(signal)
# 加汉宁窗,减小频谱泄漏
if use_window:
window = np.hanning(N)
signal = signal * window
# 计算 FFT 幅度谱
spectrum = np.abs(np.fft.fft(signal)) / N
# 构造频率轴:freqs[k] = k * fs / N
freqs = np.arange(N) * fs / N
# 只在 DTMF 低频范围和高频范围内找峰值
low_mask = (freqs >= 650) & (freqs <= 1000)
high_mask = (freqs >= 1100) & (freqs <= 1700)
#布尔掩码 mask, low_mask = (freqs >= 650) & (freqs <= 1000)得到一个布尔数组:
# [False, False, ..., True, True, ..., False],表示哪些频率点在 650Hz 到 1000Hz 之间。
# 在低频范围内找最大幅度对应的频率
f_low_detected = freqs[np.argmax(spectrum * low_mask)]
f_high_detected = freqs[np.argmax(spectrum * high_mask)]
#np.argmax()返回最大值所在的下标。找到低频范围内频谱最大的位置,然后取出这个位置对应的频率。
# 把检测到的频率贴近到标准 DTMF 频率
f_low_match = min(LOW_FREQS, key=lambda f: abs(f - f_low_detected))
f_high_match = min(HIGH_FREQS, key=lambda f: abs(f - f_high_detected))
#在 LOW_FREQS 里面找一个最接近 f_low_detected 的标准频率。比如检测到:f_low_detected = 696,标准低频组是:[697, 770, 852, 941],最接近 696 的是 697。
#所以结果是:f_low_match = 697
#lambda f: abs(f - f_low_detected)临时小函数,类比普通函数:
#def distance(f): return abs(f - f_low_detected)
# 查表得到按键
key = DTMF_TABLE[(f_low_match, f_high_match)]
info = {
"f_low_detected": f_low_detected,
"f_high_detected": f_high_detected,
"f_low_match": f_low_match,
"f_high_match": f_high_match,
}
return key, info
# ============================================================
# 4. Goertzel 算法:只计算一个目标频率的能量
# ============================================================
def goertzel(signal, f_target, fs=FS):
"""
计算 signal 在目标频率 f_target 上的能量。
"""
omega = 2 * np.pi * f_target / fs
coeff = 2 * np.cos(omega)
s_prev = 0.0
s_prev2 = 0.0
for x in signal:
s = x + coeff * s_prev - s_prev2
s_prev2 = s_prev
s_prev = s
power = s_prev2**2 + s_prev**2 - coeff * s_prev * s_prev2
return power
# ============================================================
# 5. 方法二:Goertzel 指定频点识别法
# ============================================================
def decode_dtmf_goertzel(signal, fs=FS, use_window=True):
"""
使用 Goertzel 算法识别 DTMF 信号。
思路:只计算 8 个标准 DTMF 频率上的能量。
"""
signal = np.asarray(signal, dtype=float)
N = len(signal)
# 加汉宁窗,减小截断造成的泄漏
if use_window:
window = np.hanning(N)
signal = signal * window
# 计算低频组 4 个频率的能量
low_powers = np.array([goertzel(signal, f, fs) for f in LOW_FREQS])
#[表达式 for 变量 in 可迭代对象],快速生成列表,每次循环都调用函数,传入当前遍历到的频率f,计算这个频率的信号能量。每一轮返回一个能量数值。
#整个中括号运行完得到一个普通 Python 列表,存 4 个低频能量
# 计算高频组 4 个频率的能量
high_powers = np.array([goertzel(signal, f, fs) for f in HIGH_FREQS])
# 找到能量最大的低频和高频
f_low_match = LOW_FREQS[np.argmax(low_powers)]
f_high_match = HIGH_FREQS[np.argmax(high_powers)]
# 查表得到按键
key = DTMF_TABLE[(f_low_match, f_high_match)]
info = {
"low_powers": low_powers,
"high_powers": high_powers,
"f_low_match": f_low_match,
"f_high_match": f_high_match,
}
return key, info
# ============================================================
# 6. 测试
# ============================================================
if __name__ == '__main__':
test_keys = ['1', '5', '0', '#']
for test_key in test_keys:
t, signal = generate_dtmf(test_key)
decoded_fft, info_fft = decode_dtmf_fft(signal, use_window=True)
decoded_goertzel, info_goertzel = decode_dtmf_goertzel(signal, use_window=True)
print("\n==============================")
print(f"原始按键:{test_key}")
print(
f"FFT 法识别:{decoded_fft},"
f"检测频率约为 {info_fft['f_low_detected']:.1f} Hz + "#字典取值,['f_low_detected'] 取字典里的检测到的低频值
f"{info_fft['f_high_detected']:.1f} Hz,"
f"匹配到 {info_fft['f_low_match']} Hz + {info_fft['f_high_match']} Hz"
)
print(
f"Goertzel 法识别:{decoded_goertzel},"
f"匹配到 {info_goertzel['f_low_match']} Hz + "
f"{info_goertzel['f_high_match']} Hz"
)
if decoded_fft == test_key and decoded_goertzel == test_key:
print("✓ 两种方法均识别成功")
else:
print("✗ 存在识别失败")2.运行结果
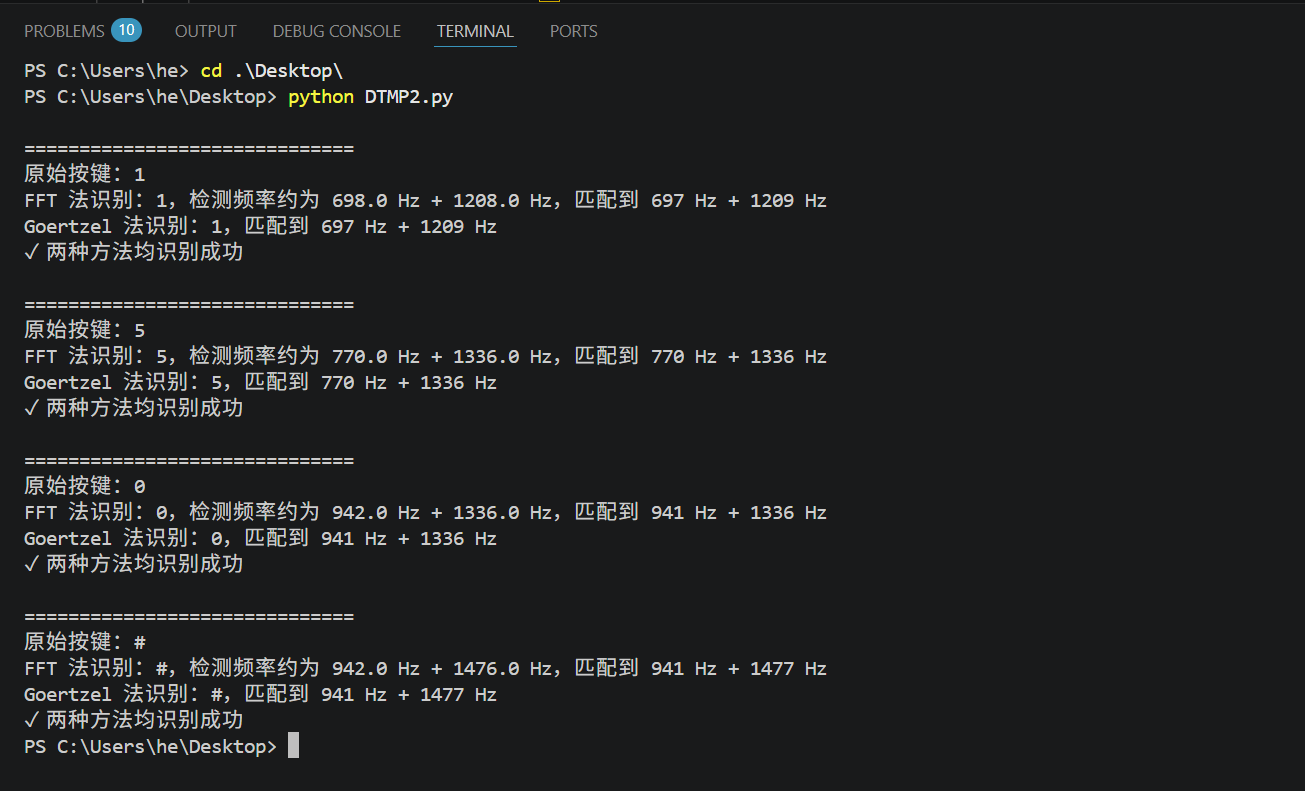
说明:关于时间轴和频率轴